- 开发语言:Python
- 框架:Flask
- Python版本:python3.8
- 数据库:mysql 5.7
- 数据库工具:Navicat12
- 开发软件:PyCharm
系统展示
系统首页
系统注册
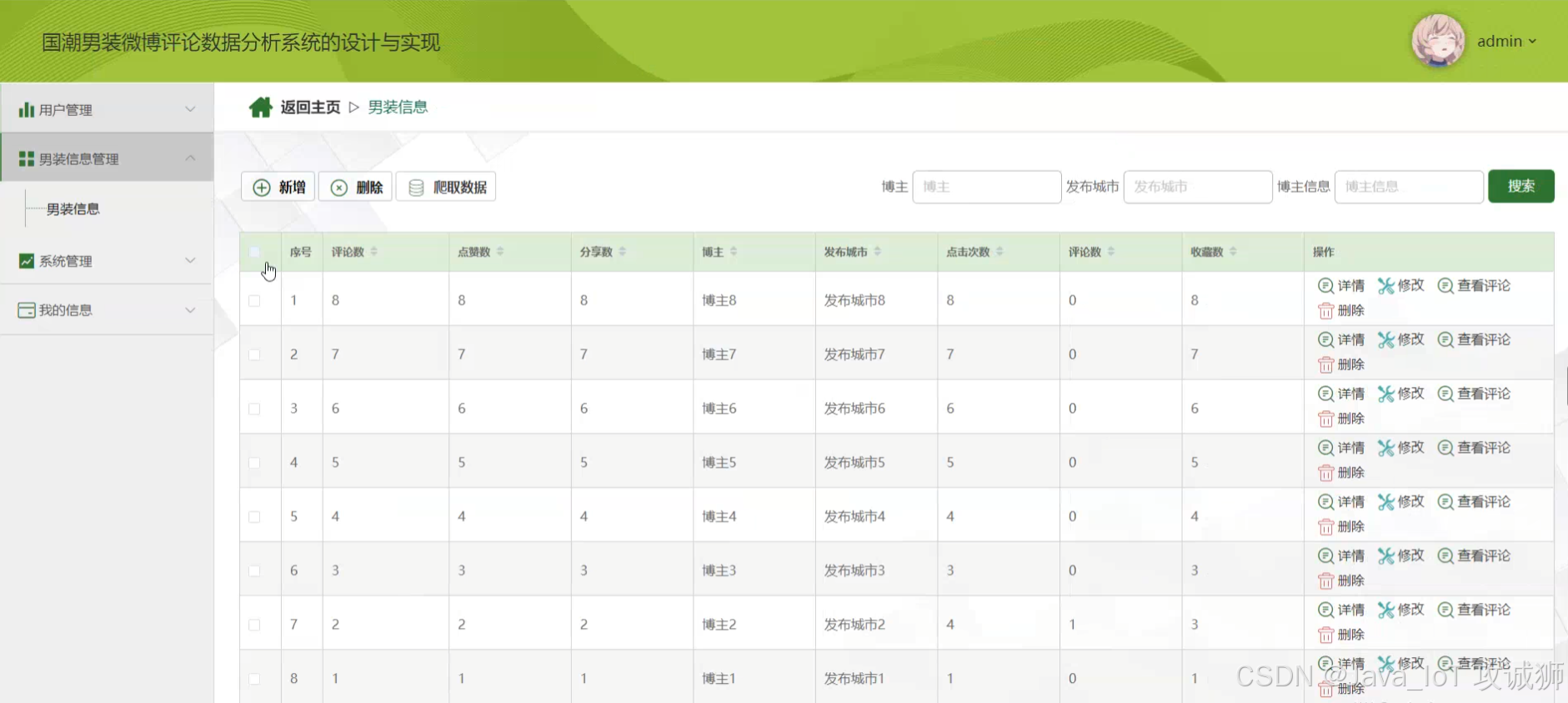
服装资讯

管理员登录
管理员功能界面
用户管理
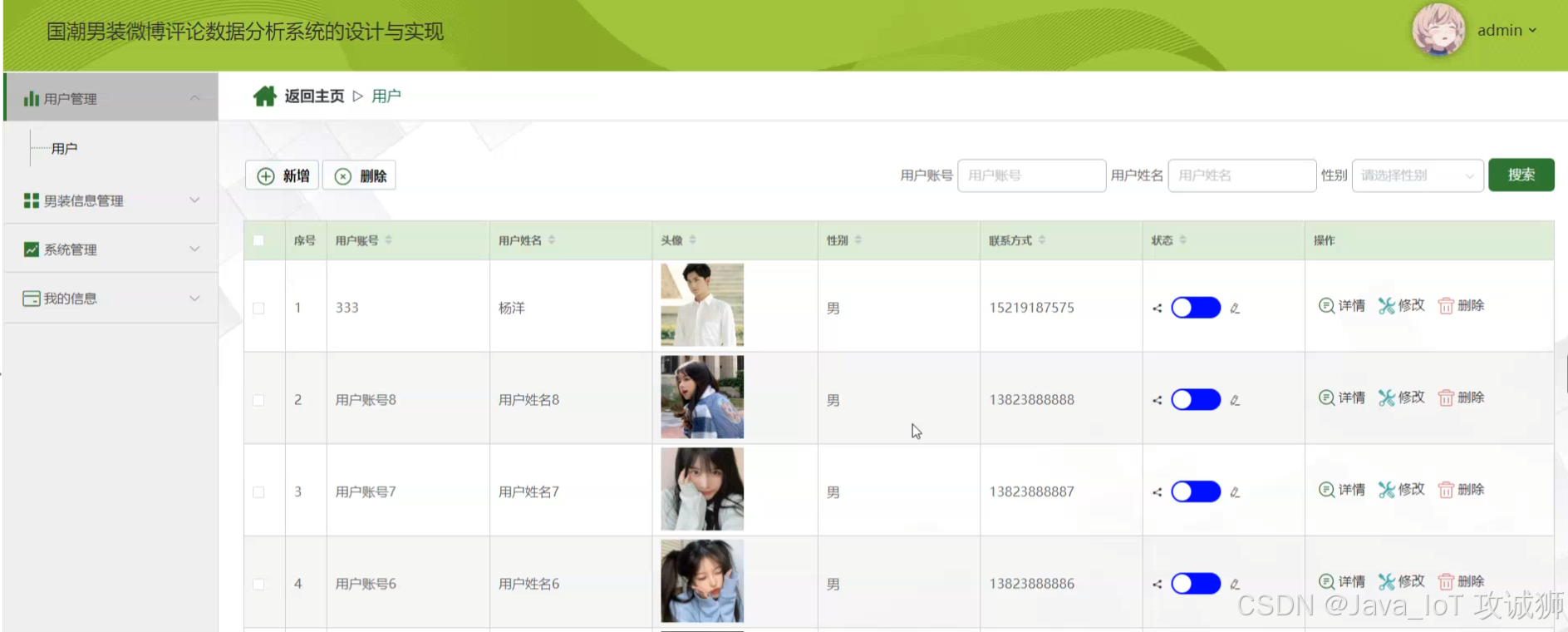
男装信息
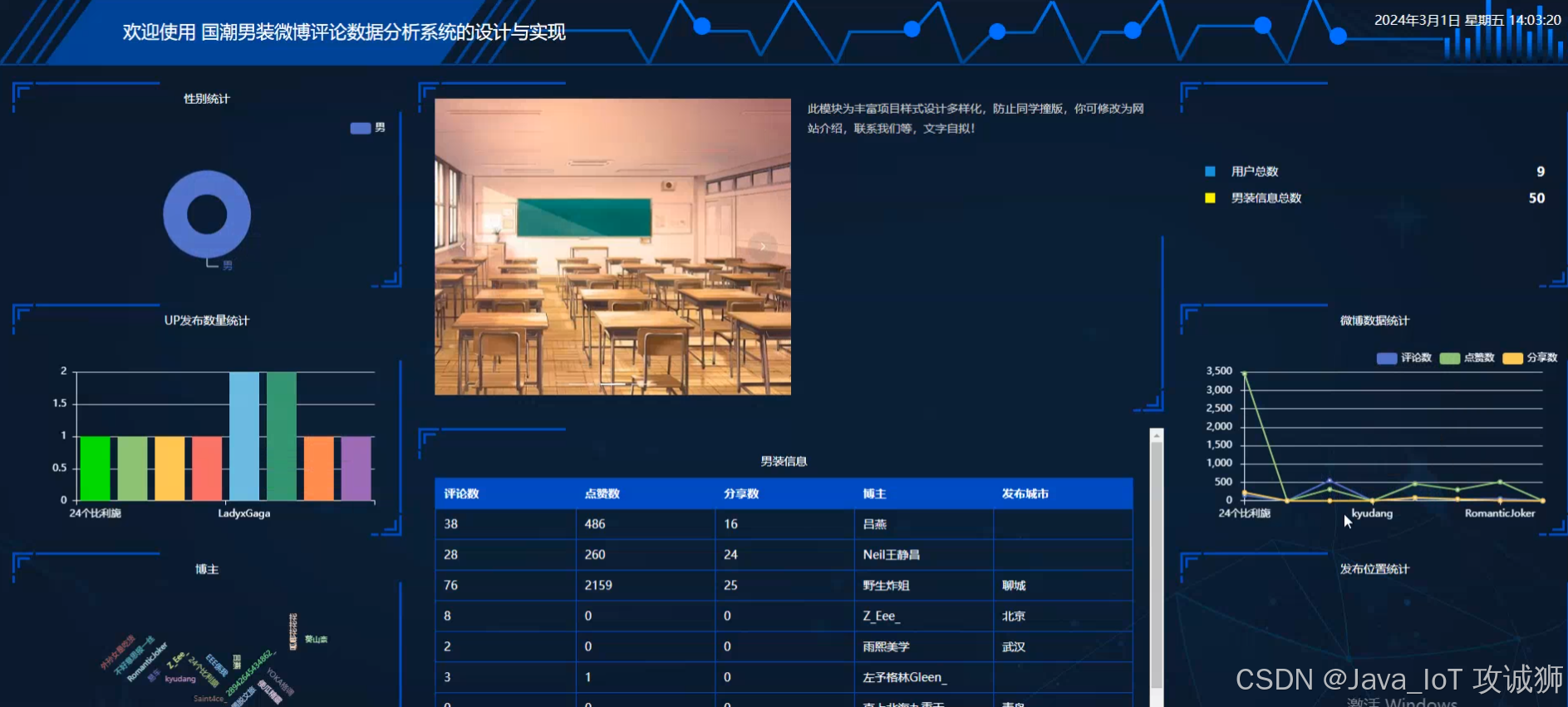
看板界面
摘要
国潮男装微博评论数据分析系统是一个在线平台,旨在为用户提供便捷的快捷预约服务。该系统分为管理员和用户两种角色。管理员可以管理用户管理、男装信息管理、系统管理、我的信息等功能。用户包括首页、男装信息、服装资讯、个人中心等选项。通过这个系统,用户可以方便地查看男装微博数据分析,而平台也能高效地管理业务,提升服务质量。
本文对国潮男装微博评论数据分析系统的需求分析、功能设计、系统设计进行了较为详尽的阐述,并对系统的整体设计进行了阐述,并对各功能的实现和主要功能进行了说明,并附上了相应的操作界面图。
研究背景
国潮男装在近年来逐渐兴起,成为时尚圈的热门话题。微博作为一个社交媒体平台,汇集了大量用户对国潮男装的评论和讨论。因此,设计与实现一个国潮男装微博评论数据分析系统具有重要的研究背景和意义。随着国潮男装的兴起,越来越多的人开始关注和购买国潮品牌的服饰。然而,对于这些品牌的评价和口碑信息分散在各种渠道上,很难进行综合分析和判断。通过对微博评论数据进行分析,可以获取用户对国潮男装的看法、喜好和需求,为品牌提供有价值的市场反馈。
关键技术
Python是解释型的脚本语言,在运行过程中,把程序转换为字节码和机器语言,说明性语言的程序在运行之前不必进行编译,而是一个专用的解释器,当被执行时,它都会被翻译,与之对应的还有编译性语言。
同时,这也是一种用于电脑编程的跨平台语言,这是一门将编译、交互和面向对象相结合的脚本语言(script language)。
Flask是一个使用Python编写的轻量级Web应用框架。它被称为一个"微框架"(microframework),因为它只提供Web应用所需的最核心的功能,如路由、会话管理和模板引擎等,而不像一些更全面的框架那样包含数据库层、表单处理等功能。然而,Flask的扩展生态系统非常丰富,开发者可以通过添加扩展来为Flask应用添加这些额外的功能。
Vue是一款流行的开源JavaScript框架,用于构建用户界面和单页面应用程序。Vue的核心库只关注视图层,易于上手并且可以与其他库或现有项目轻松整合。
MYSQL数据库运行速度快,安全性能也很高,而且对使用的平台没有任何的限制,所以被广泛应运到系统的开发中。MySQL是一个开源和多线程的关系管理数据库系统,MySQL是开放源代码的数据库,具有跨平台性。
B/S(浏览器/服务器)结构是目前主流的网络化的结构模式,它能够把系统核心功能集中在服务器上面,可以帮助系统开发人员简化操作,便于维护和使用。
系统分析
对系统的可行性分析以及对所有功能需求进行详细的分析,来查看该系统是否具有开发的可能。
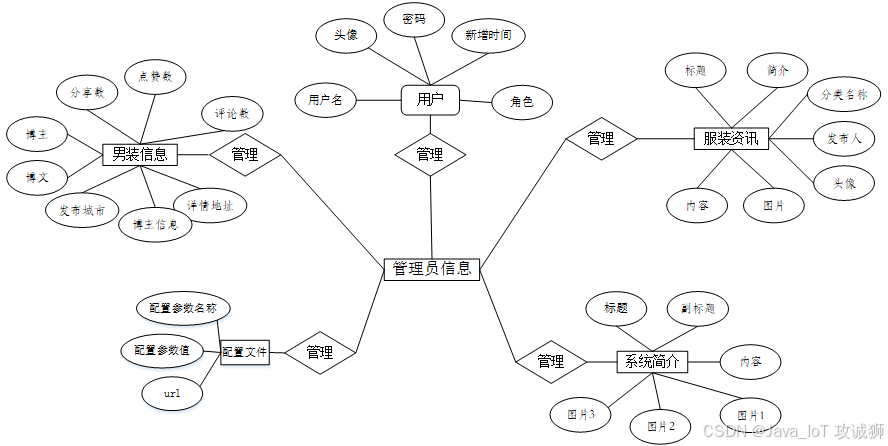
系统设计
功能模块设计和数据库设计这两部分内容都有专门的表格和图片表示。
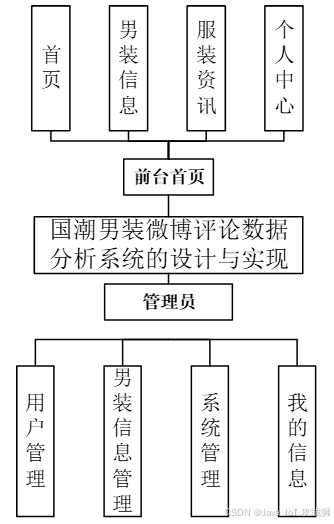
系统实现
当人们打开系统的网址后,首先看到的就是首页界面。在这里,人们能够看到系统的导航条,通过导航条导航进入各功能展示页面进行操作。管理员进入主页面,主要功能包括对用户管理、男装信息管理、系统管理、我的信息等进行操作。管理员进行爬取数据后,点击主页面右上角的看板,可以查看到性别统计、UP发布数量统计、博主、男装信息、用户总数、男装信息总数、微博数据统计、发布位置统计等实时的分析图进行可视化管理;
代码实现
python
# 男装信息
class NanzhuangxinxiSpider(scrapy.Spider):
name = 'nanzhuangxinxiSpider'
spiderUrl = 'https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E7%94%B7%E8%A3%85&_T_WM=72448699192&v_p=42&page_type=searchall&page={}'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
realtime = False
headers = {
'Referer':'https://m.weibo.cn/search?containerid=100103type%3D1%26q%3D%E7%94%B7%E8%A3%85&_T_WM=72448699192&v_p=42'
}
def __init__(self,realtime=False,*args, **kwargs):
super().__init__(*args, **kwargs)
self.realtime = realtime=='true'
def start_requests(self):
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'nlv96xz7_nanzhuangxinxi') == 1:
cursor.close()
connect.close()
self.temp_data()
return
pageNum = 1 + 1
for url in self.start_urls:
if '{}' in url:
for page in range(1, pageNum):
next_link = url.format(page)
yield scrapy.Request(
url=next_link,
headers=self.headers,
callback=self.parse
)
else:
yield scrapy.Request(
url=url,
headers=self.headers,
callback=self.parse
)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'nlv96xz7_nanzhuangxinxi') == 1:
cursor.close()
connect.close()
self.temp_data()
return
data = json.loads(response.body)
try:
list = data["data"]["cards"]
except:
pass
for item in list:
fields = NanzhuangxinxiItem()
try:
fields["author"] = emoji.demojize(self.remove_html(str( item["card_group"][0]["mblog"]["user"]["screen_name"] )))
except:
pass
try:
fields["text"] = emoji.demojize(self.remove_html(str( item["card_group"][0]["mblog"]["text"] )))
except:
pass
try:
fields["bozhuinfo"] = emoji.demojize(self.remove_html(str( item["card_group"][0]["mblog"]["user"]["description"] )))
except:
pass
try:
fields["comments"] = int( item["card_group"][0]["mblog"]["comments_count"])
except:
pass
try:
fields["attitudes"] = int( item["card_group"][0]["mblog"]["attitudes_count"])
except:
pass
try:
fields["reposts"] = int( item["card_group"][0]["mblog"]["reposts_count"])
except:
pass
try:
fields["city"] = emoji.demojize(self.remove_html(str( item["card_group"][0]["mblog"]["status_city"] )))
except:
pass
try:
fields["detailurl"] = emoji.demojize(self.remove_html(str( item["card_group"][0]["scheme"] )))
except:
pass
yield fields
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
return fields
# 数据清洗
def pandas_filter(self):
engine = create_engine('mysql+pymysql://root:123456@localhost/spidernlv96xz7?charset=UTF8MB4')
df = pd.read_sql('select * from nanzhuangxinxi limit 50', con = engine)
# 重复数据过滤
df.duplicated()
df.drop_duplicates()
#空数据过滤
df.isnull()
df.dropna()
# 填充空数据
df.fillna(value = '暂无')
# 异常值过滤
# 滤出 大于800 和 小于 100 的
a = np.random.randint(0, 1000, size = 200)
cond = (a<=800) & (a>=100)
a[cond]
# 过滤正态分布的异常值
b = np.random.randn(100000)
# 3σ过滤异常值,σ即是标准差
cond = np.abs(b) > 3 * 1
b[cond]
# 正态分布数据
df2 = pd.DataFrame(data = np.random.randn(10000,3))
# 3σ过滤异常值,σ即是标准差
cond = (df2 > 3*df2.std()).any(axis = 1)
# 不满⾜条件的⾏索引
index = df2[cond].index
# 根据⾏索引,进⾏数据删除
df2.drop(labels=index,axis = 0)
# 去除多余html标签
def remove_html(self, html):
if html == None:
return ''
pattern = re.compile(r'<[^>]+>', re.S)
return pattern.sub('', html).strip()
# 数据库连接
def db_connect(self):
type = self.settings.get('TYPE', 'mysql')
host = self.settings.get('HOST', 'localhost')
port = int(self.settings.get('PORT', 3306))
user = self.settings.get('USER', 'root')
password = self.settings.get('PASSWORD', '123456')
try:
database = self.databaseName
except:
database = self.settings.get('DATABASE', '')
if type == 'mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
# 断表是否存在
def table_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables = [cursor.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
# 数据缓存源
def temp_data(self):
connect = self.db_connect()
cursor = connect.cursor()
sql = '''
insert into `nanzhuangxinxi`(
id
,author
,text
,bozhuinfo
,comments
,attitudes
,reposts
,city
,detailurl
)
select
id
,author
,text
,bozhuinfo
,comments
,attitudes
,reposts
,city
,detailurl
from `nlv96xz7_nanzhuangxinxi`
where(not exists (select
id
,author
,text
,bozhuinfo
,comments
,attitudes
,reposts
,city
,detailurl
from `nanzhuangxinxi` where
`nanzhuangxinxi`.id=`nlv96xz7_nanzhuangxinxi`.id
))
order by rand()
limit 50;
'''
cursor.execute(sql)
connect.commit()
connect.close()系统测试
对一种产品进行检测,一种是对其性能的了解,另一种是对其进行性能检测,即对其进行性能检测,称之为"黑盒测试"。此方法被称作"白盒测试"。
软件测试的基础指导原则:一、所有的试验均应符合使用者的要求。二、在测试开始前,应制定测试方案。三、首先是"小规模"的试验,然后是"大规模"的,这是一种新的尝试。四、无法进行耗尽试验。五、应该通过一个独立的第三方执行试验以实现试验的结果。
在产品层次,系统的测试系统包括:系统层、子系统层、功能层、模块层。不同的测试对象在不同的测试阶段表现出不同的特点,以基本测验为主,组合测验次之。
为保证该系统的稳定运行,本系统进行了如下测试:一、菜单单项测试:通过添加、删除、修改等操作来保证菜单项的各项性能。二、数据追踪:数据采集完成后,将进行数据采集。例如:在国潮男装微博评论数据分析系统活动的处理上,我先设定了一个测验项目,再用一个加分模组对这个数据进行分析,同时观察两个模组之间的冲突,以确定它们之间的冲突程度,再用评分查询模块来验证这个功能是否正确,而其它的模块也是如此。三、综合测试:在以上测试的基础上,测试了该系统的各项性能。在国潮男装微博评论数据分析系统中,各个模块的功能都是通过黑盒测试来完成的。但是,存在着某些功能不能满足的问题。
结论
在软件系统的开发过程中,其中需求分析、模块设计、代码开发,都是非常关键的。为确保系统可以正常运行,我必须严格实施必要的软件开发过程,以达到节省开发成本的目的。如果漏下某个步骤,那么有可能在以后的运行中,将会造成巨大损失。通过这些方式,我可以更好地理解理论与实践之间的联系,也可以将教材中的理论运用到实践中去,从而加深对书籍的理解。虽然我花了很多的时间和精力,但我还是学到了很多,而且我在编程和认知方面也有了很大的提高。在未来的工作与生活中,我将以终身学习为宗旨,不断学习最新的编程技术,不断提高自身的专业能力,不断追求自身的价值。