我最近在测试 GPT API 渠道的时候,遇到一个挺别扭的问题。
页面上写的是 GPT-5.5 ,接口也能正常返回内容。
刚开始我也没觉得有什么问题,毕竟它能回答、能写代码、能总结,看起来都挺正常。
但用了一段时间后,我开始感觉不太对。
同一组 prompt,我拿到官方线路和某些中转线路里分别跑了一遍,结果差异很明显。有些线路不是"效果差一点",而是整个模型行为都开始变了。
比如:
- 长文本总结会漏重点;
- JSON 输出突然不稳定;
- function calling 参数经常缺字段;
- 代码解释变得很浅;
- 复杂任务里推理不连贯;
- 同一个 prompt 多跑几次,结果差异很大。
最麻烦的是,简单测试很难发现问题。
比如你随便问它:
帮我写一段文案或者:
解释一下这段代码再或者:
sql
写一个 SQL它大概率都能回答,而且看起来还不错。
但问题就在这里:
能回答,不代表它就是你以为的那个 GPT。
现在的问题,不是 GPT 强不强
以前大家聊 GPT,通常会问:
- GPT 和 Claude 哪个强?
- GPT-5.5 和 GPT-5.4 差多少?
- 哪个模型写代码更好?
- 哪个模型更便宜?
但如果你是通过 API 渠道调用 GPT,现在可能要先问另一个问题:
我现在用到的,到底是不是原版 GPT?
这句话听起来有点夸张,但实际用下来,确实是个问题。
现在 GPT 的调用来源已经很复杂了:
- 官方 API;
- 云厂商;
- 聚合平台;
- 中转线路;
- 共享池;
- 转发接口;
- OpenAI 兼容接口;
- 二次封装接口。
用户看到的名字可能都一样:
- GPT-5.5
- GPT-5.4
- GPT 系列模型
- OpenAI 兼容接口
但名字一样,不代表背后的能力一样。
有些是官方能力接入;
有些只是接口格式兼容;
有些做了二次封装;
还有一些线路为了控制成本,可能会限制上下文、改参数、关掉部分能力,甚至在高峰期切换线路。
所以你看到页面上写着 GPT,不代表复杂任务里的表现就一定和官方一致。
为什么简单问几句测不出来?
因为简单任务太容易"糊过去"了。
比如:
帮我写一段小红书文案
帮我总结一下这篇文章
sql
帮我写一个 SQL这类任务很多模型都能做。
就算线路有问题,它也能给你一段看起来还可以的答案。
这就会给人一种错觉:好像它是真的。
但 API 真正容易出问题的地方,通常不在普通聊天,而在复杂任务里。
比如:
- 处理长文档;
- 严格按照 JSON schema 输出;
- function calling 参数生成;
- 多轮对话里保持上下文约束;
- 根据一堆条件写代码、改 bug、解释原因;
- 在 Agent 流程里连续执行多个步骤。
这些场景才是真正容易拉开差异的地方。
很多线路简单问答看不出来,一到复杂场景就开始露馅。
我是怎么判断一条 GPT 线路是否靠谱的?
这个事情不能只靠感觉。
"我觉得不像 GPT"没有太大说服力。
如果要测,至少要有一个对照组。
我一般会这么做:
- 同一组 prompt,先用官方 GPT 跑一遍;
- 把官方结果作为参考;
- 再拿同样的 prompt 去跑不同渠道;
- 参数尽量保持一致,比如 temperature、max tokens、上下文长度;
- 最后不只看它有没有回答,而是看它稳不稳、能力有没有缺、行为和官方差多少。
重点不是测一次,而是反复测。
因为有些线路第一次结果还可以,连续跑几次之后,问题就出来了。
1. 先测模型行为是否稳定
GPT 本身是有一些比较明显的输出习惯的。
尤其是在这些任务里:
- 表格整理;
- 代码生成;
- JSON 输出;
- 指令跟随;
- 工具调用;
- 长文本总结。
它通常会比较稳。
可以用这种 prompt 测一下:
javascript
请严格按照以下 JSON 格式输出,不要添加任何解释:
{
"title": "",
"summary": "",
"risk": "",
"reason": "",
"score": 0
}然后连续跑几次,看输出是否稳定。
如果出现下面这些情况,就要注意了:
- 前面加了一大段解释;
- JSON 里出现注释;
- 字段名被改掉;
- 字段缺失;
- 格式不闭合;
- 同一个 prompt 多次结果差异很大。
这些问题在聊天时可能不明显。
但一旦接进业务系统,就很麻烦。
因为 JSON 少一个字段,后面的流程可能就直接失败了。
2. 再测长文本总结能力
简单总结很难看出问题。
真正要测,最好拿一篇长一点的内容,比如产品文档、会议纪要、接口说明、业务规则,让模型做结构化总结。
可以这样测:
markdown
请阅读下面这段长文本,并按以下结构总结:
1. 核心结论
2. 关键规则
3. 风险点
4. 待确认问题
5. 可以落地的执行动作
要求:
- 不要遗漏关键条件
- 不要自己编造
- 保留原文中的限制条件这类任务很容易看出模型是不是"只会表层总结"。
有些线路表面上也能总结,但会出现:
- 漏掉关键条件;
- 把不确定内容说成确定;
- 忽略限制条件;
- 只做表层概括;
- 多轮追问后前后不一致。
如果只是拿它写短文案,可能感觉不到差异。
但如果你拿它处理业务文档,问题就会很明显。
3. 重点测 JSON 和 function calling
很多人用 GPT API,不是为了聊天,而是接进系统里做结构化任务。
比如:
- 信息抽取;
- 表单解析;
- 客服工单分类;
- Agent 工具调用;
- 函数参数生成;
- 代码生成和自动修复。
这些场景里,最重要的不是它会不会说话,而是它能不能稳定输出。
可以设计一个简单的 function calling 测试:
css
{
"name": "create_ticket",
"description": "创建一个客服工单",
"parameters": {
"type": "object",
"properties": {
"title": {
"type": "string"
},
"priority": {
"type": "string",
"enum": ["low", "medium", "high"]
},
"category": {
"type": "string"
},
"summary": {
"type": "string"
}
},
"required": ["title", "priority", "category", "summary"]
}
}然后给它一段用户问题,看它能不能稳定生成参数。
重点看这些地方:
- required 字段有没有缺;
- 类型有没有错;
- enum 值有没有乱写;
- category 是否稳定;
- summary 是否准确;
- 多跑几次结果是否一致。
很多线路最容易在这里暴露问题。
简单聊天看不出来,但一旦接进系统,字段缺失、类型错误、参数乱改,都会变成真实 bug。
4. 测多轮任务能不能保持约束
还有一个很重要的点:多轮对话。
很多模型单轮回答还可以,但一进入多轮任务,就开始忘规则。
比如你第一轮告诉它:
css
接下来你只能输出 JSON,不要输出解释。
字段只能包含 title、summary、risk。第二轮让它处理内容。
第三轮再补充限制条件。
第四轮让它重新生成。
这时候可以观察:
- 它是否还记得只能输出 JSON;
- 是否新增了多余字段;
- 是否忘记前面的限制;
- 是否能根据新条件修正结果。
多轮约束保持能力,对于 Agent、工作流、自动化系统都很关键。
如果线路在这里不稳,后面接业务会非常痛苦。
单靠手动测试,还是太慢
上面这些方法,只能算快速判断。
它能帮你发现:
这条线路好像不太对。
但很难 100% 证明它到底是不是官方 GPT。
因为影响结果的因素很多:
- 模型参数;
- 系统提示词;
- 上下文长度;
- temperature;
- max tokens;
- 线路负载;
- 平台是否做了封装;
- 是否有隐藏限制;
- 高峰期是否切线路。
所以更靠谱的方式,还是把不同线路放到同一套标准下测试。
比如统一测试:
- 同一组 prompt;
- 同一篇长文本;
- 同一个 JSON 任务;
- 同一个 function calling 场景;
- 同一个多轮对话任务;
- 同一组代码生成任务;
- 同一个上下文长度压力测试。
我后来把线路放到统一维度里测了一遍,结果会比自己凭感觉判断清楚很多。
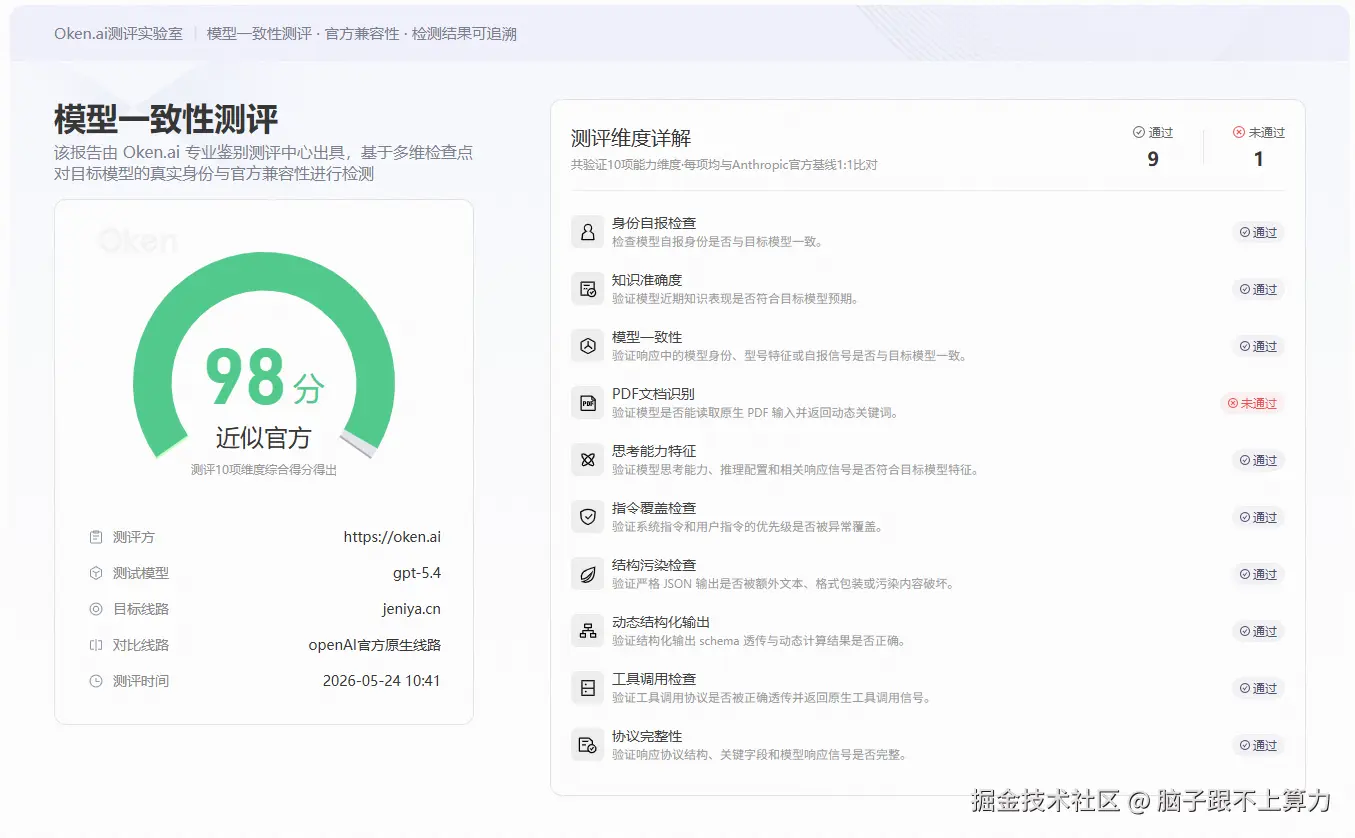
这类测试至少能看出几个问题:
- 模型身份是否和目标模型一致;
- 知识表现是否符合预期;
- 结构化输出是否稳定;
- 工具调用是否正常;
- 协议响应是否完整;
- 是否存在能力缺失。
说白了,不能只看它"能不能答"。
还要看它在关键能力上,和官方基线到底差多少。
价格只是第一层,稳定性才是后面的坑
以前我看 API 渠道,第一反应也是看价格。
哪个便宜,哪个就有优势。
但测试多了之后,我会更倾向于把价格和可用性放在一起看。
因为 API 一旦接进业务系统,问题就不只是"贵不贵",而是:
- 返回结果稳不稳;
- 结构化输出能不能用;
- 高峰期会不会切线路;
- 上下文长度有没有缩水;
- token 消耗有没有异常;
- 出问题之后能不能追溯;
- 平台有没有把限制说清楚。
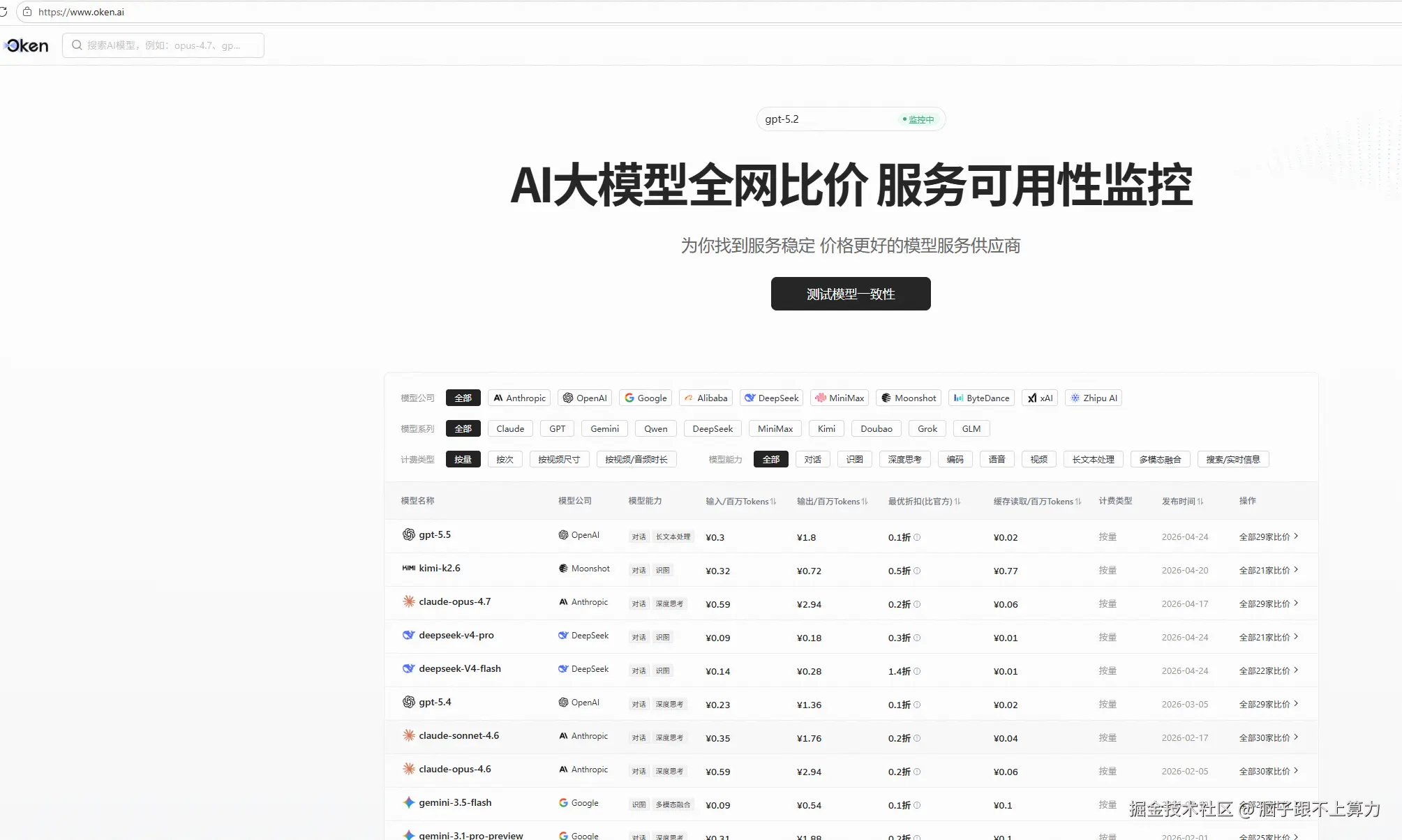
所以现在我看一个 API 渠道,不会只看模型名字和单价。
便宜当然重要。
但如果便宜的代价是模型不稳定、能力不完整、排查成本变高,那最后不一定真的省钱。
最后
我们能接受 GPT 贵,因为它确实强,也确实稳定。
但最怕的是:
我以为自己买的是 GPT,实际用到的能力却不完整。
以前大家比 API,主要看价格。
谁便宜,谁就有优势。
但现在只看价格已经不够了。
尤其是 GPT 这类模型,如果你是用 API 接进真实业务,就不能只看页面上写了什么模型名字。
还要看:
- 模型一致性怎么样;
- 长上下文稳不稳;
- JSON 输出稳不稳;
- function calling 能不能正常用;
- token 消耗有没有异常;
- 高峰期会不会切线路;
- 平台有没有把限制说清楚。
模型名字写成 GPT 很容易。
接口做成 OpenAI 兼容也不难。
真正要看的,是它跑出来到底是不是你以为的那个 GPT。
如果只是个人聊天,影响可能不大。
但如果是接进产品、Agent、客服系统、内容系统、代码工具里,那就一定要认真测一下。
因为真正贵的,可能不是 API 单价。
而是你上线后才发现:
模型不稳、能力缺失、结果不可控,最后所有问题都要你自己排查。