
你是不是也有过这种体验:装满了 Claude Code、Cursor、Copilot、Codex、Gemini CLI......结果每次写代码都像在指挥一支不会排队的军队------Skill 乱飞、命令打架,token 疯狂燃烧,产出却平平无奇。
我这半年踩完一大圈坑,最后发现:不是模型不够强,而是没有一套「能在所有工具里复用」的工作流。
于是我干了一件事:把 superpowers(执行层)+ gstack(决策层)+ GSD(上下文层)打包成一个技能 ------
superpowers-gstack,让任何coding agent,都能用同一套「AI 全栈团队」工作流冲刺开发。github地址:github.com/aoping/supe...
1. 先聊痛点:越会用 AI,越容易被 Skill 反噬 😵💫

刚开始堆 skill 的那几个月,我几乎每天都在重复三件事:
-
方案评审时,同一阶段两个框架一起脑暴:
-
gstack 在
/office-hours上半天拆目标; -
superpowers 又拉起
brainstorming和writing-plans再说一遍。
-
-
做一个小改动,要走完一整套大流程:
-
改两行配置都要 Think → Plan → Build → Review → Test → Ship → Reflect;
-
半小时能手改完的补丁,被拖成一整个 session。
-
-
换一个 agent,所有套路重学一遍:
-
Claude Code 有
EnterWorktree,Codex App 没有; -
Cursor 靠
cursor-agent,Gemini CLI 用@agent-name; -
同一套方法论,在每个工具里都要重新口述一版。
-
结果就是:AI 越强,你越累。
不是它不聪明,而是你给了它太多互相打架的规则、太多模糊不清的职责。
我真正意识到问题,是有一天看到账单:那一周的 AI 成本足足比平时多了 2.7 倍,但交付物并没有翻倍。那一刻我开始认真思考:
-
我真的需要这么多 Skill 吗?
-
为什么「方法论 A vs 方法论 B」的问题,在社区里吵了半年还没结果?
-
有没有一种方式,让这两套框架停止互相抢话筒,而是像一个团队那样互补?
2. 把 AI 变成「全栈团队」:三层分工的心智模型 🧠🛠️📚

最后我收敛出了一个非常简单、但极其好用的心智模型:
一句话版本:
gstack 负责想清楚做什么(Decision Layer)→ superpowers 负责把事做出来(Execution Layer)→ GSD 负责记住我们是怎么做到的(Context Layer)。
为了把这个模型讲清楚,我画了一张三层架构图:
暂时无法在飞书文档外展示此内容
2.1 三层分别管什么?
层级
推荐组件
一句话职责
典型动作
Decision Layer
(决策层)
gstack
像 CEO + 产品负责人,负责判断 做不做 / 做到什么程度 / 先做哪一个。
-
/office-hours聚焦问题 -
/plan-ceo-review做价值判断 -
/plan-eng-review衔接到工程实现 -
/plan-design-review看体验 & 视觉
Execution Layer
(执行层)
superpowers
像一支 纪律严明的工程团队,负责把决策拆成可执行步骤,写代码、改代码、补测试。
-
writing-plans写实现计划 -
executing-plans按计划推进 -
subagent-driven-development调度子 agent -
test-driven-development/verification-before-completion -
finishing-a-development-branch
Context Layer
(上下文层)
GSD v2
长期项目里的 记忆与约束地基,防止今天的决策和三周前的决定互相打架。
-
PROJECT.md讲清楚我们在做什么 -
DECISIONS.md记录关键决策 & 理由 -
KNOWLEDGE.md存避坑 & 约定 -
M00x-ROADMAP.md管里程碑
2.2 三条「不许越权」的红线
三层分工能不能跑稳,就看你守不守住这三条红线:
-
决策只让 gstack 说话。 Think / Plan 阶段关闭 superpowers 的 brainstorm 能力,不让它抢戏。
-
执行只让 superpowers 动手。 Build / Test 阶段禁止再跑 gstack 的自动规划,让 gstack 安心做「要不要做」的判断。
-
GSD 只管长期记忆,不管短期琐事。 两小时能做完的活,不要强行写一堆 anchor 文件,否则 GSD 会沦为「没人看的 wiki」。
为了把这套分工落地到所有 AI 工具里,我做了一件偷懒但好用的事:
过去的做法
-
每换一个 agent,就新写一套说明书;
-
每个项目都要重新解释「谁负责想、谁负责做」;
-
出了 bug 才想起来:这一步到底是哪个框架拍板的?
现在的做法(superpowers-gstack)
-
三层分工写死在一份方法论里;
-
用同一套工作流驱动所有agent;
-
每次出问题,都能追溯到「是哪一层的决策出了偏差」。
3. 七步冲刺循环:让 AI 和你同频冲刺 💨
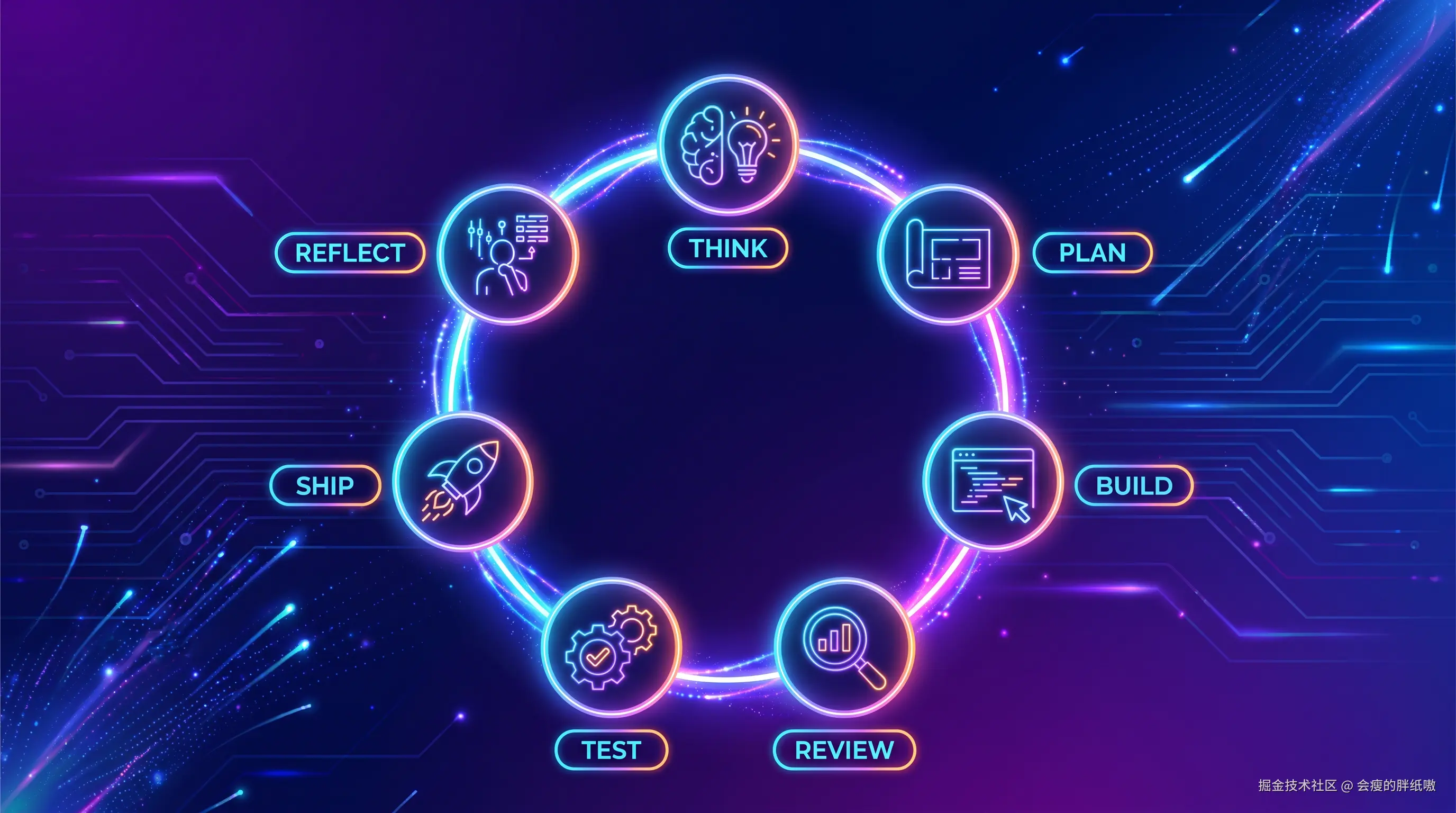
把这三层套进一次实际开发任务里,我最后收敛出了一个非常顺手的七步循环:
Think → Plan → Build → Review → Test → Ship → Reflect
我同样画成了一张可编辑的流程图(Mermaid 源文件),放在这里方便你直接改:
暂时无法在飞书文档外展示此内容
3.1 七个阶段具体怎么跑?
-
1️⃣ Think:对齐问题与边界
-
gstack:用
/office-hours把需求、约束、风险摊开讲清楚; -
人类:补充业务语境、组织现实、隐含 KPI。
-
-
2️⃣ Plan:选路线而不是背代码
-
gstack:用
/plan-ceo-review+/plan-eng-review组合出一份「决策 + 技术方案」; -
superpowers:等决策定稿后再接手,不参与「到底要不要做」的讨论。
-
-
3️⃣ Build:让 superpowers 全权负责执行
-
superpowers:
writing-plans → executing-plans → subagent-driven-development; -
AI 负责拆任务、调子 agent、改代码,人类只在关键节点拍板。
-
-
4️⃣ Review:检查的是决策 + 实现是否一致
-
superpowers:发起
requesting-code-review,请 AI / 人类双向审查; -
gstack:必要时用
/review从产品/用户视角再看一眼。
-
-
5️⃣ Test:别把验证当「顺便跑一下」
-
superpowers:至少跑一轮
verification-before-completion; -
gstack:在
/qa//qa-only里扮演挑剔的用户和测试负责人。
-
-
6️⃣ Ship:收尾永远交给流程化工具
-
superpowers:
finishing-a-development-branch负责打包、合并、清理分支; -
gstack:用
/ship→/land-and-deploy//canary等命令规划发布节奏。
-
-
7️⃣ Reflect:把这次的坑变成下一次的护城河
-
gstack:
/retro//learn总结这次迭代; -
GSD:把关键结论写回
DECISIONS.md/KNOWLEDGE.md。
-
3.2 三条「省钱又省心」的小纪律
为了不让这七步把你拖死,我给自己立了三条纪律:
-
脑暴只跑一次。 Think / Plan 阶段要么选 gstack,要么选 superpowers 的 brainstorm,绝不两边一起开会。
-
小改动允许直接从 Build 起步。 少于 10 行、纯配置/文案修改的改动,直接从 Build 开始,Think / Plan / Reflect 视情况跳过。
-
凡是合并到主干的代码,一律要过 Test + Ship。 不做「反正改得不多先合了再说」这种侥幸尝试。
4. 9 大 coding agent 的适配矩阵:一套方法论,九种落地姿势
很多人以为 superpowers + gstack 只是 Claude Code 专属,其实这套东西完全可以跨工具复用。我在梳理 superpowers-gstack Skill 时,把主流的 9 种 agent 做成了一个小矩阵:
Agent
Skill / 配置入口
子 agent 调度方式
Worktree 能力
适配提醒
Claude Code
原生 skill 系统(统一 slash + skills)
Task(general-purpose) 工具负责派发子任务
✅ 自带 EnterWorktree / WorktreeCreate
优先用原生 Worktree 工具,不要手写 git worktree add。
Codex CLI
Codex tools / worker 机制
spawn_agent / wait_agent / close_agent
❌ 无原生 Worktree,走 git worktree add 兜底
记得用 wait_agent 等结果,而不是 shell 的 wait。
Codex App
同 Codex CLI
同 spawn_agent / wait_agent
❌ 通常已在独立 worktree 内
检测到 GIT_DIR != GIT_COMMON_DIR 时要避免再次创建 worktree。
Cursor
.cursor/ 规则 + slash 命令
cursor-agent -p 调度不同 agent
❌ 通过 git worktree add 兜底
Windows 环境下注意通过 run-hook.cmd 路由命令。
Gemini CLI
GEMINI.md + skill 文件
@agent-name / @generalist
❌ 依旧是 git worktree add 兜底
并行依赖多次 @generalist 派发,注意不要一次塞太多任务。
OpenCode
experimental.chat.messages.transform 注入 bootstrap
experimental.agent
❌ 通过 git worktree add 兜底
记得把 bootstrap 注入到首条 user message,而不是 system prompt。
Copilot CLI
additionalContext
无原生子 agent,通过 prompt 约定模拟
❌ 仍靠 git worktree add
默认串行执行,别指望它帮你自动并行跑很多子任务。
Factory Droid
.factory/ 配置
内建 factory 子 agent 能力
❌ 用 git worktree add 兜底
适合用 gstack 统一管理 .factory/ 下的多角色配置。
其他通用 Agent
(Goose / Auggie / Qwen / OpenClaw 等)
各自 host 提供的配置方式
各自原生能力
❌ 通常需要自行调用 git worktree add
至少在 AGENTS.md 里写明三层分工,别让 agent 自己乱猜职责边界。
小总结:Agent 之间真正的差异在「怎么加载 Skill、怎么派发子 agent、怎么管 worktree」三件事上。
一旦这些约束写进你的 AGENTS.md / CLAUDE.md / .cursorrules 里,superpowers + gstack 的方法论就能原封不动地在所有工具之间迁移。
5. 我把这一整套方法论封装成了 superpowers-gstack 技能
光写文档是不够的,于是我做了一个真正可以在日常开发里用起来的小封装:superpowers-gstack。
它的设计目标只有一个:把「三层分工 + 七步循环 + 9 Agent 适配」收敛成两三个脚本,让任何一个 coding agent 都能用。
一个简化后的目录结构大概是这样:
bash
superpowers-gstack/
├── SKILL.md # 总纲:心智模型 + 三层分工 + 七步循环 + 使用注意
├── scripts/
│ ├── bootstrap_stack.py # 生成指定 agent 的安装命令 + AGENTS.md / CLAUDE.md 片段
│ └── print_workflow.py # 根据任务规模打印七步命令序列
└── references/
├── methodology.md # 三层 + 七步的完整说明和案例
├── agent-matrix.md # 上面那张 9 Agent 矩阵的可编辑版本
├── skill-catalog.md # superpowers 14 项 + gstack 23 项 Skill 速查
└── playbooks.md # small / feature / project 三种常见情境的剧本你大概只需要记住两个典型用法:
bash
# 1. 在 Claude Code 里准备做一次 feature
python3 scripts/bootstrap_stack.py --target claude
# → 输出 superpowers + gstack 的安装清单,以及 CLAUDE.md 里建议写入的约束片段
# 2. 想要快速看到这次任务要跑哪些命令
python3 scripts/print_workflow.py --scope feature
# → 输出从 Think 到 Reflect 一整套命令序列,包含什么时候交给哪一层处理从那以后,我在不同项目、不同 agent 之间切换时,基本只要:
-
安装必要的 superpowers / gstack 官方依赖;
-
在项目里运行一次
bootstrap_stack.py; -
用
print_workflow.py看着跑七步冲刺,就能快速「把 AI 团队搬进新项目」。
6. 三类典型任务的实战 playbook(可以直接抄走)
在真正落地之前,有一个很关键的点:七步循环不是每次都要全跑一遍,而是要根据任务规模裁剪。
我自己现在主要分三档:small、feature、project。
6.1 small:两小时内搞定的小改动
适用场景:
-
改一两行配置;
-
修一个明显的 typo;
-
调整一条文案或一个简单的 if 条件。
推荐动作:
csharp
[Build] superpowers: executing-plans
[Verify] superpowers: verification-before-completion
[Finish] superpowers: finishing-a-development-branch这里的关键,是所有决策层命令一律禁用 :不跑 /office-hours,不写大段 roadmap,只让 superpowers 执行一个严格限定的「小活」。
6.2 feature:单仓 1--3 天的功能开发
适用场景:
-
新增一个业务接口;
-
重构一块中型模块;
-
为现有系统补一组关键监控和告警。
推荐动作:
-
完整跑一次七步循环:Think → Plan → Build → Review → Test → Ship → Reflect;
-
但要记住:
-
Think / Plan 隶属于 gstack;
-
Build / Review / Test / Ship 隶属于 superpowers;
-
Reflect 阶段的产出,必要时写进 GSD。
-
一个常见的坑是:
Build 阶段发现方案不对时,很多人会直接在 superpowers 里再开一次 brainstorm,结果决策又被扔给执行层。
正确做法是:回到 gstack 的 /plan-eng-review****,从决策层重新调整路线。
6.3 project:跨周、跨人的长线项目
到了 project 级别,不再只是「一次需求」这么简单,而是:
-
可能跨越多个仓库;
-
多个开发者和测试一起参与;
-
周期跨越几周甚至几个月。
这时的套路是:
-
首次进入项目时:
-
用 GSD 创建
.project/PROJECT.md、DECISIONS.md、KNOWLEDGE.md、M001-ROADMAP.md; -
在
PROJECT.md里把项目背景、目标、范围讲清楚; -
在
M001-ROADMAP.md里把未来几次迭代切片出来。
-
-
每次 session 结束时:
-
把 gstack
/retro//learn的结论写回DECISIONS.md、KNOWLEDGE.md; -
只记录对后续几周仍然有影响的东西,避免把 GSD 写成流水账。
-
一个很实用的经验:GSD 是为跨会话记忆服务的,而不是为「当天复盘」服务的。
如果你发现自己总是在往 GSD 里塞当天才有意义的细节,那就说明:你的粒度开得太细了,该放进 PR 或当天的 daily note,而不是长期 anchor。
7. 不想踩的坑,我都帮你先踩过了 🧨
最后再快速提几个容易忽略、但极其影响体验的小坑:
7.1 brainstorm / plan 双跑 = 真金白银在燃烧
-
gstack 的
/office-hours+/plan-ceo-review+/plan-eng-review一套跑下来,很容易就是几十 k token; -
superpowers 的
brainstorming/writing-plans也不是白给的; -
两边一起开会,本质上就是「一个需求要开两次评审会」。
**解决方案:**把「哪一层负责哪一步」清清楚楚写进你的 AGENTS 文档里,用硬约束禁止双跑。
7.2 子 agent 命名不统一,Debug 会很痛苦
不同 agent 对子 agent 的命名和调度方式差异非常大:
-
Claude Code:
Task(general-purpose); -
Codex 系:
spawn_agent/wait_agent/close_agent; -
Gemini CLI:
@agent-name/@generalist; -
其他工具要么没有子 agent,要么只能靠 prompt 约定模拟。
**解决方案:**在 superpowers-gstack 的 bootstrap 里统一声明:
-
哪些名字对应决策层子 agent;
-
哪些名字对应执行层子 agent;
-
哪些只是通用助手,不能随便抢决策权。
7.3 Worktree 能力的「一等公民」只有 Claude Code
目前真正把 Worktree 做到工具层的一家,是 Claude Code:
-
EnterWorktree/WorktreeCreate让 agent 可以直接理解多仓、多分支的布局; -
其他家几乎都要靠
git worktree add .worktrees/<name>这种兜底方案。
解决方案:
-
在 AGENTS 文档里明确写出 Worktree 的优先级:
-
有原生工具就用原生;
-
没有就退回 git 命令;
-
-
让 superpowers 的
using-git-worktrees负责自动检测,而不是让每个 agent 自己瞎猜。
7.4 不要把官方源码「拷进」自己的内部 Skill
听起来很诱人:直接把 gstack / superpowers 源码搬进公司内部的私有仓库,然后写一套封装直接调用。但现实往往是:
-
License 风险没搞清楚就先复制,后面合规一查全得回滚;
-
公司沙箱环境不一定有
bun、node、npm等 runtime; -
你花时间维护的那一套 fork,永远落后于官方版本。
**更好的做法:**像 superpowers-gstack 那样,只做「方法论 + 适配层」,让用户在本地按官方文档安装,Skill 负责告诉他们:
-
该装什么;
-
该在自己的 AGENTS 文档里写什么;
-
不同 agent 下有哪些特殊注意点。
8. 写在最后:别再让 AI 只做「一个聪明的 autocomplete」了
当你把 superpowers + gstack + GSD 用三层架构+七步循环的方式组合起来,再配合 superpowers-gstack 这种方法论 Skill,你会发现:
-
Claude Code 不再是一个聪明输入法,而是一支能自己规划路线的工程小队;
-
Cursor / Codex / Copilot 也不再是「各管各的」,而是被纳入一套统一的节奏里;
-
你的 AI 成本会更可控,复盘出来的经验也能真正沉淀下来,而不是散落在无数 chat 历史里。
如果你也在被各种 AI 编程工具折腾,不妨试试这套组合拳:
-
把「三层分工 + 七步循环」写进你的 AGENTS 说明文档里;
-
在下一个 feature 上试着用
superpowers-gstack跑完一整次冲刺; -
用一次完整的复盘,把踩到的坑写回 GSD。
欢迎你在评论区聊聊:你是怎么组合自己的 AI 工具栈的?有没有什么特别好用的搭配?
如果这篇文章对你有启发,很欢迎你:收藏一波、转发给同事、在评论区抛出你的疑问和实践心得 。说不定下一版 superpowers-gstack 就会吸收你的经验,一起把这套方法论打磨得更好用。