这是「前端转 AI 应用开发」系列的第 2 篇。 全部代码在 [GitHub: python-warmup](#GitHub: python-warmup "#")(占位:把你的仓库链接放这)。
作为一个前端工程师,我一直把 Python 当成转 AI 的一道坎。直到我真正动手------才发现真正要重新适应的不到 20%。
这篇文章记录我用 2 小时做的事:搞懂 Python async 和 JS 的真实差异、用 Python 调通了阿里云 Coding Plan 的大模型 API。其实纯就调用方式来说,和 OpenAI、Anthropic 的官方协议差别不大------主流的 LLM 调用就这两套协议,把它们任一套搞熟,转栈成本极低。
如果你也是前端想转 AI,这是我能给的最短路径。
第 1 节:async 你早就会,但 Python 有 3 个暗坑
前端对 async/await 不陌生。我写了个"烧水 + 烤面包"的例子:
同步版:
python
import time
def make_tea():
print("开始烧水...")
time.sleep(2)
print("水开了,泡茶完成")
def make_toast():
print("开始烤面包...")
time.sleep(2)
print("面包烤好了")
start = time.time()
make_tea()
make_toast()
print(f"总耗时: {time.time() - start:.1f} 秒")跑出来 4 秒------两件事串着做,没毛病。
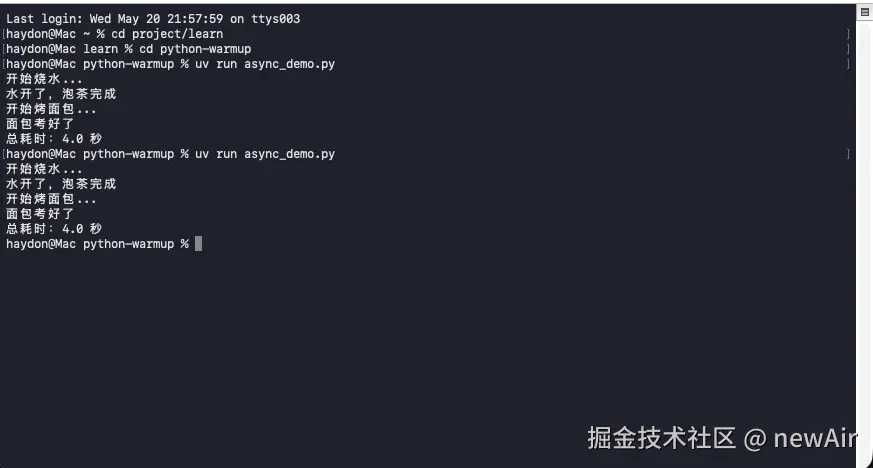
异步版(改动很小,几乎对照 JS 直翻):
python
import asyncio, time
async def make_tea():
print("开始烧水...")
await asyncio.sleep(2)
print("水开了,泡茶完成")
async def make_toast():
print("开始烤面包...")
await asyncio.sleep(2)
print("面包烤好了")
async def main():
start = time.time()
await asyncio.gather(make_tea(), make_toast())
print(f"总耗时: {time.time() - start:.1f} 秒")
asyncio.run(main())跑出来 2 秒。

第一反应:这不就跟 JS 一样吗? asyncio.gather 就是 Python 的 Promise.all,async def 就是 async function,await 就是 await。确实,API 表面一模一样。
但往下扒一层,藏着 3 个 JS 党最容易栽的坑。
坑 1:Python 必须手动"点火"事件循环
JS 的事件循环是运行时自带的------你在浏览器或 Node 里直接写 await fetch() 就行,没人问你"哪来的事件循环"。
Python 不一样。最外层必须有 asyncio.run(main()) 这一行去启动循环 ,否则你的 async def 是一坨死代码。
这是 JS 党第一个不适应的地方:"为什么我还要操心循环从哪儿来?"
坑 2:调用 async 函数,根本不会执行
这条最容易翻车。下面这段代码看起来非常无害:
python
result = make_tea()
print(result)JS 直觉告诉你:调用 make_tea(),函数体会开始执行,然后返回一个 Promise。
但在 Python 里,它输出的是:
csharp
<coroutine object make_tea at 0x10a3b5c40>make_tea() 没执行函数体 ,只返回了一个"协程对象"。要真正跑起来,必须 await make_tea() 或交给 asyncio.gather/run。
我自己看到这行的时候愣了一下------这个差异之前真的不知道,如果按 JS 直觉写代码,肯定会踩坑。
写一句话记一下:
- JS:调用 async 函数 → 立即开始执行 + 返回 Promise
- Python:调用 async 函数 → 什么都不发生,只返回协程对象
坑 3:sleep 千万别用错
| 错 | 对 |
|---|---|
time.sleep(2) 写在 async 函数里 |
await asyncio.sleep(2) |
time.sleep 是同步阻塞的------它会卡死整个事件循环。你以为自己在写异步,结果其他协程全在等你睡完,异步白写。
记住:async 函数里凡是要"等",都用 await asyncio.xxx。
🪤 顺便记一个开张第一坑:f-string 忘加 f
这跟 async 无关,但是第一次写 Python 几乎都会栽:
python
print(f"总耗时:{time.time() - start:.1f} 秒") # 对
print("总耗时:{time.time() - start:.1f} 秒") # 错第二行没加 f 前缀,Python 会把 {...} 当成字面量 ------大括号原样打出来,或者更诡异的情况:格式化符号被错误解读成科学计数法 ,输出像 总耗时:4e+00 秒 这种鬼东西。
这是 JS 模板字符串党最容易栽的坑:
- JS :反引号 ````` 触发模板
- Python :字符串前缀
f触发模板
没有 f 的字符串里,{} 就是普通字符。
第 2 节:调一次大模型,就明白为什么 AI 离不开异步
理论说完了,看个真实场景。我用 httpx(Python 版的 fetch)并发发了 3 个请求,分别等 1、2、3 秒:
python
async with httpx.AsyncClient(timeout=15) as client:
await asyncio.gather(
fetch_delay(client, 1),
fetch_delay(client, 2),
fetch_delay(client, 3),
)教科书会告诉你:串行 6 秒,并发 3 秒。
实际跑出来:并发版 5 秒,串行版 8~10 秒。
差距没有教科书那么漂亮,因为多了 TLS 握手、跨境网络、服务端处理这些开销。但这恰恰是真实生产环境的样子------调用大模型 API 永远是"理论值 + 网络抖动"的组合。


把这两个截图并排放一下,价值就出来了:
- 串行 8 秒 vs 并发 5 秒
- 省下来的 3 秒就是异步的真实收益
为什么 AI 应用里异步不是可选项?因为用户能直接感受到 5 秒和 10 秒的差距。等待大模型生成回复本来就慢,如果背后还串行调多个 API,体验直接崩。
第 3 节:5 分钟,用 Python 调通大模型
里程碑在这里。
我的环境是 阿里云 Coding Plan ------一个把 Qwen、GLM、Kimi、MiniMax 等国产模型打包按月订阅的服务,同时提供 OpenAI 兼容 和 Anthropic 兼容 两套 endpoint。我之前用 Claude Code 时,key 其实就是它(sk-sp- 开头)。
这里有个值得讲的工程认知:2024 年之后,主流 LLM 调用基本只有两套协议------OpenAI 兼容 和 Anthropic 兼容。任何模型提供商(阿里、DeepSeek、Moonshot、本地 Ollama)都会兼容这两套中的至少一套。学会其中一套,换栈成本极低------这是为什么我不焦虑"今天用了 Claude,明天要换 Qwen"。
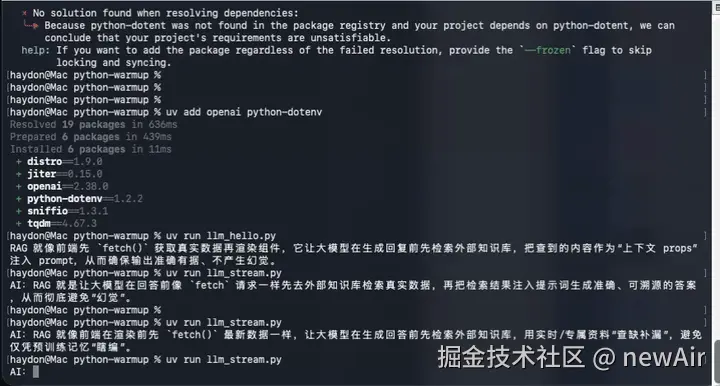
装包
bash
uv add openai python-dotenv注意------用 openai SDK 不代表用 OpenAI 的模型 。它只是 OpenAI 兼容协议的客户端,换个 base_url 就能接任何兼容服务。这种"协议互认"是当下 LLM 生态的标准玩法。
三行调通
python
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://coding.dashscope.aliyuncs.com/v1", # ← 关键:指到阿里云 Coding Plan
)
response = client.chat.completions.create(
model="qwen3-max",
max_tokens=200,
messages=[{"role": "user", "content": "用一句话解释什么是 RAG,面向前端工程师。"}],
)
print(response.choices[0].message.content)跑一次,qwen3-max 给我吐出一段完整回复。
第一次用 Python 调通大模型那一刻的感觉:模型调用真没那么高深。装包、给 key、改个 base_url、发条 message------和前端调 REST API 区别不大。和过去几年想象中的"AI 工程师"光环对比,这里更像是"普通的 HTTP 客户端,只是回复内容是模型生成的"。

但有一点不舒服:这种一次性等模型把答案全吐完再打印,体感比较慢------不像 Claude Code 里那种打字机效果。
流式输出,几行的事
把 stream=True 开起来:
python
stream = client.chat.completions.create(
model="qwen3-max",
stream=True,
messages=[{"role": "user", "content": "给前端工程师 3 条转 AI 应用开发的建议,每条一句话。"}],
)
for chunk in stream:
delta = chunk.choices[0].delta.content
if delta:
print(delta, end="", flush=True)回复瞬间变成一个字一个字冒出来。所有面向用户的 AI 应用都用流式输出------这是后面 SSE / WebSocket 工程化的基础。
几句可以摘走的结论
f-string 忘加
f,输出就长得像科学计数法的怪东西。 ------ JS 党转 Python 的开张第一坑
前端转 Python,80% 的语法是免费的。 ------ 真正要重新适应的,是那 20% 的运行时模型差异(协程对象、显式事件循环、阻塞 sleep)
模型调用没那么复杂,也没那么高深。 ------ 主流就 OpenAI 兼容 + Anthropic 兼容两套协议,会一套就够
结尾
门槛没有想象中那么高,动手那一刻就破了。
这是「前端转 AI 应用开发」系列的第 2 篇。下一篇我会写 LangChain Python 官方 quickstart,对照原生 SDK 看 LangChain 到底多做了什么------这是大多数 AI 应用面试题的基础。
如果你也在转 AI,评论区告诉我你卡在哪一步------我会挑高频问题专门写一篇。