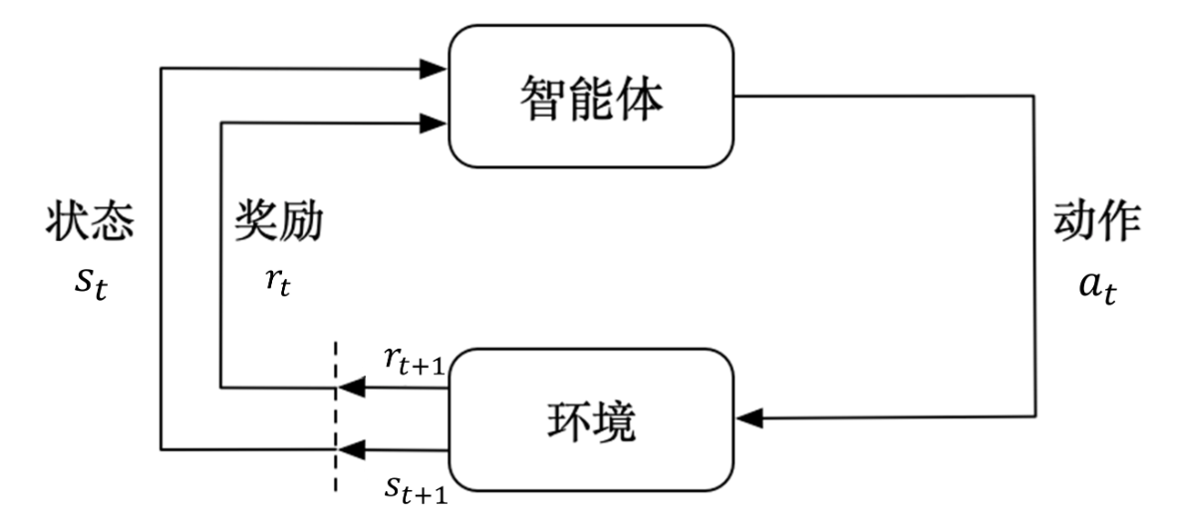
强化学习
强化学习和监督学习是机器学习中的两种不同的学习范式
强化学习: 目标是让智能体通过与环境的交互,学习到一个最优策略,以最大化长期累积奖励
例如,在机器人导航任务中,智能体需要学习如何在复杂环境中移动,以最快速度到达目标位置,同时避免碰撞障碍物,这个过程中智能体要不断尝试不同的行动序列来找到最优路径。
监督学习: 旨在学习一个从输入特征到输出标签的映射函数,通常用在预测,分类和回归等任务
比如,根据历史数据预测股票价格走势,或者根据图像特征对图像中的物体进行分类,模型通过学习已知的输入输出对来对新的未知数据进行预测
重要概念
智能体是个很宽泛的概念,可以是一个深度学习模型,也可以是一个实体机器人
环境可能随智能体的动作发生变化,为智能体提供奖励
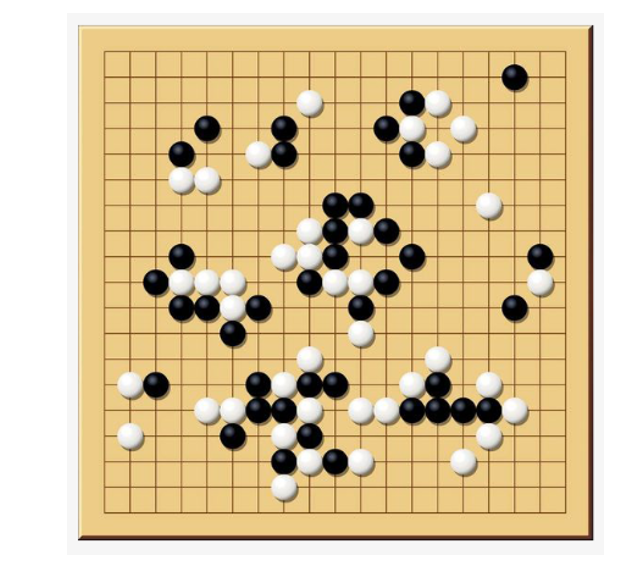
以一个围棋智能体为例,
围棋规则即是环境
状态: 当前1的盘面即使一种状态
行动: 接下来的下法是一种行动
奖励:输赢是一种由环境给出的奖励 这个和监督学习有区别,奖励不是实时的,就是不是每下一步就能有反馈当下完的时候才能有输赢,而监督学习是每一个x都对应一个y
智能体要学习的内容:
策略:
-- 用于根据当前状态,选择下一步的行动
-- 以围棋来说,可以理解为在当前盘面下,下一步走每一格的概率
-- 策略Π是一个输入状态(state)输出动作(action)的函数
a = Π(s)
-- 或者输入状态 + 动作 输出概率的函数
-- 有了策略之后,就可以不断在每个状态下,决定执行什么动作,进而进入下一个状态,依次类推完成整个任务
-- s1 ->a1 -> s2 -> a2 -> s3
这就是所谓的'马尔科夫决策过程'MDP
价值函数:
基于策略Π得到的函数,具体分为两种:
1.状态价值函数 V(s)
表示从状态s开始,遵循策略Π(当前的模型)所能获得的长期积累奖励的期望
折扣银子 属于0,1,反应对于未来奖励的重视程度
2.动作价值函数 Q(s,a)
表示在状态s下采取行动a,遵循策略Π所能获得的长期积累奖励的期望
- 二者关系
状态价值函数可以理解为目前整盘棋赢的概率,而动作价值函数,是下到这赢的概率
优化目标 : 优势估计函数 A(s,a) = Q(s,a) -V(s) 可以理解为下这个位置赢的概率一定要大于棋盘现在赢的估计概率
Q和V都是基于策略Π的函数,所以整个函数也是基于Π的函数
策略Π可以是一个神经网络,要优化这个网络的参数
训练过程中,通过最大化优势函数A(s,a),来更新策略网络的参数
也就是说优势估计函数的作业类似于loss函数,是一个优化目标
可以通过梯度反传来优化
这是强化学习中的一种方法,一般称为策略梯度算法

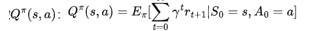
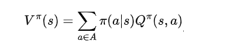
NLP与强化学习
将文本生成过程看作一个序列决策过程
state = 已经生成的部分文本
action = 选择下一个要生成的token
大模型类似于策略
然后再找个方式奖励它,就能于强化学习联系起来
那么怎么设计奖励
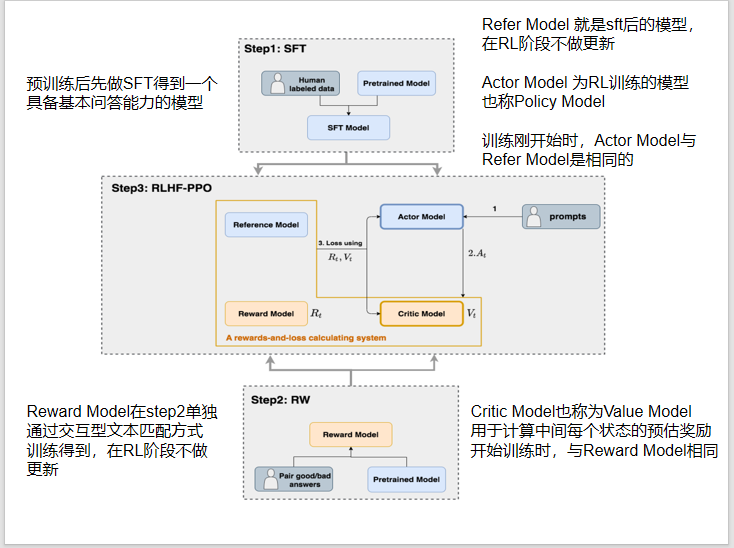
PPO算法(RLHF)
da
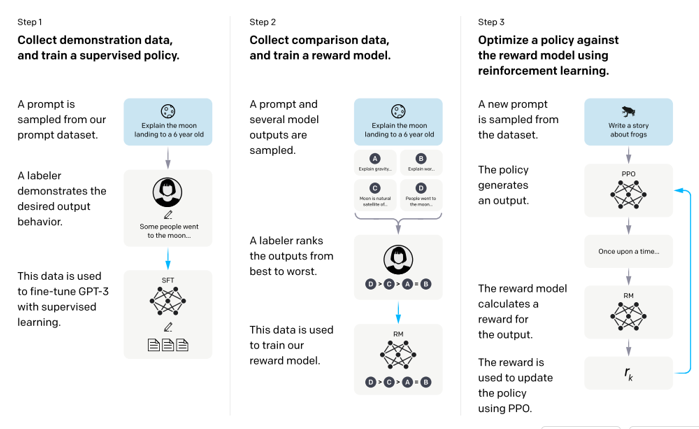
第一步:
从数据集里收集一些提示词,然后找人工标注员,来写出正确的输出,拿输入和输出做有监督学习 (SFT)
第二步(训出奖励模型):
收集对比的数据,准备若干个模型,输出不同的output,然后找人工,给输出排序,然后拿这个排序训出来一个奖励模型
RW训练(RW奖励模型)
对于一个输入问题,获取若干可能的答案
由人工进行排序打分
两两一组进行Reward Model训练
r@ 是一个交互式文本匹配模型,输出为标量(0-1)
x: 为题(prompt)
yw: 相对好的答案
yl : 相对差的答案
第三步:
RL训练
r@(x,y) 是奖励模型得到的,减去 后面的那个,后面那个代表 RL得到的比上 第一版本得到的值,因为第一步SFT后得到的模型不是差的,要约束这个结果,强化的模型的结果不能与原版差太多,后面那个附加项可有可无
r@还能再拆解一下,不过仍是与老策略对比一下
PPO加入约束
怕重要性采样过高或过低,小于 第二个时候,取第二个 1-那个, 大于 1+那个的时候,取第三个
整个流程图如下
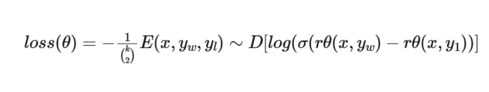
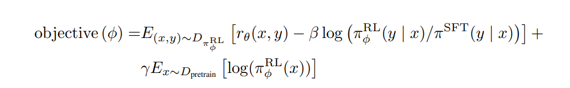

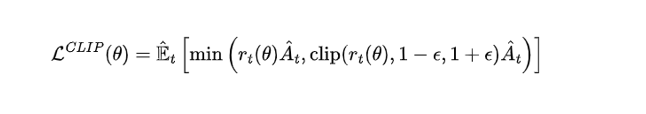
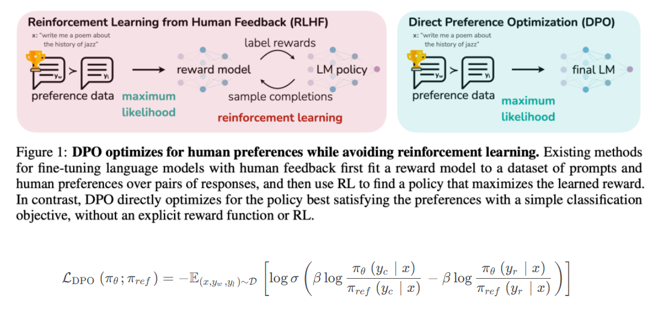
DPO(理解)
跳过reward model 训练,直接使用pair数据进行学习,实际上DPO并不是严格意义的强化学习,更适合叫对比学习
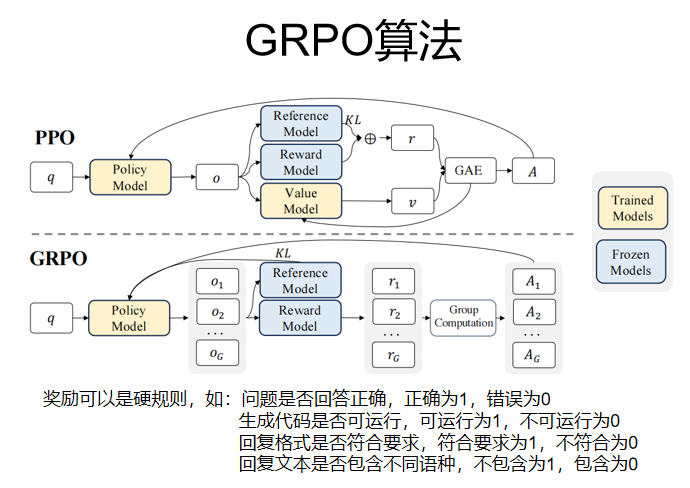
GRPO算法(主流,deepseek带火的)(称为RLVR,VR 为可验证的奖励)
GRPO去掉了价值模型,Reference Model 是 SFT微调后的模型,Reward Model 不一定是个模型,也可以是硬规则,如图,当然也不是 非0即1的
GRPO算法采用了拒绝采样,就是对于输出有多个回应
拒绝采样(高温采样)
让自己的模型针对prompt生成多个候选response,设计方法从中挑选高质量的response,拿来再次进行训练
挑选方式:
使用一个训练过的reward model 进行评分排序
使用特定规则(奖励函数)筛选
使用语言模型生成结果序列时的路径概率得分
pass@k是一个基础模型能力评估的主要标准,代表随机生成的n条路径中,有k个结果是正确的
上面的特定规则,比如可以是格式奖励
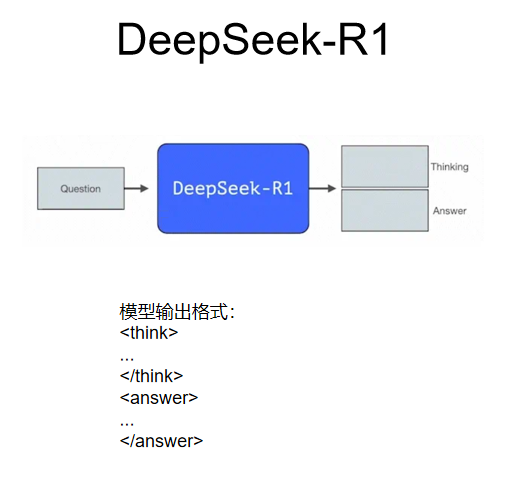
deepseek开启深度思考时,<think></think> 就是网页版上的灰色,<answer></answer>则是答案