
🔥铅笔小新z:个人主页
🎬博客专栏:Linux学习
💫滴水不绝,可穿石;步履不休,能至渊。

本节重点
- 理解磁盘物理结构
- 掌握 CHS 和 LBA 地址
- 掌握 Ext 系列文件系统原理
- 理解分区、格式化、路径解析、挂载等过程和操作
- 理解软硬链接的使用和用途
一、理解硬件
1.1 磁盘、服务器、机柜、机房
机械磁盘是计算机中唯一的一个机械设备。它属于外设,特点是:
- 速度慢------靠机械臂转动读写,比内存、CPU 慢得多
- 容量大、价格便宜------一块机械硬盘能做到几 TB,价格远低于同容量的固态硬盘


正因为磁盘慢,操作系统在设计文件系统时会想尽办法减少磁盘 I/O 次数,这就引出了后面"块"的概念和"缓存"机制。
1.2 磁盘物理结构

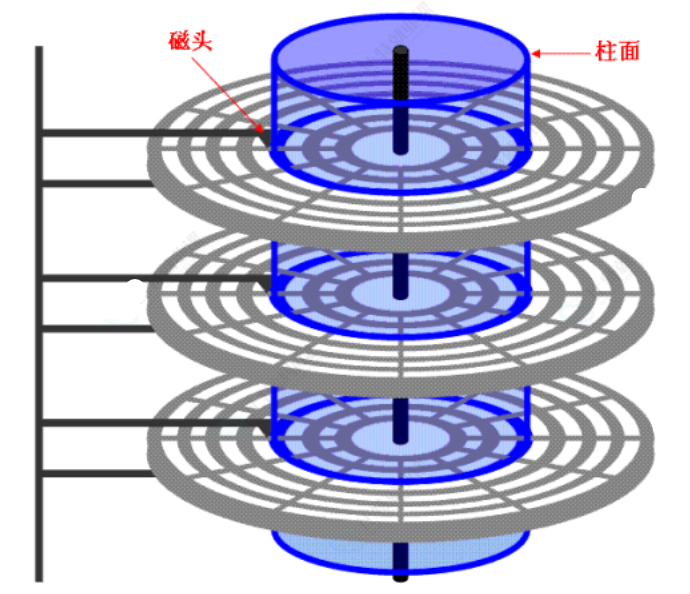
磁盘内部主要由以下几部分组成:
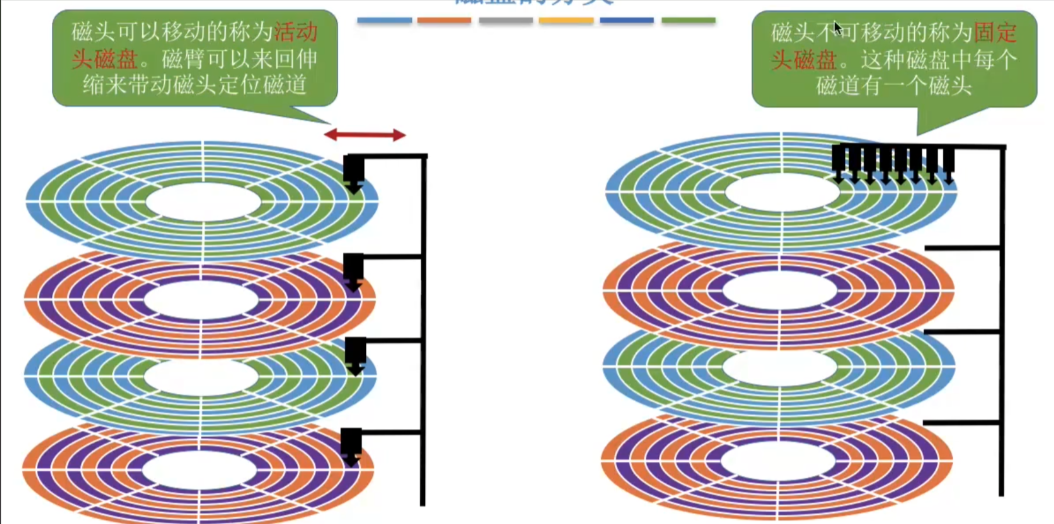
- 盘片(platter):圆形的磁性盘片,数据就存储在上面
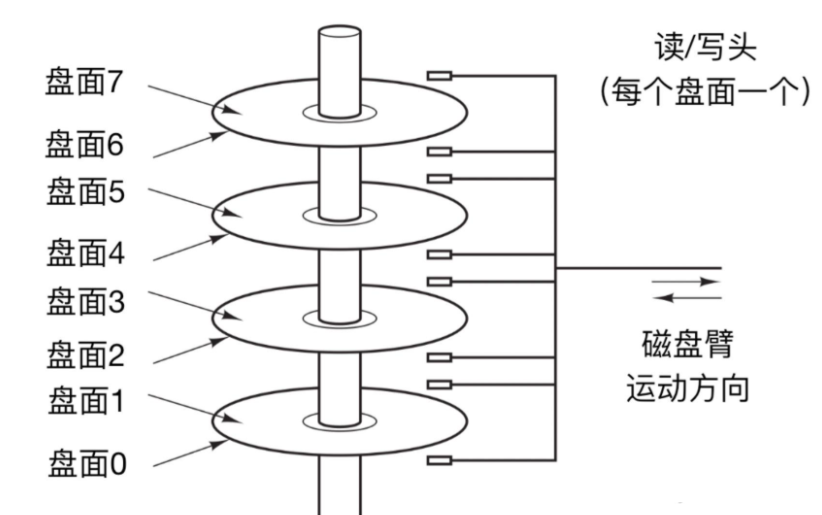
- 磁头(head):每个盘片有上下两个面,每一面对应 1 个磁头,用来读写数据
- 传动臂(actuator arm):连接所有磁头,所有磁头共进退(这个细节很重要)
- 主轴(spindle):带动盘片高速旋转
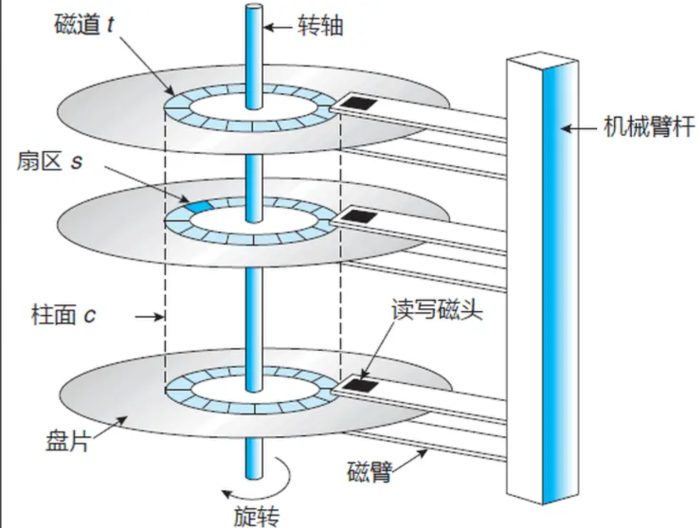
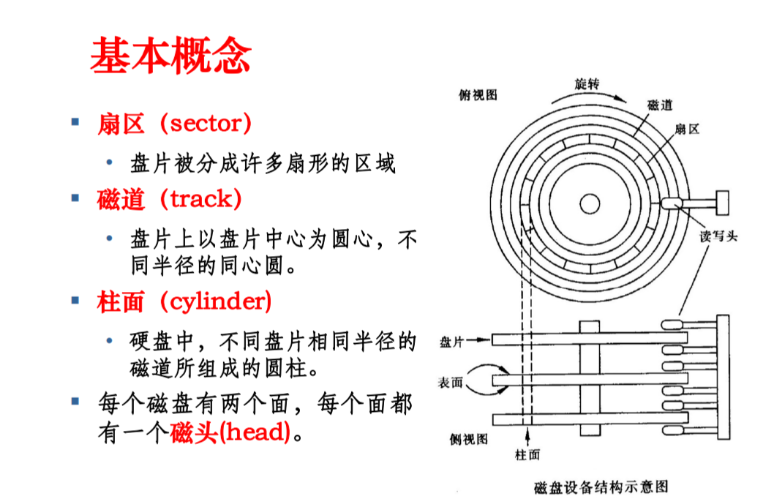
- 磁道(track):盘片上每一个同心圆环就是一个磁道,从外圈向内编号(0 磁道、1 磁道......)
- 柱面(cylinder):所有盘片上相同半径的磁道构成一个柱面,数量上等于单个盘面的磁道数
- 扇区(sector) :每个磁道被划分成若干扇形区域,每个扇区存储 512 字节,是磁盘读写的最小单位
磁盘容量计算公式
磁盘容量 = 磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数关键理解 :传动臂上的磁头是共进退的------也就是说,所有磁头永远停留在同一半径位置。当磁头移动到某个柱面时,所有盘面上的该柱面都能被访问,只不过需要切换磁头(电子切换,速度很快)。
📌 知识点总结
磁盘本质上是一个机械设备,靠磁头在旋转的盘片上读写数据。数据的最小读写单位是扇区(512 字节) 。要定位一个扇区,需要知道三个信息:用哪个磁头、在哪个柱面、扇区编号是多少------这就是 CHS 寻址。磁盘的容量 = 磁头数 × 磁道数 × 每道扇区数 × 512 字节。理解磁盘物理结构,是后续理解文件系统的基础,因为文件系统的终极目标就是高效地组织和管理磁盘上的数据。
1.3 磁盘的存储结构与 CHS 寻址
如何定位一个扇区?
要找到磁盘上的某个扇区,需要三步:
- 确定磁头(Head)------决定用哪个盘面的哪个面
- 确定柱面(Cylinder)------决定磁头移动到哪个半径位置
- 确定扇区(Sector)------决定在磁道上的哪个扇形区域
这种定位方式叫做 CHS 寻址(Cylinder-Head-Sector)。
CHS 寻址的局限性
CHS 对早期小容量磁盘很有效,但在大容量磁盘上存在瓶颈:
- 系统用 8 bit 存储磁头地址 → 最多 256 个磁头
- 用 10 bit 存储柱面地址 → 最多 1024 个柱面
- 用 6 bit 存储扇区地址 → 最多 63 个扇区(编号从 1 开始)
- 每个扇区 512 字节
最大容量 = 256 × 1024 × 63 × 512 B ≈ 8.064 GB
这个容量在现代看来太小了,因此引入了更先进的 LBA 寻址方式。
补充:文件 = 内容 + 属性,本质上都是数据,存储到磁盘上就是占据若干个扇区的问题。只要能定位一个扇区,就能通过连续读取定位多个扇区。
📌 知识点总结
CHS 寻址是早期磁盘的数据定位方式,通过"柱面号 + 磁头号 + 扇区号"三维坐标确定一个扇区。但由于 CHS 用固定的位数来存储这三部分信息(10bit + 8bit + 6bit),导致最大只能管理约 8GB 的磁盘空间,远远无法满足现代存储需求。所以后来出现了 LBA 寻址,把磁盘"拉直"成一维线性地址来访问。
1.4 磁盘的逻辑结构

理解过程------把磁盘想象成"拉直的磁带"
磁盘虽然是硬质的圆盘,但逻辑上 我们可以把它想象成一根卷在一起的磁带:

-
把磁带"拉直",就形成了一条线性结构

-
每个扇区在这条线上都有一个唯一的编号,类似于数组的下标
-
这种编号就叫 LBA(Logical Block Address,逻辑块地址)
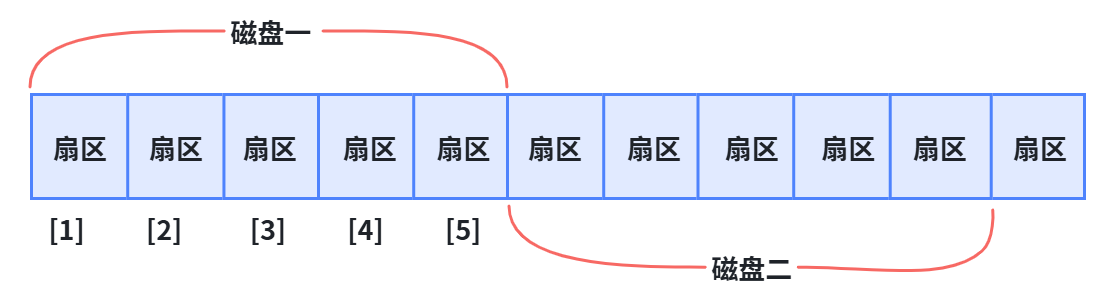
真实过程------为什么可以这样想?
核心原因就是:传动臂上的磁头是共进退的 。
- 所有磁头永远停留在同一个柱面位置
- 切换不同盘面上的磁头只是电子切换,非常快
- 因此从逻辑上看,磁盘不像是多个盘片,而像是把柱面一层层"卷起来"的线性磁带
磁道:
某一盘面的某一个磁道展开:

即:一维数组
柱面:
整个磁盘所在盘面的同一个磁道,即柱面展开:
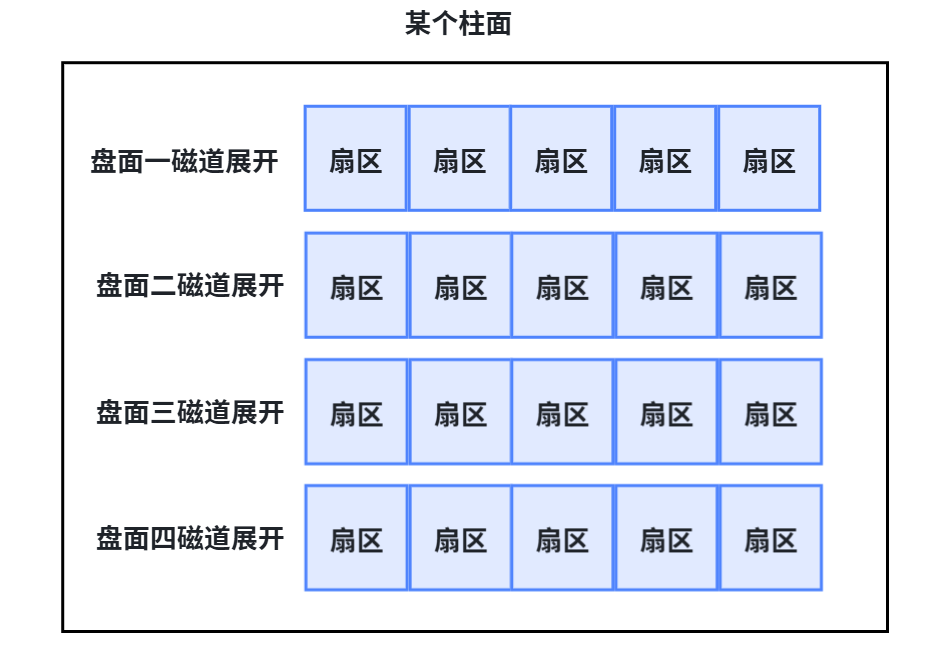
- 柱面上的每个磁道,扇区个数是一样的
- 这就是二维数组
整盘:
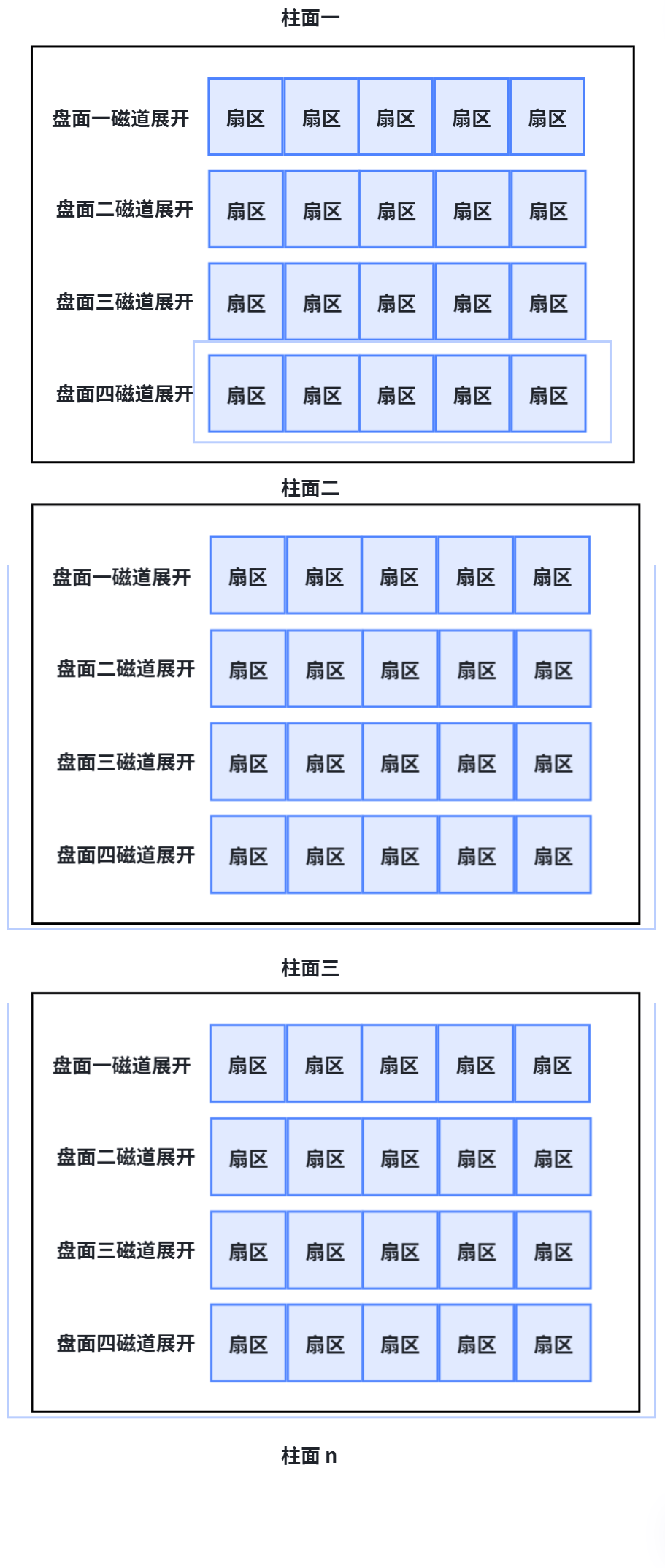
- 整个磁盘就是多张二维的扇区数组表(三维数组)
所有,寻址一个扇区:先找到那一个柱面,在确定柱面内那一个磁道(其实就是磁头位置 Head ),在确定扇区(Sector ),所以就有了 CHS。
我们之前学过 C/C++ 的数组,在我们看来,其实全部都是一维数组:
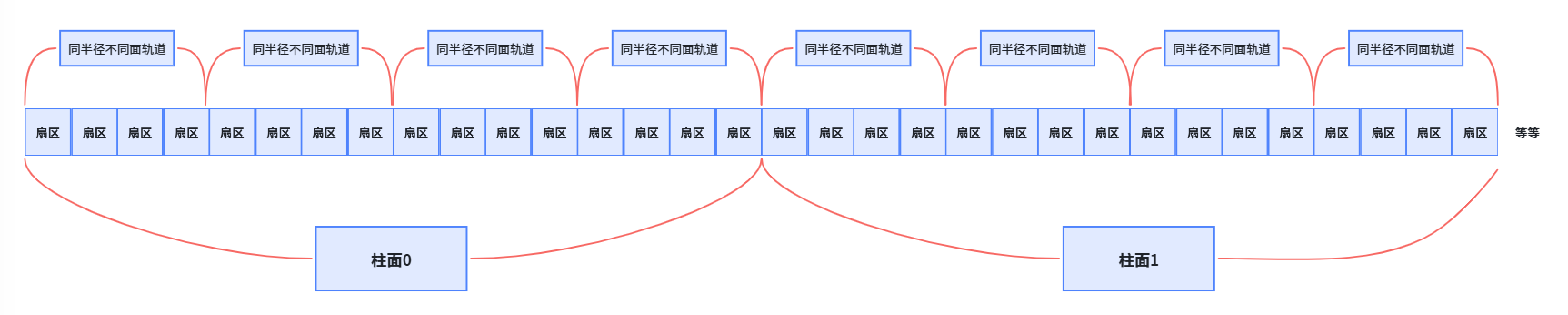
所以磁盘物理上有多个盘面、多个磁道,但从逻辑角度,我们可以把整个磁盘看作一个一维数组,数组的每个元素就是一个扇区,数组下标就是 LBA 地址。
📌 知识点总结
由于所有磁头共进退,我们无需关心复杂的物理三维结构,完全可以把磁盘抽象成一个一维数组:扇区就是数组元素,LBA 就是数组下标。这种抽象极大地简化了操作系统和文件系统对磁盘的管理------用一个数字就能直接访问任意扇区。
1.5 CHS 与 LBA 地址的互相转换
CHS → LBA
LBA = C × (H总 × S每道) + H × S每道 + S - 1其中:
H总 × S每道= 一个柱面的扇区总数- 扇区号
S从 1 开始,LBA 从 0 开始,所以要减 1 - 柱面号和磁头号都是从 0 开始编号
LBA → CHS
C = LBA ÷ (H总 × S每道) // 取整
H = (LBA % (H总 × S每道)) ÷ S每道 // 取整
S = (LBA % S每道) + 1计算机开机时,磁盘内部会自动维护柱面数、磁头数、每道扇区数等参数,操作系统启动时会获取这些参数来完成地址转换。
📌 知识点总结
LBA 是线性地址,从 0 开始编号;CHS 是三维地址,扇区从 1 开始编号。两者可以互相转换,转换公式其实就是一个"进制换算"的过程。有了 LBA,操作系统就可以用一个简单的整数来访问磁盘的任意扇区,不再需要关心复杂的磁盘物理结构。从此以后,磁盘在 OS 眼中就是一个以扇区为元素的一维大数组。
二、引入文件系统
2.1 引入"块"的概念
为什么需要"块"?
磁盘是典型的块设备 。如果操作系统一个个扇区(512 字节)地读取,效率太低了。因此操作系统采用了一次性读取多个连续扇区 的策略------这些连续扇区合在一起就叫一个块(Block)。
块的大小
- 块的大小在格式化时确定,之后不可更改
- 最常见的块大小是 4 KB = 8 个扇区(8 × 512 B)
- 块是文件存取的最小单位,即使文件只有 1 个字节,也要占用一个块
块与 LBA 的关系
知道 LBA:块号 = LBA ÷ 8
知道块号:该块的第一个扇区 LBA = 块号 × 8一句话总结:磁盘是三维的 → 抽象成 LBA 一维数组 → 再把 8 个连续扇区合并成一个块 → 最终以块为单位管理数据。
📌 知识点总结
"块"是文件系统管理存储空间的基本单位,通常为 4KB(8 个扇区)。引入块的原因很简单:每次只读 512 字节太慢了,操作系统希望一次多读点数据来提高 I/O 效率。块在格式化时确定大小,后续不可更改,并且文件哪怕只有 1 字节也要占用整整一个块。这不是浪费,而是为了效率必须付出的代价。
2.2 引入"分区"概念
什么是分区?
分区就是把一块物理磁盘逻辑上分成多个独立区域。以 Windows 为例,一块磁盘可以分成 C 盘、D 盘、E 盘,这些就是分区。
分区的本质
分区的本质是对硬盘的一种格式化,通过设定起始柱面和结束柱面 来划分区域。柱面是分区的最小单位。
Linux 下的分区
Linux 下一切皆文件,磁盘设备也是以文件形式存在的,比如 /dev/sda1、/dev/sda2 等。
思考:分区后每个分区可以独立格式化不同的文件系统(ext4、NTFS、FAT32 等),互不干扰。
📌 知识点总结
分区就是把一块硬盘切成几个独立的逻辑区域,每一个区域都可以单独格式化成不同的文件系统。柱面是分区的最小单位,分区本质上就是设定起始柱面和结束柱面。在 Linux 中,分区设备也以文件形式呈现(如 /dev/sda1),体现了"一切皆文件"的思想。
2.3 引入"inode"概念
文件的本质
文件 = 数据 + 属性
- 数据:文件的内容(比如文本里的文字、图片的像素信息)
- 属性:文件的元数据(大小、权限、所有者、修改时间等)
使用 ls -l 可以看到文件的属性:
-rw-r--r--. 2 root root 0 Dec 25 10:00 abc共 7 列:
- 模式(文件类型 + 权限)
- 硬链接数
- 文件所有者
- 所属组
- 大小
- 最后修改时间
- 文件名
使用 stat 命令可以看到更详细的属性信息。
inode 是什么?
- inode(index node,索引节点)是存储文件属性的数据结构
- Linux 下文件的属性和内容是分离存储的
- 每一个文件都有一个对应的 inode
- 每个 inode 有唯一的标识符,叫做 inode 号
inode 数据结构(ext2 中的定义)
c
struct ext2_inode {
__le16 i_mode; /* 文件模式(类型 + 权限) */
__le16 i_uid; /* 所有者 UID(低 16 位) */
__le32 i_size; /* 文件大小(字节) */
__le32 i_atime; /* 最后访问时间 */
__le32 i_ctime; /* 创建时间 */
__le32 i_mtime; /* 最后修改时间 */
__le32 i_dtime; /* 删除时间 */
__le16 i_gid; /* 所属组 GID(低 16 位) */
__le16 i_links_count; /* 硬链接计数 */
__le32 i_blocks; /* 文件占用的块数 */
__le32 i_flags; /* 文件标志 */
// ...
__le32 i_block[EXT2_N_BLOCKS]; /* 数据块指针数组,用于映射数据块位置 */
// ...
};
/* 块指针常量定义 */
#define EXT2_NDIR_BLOCKS 12 /* 12 个直接块指针 */
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS /* 第 13 个:一级间接块指针 */
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1) /* 第 14 个:二级间接块指针 */
#define EXT2_TIND_BLOCK (DIND_BLOCK + 1) /* 第 15 个:三级间接块指针 */
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1) /* 总共 15 个块指针 */关于 inode 的重要说明
- 文件名不在 inode 中------文件名存储在目录文件的数据块里,与 inode 号组成映射关系
- inode 大小固定------一般为 128 字节或 256 字节,文件内容可以大小不一,但 inode 大小是固定的
- 每个文件都有一个 inode------包括目录文件本身
📌 知识点总结
inode 就是文件的"身份证",里面存储了文件的所有属性信息(大小、权限、时间戳等),但不包含文件名。Linux 把文件的内容和属性分开存储:属性放在 inode 中,内容放在数据块中。每个 inode 有一个唯一的 inode 号,操作系统通过 inode 号来识别和管理文件。inode 的大小是固定的(128B 或 256B),无论文件内容多大,inode 占用的空间都一样。
三、ext2 文件系统
3.1 宏观认识
要在一个分区上存储文件,必须先将其格式化(写入文件系统)。文件系统的作用就是组织和管理磁盘上的文件。
ext2(Second Extended File System) 是 Linux 中最经典的文件系统之一。它的核心设计思想是:
将整个分区划分成若干个大小相同的块组(Block Group),只要能管理好一个块组,就能管理所有块组,也就能管理整个分区的所有文件。
📌 知识点总结
ext2 文件系统把分区切成若干个同样大小的块组,每个块组内部结构完全相同。这种"分而治之"的设计思想使得文件系统结构清晰、易于管理。只要理解了单个块组的组成,就理解了整个 ext2 文件系统。
3.2 Block Group(块组)
每个块组内部包含以下 6 个组成部分:
| 组成部分 | 存放内容 | 作用 |
|---|---|---|
| 超级块(Super Block) | 文件系统全局信息 | 描述整个分区的 inode 总量、block 总量、空闲数等 |
| 块组描述符表(GDT) | 块组属性信息 | 每个块组对应一个描述符,记录该块组的位置信息 |
| 块位图(Block Bitmap) | 数据块占用情况 | 每个 bit 表示一个数据块是否被占用 |
| inode 位图(Inode Bitmap) | inode 占用情况 | 每个 bit 表示一个 inode 是否被占用 |
| inode 表(Inode Table) | 所有 inode 的集合 | 存储该块组内所有文件的属性信息 |
| 数据块区(Data Block) | 文件实际内容 | 存放文件数据的真正区域 |
📌 知识点总结
每个块组就像一个小社区,里面有"户口本"(超级块+GDT)记录全局信息,"门牌号"(位图)标记哪些位置被占了,"居民信息"(inode 表)记录每个人的身份,"住房"(数据块)存放实际物品。这种分层管理的方式让文件系统能够高效地分配和回收存储空间。
3.3 块组内部各组成部分详解
3.3.1 超级块(Super Block)
超级块存放文件系统本身的结构信息,是整个分区的"总目录"。记录的信息包括但不限于:
- block 和 inode 的总量
- 未使用的 block 和 inode 数量
- 一个 block 和 inode 的大小
- 文件系统的挂载时间、最近写入时间等
注意 :超级块在每个块组的开头都有一份拷贝(第一个块组必须有,后面的块组可以没有)。这么做是为了"冗余备份"------如果第一个块组的超级块损坏了,可以从后面的块组恢复。
3.3.2 GDT(Group Descriptor Table)------块组描述符表
GDT 描述每个块组的属性信息,例如:
- 该块组的块位图存放在哪个块
- 该块组的 inode 位图存放在哪个块
- 该块组的 inode 表起始位置
分区分成多少个块组,GDT 中就有多少个块组描述符。
3.3.3 块位图(Block Bitmap)
块位图用一个 bit 对应一个数据块:
- bit = 0:该数据块空闲可用
- bit = 1:该数据块已被占用
这样,文件系统要分配新数据块时,只需要在位图中找到第一个为 0 的 bit 即可。
3.3.4 inode 位图(Inode Bitmap)
和块位图原理相同,但管理的是inode:
- bit = 0:该 inode 空闲可用
- bit = 1:该 inode 已被占用
3.3.5 inode 表(Inode Table)
inode 表是当前块组内所有 inode 的集合,每个 inode 存储一个文件的属性信息(大小、权限、时间戳等)。
重要 :inode 编号以分区为单位整体划分,不可跨分区。也就是说,不同分区的 inode 号可能重复。
3.3.6 数据块区(Data Block)
数据块区是真正存放文件内容的区域。对于不同类型的文件,用途不同:
- 普通文件:数据块存放文件内容
- 目录文件 :数据块存放该目录下所有文件名与 inode 号的映射关系
- 符号链接:如果链接路径较短,直接存在 inode 中;较长则占用数据块
重要:块号也以分区为单位划分,不可跨分区。
📌 知识点总结
块组的六个组成部分各司其职:超级块是全局"户口本",GDT 是"各社区地址簿",块位图和 inode 位图是"占用标记表",inode 表是"居民信息档案",数据块区是"真正的储物空间"。文件系统通过这套机制,把文件的内容和属性有条理地组织在磁盘上。
3.4 inode 与 Data Block 的映射
核心问题
文件内容可能非常大,而 inode 里只有 15 个块指针(i_block[15]),如何映射任意大小的文件?
解决方案------多级索引(重点)
ext2 采用直接 + 间接的多级索引方案:
i_block[0] ~ i_block[11] → 12 个直接块指针(直接指向数据块)
i_block[12] → 一级间接块指针
i_block[13] → 二级间接块指针
i_block[14] → 三级间接块指针假设块大小为 4KB,每个块指针占 4 字节:
| 级别 | 可管理的块数 | 可管理的最大数据量 |
|---|---|---|
| 直接(12 个) | 12 块 | 12 × 4KB = 48KB |
| 一级间接 | 1024 块 | 1024 × 4KB = 4MB |
| 二级间接 | 1024² = 1,048,576 块 | 4GB |
| 三级间接 | 1024³ = 1,073,741,824 块 | 4TB |
| 合计 | ≈ 1,074,790,436 块 | ≈ 4TB+ |
一个 4KB 的块可以存放 1024 个指针(4KB ÷ 4B = 1024),这就是间接块能管理 1024 个块的原因。
创建新文件的 4 个步骤
当你创建一个新文件时,文件系统做了以下 4 件事:
- 存储属性:内核在 inode 位图中找到一个空闲的 inode,将文件信息记录到其中
- 存储数据:在块位图中找到空闲的数据块,将数据写入
- 记录分配情况 :在 inode 的
i_block[]数组中记录数据块的位置 - 添加文件名到目录 :在目录文件的数据块中添加一条记录------
(inode号, 文件名)
📌 知识点总结
inode 通过 15 个块指针(12 个直接 + 1 个一级间接 + 1 个二级间接 + 1 个三级间接)实现了对大文件的灵活映射。小文件直接用直接块指针访问,速度快;大文件通过多级索引逐层跳转,虽然多几次读取,但能支持最大 TB 级别的文件。这种设计在空间利用率和访问效率之间取得了很好的平衡。创建文件时,系统依次完成:分配 inode → 写入数据 → 记录块位置 → 添加到目录,四步缺一不可。
3.5 目录与文件名
目录也是文件
你可能觉得目录是一个"文件夹",但在 Linux 文件系统中:
- 磁盘上没有"目录"这个概念,只有文件属性和文件内容
- 目录本质上是一个特殊文件 ------它的内容是文件名与 inode 号的映射关系表
目录的数据块里存了什么?
目录文件的数据块存储的是这样的一张表:
| inode 号 | 文件名 |
|---|---|
| 2 | . |
| 2 | ... |
| 263466 | abc |
| 263467 | def |
.和..也是目录项,分别代表当前目录和父目录。
问题解答
问:我们访问文件都是用的文件名,没用过 inode 号啊?
答:当你输入文件名时,操作系统会去目录文件中查找该文件名对应的 inode 号,然后通过 inode 号找到文件的属性和数据。文件名只是给用户看的"标签",内核真正关心的是 inode 号。
读取目录内容的代码示例
c
/* readdir.c - 读取目录内容,显示文件名和 inode 号 */
#include <stdio.h>
#include <dirent.h>
#include <sys/types.h>
int main()
{
/* 打开当前目录 */
DIR* dir = opendir(".");
if (dir == NULL) {
perror("打开目录失败");
return 1;
}
struct dirent* entry;
/* 循环读取目录中的每一项 */
while ((entry = readdir(dir)) != NULL) {
/* 打印 inode 号和文件名 */
printf("inode: %lu, 文件名: %s\n", entry->d_ino, entry->d_name);
}
/* 关闭目录 */
closedir(dir);
return 0;
}📌 知识点总结
目录也是文件,它的特殊之处在于数据块存储的不是普通内容,而是"文件名 → inode 号"的映射表。我们平时用文件名访问文件,操作系统会通过目录文件找到对应的 inode 号,然后通过 inode 找到文件的属性和数据块位置。所以文件名只是给人类看的标签,inode 才是内核识别文件的真正依据。
3.6 路径解析
什么是路径解析?
当我们访问一个文件路径,比如 /home/whb/code/test/test.c,操作系统需要从根目录开始,依次查找每一级目录,最终定位到目标文件。这个过程就叫路径解析。
路径解析的过程
- 从根目录
/开始(根目录的 inode 号固定为 2) - 读取根目录的数据块,找到
home目录对应的 inode 号 - 根据 inode 号读取
home目录的属性,再读取其数据块,找到whb目录的 inode 号 - 重复上述步骤,依次找到
code→test→test.c - 最终得到
test.c的 inode 号,通过 inode 找到文件的属性和数据块
为什么要这么做?
因为文件名存储在目录文件中,而文件属性和数据在其他地方。所以每一步都需要先读目录的内容,才知道下一步该查哪个 inode。
📌 知识点总结
路径解析就是从根目录开始,一层层地"翻目录",每次读取当前目录的数据块找到下一级目录的 inode 号,直到最终找到目标文件。这个过程体现了 Linux 文件系统"目录名 → inode → 数据块"的三层访问结构。路径越长,需要读取的目录层数就越多,I/O 次数也越多------所以路径缓存机制就显得尤为重要。
3.7 路径缓存(dentry)
问题
每次访问文件都重新做路径解析效率太低,特别是频繁访问的目录。
解决办法
Linux 内核在内存中维护了一个树状缓存结构,叫做 dentry(Directory Entry)。它缓存了:
- 已经解析过的路径
- 路径中每个节点对应的 inode 信息
这样,下次访问同一个路径时,内核可以直接从 dentry 缓存中获取 inode 信息,省去了反复读取目录磁盘块的开销。
struct dentry是内核中用于路径缓存的核心结构体。
📌 知识点总结
dentry 是 Linux 内核中的路径缓存机制,它把已经解析过的路径"记住"在内存中。下次再访问同样的路径时,就不需要重新从磁盘读取目录数据了,直接走内存缓存,速度会快很多。这是一种典型的"空间换时间"策略------用内存空间换取磁盘 I/O 时间的节省。
3.8 挂载分区
什么是挂载?
分区格式化为文件系统后不能直接使用 ,必须将它关联到系统目录树上的某个目录 ,这个操作就叫挂载(mount)。
挂载实验
bash
# 第一步:制作一个 5MB 的磁盘镜像文件
dd if=/dev/zero of=./disk.img bs=1M count=5
# 第二步:格式化,写入 ext4 文件系统
mkfs.ext4 disk.img
# 第三步:创建一个空目录作为挂载点
mkdir /mnt/mydisk
# 第四步:挂载,将 disk.img 关联到 /mnt/mydisk
sudo mount -t ext4 ./disk.img /mnt/mydisk/
# 第五步:查看系统已挂载的分区
df -h
# 第六步:卸载分区
sudo umount /mnt/mydisk/结论
- 分区必须挂载才能使用------不挂载的操作系统不知道该分区的文件从哪个目录开始找
- 路径前缀决定分区归属 ------系统根据访问路径的前缀来判断属于哪个分区。比如
/mnt/mydisk下的文件就去 disk.img 分区找,/home下的文件去对应分区找
📌 知识点总结
挂载就是把一个分区"粘"到系统目录树的某个目录节点上,这样访问该目录及其子目录就相当于访问那个分区。不挂载的分区无法被用户直接使用------操作系统根本不知道它在哪里。挂载点是目录树上的一个空目录,一个分区只能挂载到一个挂载点,一个挂载点也只能挂载一个分区。路径的前缀决定了文件属于哪个分区。
四、软硬链接
4.1 硬链接
原理
真正找到磁盘上文件的不是文件名,而是 inode 。Linux 允许多个文件名指向同一个 inode,这就是硬链接。
示例
bash
# 创建原始文件 abc
touch abc
# 创建硬链接 def,指向同一个 inode
ln abc def
# 查看两个文件的 inode 号和属性
ls -li abc def输出结果:
263466 -rw-r--r--. 2 root root 0 abc
263466 -rw-r--r--. 2 root root 0 def可以看到:
abc和def的 inode 号完全相同(263466)- 硬链接数变为 2(在
-rw-r--r--.后面的那个数字)
删除文件时发生了什么?
删除文件时,系统做了两件事:
- 在目录中删除该文件名对应的记录
- 将 inode 中的硬链接计数减 1
只有当硬链接计数变为 0 时,系统才真正释放 inode 和数据块。
所以 Linux 中"删除文件"的操作准确叫"解除链接(unlink)"。
📌 知识点总结
硬链接的本质就是给同一个 inode 起多个不同的名字。删除任意一个"名字"只是删除目录中的一条记录,只要还有别的名字指向这个 inode,文件数据就还在。只有当所有硬链接都被删除(链接计数归零),文件才被真正从磁盘上抹去。ls -l 输出中第二列显示的就是硬链接数。
4.2 软链接
原理
软链接(符号链接)和硬链接不同,它通过文件名引用目标文件,而不是通过 inode。
示例
bash
# 创建原始文件 abc
touch abc
# 创建软链接 abc.s 指向 abc
ln -s abc abc.s
# 查看详细信息
ls -li输出结果:
263466 -rw-r--r--. 2 root root 0 abc
261678 lrwxrwxrwx. 1 root root 3 abc.s -> abc可以看到:
abc和abc.s的 inode 号不同(一个是 263466,另一个是 261678)abc.s的文件类型是l(link),表示这是一个软链接abc.s的文件大小是 3 个字节,刚好等于abc这个字符串的长度- 权限是
lrwxrwxrwx(软链接的权限通常是 777,但实际权限由目标文件决定)
📌 知识点总结
软链接是一个独立的文件,有自己的 inode 和数据块。它的数据块里存储的是目标文件的路径名(字符串)。访问软链接时,操作系统会自动"跳转"到这个路径。软链接的用途类似于 Windows 的"快捷方式"------它可以跨分区、跨文件系统,甚至指向一个不存在的文件(创建后目标被删除,软链接就变成"断链")。
4.3 软硬链接对比
| 对比项 | 硬链接 | 软链接 |
|---|---|---|
| inode 号 | 与原文件相同 | 与原文件不同(独立文件) |
| 跨分区 | 不可以 | 可以 |
| 跨文件系统 | 不可以 | 可以 |
| 链接目标被删除 | 文件数据还在(其他硬链接仍可访问) | 变成"断链",无法访问 |
| 对目录链接 | 不可以(但 . 和 .. 是特例) |
可以 |
| 本质 | 文件名 → inode 的额外映射 | 独立的文件,内容存的是路径 |
📌 知识点总结
硬链接是 inode 层面的链接,软链接是文件名层面的链接。硬链接不能跨分区、不能链接目录,但更"稳固"------只要还有一个硬链接存在,文件数据就不会丢。软链接可以跨分区、可以链接目录,但目标被删除后就变成"死链接"。
4.4 软硬链接的用途
硬链接的用途
-
目录中的
.和..就是硬链接.指向当前目录..指向父目录- 这也是目录的硬链接数至少为 2 的原因
-
文件备份
- 创建硬链接实现"即时备份",不占用额外磁盘空间
- 只在原文件被彻底删除时才占用空间的特性,适合做快照
软链接的用途
- 快捷方式------就像 Windows 的桌面快捷方式
- 简化路径------将长路径映射为短路径
- 版本管理 ------如
linux -> linux-5.10.1,更新时只需改链接指向 - 跨分区引用------硬链接做不到的事,软链接可以
📌 知识点总结
硬链接的典型应用是目录中的 . 和 ..,以及文件快照备份------多个名字共享同一个 inode,不额外占用磁盘空间,删除任何一个都不影响其他名字。软链接则像 Windows 的快捷方式,灵活轻便、可以跨分区,适合做路径简化和版本切换。两者各有适用场景,理解它们的区别能在实际工作中做出更合适的选择。
总结:完整的数据访问流程
通过以上学习,我们终于可以串起一条完整的数据访问链路:
用户输入路径 → 路径解析(逐层查找目录)→ dentry 缓存加速
→ 找到目标文件的 inode → 读取 inode 属性
→ 通过 i_block[] 找到数据块 → 读取文件内容整个过程涉及的关键概念:
| 概念 | 作用 |
|---|---|
| 扇区 | 磁盘读写的最小单位,512 字节 |
| 块 | 文件系统管理的最小单位,通常 4KB |
| 分区 | 将磁盘划分为独立区域 |
| 块组 | ext 文件系统划分分区的基本单元 |
| 超级块 | 文件系统全局信息 |
| inode | 存储文件属性 |
| 数据块 | 存储文件内容 |
| dentry | 路径缓存 |
| 挂载 | 将分区与目录树关联 |
| 硬链接 | 多个文件名共享同一 inode |
| 软链接 | 一个文件存储另一个文件的路径 |
📌 知识点总结
从磁盘物理结构到文件系统逻辑,从 CHS 到 LBA,从 inode 到数据块,从路径解析到挂载,从软硬链接到实际用途------这就是 Ext 系列文件系统的完整知识体系。核心思想可以归纳为一句话:磁盘是硬件,文件系统是软件,文件系统的作用就是把硬件的存储能力包装成方便用户使用的文件和目录结构。理解了这一整套机制,你就掌握了 Linux 文件系统的"底层密码"。
