
5 月 25 日至 29 日,面壁智能与 OpenBMB 联合举办「端侧大模型开源周」,每天解锁一个端侧大模型的杀手锏。端侧大模型的顶峰,不只在冰山一角,而在整座冰山。今天是开源周的第一弹:低比特大模型训练成果 BitCPM-CANN。
面壁智能联合清华大学、OpenBMB开源社区,在清华大学鲲鹏昇腾科教创新卓越中心的支持下,今天 正式发布并开源其在低比特大模型训练方向的最新成果------BitCPM-CANN。
这款中国首个完全基于国产算力平台(华为昇腾)实现端到端训练并开源的三值(1.58-bit)大模型,继日前(5 月 23 日)在华为鲲鹏昇腾开发者大会(KADC 2026)完成首次技术亮相后,今日正式将其全系列模型向全社会开放。
目前,该模型已正式开源并上线 AtomGit AI:
🔗 模型开源地址:
https://ai.atomgit.com/collections/OpenBMB/2058756028210290689
从量化算子、训练算法到全链路框架,BitCPM-CANN 均在 华为昇腾上原生完成,包含 0.5B、1B、3B、8B 四个模型尺寸,与同尺寸 MiniCPM4 全精度家族逐项对照评测,性能表现优异。
相比传统 BF16 精度,BitCPM-CANN 在推理阶段 释放约 6 倍显存红利 ,同时将模型能力保留率维持在 90%-- 97.2 %。
手机内存大小决定了可同时运行的「专家」数量,进而决定了可承载的模型总规模。
同样的设备内存,可以承载远超以往的模型能力;或者反过来说,同样的模型能力在同一款终端上运行,只需要过去 1/6 的内存 ------这意味着,未来有望在手机上运行 60B 大模型,手机的智能会大幅提升。
「2-bit」是近一年来端侧芯片行业的热门研究话题,也是在手机上运行更大参数模型的最大技术卡点之一。
2-bit 量化将模型权重压缩 6-8 倍,使其能存入手机闪存,如 4GB 内存能放 16B,再配合 MoE 与激活范围约束、能放 32B;若内存扩大到 8GB,则能将模型参数扩大到 60B。
在内存价格飞涨、端侧设备资源始终受限的情况下,低比特量化成为手机厂商未来市场竞争力的「斩杀线」------大模型能力持续进化,谁能最早用更低的成本将手机做得更智能,谁就能掌握大模型时代的主动权。
BitCPM-CANN 的亮相,标志着面壁智能高效大模型「小钢炮」在端侧落地的能力进一步跃升,同时也通过开源向中国端侧大模型赛道提交了一份新的答卷。
6 倍显存红利,打破端侧 AI 天花板
长期以来,内存的物理瓶颈------包括容量、带宽与成本------是大模型走向规模化应用,尤其是深入手机、PC、汽车等端侧设备时最严峻的挑战。
高盛近期大幅上调预期,AI 服务器引爆的半导体需求链中,存储涨幅最高被看至 280%,内存正在成为全球 AI 供应链中最紧张的资源之一。
针对这一问题,行业的传统解法是后训练量化(Post-Training Quantization,PTQ),即先用高精度(如 BF16)完成模型训练,再将其权重压缩至 INT8 或 INT4。
这本质上是一种「事后补救」,一种「以精度换内存」的工程妥协,压缩越狠,性能损失越大。
BitCPM-CANN 彻底颠覆了这一路径。
它采用的是技术门槛更高、但效果也更优越的 **量化感知训练(Quantization-Aware Training,QAT)**路线------模型并非在训练完成后才被动压缩,而是在训练的初始阶段,就主动学习如何用 1.58-bit 的三值权重(-1,0,+1)来承载和表达知识。
这不再是简单的精度丢弃,而是从根本上让模型在极低比特位宽的约束下「原生生长」,迫使每一个 bit 发挥出最大的信息密度和知识承载效率。
换言之,权重精度不再取决于位宽大小,而是取决于每 bit 承载了多少知识。也因此,低比特训练不再只是一种节省显存的工程手段,而是一种全新的权重知识承载范式。
根据 BitCPM-CANN 与同尺寸 MiniCPM4 全精度模型家族在常识、阅读理解、学科知识、数学与推理等 11 项任务上的 1:1 性能对照,四个模型规模 0.5B、1B、3B、8B的评测结果如下:
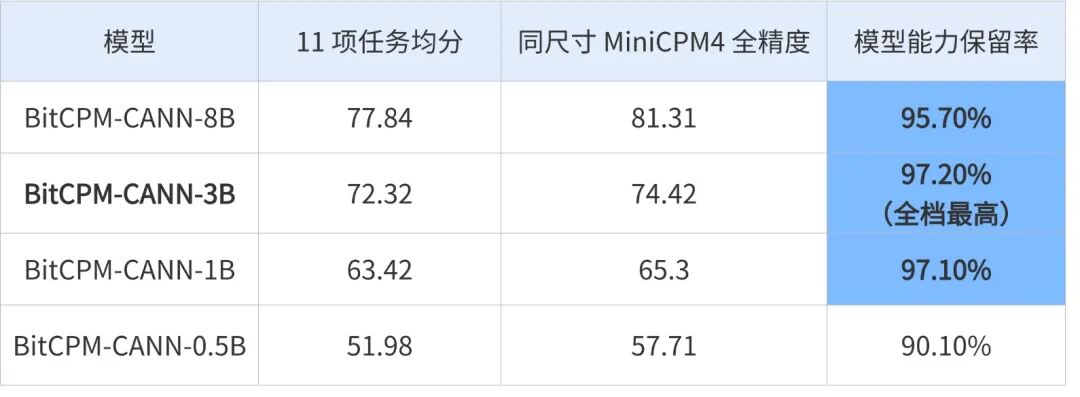
从评测结果看,BitCPM-CANN 三个尺寸模型的能力保留率达到 9 5.7 %---9 7.2 % 区间;即使是能力保留最弱的 0.5B,保留率也达到了 90% 以上**(90.1%)。**
这个结果表明:低比特训练的技术路线具备系统性、可扩展性和工程可复现性。
这一范式转变,对手机与芯片等行业的影响是具体而颠覆性的:
对手机产业来说,6 倍的显存红利意味着,一个 8B 参数的 BitCPM-CANN 大模型,可以轻松运行在当前主流旗舰手机之上。
若进一步结合混合专家(MoE)架构,将 50B 乃至 100B 参数的超大模型装入终端,这一在 BF16 时代近乎天方夜谭的设想,如今已拥有了清晰的实现路径。
这无疑将端侧 AI 的能力天花板提升到了全新的高度!PC、汽车等终端也同理。
对芯片生态来说,今年 2 bit 是所有主流端侧芯片厂商的追求,已有部分芯片厂商支持 2-bit 推理,BitCPM-CANN 补全了模型侧的空白。
例如,以高通骁龙8 Gen 4为代表的新一代端侧芯片,已在硬件层面原生支持 2-bit 推理。然而,硬件的就绪需要高质量、可直接落地的低比特模型来匹配。
BitCPM-CANN 精准填补了端侧芯片在低比特模型「供给侧」的巨大空档,为软硬件协同发展提供了关键的弹药。
对 AI 应用来说,内存成本急剧下降。
在全球 HBM(高带宽内存)价格因 AI 服务器需求激增而持续飙升的背景下,BitCPM-CANN 提供的 6 倍显存优化,是一份无需额外硬件投入的、实实在在的「降本方案」。
它允许企业在不增加物理内存的情况下,大幅提升模型能力或服务密度,有效对冲了供应链成本压力。
基于昇腾,攻克国产算力极低比特训练难题
BitCPM-CANN 的另一个重磅意义,在于它 完全基于国产算力平台完成训练。
从最底层的量化算子、QAT(量化感知训练)算法,到完整的并行策略和训练框架,BitCPM-CANN 的整个训练链路均在华为昇腾上原生完成。
这是昇腾平台上 首个 公开的、 端到端完成 1.58- bit 训练 并进行 全精度对照评测 的成果,且模型规模一次性推进至 8B 级 别。
这项技术的门槛远超「把一个 GPU 上训好的模型搬到昇腾上跑推理」。过去,国产 NPU 阵营验证低比特训练,通常需要先在 CUDA 上完成再迁移,链路漫长且损耗巨大。
BitCPM-CANN的成功,意味着 国产 NPU 阵营第一次拥有了自己的 1.58-bit 低比特训练栈。
面壁智能基于 MindSpeed × Megatron-LM 主干搭建了完整的低比特训练底座,包含环境适配、32K长序列支持、并行策略、融合算子等完整工程体系。从此,所有面向昇腾的低比特训练工作,都可建立在同一套公共基础设施之上。
BitCPM-CANN 用事实回答了一个行业关切的问题:昇腾不仅能训大模型,更能完成世界级的极低比特训练。
「 国产芯片只能跑推理 」 的刻板印象, 从此可以正式 翻篇。
端侧大模型:底层功夫决定上层高度
作为「小钢炮」的新成员,低比特大模型 BitCPM-CANN 不是一次孤立的技术路线尝试,而是面壁智能在端侧大模型上的多年技术积累与率先探索爆发。
受终端内存、计算、网络、功耗、散热等多因素的约束,端侧大模型的能力高度在很大程度上取决于算法底层的 Infra 创新根基。自 2022 年自研分布式训练框架 BMTrain 以来,面壁智能在打造端侧大模型地基上,已扎根四年------几乎与 ChatGPT 掀起的大模型热潮期完全重叠。
从训练框架 BMTrain,到稀疏架构 InfLLM,再到低比特量化训练方法BitCPM、推理框架 CPM.cu 等等,面壁智能始终致力于构建体系化的高效端侧大模型方案。
早在 2024 年下半年,在业界对极低位宽 QAT 尚未形成共识时,团队就选定了 ≤2bit 的 QAT 路线------这是一次直接领先于行业的判断。此前在 GPU 上发布的 BitCPM 系列,在发布时即为全球同尺寸最领先的三值模型,BitCPM 1B 全面超越了 BitNet 2B,并且只使用了 1/20 的训练算力,训练效率显著优于微软 BitNet 等一类方案。
为什么要在 1.58-bit / 2-bit 这条看起来极端的路线上持续投入?
因为它同时击中了大模型落地最现实的两类约束------**显存容量与带宽的物理瓶颈,以及端侧部署对参数密度的持续追求。**这两个约束不会随硬件进步而消失,只会随模型变大变得更紧迫。
从 MiniCPM 到 BitCPM-CANN,面壁智能在端侧 AI 上的信念始终没有变:不是等硬件变得足够强大来适应模型,而是让模型变得足够聪明来适应硬件。
除此之外,面壁智能专注于对底层硬件的极致优化,此前曾参与协助华为昇腾、鲲鹏,以及寒武纪、天数智芯等国产芯片构建和优化软件栈,由此建立了对国产芯片生态的独特认知积累,并一直致力于实现「国产 NPU + 国产模型 + 国产训练框架」的完整闭环;
基于上述积累,BitCPM-CANN 并非将一项孤立技术移植到昇腾平台,而是将面壁智能已在 GPU 上系统验证的 QAT 训练方法、2-bit 模型路线与训练效率优势,整体推进至国产 NPU 的完整训练底座中,进一步回答这条路线能否在昇腾上形成端到端、可复用、可持续扩展的基础设施。
端侧大模型的性能潜力释放,离不开模型厂商与芯片厂商的共同投入。在这个重要的 AGI 赛道,面壁智能的追求从来不止于参与,而是致力于成为端侧 AI 技术的推动者与构建者。
坚持开源,系统验证
BitCPM-CANN 的发布与开源,实现了国产 NPU、国产模型、国产训练框架的完整闭环,为端侧 AI 产业提供了直接可用的低比特模型方案。
但一项技术路线的真正价值,不在于某个孤立尺寸上跑出的漂亮数字,而在于其系统性、可扩展性与工程可复现性。
为此,面壁智能联合 OpenBMB 开源社区,选择以透明、严谨的方式,将 BitCPM-CANN 全面开源。
希望能为开发者零门槛体验国产算力在低比特场景的真实性能,并在此基础上进行二次创新。
每一 bit 都不该被浪费。我们诚邀全球开发者,共同加入这场探索 AI 效率极限的旅程。
目前,BitCPM -CANN 0.5B / 1B / 3B / 8B 全系列模型权重现已开源并入驻 AtomGit AI,欢迎下载、复现与共建 :
🔗 模型开源地址:
https://ai.atomgit.com/collections/OpenBMB/2058756028210290689