引言
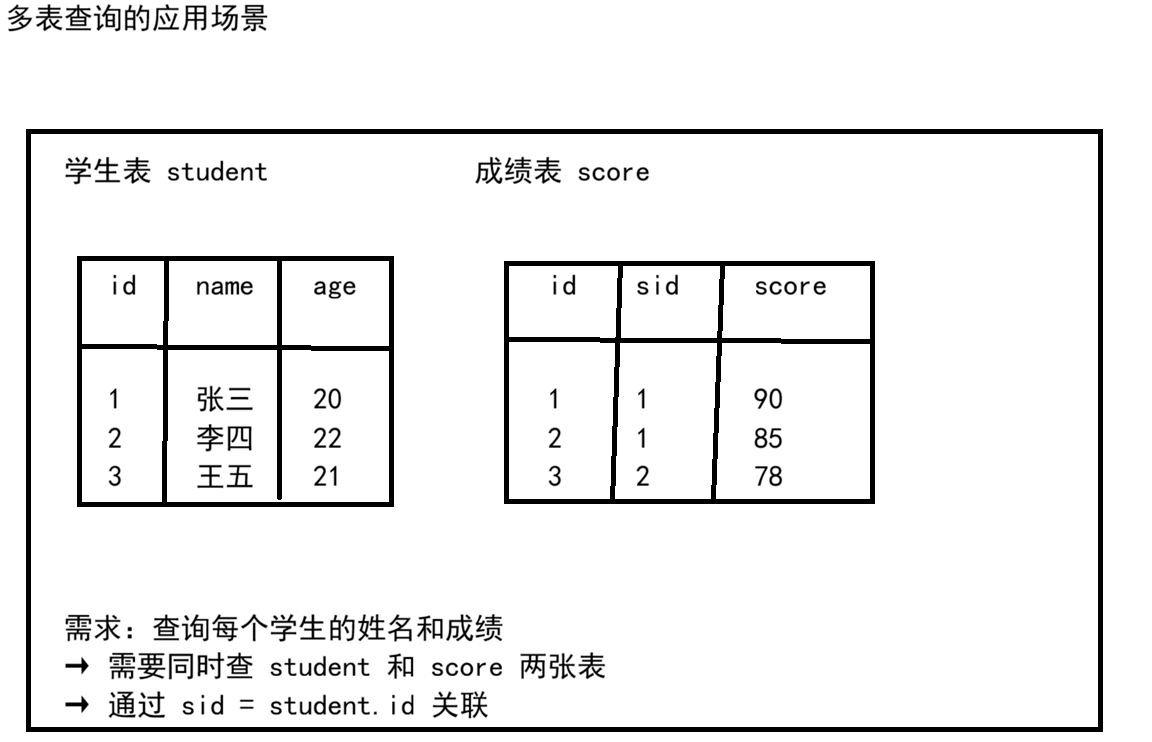
在前面的 MySQL 文章中,我们学习了单表的 CRUD 操作、事务、索引和视图。然而,实际开发中数据往往分布在多个表中------学生表、课程表、成绩表......需要联合查询才能得到完整信息。
多表查询 是 SQL 的核心能力,主要包括连接查询(JOIN) 和子查询两大类。本文将通过大量示例,彻底讲透各种 JOIN 的用法和子查询的写法。
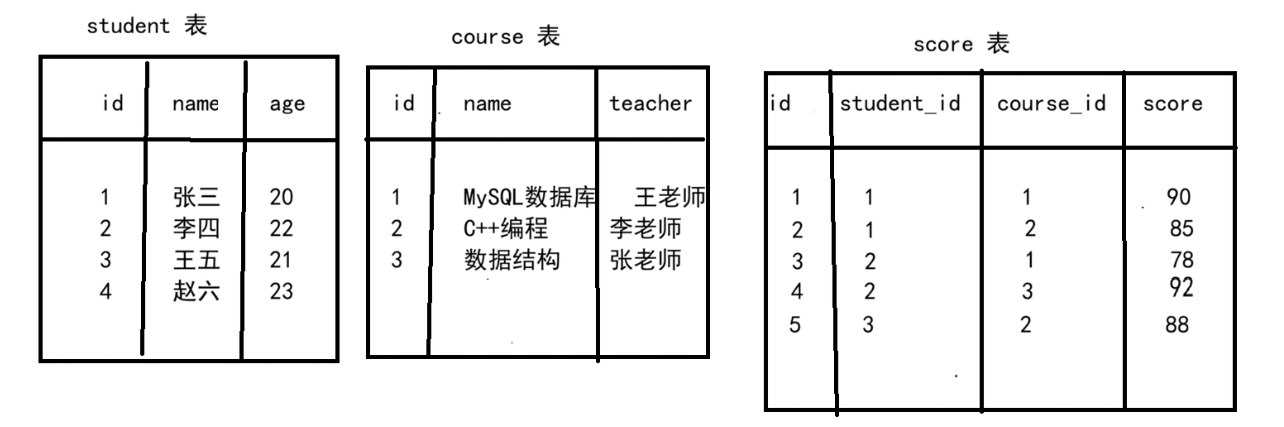
第一部分:准备测试数据
sql
-- 创建学生表
CREATE TABLE student (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
age INT
);
-- 创建课程表
CREATE TABLE course (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
teacher VARCHAR(20)
);
-- 创建成绩表(关联学生和课程)
CREATE TABLE score (
id INT PRIMARY KEY AUTO_INCREMENT,
student_id INT,
course_id INT,
score INT,
FOREIGN KEY (student_id) REFERENCES student(id),
FOREIGN KEY (course_id) REFERENCES course(id)
);
-- 插入学生数据
INSERT INTO student VALUES (1, '张三', 20), (2, '李四', 22), (3, '王五', 21), (4, '赵六', 23);
-- 插入课程数据
INSERT INTO course VALUES (1, 'MySQL数据库', '王老师'), (2, 'C++编程', '李老师'), (3, '数据结构', '张老师');
-- 插入成绩数据
INSERT INTO score VALUES
(1, 1, 1, 90), -- 张三 - MySQL - 90
(2, 1, 2, 85), -- 张三 - C++ - 85
(3, 2, 1, 78), -- 李四 - MySQL - 78
(4, 2, 3, 92), -- 李四 - 数据结构 - 92
(5, 3, 2, 88); -- 王五 - C++ - 88
-- 注意:赵六没有选任何课当前数据状态:
第二部分:JOIN 连接查询
一、JOIN 类型总览
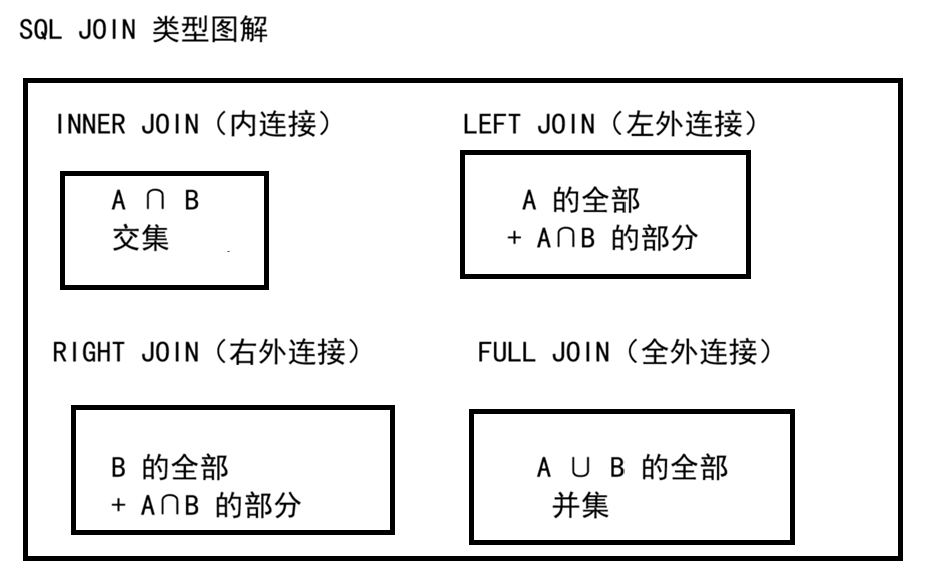
| JOIN 类型 | 含义 | 结果 |
|---|---|---|
| INNER JOIN | 内连接 | 只返回两表都匹配的行 |
| LEFT JOIN | 左外连接 | 左表全部 + 右表匹配的行(右表无匹配填 NULL) |
| RIGHT JOIN | 右外连接 | 右表全部 + 左表匹配的行(左表无匹配填 NULL) |
| CROSS JOIN | 交叉连接 | 笛卡尔积,两表所有行组合 |
| 自连接 | 表和自己 JOIN | 用于树形结构、上下级关系 |
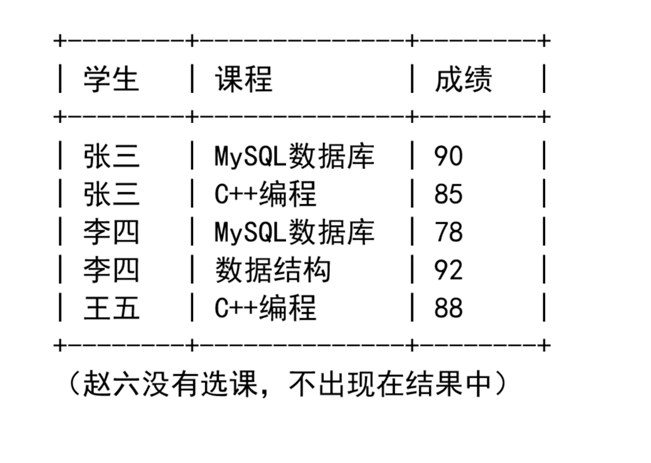
二、INNER JOIN(内连接)------ 最常用
sql
-- 查询每个学生选了什么课、得了多少分
-- 写法1:INNER JOIN(推荐)
SELECT s.name AS 学生, c.name AS 课程, sc.score AS 成绩
FROM student s
INNER JOIN score sc ON s.id = sc.student_id
INNER JOIN course c ON sc.course_id = c.id;
-- 写法2:WHERE 隐式连接(老式写法,不推荐)
SELECT s.name, c.name, sc.score
FROM student s, score sc, course c
WHERE s.id = sc.student_id AND sc.course_id = c.id;结果:
三、LEFT JOIN(左外连接)
sql
-- 查询所有学生及其选课情况(包括没选课的学生)
SELECT s.name AS 学生, c.name AS 课程, sc.score AS 成绩
FROM student s
LEFT JOIN score sc ON s.id = sc.student_id
LEFT JOIN course c ON sc.course_id = c.id;结果:
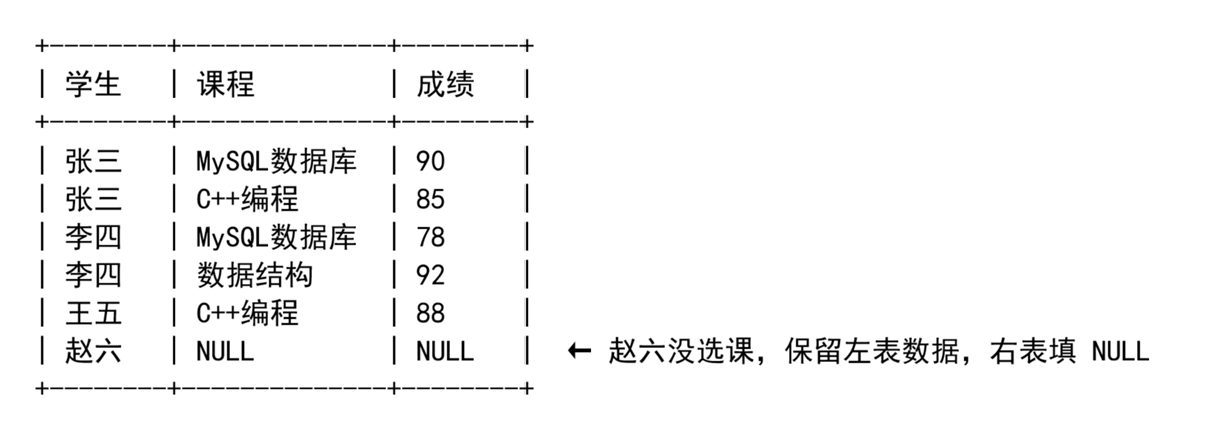
典型应用:找出没有选课的学生。
sql
SELECT s.name AS 学生
FROM student s
LEFT JOIN score sc ON s.id = sc.student_id
WHERE sc.student_id IS NULL;
-- 结果:赵六四、CROSS JOIN(交叉连接)
sql
-- 两表所有行一一组合(笛卡尔积)
SELECT s.name, c.name
FROM student s
CROSS JOIN course c;
-- 4 个学生 × 3 门课 = 12 行五、自连接
sql
-- 假设有员工表,查询每个员工的上级
CREATE TABLE emp (
id INT,
name VARCHAR(20),
manager_id INT
);
INSERT INTO emp VALUES (1, '老板', NULL), (2, '经理A', 1), (3, '员工B', 2);
-- 自连接:查员工和上级
SELECT e.name AS 员工, m.name AS 上级
FROM emp e
LEFT JOIN emp m ON e.manager_id = m.id;第三部分:子查询
一、什么是子查询
子查询是一个嵌套在另一个 SQL 语句中的 SELECT 语句。它可以出现在 WHERE、FROM、SELECT 子句中。
二、WHERE 子查询(最常用)
sql
-- 查询成绩高于平均分的学生
SELECT s.name, sc.score
FROM student s
JOIN score sc ON s.id = sc.student_id
WHERE sc.score > (SELECT AVG(score) FROM score);
-- 查询选了 MySQL 数据库的学生姓名
SELECT name FROM student
WHERE id IN (
SELECT student_id FROM score
WHERE course_id = (SELECT id FROM course WHERE name = 'MySQL数据库')
);三、FROM 子查询
sql
-- 将子查询结果作为临时表
SELECT avg_score.course_name, avg_score.avg
FROM (
SELECT c.name AS course_name, AVG(sc.score) AS avg
FROM course c
JOIN score sc ON c.id = sc.course_id
GROUP BY c.name
) AS avg_score
WHERE avg_score.avg > 80;四、SELECT 子查询
sql
-- 每个学生及其最高分
SELECT s.name, (
SELECT MAX(sc.score) FROM score sc WHERE sc.student_id = s.id
) AS 最高分
FROM student s;五、EXISTS 子查询
sql
-- 查询有选课记录的学生
SELECT name FROM student s
WHERE EXISTS (
SELECT 1 FROM score sc WHERE sc.student_id = s.id
);
-- 查询没有选课的学生
SELECT name FROM student s
WHERE NOT EXISTS (
SELECT 1 FROM score sc WHERE sc.student_id = s.id
);| 子查询写法 | 使用场景 |
|---|---|
WHERE x IN (子查询) |
判断某值是否在子查询结果中 |
WHERE x > (子查询) |
和子查询结果比较(子查询必须返回单值) |
WHERE EXISTS (子查询) |
判断子查询是否有结果 |
FROM (子查询) AS t |
子查询结果作为临时表 |
SELECT (子查询) |
子查询结果作为一列 |
第四部分:UNION 联合查询
UNION 把多个 SELECT 的结果合并成一个结果集。
sql
-- 查询选了 MySQL 或 C++ 的学生(去重)
SELECT DISTINCT s.name
FROM student s
JOIN score sc ON s.id = sc.student_id
JOIN course c ON sc.course_id = c.id
WHERE c.name = 'MySQL数据库'
UNION
SELECT DISTINCT s.name
FROM student s
JOIN score sc ON s.id = sc.student_id
JOIN course c ON sc.course_id = c.id
WHERE c.name = 'C++编程';| 关键字 | 区别 |
|---|---|
UNION |
合并并去重 |
UNION ALL |
合并但不去重(更快) |
第五部分:聚合函数与 GROUP BY
一、常用聚合函数
| 函数 | 作用 |
|---|---|
COUNT(*) |
统计行数 |
SUM(列) |
求和 |
AVG(列) |
平均值 |
MAX(列) |
最大值 |
MIN(列) |
最小值 |
二、GROUP BY 分组统计
sql
-- 每个学生的平均分
SELECT s.name, AVG(sc.score) AS 平均分
FROM student s
JOIN score sc ON s.id = sc.student_id
GROUP BY s.name;
-- 每门课的平均分、最高分、最低分
SELECT c.name AS 课程,
AVG(sc.score) AS 平均分,
MAX(sc.score) AS 最高分,
MIN(sc.score) AS 最低分
FROM course c
JOIN score sc ON c.id = sc.course_id
GROUP BY c.name;三、HAVING 过滤分组
WHERE 在分组前过滤行,HAVING 在分组后过滤组。
sql
-- 平均分大于 85 的课程
SELECT c.name, AVG(sc.score) AS avg_score
FROM course c
JOIN score sc ON c.id = sc.course_id
GROUP BY c.name
HAVING avg_score > 85;| 关键字 | 作用 | 执行时机 |
|---|---|---|
WHERE |
过滤行 | GROUP BY 之前 |
HAVING |
过滤组 | GROUP BY 之后 |
总结
一、核心要点
| 知识点 | 关键语法 |
|---|---|
| 内连接 | INNER JOIN ... ON |
| 左连接 | LEFT JOIN ... ON |
| 子查询 | WHERE x IN (SELECT ...) |
| 联合查询 | UNION / UNION ALL |
| 分组统计 | GROUP BY ... HAVING |
二、SQL 执行顺序
FROM → JOIN → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT
三、一句话记忆
多表查询用 JOIN...ON 关联,左连接保留左表全量,子查询嵌套在 WHERE/FROM/SELECT 中,GROUP BY 配合聚合函数做分组统计,HAVING 过滤分组结果。