概述
过去两年,几乎所有玩过大模型的人,都绕不开两个词:Prompt 和 Agent 。但 2025 年开始,一个新词快速占领技术圈与 AI 圈的视野 ------ Claude Skills / Agent Skills。
很多人已经听说过 Skills,却并没真正搞清楚三个关键问题:
-
Skills 和 Prompt 的本质区别是什么?
-
Claude Skills 为什么会在 2025 年突然爆火?
-
对普通开发者和职场人来说,具体能带来什么改变?
接下来我将试图从工程实践视角,把这件事讲清楚:
从 "会写 Prompt 的高级用户" ,到 "会运营 Claude Skills 的协作架构师",中间到底差了什么台阶。
一、Claude Skills 到底是什么?不是"更长的 Prompt"
1.1 直觉理解
如果只能用一句话总结:Claude Skills,是能被反复调用、自动触发、真正 "干活" 的 AI 能力模块。
换句话说,Skills 做的事情,是把你一次性对话里的"灵光一现",沉淀成可复用的长期资产。
在日常使用中,很多人遇到的问题是这样的:
-
每次都要从头向 Claude 描述同一类需求
-
稍微复杂一点就需要反复改提示词、改示例
-
整个工作流高度依赖"当下怎么临时发挥"
Prompt 在这种场景里,更像一次性的即时指令。 而 Skill 的定位,是一个 被命名的能力单元,可以被多轮对话、多个项目反复调用。
一个常用的比喻是:
Prompt = 临时指令 Skill = 固定技能 Claude = 带技能树的智能体
从架构视角看,一个 Skill 至少包含三层含义:
-
能力边界:这个 Skill 负责解决哪一类问题?不做什么?
-
输入输出约定:接收什么输入(文本 / 结构化数据),产出什么格式的结果。
-
触发策略:什么时候该用它、什么时候不该用,是否可以自动被 Agent 决策调用。
这也是为什么很多人第一次真正用上 Skills 之后,会有一种很直观的感觉: "同一个 Claude,怎么突然变得像一个真正的协作同事了?"
1.2 一个 Skill 长什么样?技术解剖
光说概念容易虚,我们直接看一个真实的 Skill 文件结构。
Claude Code 的 Skill 本质上是一个 Markdown 文件 ,通常存放在 ~/.claude/skills/(全局)或项目目录下的 .claude/skills/(项目级)。每个 Skill 文件大致包含两个部分:
① YAML 元数据头(Frontmatter) :声明这个 Skill 的名称、描述、触发条件和所需工具。② 指令正文(Body):这才是真正的"能力定义"------告诉 Claude 在被调用时该做什么、怎么做、输出什么格式。
以一个"Git Commit 生成器"为例:
go
---
name: commit
description: 分析当前暂存区变更,自动生成符合规范的 git commit message
trigger: 当用户说"提交代码"、"帮我 commit"、"生成 commit message" 时触发
tools:
- Bash
- Read
---
你是一个 git commit message 生成专家。请:
1. 使用 Bash 工具执行 `git diff --staged` 获取暂存区变更
2. 分析变更内容,识别变更类型(feat / fix / refactor / docs 等)
3. 按照 Conventional Commits 规范生成 commit message
4. 生成格式:`<type>(<scope>): <subject>`
约束:
- subject 不超过 72 字符
- 如有必要,附加 body 说明变更动机
- 不要猜测 scope,从文件路径中推断注意几个关键设计点:
-
trigger字段定义了 自动调用时机 ,Claude 可以在用户无需手动/commit的情况下主动触发 -
tools字段限制了这个 Skill 能使用的工具集,形成 权限边界 -
正文是结构化的指令,而不是模糊的"帮我写提交信息"
这就是 Skills 和普通 Prompt 最根本的区别:Skills 是被工程化管理的能力单元,而 Prompt 只是一次性的对话输入。
二、Prompt、Skills、MCP:三者的边界在哪里?
这是很多技术人会困惑的问题。2024--2025 年间,AI 工程领域同时涌现了三个重要概念:Prompt Engineering、Agent Skills、MCP(Model Context Protocol)。它们的边界是什么?能力范围是否重叠?
| 维度 | Prompt | Skills | MCP |
|---|---|---|---|
| 本质 | 一次性的文本指令 | 可复用的能力模块 | 标准化的工具/数据接入协议 |
| 生命周期 | 单次对话 | 长期可复用 | 持久注册 |
| 触发方式 | 用户手动输入 | 手动调用 / 自动触发 | 模型决策调用工具 |
| 携带上下文 | 否(每次重新描述) | 是(能力定义持久化) | 工具描述持久化 |
| 适合场景 | 临时任务、一次性需求 | 高频任务、有固定流程的工作 | 需要外接数据源或执行系统操作 |
| 代表例子 | "帮我润色这段文案" | /commit 、/code-review |
连接数据库、查询 API、读取文件系统 |
一句话版本:
Prompt 决定"这次对话能做什么";Skills 决定"Claude 长期会什么";MCP 决定"Claude 能访问哪些外部资源"。
三者并不互斥,实际上是分层叠加的关系:
go
MCP(外部能力接入层)
↓
Skills(能力封装复用层)
↓
Prompt(单次指令执行层)在一个成熟的 AI 工作流里,三者往往同时出现:
-
用户通过 Prompt 描述目标
-
Skill 提供结构化的执行框架
-
MCP 赋予 Claude 操作数据库、调用 API 的能力
理解了这个分层,就不会纠结于"该用 Prompt 还是 Skill"的选择困难------不同层次的工具,解决不同层次的问题。
三、为什么 Claude Skills 会在 2025 年突然爆火?
从时间线上看,Skills 的出现并不是偶然事件,而是一个趋势的临界点:AI 正在从"陪你聊天",变成"替你完成任务"。
3.1 三个条件同时成熟
过去几年主流使用方式是:人来拆解任务,AI 负责给出点子、写代码、润色文案,每一步如何执行主要靠人来设计、决定和衔接。
而到了 2025 年,这种分工在几个方面出现了质变:
① 模型的工具调用能力显著成熟Claude 已经能做更可靠的"该不该用工具 / 用哪个工具"的决策,而不是像早期一样频繁误触发或漏触发。这是 Skill 自动触发的基础。
② Agent 架构从单轮走向多步从 Claude 3 系列开始,模型在多步任务执行上的稳定性大幅提升。Skill 作为多步任务的封装单元,此时变得"可用"而不只是"可想象"。
③ 生态形成了正反馈循环官方与社区围绕 Skills 形成了类似"插件市场"的生态------有人写,有人用,有人维护,有人迭代。这三个条件叠加,意味着 Skills 已经从"PPT 概念",变成"有人在生产环境天天用的东西"。
3.2 企业侧:从个人工具到组织基础设施
更值得关注的变化发生在企业侧。
2025 年开始,一些数字化程度较高的互联网公司开始把 Skills 纳入团队基础设施建设:
-
数据团队把 SQL 审查、数仓建模规范封装成 Skills,新人入职第一天就能用上团队沉淀的"最佳实践"
-
工程团队把代码 Review 标准、API 文档生成规范封装成 Skills,统一了 AI 辅助编码的输出质量
-
产品团队把竞品分析框架、需求拆解方法论封装成 Skills,让每个 PM 都能复用团队最优秀的分析思路
这个趋势意味着:Skills 已经不只是个人效率工具,而是在成为组织 AI 能力建设的基础设施。
连主打代码场景的 Qwen Code 也已经官宣支持 Skills 体系,这进一步验证了这一方向的可行性。
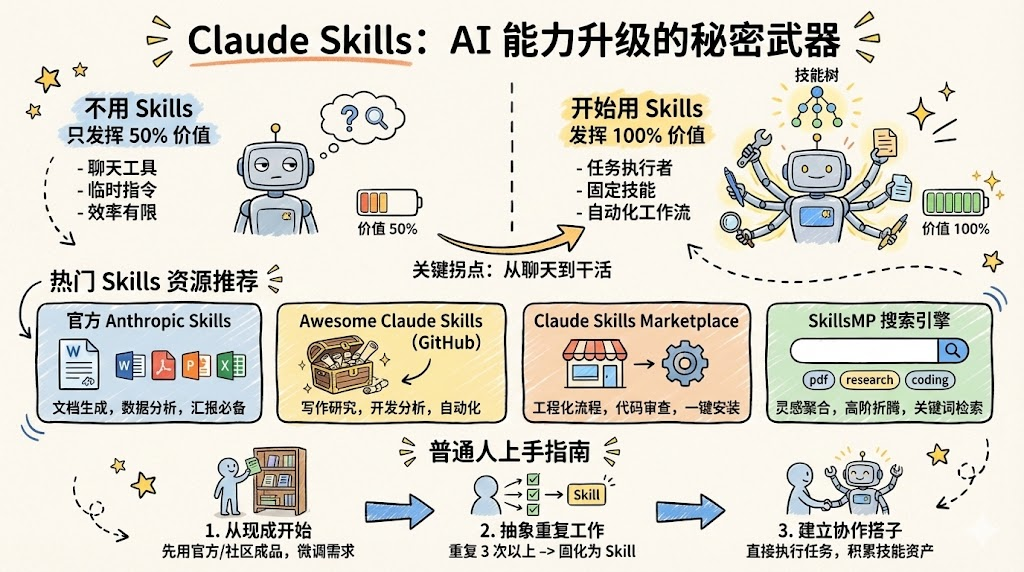
四、官方与社区:那几套"装上就能提升效率"的 Claude Skills
如果把 Skills 比作"能力插件",那眼下最实用的一批,其实已经有人帮你精选好了。
下面按照装上后的直接生产力收益,梳理几类值得优先关注的 Skills 资源。
4.1 Anthropic 官方 Skills 仓库:文档工作者的刚需工具箱
官方 Skills 仓库可以理解为 Claude 的"官方技能树",由 Anthropic 自己维护,质量和稳定性都比较有保障。
核心能力覆盖了绝大多数知识工作者的日常场景:
-
Word(DOCX)自动生成与编辑:写方案、写合同、写总结报告
-
PDF 解析、合并、结构抽取:从长文档里抓关键内容、抽表格、提纲要点
-
PPT 自动生成汇报稿:根据输入内容自动形成结构清晰的汇报文档
-
Excel(XLSX)数据处理与分析:做数据清洗、简单统计与分析说明
如果你的工作大量包含"写文档 + 做汇报 + 看资料",那么官方 Skills 基本是装了就见效的一类选择。 对应仓库地址为:https://github.com/anthropics/skills。
4.2 Awesome Claude Skills:社区维护的导航站
除了官方仓库,社区里也出现了多个"Skills 导航站",其中最典型的就是 Awesome Claude Skills 系列仓库。
它们的用途非常明确:帮你在海量 Skills 里快速定位"别人已经踩过坑的好用技能"。
当前两个质量较高的清单是:
里面按照场景整理了多种类型的 Skills:
-
写作 / 研究:论文阅读、文献总结、结构化写作
-
开发 / 代码分析:代码解释、接口梳理、单元测试生成
-
自动化工作流:流程拆解、任务编排、批处理操作
-
内容整理 / 知识管理:笔记清洗、结构化知识库构建
这类资源特别适合这样一类人:已经知道自己想用 Skills 做什么,但不想从 0 开始造轮子,只想"先抄一份能用的作业再改造"。
4.3 Claude Skills Marketplace:最接近"插件市场"的形态
如果说官方仓库更偏"基础能力组件",Awesome 列表更像"目录索引",那 Claude Skills Marketplace 则是一个"装完就能跑流程"的工作流合集。
它的特点是:
-
提供工程化的工作流,而不仅仅是一个个单点技能
-
可以一键安装你需要的整套流程,比如"工程开发 + 任务拆解 + 自动代码 Review"等
-
支持命令行形式的快速安装,例如:
go
/plugin marketplace add mhattingpete/claude-skills-marketplace/engineering-workflow-plugin仓库地址为:https://github.com/mhattingpete/claude-skills-marketplace。
适合人群非常清晰:程序员、技术负责人,已经在用 AI 辅助项目开发、希望进一步自动化流程的实践派工程师。
4.4 SkillsMP:面向 Skills 的"搜索引擎"
当 Skills 数量越来越多,仅靠 GitHub 搜索就显得有点粗糙。于是出现了一个专门的聚合站:SkillsMP。
访问 https://skillsmp.com/,你可以像逛市场一样搜索和筛选 Skills:
-
支持直接用关键词检索,比如
pdf、research、automation、coding等 -
聚合了不同作者、不同仓库的 Skill,实现统一入口
-
更适合"我大概知道方向,但还想多看看别人都在做什么"的探索型场景
这类工具,特别适合那些喜欢折腾、希望搭建自己自动化工作流的人。
五、从聊天工具到执行者:Claude Skills 带来的使用方式跃迁
很多人在用 Claude 一段时间后,都会产生这种体验的落差: "模型不差,但总觉得没真正帮我省多少事。"
一个重要的观点是:差距不在于模型,而在于使用方式。
5.1 不用 Skills 的 Claude:高级聊天工具
在完全不使用 Skills 的模式下,Claude 的定位大致是这样的:
-
更聪明的问答助手
-
能写代码、能写文案、能写方案
-
但每一次合作,都是从零开始重新"磨合"
这会导致几个结果:
-
能力高度依赖当次 Prompt 的质量与上下文
-
同一类工作在不同项目之间几乎不具备"记忆性"
-
整体工作流的自动化程度很有限,更多是"人想好了,再交给 Claude 去做"
5.2 用上 Skills 的 Claude:任务执行者与协作伙伴
一旦把 Skills 引入进来,角色关系会发生明显变化:
-
Claude 不再只是"回答问题",而是被赋予了"调用技能完成任务"的责任
-
能力模块变得可复用、可叠加,形成自己的"技能树"
-
工作流开始出现可重复的自动化路径,而不是完全依赖临场发挥
两种模式下的具体差异,可以用一个数据工程场景来感受:
| 工作场景 | 无 Skills | 有 Skills |
|---|---|---|
| SQL 代码 Review | 每次粘贴代码 + 手动描述评审标准 | /code-review 自动应用团队规范 |
| 写周报 | 每次重新说明格式、风格、受众 | /weekly-report 直接生成目标格式 |
| 查表结构 | 手动查文档或粘贴 DDL | Skill 自动连接元数据系统返回结构 |
| 分析报警 | 粘贴报警信息 + 描述分析框架 | /oncall 自动匹配排查 SOP |
简单来说,从"不用 Skills"到"运用 Skills",实际上是在做这件事:把你和 Claude 之间的关系,从一次性的问答,升级成长期的协作系统。
六、普通人 / 开发者如何开始用 Claude Skills?一个可落地的三步法
对于很多刚接触 Skills 的用户来说,最大的门槛往往不在技术,而在心理: "听起来很厉害,但我一时半会儿也不知道从哪儿下手。"
务实的建议是:先不要急着自己写,从用好别人写的开始。
6.1 第一步:优先使用官方 + 社区现成 Skills
目标是解决"从 0 到 1 的心理门槛"。
在这个阶段,可以遵循这样的策略:
-
先列出自己最近 1--2 个月经常重复的任务场景
-
针对每类场景,到官方 Skills 仓库和 Awesome 列表里搜索相近能力
-
能 70% 契合需求就先用起来,后续再做微调和适配
这样做至少有三个好处:
-
避免一上来就把精力砸在"如何写出完美 Skill"这种高难度任务上
-
通过使用别人写的优秀 Skills,反向学习结构与实现思路
-
快速体验到"会用 Skills 到底能省多少事",产生正反馈
6.2 第二步:把重复 3 次以上的工作"技能化"
当你开始熟悉 Skills 的基本用法后,可以进入第二个阶段:有意识地把高频任务抽象成自己的 Skill。
一个简单的判断标准是:
如果过去一周你已经为某类任务重复向 Claude 描述同一类需求 ≥ 3 次,就值得考虑把它抽象成 Skill。
典型的候选场景包括:
-
固定格式的周报 / 月报写作
-
固定结构的需求评审、技术方案模版
-
固定风格的代码 Review 与优化建议
-
针对某个业务知识库的高频问答
在这个过程中,建议注意两点工程化思路:
-
明确 Skill 的"职责边界":尽量单一职责,不要做成一个"万能大而全"的 Skill
-
把输入输出格式设计好:尤其是输出,尽量结构化,方便后续工作流串联
6.3 第三步:把 Claude 当"搭子",而不是搜索框
这一步其实是心智模式的切换。
搜索框心态 :问它怎么做,然后自己去执行协作心态:告诉它要做什么,并让它直接承担一部分执行
在 Skills 的架构下,这种心态转变会更加自然:
-
不再只问"怎么写一份汇报 PPT",而是让某个 PPT Skill 直接生成初稿
-
不再只问"这段代码哪里有问题",而是让代码分析 Skill 做系统性诊断
-
不再只问"帮我理解这份长 PDF",而是让 PDF Skill 提取结构化要点供后续加工
换句话说,不是"问它怎么做",而是让它直接去做。
6.4 反模式:这些坑不要踩
在实际落地 Skills 的过程中,有几类常见的反模式值得提前避开:
**① 把 Skill 做成"超级上帝模式"**一个 Skill 试图解决所有问题。这类 Skill 往往表现不稳定,触发条件模糊,输出质量参差不齐。 正确做法:保持单一职责,宁可多几个小 Skill,也不要做一个大而全的 Skill。
② Trigger 描述过于宽泛 比如 trigger: 当用户需要帮助时------这会导致 Claude 频繁误触发,严重干扰正常对话。 正确做法:Trigger 条件要具体,明确说明什么情况触发、什么情况不触发(DO NOT TRIGGER)。
③ 忽略输出格式设计只定义了"做什么",没有定义"输出格式是什么"。当 Skill 作为工作流中的一个环节时,下游处理会因格式不一致而崩溃。 正确做法:输出格式尽量结构化(Markdown 表格、JSON、固定模板等),并在 Skill 中明确约定。
④ 跳过版本管理Skills 会随业务需求不断演化,如果不纳入版本管理,一旦改坏就难以回退。 正确做法:把团队 Skills 放入 Git 仓库,像管理代码一样管理 Skills。
七、从 Prompt 到 Skills:长期协作关系的重构
一个很有代表性的观点是:
Prompt 决定一次对话的质量,Skills 决定你和 AI 的长期协作关系。
站在工程和组织视角,这句话可以有至少三层解读:
对个人而言: Prompt 决定你当下"聊得好不好"; Skills 决定你能否把经验沉淀下来,形成自己的 AI 协作资产。
**对团队而言:**Prompt 文档更多是"使用说明书"; Skills Library 则是"可执行的能力组件库",可以被团队成员反复调用,而且会随着团队实践不断迭代升级。
**对组织而言:**围绕 Skills 搭建起来的,不只是工具箱,而是在构建一个可生长的 "集体大脑" ------每一个被沉淀的 Skill,都是组织知识的一次结晶。
对于已经熟练使用 Claude 的开发者和技术从业者,下一阶段真正的升级,不是再多记几个提示词模板,而是开始系统地思考:
-
哪些能力应该被沉淀为 Skills?
-
如何维护一套适合自己或团队的 Skills Library?
-
如何让 Claude 在这套 Library 之上,扮演好"通用执行者"的角色?
也许再过一两年,大家回头再看 2025--2026 年这段时间,会发现一个清晰的分水岭:
之前的时代,是"谁会写 Prompt 谁占优"; 之后的时代,是"谁会写、会运营 Skills,谁在真正定义人与 AI 的协作方式"。
而现在,恰好是这条分水岭的此岸。