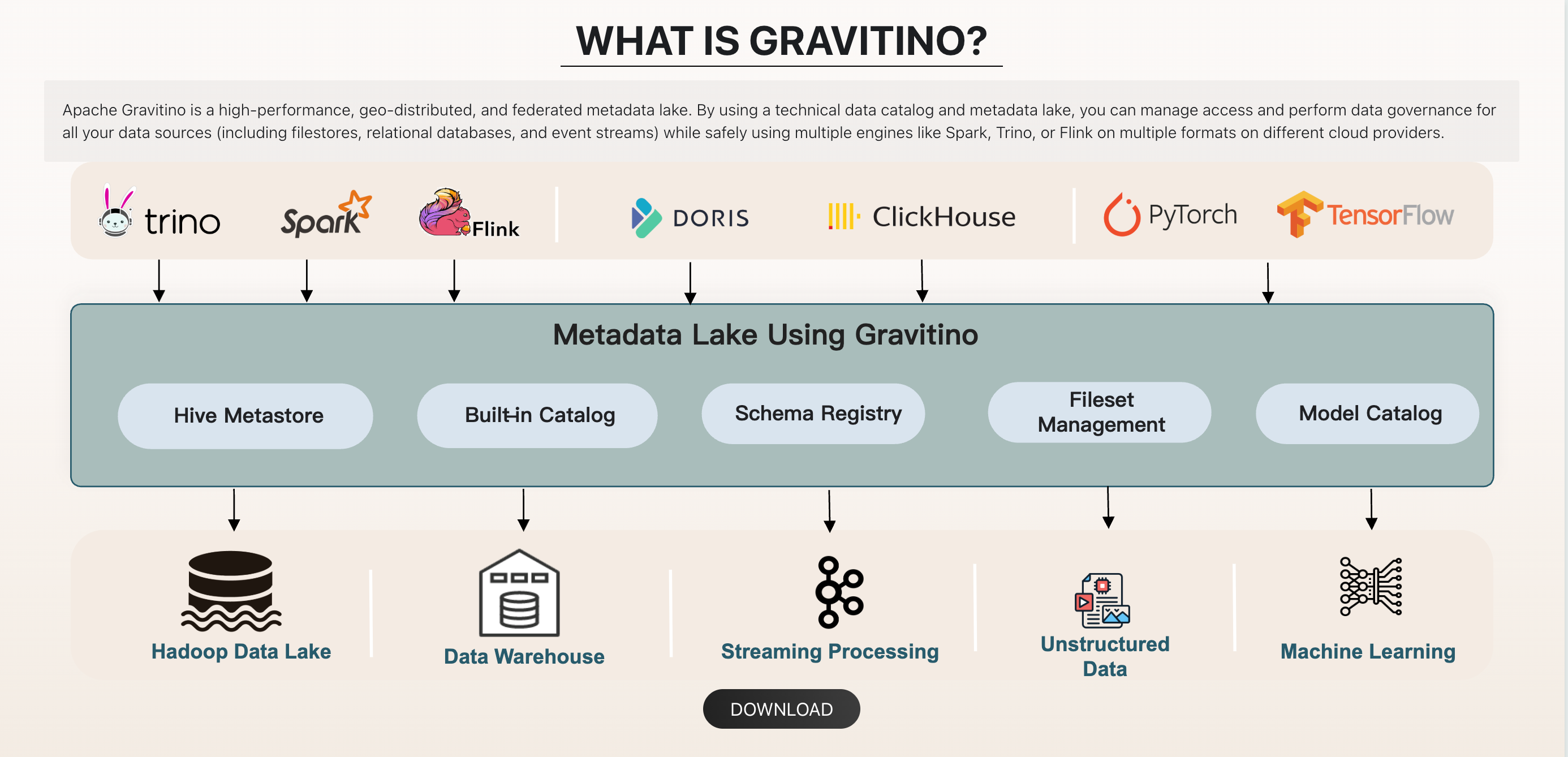
一、现有数据治理平台能力盘点
1.1 元数据管理模块
现状:
| 维度 | 当前能力 | 成熟度 |
|---|---|---|
| 元数据采集 | 支持Hive/MySQL/PostgreSQL等主流数据源的元数据定时采集 | ★★★☆ |
| 元数据存储 | 自建元数据存储,以关系型数据库为主 | ★★★☆ |
| 元数据检索 | 支持基础的关键词检索和分类浏览 | ★★☆☆ |
| 元数据变更感知 | 依赖定时采集,变更延迟较大(分钟~小时级) | ★★☆☆ |
| 元数据模型 | 各数据源元数据模型不一致,需适配层转换 | ★★☆☆ |
痛点:
- 被动采集模式:现有系统采用定时拉取元数据的方式,无法实时感知底层变更,元数据时效性差
- 多源异构适配成本高:每接入一种新数据源,需开发对应的采集适配器,扩展性差
- 元数据模型不统一:不同数据源的元数据结构差异大,上层应用需要处理多种格式,增加开发复杂度
- 缺乏主动管理能力:现有系统只能"看到"元数据,无法通过统一入口"管理"元数据(如统一DDL操作)
- AI资产元数据缺失:模型、特征等AI资产尚无元数据管理能力
1.2 数据目录模块
现状:
| 维度 | 当前能力 | 成熟度 |
|---|---|---|
| 目录浏览 | 支持按数据源/数据库/表层级浏览 | ★★★☆ |
| 标签管理 | 支持基础标签体系,可对表/字段打标 | ★★☆☆ |
| 目录搜索 | 关键词搜索,缺少语义化搜索能力 | ★★☆☆ |
| 目录分类 | 支持业务域/主题域分类 | ★★★☆ |
| 资产详情页 | 展示表结构、字段说明、基础统计信息 | ★★★☆ |
痛点:
- 多数据源体验割裂:用户需在不同数据源之间切换,缺乏统一的目录浏览体验
- 目录信息与底层不同步:标签、描述等目录信息存于本地,与底层数据源无关联
- 缺乏统一的数据发现机制:用户难以跨数据源发现相关数据,影响数据复用
- 分类标签体系单薄:缺乏策略化的标签管理,无法支持数据分级分类等治理需求
1.3 数据血缘模块
现状:
| 维度 | 当前能力 | 成熟度 |
|---|---|---|
| 血缘采集 | 支持Spark任务血缘解析(基于SQL解析) | ★★★☆ |
| 血缘展示 | 表级/字段级血缘可视化 | ★★★☆ |
| 血缘存储 | 自建图数据库存储血缘关系 | ★★★☆ |
| 影响分析 | 支持上游变更的下游影响分析 | ★★☆☆ |
| 溯源分析 | 支持数据的来源溯源 | ★★☆☆ |
痛点:
- 引擎覆盖不全:仅覆盖Spark任务血缘,Flink/Trino等引擎的血缘尚未支持
- 血缘准确性依赖SQL解析:基于SQL静态解析的方案对复杂逻辑(动态SQL、存储过程等)覆盖率不足
- 跨平台血缘断裂:不同引擎之间的数据流转血缘难以串联
- 血缘时效性差:血缘更新依赖任务完成后解析,无法实时反映数据流变化
1.4 数据质量模块
现状:
| 维度 | 当前能力 | 成熟度 |
|---|---|---|
| 质量规则 | 支持完整性/准确性/一致性/及时性等规则模板 | ★★★☆ |
| 质量监控 | 配置化质量检测任务,定时执行 | ★★★☆ |
| 质量告警 | 支持多渠道告警通知 | ★★★☆ |
| 质量报告 | 质量评分、趋势分析 | ★★☆☆ |
| 质量工单 | 问题发现-分派-处理-验证闭环 | ★★☆☆ |
痛点:
- 质量规则与元数据脱节:质量规则绑定在本地目录对象上,与底层数据源的表/字段变更感知延迟
- 缺乏跨源质量对比:同一逻辑数据在不同数据源中的质量难以对比分析
- 质量规则复用性差:相似的表/字段需要重复配置质量规则
1.5 数据安全模块
现状:
| 维度 | 当前能力 | 成熟度 |
|---|---|---|
| 数据分级 | 支持数据敏感级别标注 | ★★☆☆ |
| 访问控制 | 基于角色的访问控制(RBAC),在应用层实现 | ★★★☆ |
| 审计日志 | 记录数据访问操作日志 | ★★★☆ |
| 脱敏规则 | 支持基础的数据脱敏能力 | ★★☆☆ |
| 权限管理 | 各数据源独立管理权限,缺乏统一授权 | ★★☆☆ |
痛点:
- 多源权限管理割裂:每个数据源独立管理权限,管理员需要在多个系统中配置,效率低且易遗漏
- 权限变更无法同步:在平台层配置的权限无法自动下推到各数据源,实际数据访问控制仍依赖各系统原生的权限体系
- 缺乏统一的审计视图:不同数据源的审计日志格式各异,难以形成统一的安全审计视图
- 数据分级与权限未联动:敏感级别标注后,无法自动触发对应的权限策略
1.6 数据资产模块
现状:
| 维度 | 当前能力 | 成熟度 |
|---|---|---|
| 资产编目 | 支持全域数据资产统一编目 | ★★★☆ |
| 资产检索 | 关键词/分类/标签多维检索 | ★★★☆ |
| 资产运营 | 资产热度、使用统计 | ★★☆☆ |
| 资产价值评估 | 基础的价值评分模型 | ★☆☆☆ |
| 资产门户 | 一站式资产发现与申请 | ★★☆☆ |
痛点:
- 资产信息被动汇聚:资产信息依赖采集,与底层数据源的真实状态可能存在偏差
- 资产运营缺乏深度:热度分析较粗粒度,缺乏跨源的数据使用分析
- 资产价值评估模型简单:无法准确量化数据资产的实际业务价值
二、能力差距识别:对比Gravitino核心能力
2.1 核心差距矩阵
| 能力维度 | 现有平台 | Gravitino | 差距评估 |
|---|---|---|---|
| 元数据管理模式 | 被动采集,定时同步 | 直接管理,实时同步 | 🔴 重大差距 |
| 多数据源统一视图 | 各源独立,体验割裂 | Metalake统一命名空间 | 🔴 重大差距 |
| 元数据操作 | 只读浏览为主 | 统一CRUD,DDL透传到底层 | 🔴 重大差距 |
| 数据源覆盖 | Hive/MySQL/PG等5~8种 | Hive/Iceberg/Paimon/Hudi/MySQL/PG/ClickHouse/Doris/StarRocks/Kafka等15+种 | 🟡 中等差距 |
| 权限统一管理 | 各源独立权限体系 | RBAC+DAC统一授权,支持授权下推 | 🔴 重大差距 |
| 引擎联邦访问 | 无统一联邦入口 | Spark/Trino/Flink统一访问 | 🔴 重大差距 |
| 数据血缘 | 仅Spark SQL解析 | OpenLineage标准+Spark列级血缘 | 🟡 中等差距 |
| 标签与策略 | 基础标签 | 标签+策略,权限控制 | 🟡 中等差距 |
| AI资产管理 | 无 | Model元数据+版本管理+Lance REST | 🔴 重大差距 |
| 数据质量 | 完整的质量规则体系 | 无内置数据质量能力 | 🟢 现有平台优势 |
| 质量规则模板 | 丰富的规则模板库 | 无 | 🟢 现有平台优势 |
| 质量监控与告警 | 配置化监控+告警闭环 | 无 | 🟢 现有平台优势 |
| 资产运营分析 | 热度/价值/生命周期分析 | 基础标签,无运营分析 | 🟢 现有平台优势 |
| 资产门户 | 一站式发现与申请 | Web UI(管理导向,非业务门户) | 🟢 现有平台优势 |
2.2 差距分析总结
重大差距(需重点突破):
-
元数据管理模式差异:现有平台"被动采集"vs Gravitino"直接管理",这是最根本的架构差异。Gravitino通过连接器直接连接底层系统,变更实时双向同步,而现有平台只能做到定期采集,时效性和一致性都无法保证。
-
多数据源统一体验缺失:Gravitino提供Metalake/Catalog/Schema/Table四级命名空间,用户可在一个入口统一浏览和操作所有数据源。现有平台各源独立,用户体验割裂。
-
统一权限管控缺失:Gravitino提供跨数据源的RBAC+DAC统一授权,并支持授权下推(到Ranger等系统)。现有平台各源独立管理权限,无法实现统一的权限策略。
-
引擎联邦访问缺失:Gravitino通过Spark/Trino/Flink连接器,让计算引擎通过Gravitino统一访问所有数据源。现有平台缺乏这种统一的数据访问入口。
-
AI资产管理空白:Gravitino已提供Model元数据管理、Lance REST服务、MCP Server等AI资产管理能力。现有平台完全没有AI资产管理能力。
中等差距(需持续提升):
-
数据源覆盖范围:Gravitino支持的Catalog类型更多(尤其Lakehouse格式和消息队列),现有平台需要逐步扩展。
-
血缘引擎覆盖:虽然双方都主要覆盖Spark血缘,但Gravitino基于OpenLineage标准有更好的扩展性。
现有平台优势(需保持和深化):
-
数据质量能力:这是现有平台的核心差异化能力,Gravitino完全不具备数据质量管理能力,需要现有平台来补充。
-
资产运营能力:现有平台在资产热度分析、价值评估、生命周期管理等方面比Gravitino更贴近业务需求。
三、结合点初步分析
3.1 Gravitino作为统一元数据层与现有目录的互补/替代关系
分析结论:互补为主,部分替代
| 现有目录能力 | 与Gravitino的关系 | 建议 |
|---|---|---|
| 元数据浏览 | 可被Gravitino替代(统一视图更优) | 中长期替代 |
| 元数据采集 | 可被Gravitino替代(直接管理模式更优) | 中长期替代 |
| 标签管理 | 与Gravitino互补(Gravitino提供底层标签能力,现有系统提供业务级标签) | 互补整合 |
| 分类体系 | 与Gravitino互补(业务分类保留在现有系统) | 互补整合 |
| 资产搜索 | 现有系统语义化搜索 + Gravitino元数据 | 互补整合 |
| 资产门户 | 保留现有门户,底层接入Gravitino元数据 | 互补整合 |
关键判断:
- 替代部分:元数据采集和浏览功能可逐步由Gravitino承担,因为Gravitino的"直接管理"模式从根本上解决了时效性和一致性问题
- 互补部分:业务化的标签体系、分类管理、语义搜索、资产门户等功能是现有平台的价值所在,应保留并与Gravitino元数据层整合
- 演进路径:先让Gravitino作为元数据基础设施,现有目录的上层功能通过Gravitino API获取元数据,逐步替代自建采集层
3.2 Gravitino统一Catalog对多数据源管理的价值
核心价值:
-
单一入口管理所有数据源
- 目前:管理员需要在Hive Metastore、MySQL权限、PG权限等多个系统分别操作
- 引入后:通过Gravitino统一Catalog管理,一次配置即可同步到所有数据源
-
统一的数据源发现与浏览
- 目前:用户需知道数据在哪个系统才能找到
- 引入后:在Metalake中统一浏览所有数据源,降低数据发现门槛
-
简化新数据源接入
- 目前:每接入新数据源需开发采集适配器+权限适配器+血缘解析器
- 引入后:仅需配置Gravitino Catalog连接器即可
-
支持Lakehouse架构演进
- 目前:Iceberg/Paimon等Lakehouse格式管理能力薄弱
- 引入后:Gravitino原生支持Iceberg REST Catalog、Paimon Catalog等,且可作为Iceberg REST Catalog服务直接为引擎提供服务
价值量化预估:
| 指标 | 现状 | 引入Gravitino后预期 |
|---|---|---|
| 新数据源接入周期 | 2~4周 | 1~3天(配置Catalog连接器) |
| 元数据同步延迟 | 分钟~小时级 | 秒级(直接管理) |
| 跨源数据发现 | 不支持 | 支持(统一Metalake浏览) |
| 多源权限配置时间 | 30分钟+/用户(多系统操作) | 5分钟内(统一授权) |
3.3 Gravitino权限模型与现有安全体系的整合可能
整合分析:
| 维度 | 现有安全体系 | Gravitino权限模型 | 整合方式 |
|---|---|---|---|
| 权限模型 | 应用层RBAC | RBAC + DAC | Gravitino统一权限层,现有RBAC角色映射 |
| 权限下推 | 无 | 支持下推到Ranger/原生数据源 | 利用Gravitino授权下推,实现应用层到数据层的权限统一 |
| 用户/角色管理 | 应用内用户体系 | Gravitino User/Group/Role | 统一用户体系,Gravitino作为权限决策点 |
| 数据分级 | 应用层标注 | Policy管理 | Gravitino策略引擎+现有分级体系联动 |
| 审计日志 | 各源独立 | 统一审计(通过Gravitino访问) | Gravitino作为统一访问入口后,审计集中化 |
整合路径建议:
- Phase 1 --- 权限映射:将现有RBAC角色映射到Gravitino Role,实现权限声明统一
- Phase 2 --- 授权下推:启用Gravitino授权下推,将权限策略同步到底层数据源(特别是Ranger)
- Phase 3 --- 统一访问:计算引擎通过Gravitino访问数据时,权限由Gravitino统一控制,审计日志集中化
- Phase 4 --- 策略联动:数据分级标签与Gravitino Policy联动,实现分级后自动触发权限策略
关键风险:
- Gravitino目前不支持组所有权,仅支持用户所有权,与现有体系可能不完全匹配
- 权限迁移过程中可能出现双系统并存的过渡期,需灰度策略
- 底层数据源原生权限体系与Gravitino权限的映射可能不完整(各源权限粒度不同)
3.4 Gravitino与现有数据血缘、数据质量等模块的协作方式
3.4.1 与数据血缘模块协作
协作模式:
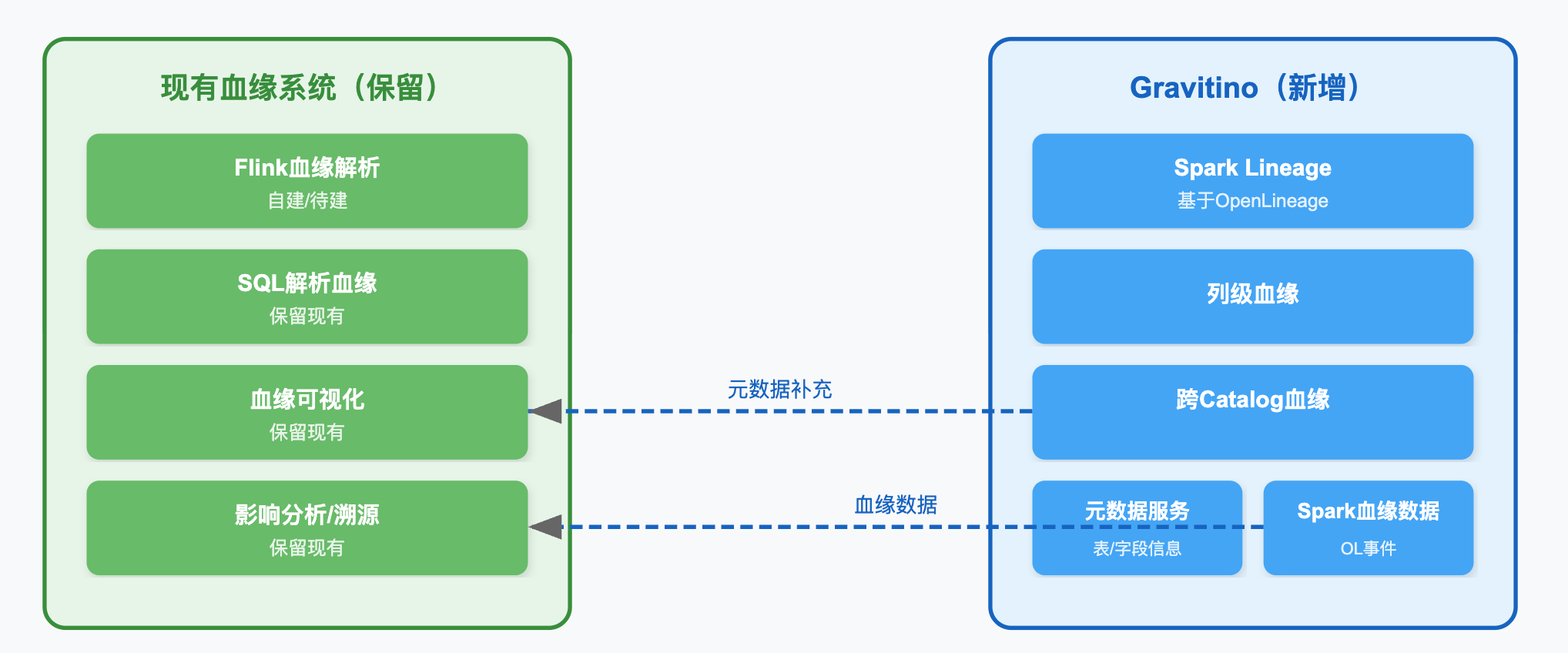
具体协作方式:
-
血缘数据互补:
- Gravitino提供Spark引擎的OpenLineage血缘数据,补充现有系统的Spark血缘
- 现有系统继续负责Flink/Trino等其他引擎的血缘采集(Gravitino暂不支持)
- 统一由现有血缘系统做血缘聚合和可视化
-
元数据增强:
- Gravitino作为元数据源,为血缘系统提供准确的表/字段元数据
- 血缘解析时通过Gravitino API获取跨Catalog的表信息,提升跨源血缘准确性
-
标识符统一:
- Gravitino提供统一的
metalake.catalog.schema.table命名空间 - 血缘系统采用Gravitino标识符,解决跨数据源标识不统一的问题
- Gravitino提供统一的
3.4.2 与数据质量模块协作
协作模式:
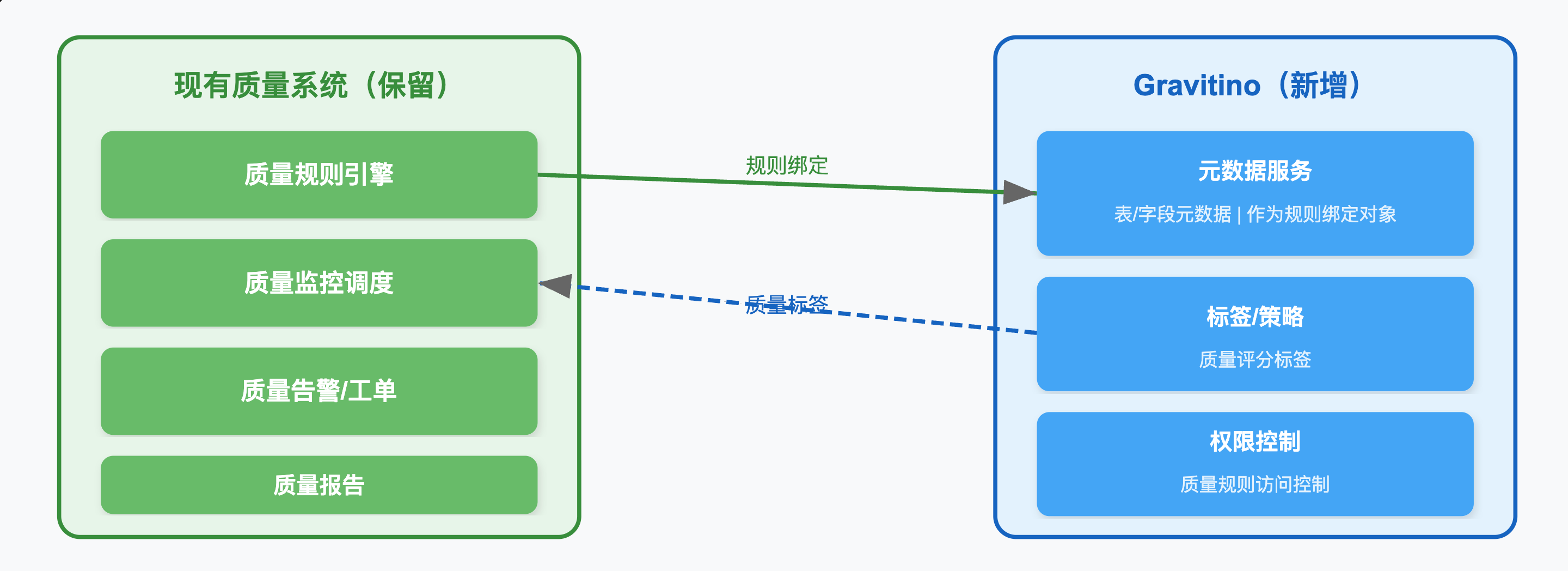
具体协作方式:
-
元数据驱动质量规则:
- 质量规则的绑定对象从"本地目录对象"升级为"Gravitino元数据对象"
- 当Gravitino感知到底层表/字段变更时,通知质量系统调整关联规则
-
质量评分标签化:
- 质量检测结果以Gravitino Tag的形式标注到对应表/字段
- 下游用户在Gravitino浏览元数据时可直接看到质量评分
-
质量规则跨源复用:
- 通过Gravitino统一元数据模型,相同结构的表(如MySQL和PG中的同名字段)可共享质量规则模板
- 降低质量规则配置成本
-
权限联动:
- 质量规则的查看/修改权限通过Gravitino统一权限体系管控
- 敏感字段的脱敏规则与Gravitino Policy联动
四、集成优先级建议
4.1 优先级评估框架
按业务价值 (解决痛点程度 × 影响面)和技术可行性(Gravitino成熟度 × 集成复杂度)两个维度评估:
| 集成方向 | 业务价值 | 技术可行性 | 综合优先级 |
|---|---|---|---|
| 统一Catalog管理(多数据源统一视图) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | P0 |
| Iceberg REST Catalog服务 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | P0 |
| 统一权限管控(授权下推) | ⭐⭐⭐⭐ | ⭐⭐⭐ | P1 |
| Spark血缘集成(OpenLineage) | ⭐⭐⭐ | ⭐⭐⭐⭐ | P1 |
| 元数据层替代(替代采集层) | ⭐⭐⭐⭐ | ⭐⭐⭐ | P2 |
| 计算引擎联邦访问 | ⭐⭐⭐ | ⭐⭐⭐ | P2 |
| 质量模块与Gravitino元数据联动 | ⭐⭐⭐ | ⭐⭐⭐ | P2 |
| 标签/策略体系整合 | ⭐⭐⭐ | ⭐⭐⭐ | P3 |
| AI资产管理(Model Catalog) | ⭐⭐ | ⭐⭐ | P3 |
| 地理分布式元数据管理 | ⭐⭐ | ⭐ | P4 |
4.2 分阶段集成路径
Phase 1 --- 基础接入(1~2个月)
目标:让Gravitino跑起来,验证核心能力
| 里程碑 | 内容 | 交付物 |
|---|---|---|
| M1.1 | Gravitino部署与配置 | 部署文档、运维手册 |
| M1.2 | 接入核心数据源(Hive/MySQL/PG) | Catalog配置、连通性验证报告 |
| M1.3 | Iceberg REST Catalog服务上线 | Iceberg引擎对接验证 |
| M1.4 | 统一目录浏览PoC | 通过Gravitino API统一浏览所有数据源 |
验收标准:
- Gravitino成功管理3+种数据源
- 元数据浏览延迟<3秒
- Iceberg引擎可通过Gravitino REST Catalog创建/查询表
Phase 2 --- 权限与血缘(2~3个月)
目标:建立统一权限体系和增强血缘能力
| 里程碑 | 内容 | 交付物 |
|---|---|---|
| M2.1 | RBAC角色映射 | 现有角色→Gravitino Role映射方案 |
| M2.2 | 授权下推到Ranger | 授权下推验证报告 |
| M2.3 | Spark OpenLineage集成 | Spark血缘通过Gravitino采集 |
| M2.4 | 血缘数据汇聚到现有血缘系统 | 统一血缘展示 |
验收标准:
- 现有RBAC角色成功映射到Gravitino
- Gravitino授权变更能同步到Ranger
- Spark任务血缘通过OpenLineage自动采集,并在现有血缘系统中展示
Phase 3 --- 深度整合(3~4个月)
目标:现有平台与Gravitino深度融合
| 里程碑 | 内容 | 交付物 |
|---|---|---|
| M3.1 | 元数据采集层迁移到Gravitino | 采集层替代方案与迁移报告 |
| M3.2 | 计算引擎(Spark/Flink)对接Gravitino | 引擎连接器配置文档 |
| M3.3 | 数据质量模块与Gravitino元数据联动 | 质量规则绑定Gravitino对象 |
| M3.4 | 现有资产门户接入Gravitino元数据 | 门户改造方案 |
验收标准:
- 元数据实时性从分钟级提升到秒级
- Spark/Flink可通过Gravitino统一访问数据
- 质量规则自动跟随元数据变更
Phase 4 --- 扩展与创新(4~6个月)
目标:拓展Gravitino高级能力,探索创新场景
| 里程碑 | 内容 | 交付物 |
|---|---|---|
| M4.1 | 标签/策略体系整合 | 统一标签策略管理方案 |
| M4.2 | AI资产管理(Model Catalog) | AI资产管理能力建设 |
| M4.3 | 更多数据源接入(ClickHouse/Doris/StarRocks/Kafka) | 新数据源接入报告 |
| M4.4 | Gravitino MCP Server与AI工具集成 | AI+数据治理场景验证 |
验收标准:
- 标签/策略与权限体系联动
- AI模型元数据可管理、可发现
- Gravitino MCP Server支持AI工具直接查询元数据
五、关键决策点
在推进集成过程中,以下决策需要尽早明确:
5.1 元数据权威源选择
问题:当Gravitino与现有平台元数据不一致时,以谁为准?
| 方案 | 优点 | 缺点 | 建议 |
|---|---|---|---|
| Gravitino为权威源 | 实时性好,直接管理底层 | 需要现有平台全部适配Gravitino | 长期目标 |
| 现有平台为权威源 | 改动小,风险低 | 无法解决时效性问题 | 过渡方案 |
| 双写+冲突检测 | 平滑过渡 | 一致性保障复杂 | 推荐 |
建议:Phase 1~2采用双写模式,Phase 3逐步切换到Gravitino为权威源。
5.2 权限体系演进策略
问题:现有应用层权限与Gravitino权限如何过渡?
- 方案A --- 激进替换:直接用Gravitino替代现有权限体系。风险高,但一步到位。
- 方案B --- 灰度切换:先在新接入的数据源上使用Gravitino权限,存量数据源逐步迁移。
- 方案C --- 旁路校验:Gravitino权限仅做审计和策略推荐,实际访问控制仍由现有体系执行。
建议:采用方案B(灰度切换),降低迁移风险。
5.3 现有采集层去留
问题:现有元数据采集层何时退役?
- 保留期:Phase 1~2,Gravitino与采集层并存,互为校验
- 退役条件:Gravitino管理的元数据覆盖率达到90%+,且一致性验证通过
- 预计时间:Phase 3后期
六、风险与应对
| 风险 | 影响 | 概率 | 应对措施 |
|---|---|---|---|
| Gravitino生产稳定性不足 | 元数据服务不可用 | 中 | 灰度上线,保留现有系统作为降级方案 |
| 权限迁移遗漏导致数据泄露 | 安全事故 | 低 | 严格审计,双系统并行期强化核查 |
| 现有功能回退 | 用户体验下降 | 中 | 充分PoC验证,功能对齐后再切换 |
| Gravitino版本升级不兼容 | 集成成本增加 | 中 | 锁定LTS版本,跟踪社区版本计划 |
| 多团队协作成本 | 交付延迟 | 高 | 成立专项小组,明确分工与里程碑 |
| 血缘采集覆盖不全 | 治理盲区 | 中 | 分阶段扩展引擎覆盖,优先保障核心链路 |
七、总结
核心结论
-
Gravitino的价值定位明确:作为统一元数据湖(Metadata Lake),Gravitino从根本上解决了现有平台"被动采集、多源割裂、权限分散"三大痛点,其"直接管理"模式是对现有"被动采集"模式的代际升级。
-
互补大于替代:Gravitino在元数据管理、统一Catalog、权限管控方面是强有力的补充/替代,但在数据质量、资产运营、业务门户等方面完全不具备能力,这些是现有平台的核心价值,需要保留和深化。
-
集成路径清晰:建议从"统一Catalog管理"和"Iceberg REST Catalog"切入(P0),逐步扩展到权限和血缘(P1),再深入到元数据层替代和质量联动(P2),最后拓展到AI资产管理等创新方向(P3/P4)。
-
需要充分验证:Gravitino作为相对年轻的项目(v1.2.1),在生产环境的稳定性、与现有体系的兼容性、版本升级的兼容性等方面仍需充分验证,建议采用灰度上线策略。
对技术设计报告的输入建议
本文档识别的以下内容应作为技术设计报告的关键输入:
- 元数据管理模式从"被动采集"到"直接管理"的架构切换方案
- 统一Catalog管理的Metalake/Catalog设计
- 权限体系的RBAC+DAC映射与授权下推方案
- 血缘模块的OpenLineage集成与跨引擎扩展方案
- 质量模块与Gravitino元数据的联动方案
- 分阶段集成路径与里程碑定义