大模型训练两大问题
效率问题: 时间
数据量大,如何快速完成训练
显存问题:物理
模型太大,如何在GPU上完成运算
那么怎么解决效率问题,显存问题?
并行训练
第一种:
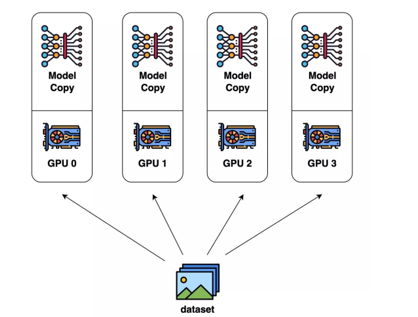
数据并行 DP(提效的手段)
复制模型到多个GPU
各自计算梯度后累加,再反传更新
需要单卡就能训练整个模型(显存够大)
如图,假如有4个gpu,把1000分数据均分到4个gpu上,一个250份,但是会出现4个不一样的梯度,因为相当于分到4个模型上来训,那么权重更新就会出现4个梯度,那肯定不行
那怎么完成?
算完梯度之后,有一个通讯过程,将所有梯度,传到一个上面,然后汇总求平均,更新一个卡,然后其他卡再同步
但是有时,模型较大,做不到一张卡容纳一个模型
第二种:
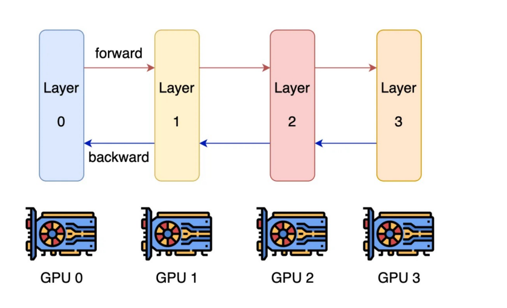
模型并行PP(解决显存不足的手段)
将模型的不同层放在不同的gpu上
解决单块不够大的问题(模型比显存大)
需要更多的通讯时间(卡之间互相传输数据)
但是,transformer中,q,k,v 这种大型矩阵运算,参数太多卡放不下怎么办
第三种:
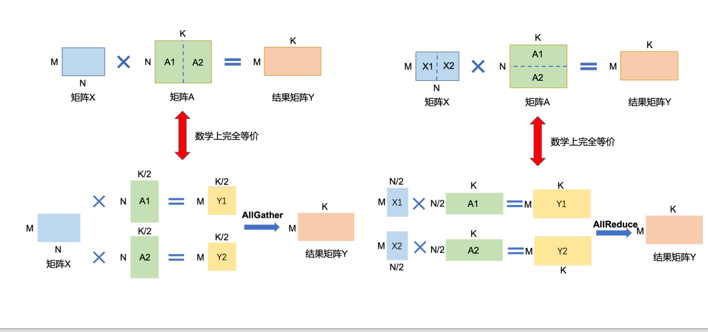
张量并行TP
将张量划分到不同GPU上进行运算
进一步减少对单卡显存的需求
需要更多的数据通讯
第四种:
混合并行:
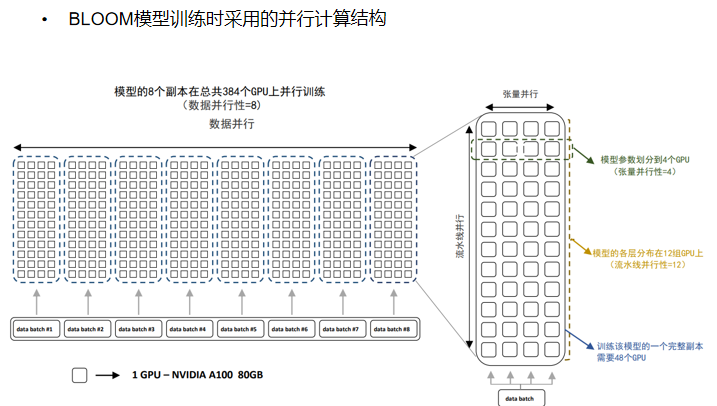
降低模型训练,还可以采用一些其他方法
混合精度
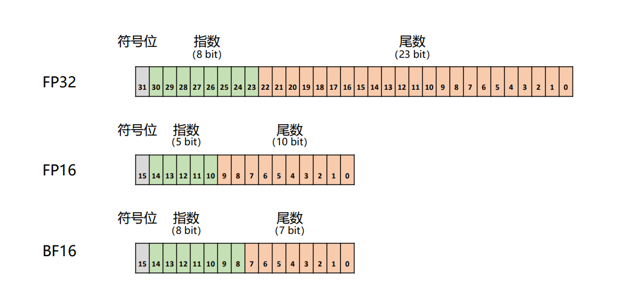
计算机的底层是二进制,只有0和1,所有的数字在计算机中都能有0和1表示出来,包括浮点数
根据x和这个公式可以得到 S,M是多少
在机器学习中主要用BF16
高精度转低精度会造成损失,低精度转高精度会加大空间消耗
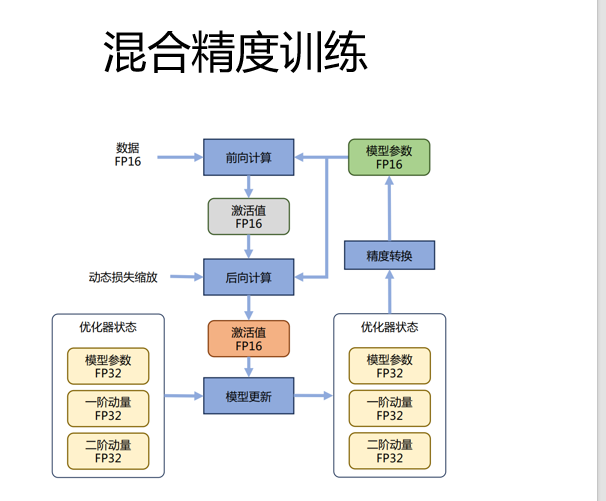
所以在训练的时候采用混合训练
更新权重的时候用FP32,在其他比如前向计算时用FP16,在优化器中保留高精度,模型参数也保留一份高精度,然后转化为低精度,虽然会造成写精度损失但是可接收

deepspeed 零冗余优化器 ZeRo
尽可能减少每一块显存的占用
设置了几个阶段的模式
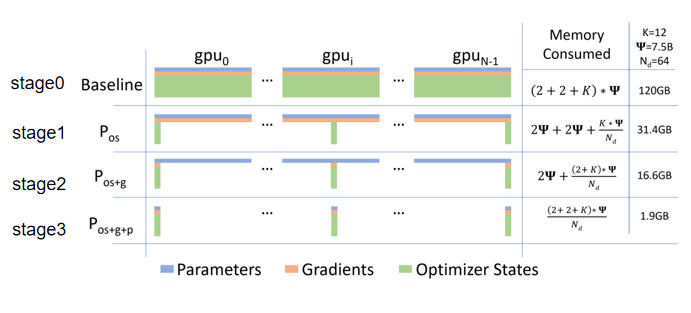
stage0:
本质上时数据并行,每个gpu包含模型的所有信息,包括模型的参数(蓝色的),梯度(黄色的),优化器内的权重,这样可以在每一块卡上完成梯度计算和反向传播
stage1:
就是把优化器内所有的参数(优化器用的高精度的值), 然后把参数均分到每一个gpu上,
stage2:
进一步把模型梯度均分到gpu
stage3:
把模型的参数均分到每一个卡上了
从上到小,单块显存的空间占用越来越少,但是训练速度也逐渐增加
ZeRO-offload
把一部分计算放到内存中,用CPU计算目的是解决显存不足问题,在CPU做运算的速度低于GPU慢
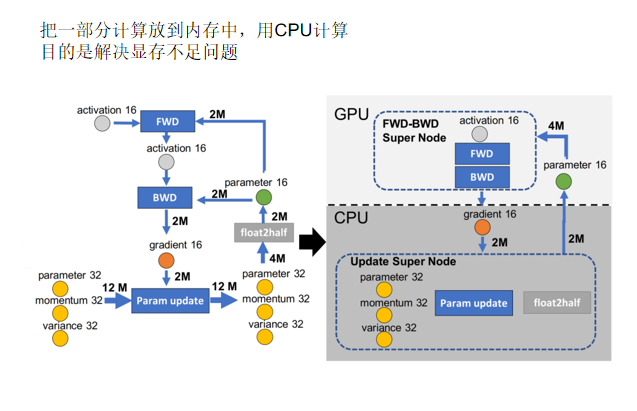
策略对比

PEFT微调(Parameter- Effcient Fine-Tuning)
当训练整个大模型不能实现时,可以采取的一种策略
通过最小化微调参数的数量缓解大型预训练模型的训练成本
Adapter
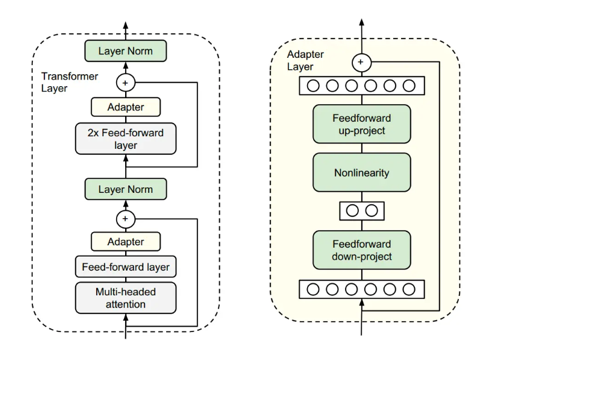
比一般的transformer增加了2个Adapter模块,模块内部为右边的图
把高维向量映射成低维向量,非线性激活,然后再升维
在训练的时候冻结 Multi-headed attention 和Fedd-forward layer 以及 2*Fedd-forward layer,参数不再变化,变化Adapter Layer中的参数
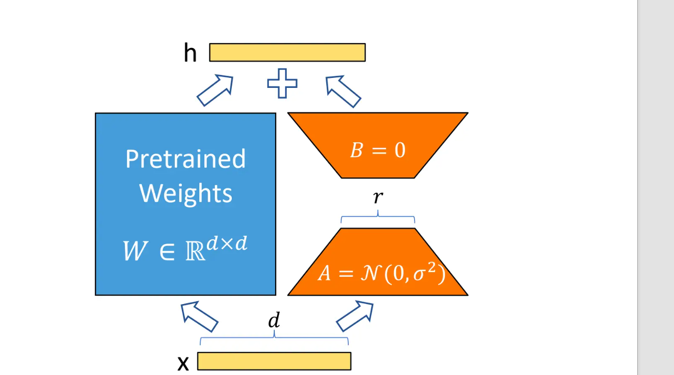
LoRA
在transformer中有很多线性层,在任一一个线形层旁边都可以选择加上一个黄色矩阵的分值,这两黄色矩阵 一个是升维,一个是降维,r则是降到r维,左边冻结,两加起来当作线性层的输出
A是正太分布初始化,B则是全0初始化, 为什么?
为了一开始让x进来的时候,B为全0,结果依旧是0,加起来对结果依旧是x,和模型原本输出一致,然后再微调,不至于结果遍历太远