1. 核心层级架构:文档、集合与数据库
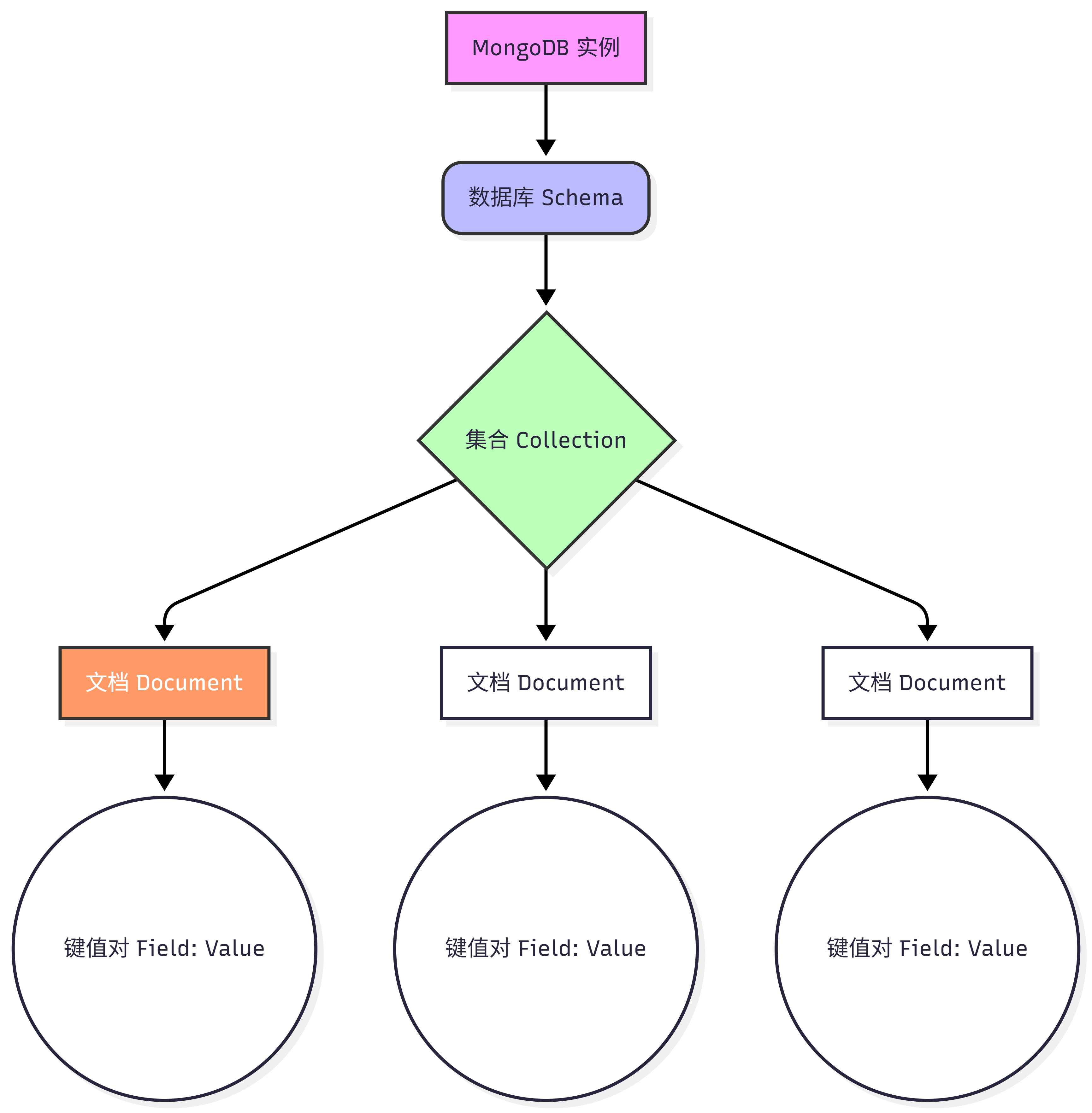
MongoDB 的数据组织形式在逻辑上非常直观,主要分为三个层级:文档(Document)、集合(Collection)和数据库(Schema)。
- 文档(Document): 这是 MongoDB 中最基本的数据单元。类似于关系型数据库中的"行(Row)",但表达能力远强于行。文档是由键值对(Field-Value Pair)组成的数据结构。
- 集合(Collection): 一组文档的容器,类似于关系型数据库中的"表(Table)"。但不同的是,集合没有强制的结构限制。
- 数据库(Schema): 集合的容器,一个 MongoDB 实例可以包含多个数据库,每个数据库拥有自己独立的文件集合和权限控制。
以下架构图更直观地展示了这三者的层级与包含关系:
2. BSON 文档结构:超越 JSON 的二进制编码
MongoDB 的文档在内存和磁盘中并非以 JSON(JavaScript Object Notation)文本形式存储,而是采用了一种称为 BSON(Binary JSON)的二进制序列化格式。
- 丰富的数据类型: JSON 仅支持字符串、数字、布尔值、数组、对象和 null。而 BSON 在此基础上扩展了丰富的数据类型,包括 32位/64位整数、双精度浮点数、日期(Date)、二进制数据(Binary Data)、ObjectID、正则表达式等。这使得 MongoDB 能够更精确地处理各类业务数据。
- 遍历与查询效率: BSON 在设计时在键值对中增加了长度前缀。这意味着数据库引擎在扫描文档时,可以直接跳过不需要的字段,极大地提高了遍历和查询的效率。
- 空间换时间: 虽然 BSON 的空间占用通常比精简的 JSON 略大,但它换取了极高的编解码速度和查询性能。
3. 动态 Schema 特性:灵活性与挑战并存
这是 MongoDB 与传统关系型数据库最大的不同点之一。在 RDBMS 中,表结构(Schema)是预先定义且严格受限的,每一行数据必须符合表定义。而在 MongoDB 中,集合具有"动态 Schema"(Dynamic Schema)特性。
- 异构文档共存: 在同一个集合中,你可以存放结构完全不同的文档。例如,在一个
users集合中,第一个文档可以包含name和email字段,而第二个文档可以包含name、age和address字段。 - 敏捷开发与迭代: 当业务需求变更需要新增字段时,无需像关系型数据库那样执行耗时的
ALTER TABLE操作,直接写入包含新字段的文档即可。
4. MongoDB 与关系型数据库(RDBMS)逻辑组织对比
通过表格对比两者的核心概念与特性:
| 核心概念 | 关系型数据库 (RDBMS) | MongoDB (NoSQL) | 核心差异解析 |
|---|---|---|---|
| 基本数据单元 | 行 (Row) | 文档 (Document) | 文档支持嵌套结构,表达能力更强 |
| 数据容器 | 表 (Table) | 集合 (Collection) | 集合无固定结构,支持动态 Schema |
| 结构定义 | 预定义 Schema (严格) | 动态 Schema (灵活) | MongoDB 适应业务变更更敏捷 |
| 表间关联 | 强依赖 JOIN 操作 | 嵌入式文档 或 $lookup | MongoDB 推荐通过嵌入减少联表查询 |
| 事务特性 | 强 ACID 事务 | 多文档 ACID 事务 (v4.0+) | 现代 MongoDB 已具备完善的事务能力 |
虽然 MongoDB 支持动态 Schema,但在实际生产环境中,建议在同一集合内保持文档结构的高度一致性。这不仅能降低应用层代码的复杂度,还能显著提升索引的利用率和查询性能。
4. 高频面试题
Q1:请简述 MongoDB 中 BSON 与 JSON 的主要区别,为什么 MongoDB 选择使用 BSON?
参考答案:
JSON 是一种轻量级的文本数据交换格式,易于人类阅读,但仅支持有限的几种数据类型(如字符串、数字、布尔值等)。BSON 是 JSON 的二进制编码形式,它不仅包含了 JSON 的所有数据类型,还扩展了 Date、Binary、ObjectID、32位/64位整数等类型。MongoDB 选择 BSON 的原因主要有两点:一是更高的遍历效率 ,BSON 在元素前增加了长度前缀,使得数据库引擎可以快速扫描和定位字段;二是更强的类型支持,能够更精确地映射编程语言中的原生数据类型,减少编解码过程中的精度丢失。
Q2:MongoDB 的"动态 Schema"带来了哪些优势?在实际开发中应该如何权衡使用?
参考答案:
动态 Schema 的核心优势在于灵活性 和开发效率。它允许开发者在不中断服务、不执行复杂迁移脚本的情况下,随时为数据添加新字段,非常适合需求快速迭代的业务场景。然而,在实际开发中需要权衡使用:
- 应用层复杂度: 如果同一集合中文档结构差异过大,应用层在读取数据时需要编写大量的兼容性逻辑(如判断字段是否存在)。
- 索引效率: 如果字段在文档中出现的频率极低(稀疏字段),为其建立索引可能会造成存储空间的浪费且收益不高。
- 最佳实践: 建议在同一集合中保持核心字段的结构一致性,将频繁变化的扩展属性放入一个内嵌的子文档中,兼顾灵活性与性能。
Q3:在 MongoDB 中,如何处理传统关系型数据库中的"多表关联(JOIN)"需求?
参考答案:
在 MongoDB 中,处理关联数据主要有两种模式:
- 嵌入式模型(Embedding): 这是 MongoDB 推荐的首选方案。将相关联的数据(如用户的地址信息、订单中的商品快照)直接内嵌到主文档中。这种设计利用了文档的嵌套特性,使得单次查询即可获取完整数据,极大提升了读取性能。
- 引用式模型(Referencing)与
$lookup: 当数据量极大、存在大量重复子数据或存在多对多复杂关系时,可以采用引用式模型(类似 RDBMS 的外键)。在查询时,使用聚合管道中的$lookup阶段来实现类似 SQL JOIN 的操作。但需注意,$lookup的性能开销通常高于嵌入式读取,应在必要时使用。