本文主要整理一些自己对Linux网络协议栈的概念性问题,Q&A形式,不成体系,想到哪里写到哪里
1.Linux协议栈如何处理来自网线上的数据帧?
在linx环境下,当以太网线上来一帧数据时,SOC通过"中断+软中断+协议栈"的机制来处理该数据帧
硬件层面 - 网卡如何通知SOC有数据帧到达
1.DMA预分配接收缓冲区(Ring Buffer)
在系统启动时,网卡初始化初始化,内核会通知DMA在主内存为网卡预分配一组接收描述符(Rx Descriptor Ring)和对应的缓冲区sk_buff或raw buffer,网卡也知道这些缓冲区的物理地址
2.数据帧到达 & DMA写入
当以太网线上有数据帧到达时,网卡硬件直接通过DMA将帧内容写入预分配的接收缓冲区,无需CPU参与数据搬运
3.触发硬件中断IRQ
DMA写完一帧后,网卡会向SOC的中断控制器发送一个硬件中断信号告诉CPU有新数据到了
内核层面
1.硬中断处理 - Top Half 上半部
CPU收到中断后,跳转到网卡驱动注册的中断处理函数
这种函数一般非常轻量,通常只做两件事(因为硬中断上下文不能睡眠,所以不做复杂操作):
1.禁用网卡的接收中断,防止频繁中断,后续靠NAPI轮询
2.调度软中断,触发NET_RX_SOFTIRQ,然后立即返回
2.软中断处理 - Bottom Half下半部 - NAPI机制
Linux使用NAPI(New API)机制来高效处理高速网络流量,软中断net_rx_action()被调度执行后:
1.调用网卡驱动的poll()函数
2.驱动从RX Ring Buffer中批量取出已接收的数据帧
3.对每个帧会构造sk_buff(socket buffer)结构体,填充协议信息(比如:ETH_P_IP),再调用netif_reveive_skb()将buffer送入网络协议栈
使用NAPI会再高负载时自动从"中断驱动"切换为"轮询模式",避免中断风暴
3.协议栈处理
netif_receive_skb()根据帧EtherType(比如:IPV4,ARP)查找对应的上层协议处理函数
如果是IP包则调用ip_rvc()
如果是ARP包则调用arp_rcv()
然后数据包逐层向上交,IP->TCP/UDP->Socket
4.交给用户进程
最终数据被放入socket的接收队列中,用户进程调用recv()/read()时,从队列中取走数据
流程图
[以太网帧到达]
↓
[网卡通过 DMA 写入 RX Ring Buffer]
↓
[网卡触发硬件中断 (IRQ)]
↓
[CPU 执行硬中断处理:禁用中断 + 调度软中断]
↓
[软中断执行 net_rx_action → 驱动 poll() 函数]
↓
[批量从 Ring Buffer 取出帧 → 构造 sk_buff]
↓
[调用 netif_receive_skb() → 协议栈 (IP/TCP/UDP)]
↓
[数据进入 socket 接收队列]
↓
[用户进程 recv() 读取数据]2.Linux本机与本机socket通信会走网卡吗?
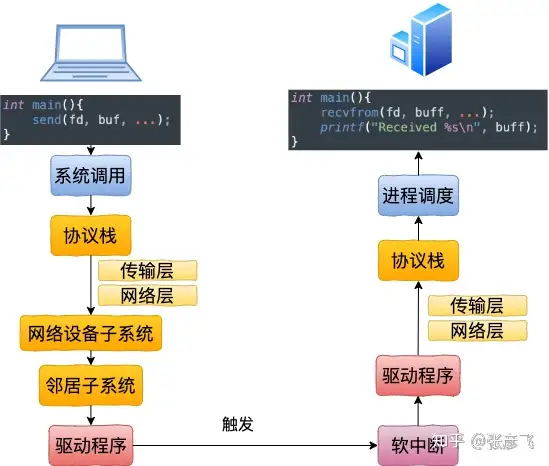
1.127.0.0.1本机网络IO需要经过网卡吗?
不需要经过网卡,即使把网卡拔了本机网络还是可以正常使用的。
本机网络IO的内核执行流程:
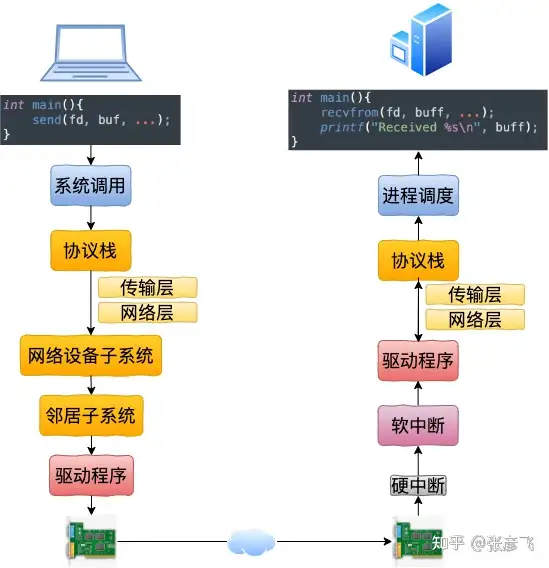
跨机网络IO的流程:
2.数据包在内核中是什么走向,和外网发送相比流程上有什么区别?
本机网络 IO 和跨机 IO 比较起来,确实是节约了驱动上的一些开销。发送数据不需要进 RingBuffer 的驱动队列,直接把 skb 传给接收协议栈(经过软中断)。但是在内核其它组件上,可是一点都没少,系统调用、协议栈(传输层、网络层等)、设备子系统整个走了一个遍。连"驱动"程序都走了(虽然对于回环设备来说只是一个纯软件的虚拟出来的东东)。
3.用本机ip(例如192.168.x.x)和用127.0.0.1性能上有差别吗?
正确结论是和 127.0.0.1 没有差别,都是走虚拟的环回设备 lo。
这是因为内核在设置 ip 的时候,把所有的本机 ip 都初始化 local 路由表里了,而且类型写死 RTN_LOCAL。在后面的路由项选择的时候发现类型是 RTN_LOCAL 就会选择 lo 了。
具体分析请参考原文:https://www.zhihu.com/question/43590414/answer/1928842338
3.DPDK是什么?
DPDk(Data Plane Development Kit)是一套数据平面开发套件,核心目标是绕过Linux协议栈,在用户态直接接管网卡进行数据包处理,从而实现极致的网络吞吐量和超低延迟
在传统的 Linux 网络模型中,数据包处理路径长且开销大:
- 频繁中断 :每收到一个包就触发一次硬件中断,CPU 大量时间消耗在中断上下文切换上。
- 内存拷贝 :数据从网卡 DMA 到内核空间,再拷贝到用户空间,至少 2 次内存复制。
- 系统调用 :用户程序通过 socket 等系统调用与内核交互,涉及模式切换和锁竞争。
- 协议栈开销 :完整的 TCP/IP 协议栈处理逻辑复杂,不适合纯转发场景。
当网络带宽达到 10Gbps、25Gbps 甚至 100Gbps+ 时,CPU 几乎全部被上述开销耗尽,无法进行有效的业务处理。
DPDK 通过以下关键技术彻底解决了上述瓶颈:
| 核心技术 | 原理说明 | 解决的问题 |
|---|---|---|
| UIO / VFIO | 将网卡的 MMIO 空间和中断映射到用户空间,用户态程序可直接读写网卡寄存器。 | 绕过内核驱动,消除系统调用开销。 |
| PMD (Poll Mode Driver) | 用户态轮询驱动,主动查询网卡收发包队列, 完全禁用硬件中断 。 | 消除中断风暴和上下文切换开销。 |
| HugePages | 使用大页内存(2MB/1GB),减少 TLB Miss,并将内存锁定在物理 RAM 中防止换出。 | 提升内存访问效率,保证确定性延迟。 |
| Zero-Copy | 数据包直接在网卡 DMA 缓冲区和用户态应用之间传递,无中间拷贝。 | 消除内存复制开销。 |
| CPU Affinity & Core Pinning | 将收发包线程绑定到专用 CPU 核上,避免调度迁移和缓存失效。 | 最大化单核算力利用率。 |
| Batch Processing | 批量收发包(如一次取 32/64 个描述符),摊薄单次操作开销。 | 提升指令缓存命中率和吞吐量。 |
DPDK软件架构:
┌─────────────────────────────────────┐
│ 用户态应用程序 │ ← 你的业务逻辑(路由/过滤/DPI等)
├─────────────────────────────────────┤
│ DPDK Libraries (EAL, MBUF, │ ← 环境抽象层、内存池、Ring队列
│ Ring, Mempool, Ethdev...) │ 流分类、加密、压缩等加速库
├─────────────────────────────────────┤
│ PMD (User-space NIC Drivers) │ ← 用户态网卡驱动(Intel/Mellanox/Broadcom等)
├─────────────────────────────────────┤
│ UIO / VFIO / HugePages │ ← 内核旁路机制
├─────────────────────────────────────┤
│ Linux Kernel │ ← 仅负责启动初始化,运行时不参与数据面
└─────────────────────────────────────┘- EAL (Environment Abstraction Layer) :DPDK 的"操作系统",负责初始化 HugePages、CPU 亲和性、PCIe 设备探测等底层环境。
- Mbuf :DPDK 的数据包缓冲区结构体,类似内核的
sk_buff,但更轻量高效。 - Ring Library :无锁环形队列,用于多核之间的零拷贝数据传递。
- Ethdev API :统一的网卡抽象接口,屏蔽不同厂商 PMD 的差异。
DPDK 就是把原本由内核干的"搬包"活儿,搬到用户态用专用 CPU 核以"流水线工厂"的方式高效完成,让通用服务器也能拥有媲美专用 ASIC 的网络处理能力。