目录
- 一、线程互斥
-
- 1.1、相关概念回顾
- 1.2、互斥量Mutex
- [1.3、 锁的原理](#1.3、 锁的原理)
- 二、线程同步
-
- 2.1、为什么引入同步?
- 2.2、条件变量
- 2.3、条件变量实例
- 2.3、POSIX信号量
- 2.4、生产者消费者模型
-
- 总结:"321"原则
- [2.4.1 基于阻塞队列的生产消费模型](#2.4.1 基于阻塞队列的生产消费模型)
- [2.4.2 基于环形队列的生产消费模型](#2.4.2 基于环形队列的生产消费模型)
- 三、总结
引入
同一个进程下的线程共享虚拟地址空间,即共享资源。这让线程之间天生具有通信的条件,但同时面临着共享资源带来的数据不一致,数据竞争等问题,所以引入了线程同步互斥来解决,让线程进行安全的数据读写。
一、线程互斥
1.1、相关概念回顾
共享资源: 能够被多个进程或线程看到的资源。
临界资源: 一次只允许一个执行流访问的共享资源,即被保护起来的共享资源。
临界区: 访问临界资源的代码就是临界区。
互斥 其实我们也并不陌生,即任意时刻只有一个执行流访问临界资源。
原子性: 两种状态,要么不做,要么一次性做完。
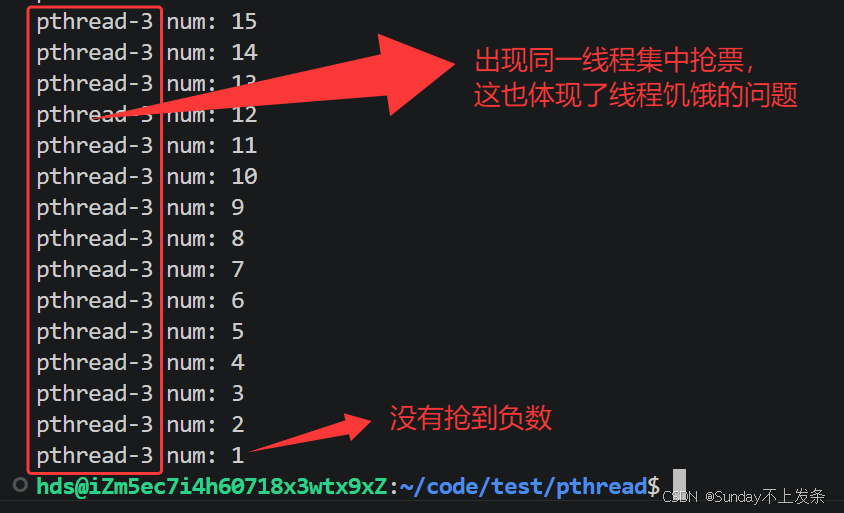
抢票实例演示:
下面我们通过一个多线程抢票的例子,直观感受一下这种数据不一致带来的后果:
cpp
#include <iostream>
#include <unistd.h>
#include <pthread.h>
#include <vector>
int num = 1000; // 共1000张票
void *routine(void *args)
{
std::string name = static_cast<char *>(args);
while (true)
{
if (num > 0) // 有票抢票
{
usleep(1000); // 故意制造时间窗口让竞争更容易发生。
std::cout << name << " " << num << std::endl;
--num; // 票数--
}
else
break; // 票抢完了,退出
}
return nullptr;
}
int main()
{
// 创建线程
std::vector<pthread_t> pthread;
for (int i = 1; i <= 4; i++)
{
pthread_t tid;
char buff[128];
snprintf(buff, sizeof(buff), "pthread-%d", i);
pthread_create(&tid, nullptr, routine, buff);
pthread.push_back(tid);
}
// 回收线程
for (auto &p : pthread)
pthread_join(p, nullptr);
return 0;
}正常我们看到的结果就应该是,票被抢到0,结束!!!
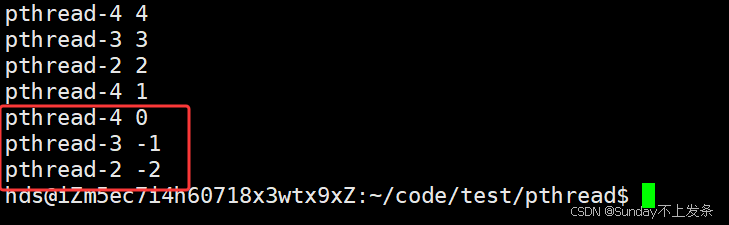
票竟然被干到了负数,为什么呢?
因为此时票数num作为临界资源,判断票数是否为0这部分代码就是临界区,我们没有对临界区做任何的限制或保护,导致多线程将票数干到了负数。
而本质其实是:--num这个操作并不是原子的。
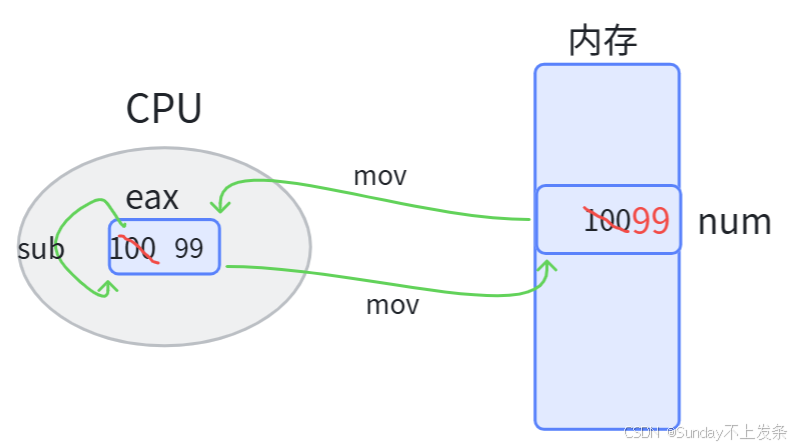
CPU执行--num操作:先从内存将num读到exa寄存器,然后执行sub操作,最后覆盖式写入内存。底层其实是由三条汇编代码实现的,这就使得--num不是原子的,如果是一条汇编,那就是原子的。
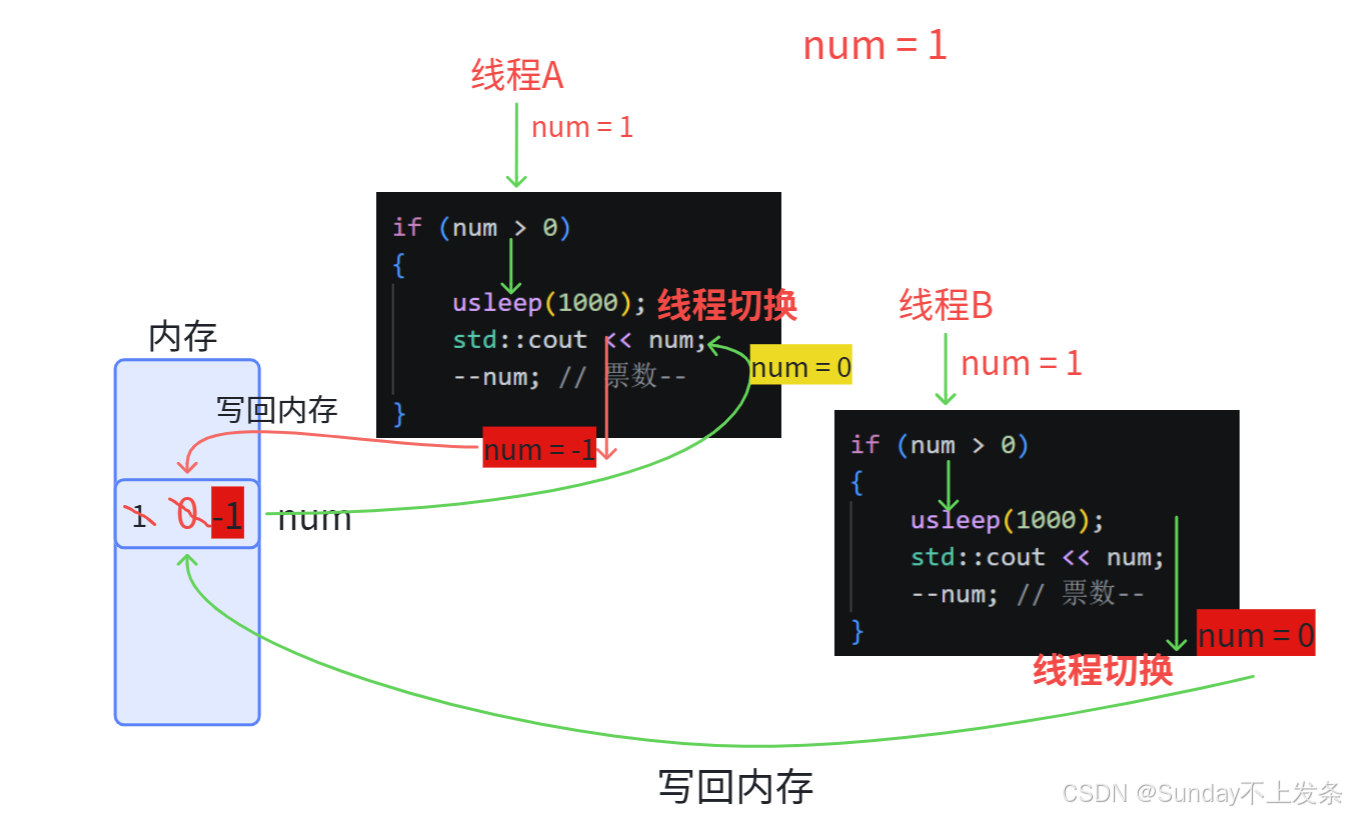
由于--num,并不是原子的,而且判断num > 0这个操作也不是原子的 ,导致了抢票抢到了负数。
怎么解决这种问题呢?让临界区对临界资源的访问变成原子的不就行了。
1.2、互斥量Mutex
互斥量其实就是锁,本质就是对临界区进行保护,变相保护临界资源。对临界区加上锁,就可以保证在任意时刻只会有一个线程访问临界资源,保证了原子性。
互斥量接口
创建和加锁
- 创建,即初始化,有两种方法:
- 静态分配:在全局创建
c
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER- 动态分配:在代码块内部创建
c
int pthread_mutex_init(pthread_mutex_t *restrict mutex,
const pthread_mutexattr_t *restrict attr);第二个参数:设置互斥量的属性的指针,nullptr即默认属性。
- 加锁

c
pthread_mutex_lock(&mutex); // 加锁
// 临界区
{
//...
}
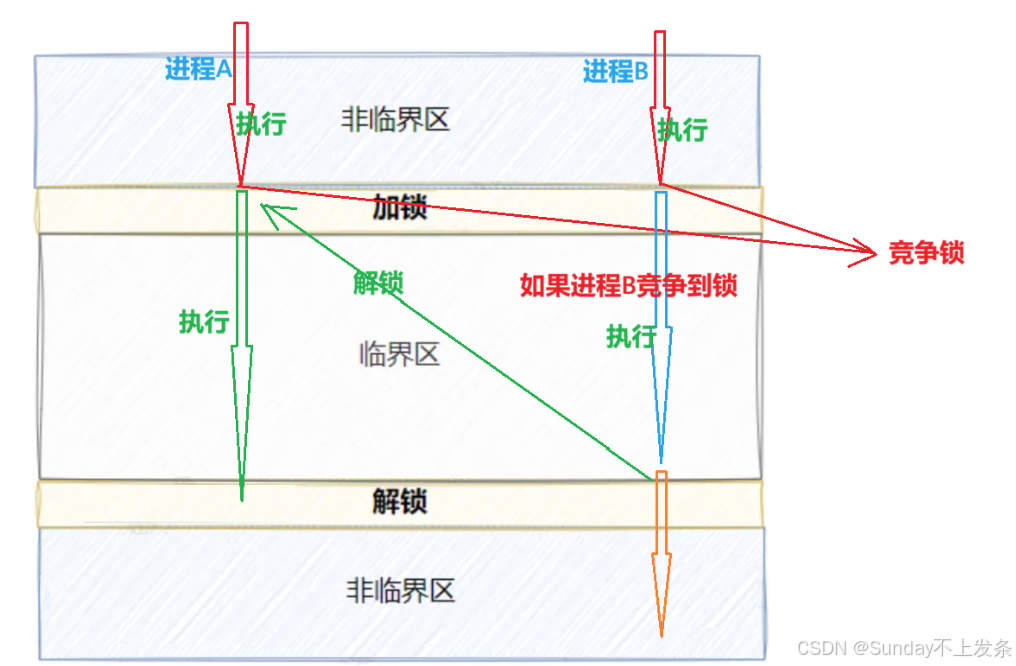
pthread_mutex_unlock(&mutex); // 解锁加锁之后,线程进入临界区访问临界资源就需要先申请锁。如果申请成功,就进入临界区;否则就会将该线程放入到该锁对应的等待队列,直到锁被unlock,操作系统就会唤醒队头的锁,直接拥有锁,进入临界区。
这个机制,听着似乎很公平,但如果线程A在unlock之后又立马去申请锁,就会和线程B竞争,这有什么问题?
当然,线程A此时就在CPU上运行,不需要切换上下文,直接去抢锁,而线程B在阻塞队列,需要OS唤醒,CPU调度,准备抢锁,这个过程耗费的时间显然比线程A 多。那么线程A 有更大概率再次获得锁,就会造成线程饥饿的问题。
怎么解决!!!就需要用到线程同步的知识。
销毁回收
c
int pthread_mutex_destroy(pthread_mutex_t *mutex);- 销毁互斥量需要注意:
- 使用PTHREAD_MUTEX_INITIALIZER初始化的互斥量(锁),不需要手动释放。
- 不要销毁一个已经加锁的互斥量。
- 已经销毁的互斥量,要确保后面不会有线程再尝试加锁。
改善上面的售票系统:
我们已经知道了,num作为共享资源,但num > 0和num--等操作不是原子的,那么在访问时就会出现将票干到负数的情况。那么我们就对临界区进行加锁,保证其原子性。
cpp
pthread_mutex_lock(&mutex); // 加锁
if (num > 0) // 有票抢票
{
usleep(1000); // 故意制造时间窗口让竞争更容易发生。
std::cout << name << " " << num << std::endl;
--num; // 票数--
pthread_mutex_unlock(&mutex); // 解锁
}
else
{
pthread_mutex_unlock(&mutex); // 解锁
break; // 票抢完了,退出
} 
1.3、 锁的原理
锁也是共享资源,多个线程竞争锁,即访问临界资源,是不是也需要对锁加锁呀!!! 当然不是,不然不成了鸡生蛋,蛋生鸡了。
竞争锁在底层只有一条汇编,保证了竞争锁的原子性 ,不需要加锁(保护)。具体我们看下面的lock和unlock的底层原理就明白了。

竞争锁核心就xchgb %al,mutex 一条汇编,即 交换 内存中mutex和寄存器al的值,当mutex = 1表示锁未被占用,mutex = 0表示锁被占用。
**注意:**是交换而不是拷贝!!!
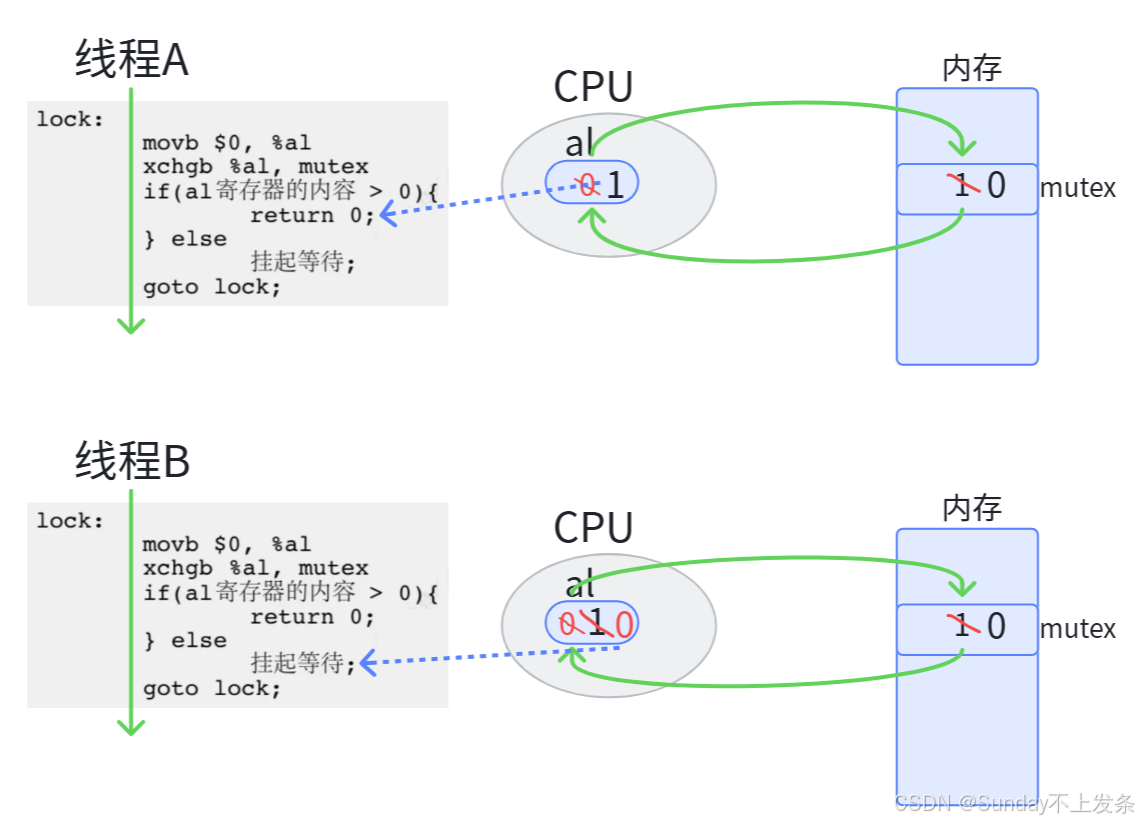
线程A,B竞争锁,由于竞争锁本身是原子的,只有一个线程获得锁,当线程A获得锁后,内存中mutex被置为0,而当线程B再次申请锁时,会先将al寄存器的值清0,此时线程B无论怎样交换mutex的值,都是0,就会进入阻塞队列。
当线程A将锁unlock,线程B获得锁。

二、线程同步
2.1、为什么引入同步?
因为线程互斥有缺陷:
当线程A释放锁后,再次去申请,很大概率比阻塞队列中的线程先得到锁,就会导致线程饥饿问题。这对于其他线程而言是不公平的,而且也不高效,所以引入线程同步,两者配合使用才更加公平高效 。
同步,即在数据安全的前提下,让线程按一定的顺序访问临界资源,有效避免了饥饿问题。可以理解为一个线程释放锁之后不能立马去再申请锁,不就轮到队头线程了嘛!!!
2.2、条件变量
条件变量本质就是一个线程的阻塞队列 ,条件不满足时,将线程加入到条件变量cond对应的阻塞队列。
注意: 这个过程必须是保证是原子的,因为如果线程A还没有进入阻塞队列,而此时线程B发送过了一个唤醒信号,就会丢失,所以使用条件变量,必须加锁。即,条件变量本身就是临界资源。
条件变量初始化
与互斥量类似,有两种方式:
- 静态分配:全局初始化
c
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;- 多态分配:局部创建
c
int pthread_cond_init(pthread_cond_t *restrict cond,
const pthread_condattr_t *restrict attr);等待条件满足
c
int pthread_cond_wait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex);第一个参数是条件变量cond,没什么好说的。
注意: 第二个参数为什么是mutex呢?
上面讲到,使用条件变量之前必须加锁,而当线程进入条件变量对应的阻塞队列,就必须先将锁加锁,不然线程拿着锁进入阻塞队列,锁就无法被解锁,其他线程永远无法拿到锁,不就是死锁嘛!!!所以将锁作为第二个参数,OS帮我们解锁。
唤醒线程
条件不满足时我们让线程进入条件变量的阻塞队列,那么不就保证线程不会再次申请锁了嘛。然后我们在需要的时候再从阻塞队列唤醒一个或多个线程,此时线程公平竞争锁,同时也保证了按顺序执行。
- 唤醒一个线程
c
int pthread_cond_signal(pthread_cond_t *cond);- 唤醒所有线程
c
int pthread_cond_broadcast(pthread_cond_t *cond);销毁
c
int pthread_cond_destroy(pthread_cond_t *cond);2.3、条件变量实例
cpp
#include <iostream>
#include <unistd.h>
#include <pthread.h>
#include <vector>
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; // 锁
pthread_cond_t cond = PTHREAD_COND_INITIALIZER; // 条件变量
void* routine(void* args)
{
std::string name = static_cast<const char*>(args);
while(true)
{
pthread_mutex_lock(&mutex); // 加锁
// 直接让线程进入阻塞队列等待
pthread_cond_wait(&cond, &mutex);
std::cout << "唤醒一个线程:" << name << std::endl;
pthread_mutex_unlock(&mutex);
}
}
int main()
{
std::vector<pthread_t> pthread;
for(int i = 1; i <= 5; i++)
{
pthread_t tid;
char* buff = new char[64];
snprintf(buff, 64, "pthread-%d", i);
pthread_create(&tid, nullptr, routine, buff);
std::cout << buff << std::endl;
pthread.push_back(tid);
}
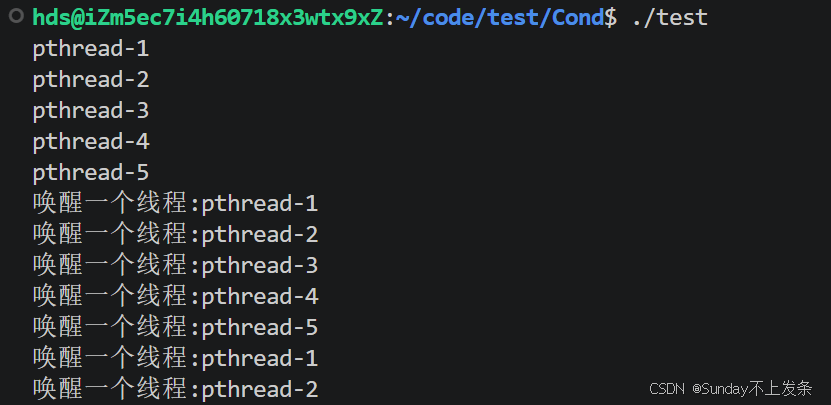
while(true)
{
pthread_cond_signal(&cond); // 在cond对应的阻塞队列中唤醒一个线程
sleep(1);
}
// 回收新线程
for(auto& p : pthread) pthread_join(p, nullptr);
return 0;
}
2.3、POSIX信号量
前面我们在system V中简单介绍了信号量,而POSIX的信号量功能与其几乎一模一样,都是用于同步操作,只是归属不同的标准。但POSIX可以用于线程间同步。
信号量本质: 一个计数器,表示资源的数量。但这个计数器绝非一个整数,因为我们已经知道整数加减不是原子的。
信号量如何保证线程的同步?
线程访问资源,即对计数器--,当资源不足时,线程进入信号量对应的阻塞队列等待;访问结束线程归还资源,再对计数器++,OS从阻塞队列唤醒一个线程。对应信号量的P和V操作,且这两个操作是原子的,这样就保证了线程顺序访问共享资源(同步)。
信号量即对资源的预定机制!!!
补充:二元信号量(互斥锁),最常用!!!
c
// 初始化:sem = 1
P(sem); // sem--到0,再有线程就会阻塞
// ...
// 访问共享资源(比如共享内存)
// ...
V(sem); // 离开临界区:sem++到1,唤醒等待进程保证任意时刻只有一个线程访问共享资源。
信号量初始化
c
int sem_init(sem_t *sem, int pshared, unsigned int value);参数:
- pshared:0表示线程间共享,非零表示进程间共享
- value:信号量初始值,即资源个数
P & V操作
- P操作:申请资源(信号量--)
c
int sem_wait(sem_t *sem);- V操作:归还资源(信号量++)
c
int sem_post(sem_t *sem);销毁信号量
c
int sem_destroy(sem_t *sem);2.4、生产者消费者模型
生产者消费者模型是一种多线程并发的设计模式。 具体解决什么问题呢?
举个栗子: 假设工厂直接对消费者,没有经销商。
那么,消费者想买手机 ->打电话给工厂 ->工厂专门加工这一个手机 ->完事叫消费者来拿,这无疑效率低下,成本高。如果,
- 工厂产能波动,而订单暴增,工厂生产不过来,消费者等到崩溃;
- 消费者需求零散,工厂无法规划生产;
- 双方强耦合,必须互相知道地址,电话等。
如果引入经销商:
此时工厂只管生产,经销商从工厂进货保证足够的库存,消费者只需要从特定的地方(超市,商场等)按需购买,两者解耦合,生产与消费可以并发进行,提高了效率。
生产者消费者模型就是在生产与消费数据之间加了一个缓冲区,可以是队列等特定数据结构。生产者只需要生产数据,放入缓冲区,满了就阻塞;消费者只需要从缓冲区消费数据,空了就阻塞,两者完全解耦。
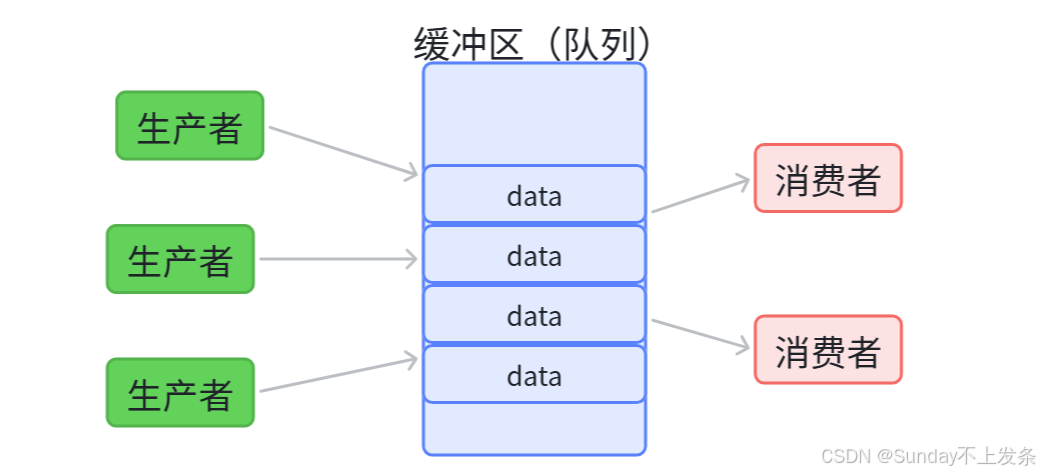
生产者消费者模型优势:
- 生产与消费解耦;
- 支持忙闲不均,即生产与消费速度不匹配
- 并发,提高效率
并行:多个CPU,多个线程在严格意义同时运行。
并发:只有一个CPU,不能做到严格意义上的同时运行。生产者-消费者模型通过快速切换+阻塞等待实现逻辑并发: 生产者生产完通知消费者,但消费者不一定"立马"执行,而是进入就绪队列等待调度。这种"你阻塞时我干活,我阻塞时你干活"的协作,让CPU利用率最大化,看起来像同时运行,实际是高效串行。
需要注意,由于此时缓冲区是共享资源,就要避免多线程同时向缓冲区写数据或从缓冲区读数据,而造成数据不一致,混乱的问题。所以,我们必须保证对缓冲区的访问是原子的,因而不得不引入互斥量(锁),条件变量和信号量等措施。实际上就是要保证三组关系:
- 生产者与生产者之间互斥:不能同时向缓冲区写
- 消费者与消费者之间互斥:不能同时从缓冲区读
- 生产者与消费者之间同步与互斥:写满等消费者读,读空等生产者写;消费者正在读时写等,生产者正在写时读等。
总结:"321"原则
3:三种关系
2:两种角色
1:一个交易场所
2.4.1 基于阻塞队列的生产消费模型
在多线程编程中阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构 。其与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出。
实现这样一个生产消费模型,本质上就是维护其3种关系,2个角色,1个交易场所。对于同步互斥我们利用锁和条件变量实现,生产者和消费者由线程充当,交易场所用C++中的队列即可。
注意一点: 队列为满时,生产者阻塞;队列为空时,消费者阻塞。所以,我们需要两个条件变量,对应生产者阻塞队列和消费者阻塞队列。
具体代码以及细节,大家可以移步我的Gitee代码仓库:点击这里哟!!!
2.4.2 基于环形队列的生产消费模型
不同于阻塞队列版本的生产消费模型,我们采用信号量+环形队列(数组)来实现,此时,单生产者单消费者模型与多(单)生产者多(单)消费者模型有一些区别。
注意: 这里的环形队列并不是单链表,或双链表。而是一个vector数组,我们对数组下标进行 i %= size操作,即当越界时又立马回到下标0,维护一个逻辑上的环形队列。
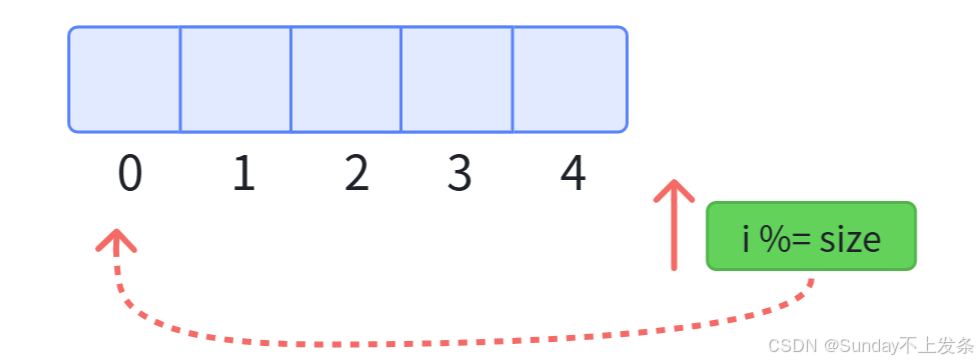
首先,对于环形队列而言,需要遵守以下规则:
- 队列为空,读阻塞;
- 队列为满,写阻塞;
- 生产者不能把消费者套圈(数据覆盖);
- 消费者不能在生产者前面。
要实现生产者在队列为满时阻塞,消费者在队列为空时阻塞,同样需要两个信号量。对于生产者,资源数就是队列中空位置的个数;对于消费者,资源个数就是队列中数据的个数。 那么,两个信号量应该分别表示队列空位置个数与队列中数据个数。
同时,要维护环形队列结构,我们需要记录生产者和消费者当前所在的位置(数组下标),读或写完数据,就需要pos++,并pos %= size。
结合上面的内容,可以得到两个非常重要的结论:
- 生产者和消费者只有在队列为空或已满时处于同一个位置;
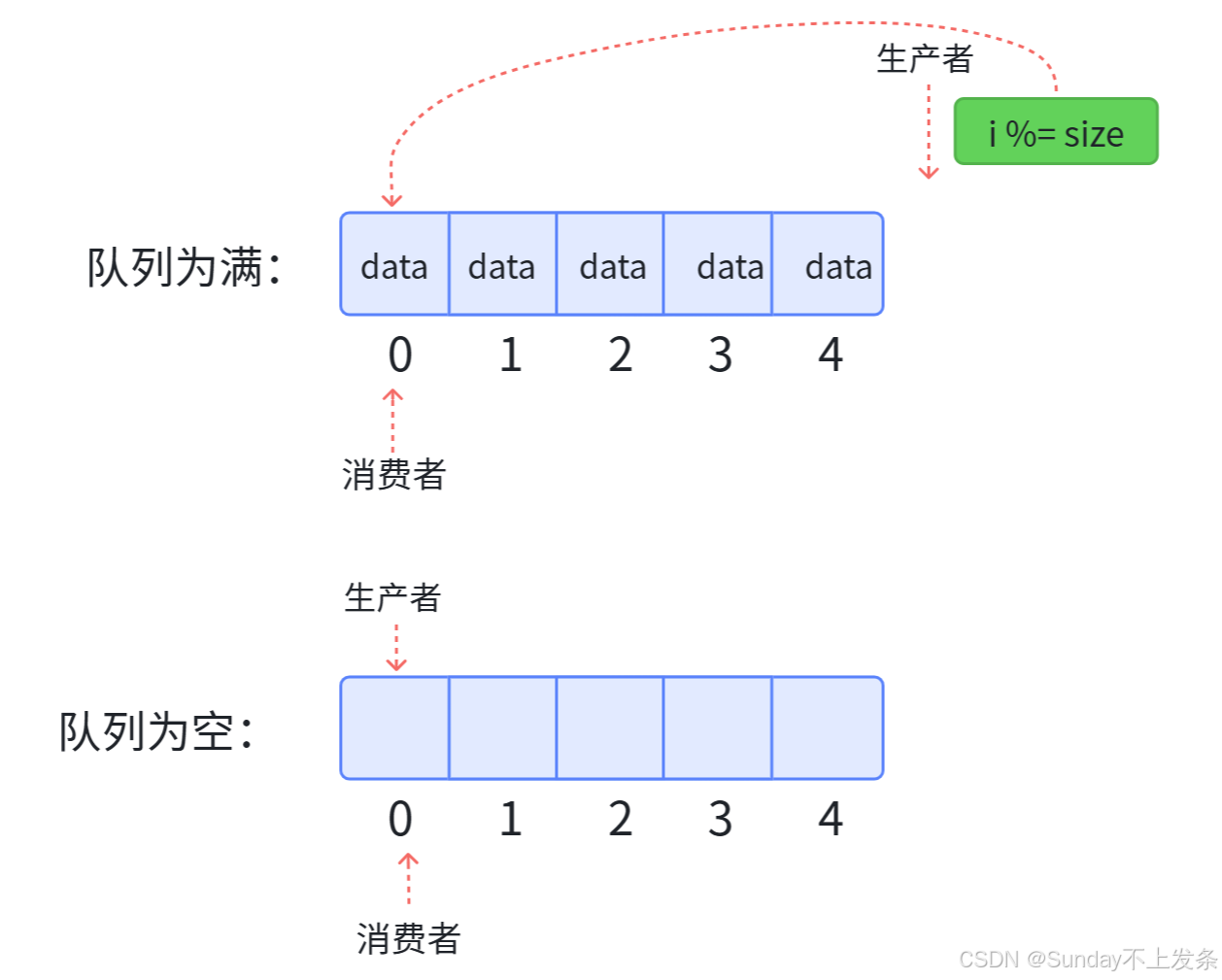
- 只要队列不为空或满,生产者和消费者一定不在同一个位置
为什么??????
假设,生产者对应信号量为
blank_sem,所在位置为p_pos;消费者对应信号量为data_sem,所在位置为c_pos。P操作与V操作是原子的。刚开始,队列为空,data_sem = 0,p_pos = c_pos = 0,消费者肯定在阻塞队列。只有当生产者写入一个数据,此时,data_sem = 1(V操作),p_pos = 1,如果唤醒一个消费者读数据,那么data_sem就会减到0(P操作),c_pos = 1,但此时,消费者再次进入阻塞队列,而生产者继续生产数据,p_pos++,所以,生产者与消费者在队列不为空或满时,永远不可能在同一个位置。
这不就是生产者与消费者天然的具有互斥关系嘛!!!
又由于信号量自带阻塞队列,只有又空位置,生产者就会生产数据,队列不为空,消费者就来读,所以又有了同步关系!!!
对于单生产者单消费者模型,321原则完全具备。但对于其他模型,如多生产者多消费者模型,就还需要维护生产者与生产者,消费者与消费者之间的互斥关系,只要引入两把锁即可。
同样的,具体代码以及细节,大家可以移步我的Gitee代码仓库:
单生产者消费者模型
多生产者多消费者模型
三、总结
3.1、线程安全与重入问题
概念
线程安全:
多个线程在访问共享资源时,能够正确地执行,不会相互干扰或破坏彼此的执行结果。
保证线程安全: 互斥锁,原子操作,不共享,数据隔离...
重入:
同一个函数被不同的执行流调用,当前一个流程还没有执行完,就有其他的执行流再次进入,我们称之为重入。一个函数在重入的情况下,运行结果不会出现任何不同或者任何问题,则该函数被称为可重入函数,否则,是不可重入函数。
例如,malloc 和 new 内部访问全局堆空闲链表,并使用全局互斥锁保证线程安全;在信号处理等中断场景下,函数可能在未执行完时被再次调用(重入),导致递归加锁死锁,因此它们不可重入
两者的联系
可重入一定是线程安全的,但线程安全不一定可重入。
如果将对临界资源的访问加上锁,则这个函数是线程安全的,但如果这个函数内部使用了互斥锁,当函数执行中途被中断(信号 / 异常),再次进入该函数时,锁尚未释放,再次申请同一把锁就会死锁,因此不可重入。
3.2、死锁
概念及场景
两个或多个线程互相等待对方释放资源,永远阻塞下去。
实例:假设我们对临界区加两把锁,线程A与线程B想要访问临界资源,就需要同时拥有两把锁。
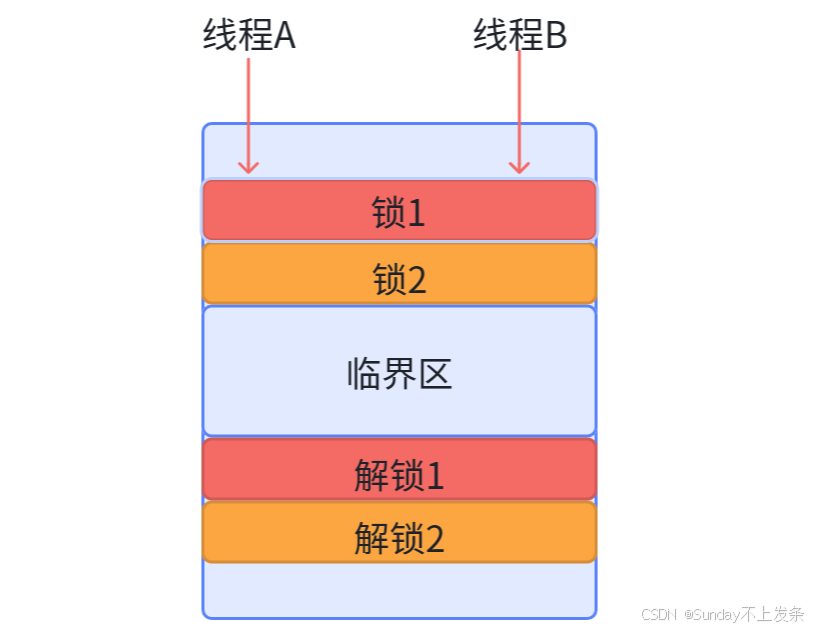
假设此时,线程A持有锁1,线程B持有锁2,当线程A再申请锁2时,由于锁2被线程B持有,而形成B也在申请锁1,导致锁2无法被解锁,此时线程A进入锁2的阻塞队列,同理,线程B进入锁1的阻塞队列,永远阻塞,即死锁。
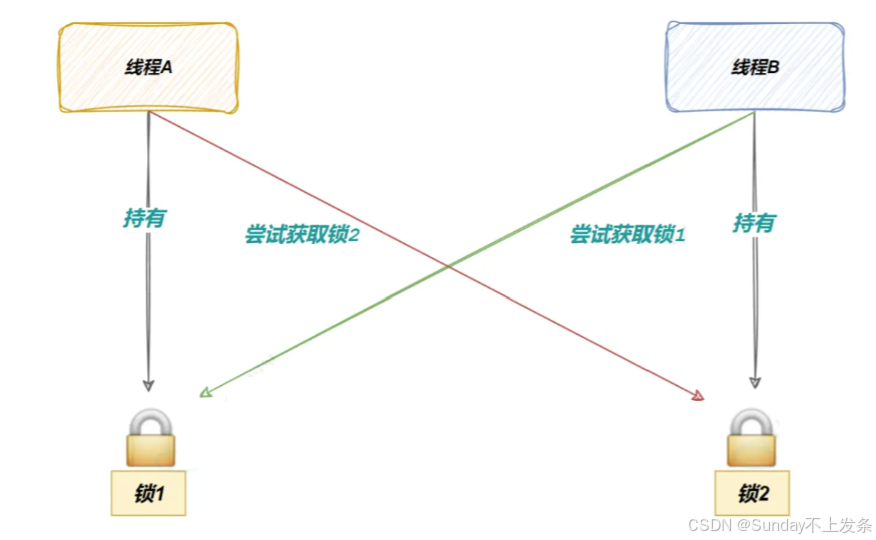
死锁形成的必要条件
- **互斥条件:**一个资源只能被一个执行流拥有;
- **请求与保持条件:**一个执行流请求某资源,而另一个执行流抓住该资不放,执行流阻塞;
- **不剥夺条件:**一个执行流获得资源后,未使用完之前不会被强行剥夺;
- **循环等待条件:**若干执行流之间形成一种头尾相接的循环等待资源的关系。
那么如何避免死锁呢?
既然是必要条件,那我们只需要败坏其中一个或几个条件即可。
3.3、STL,智能指针和线程安全
- STL 容器
标准STL容器(vector、map、list等)不是线程安全的。STL 的设计初衷是将性能挖掘到极致,而一旦涉及到加锁保证线程安全,会对性能造成巨大的影响。如果需要多线程使用,必须在外部手动加锁保护。
**示例:**两个线程同时向vector执行push_back,可能触发重分配时的内存混乱,这是典型的数据竞争。 - 智能指针
shared_ptr的引用计数操作是线程安全的(使用原子指令),但它指向的对象内容不是线程安全的。
unique_ptr是独占所有权,不可复制,移动后原指针失效,不存在多线程共享问题,也就不涉及线程安全问题。
weak_ptr不增加引用计数,专门用于打破shared_ptr的循环引用。
线程内容的分享到此结束,下一篇博客我会带大家手撕一个线程池项目,实战运用一下线程及相关知识,再次感谢大家的阅读!!!