 上一篇把 harness 和业务工程的边界划清了:harness 是平台层,业务工程建在它之上,不去改它。结尾我留了个问题:业务侧的 spec 到底要写些什么。
上一篇把 harness 和业务工程的边界划清了:harness 是平台层,业务工程建在它之上,不去改它。结尾我留了个问题:业务侧的 spec 到底要写些什么。
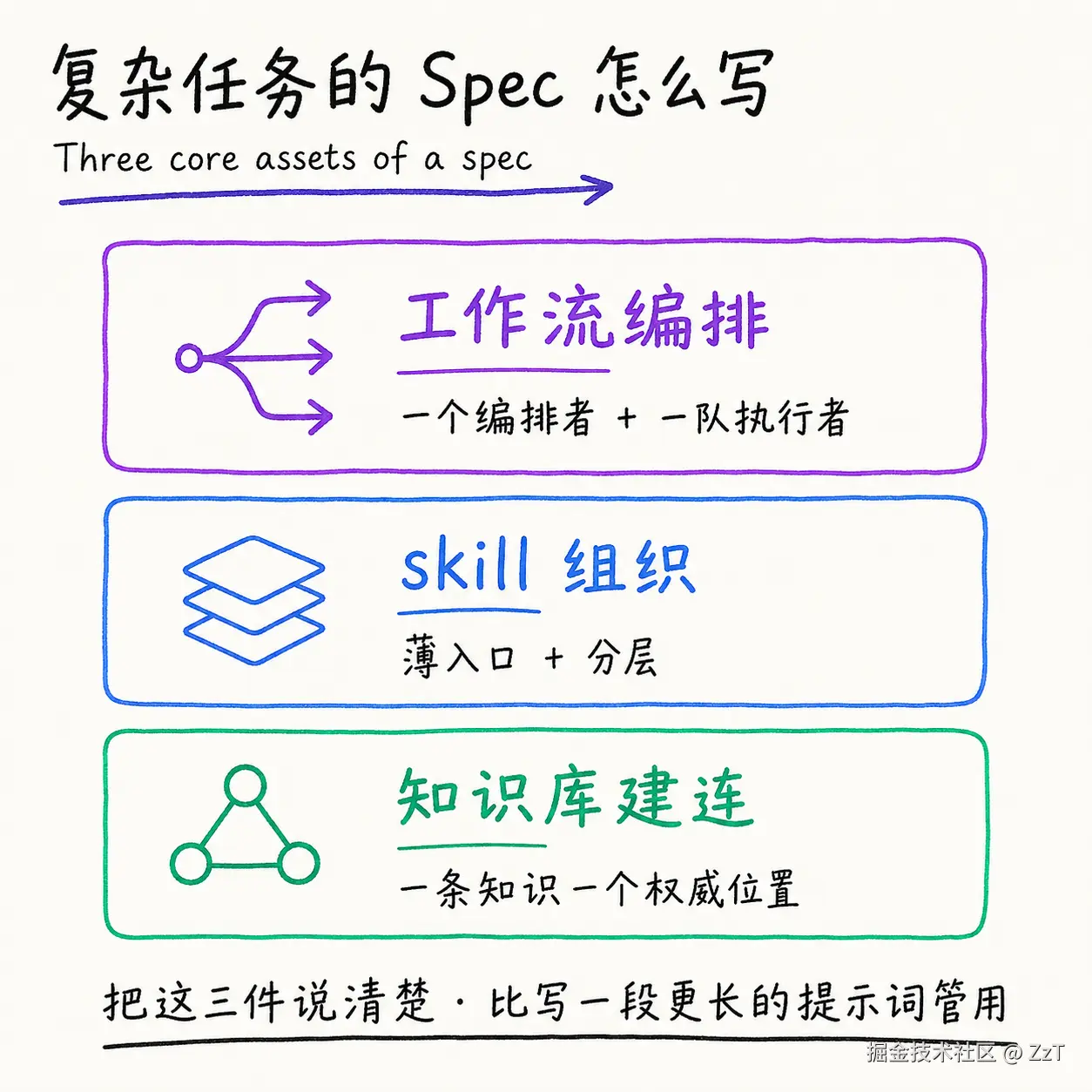
这篇正面回答。一个简单任务,你写句话扔给模型就完事了。但当任务复杂到需要多个角色协作、跨多个阶段、还要保证每步可追溯,spec 就不再是"一段提示词",而是一套有结构的工程资产。我把它拆成四个问题来讲:多 Agent 怎么落地、编排者入口写什么、rules/docs/skills 怎么分工、skill 怎么分层。
一、多 Agent:一个编排者 + 一队专职执行者
复杂任务的第一个决定,是别让一个 Agent 从头干到尾。
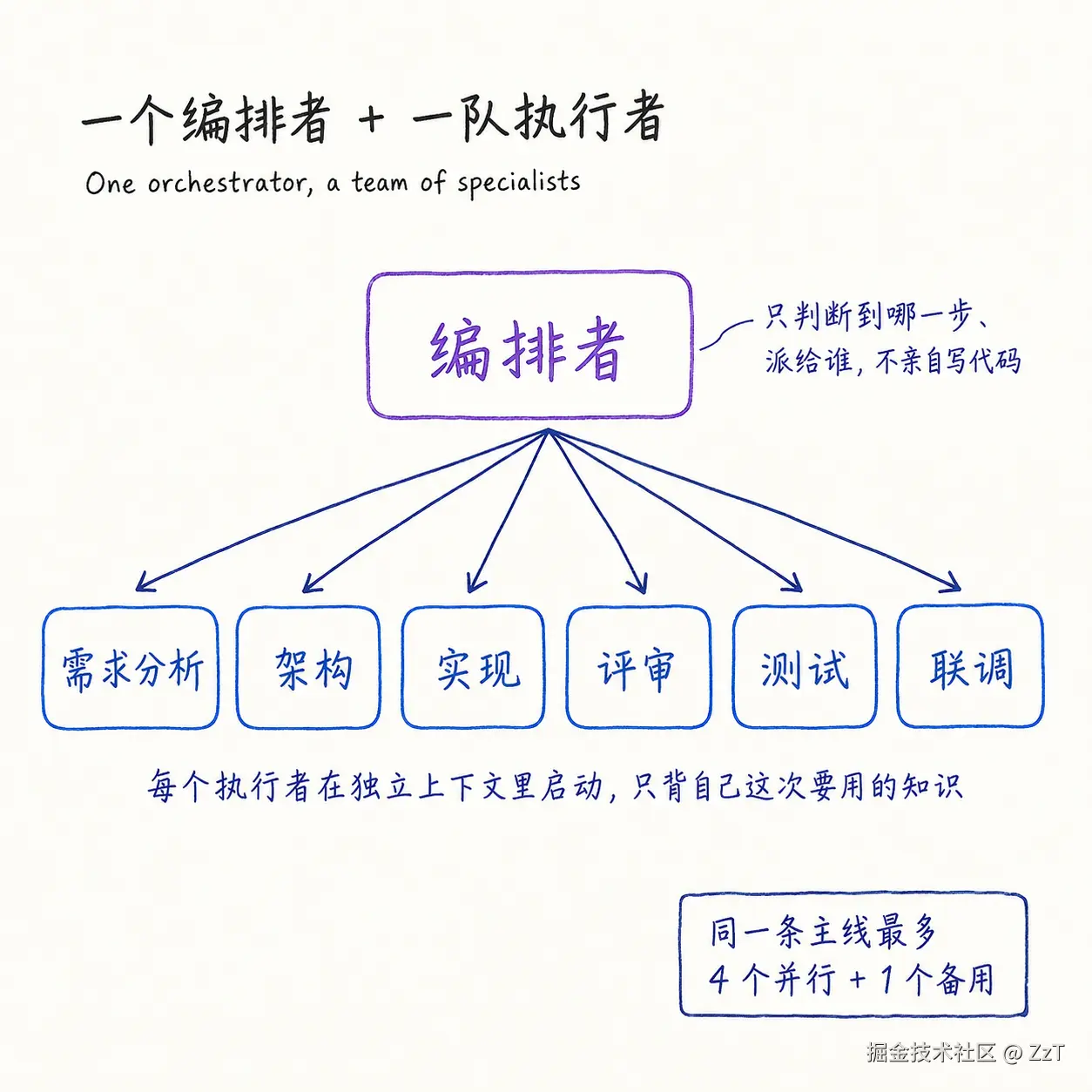
上下文会爆,职责会糊,一个 Agent 既做需求分析又写代码又做评审,到后面它自己都分不清现在是哪个身份、该守哪条规矩。我的做法是一个编排者带一队专职执行者。
编排者(入口 Agent)只做编排和收口:判断现在到哪个阶段、门禁过没过、该派给谁、要不要继续。它不亲自写业务代码。具体的活派给专职子 Agent,每个子 Agent 在一个全新上下文里启动,只背它这次要用的知识。
执行者按职责分角色,我这套大概是这么几个:
- 需求分析师:把需求文档和范围拆成结构化输入
- 架构师:做技术设计、定跨端统一契约、写 ADR,但不写实现代码
- 各端实现者:按平台分开,每端一个,只写自己那端
- 代码评审者:从安全、性能、规范、参考实现对齐等多个维度核验
- 测试工程师:补测试口径、写先失败的验收测试
- 联调工程师:跑端到端构建、安装、运行、日志、跨端一致性
- 效率工程师:把反复出现的模式沉淀成可复用资产
角色划分有一个容易被忽略的作用:选错角色,不只是分工不对,更会绕过这个角色绑定的规则约束。 比如各端实现者会自动加载对应平台的硬约束清单,而架构师不会。如果把一个该交给实现者的活错派给架构师,那套实现层的检查就整个失效了。我吃过这个亏:一次把端上 UI 实现错派给了架构师,绕过了它该过的几道关卡,视觉对齐的问题又冒出来了。
所以派发不能凭感觉。我的规则是先按阶段选角色,再用"改动文件路径 → 角色"的映射表校验写入范围,两者冲突就停下来说清楚,绝不擅自扩大某个 Agent 的写入范围。还有一条:跨端的改动禁止用一个 Agent 包办,必须先由架构师产出统一契约,再让各端实现者在隔离的写入范围里并行。
并行也要有节制。同一条主线我最多挂 5 个子 Agent,常态并行 4 个,第 5 个只留作备用。每个子 Agent 派出去时就声明清楚:要交付什么产物、什么格式、写到哪、验收条件是什么。完成后先核验产物在不在、合不合格,再关闭它释放名额。没有这套配额和产物核验,多 Agent 很快会变成一群失控的并发进程。
二、编排者入口(CLAUDE.md / AGENTS.md)写什么
编排者的行为,绝大部分由它的入口文件决定,也就是 CLAUDE.md 或 AGENTS.md。这个文件写好写坏,直接决定整个协作是有序还是混乱。
我的第一条原则是:入口只放启动索引和硬边界,不放具体步骤。
很多人会把所有规则、所有流程一股脑塞进 CLAUDE.md,最后它长到几千行,模型每次启动都要读一遍,既慢又抓不住重点。正确的做法是让入口很薄:它只告诉模型"任务来了先判断类型、然后去读哪个文件"。具体步骤放进 skill,硬规则放进 rules,角色契约放进 agents,背景和决策记录放进 docs。入口本身只是一张地图。
第二条是把编排者的契约写死。我的入口文件里有一段"入口 Agent 契约",核心就几句:
- 它是编排者和收口者,不是执行者
- 只判断阶段、门禁、交接、是否继续、派给谁
- 小型机械修订、索引更新、跑校验可以自己做,其余默认派给子 Agent
- 不直接改生产代码,不绕过门禁、评审和校验
- 遇到非致命问题,先记录 owner、route、证据、下一步,而不是停下来问
- 只有致命错误,或当前门禁明确卡住,才允许停
最后这两条尤其重要。复杂工作流最怕的是 Agent 一遇到小问题就停下来等你拍板,跑十分钟问你八次。把"什么情况记录后继续、什么情况才允许停"写进契约,它才能真正一口气跑完一条链路。同理,子 Agent 的派发是编排者的内部动作,不该每次都回来问你"能不能派下一个"------只有范围扩大、破坏性操作、风险接受、对外发布这些才回到你这里决策。
还有一个坑要专门提醒:别直接编辑生成态的入口文件。 我的入口真正的权威源是一个模板文件,CLAUDE.md 和 AGENTS.md 都是用工具从模板投影出来的。直接改投影出来的文件,下次一同步就被覆盖了。这点在多 Agent 协作里很容易踩------你以为改了规则,其实改的是个一次性产物。
三、rules / docs / skills 怎么组织
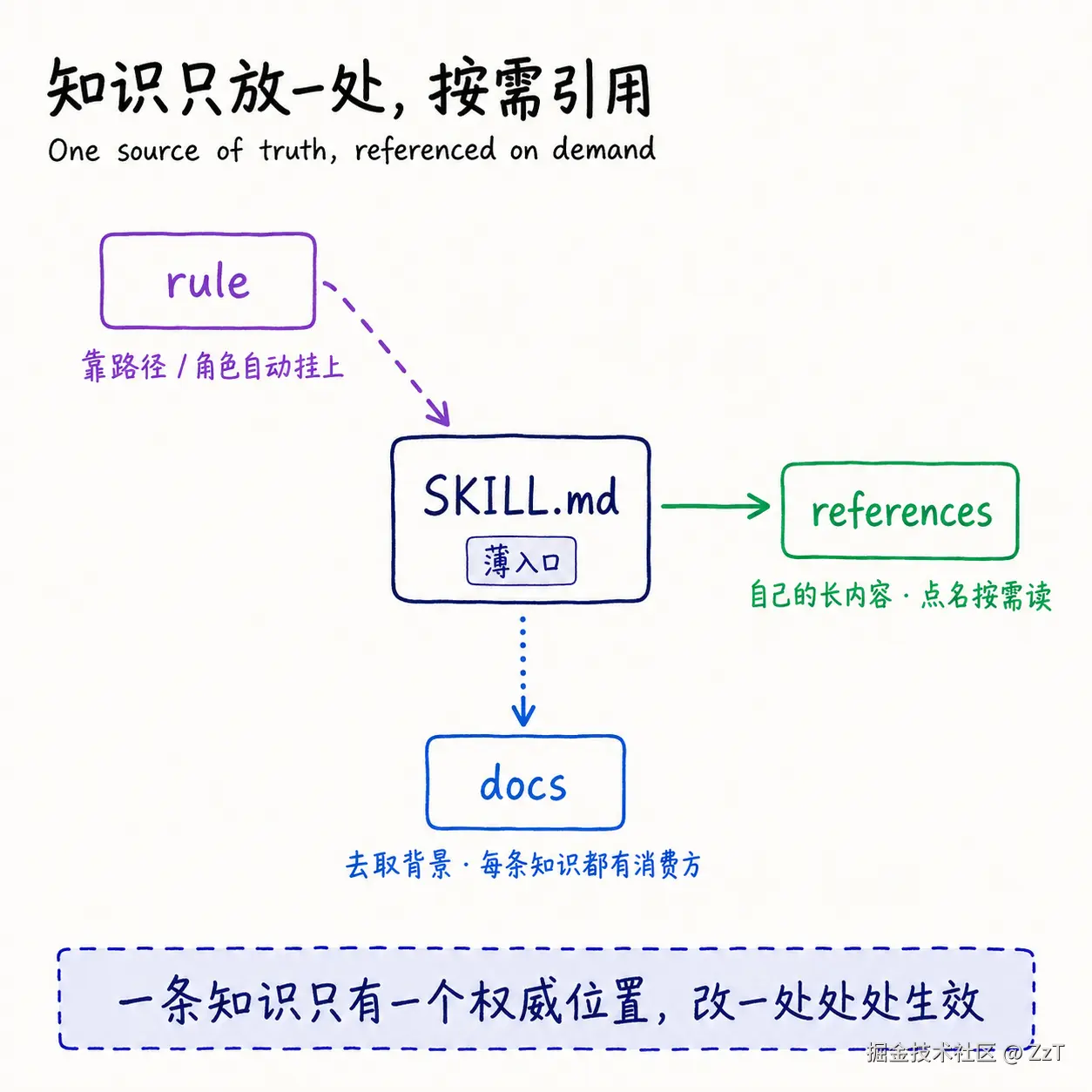
spec 不只是流程,它还包括"知识、约束、步骤分别放在哪、怎么互相引用"。我用三类目录回答三个不同的问题:
- skills:怎么做(具体步骤和流程)
- rules:必须遵守什么(硬约束、检查清单)
- docs:为什么是现在这样(架构、背景、长期决策记录)
这套分法的核心好处是,同一条知识只有一个权威位置。流程变了改 skill,约束变了改 rule,要追溯某个设计为什么这么定就翻 docs,不会到处都是重复又互相矛盾的说明。
一个 skill 的文件结构长什么样
每个 skill 是一个目录,标准结构很简单:
objectivec
某个 skill/
SKILL.md 入口:路由 + 职责 + 边界 + 输出契约
references/ 按需加载的长内容:方法论、模板、检查段
scripts/ 确定性脚本(只有 script-backed skill 才有)测试样例不放在 skill 目录里,而是放在一个平行的 evals 目录下、按 skill 名一一对应(下一篇讲)。
SKILL.md 本身也有固定骨架,几段都很短:
- frontmatter:name、用于路由的 description(必须含"适用 / 不适用 / 典型触发语")、层级、风险等级、要不要人工复核
- 职责边界:这个 skill 管什么
- 适用与不适用:什么时候召唤、什么时候别召唤
- 工作方式:最小流程,外加"什么时候该去读哪个 reference"
- 按需加载 references:一张清单,把每个场景对应的 reference 文件列出来
- 输出与验证:交付什么、怎么算通过
关键就一条:SKILL.md 要薄。 它是给模型快速判断"要不要用我、怎么用我"的路由卡,不是知识库。把平台细节、反模式、长模板全堆进去,等于每次召唤都让它读一篇论文,召唤判断反而被淹没。
skill 怎么引用 rule、docs 和知识库
skill 正文薄,那真正的长知识在哪、怎么被用上?靠三种不同的引用方式,各管一类。
references 是 skill 自己的长内容,按需点名加载。 我不把方法论和模板写进 SKILL.md,而是拆成 references 下的独立文件,在"工作方式"里写清"这一步去读哪个 reference"。模型只在真正走到那一步时才把它读进上下文,平时不占。
rule 不在 skill 正文里抄,靠路径和角色自动挂。 一种是目录级规则:每份规则声明它管哪些路径,Agent 一进入这个路径,规则就自动加载进来;另一种是角色绑定,某个角色被派出去时,它该守的检查清单自动跟着加载。最硬的那几条约束则不挂路径,启动就常驻。这样规则的权威源只有一份,skill 和角色都是"引用"它,而不是各自抄一份。
docs 是被消费的知识库,引用关系必须显式。 docs 放长期知识和决策记录,skill 在需要背景时去读它。这里有一条我特别在意的纪律:docs 里的每条长期知识,都应该有一个明确的消费方(某个 skill、rule 或角色)引用它。 没有消费方的知识就是孤儿知识------写下来没人读、改了没人知道、慢慢就和实际脱节了。新增一条 docs 知识时,顺手补上谁会用它,这条知识才算真正进了系统,而不是堆在一个没人看的文件夹里。
三者合起来是一张引用网:skill 正文薄、点名读自己的 references、被动挂上路径和角色绑定的 rule、主动去 docs 取背景,而每条知识都只有一个权威位置。
script 怎么组织
scripts 目录放确定性工具:校验器、命令包装器、流程辅助脚本。它存在的意义,是缩小 Agent 自由发挥的空间。凡是有唯一正确做法的事,就别让模型每次现编,写成脚本钉死。
我对脚本有几条硬要求:优先用标准库和 POSIX shell,少引外部依赖;写状态文件必须原子写入,并发要加锁;命令包装器只调配置里声明过的入口,完整日志落盘、主会话只回传摘要。还有一条容易偷懒的:新脚本必须配测试,改了流程脚本要跑回归,不能只过一遍语法检查。脚本是用来兜住确定性的,它自己不可靠就失去了意义。
四、skill 怎么分层,为什么分层
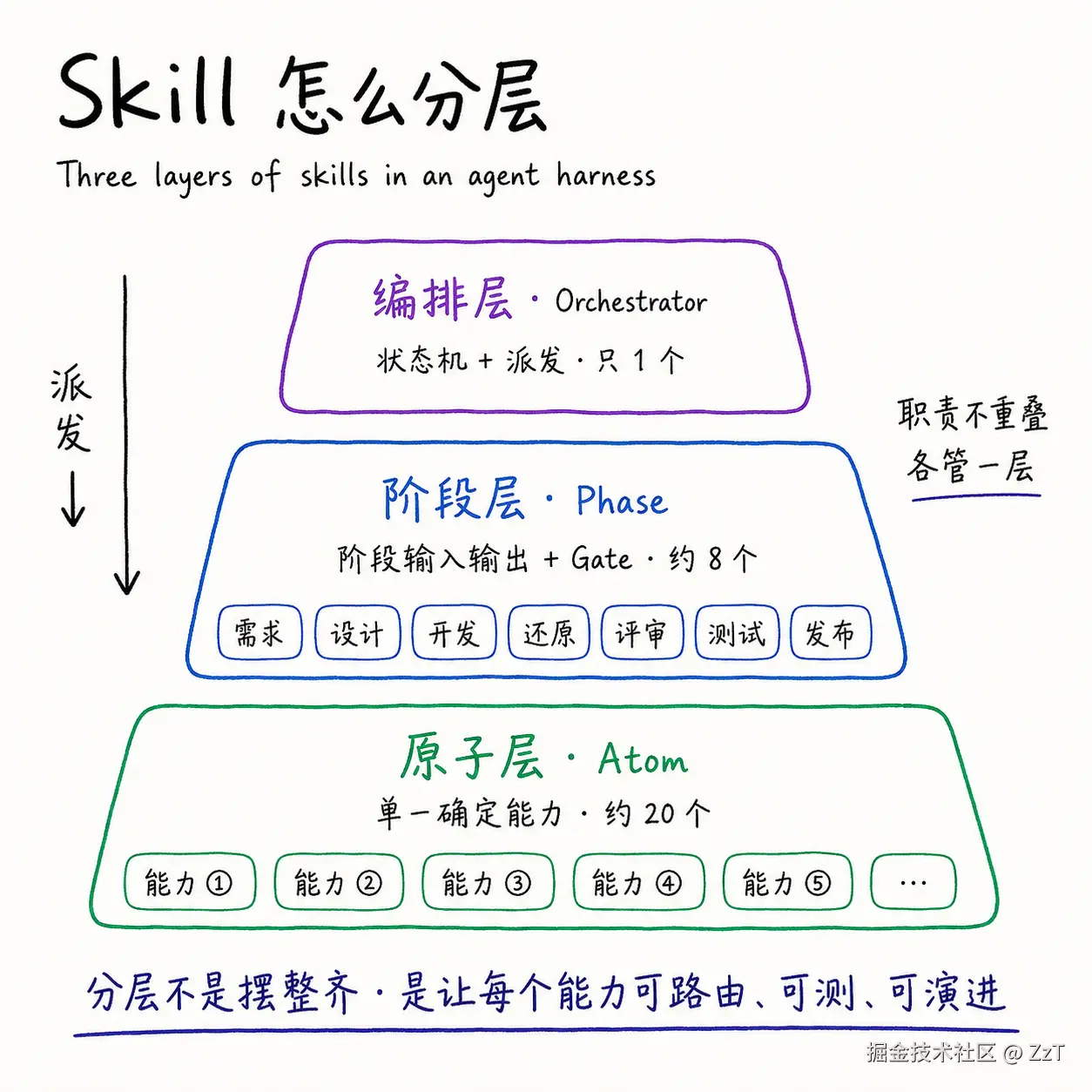
最后一层组织,是 skill 内部怎么分层。
我的 skill 分三层,职责严格不重叠:
- 编排层(orchestrator):通常只有一个,维护状态机、派发控制权,不干具体活
- 阶段层(phase):对应交付链路的每一段,比如需求、设计、开发、评审、测试、发布,每段管自己的输入输出和门禁
- 原子层(atom):最底下的单一确定能力,每个只做一件事,不编排别的 skill,也不发明命令
阶段层有个关键设计叫 gate。每个阶段结束不是简单的"做完了",而是给一个四态结论:pass(通过)、blocked(卡住,附负责人和回退路径)、not_required(本阶段对该模块不适用)、risk_accepted(有问题但已被显式接受)。举个例子,某个模块根本不渲染界面,那它的 UI 还原阶段直接写 not_required 放行;但如果缺少必要的设计参考,它不会硬着头皮凭感觉调,而是标 blocked 退回上游补齐。没有证据时,宁可卡住也不要假装完成。
光在脑子里分三层没用,得让它变成机器能读、能校验的东西。我把整张图落成一个清单文件,是所有 skill 的单一事实来源。每个节点声明固定字段:属于哪一层、怎么执行(背后挂脚本还是靠模型推进)、用于路由的描述(必须含"适用 / 不适用 / 典型触发语")、输入输出、可用工具、风险等级、要不要人工复核。
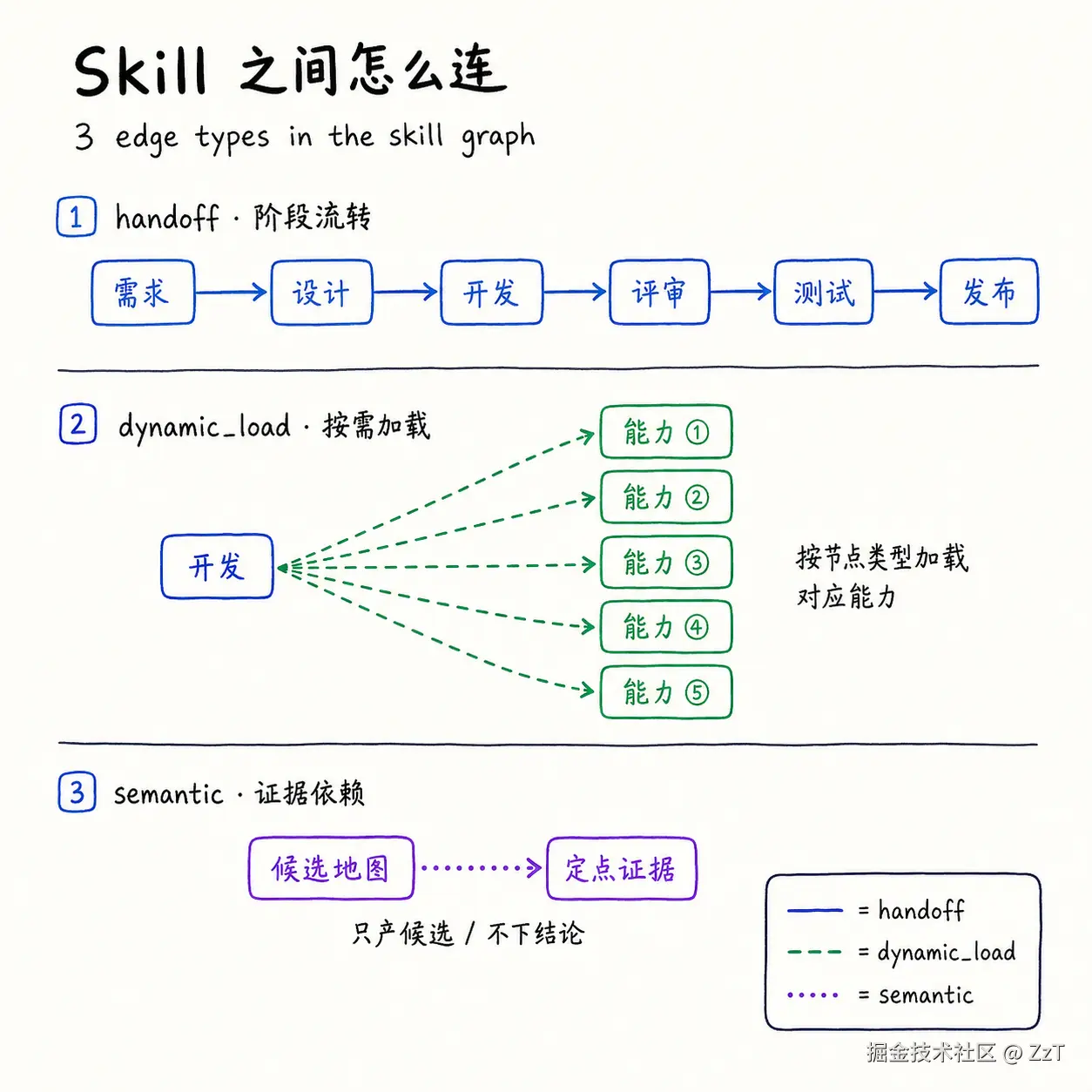 节点之间用三种 edge 连起来:
节点之间用三种 edge 连起来:
- handoff:阶段之间的流转,由编排者驱动
- dynamic_load:按当前任务类型,在子 Agent 的新上下文里动态加载对应能力,用什么加载什么,不全塞进去
- semantic:证据依赖,比如"发现候选"这步只产候选地图,真正的定点证据必须由下游证据 skill 收敛,不能看到候选就当结论
那么,为什么非要分层? 因为这几件事的变化频率和失败模式完全不同。编排逻辑很少变,一变就是全局的;阶段契约中等频率变,改的是某一段的输入输出;原子能力最常变,但每次只动一个点。混在一起,你就没法只改一层而不担心其他层崩。分层之后,每个能力都能被独立地路由、独立地测、独立地改,而不会悄悄拖动别的部分。
记住一句话
复杂任务的 spec,核心是三件资产:工作流怎么编排、skill 怎么组织、知识库怎么建连。把这三件分别说清楚,比写一段更长的提示词管用得多。
回头看这一篇,正好对着这三件资产。
工作流编排是前两节:多 Agent 决定活分给谁、各自守什么;编排者入口决定从哪进、谁说了算、怎么记录着问题一口气跑完,而不是动不动停下来等你。
skill 组织贯穿三、四节:一个 skill 的文件怎么摆(薄入口 + 按需加载的长内容 + 确定性脚本),整套 skill 怎么分成编排、阶段、原子三层,让能力加得越多也不乱。
知识库建连是第三节那张引用网:rule 靠路径和角色自动挂上、docs 的每条知识都得有消费方、skill 只点名读自己的 references。一条知识只有一个权威位置,改一处就处处生效,不会到处是互相矛盾的副本。
这三件合起来,让"AI 到底在干什么"变得可追踪:每一步该谁做、该守什么、该产出什么证据、卡住往哪退,都写在 spec 里,而不是藏在某次对话的临场发挥里。
这跟第一篇是同一个主题------克制。不让能力随便长,每加一个都要说清楚它的位置和契约。
但写好 spec 只解决了"组织得清不清楚",还没解决"每个 skill 到底好不好用"。一段路由描述写得再漂亮,模型就一定会在对的时候召唤它吗?一个阶段声称会输出门禁结论,它真的每次都输出了吗?这些要靠测。
下一篇讲怎么测一个 skill 到底好不好用,主要是三件事。
第一,怎么做对照。同一道题,给模型配上这个 skill 跑一遍、不配再跑一遍,比两次输出差在哪。只有这样才知道,好的地方是这个 skill 带来的,还是通用规则本来就能做到的,不会把功劳算错。
第二,怎么把结果存下来。模型每次的真实回答都存成文件、提交进代码库,谁都能随时翻出来复查,而不是跑完就忘、下次又是一套新结果。
第三,为什么我不拿另一个大模型来打分。让 AI 当裁判听着省事,但裁判自己也不稳,今天给 8 分明天给 6 分。我宁可用一组写死的、对错一目了然的检查项来判。