一句话解释
RAG,Retrieval-Augmented Generation,检索增强生成,是一种让大模型在回答前先从外部知识库检索相关资料,再基于检索结果生成答案的方法。
更直白地说:不要只让模型"凭记忆回答",而是让它先"查资料",再"带着资料回答"。
为什么最近变火
RAG 的正式命名通常追溯到 2020 年 Lewis 等人的论文 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks。但它真正成为 AI 应用开发中的高频词,是在 2023 年 ChatGPT 和企业大模型应用爆发之后。
原因很简单:大模型很会生成语言,却并不天然知道你的私有文档、公司制度、项目代码、数据库记录和最新业务变化。即使模型在训练时见过大量公开知识,它的知识也可能过时、不完整,甚至会在不确定时编造答案。
企业和开发者很快遇到几个现实问题:
- 公司知识库、合同、产品文档、客服手册不在模型训练数据里。
- 重新训练或微调大模型成本高,也不适合频繁变化的资料。
- 用户希望答案能引用来源,而不是只得到一段看似可信的文本。
- 长上下文模型虽然能塞入更多资料,但仍需要知道"该塞哪些资料"。
- 真实应用需要权限控制、审计、更新、可追溯,而不是一次性聊天。
RAG 正好提供了一个务实方案:把"知识存储"和"语言生成"分开。知识放在外部系统里,模型需要时检索;模型负责理解问题、整合资料、生成回答。
这让 RAG 成为大模型应用的第一批核心工程模式之一。它不要求你重新训练一个模型,就能让通用大模型接入企业私有知识、最新信息和可引用来源。
它解决了什么问题
- 知识过时:模型训练数据有截止时间,外部知识库可以持续更新。
- 私有知识缺失:企业文档、内部制度、代码仓库、客户记录可以通过检索提供给模型。
- 幻觉风险:让模型基于检索材料回答,可以降低凭空编造的概率。
- 答案可追溯:检索结果可以作为引用来源,方便用户检查。
- 微调成本高:很多知识更新不需要改模型参数,只需要更新索引。
- 上下文有限:不是把所有文档塞给模型,而是先筛选最相关片段。
- 权限与合规:检索层可以控制用户能访问哪些资料。
需要注意,RAG 不是"消灭幻觉"的魔法。它只是把模型回答的依据从内部参数扩展到外部知识。检索错了、资料过时、上下文拼接混乱、模型忽略证据,仍然会导致错误答案。
核心概念
1. 生成模型
生成模型通常是大语言模型,例如 GPT、Claude、Gemini、Llama、Mistral 等。它负责理解用户问题、阅读检索结果,并生成自然语言答案。
在 RAG 中,生成模型不是唯一主角。它更像一个会读资料、会总结、会解释的写作者。它写得好不好,取决于模型能力,也取决于给它的资料是否准确、完整、相关。
2. 检索器
检索器负责从知识库中找出和用户问题相关的内容。它可以基于关键词,也可以基于语义向量,还可以混合使用。
常见检索方式包括:
| 检索方式 | 核心思想 | 优点 | 局限 |
|---|---|---|---|
| 关键词检索 | 根据词项匹配,例如 BM25 | 对精确术语、编号、名称很有效 | 不理解同义表达和语义相似 |
| 向量检索 | 用 embedding 表示语义相似度 | 能找语义相关内容 | 可能忽略精确词、数字、过滤条件 |
| 混合检索 | 结合关键词和向量 | 兼顾精确匹配和语义匹配 | 系统更复杂,需要调参 |
| 图检索 | 利用实体、关系和知识图谱 | 适合复杂关系和全局总结 | 构建和维护成本更高 |
3. Embedding
Embedding 是把文本、图片、代码等内容转换成向量表示的方法。相似含义的内容,在向量空间中通常距离更近。
例如:
text
"如何申请年假?"
"年假审批流程是什么?"这两句话字面不完全相同,但语义接近。向量检索可以帮助系统找到相关制度文档。
为什么向量距离能表达语义
很多人第一次听到"用余弦相似度衡量句子语义"会觉得奇怪:几个浮点数怎么会知道两句话意思相近?
直觉可以从早期词向量讲起。Word2Vec、GloVe 训练时让"经常出现在相似上下文的词"在向量空间中相互靠近。结果就出现了那个著名的"king − man + woman ≈ queen"------性别维度、王室维度都被自动编进了向量的不同方向。
现代句子 embedding(如 BGE、E5、OpenAI text-embedding-3、Cohere Embed)规模更大、训练数据更多,但核心思想一致:用对比学习把"互相相关的内容"在向量空间拉近、把"无关内容"推远。在训练目标的反复打磨下,向量的不同维度会捕捉不同语义特征------话题、情绪、领域、是否是问句等等。
所以"向量距离 ≈ 语义距离"不是巧合,而是训练目标直接造成的。理解这一点,可以解释 RAG 工程里几条经验规则:
- 通用 embedding 在专业领域(法律、医疗、代码)效果可能不佳------训练数据没覆盖这种语义;
- 多语言场景下,要用专门训练过的多语种 embedding,否则跨语言相似度不可靠;
- 同一个查询用不同 embedding 模型会得到完全不同的检索结果------这不是 bug,是各模型对"相似"的定义不一样。
4. Chunk
Chunk 是把长文档切成较小片段。RAG 通常不会把整本手册直接放进索引,而是切成一段一段,方便检索和放入模型上下文。
切分看似简单,实际很关键。切得太短,片段缺少上下文;切得太长,检索不够精确,也浪费上下文窗口。好的 chunk 策略会考虑标题、段落、表格、代码块、章节结构和语义边界。
Chunk 的几个关键参数
经验数字(仅供参考,需要按业务评测调整):
- chunk size :常见经验值是 200-800 token。文本越规整、问答越细颗粒,可以越小;技术手册、合同条款这类需要完整段落的场景适合更大。
- overlap(重叠) :相邻 chunk 之间留 10-20% 的重叠,避免关键信息正好被切在边界上。比如一个 500 token 的 chunk 配 50-100 token 的 overlap。
- 切分单位:优先按"段落 → 句子 → 字符"层级切,避免在句子中间硬截断。代码用 AST 节点切、Markdown 用标题/段落切、表格按行切。
- 保留上下文 :除了 chunk 正文,最好在每段前面加上来源标题、章节路径(如
第 3 章 > 3.2 节 > 报销流程),这样模型读到 chunk 时知道它来自哪。
更高级的做法包括:
- Parent-Child Chunking:用小 chunk 做精确检索,命中后返回它所在的更大 parent 段落给模型,兼顾召回精度和上下文完整性;
- Semantic Chunking:用 embedding 找语义跳变点,让分块顺着语义边界而不是固定长度;
- Late Chunking:先对整篇文档做 embedding,再按位置切------保留全文上下文影响下的局部向量。
实际项目中,chunk 策略的好坏只能靠评测验证。两个 chunk 配置在不同领域语料上的检索召回率可能差几十个百分点。
5. Reranking
第一轮检索通常会召回多个候选片段,但它们不一定都适合最终回答。Reranking 会对候选结果重新排序,把更相关、更可靠的片段排在前面。
Bi-Encoder vs Cross-Encoder:为什么需要两步
理解 reranker 的关键,是看清"召回"和"精排"用的是两种不同的编码方式:
| 维度 | Bi-Encoder(双塔编码器) | Cross-Encoder(交叉编码器) |
|---|---|---|
| 编码方式 | Query 和 Doc 分别独立编码成向量 | Query 和 Doc 拼接后一起送进模型打分 |
| 计算时机 | Doc 向量可提前计算并存入向量库 | 必须在查询时实时计算 |
| 速度 | 快,单次查询毫秒级扫百万级文档 | 慢,每个候选都要跑一次模型 |
| 准确度 | 中,缺少 Query-Doc 交互信息 | 高,模型能直接看到两者关系 |
| 典型用法 | 向量库召回阶段(top-50 ~ top-200) | 精排阶段(重排成 top-3 ~ top-10) |
| 代表模型 | BGE、E5、text-embedding-3 | BGE-Reranker、Cohere Rerank、Jina Reranker |
工程上常见的两阶段流水线:
用户查询
Bi-Encoder 召回 top-100
Cross-Encoder 精排 top-5
送给 LLM 生成
为什么不直接用 Cross-Encoder?因为它无法预计算------每一对 (query, doc) 都要单独跑一次模型。对一个百万级文档库,单查询就要算百万次,完全不可行。Bi-Encoder 牺牲一点精度换百万倍速度,先把范围缩到 50-200 个候选,再让 Cross-Encoder 精排,这样质量和成本就能兼顾。
近年还出现了 late interaction 路线(如 ColBERT、ColPali),把每个 token 单独 embedding,检索时再做 token 级交互。它在质量和速度之间找了另一个折衷点,常用于高质量企业 RAG。
可以把检索分成两步:
- 召回:先尽量把可能相关的内容找出来。
- 重排:再精细判断哪些内容最值得给模型。
这和搜索引擎很像。第一步要"别漏掉",第二步要"排得准"。
工作原理
一个典型 RAG 系统分为两个阶段:离线建库和在线问答。
离线阶段负责准备知识库:
- 收集资料:PDF、网页、Markdown、数据库、代码、客服记录等。
- 清洗内容:去掉噪声、重复、导航栏、无意义格式。
- 文档切分:按章节、段落或语义边界切成 chunks。
- 生成向量:为每个 chunk 计算 embedding。
- 建立索引:把文本、元数据、向量存入检索系统。
在线阶段负责回答用户问题:
- 用户提出问题。
- 系统对问题做改写、扩展或生成 embedding。
- 检索器从知识库找相关 chunks。
- 可选:reranker 重新排序。
- 系统把最相关材料放进 prompt。
- 大模型基于材料生成答案。
- 返回答案、引用来源和必要说明。
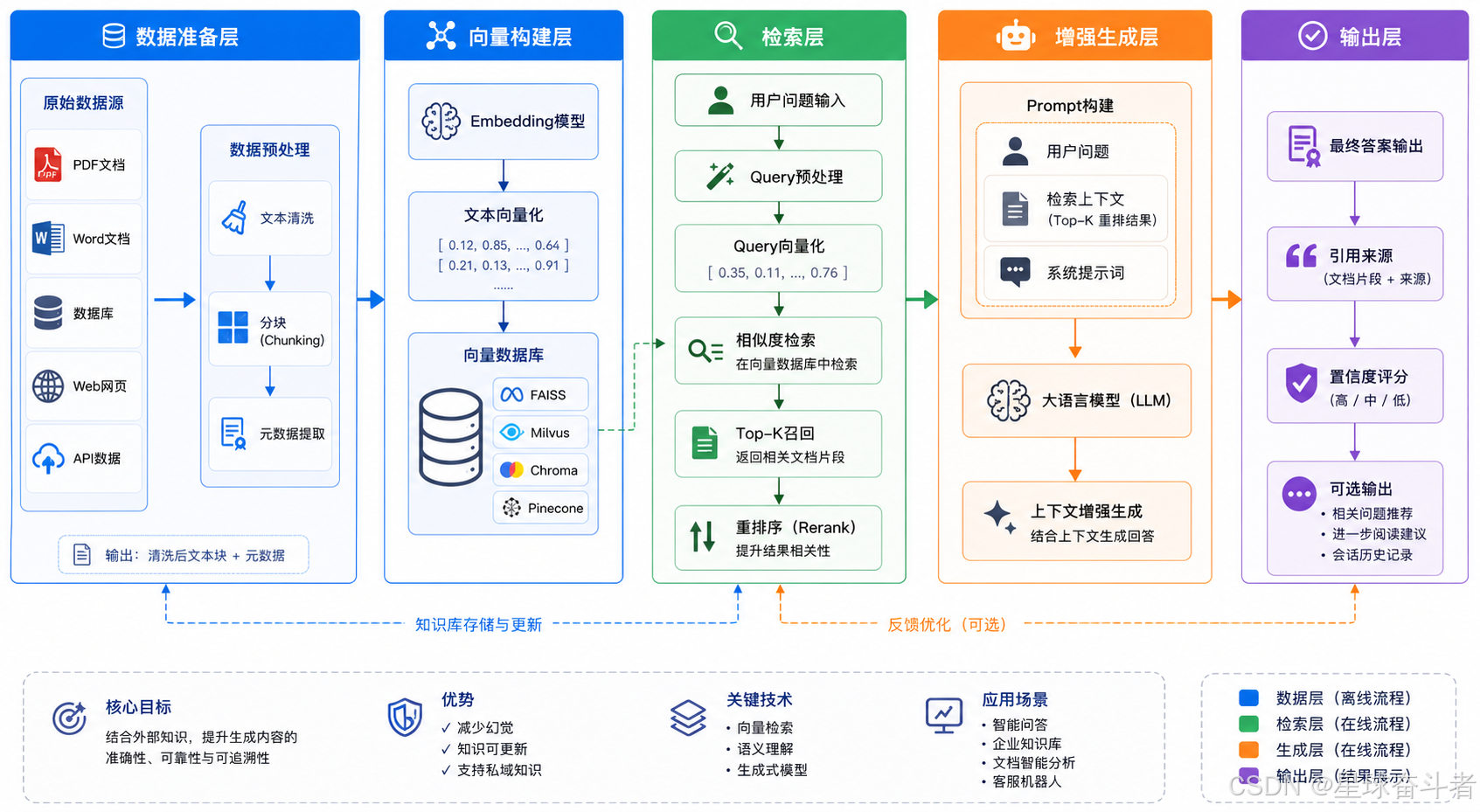
更成熟的 RAG 系统还会加入权限过滤、结果去重、上下文压缩、冲突检测、引用校验、日志记录、反馈学习和自动评估。
一个关键点:RAG 是系统,不是一个模型
很多初学者会以为 RAG 是某种模型名称。更准确地说,RAG 是一种系统架构。它把检索系统和生成模型组合起来,让模型能利用外部知识。
因此,RAG 做得好不好,不能只看大模型强不强,还要看:
- 文档是否干净;
- chunk 是否合理;
- embedding 是否适合领域;
- 检索是否准确;
- reranker 是否有效;
- prompt 是否能约束模型基于证据回答;
- 引用是否可追溯;
- 用户权限是否正确;
- 评估集是否覆盖真实问题。
RAG 很像一个资料室加一位写作者。写作者再聪明,如果资料室混乱、索引错误、拿到的材料不相关,也很难写出可靠答案。
RAG 质量拆解:召回、排序、生成、引用
初学者调 RAG 时常犯的错误,是看到答案错了就马上换模型。实际上,RAG 的质量至少要拆成四层看:
| 层次 | 要回答的问题 | 常见失败 |
|---|---|---|
| 召回 | 相关资料有没有被找出来? | embedding 不适合领域、chunk 太碎或太长、查询改写错误 |
| 排序 | 最有用的资料有没有排在前面? | top-k 太大引入噪声,reranker 缺失或不适配领域 |
| 生成 | 模型是否基于证据回答? | 模型使用常识补全、忽略检索资料、上下文冲突未处理 |
| 引用 | 答案能否追溯到来源? | 引用片段不能支持结论、引用旧版本文档、权限过滤缺失 |
因此排查 RAG 问题时,可以按顺序问:
- 相关文档是否在知识库里?
- 相关 chunk 是否被检索出来?
- 被检索出来的 chunk 是否排在足够靠前的位置?
- Prompt 是否明确要求"只基于资料回答"?
- 答案中的每个关键结论是否能被引用支持?
如果第 2 步就失败,问题在检索,不在模型;如果检索正确但回答编造,问题在上下文构造、生成约束或引用校验;如果引用看似存在但不能支持结论,问题在答案验证。这样拆开看,RAG 才能从 demo 走向可维护系统。
典型应用场景
1. 企业知识库问答
这是最典型的 RAG 场景。员工可以询问公司制度、报销流程、产品文档、技术规范、项目历史等问题,系统从内部知识库检索资料后回答。
关键要求是权限控制。不同员工能访问的文档不同,RAG 系统必须先过滤用户无权访问的资料,再交给模型生成答案。
2. 客服和售后支持
客服系统可以把产品手册、FAQ、工单记录、历史解决方案作为知识库。用户提问时,系统检索相关条款或步骤,再生成更自然的回答。
这类场景要特别注意答案准确性。不能为了语气流畅而编造政策或承诺,因此通常需要引用原文、设置拒答规则,并在高风险问题上转人工。
3. 法务、合同和合规审查
合同条款、法规、内部政策和历史案例都适合 RAG。模型可以帮助查找相关条款、总结差异、提示风险。
但法务场景不能只依赖模型结论。RAG 更适合做辅助检索和草稿总结,最终判断仍需要专业人员审核。
4. 代码库问答与开发助手
开发者可以问:"这个函数在哪里被调用?""登录流程如何实现?""为什么这个测试失败?"系统从代码仓库、文档、Issue、PR 记录中检索相关片段,再让模型解释。
代码 RAG 不只是检索文本,还需要理解符号、依赖、调用关系和文件结构。成熟系统往往会结合全文检索、语义检索、AST、语言服务器和执行结果。
5. 研究助手和资料综述
RAG 可以帮助读论文、查资料、整理引用。用户提出研究问题,系统检索相关论文段落、报告、网页,再生成结构化综述。
这类场景的关键是引用质量。模型应该明确区分"资料中有证据的内容"和"根据资料推断的内容"。
和其他概念的区别
| 概念 | 解决的问题 | 典型做法 | 和 RAG 的关系 |
|---|---|---|---|
| RAG | 给模型补充外部知识 | 检索相关资料后生成答案 | 核心是"先查再答" |
| Fine-tuning | 让模型学会特定风格、格式或任务能力 | 用训练数据更新模型参数 | 适合行为和格式,不适合频繁更新事实 |
| Prompt Engineering | 改善单次输入对模型的引导 | 写更好的指令和示例 | RAG 会把检索内容放进 prompt |
| Context Engineering | 系统性组织模型上下文 | 管理指令、记忆、检索、工具结果 | RAG 是上下文工程的重要组成部分 |
| Vector Database | 存储和检索向量 | 向量索引、相似度搜索 | 是 RAG 常用基础设施,不等于 RAG |
| Search Engine | 找到相关网页或文档 | 关键词、排序、索引 | RAG 可以使用搜索引擎作为检索器 |
| Agent | 围绕目标多步行动 | 规划、工具调用、反馈循环 | Agent 可以把 RAG 当作工具 |
| Long Context | 模型能读取更长输入 | 扩大上下文窗口 | 长上下文不能替代检索,常与 RAG 结合 |
RAG 和微调怎么选
一个常见问题是:有了 RAG,还需要微调吗?
答案是看目标。
如果你想让模型知道最新产品手册、内部制度、合同条款,优先考虑 RAG。因为这些知识会变化,放在外部知识库更容易更新和审计。
如果你想让模型稳定输出某种格式、学会特定语气、掌握某类标注规则、适应固定任务,微调可能更合适。
很多真实系统会同时使用两者:微调让模型更会"怎么回答",RAG 提供"回答依据是什么"。
一个简单例子
假设公司有一份内部制度文档:
text
员工每年可申请 10 天年假。连续请假超过 5 天,需要直属主管和部门负责人共同审批。用户问:
text
我想一次性请 6 天年假,需要谁审批?没有 RAG 时,模型可能根据常识回答:
text
一般需要主管审批,具体请查看公司制度。使用 RAG 后,系统会先检索到相关制度片段,再把它放进上下文:
text
已检索资料:
员工每年可申请 10 天年假。连续请假超过 5 天,需要直属主管和部门负责人共同审批。
用户问题:
我想一次性请 6 天年假,需要谁审批?模型就可以回答:
text
需要直属主管和部门负责人共同审批。依据是公司年假制度中"连续请假超过 5 天,需要直属主管和部门负责人共同审批"的规定。这个例子很小,但体现了 RAG 的本质:答案不是来自模型"猜测公司制度",而是来自可检索的外部资料。
常见误解
误解 1:RAG 可以完全消除幻觉
不能。RAG 可以降低幻觉,但不能完全消除。检索不到资料、检索到错误资料、资料互相冲突、模型没有严格遵守证据,都可能导致幻觉。
更可靠的做法是让模型在证据不足时明确说"不确定"或"资料中未找到",并提供引用来源。
误解 2:只要接入向量数据库就是 RAG
不是。向量数据库只是常见组件。真正的 RAG 还包括文档处理、chunk 策略、检索策略、重排、上下文构造、生成约束、引用、权限、安全和评估。
一个糟糕的向量索引加一个强模型,仍然可能得到糟糕答案。
误解 3:RAG 一定比长上下文好
不一定。长上下文适合用户一次性提供完整材料,例如让模型读一份报告。RAG 适合从大量资料中筛选相关内容。
真实系统常常结合两者:先用 RAG 找资料,再利用长上下文放入更多相关片段。
误解 4:RAG 不需要评估
RAG 更需要评估,因为它有更多环节。你不仅要评估最终答案,还要评估检索是否命中、引用是否正确、上下文是否充分、模型是否忠于证据。
常见评估维度包括:
| 维度 | 问题 |
|---|---|
| 检索召回 | 正确资料有没有被找出来? |
| 检索精度 | 找出来的资料是否真的相关? |
| 答案忠实度 | 回答是否严格基于资料? |
| 答案完整性 | 是否回答了用户真正的问题? |
| 引用准确性 | 引用是否支持对应结论? |
| 权限安全 | 是否泄露用户无权访问的内容? |
误解 5:RAG 只适合文本
早期 RAG 多用于文本,但现在已经扩展到多模态。图片、表格、音频、视频、代码、结构化数据库都可以成为检索对象。多模态 RAG 和代码 RAG 是很重要的发展方向。
未来趋势
1. 从简单 RAG 到 Agentic RAG
简单 RAG 通常只检索一次,然后生成答案。复杂问题往往需要多轮检索:先查背景,再拆问题,再查细节,再验证答案。
Agentic RAG 会让模型像研究员一样主动决定:
- 是否需要检索;
- 应该检索什么;
- 检索结果是否足够;
- 是否需要换关键词;
- 是否需要查数据库或调用工具;
- 最终答案是否被证据支持。
这会让 RAG 从"固定流水线"变成"可迭代的信息获取过程"。
2. Self-RAG 和 Corrective RAG
Self-RAG、CRAG 等研究试图让模型更主动地判断检索是否必要、检索结果是否可靠、生成答案是否需要修正。
这类方法的共同方向是:不要假设检索结果天然正确,而是让系统学会反思和纠错。
3. GraphRAG
传统 RAG 常按片段检索,适合回答局部问题。但当用户问"这个组织过去一年战略重点如何变化"或"这批事件之间有什么关系"时,单个片段可能不够。
GraphRAG 会从文档中抽取实体、关系和社群结构,用图来组织知识,再支持全局总结、关系推理和跨文档分析。它适合复杂知识网络,但构建成本也更高。
4. 多模态 RAG
未来 RAG 不只检索文本。系统可能同时检索:
- PDF 正文;
- 图片和图表;
- 视频片段;
- 音频转写;
- 表格数据;
- 代码符号;
- 数据库记录。
多模态 RAG 的挑战是:不同模态如何统一索引、如何对齐引用、如何让模型正确理解图表和视频中的证据。
5. RAG 评估和可观测性
RAG 从 demo 走向生产,评估会越来越重要。系统需要记录每次问答检索了什么、用了哪些片段、生成了什么结论、用户是否满意、是否违反权限。
未来成熟 RAG 系统会更像搜索引擎、数据库和 LLM 应用的结合体,而不是一个简单 prompt 模板。
小结
- RAG 的核心思想是:让模型先检索外部资料,再基于资料生成答案。
- RAG 解决了大模型知识过时、私有知识缺失、答案难追溯等问题。
- 一个完整 RAG 系统包括资料清洗、切分、embedding、索引、检索、重排、上下文构造、生成和引用。
- RAG 是系统架构,不是单个模型,也不等于向量数据库。
- RAG 和微调不是替代关系:RAG 更适合动态知识,微调更适合稳定行为和任务格式。
- RAG 可以降低幻觉,但不能完全消除幻觉。
- 高质量 RAG 的关键在于检索质量、chunk 策略、权限控制、引用校验和评估体系。
- 长上下文不会让 RAG 消失,二者往往会结合使用。
- 未来 RAG 会向 Agentic RAG、Self-RAG、GraphRAG、多模态 RAG 和生产级评估演进。
参考资料
- Patrick Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, 2020: https://arxiv.org/abs/2005.11401
- Vladimir Karpukhin et al., Dense Passage Retrieval for Open-Domain Question Answering, 2020: https://arxiv.org/abs/2004.04906
- Kelvin Guu et al., REALM: Retrieval-Augmented Language Model Pre-Training, 2020: https://arxiv.org/abs/2002.08909
- Gautier Izacard and Edouard Grave, Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering, 2020: https://arxiv.org/abs/2007.01282
- Sebastian Borgeaud et al., Improving language models by retrieving from trillions of tokens, 2021: https://arxiv.org/abs/2112.04426
- Gautier Izacard et al., Few-shot Learning with Retrieval Augmented Language Models, 2022: https://arxiv.org/abs/2208.03299
- Yunfan Gao et al., Retrieval-Augmented Generation for Large Language Models: A Survey, 2023: https://arxiv.org/abs/2312.10997
- Akari Asai et al., Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection, 2023: https://arxiv.org/abs/2310.11511
- Yan Xiong et al., Corrective Retrieval Augmented Generation, 2024: https://arxiv.org/abs/2401.15884
- Darren Edge et al., From Local to Global: A Graph RAG Approach to Query-Focused Summarization, 2024: https://arxiv.org/abs/2404.16130
- Microsoft Research, GraphRAG: Unlocking LLM discovery on narrative private data, 2024: https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/