前言
有了AI构建本体后,会不会取代高级工程师:
不会!AI 越强:
越需要高级 FDE / 架构师。未来真正的企业AI:
AI负责规模化,人类负责最终治理。
高级FDE他们会从"写代码的人"升级为"判断AI是否正确的人"。这才是AI时代真正的职业进化方向。
### 闭雨哲 本体数据库AbutionGraph与OntoFlow平台作者
📌 **独立开发与核心能力**
- **全栈研发**:1人完成发明、设计及研发,2019年首发并曾开源两年。
- **技术特性**:支持时序图谱、向量图谱、静态/动态图谱及子图权限隔离。
- **市场定位**:首款完整本体论语义的原生数据库,通过多项目验证。
🚀 **差异化愿景**
非Palantir仿制品,基于早期对本体智能赛道的独立判断,实现跨国界同类技术创新。 正文
一、很多人误解了"AI自动建模"
一提到"本体",很多人第一反应是:"又要一堆专家开几个月会?"
一提到"AI自动建模",又变成:"AI能直接帮我做?"
答案是:可以,而且已经开始工程化落地。
但关键是------很多所谓"AI生成知识图谱",其实只是自动抽几个实体、写几条查询、配个聊天界面。
离真正的"本体智能应用"还差很远。
二、真正的本体系统,是一个"可执行世界"
它需要:数据理解、特征工程、实体建模、规则推理、查询API、Skill、工作流、人机协同。
最终形成:一个可运行、可查询、可决策的数字系统。
这也是为什么------很多企业做知识图谱做成了"静态PPT",而OntoFlow未来能做成"可作战的数字战场"。
区别在于:后者是本体驱动的执行系统。
三、OntoFlow的核心思路:固定流程 + AI Harness
OntoFlow不是让AI"随便生成",而是先把本体开发流程工程化:
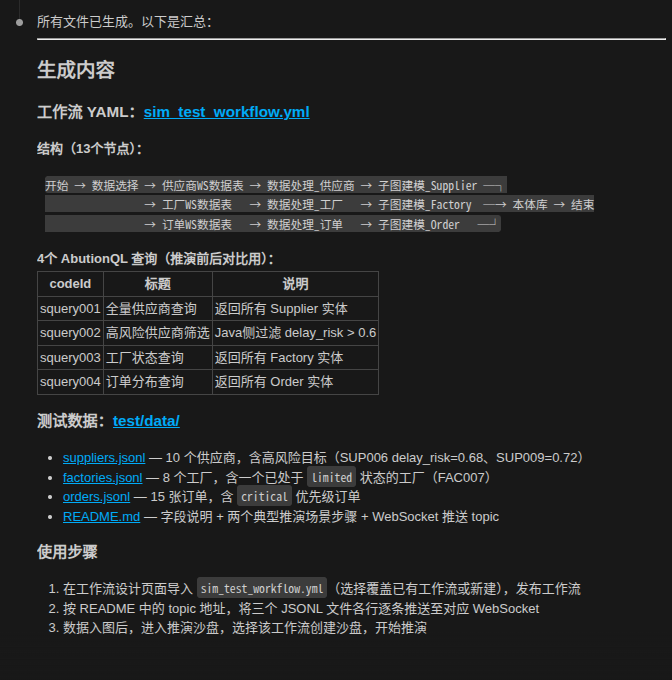
数据选择 → 数据处理 → 本体建模 → 查询设计 → API/Skill → 验证迭代以前人做,现在AI做:
人定义目标 → AI自动规划 → AI自动选数据 → AI自动理解字段 → AI自动生成处理逻辑 → AI自动构建本体 → AI自动生成查询 → AI自动生成Skill → 人类确认 → 上线运行
闭环式AI本体生成,可持续演化。
四、为什么"固定流程"反而更适合AI?
企业系统里,AI最怕没有边界------Prompt会乱、Agent会漂、结果会随机。
OntoFlow先把流程标准化:
第一阶段:数据选择
AI自动探索数据源、理解表结构、分析字段样例。连数据都没看懂,后面都是幻觉。
当前准确率约85%,字段命名不规范时需要人工修正。
第二阶段:数据处理
AI自动做特征工程------滚动统计、异常分数、时间窗口聚合。这才是真正的智能应用。
代码首次编译通过率约60%,2-3轮迭代后达90%。
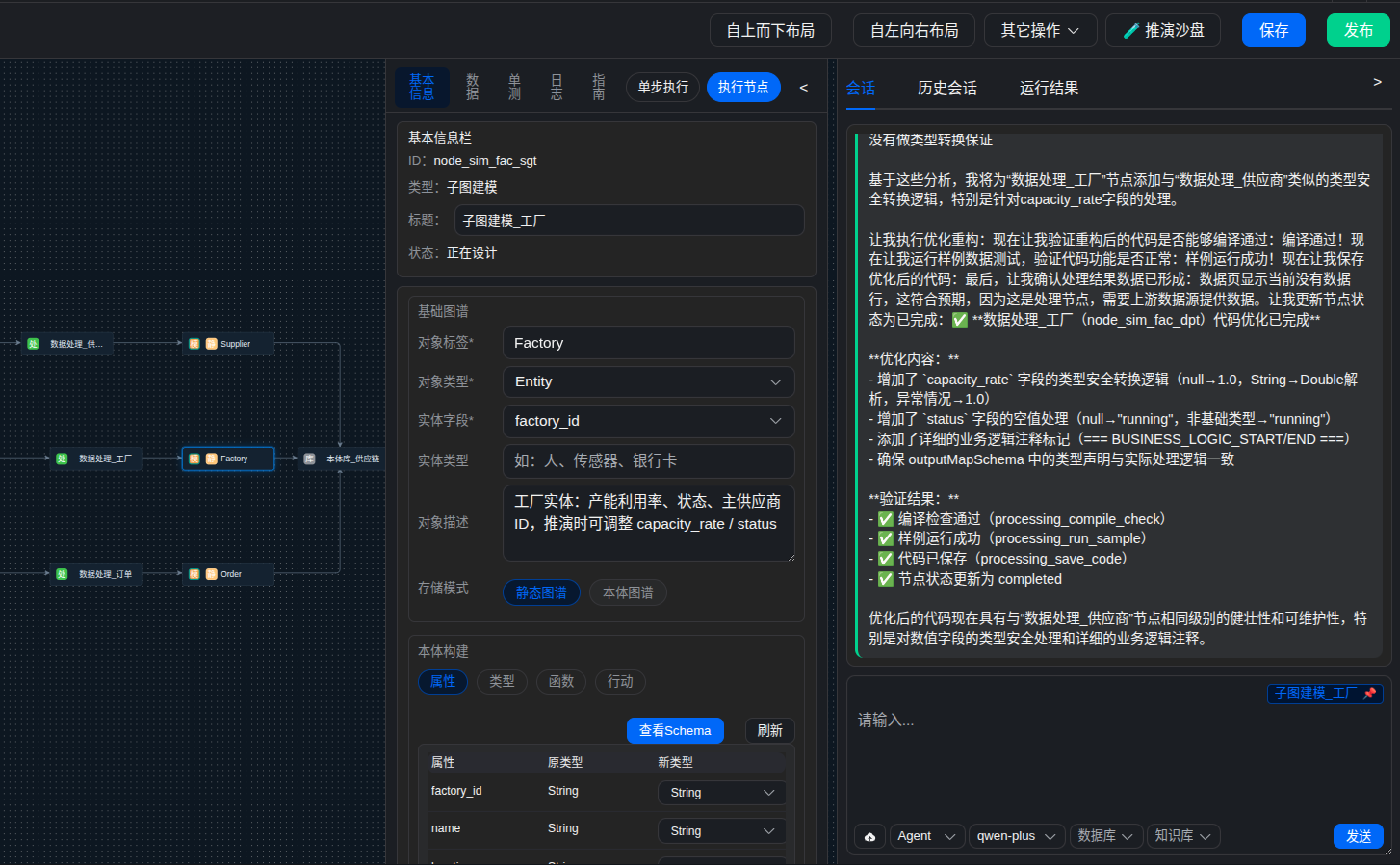
第三阶段:本体建模
AI自动识别实体、关系、层级、约束、事件流。不是"关系线",而是世界结构。
常见业务域准确率90%,垂直领域70%以下需专家介入。
第四阶段:查询+Skill
AI自动生成查询、API、Skill。让系统能被调用,而不是只做展示。
五、Harness是什么?AI本体工程的总控系统
Harness不只是Prompt工具,它负责:
- 管理阶段状态机
- 管理上下文记忆
- 管理Agent与工具
- 管理HITL(人在回路)
当前已进入多子代理Team模式:
数据代理 → 处理代理 → 建模代理 → 查询代理 → 验证代理这是AI软件工程流水线。
六、HITL为什么重要?AI不做"删库跑路"
企业最怕AI"自由发挥"删数据。
OntoFlow的HITL闭环:
AI发现风险操作 → 分析影响 → 生成确认卡片 → 等待用户确认
机器负责规模化,人负责最终裁决。
高级人员的角色:从"写代码"变成"判断AI是否正确、管控组织风险"。
七、落地对比:传统方式 vs OntoFlow
| 环节 | 传统方式 | OntoFlow |
|---|---|---|
| 数据接入 | 1天 | 配置节点,自动生成API |
| 本体建模 | 1-2周 | 可视化配置,半天 |
| 接口开放 | 2周 | 自动生成,零代码 |
| 总周期 | 2-3个月 | 5-10天 |
这不是效率提升,是工程范式跃迁。
八、坦诚的能力边界
已成熟(可放心用):
- Ask模式:只读问答
- Plan模式:生成计划草稿
- Agent模式:单节点执行
- HITL闭环:高风险人工确认
完善中(2-4周上线):
- Team模式:全流程自动构建
- 会话持久化:重启不丢进度
需人工兜底:
- 垂直领域术语识别(70-85%)
- 复杂规则推导(AI出初稿,人精修)
九、结语:中国版Palantir的正确路线
真正的Palantir级平台,不是堆功能,而是用固定工作流把现实世界变成可执行系统。
OntoFlow的答案:
- 底层:AbutionGraph原生本体数据库,统一图谱、时序、向量、函数、行动等一体能力
- 上层:一条固定工作流,完成本体应用开发
- 目标:每个企业都能低成本搭建认知操作系统
用工作流的方式落地本体智能------这就是OntoFlow的路线。