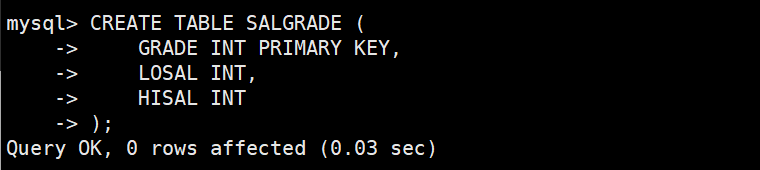
表的增删改查
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
给大家补充小知识点:(后面还会持续更新的)
**mysql不区分大小写,都可以(**针对 SQL 关键字和数据库名、表名、字段名)
mysql不支持+=;
select支持数学运算
一.Create
语法:
INSERT [INTO] table_name [(column [, column ...])] VALUES (value_list) [, (value_list)] ...
部分 含义 是否必须 INSERT [INTO]插入数据的关键字, INTO可省略必须 table_name要插入数据的表名 必须 [(column [, column ...])]指定要插入的列名,可省略(省略=全列插入) 可选 VALUES表示后面跟要插入的值 必须 (value_list)一组值,对应前面指定的列 必须 [, (value_list)] ...可以跟多组值,表示一次插入多行 可选
全列插入 时,
VALUES左侧不指定列名,右侧必须为表中所有列 按定义顺序提供对应值,数量和类型必须完全匹配;按列插入 时,VALUES左侧明确列出所需列名,右侧只需为这些列提供对应值,其余列自动使用默认值或NULL。两者核心区别在于:是否显式指定列及值的数量是否与表结构一致。
创建一张学生表

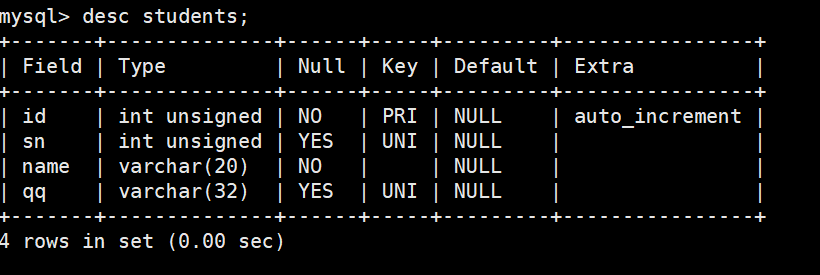
1-1单行数据 + 全列插入
- 插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
- 注意,这里在插入的时候,也可以不用指定id(当然,那时候就需要明确插入数据到那些列了),那么mysql会使用默认的值进行自增
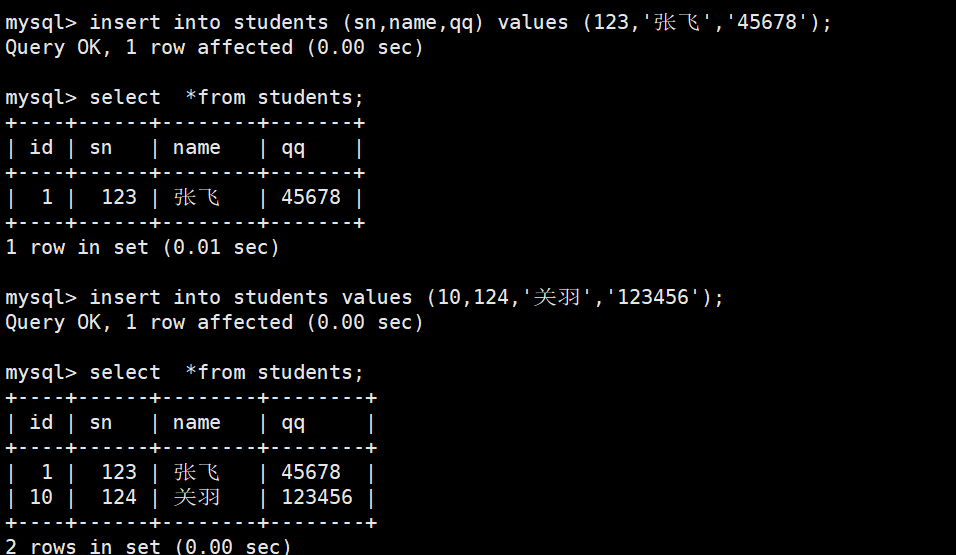
1-2多行数据 + 指定列插入
插入两条记录,value_list 数量必须和指定列数量及顺序一致
我前面还补充了几个都是用的单行插入但是不影响讲解
1-3插入否则更新
由于 主键 或者 唯一键 对应的值已经存在而导致插入失败

可以选择性的进行同步更新操作 语法:
INSERT ... ON DUPLICATE KEY UPDATE
column = value , column = value ...
之前还插入了一些为了方便我后续进行其他的操作:
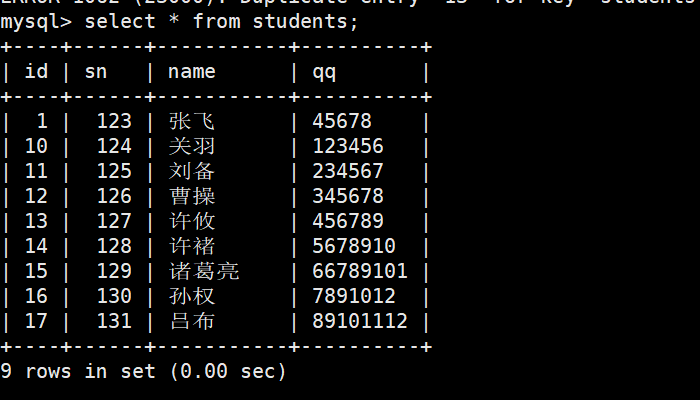
INSERT ... ON DUPLICATE KEY UPDATE是一种有条件的插入或更新操作:
当插入的数据没有与表中现有的主键或唯一键发生冲突时,就执行普通的插入操作。
当插入的数据与主键或唯一键发生冲突 (即该键的值已存在)时,则不插入新记录,而是更新该冲突行中指定的列。
示例:
sql
INSERT INTO students (id, name, score) VALUES (1, '张三', 90)
ON DUPLICATE KEY UPDATE name = VALUES(name), score = VALUES(score);
VALUES(列名)表示本次要插入的新值。可以同时更新多个列,用逗号分隔。
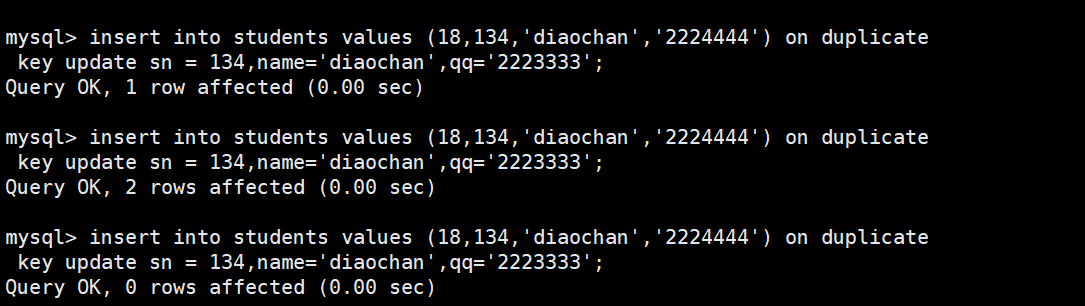
0 row affected :表中已存在冲突数据(主键或唯一键重复),且冲突行的当前值与
UPDATE子句中指定的新值完全相同,因此无需实际修改,故影响行数为 0。1 row affected:表中没有冲突数据,执行的是纯插入操作,因此影响行数为 1。
2 row affected :表中存在冲突数据,且冲突行的原值与
UPDATE子句中的新值不同,因此先删除旧行(1 行影响),再插入新行(1 行影响),总共影响 2 行。简单记忆:0 表示有冲突但值未变,1 表示无冲突直接插入,2 表示有冲突且值被更新。
通过 MySQL 函数获取受到影响的数据行数
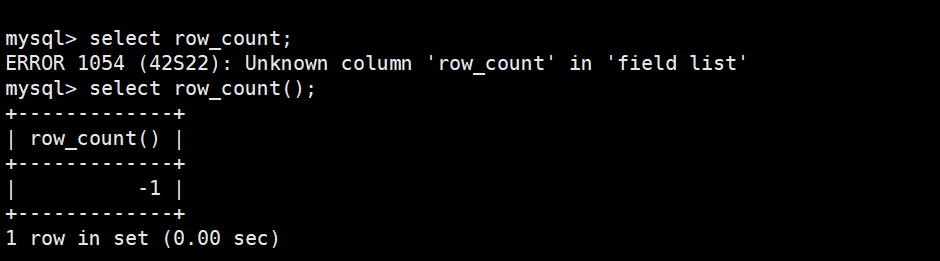
| 返回值 | 场景 |
|---|---|
-1 |
执行的是 SELECT 等非修改语句 |
0 |
有冲突,但新旧值相同,无实际修改 |
1 |
无冲突,执行插入 |
2 |
有冲突,且执行了更新 |
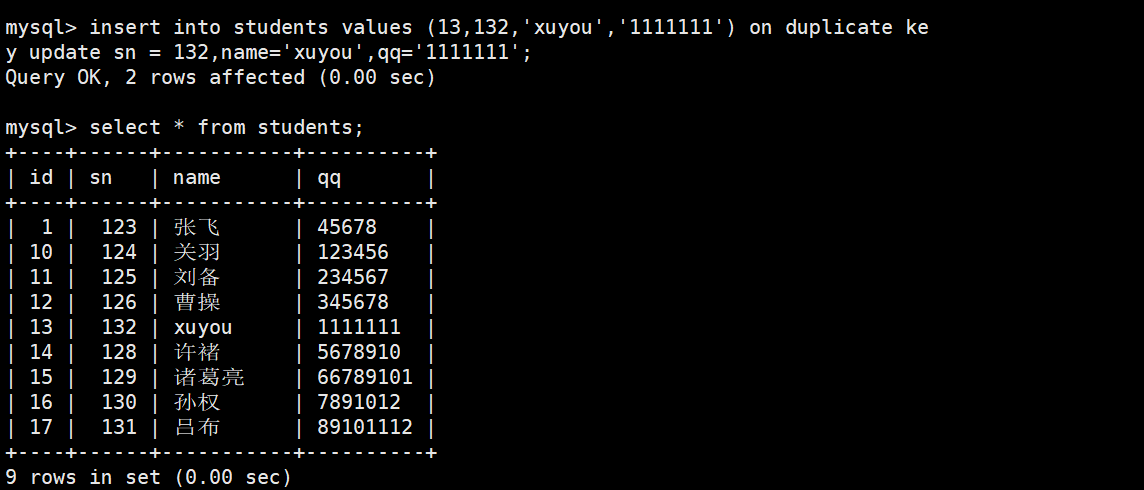
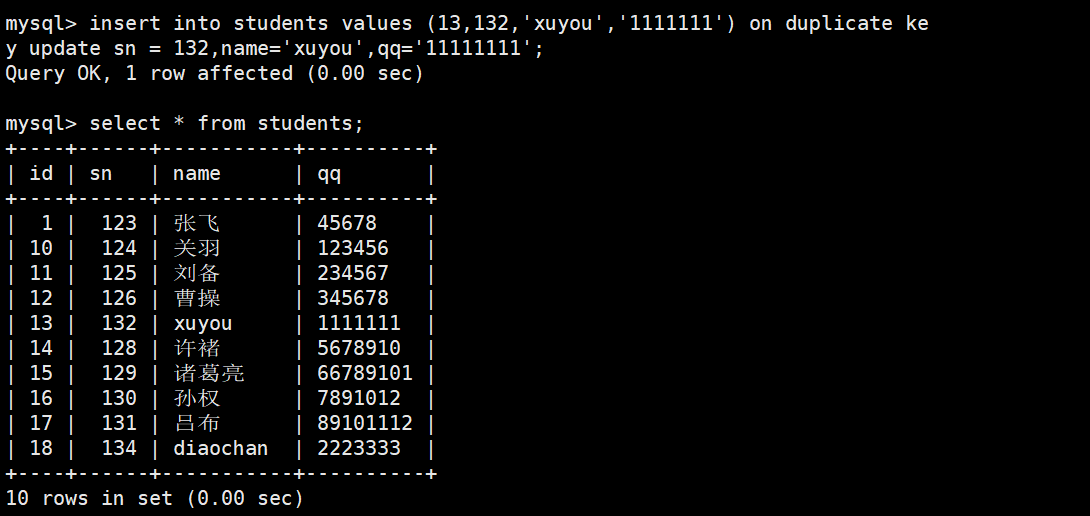
尝试插入一条
(id=13, sn=132, name='xuyou', qq='1111111')的记录,但如果主键id=13已经存在,就改为更新这条已存在记录的sn、name、
执行结果
2 rows affected的含义
2 rows affected表示:发生了主键冲突,且执行了更新操作。在
INSERT ... ON DUPLICATE KEY UPDATE中:
1 row affected-->没有冲突,执行插入
2 rows affected-->有冲突,执行更新(MySQL 内部是先删旧行再插新行的逻辑)
尝试插入一条
id=13, sn=132, name='xuyou', qq='1111111'的记录,但如果id=13已经存在(主键冲突),则改为更新这条记录,将它的sn、name、
Query OK, 1 row affected表示:
没有发生冲突 (
id=13原本不存在)执行的是 插入 操作
所以新行
(13,132,'xuyou','1111111')被成功插入
|---------------------------------------------|--------------------------------------------------|
|ALUES (13,132,'xuyou','1111111')| 要插入的数据:id=13, sn=132, name='xuyou', qq='1111111' |
|ON DUPLICATE KEY UPDATE| 如果主键(id)或唯一键冲突,就执行更新 |
|sn = 132, name = 'xuyou', qq = '11111111'| 冲突时,把这些列更新成新值 |
ON DUPLICATE KEY UPDATE是 先删除再插入,不是"比较新旧值是否相同"- 这就是"指定的值"的意义:冲突时以 UPDATE 里写的为准,而不是插入时的值 。(指定的值 "指的是
ON DUPLICATE KEY UPDATE后面 等号右边你手动写的那个值)
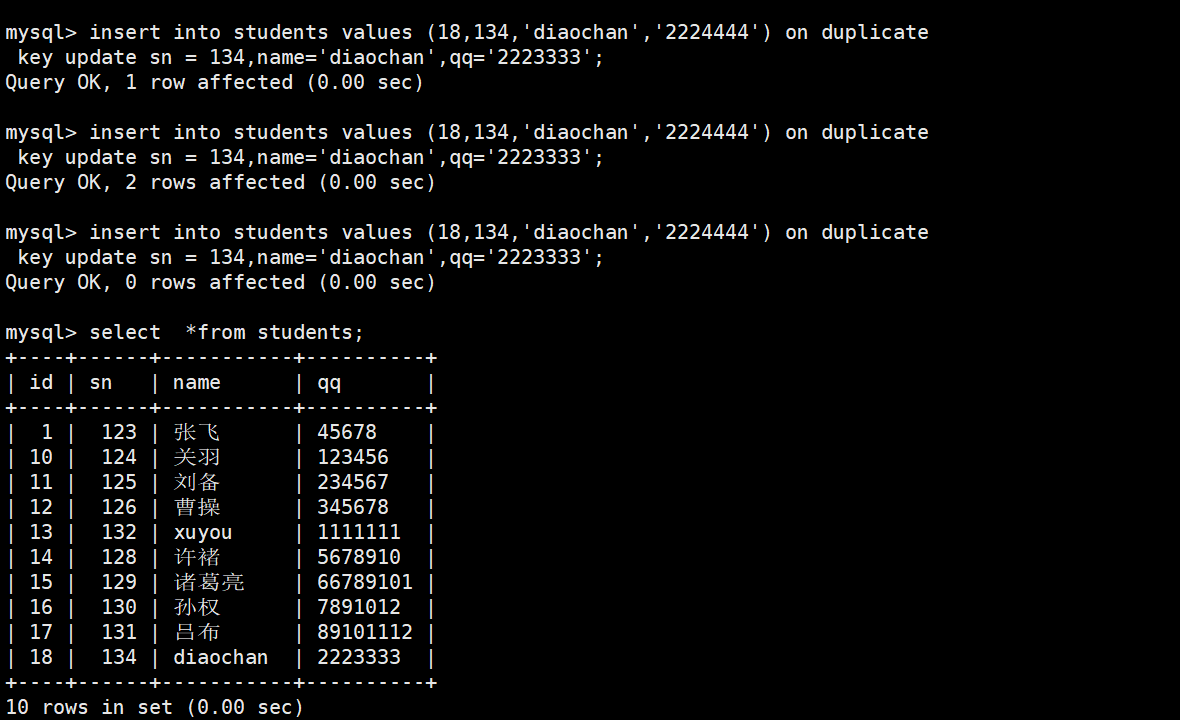
1-4替换
- 主键 或者 唯一键 没有冲突,则直接插入;
- 主键 或者 唯一键 如果冲突,则删除后再插入
| rows affected | 含义 |
|---|---|
| 1 | 无冲突,插入新行 |
| 2 | 有冲突,执行了删除 + 插入(数据可能变也可能不变,但 MySQL 物理上做了删插) |
| 0 | 有冲突,且 新旧数据完全相同,MySQL 跳过了实际修改 |
三次执行结果对应的"替换情况"
第一次(1 row affected)
-
没有冲突
-
没有发生任何替换(插入新行)
第二次(2 rows affected)
-
冲突发生
-
发生了替换 :
将
id=18这一行的sn/name/qq替换成 UPDATE 里指定的值 -
虽然插入值和旧值可能不同,但 MySQL 执行了物理删插
第三次(0 rows affected)
-
冲突发生
-
没有发生有效替换
因为 UPDATE 里的值和当前行已经一模一样,MySQL 认为"无需替换"
和 REPLACE 的区别(容易混淆的点)
| 语句 | 是否删除整行 | 是否可能丢列 | 自增行为 |
|---|---|---|---|
REPLACE |
是 | 会丢未指定的列 | 一定会新增自增 ID |
INSERT ... ON DUPLICATE KEY UPDATE |
否(逻辑是更新) | 只改指定列 | 不一定会新增自增 ID(除非物理删插) |
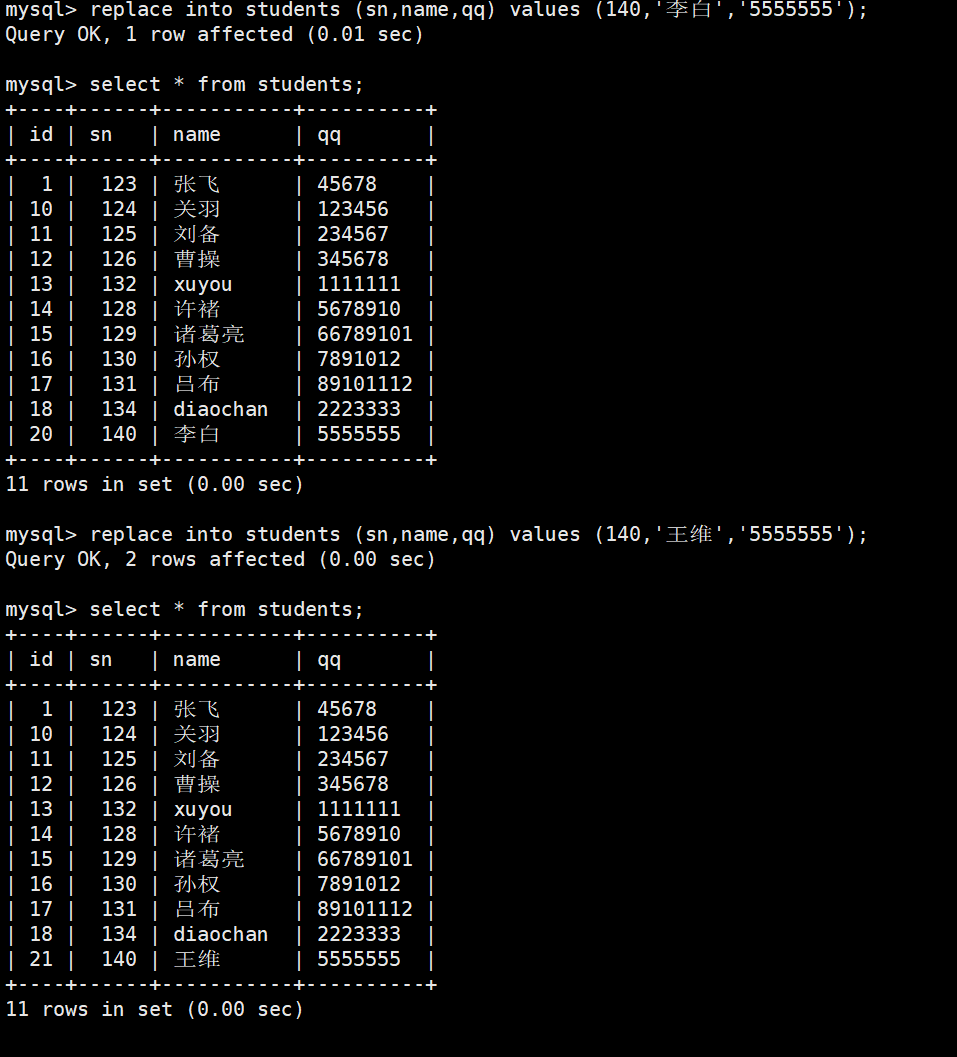
- 1 row affected:表中没有冲突数据,数据被插入。
- 2 row affected:表中有冲突数据,删除 后重新插入。
二.Retrieve
语法:
SELECTDISTINCT {* | {column , column ...}FROM table_nameWHERE ...ORDER BY column \[ASC \| DESC, ...]LIMIT ...
部分 含义 是否必须 SELECT查询关键字 必须 [DISTINCT]去重,去掉结果集中重复的行 可选 `{* column [, column ...]}` 选择哪些列: *表示所有列,或列出指定列名FROM table_name从哪张表查 必须 [WHERE condition]筛选条件,只返回满足条件的行 可选 [ORDER BY ...]排序,按指定列升序( ASC)或降序(DESC)排列可选 [LIMIT count]限制返回的行数 可选
2-1select列
1)全列查询
**通常情况下不建议使用 * 进行全列查询
- 查询的列越多,意味着需要传输的数据量越大;
- 可能会影响到索引的使用。(索引待后面课程讲解)**
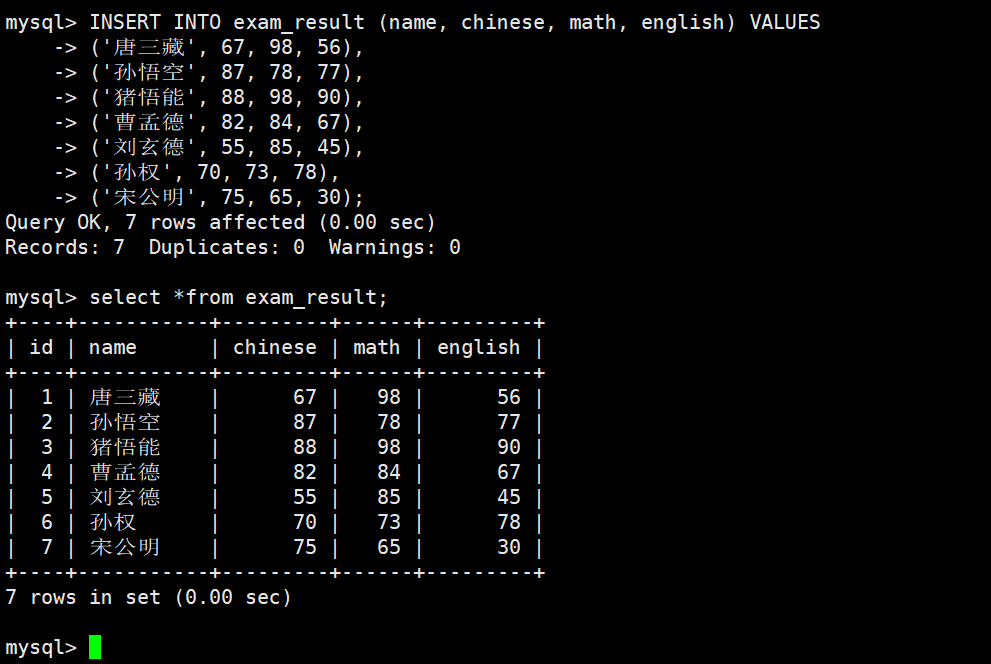
2)指定列查询
指定列的顺序不需要按定义表的顺序来
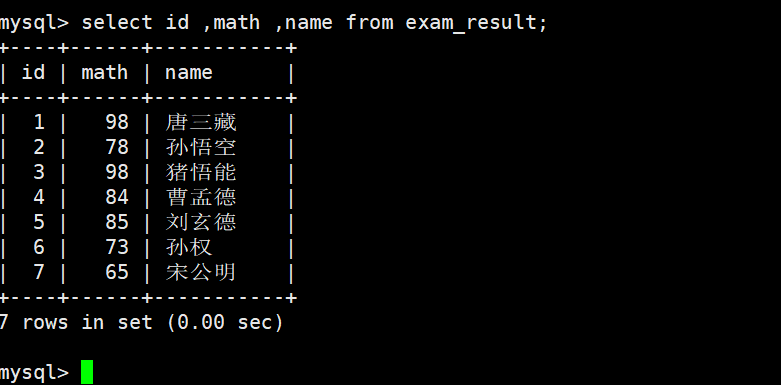
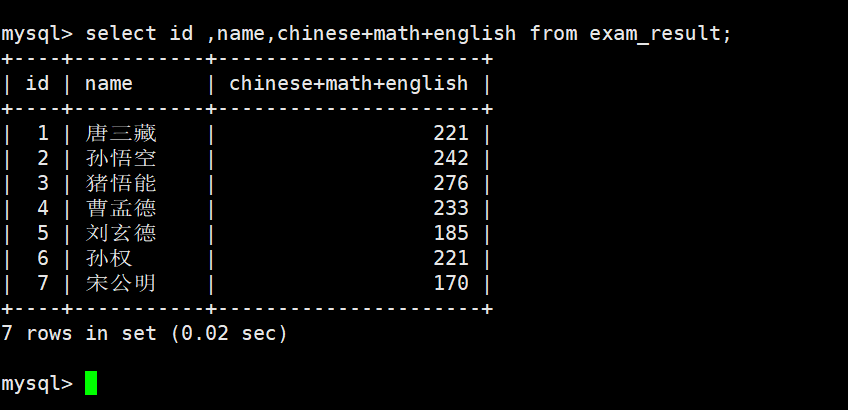
3)查询字段为表达式
表达式不包含字段
- 表达式不包含字段
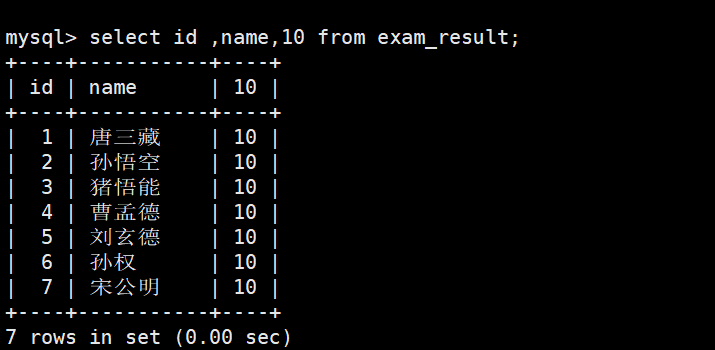
- 表达式包含一个字段
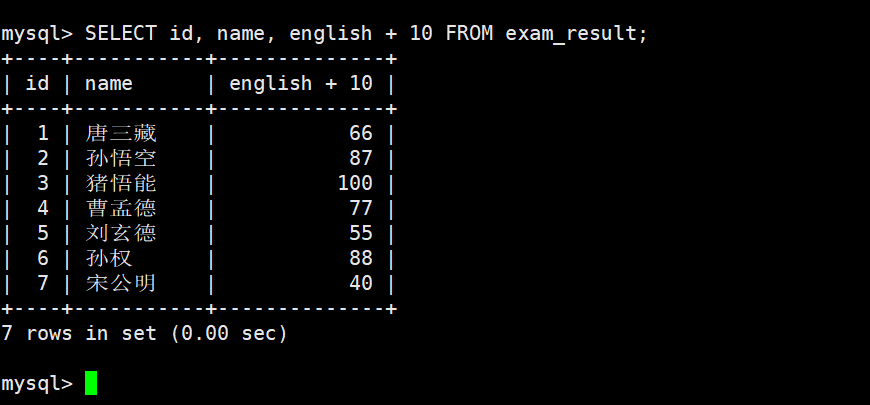
- 表达式包含对个字段
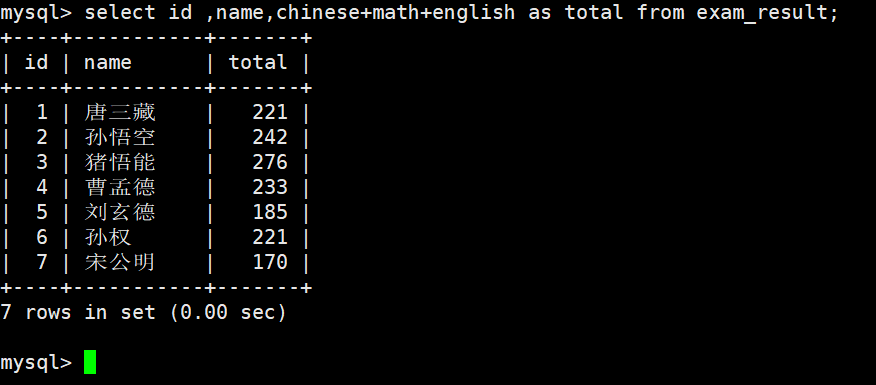
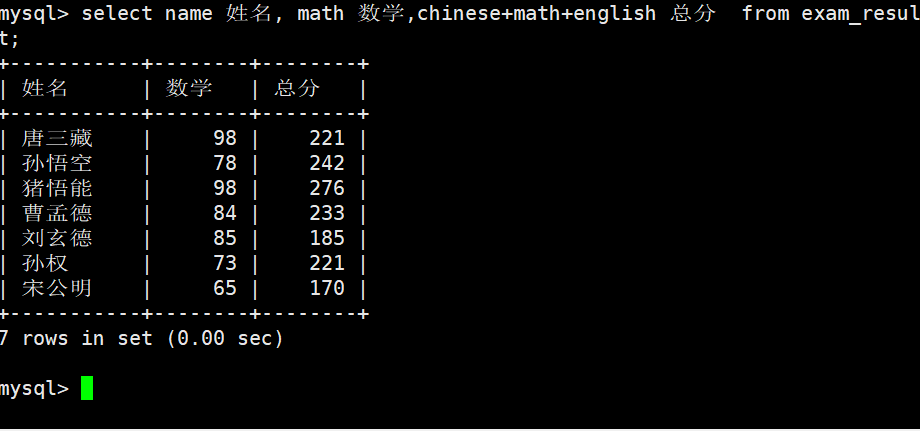
4)为查询结果指定别名
语法:
SELECT column AS alias_name ... FROM table_name;
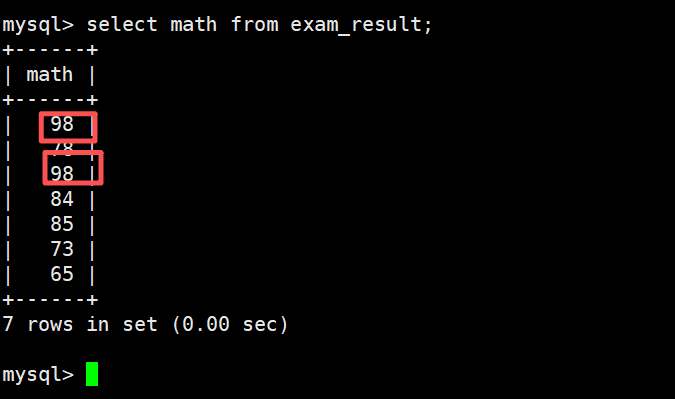
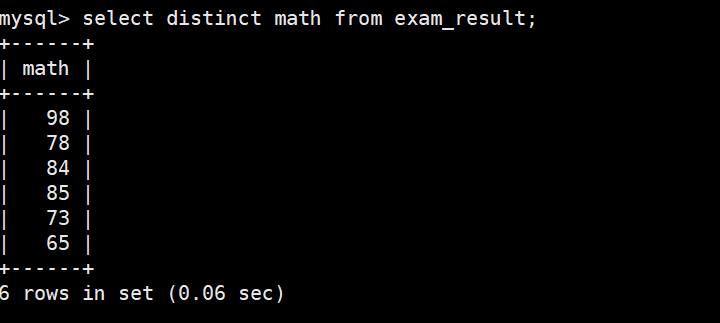
5)结果去重
98 分重复了
2-2WHERE 条件
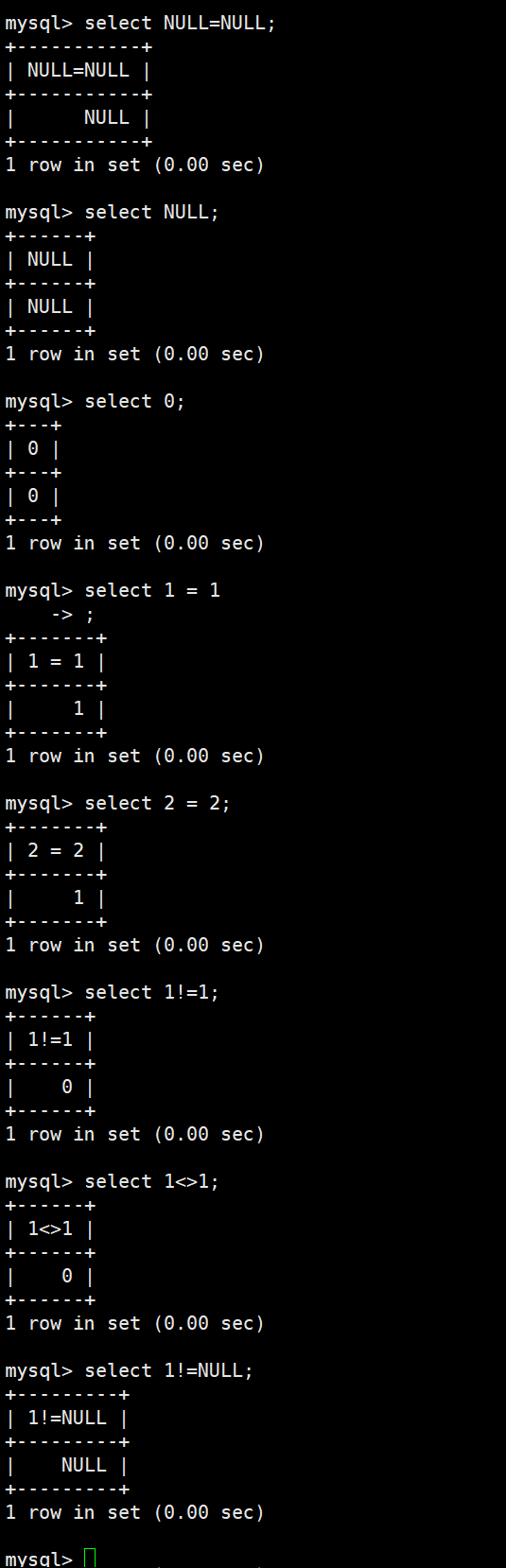
比较运算符:

在 MySQL 中,
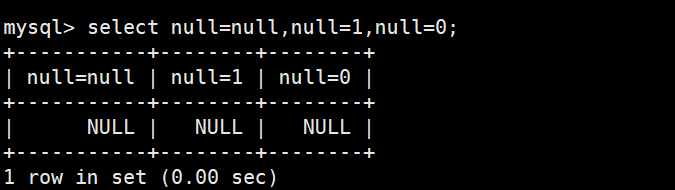
=用于判断两个值是否相等,但不能用来判断NULL,因为NULL = NULL的结果不是TRUE,而是NULL,不会匹配任何行。判断NULL必须使用IS NULL或IS NOT NULL。此外,NULL表示"未知值",与数字0或空字符串''完全不同,不要混用。
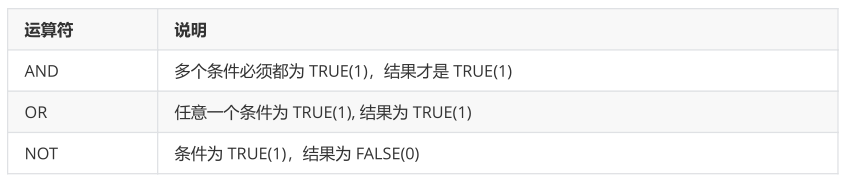
逻辑运算符:
练习
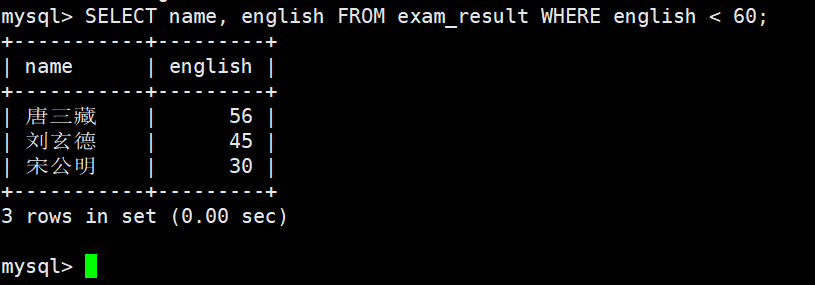
英语不及格的同学及英语成绩 ( < 60 )
基本比较
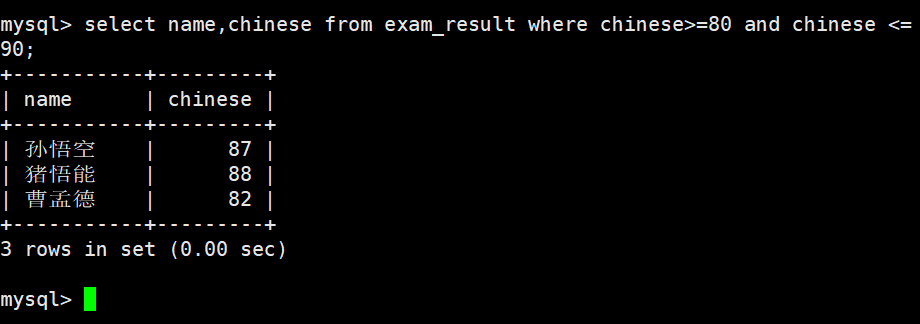
语文成绩在 80, 90 分的同学及语文成绩
使用 AND 进行条件连接
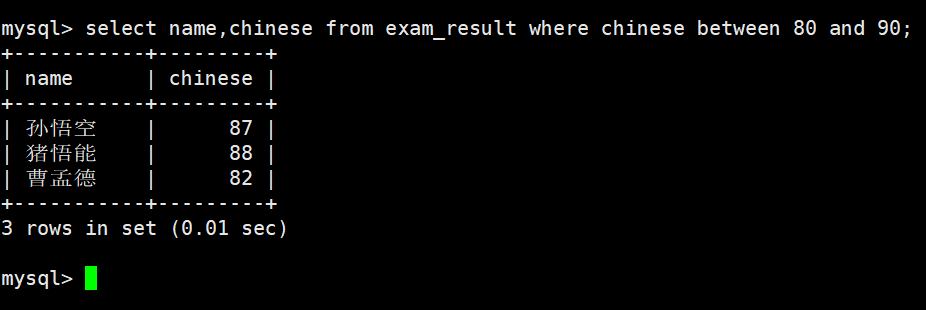
使用 BETWEEN ... AND ... 条件
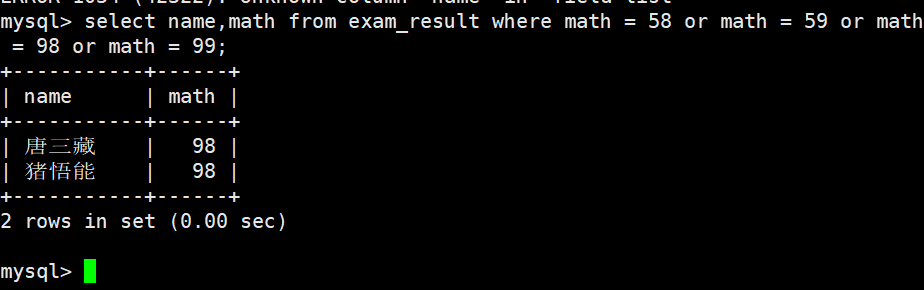
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
使用 OR 进行条件连接
使用 IN 条件
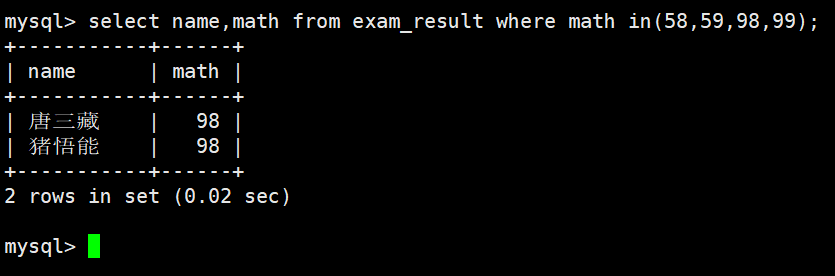
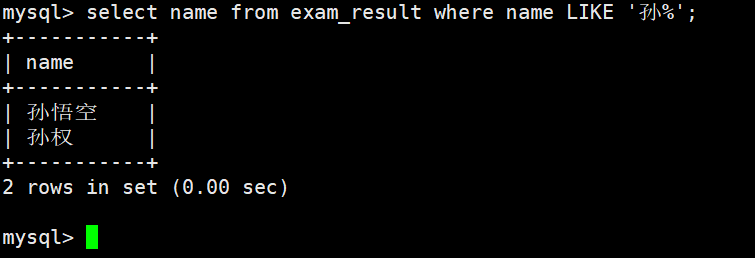
姓孙的同学 及 孙某同学
% 匹配任意多个(包括 0 个)任意字符
_ 匹配严格的一个任意字符
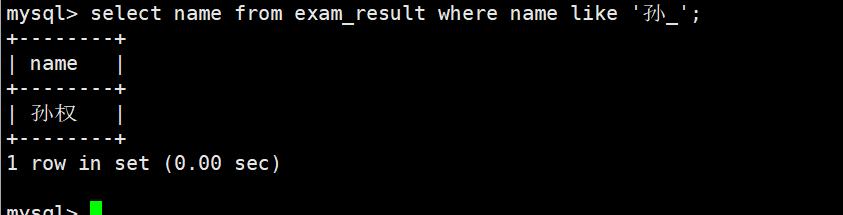
语文成绩好于英语成绩的同学
WHERE 条件中比较运算符两侧都是字段
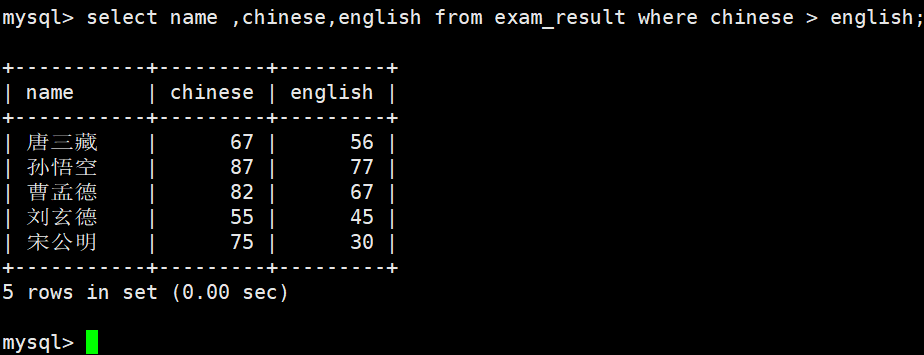
总分在 200 分以下的同学
WHERE 条件中使用表达式
别名不能用在 WHERE 条件中
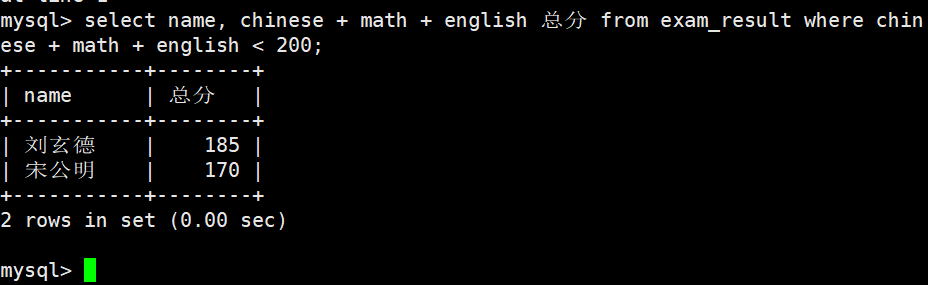
语文成绩 > 80 并且不姓孙的同学
AND 与 NOT 的使用
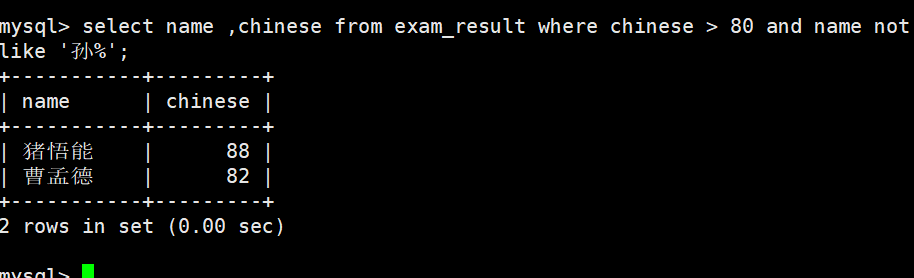 孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
综合性查询
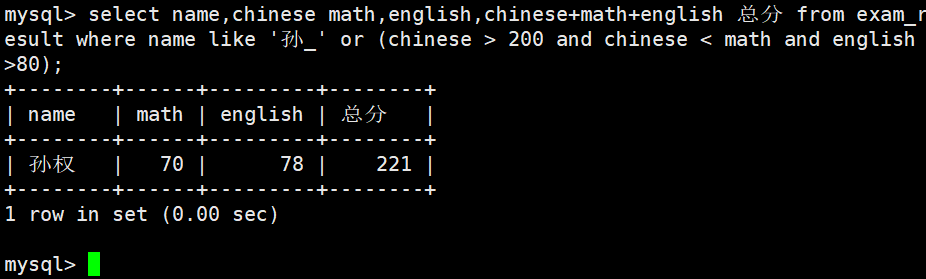
NULL 的查询
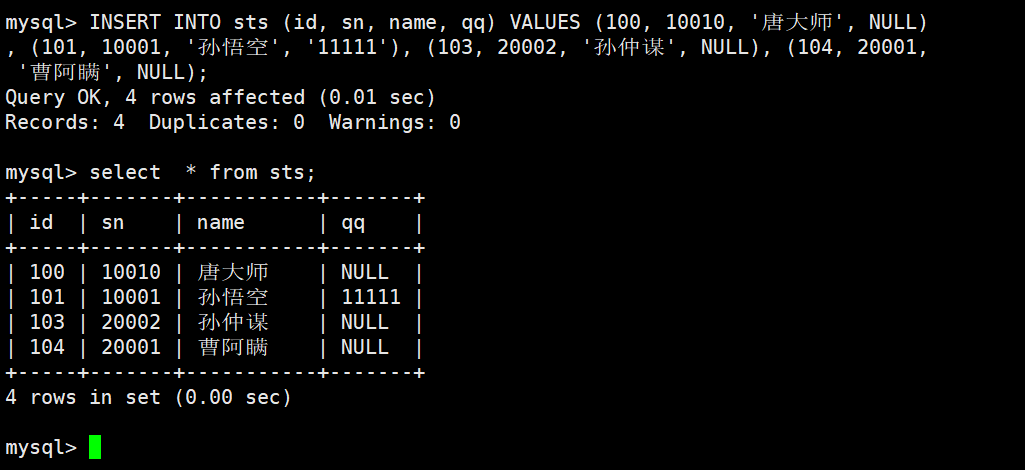
查询 qq 号已知的同学姓名
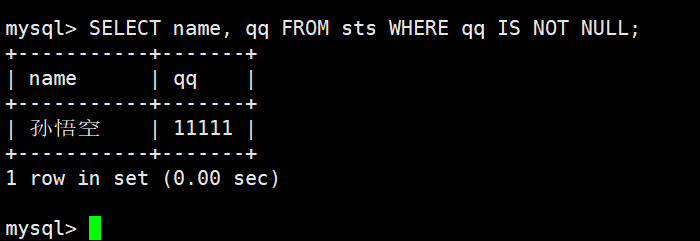
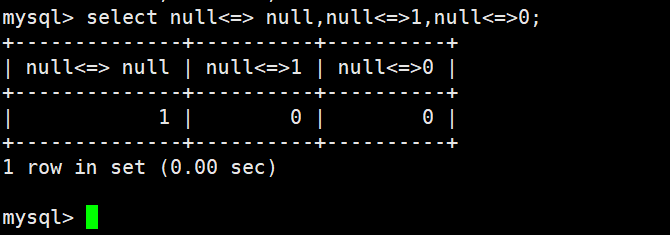
NULL 和 NULL 的比较,= 和 <=> 的区别
三.结果排序
练习:
语法:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASCSELECT ... FROM table_name WHERE ...
ORDER BY column ASC\|DESC, ...;
**注意:**没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
同学及数学成绩,按数学成绩升序显示
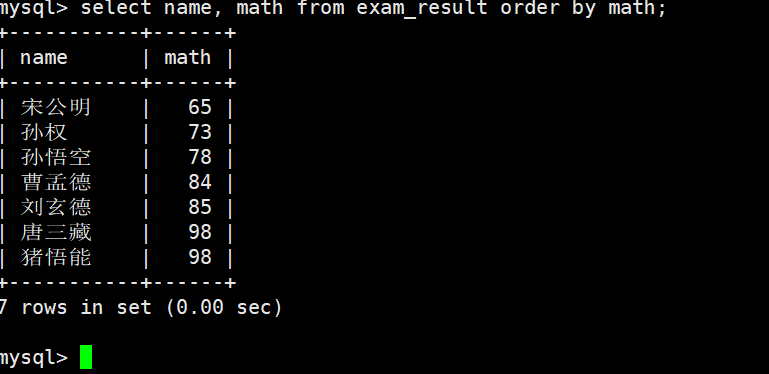
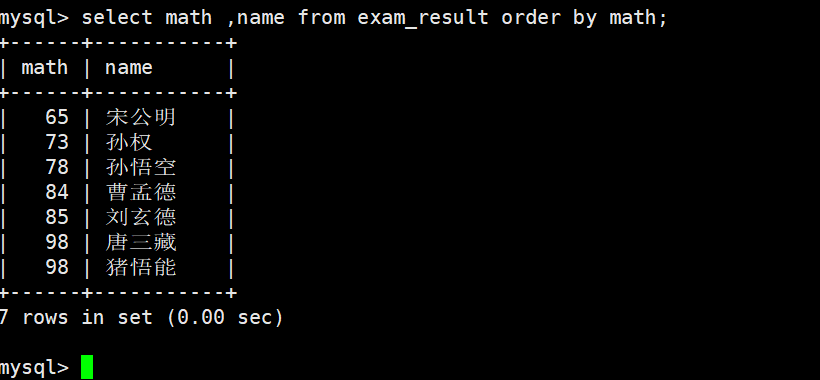
我验证了颠倒一下啥感觉
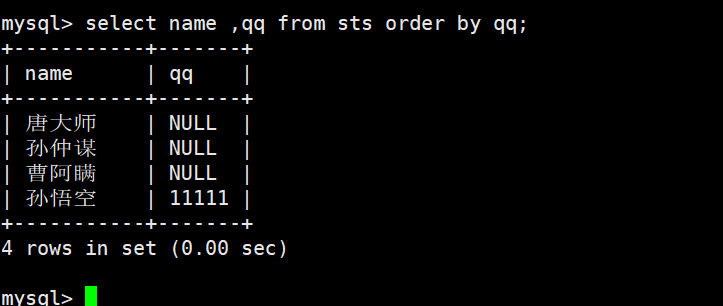
同学及 qq 号,按 qq 号排序显示
NULL 视为比任何值都小,升序出现在最上面
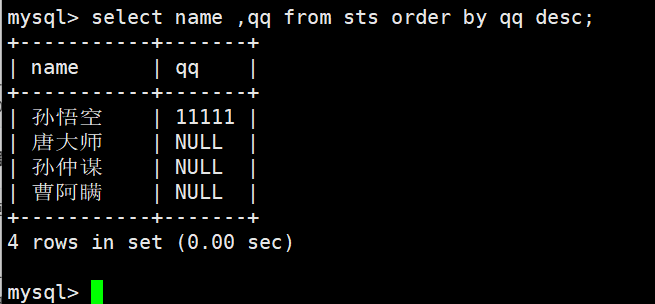
NULL 视为比任何值都小,降序出现在最下面
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
多字段排序,排序优先级随书写顺序
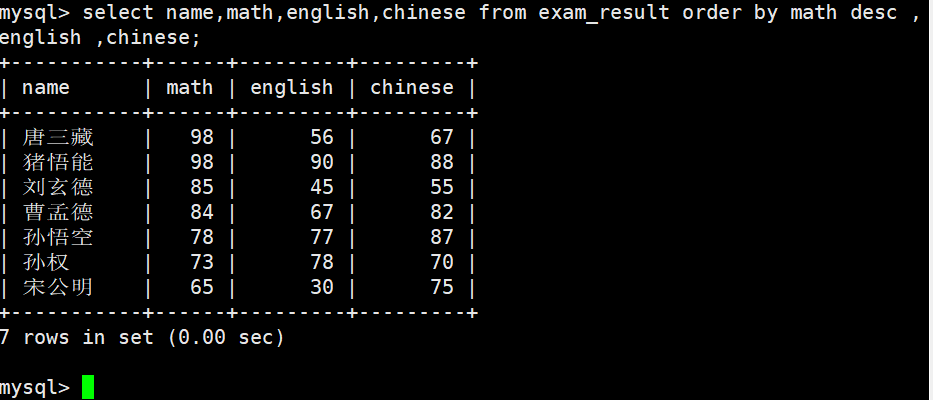
查询同学及总分,由高到低
ORDER BY 中可以使用表达式
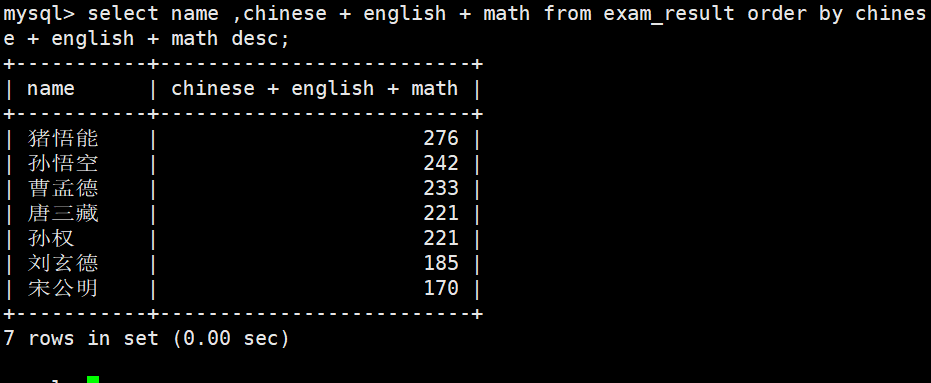
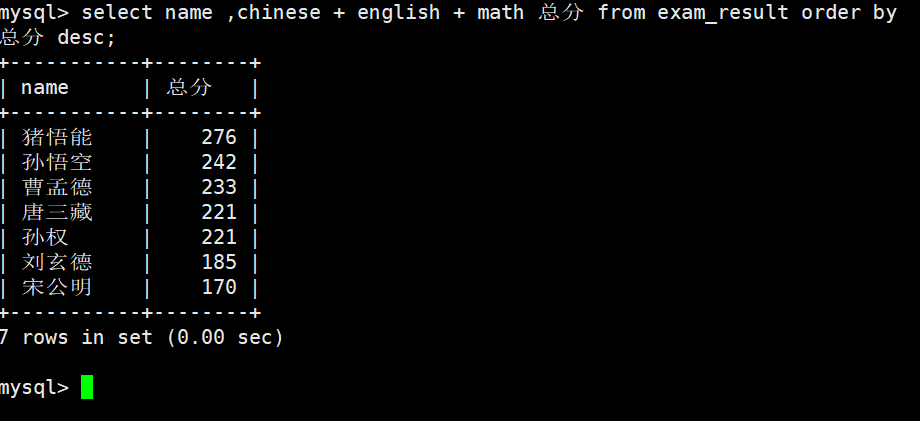
ORDER BY 子句中可以使用列别名
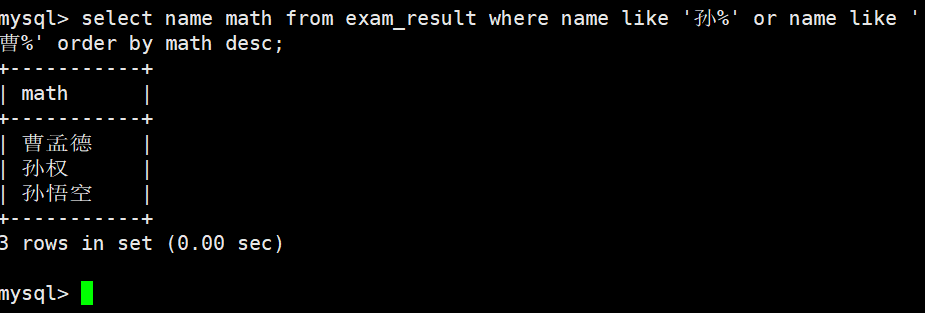
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
结合 WHERE 子句 和 ORDER BY 子句
 筛选分页结果
筛选分页结果
语法:
- 起始下标为 0
- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name WHERE ... ORDER BY ... LIMIT s, n;
- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name WHERE ... ORDER BY ... LIMIT n;
- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name WHERE ... ORDER BY ... LIMIT n OFFSET s;
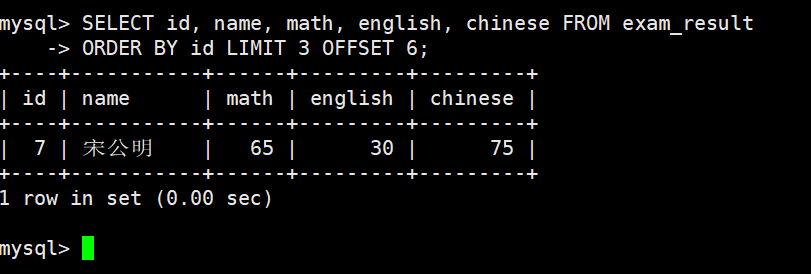
- 建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死 按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页
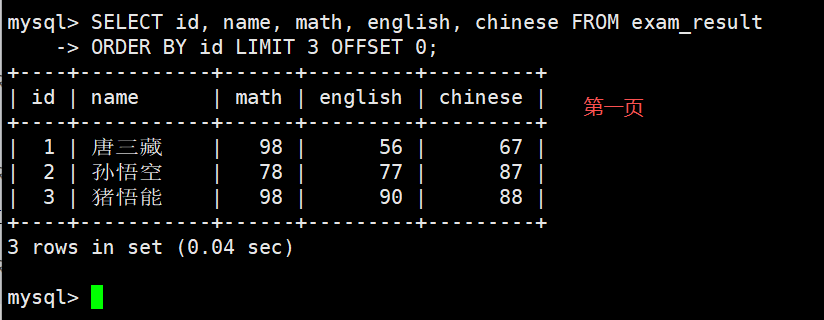
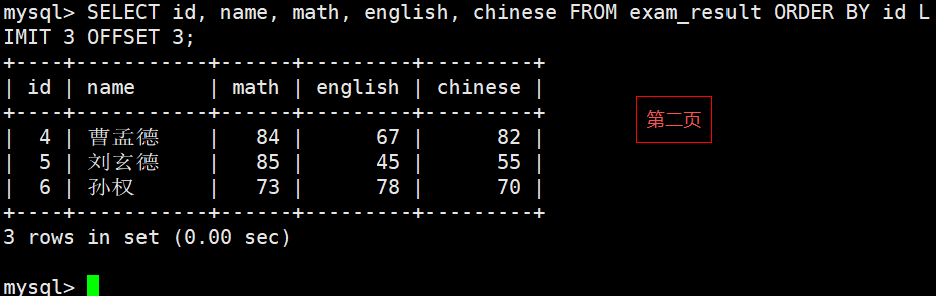
第 3 页,如果结果不足 3 个,不会有影响
LIMIT的本质功能是 控制结果显示的数量与起始位置 ,而不是条件筛选。它的执行顺序非常靠后:必须先有数据(经过
WHERE筛选、JOIN关联、ORDER BY排序等完整的数据准备阶段) ,最后才由LIMIT决定"从第几行开始显示、显示多少行"。也就是说,
LIMIT不参与"哪些数据要被拿出来"的判断,只参与"拿出来的数据怎么展示"的最终控制。因此,
LIMIT不能理解为"条件过滤",而应理解为 结果集的截取与分页展示工具。
四.Update
语法:
UPDATE table_name SET column = expr , column = expr ...
WHERE ...\] \[ORDER BY ...\] \[LIMIT ...
对查询到的结果进行列值更新
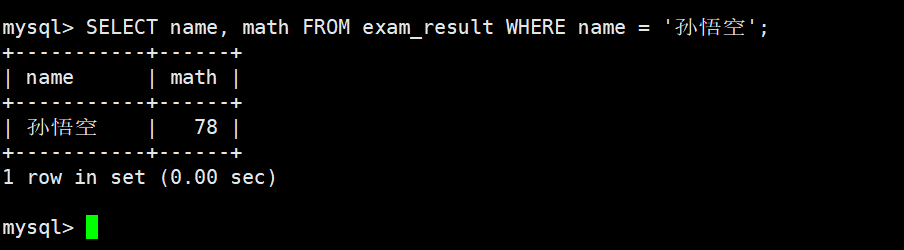
将孙悟空同学的数学成绩变更为 80 分
更新值为具体值,查看原数据
数据更新,查看更新后数据
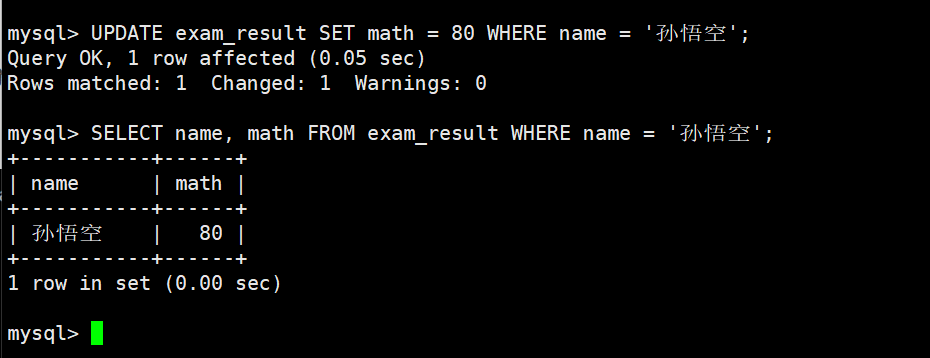
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
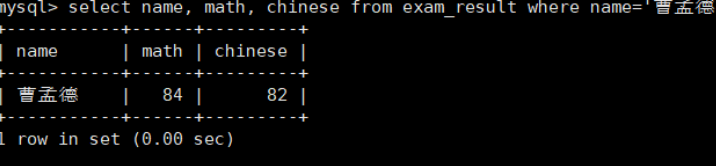
一次更新多个列

查看更新后数据

将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
更新值为原值基础上变更
查看原数据
别名可以在ORDER BY中使用
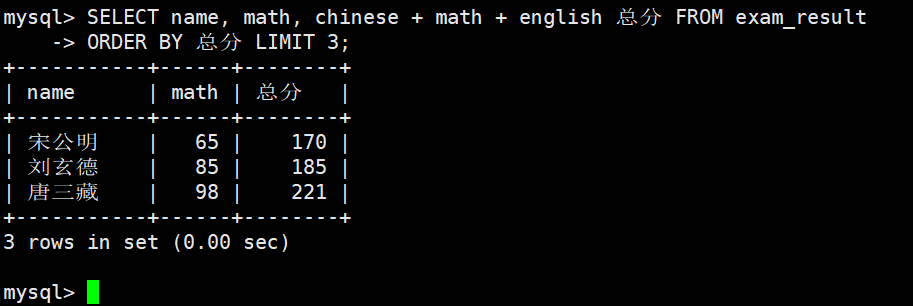
数据更新,不支持 math += 30 这种语法(更新后)

查看更新后数据
思考:这里还可以按总分升序排序取前 3 个么?
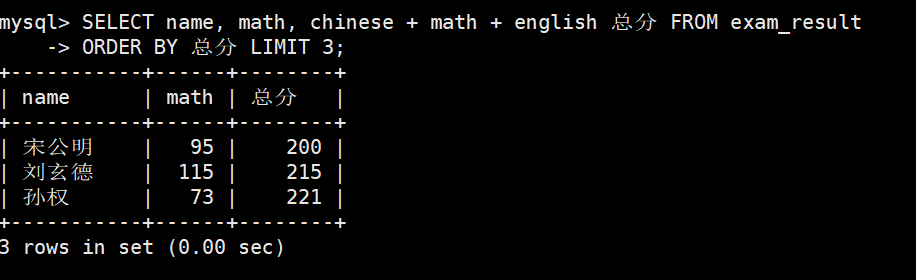
按总成绩排序后查询结果
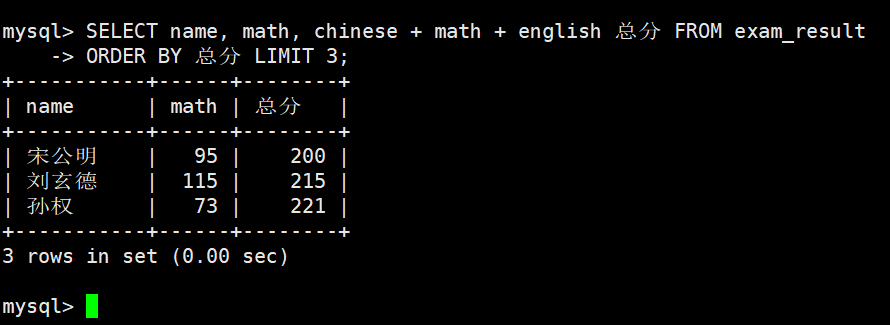
将所有同学的语文成绩更新为原来的 2 倍
注意:更新全表的语句慎用!(没有 WHERE 子句,则更新全表)
查看原数据
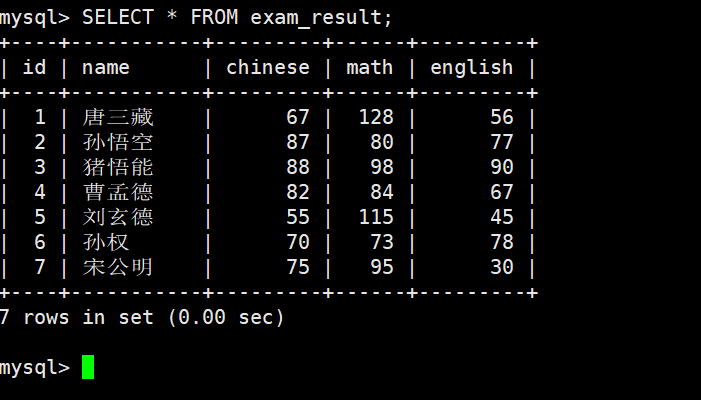
数据更新,查看更新后数据

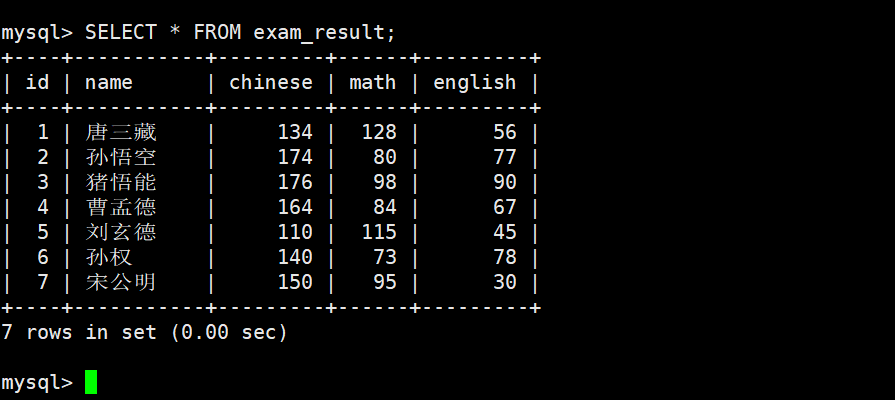
五. 删除数据
删除数据
语法:
DELETE FROM table_name WHERE ... ORDER BY ... LIMIT ...
删除孙悟空同学的考试成绩
查看原数据
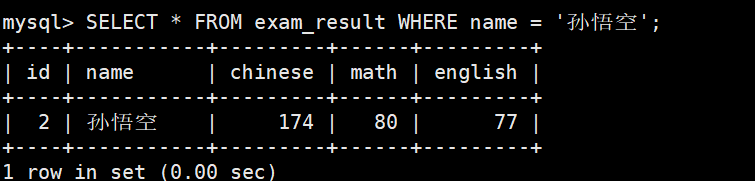
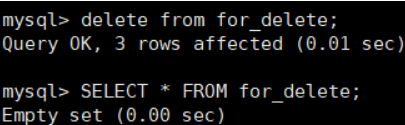
删除数据

查看删除结果

删除整张表数据
注意:删除整表操作要慎用!
准备测试表
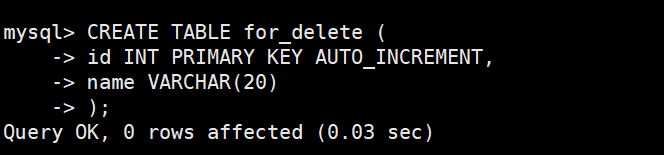
插入测试数据

查看测试数据
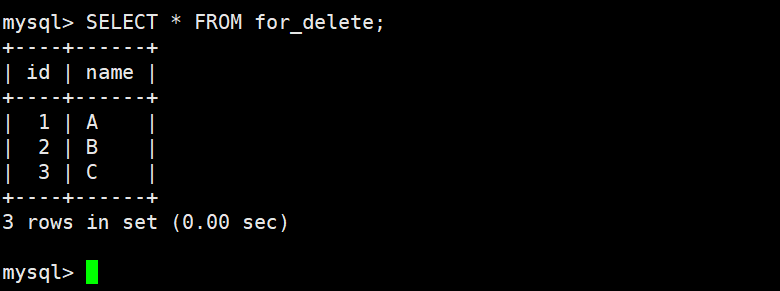
删除整表数据

查看删除结果

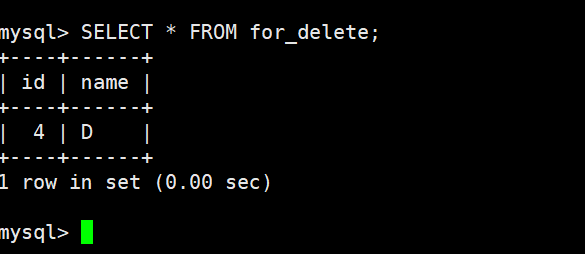
再插入一条数据,自增 id 在原值上增长

查看数据
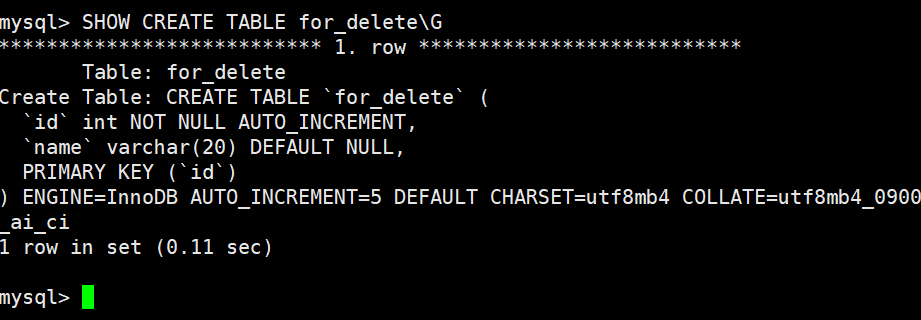
查看表结构,会有 AUTO_INCREMENT=n 项
截断表
语法:
TRUNCATE TABLE table_name
截断整表数据,影响行数是 0,所以实际上没有对数据真正操作
注意:这个操作慎用
只能对整表操作,不能像 DELETE 一样针对部分数据操作;
实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事
物,所以无法回滚
- 会重置 AUTO_INCREMENT 项
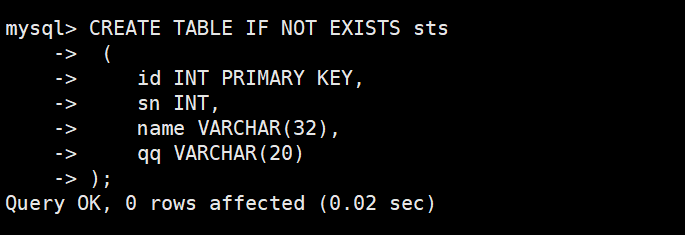
准备测试表

插入测试数据

查看测试数据
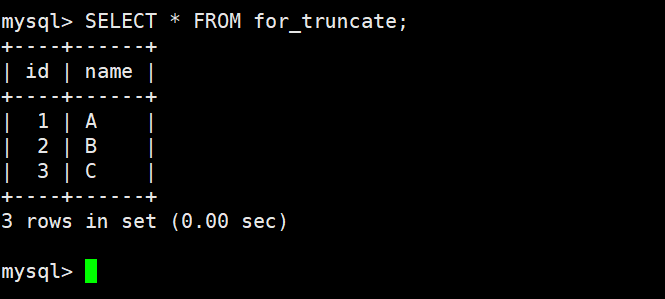
截断整表数据,注意影响行数是 0,所以实际上没有对数据真正操作

查看删除结果
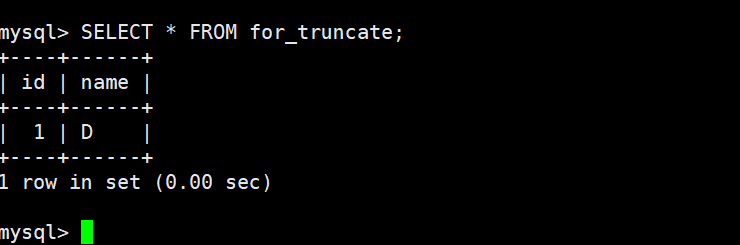
再插入一条数据,自增 id 在重新增长

查看数据
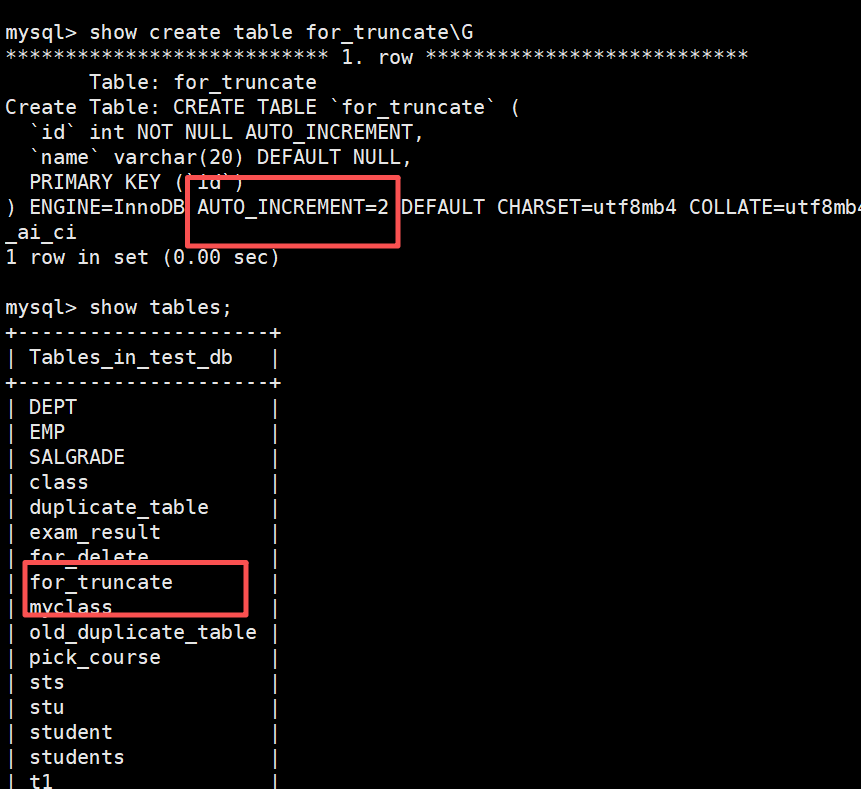
查看表结构,会有 AUTO_INCREMENT=2 项
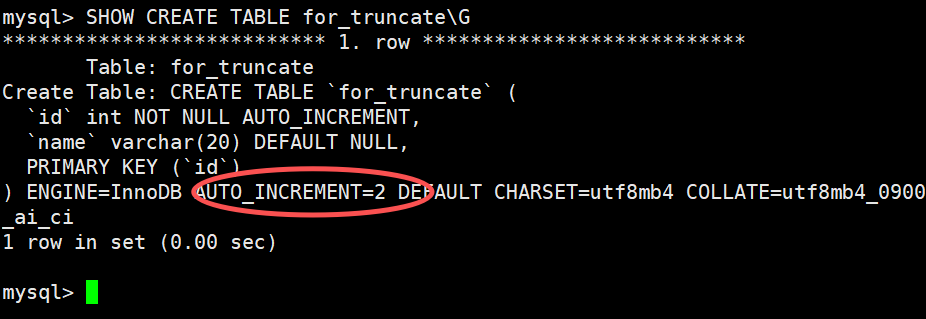
这张表叫
for_truncate,有一个自增主键id,下一个自增值是 2。使用
utf8mb4字符集,不区分大小写和重音的排序规则,存储引擎是 InnoDB。
AUTO_INCREMENT=2
表示下一个自增 id 的值是 2
说明表中已经有一条记录(id=1)
或者曾经有过 id=1 的记录(后来被删除,但自增不会回退)
DELETE和TRUNCATE的区别两者都可以清空表中的数据,但行为上有本质区别。
对自增计数器的影响:
DELETE FROM不会重置自增计数器,下次插入时 id 会从之前的值继续递增;而TRUNCATE会重置自增计数器,下次插入时 id 从 1 开始。事务与回滚:
DELETE FROM支持事务,每行删除都在事务中执行,可以通过ROLLBACK回滚恢复数据;TRUNCATE不支持事务,不经过事务处理,一旦执行就无法回滚,数据永久丢失。因此TRUNCATE操作必须慎用。操作粒度:
DELETE FROM可以带WHERE条件,只删除部分数据;TRUNCATE只能整表清空,不能加任何条件。执行效率:
DELETE FROM是逐行删除,并记录每行的日志,所以速度较慢;TRUNCATE本质上是直接释放数据页,不逐行操作,也不记录每行的日志,所以速度远快于DELETE。
六.插入查询结果
语法:
INSERT INTO table_name (column \[, column ...)] SELECT ...
删除表中的的重复复记录,重复的数据只能有一份
创建原数据表

插入测试数据
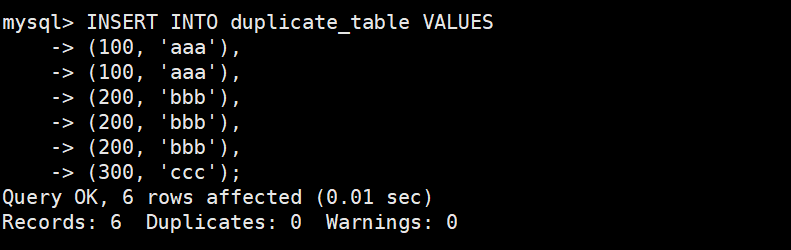
错误思路:直接用distinct
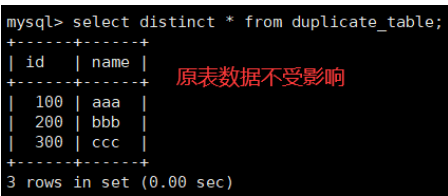
正确思路
创建一张空表 no_duplicate_table,结构和 duplicate_table 一样
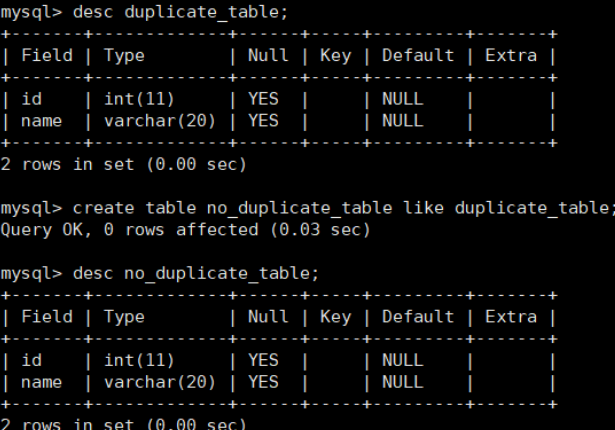
将 duplicate_table 的去重数据插入到 no_duplicate_table
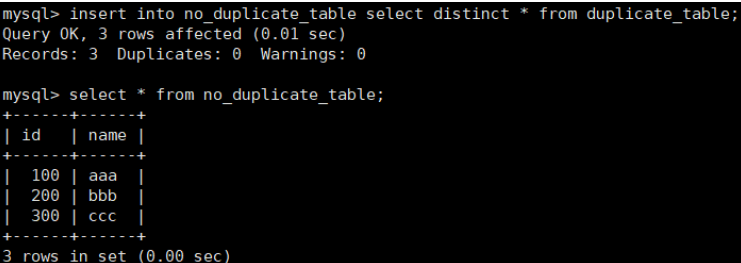
通过重命名表,实现原子的去重操作
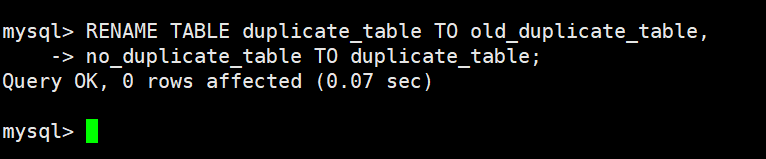
查看最终结果
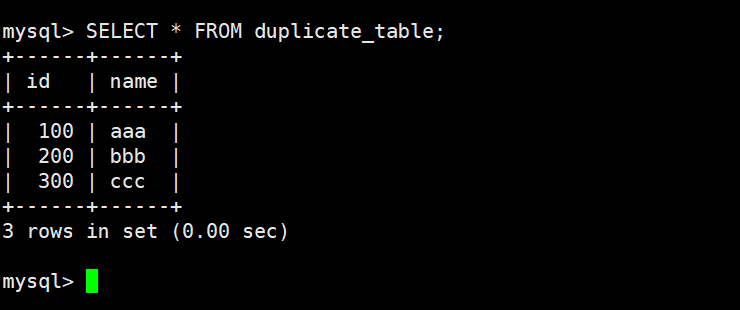
为什么最后是通过 rename 方式进行的?
具体过程是:
先创建一个临时表(或新表)。
在临时表中完成所有的数据清洗、去重、合并等操作(这个过程可能很慢,但它不影响线上业务)。
确认临时表中的数据已经准备就绪、完全正确后,再通过一条
RENAME TABLE语句,原子地将原表替换成新表
RENAME TABLE的本质是:把"复杂的数据准备过程"和"最终生效"分开。准备阶段在幕后偷偷做,最后通过一条原子指令瞬间切换,做到业务无感知、操作可回滚。
一.当前在 bash 看到了文件
说明你已经在 MySQL 的数据目录里,比如:
cd /var/lib/mysql/test_db/
ls -l但去重操作不能在 bash 里做,必须回到 MySQL 命令行。
二、回到 MySQL 命令行
mysql -u root -p输入密码,然后进入对应数据库:
USE test_db; 三、查看当前有哪些表
SHOW TABLES;应该能看到:
duplicate_table(原表,有重复数据)
no_duplicate_table(临时空表,你已经创建好了)
四、向临时表插入去重数据
sql
INSERT INTO no_duplicate_table
SELECT * FROM duplicate_table
GROUP BY name;这里假设按
name去重。如果你想按其他字段,把name换成你的字段名。
五、原子替换表名
sql
RENAME TABLE duplicate_table TO duplicate_table_old,
no_duplicate_table TO duplicate_table;这一步执行完:
新表
duplicate_table上线(无重复数据)原表被备份为
duplicate_table_old
六、验证结果
sql
SELECT * FROM duplicate_table;确认数据正确后,删除备份表:
sql
DROP TABLE duplicate_table_old七. 聚合函数
练习:
统计班级共有多少同学
使用 * 做统计,不受 NULL 影响
使用表达式做统计
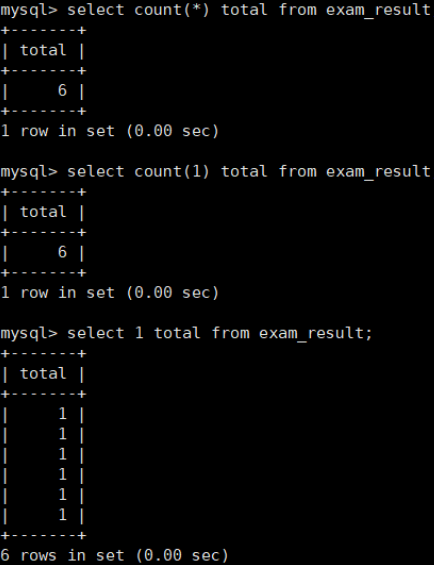
统计本次考试的数学成绩分数个数
COUNT(math) 统计的是全部成绩
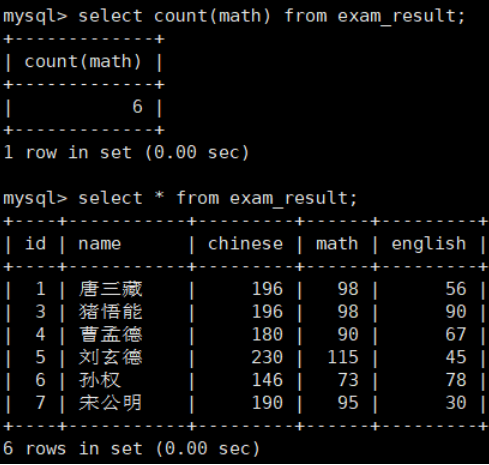
COUNT(DISTINCT math) 统计的是去重成绩数量
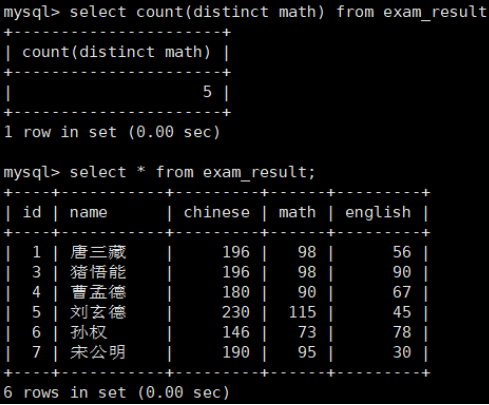
distinct 在括号内,因为是要对 math 去重,而不是对 count() 的结果去重。
NULL 不会计入结果。
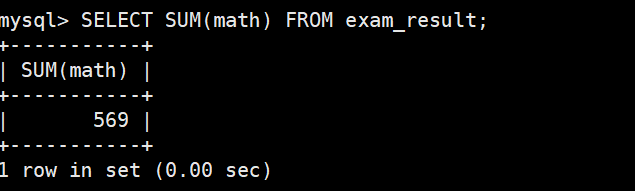
统计数学成绩总分
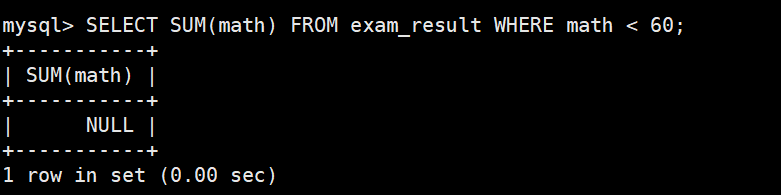
不及格 < 60 的总分,没有结果,返回 NULL,有直接返回成绩
统计数学平均成绩
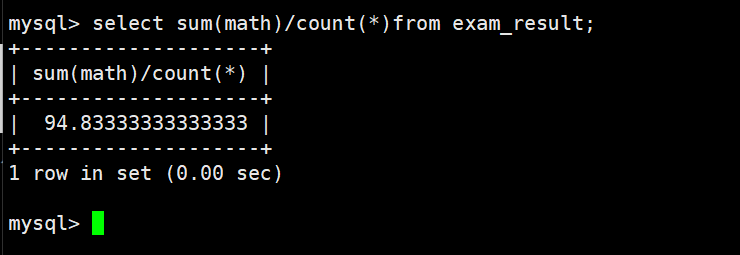
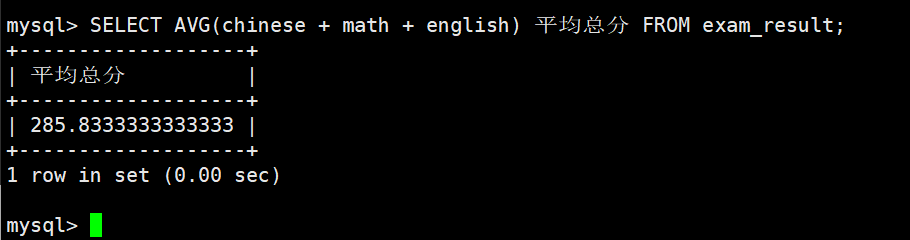
统计平均总分
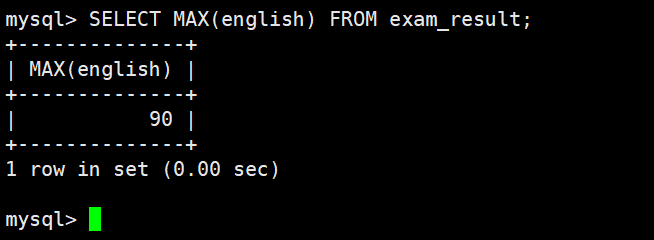
返回英语最高分
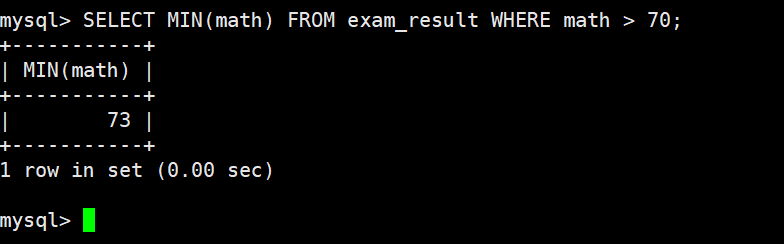
返回 > 70 分以上的数学最低分
8.group by子句的使用
在select中使用group by 子句可以对指定列进行分组查询
select column1, column2, .. from table group by column;
目的:为了进行分组 后,方便进行聚合统计。
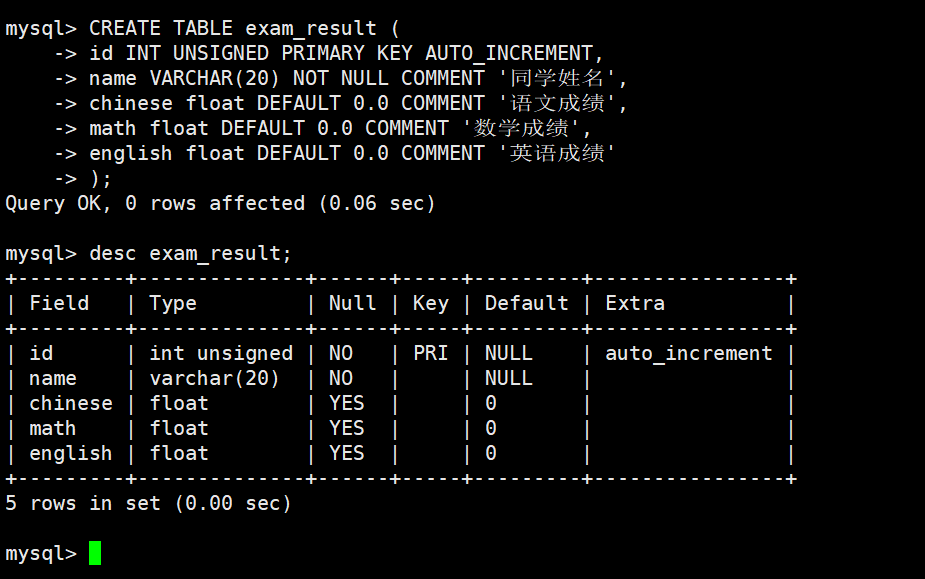
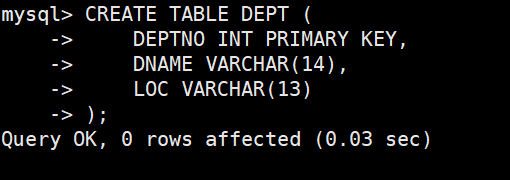
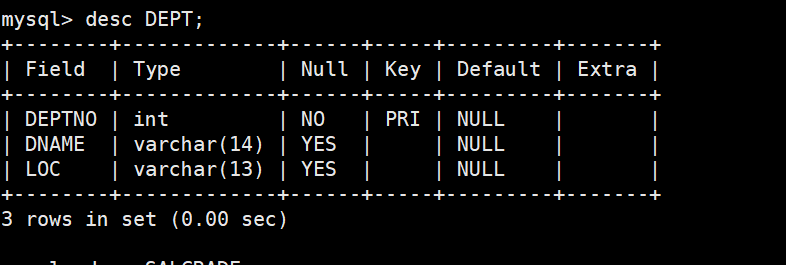
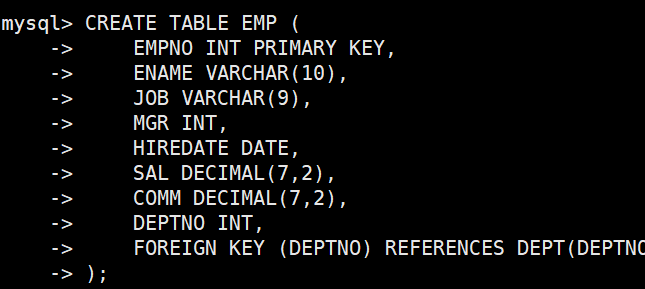
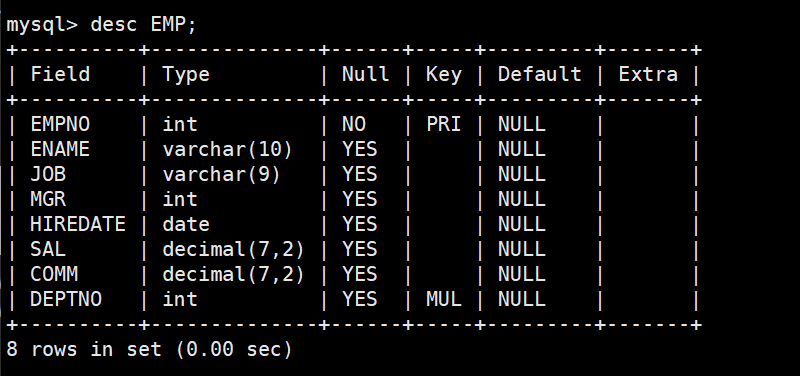
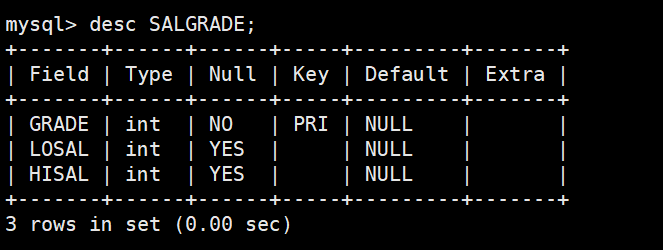
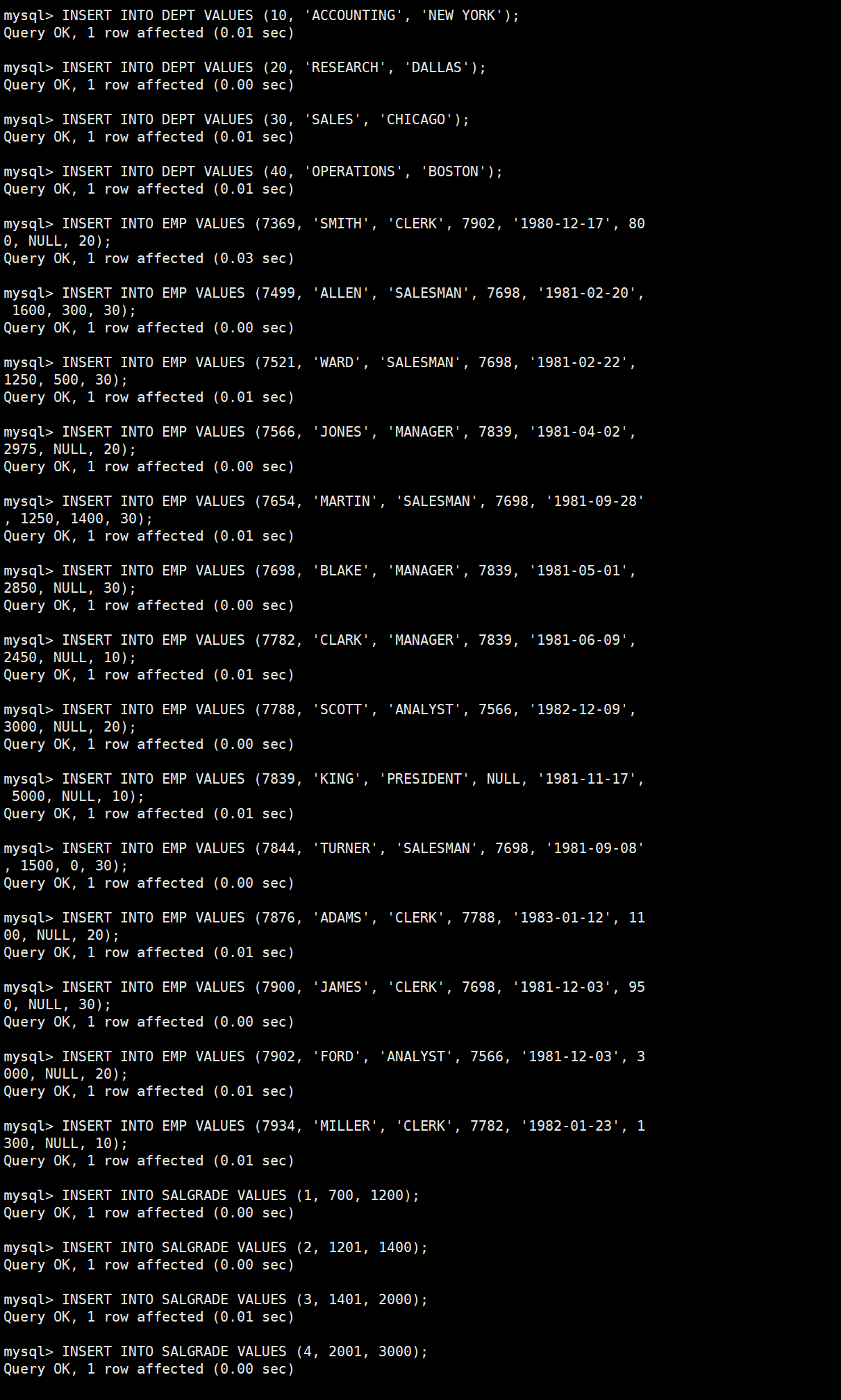
准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
EMP员工表
DEPT部门表
SALGRADE工资等级表
1. DEPT(部门表)
2. EMP(员工表)
3. SALGRADE(工资等级表)
数据插入
1.如何显示每个部门的平均工资和最高工资
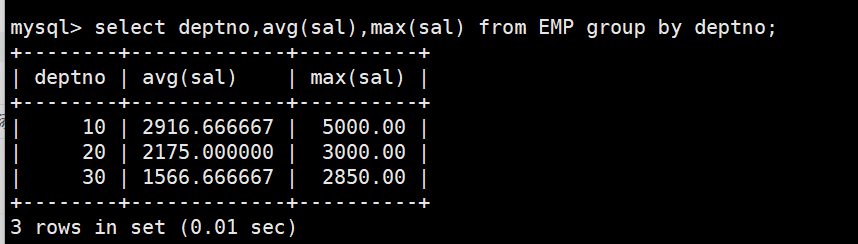
2.如何显示每个部门的平均工资和最高工资
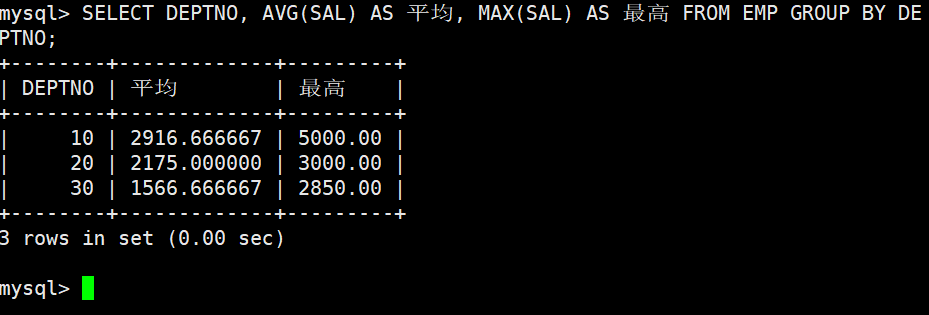
分组(GROUP BY)的本质
GROUP BY指定列名后,实际分组是以该列中不同取值的行来划分的。分组后,同一组内的该列值一定是相同的,这意味着该列可以被"聚合压缩"------即多个行在分组后合并为一个组,组内的其他列需要通过聚合函数(如
SUM、AVG、MAX、MIN、COUNT)来处理。理解分组的一种方式: 分组就是把一张表按照指定的条件,在逻辑上拆分成多个子表,每个子表对应一个组。然后针对每个子表单独进行聚合统计。
例如:按部门编号分组,就是把员工表拆成"10号部门子表"、"20号部门子表"、"30号部门子表"等,然后分别统计每个子表的平均工资、最高工资等。
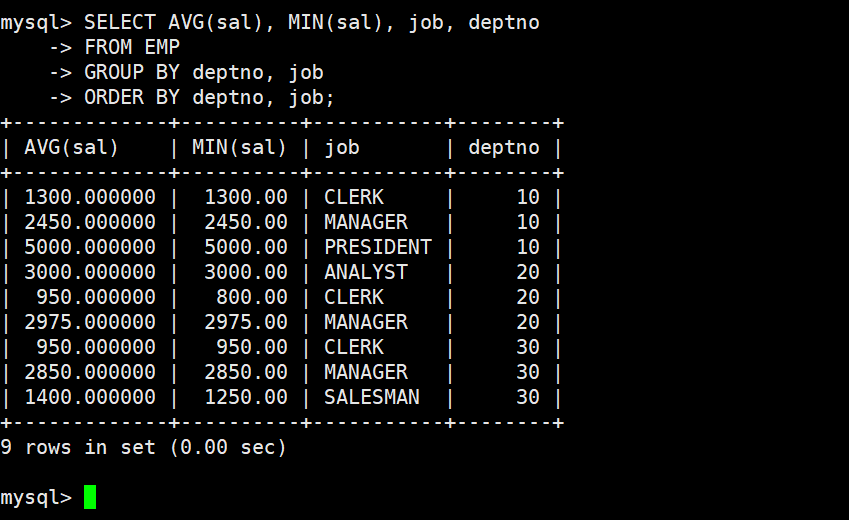
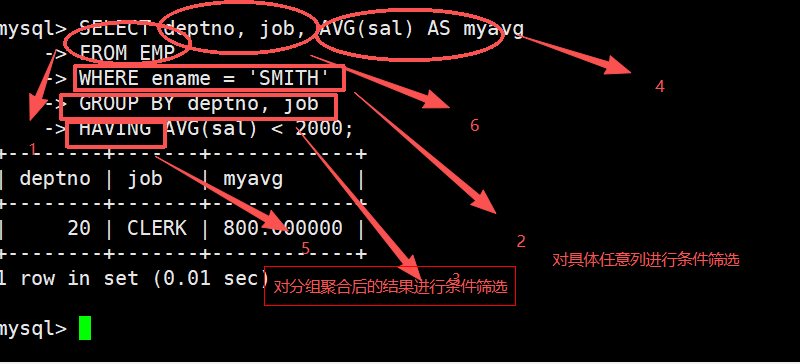
3.显示每个部门的每种岗位的平均工资和最低工资
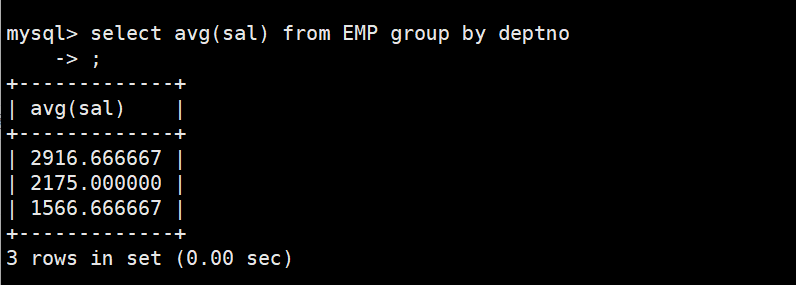
4.显示平均工资低于2000的部门和它的平均工资
统计各个部门的平均工资
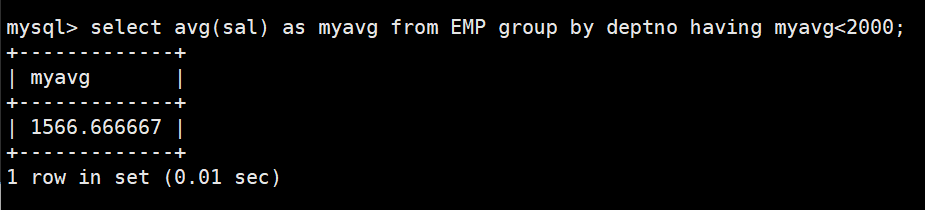
having和group by配合使用,对group by结果进行过滤(having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where)
5.having VS where 的区别与执行顺序是什么的。
都能够做条件筛选,这是它们的共性。
但它们是完全不同的条件筛选,它们的条件筛选的阶段是不同的。
WHERE是在分组之前对原始行进行筛选,筛完再分组;HAVING是在分组之后对聚合结果进行筛选。所以WHERE里不能用AVG、SUM这类聚合函数,但HAVING里可以。执行顺序是:FROM→WHERE→GROUP BY→HAVING。能用WHERE提前筛掉数据,就尽量别等分组后靠HAVING再筛,这样效率更高。
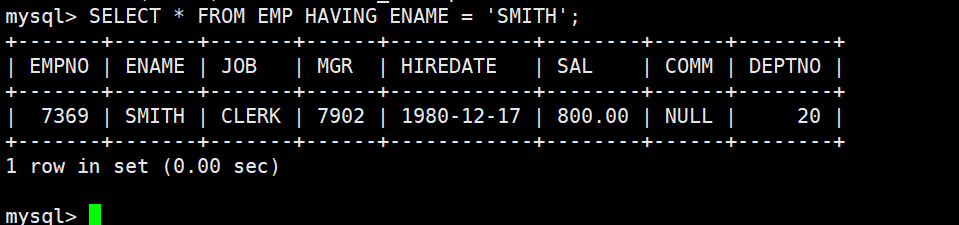
理解 MySQL 中的"表"
不要单纯地认为,只有在磁盘上将表结构导入到 MySQL、真实存在的表才叫表。
在 MySQL 中,一切查询结果都是逻辑上的表。
中间筛选出来的结果集,是表
最终输出的结果,也是表
子查询返回的结果,还是表
甚至一个聚合统计后的输出,同样是表
只要你能够处理好单张表的增删改查(CURD),所有的 SQL 场景都可以用统一的方式去理解和操作。
因为无论是多表查询、子查询、分组统计还是聚合计算,本质上都是在"逻辑表"上做操作------只是这个表可能是临时的、筛选过的、聚合后的,但它依然遵循单表操作的基本规则。
【细节补充】
SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select> distinct > order by > limit