基本面试:
做过最满意的项目是什么?项目背景?为什么要做这件事情?最终达到什么效果?你处于什么样的角色,起到了什么方面的作用?在项目中遇到什么技术问题?具体是如何解决的? 如果再做这个项目,你会在哪些方面进行改善?
基础扎实:IT行业,哪些发展好的同学都是具备扎实基础知识,如果理解计算机基础会更好,因为我们面临很多非前端计算问题的。
主动思考:被动完成任务成长会很慢的,需要有自己的想法,而不是仅仅是完成任务的。
自动学习 :前端领域知识淘汰速度很快,需要经常学习新知识。
追溯深度:遇到问题是多研究背后深层次的原因,而不是绕过去。如遇到一个bug,有时间一定要理解本质原因。
宽阔视野:创新往往来自不同领域的交集,如果理解更多领域,就会有更多的想法。
学习总结:谈到某个技术的时候,需扪心自问,学这个是为了做什么?如何学习的?可以从什么渠道了解最新的知识?
目录概览
-
- 一、基础概念题(必问)
-
- [1、简单说说你理解的大语言模型(LLM)、生成式 AI、AIGC](#1、简单说说你理解的大语言模型(LLM)、生成式 AI、AIGC)
- [2、前端和 AI 常见结合场景有哪些?](#2、前端和 AI 常见结合场景有哪些?)
- [3、什么是 Prompt(提示词)?前端为什么要关注提示词工程?](#3、什么是 Prompt(提示词)?前端为什么要关注提示词工程?)
- [4、简述 Token 是什么?和前端有什么关系?](#4、简述 Token 是什么?和前端有什么关系?)
- [二、前端调用 AI 接口(高频实操)](#二、前端调用 AI 接口(高频实操))
-
- [1、前端如何调用大模型 API?流式输出(SSE)和普通轮询区别?](#1、前端如何调用大模型 API?流式输出(SSE)和普通轮询区别?)
- [2、AI 流式输出常见问题及前端解决方案?](#2、AI 流式输出常见问题及前端解决方案?)
- [3、前端请求 AI 接口,如何做安全和权限控制?](#3、前端请求 AI 接口,如何做安全和权限控制?)
- 4、什么是上下文(Context)?前端如何管理对话上下文?
- [三、Web AI / 前端本地 AI(热点面试题)](#三、Web AI / 前端本地 AI(热点面试题))
-
- [1、什么是 Web AI?模型跑在浏览器有什么优缺点?](#1、什么是 Web AI?模型跑在浏览器有什么优缺点?)
- [2、简单介绍 Transformers.js 能做什么?](#2、简单介绍 Transformers.js 能做什么?)
- [3、前端加载本地 AI 模型如何优化加载速度?](#3、前端加载本地 AI 模型如何优化加载速度?)
- [四、RAG 检索增强生成(中高级必考)](#四、RAG 检索增强生成(中高级必考))
-
- [1、什么是 RAG?解决了大模型什么问题?](#1、什么是 RAG?解决了大模型什么问题?)
- [2、前端在 RAG 系统中承担哪些工作?](#2、前端在 RAG 系统中承担哪些工作?)
- [3、简述 RAG 完整链路(从用户提问到回答)](#3、简述 RAG 完整链路(从用户提问到回答))
- [五、AI + 前端工程化 & 性能体验](#五、AI + 前端工程化 & 性能体验)
-
- [1、AI 对话页面常见性能优化点](#1、AI 对话页面常见性能优化点)
- [2、如何实现 AI 代码高亮、代码块复制?](#2、如何实现 AI 代码高亮、代码块复制?)
- 3、多轮对话如何做状态管理(Vue/React)?
- [六、场景面试题(问答 + 实操)](#六、场景面试题(问答 + 实操))
-
- [1、需求:做一个 AI 智能客服,逐字输出回复,你技术选型和实现思路?](#1、需求:做一个 AI 智能客服,逐字输出回复,你技术选型和实现思路?)
- [2、需求:做浏览器本地 AI 图片抠图,不用后端,怎么实现?](#2、需求:做浏览器本地 AI 图片抠图,不用后端,怎么实现?)
- [3、遇到 AI 接口响应慢、超时,前端如何处理?](#3、遇到 AI 接口响应慢、超时,前端如何处理?)
- 七、手写代码题(面试手撕)
-
- [1、手写简易 SSE 接收 AI 流式消息](#1、手写简易 SSE 接收 AI 流式消息)
- 2、简单封装对话上下文截断(控制最大消息数)
- [八、拔高 / 开放性问题(高级前端 / AI 前端负责人)](#八、拔高 / 开放性问题(高级前端 / AI 前端负责人))
- [九、AI 前端面试题【精简背诵版】](#九、AI 前端面试题【精简背诵版】)
一、基础概念题(必问)
1、简单说说你理解的大语言模型(LLM)、生成式 AI、AIGC
- AIGC: 人工智能生成内容,利用 AI 自动生成文本、图片、语音、代码、视频等内容。
- 生成式 AI: 区别于传统判别式 AI(分类 / 检测),通过模型学习数据分布,主动创造全新内容。
- LLM(大语言模型): 基于 Transformer架构、海量文本训练的大型模型,擅长理解、对话、总结、推理、代码生成,是当前前端对接最多的 AI 模型。
2、前端和 AI 常见结合场景有哪些?
- 对话机器人 / 智能客服、AI 聊天助手
- AI 代码助手、代码解释、Bug 排查
- 文生图 / 图生图、海报 / 头像生成
- 智能文案、翻译、摘要、润色
- 语音转文字、文字转语音(ASR/TTS)
- 前端本地 Web AI(模型跑在浏览器)
- RAG 知识库问答、文档智能解析
3、什么是 Prompt(提示词)?前端为什么要关注提示词工程?
Prompt 是发给大模型的指令 + 上下文 + 问题,决定模型输出质量。
前端侧需要:
- 封装规范、易懂的提示词模板,统一交互风格
- 做角色设定、格式约束、输出限制,避免模型乱输出
- 动态拼接用户输入、历史对话、业务上下文
4、简述 Token 是什么?和前端有什么关系?
Token 是大模型的最小文本单元(字 / 词 / 子词),模型按 Token 计费、限制上下文长度。
前端关注点:
- 控制输入 + 历史对话 Token 总数,防止超出模型上下文窗口报错
- 超长文本做分段、截断、摘要,降低 Token 消耗与接口耗时
- 预估 Token 数量,做前端提示、限流。
二、前端调用 AI 接口(高频实操)
1、前端如何调用大模型 API?流式输出(SSE)和普通轮询区别?
主流调用方式:HTTP 接口 + SSE 流式推送
- 普通 POST 请求: 一次性接收完整结果,等待久、体验差,适合短文本。
- SSE(Server-Sent Events): 服务端持续向前端推送数据流,逐字输出,就是常见的 "打字机效果",AI 对话标配。
- WebSocket: 双向通信,适合高并发、实时交互场景。
SSE 简单代码示例
javascript
// 浏览器原生 SSE
const source = new EventSource('/api/ai/chat');
source.onmessage = (e) => {
// 逐段接收 AI 返回内容
console.log(e.data);
};
source.onerror = () => {
source.close();
};2、AI 流式输出常见问题及前端解决方案?
- 乱码 / 分段不完整: 后端按 \n 或特定分隔符分片,前端拼接后再渲染。
- 超长历史对话卡顿 / 超限: 前端维护对话窗口,自动截断旧消息、压缩上下文。
- 断流、重连: 增加重试机制、心跳检测。
- 界面抖动: 使用虚拟列表、防抖渲染。
3、前端请求 AI 接口,如何做安全和权限控制?
- 禁止前端直连大模型官方 Key: 密钥暴露会被盗刷,必须后端做接口中转。
- 接口加登录态、Token 鉴权、接口签名。
- 前端做输入内容过滤: 敏感词、特殊字符拦截。
- 限流: 单用户 / IP 限制调用频次,防止恶意刷接口。
- 超时处理: AI 生成较慢,前端设置合理超时、加载状态。
4、什么是上下文(Context)?前端如何管理对话上下文?
上下文 = 历史对话消息列表,模型依靠上下文理解多轮对话。
前端管理方案:
- 统一消息结构:{role: 'user', content: ''}, {role: 'assistant', content: ''}
- 设置最大轮数 / 最大 Token,超出则删除最早对话
- 支持清空上下文、新建会话
- 复杂场景:对历史消息做摘要压缩,减少 Token 占用
三、Web AI / 前端本地 AI(热点面试题)
1、什么是 Web AI?模型跑在浏览器有什么优缺点?
Web AI = 在浏览器 / 客户端本地运行轻量化 AI 模型(而非调用云端接口),
主流框架: Transformers.js、MediaPipe、ONNX Runtime Web。
优点:
- 隐私高:数据不上传服务器
- 无网络也可用
- 节省云端接口费用
- 低延迟
缺点:
- 受设备性能限制,大模型跑不动,只能用小模型
- 首次加载模型体积大,需做缓存、分片加载
- 移动端低端设备体验差
2、简单介绍 Transformers.js 能做什么?
Hugging Face 推出的 JS 库,可在浏览器 / Node.js 运行预训练模型,支持:
- 文本: 翻译、分类、摘要、问答
- 图像: 图片分类、抠图、检测
- 语音: 语音识别
- 无需后端: 纯前端完成 AI 能力
3、前端加载本地 AI 模型如何优化加载速度?
- 模型量化: 使用 INT8/FP16 轻量化模型,减小体积。
- 浏览器缓存: 利用 HTTP Cache、IndexedDB 缓存模型文件。
- 分片加载、懒加载: 进入对应功能再下载模型。
- CDN 加速模型静态资源。
- 加载进度条,提升用户感知。
四、RAG 检索增强生成(中高级必考)
1、什么是 RAG?解决了大模型什么问题?
RAG = 检索增强生成,流程:文档切片 → 向量化 → 向量库检索 → 拼接进 Prompt → 交给 LLM 回答。
解决大模型核心痛点:
- 知识幻觉:模型编造不存在信息
- 知识库更新慢:模型训练数据滞后,无法使用企业私有文档、最新资料
- 不支持私有业务数据问答
2、前端在 RAG 系统中承担哪些工作?
- 文件上传、解析(PDF/Word/ 文本)、预览
- 上传进度、解析进度展示
- 问答页面交互、历史问答管理
- 检索结果溯源(展示引用的原文片段)
- 长文档分段展示、分页
- 部分轻量化向量化 / 文本切片(简单场景)
3、简述 RAG 完整链路(从用户提问到回答)
- 用户输入问题 → 前端传给后端
- 后端对问题向量化
- 向量数据库检索相似文档片段
- 将问题 + 检索到的参考文档拼接成 Prompt
- 调用 LLM 接口生成答案
- 前端流式接收并渲染答案 + 引用来源
五、AI + 前端工程化 & 性能体验
1、AI 对话页面常见性能优化点
- 消息列表使用虚拟滚动,避免 DOM 过多卡顿
- 流式输出做分段渲染,不频繁整段重绘
- 图片 / 富文本懒加载
- 对话数据持久化到 LocalStorage/IndexedDB
- 防抖:防止用户连续重复提问
- 骨架屏、加载动画、空状态、错误兜底
2、如何实现 AI 代码高亮、代码块复制?
- 模型返回 Markdown 格式内容,前端使用 marked/markdown-it 解析
- 搭配 Prism.js / Highlight.js 实现代码高亮
- 代码块内增加一键复制按钮,使用 Clipboard API 实现复制
- 对长代码做折叠、滚动区域限制
3、多轮对话如何做状态管理(Vue/React)?
- Vue:Pinia/Vuex 统一管理会话列表、当前对话、加载状态
- React:Redux/Zustand/Context 管理全局对话数据
- 拆分状态:会话列表、单条消息、loading、错误、上下文
六、场景面试题(问答 + 实操)
1、需求:做一个 AI 智能客服,逐字输出回复,你技术选型和实现思路?
- 架构: 前端 + 后端中转 + LLM 接口,不暴露 API Key
- 通信: 使用 SSE 实现流式打字机效果
- 技术栈: Vue3/React + 组件库 + Markdown 解析
功能点:
- 消息结构区分用户 / AI
- 维护对话上下文,自动截断超长历史
- 加载状态、断流重试、错误提示
- 敏感词前端初步过滤
体验优化: 虚拟列表、消息动画、代码高亮、复制功能
2、需求:做浏览器本地 AI 图片抠图,不用后端,怎么实现?
使用 MediaPipe 或 Transformers.js 本地图像分割模型:
-
前端上传图片,渲染到 Canvas
-
调用本地 AI 模型做图像分割
-
模型返回蒙版数据,在 Canvas 合成抠图结果
-
支持下载图片、预览
优化: 模型预加载、进度提示、兼容低版本浏览器
3、遇到 AI 接口响应慢、超时,前端如何处理?
-
设置分级超时: 短请求 15s,长生成 30~60s
-
超时后友好提示,提供重新生成按钮
-
增加排队 / 等待提示: 告知用户 AI 正在生成
-
接口做降级:繁忙时切换备用模型 / 简化回答
-
禁止重复点击: 添加按钮置灰
七、手写代码题(面试手撕)
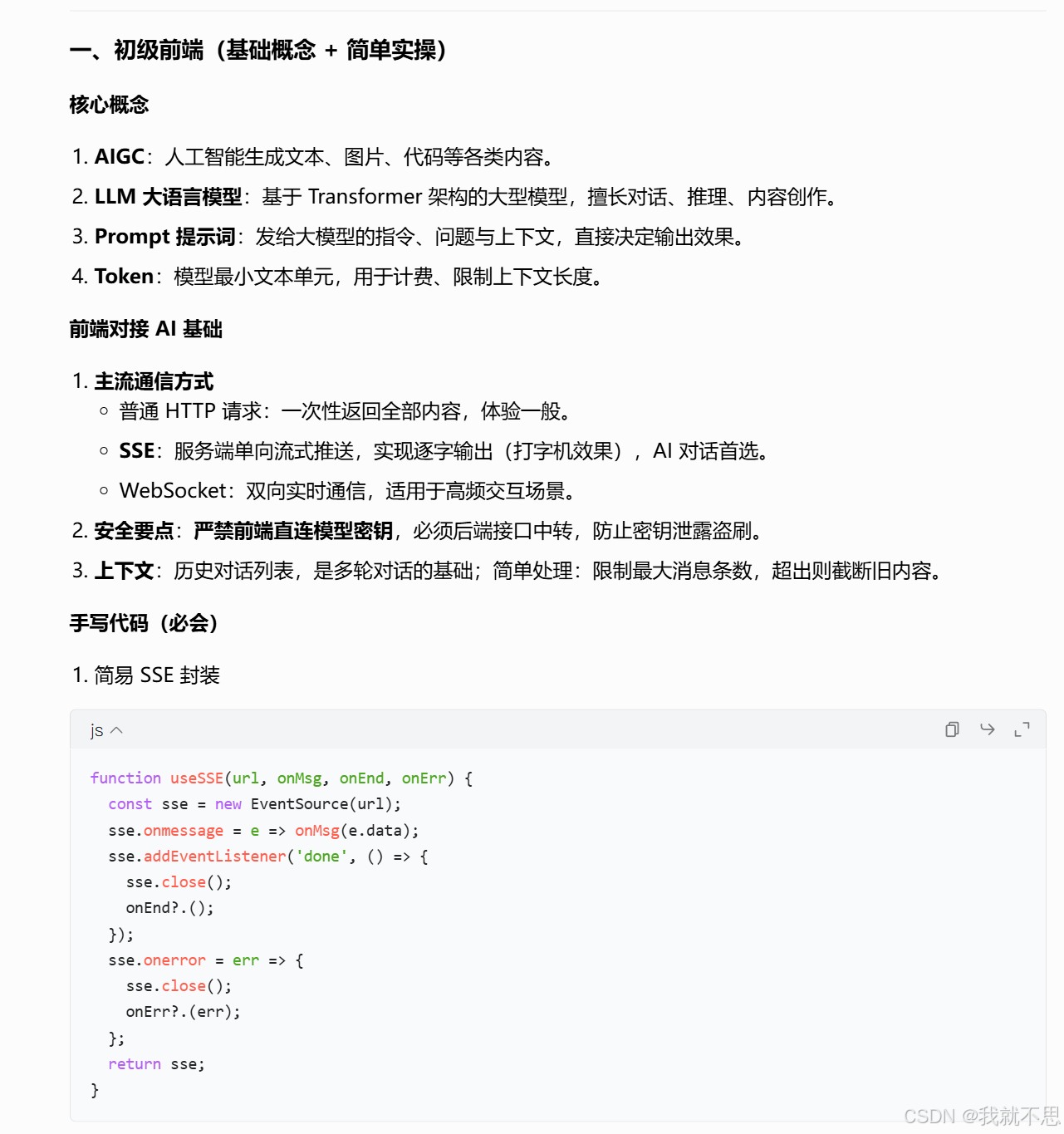
1、手写简易 SSE 接收 AI 流式消息
javascript
// 原生 JS 实现 SSE 流式接收
function createAIChat(url, onMessage, onEnd, onError) {
const sse = new EventSource(url);
sse.onmessage = (e) => {
onMessage(e.data);
};
sse.addEventListener('done', () => {
sse.close();
onEnd && onEnd();
});
sse.onerror = (err) => {
sse.close();
onError && onError(err);
};
return sse;
}
// 使用
const contentBox = document.getElementById('content');
let result = '';
const sse = createAIChat('/api/ai/stream',
(data) => {
result += data;
contentBox.innerText = result;
},
() => console.log('生成完成'),
() => alert('请求失败')
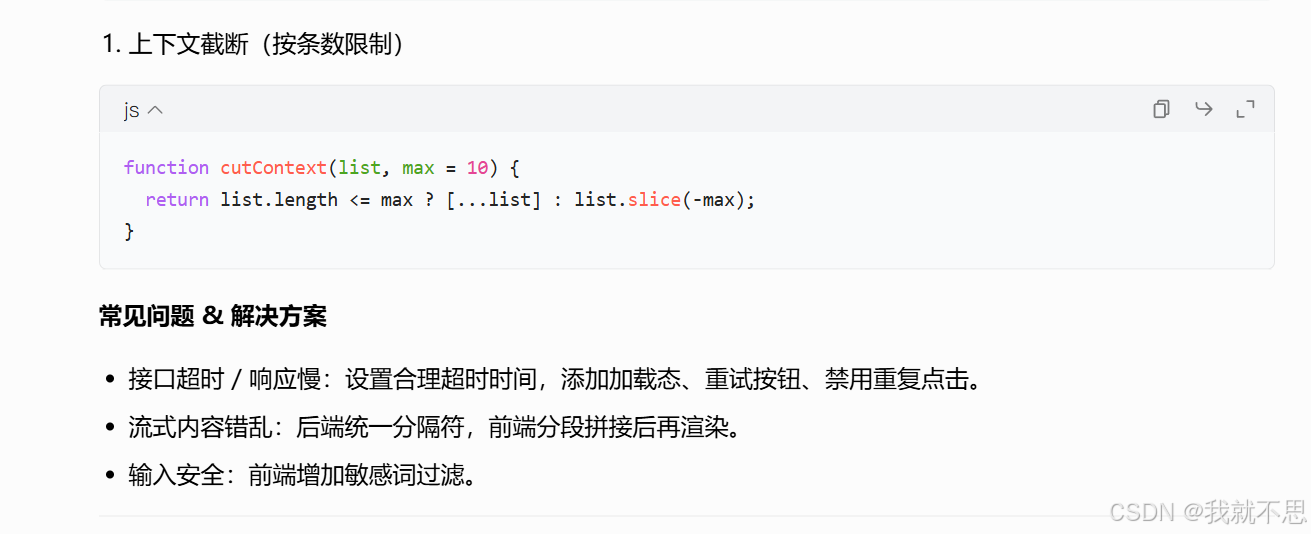
);2、简单封装对话上下文截断(控制最大消息数)
javascript
/**
* 截断对话上下文,保留最近 n 条
* @param {Array} messages 对话数组
* @param {number} maxLen 最大保留条数
* @returns 新数组
*/
function cutChatContext(messages, maxLen = 10) {
if (messages.length <= maxLen) return [...messages];
// 保留最后 maxLen 条
return messages.slice(-maxLen);
}八、拔高 / 开放性问题(高级前端 / AI 前端负责人)
你认为 AI 会对前端开发带来哪些改变?
答:代码编写效率提升、低代码 / AI 生成页面普及、前端岗位偏向AI 应用整合、体验优化、提示词工程、私有知识库搭建。
如何设计一套可复用的 AI 前端组件库?
答:拆分通用组件(对话气泡、流式渲染、代码块、上传解析、溯源面板),统一 SSE 请求、上下文管理、样式主题,支持多模型切换。
大模型并发高时,前端如何配合后端削峰?
答:前端限流、排队队列、请求合并、客户端缓存常见问答、静态知识库优先查询,减少直连 LLM。
九、AI 前端面试题【精简背诵版】
按初级、中级、高级分级,剔除冗余内容,直击考点,方便快速背诵