AWS Data Sharing (数据共享):Redshift 原生功能,允许跨集群、跨账户以只读方式访问数据,数据不会被物理复制,消费方直接查询提供方的存储。
Zero-ETL :AWS 托管的实时同步管道,将 Aurora、DynamoDB、RDS 等 OLTP 数据库的变更自动持续同步到 Redshift,消除手写 ETL 代码。
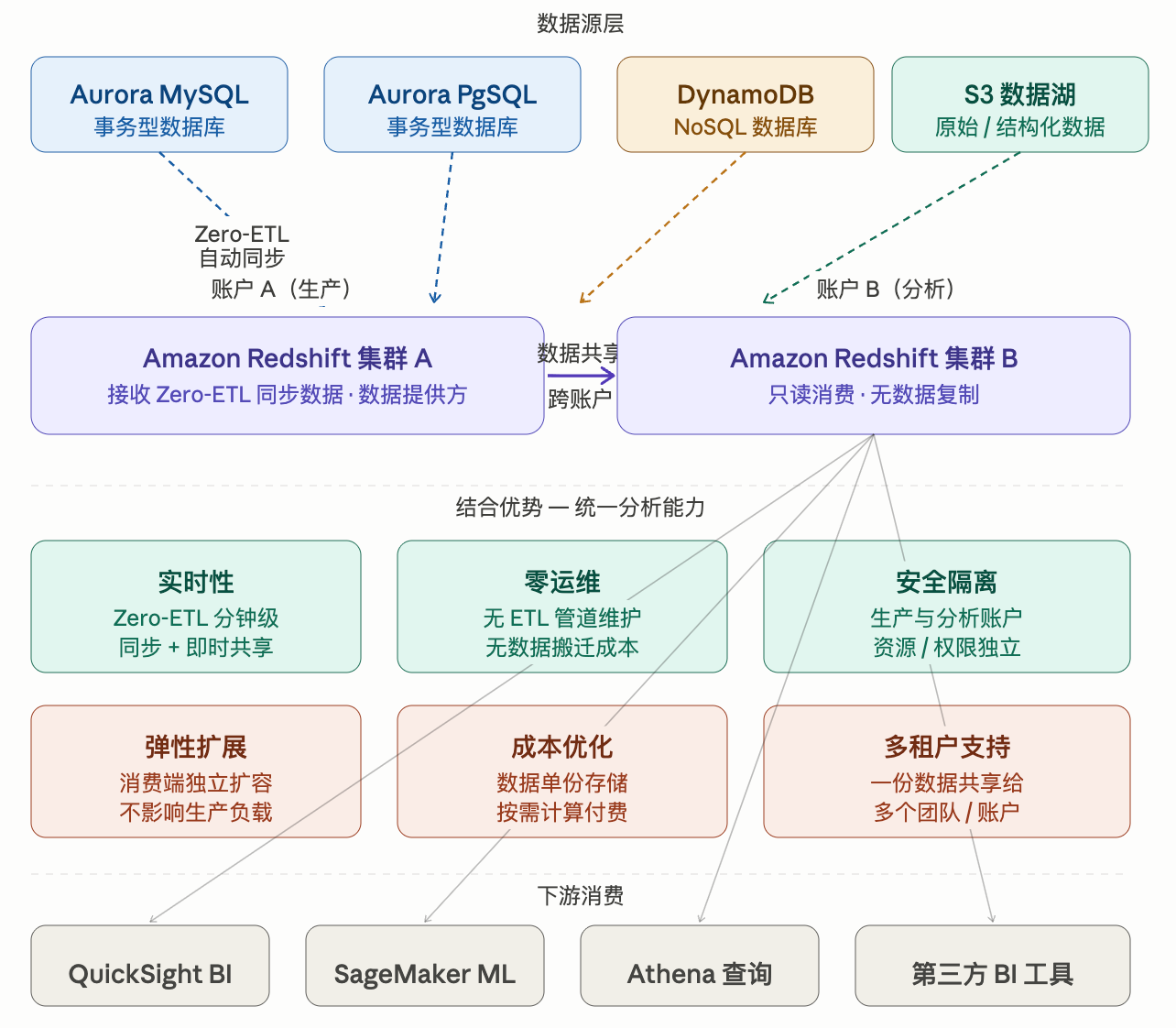
结合的核心优势
- 端到端实时分析,无管道维护
Zero-ETL 负责将事务数据分钟级同步进 Redshift,Data Sharing 负责将这份数据即时暴露给分析团队,整个链路不需要写一行 ETL 代码或 Glue Job。 - 生产与分析彻底隔离
事务数据库 → Redshift A(生产账户)→ Redshift B(分析账户)。分析团队的重查询完全打在消费集群上,不会抢占生产 compute,两侧可独立扩缩容。 - 数据单份存储,多方消费
Data Sharing 的核心是"数据不动,算力动",配合 Zero-ETL 同步来的单份数据,可同时给 BI 团队、ML 团队、多个业务部门只读访问,节省存储成本。 - 权限精细管控
可以在数据共享粒度上控制哪些 schema / table 可见,消费账户无法修改数据,满足数据治理和合规要求。 - 成本控制
使用Redshift Serverless时,计费粒度是分钟,也就是说一分钟内只要用了1秒1RPU都会算成一分钟满RPU。所以单独建个小集群用来同步数据,然后数据共享到大集群,能省大量成本。
如何使用AWS Zero-ETL不再赘述
详见:使用AWS Zero-ETL 实时同步MySQL库表到Redshift
需注意将数据同步到小集群,接下来使用数据共享到大集群
详见:在AWS Redshift 中使用数据共享 Data sharing
Zero-ETL 新增表需重新赋权
bash
ALTER DATASHARE share ADD ALL TABLES IN SCHEMA india_fea;
GRANT USAGE ON DATABASE share TO user;
GRANT USAGE ON SCHEMA share.india_fea TO user;
GRANT SELECT ON all tables in SCHEMA share.india_fea to user;Zero-ETL 若有表同步失败,可手动同步
bash
ALTER DATABASE feat INTEGRATION REFRESH TABLE xx;
ALTER DATABASE feat INTEGRATION REFRESH TABLES a, b;