一、FastText模型
1.概念与优势
FastText主要用于训练词向量和文本分类,其最大优势在于:保持较高精度的情况下,实现快速的训练和预测 。
FastText速度快的原因主要有三点:
- 模型结构简单:只有输入层、隐藏层、输出层三层
- 层次Softmax:训练词向量时,使用层次Softmax来提升超多类别下的计算性能
- 负采样技术:每次训练仅更新一小部分权重,大幅降低梯度下降的计算量。
需要注意的是,FastText模型过于简单,无法捕捉词序特征,解决办法是采用n-gram特征来弥补缺陷、提升精度。
2.模型架构
FastText采用经典的三层架构:
- 输入层(Input):对文档进行embedding后的向量,包含N-gram特征
- 隐藏层(Hidden):对输入数据进行求和平均
- 输出层(Output):文档对应的Label
3.层次Softmax
3.1 为什么需要层次Softmax?
传统Softmax在计算多分类时,需要计算所有类别的得分再归一化,当类别数量非常多时,计算量巨大。
3.2 层次Softmax的核心思想:
不再把输出看做扁平的类别列表,而是构建一颗哈夫曼二叉树,每个叶子节点对应一个类别,每个内部节点代表一个二分类逻辑回归问题。
3.3 哈弗曼树的构建规则:
WPL :带权路径长度(Weight Path Length)
权值:衡量某个节点的重要性的值
构建规则:
- 将n个权值看成n棵只有根节点的树的森林
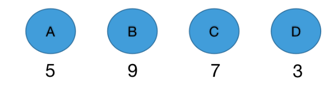
- 选取两个根节点权值最小的树合并,作为新树的左右子树,新树根节点为两者之和
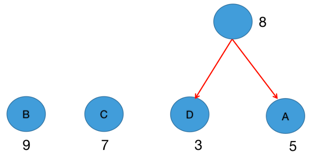
- 从森林中删除选取的两棵树,将新树加入森林
- 重复步骤2~3,直到森林只剩一棵树
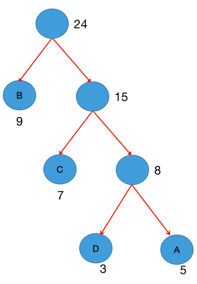
3.4 哈夫曼编码规则
左分支为0,右分支为1,从根到叶子节点所经过的0/1序列即为该节点的哈夫曼编码。
以下案例中,D的哈夫曼编码为110 。
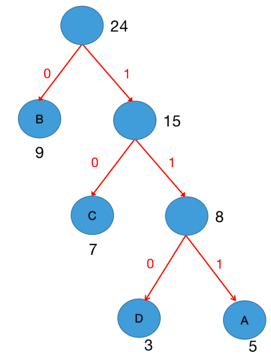
在预测时,从根节点出发,每个二分类节点输出一个概率,路径上所有概率相乘即为最终类别概率。
4.负采样
4.1 为什么需要负采样?
以Skip-Gram训练词向量为例,若词汇量达上万个,每次计算softmax概率时需要计算上万个概率值,且每个值都要反向传播更新参数,计算资源消耗巨大,训练缓慢。
4.2 负采样的核心思想
每次训练仅更新一小部分权重,而非全部。具体做法是:对于正样本期望输出1,同时随机选取少量负样本,期望输出0。训练时只更新正样本和负样本对应的权重。
4.3 负采样的优势
- 提高训练速度
- 损失计算更简单
- 增加负样本能模拟真实噪声,增强模型稳健性
小规模数据集:选5-20个negative words;大规模数据集:选2-5个negative words
二、文本分类
1.概念与种类
文本分类 :将文档分配到一个或多个类别,属于有监督学习,需要标签。
三种分类类型:
| 类型 | 含义 | 例子 |
|---|---|---|
| 二分类 | 非此即彼,二选一 | 好评 vs 差评 |
| 单标签多分类 | 多选一,单选题 | 判断人名属于哪个国家 |
| 多标签多分类 | 多选多,可同时属于多类 | 一段讨论涉及美食+体育+游戏 |
2.FastText数据格式
FastText有监督学习的训练数据格式如下:
text
__label__类别 词1 词2 ... 词N单标签示例:
text
__label__baking How much does potato starch affect a cheese sauce recipe?多标签示例:
text
__label__sauce __label__cheese How much does potato starch affect a cheese sauce recipe?三、实操案例
数据集使用Facebook AI提供的烹饪数据集(cooking.stackexchange),为多标签多分类问题。
1.数据获取与预处理
数据获取
bash
# 下载数据集
curl -o cooking.stackexchange.tar.gz https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz
# 解压
tar -xvzf cooking.stackexchange.tar.gz解压后得到这三个文件

数据预处理
python
import os
input_file = r"03_FasttextClassifier\data\cooking.stackexchange.txt"
with open(input_file, "r", encoding="utf-8") as f:
# 读取所有行
lines = f.readlines()
# 按8/2划分
split_idx = int(len(lines) * 0.8)
train_lines = lines[:split_idx]
valid_lines = lines[split_idx:]
# 写入文件
with open(r"03_FasttextClassifier\data\train_dataset.txt", "w", encoding="utf-8") as f:
f.writelines(train_lines)
with open(r"03_FasttextClassifier\data\valid_dataset.txt", "w", encoding="utf-8") as f:
f.writelines(valid_lines)
print("训练集已生成")2.基础模型训练
python
import fasttext
model = fasttext.train_supervised(r"03_FasttextClassifier\data\train_dataset.txt")
# 评估模型:(样本数,精确率,召回率)
result = model.test(r"03_FasttextClassifier\data\valid_dataset.txt")
print(f"评估模型:{result}")
# 预测
pred = model.predict("Which baking dish is best to bake a banana bread ?")
print(f"预测结果:{pred[0][0][9:]}")
"""
评估模型:(3081, 0.15676728334956183, 0.06791338582677166)
预测结果:baking
"""3.手动调参优化
3.1 增加训练轮数
python
import fasttext
model = fasttext.train_supervised(r"03_FasttextClassifier\data\train_dataset.txt", epoch=25)
result = model.test(r"03_FasttextClassifier\data\valid_dataset.txt")
pred = model.predict("Which baking dish is best to bake a banana bread ?")
print(f"评估模型:{result}")
print(f"预测结果:{pred[0][0][9:]}")
"""
评估模型:(3081, 0.45796819214540735, 0.1983970753655793)
预测结果:baking
"""3.2 调整学习率
python
import fasttext
model = fasttext.train_supervised(r"03_FasttextClassifier\data\train_dataset.txt", epoch=25, lr=0.1)
result = model.test(r"03_FasttextClassifier\data\valid_dataset.txt")
pred = model.predict("Which baking dish is best to bake a banana bread ?")
print(f"评估模型:{result}")
print(f"预测结果:{pred[0][0][9:]}")
"""
评估模型:(3081, 0.45666991236611487, 0.19783464566929135)
预测结果:baking
"""3.3 增加n-gram特征
python
import fasttext
model = fasttext.train_supervised(r"03_FasttextClassifier\data\train_dataset.txt", epoch=25, lr=0.1, wordNgrams=2)
result = model.test(r"03_FasttextClassifier\data\valid_dataset.txt")
pred = model.predict("Which baking dish is best to bake a banana bread ?")
print(f"评估模型:{result}")
print(f"预测结果:{pred[0][0][9:]}")
"""
评估模型:(3081, 0.32554365465757873, 0.14102924634420697)
预测结果:baking
"""3.4 使用层次Softmax替代普通Softmax
python
import fasttext
model = fasttext.train_supervised(
r"03_FasttextClassifier\data\train_dataset.txt",
epoch=25,
lr=0.1,
wordNgrams=2,
loss="hs"
)
result = model.test(r"03_FasttextClassifier\data\valid_dataset.txt")
pred = model.predict("Which baking dish is best to bake a banana bread ?")
print(f"评估模型:{result}")
print(f"预测结果:{pred[0][0][9:]}")
"""
评估模型:(3081, 0.36968516715352157, 0.16015185601799775)
预测结果:baking
"""4.自动超参数调优
python
from tabnanny import verbose
import fasttext
model = fasttext.train_supervised(
r"03_FasttextClassifier\data\train_dataset.txt",
autotuneValidationFile=r"03_FasttextClassifier\data\valid_dataset.txt",
autotuneDuration=60, # 自动调优时长(秒)
verbose=3 # 展示详细训练过程
)
result = model.test(r"03_FasttextClassifier\data\valid_dataset.txt")
print(f"评估模型:{result}")
"""
评估模型:(3081, 0.36968516715352157, 0.16015185601799775)
预测结果:baking
"""四、总结
FastText是NLP领域高效实用的工具包,核心价值在于兼顾精度与速度。其三层架构简单直接,通过层次Softmax解决多分类计算量大的问题,通过负采样降低梯度下降的计算开销,同时用n-gram特征弥补无法捕捉词序的缺陷。
| 优化方向 | 方法 | 效果 |
|---|---|---|
| 数据质量 | 预处理标点符号 | precision明显提升 |
| 训练轮数 | epoch: 5→25 | precision从0.12→0.52 |
| 学习率 | lr: 0.05→1.0 | 收敛更快 |
| 词序特征 | wordNgrams: 1→2 | precision→0.61 |
| 多标签分类 | loss='ova' | 正确处理多标签场景 |
| 自动调参 | autotune | 自动搜索最优超参数 |