软件开发七年,我清晰感知到,开发的工作模式已经彻底迭代。过去开发比拼的是手写代码速度、API 熟练度、技术记忆储备;而当下,真正拉开开发者差距的,是业务拆解思维、架构把控能力、AI 调度能力和复杂问题治理能力。
Cursor 是我目前日常开发的核心工具,但真正让我研发效率翻倍、代码质量稳步提升的,并非 AI 的自动编码能力,而是实战沉淀的一套标准化、可复用、高质量的 AI 辅助开发工作流。
和很多新手直接抛需求、让 AI 自由生成代码的粗放模式不同,我的开发逻辑始终闭环且可控:先拆解分析、再架构设计、后落地编码、最后迭代优化修 Bug。全程坚持人工主控、AI 辅助赋能,既规避了 AI 开发常见的架构混乱、业务跑偏问题,又最大化释放了 AI 的提效价值。
 下文详细分享我这套日常落地的五段式 Cursor 实战开发方法论。
下文详细分享我这套日常落地的五段式 Cursor 实战开发方法论。
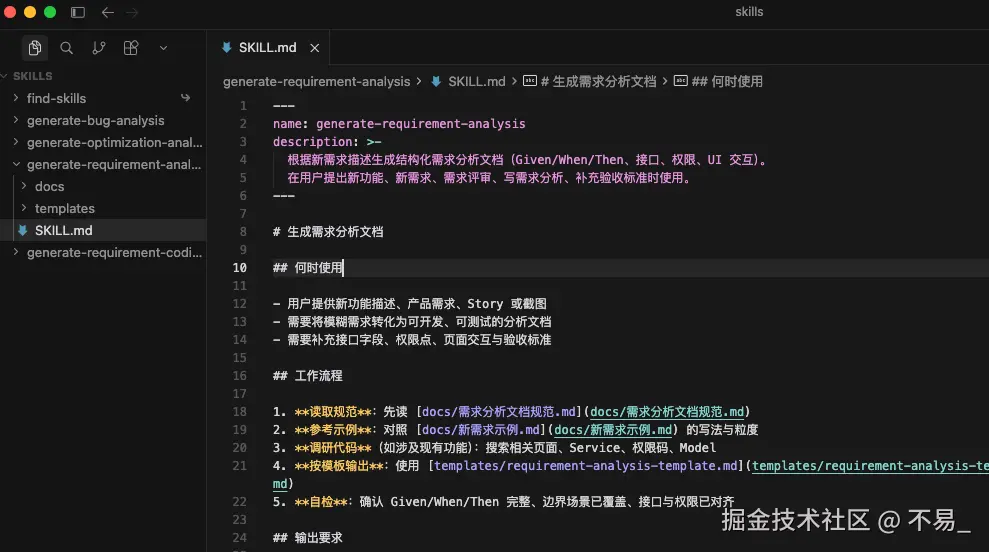
第一步:业务需求分析 Skill ------ 借 AI 吃透需求、拆解任务,从源头杜绝返工
开发过程中绝大多数的返工、逻辑漏洞、迭代卡顿,根源都是拿到需求就直接编码,没有理清业务流程、边界场景和隐性规则。如今我开启任何一个功能开发,第一步必然是需求拆解分析,借助 Cursor 的 Ask 模式把模糊的业务需求,转化为清晰可落地的开发任务。
我会将产品需求文档、交互原型、业务规则完整同步给 Cursor,依托 AI 完成三件核心工作:
1. 梳理完整闭环业务流程
让 AI 梳理出功能完整的用户操作链路、前置依赖条件、后置状态变更、各类分支场景。重点校验产品文档中未明确提及的异常场景、边界 Case,提前规避上线后出现的逻辑漏洞。
2. 模块化拆解开发任务
将大型复杂需求,拆解为页面结构搭建、接口联调、状态管理、交互逻辑、权限控制、异常兜底等独立子任务,做到任务拆分粒度均匀、职责清晰,避免单次开发逻辑过载。
3. 生成可落地开发 Plan
基于拆解后的任务,让 AI 输出有序的详细开发步骤,我再人工审核、微调顺序、删减冗余步骤、补充业务特殊规则。只有整套开发 Plan 完全确认无误,才会进入编码阶段。
核心价值:彻底解决「边写边想、越写越乱、中途返工」的问题,把模糊的业务需求固化为标准化、可执行的开发流程,从根源降低迭代成本。
第二步:代码架构设计 Skill ------ 先定架构结构,再落地业务代码
能否做好前置架构设计,是资深开发者和初级开发者的核心分水岭。新手开发习惯「边写边改、边改边凑」,而我始终坚持先设计、后落地,架构先行、细节后补的原则。需求完全吃透后,我不会立刻编写业务逻辑,而是借助 Cursor 完成局部架构设计与模块规划,筑牢代码根基:
1. 定制模块与目录拆分规则
结合当前业务的复杂度,界定组件拆分维度、通用逻辑抽离范围、业务 Hooks 沉淀场景,判断模块状态是局部维护还是全局托管,保证目录结构清晰、模块高内聚低耦合。
2. 优先定义数据结构与 TS 类型
坚持类型先行,让 AI 统一生成接口入参出参、表单结构、列表数据、业务枚举的完整 TS 类型定义。统一的类型规范,能彻底规避后续编码中字段错乱、参数不匹配、类型报错等问题。
3. 区分通用能力与业务能力
提前甄别可复用的 UI 组件、工具方法、通用逻辑,和专属业务逻辑做隔离,提前封装沉淀,避免后期代码堆砌、冗余重复。
4. 固化页面分层规范
严格遵循分层原则:视图层只负责 UI 渲染和用户交互触发,所有数据处理、业务判断、异步逻辑全部下沉,保证页面代码极致简洁。
核心原则:架构由我定义、规范由我把控、边界由我界定,AI 只负责落地细节,绝不参与架构决策和规则制定。
第三步:业务代码编写 Skill ------ AI 高效落地,人工严控质量
当前期需求拆解、架构设计、开发规划全部完成后,编码阶段会变得极度顺滑高效。我会基于已定的架构和 Plan,指挥 Cursor 分模块、小步迭代、循序渐进生成代码,全程可控、有序、高质量。
1. 先搭骨架,后补细节
优先让 AI 生成页面整体骨架、组件结构、Hooks 入口、接口基础封装,先打通整体项目架构链路,再逐步填充表单、弹窗、交互联动等细节逻辑,保证结构不跑偏。
2. 重复性工作全权交给 AI
对于 CRUD 页面、表格分页、搜索重置、表单校验、弹窗显隐、基础状态变更等高度模板化、重复性极强的代码,全部交由 AI 批量生成,彻底解放机械重复的编码工作。
3. 核心业务逻辑人工主导把控
涉及核心业务流程、权限校验、复杂数据联动、精准数据计算、关键边界判断的核心逻辑,我会亲自编写、审核、微调。AI 仅作为辅助工具,绝不全权依赖,从源头守住业务正确性。
4. 强制对齐项目编码规范
每次生成代码前,我都会明确带入项目的分层规则、命名规范、组件写法、Hooks 封装标准,确保 AI 输出的代码完全适配项目风格,和原有代码体系统一,不会出现风格割裂、规范混乱的问题。
核心认知:AI 负责编码产量和效率,我负责业务质量和架构底线;AI 负责模板落地,我负责业务价值落地。
第四步:改 Bug & 迭代优化 Skill ------ 智能排错、持续打磨高质量代码
代码开发完成只是功能落地,真正让项目稳定、易维护、可迭代,靠的是 Bug 修复和持续优化。在日常调试排错、代码重构、性能优化的场景中,Cursor 的赋能效果尤为明显。
1. 上下文联动精准排错
遇到报错无需逐行断点调试、翻阅文档,直接将报错信息 + 对应上下文代码同步给 AI,可快速精准定位语法错误、逻辑漏洞、渲染异常、异步时序、闭包遗留等各类问题。
2. 挖掘肉眼不可见的隐性 Bug
借助 AI 扫描代码隐患,提前发现人工容易忽略的重复请求、内存泄漏、定时器未销毁、无效重渲染、数据状态不同步等隐性问题,提前规避线上故障。
3. 无损重构与代码优化
针对臃肿冗余、耦合度高、可读性差的代码,我会让 AI 在不改动原有业务功能的前提下,完成逻辑精简、Hooks 抽离、通用封装、性能优化,让代码更整洁、更易维护、更利于后续迭代。
4. 小步迭代,持续沉淀项目资产
每一轮功能迭代结束后,都会让 AI 协助复盘代码,梳理可优化点、冗余逻辑、可复用能力,持续沉淀项目通用组件、工具方法和规范体系,不断降低项目维护成本。
第五步:精细化 Token 消耗治理(实战核心技巧)
长期使用 Cursor 开发,我发现多数开发者忽略了一个关键问题:AI 开发效率的上限,取决于上下文 Token 的精准管控。
无节制粘贴代码、全量投喂项目文件、超长对话不重置,只会造成大量无效 Token 消耗、模型压缩上下文、逻辑失真、响应变慢,反而拖慢开发节奏、增加使用成本。因此我在整套开发流程中,固化了一套轻量化、低消耗的 Token 管控方案。
为什么 Token 治理是独立一步?
前四步解决的是「做什么、怎么做、做得对不对」;Token 治理解决的是「用什么成本做」。它贯穿需求分析、架构设计、编码、排错全流程,但容易被混在 Bug 修复里一带而过。单独拎出来,是为了在每次对话前都做一次意识检查,避免「效率工具反而拖慢效率」。
1. 按需投喂,最小上下文原则
绝不把整个项目代码、完整路由、全局配置一次性发给模型。每次对话只上传:
| 场景 | 应投喂 | 应剔除 |
|---|---|---|
| 单文件开发 | 当前文件 + 直接依赖的类型/工具 | 无关页面、全局配置 |
| Bug 排查 | 报错栈 + 相关函数/组件 | 完整模块、历史对话冗余 |
| 架构讨论 | 目录结构摘要 + 关键接口定义 | 全部实现细节 |
复杂页面拆分开发,对应上下文也做拆分隔离,避免对话载荷过载。
2. 适时重置会话基线
单轮对话迭代超过 20 轮,或出现以下信号时,主动重置会话、新建对话继续开发:
- 模型开始重复输出、逻辑混乱
- 细节遗漏增多,需要反复纠正同一问题
- 上下文堆叠杂乱,难以追溯当前任务边界
相比拖着臃肿的上下文继续迭代,重置后的模型响应更快、准确率更高,整体 Token 消耗反而更低。
3. 区分模型能力,按需选型控耗
| 任务类型 | 推荐策略 |
|---|---|
| 代码补全、格式调整、文案修改 | 轻量化模型 |
| 基础 Bug 修复、简单重构 | 中等能力模型 |
| 复杂架构设计、长代码重构、业务逻辑复盘 | 高阶模型 |
杜绝大模型做小事的资源浪费,精准平衡开发精度和 Token 消耗成本。
4. 标准化提示词,精简冗余
摒弃冗长无效的描述话术,固定简洁、精准的指令范式:
【任务】一句话说明要做什么
【约束】项目规范、不可改动范围
【上下文】仅附必要代码/报错
【期望输出】格式、粒度、验收标准只传递核心需求、项目规范、约束条件,减少提示词本身的 Token 占用,让每一次模型调用都高效、有用、不浪费。
5. 如何合理使用 Token:成本结构与实战策略
先理解 Token 花在哪里,再谈怎么省。一次 Cursor 对话的总消耗 ≈ 系统提示 + 项目 Rules/Skills + 对话历史 + 当前输入(@ 引用 / 粘贴代码 / 提示词)+ 模型输出。其中前三项往往被忽略,却是「越聊越慢、越聊越贵」的主因。
| 消耗来源 | 典型场景 | 治理思路 |
|---|---|---|
| 对话历史 | 同一窗口反复改 Bug、多轮纠偏 | 任务切换时新建对话,携带精简摘要而非整段历史 |
| @ 引用范围 | @Codebase、整目录、大文件全量引入 |
收窄到单文件、单函数,或只贴相关行段 |
| 重复投喂 | 每轮再把同一规范、同一报错栈粘贴一遍 | 规范写入 Rules/Skill,报错只增量补充变化部分 |
| 模型档位 | 改个变量名也开高阶模型 | 按任务复杂度选型,简单任务降档 |
| 无效输出 | 要求「全面分析整个项目」 | 限定输出范围:改哪些文件、验收标准是什么 |
核心判断 :不是上下文越大 AI 越聪明,而是与当前任务相关的信号密度越高,输出才越准。无效 Token 会挤占有效上下文,触发压缩后模型「遗忘」早期约束,表现为重复犯错、风格漂移、响应变慢。
5.1 缩小上下文:只给「决策所需的最小信息集」
- 能定位就不全量:修某个 Hook,只给 Hook 文件 + 调用它的组件片段,不必附带整页 JSX。
- 能摘要就不原文 :讨论目录结构,用
tree摘要或文字描述模块职责,而不是@整个src/。 - 能拆分就不混聊:一个对话只做一个子任务(例如「表单校验」和「列表分页」分开),避免上下文互相污染。
- 先描述再引用 :用一句话说明业务意图和约束,再
@具体文件,比直接丢文件更高效。
5.2 优先用 @ 引用,替代手动粘贴整文件
| 方式 | 适用 | 注意 |
|---|---|---|
@文件名 |
改动集中在单文件 | 大文件可配合行号范围或选中片段 |
@文件夹/ |
需要了解模块边界 | 避免一次 @ 过深、过大的目录 |
@Codebase |
不确定代码在哪 | 问题要具体,否则检索范围大、消耗高 |
| Rules / Skill | 重复出现的规范、流程 | 一次配置,多轮复用,比每轮粘贴省 Token |
手动粘贴整文件适合「临时、一次性、无仓库索引」的场景;日常开发优先 @,让 Cursor 按需拉取,通常比整文件塞进对话更省、也更易维护。
5.3 会话重置:不是浪费,而是降本增效
出现以下任一情况,新建对话 + 3~5 行任务摘要 往往比继续硬聊更划算:
- 同一问题已纠正 2 次以上 仍反复出现
- 对话轮次 > 20,或已横跨多个无关子任务
- 模型开始「复述已知信息」而非推进任务
- 你需要切换模型档位(例如从架构讨论切到单行修复)
重置时携带的摘要示例:
markdown
【背景】用户列表页分页接口字段从 page 改为 pageNum
【已完成】types 已更新,Table 组件待改
【本次目标】只改 src/pages/User/List.tsx 的分页参数映射
【约束】不改动接口层与其他页面5.4 模型选型:精度与成本的平衡点
- 低档位:补全、格式化、改文案、改类型名、简单语法错误
- 中档位:局部 Bug、单文件重构、常规 CRUD 生成
- 高档位:跨模块架构、复杂状态机、长链路排错、需求/方案复盘
原则:先低后高。涵盖 DeepSeek-V4 (Pro/Flash)、GPT系列 (5.3/5.4/5.5)、Claude (Opus 4.7/Sonnet 4.6)、Gemini 3.1 Pro、豆包及 Qwen等,多采用组合使用的策略低档模型一轮能解决,就不要默认开高档;高档模型一轮搞不定,先缩小上下文或拆任务,而不是继续堆对话长度。
5.5 提示词:短、准、可验收
同样一件事,Token 占用和成功率差很多:
markdown
❌ 低效(冗长、边界不清)
请帮我看看这个页面,感觉哪里不太对,顺便优化一下性能,
再把相关代码都检查一下,尽量写好一点。
✅ 高效(任务 + 约束 + 验收)
【任务】修复 UserList 切换页码后请求参数仍为 page=1 的问题
【上下文】@src/pages/User/List.tsx @src/api/user.ts
【约束】仅改分页参数映射,不动 UI 与接口定义
【验收】切到第 2 页时 network 请求 pageNum=2快捷自检(复制即用):
markdown
- [ ] 1. 上下文最小化:本次只引用了完成任务所需的文件/片段
- [ ] 2. 引用方式:优先 @ 引用,未整文件粘贴
- [ ] 3. 会话状态:无多轮纠偏/跨任务混杂,必要时已新建对话并附摘要
- [ ] 4. 模型档位:任务复杂度与所选模型匹配
- [ ] 5. 提示词质量:已写明任务、约束、验收标准,无空泛描述核心价值:用最小的资源消耗,换取最高质量的 AI 输出,避免模型能力衰减,同时降低开发成本、提升整体迭代效率。
结语:AI 是工具,人才是架构与业务价值的核心决策者
长期使用 AI 辅助开发,我最深的感悟是:AI 不会替代开发者,只会替代不会合理使用 AI 的开发者。 架构的价值,从来不是追逐新潮技术、堆砌复杂方案;真正好用、能落地、长期稳定的架构,永远是深度贴合业务、易于维护、迭代高效,且适配团队协作模式的架构。
一名软件开发工程师的成长,本质是认知与角色的持续升级------从单纯执行任务的编码者,逐步成长为项目的治理者、业务的赋能者、团队效率的推动者。我们提笔写代码,从来不是为了产出代码本身,而是依托技术,实实在在解决业务和客户的真实问题。AI 解放了开发者重复劳作的双手,让我们得以跳出琐碎编码,专注于架构设计、业务落地、价值创造------这也是新时代技术开发者最大的核心优势。
前端不易~