引言
强化学习人类反馈(RLHF)是近年来大语言模型领域最重要的技术突破之一。它解决了预训练语言模型与人类意图对齐的核心问题,使得模型输出不仅流畅准确,更符合人类价值观和使用习惯。从InstructGPT到ChatGPT,再到Claude和GPT-4,RLHF已成为现代对话式AI系统的标准范式。
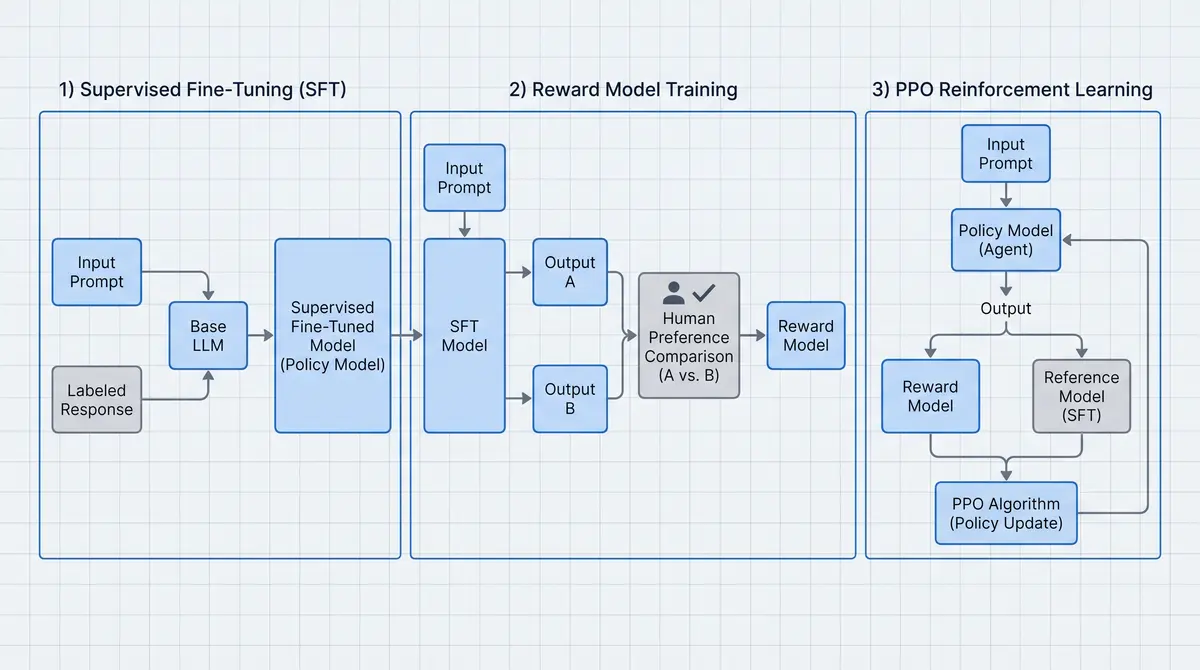
传统监督学习难以捕捉人类偏好的复杂性。RLHF通过强化学习框架,将人类比较性反馈转化为奖励信号,指导模型优化生成策略。这种范式提升了模型的有用性和无害性,为AI安全研究开辟了新路径。
核心原理
RLHF的三阶段流程
阶段一:监督微调(SFT) - 使用高质量人类标注示例进行监督学习,使模型具备指令遵循能力。
阶段二:奖励模型训练 - 将人类偏好建模为奖励函数。收集人类对多个输出的排序数据,训练奖励模型评估响应质量。
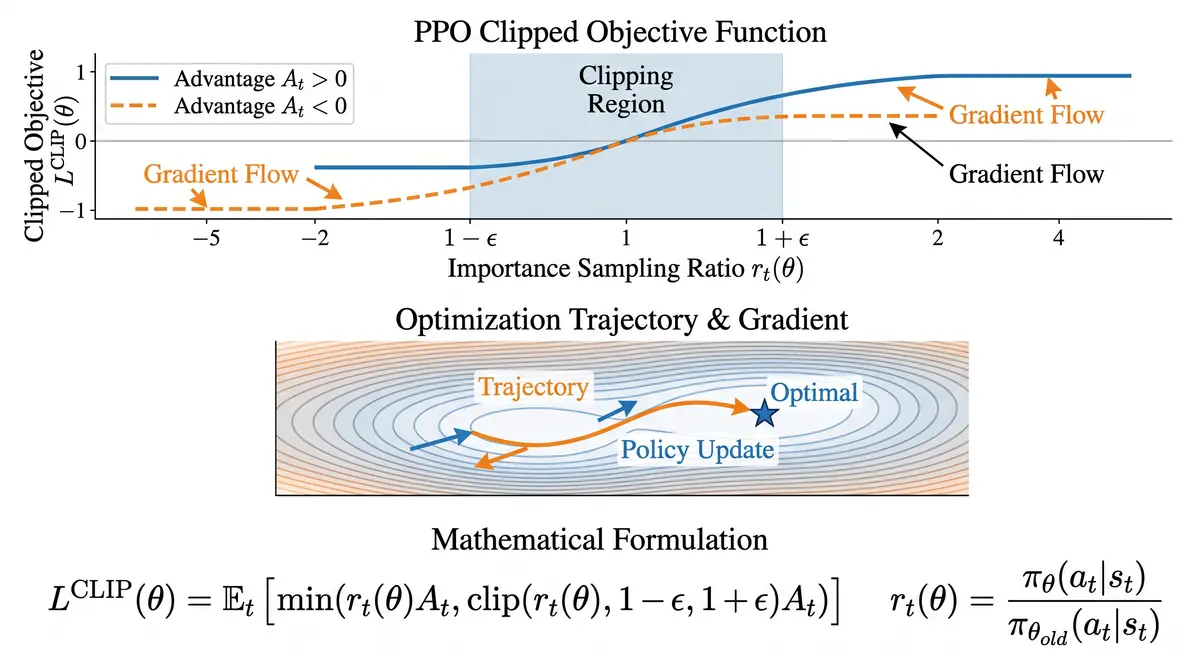
阶段三:PPO强化学习优化 - 使用奖励模型反馈,通过PPO算法微调策略模型。优化目标结合奖励最大化和KL散度约束,防止过度优化。
关键模块:策略模型(生成响应)、奖励模型(评估质量)、参考模型(防止遗忘)、价值模型(估计未来奖励)。
技术演进
早期探索(2017-2019)
RLHF思想源于OpenAI的Christiano et al. (NeurIPS 2017)论文,首次提出从比较性反馈学习奖励函数,初期应用于Atari游戏和机器人控制,证明了少量人类反馈(约900次比较)即可有效训练复杂任务。
InstructGPT突破(2022)
OpenAI的InstructGPT (Ouyang et al., NeurIPS 2022)是RLHF里程碑应用。关键发现:13,000条高质量标注胜过大规模低质量数据;InstructGPT 1.3B在人类评估中优于175B的GPT-3(无RLHF)。
ChatGPT与Claude(2022-2023)
ChatGPT基于InstructGPT技术优化多轮交互。Anthropic的Claude引入宪法AI,结合AI反馈减少人工标注。最新进展包括过程监督、红队对抗、多模态RLHF扩展。
应用场景与技术对比
对话系统
ChatGPT/Claude通过RLHF实现:拒绝不当请求、承认不确定性、遵循复杂指令、自我纠正错误。
代码生成
GitHub Copilot使用RLHF优化代码正确性、可读性和安全性。
技术对比
-
SFT:数据需求万级,训练复杂度低,适合指令遵循
-
RLHF:数据需求十万级,训练复杂度高,对齐效果强
-
DPO:简化RLHF,计算成本降低50%
最新研究(2024-2025)
1. 直接偏好优化(DPO) Rafailov et al., NeurIPS 2023 - 跳过奖励模型训练,直接优化策略,训练更稳定,成本降低50%。
2. 宪法AI Bai et al., arXiv 2022 - 使用AI系统根据价值准则评估响应,减少人工依赖。
3. 过程奖励模型(PRMs) Lightman et al., arXiv 2023 - 对推理步骤提供反馈,MATH数据集准确率提升至81%。
开源项目
-
trlX (CarperAI):https://github.com/CarperAI/trlx
-
DeepSpeed-Chat (Microsoft):大规模训练框架
-
TRL (Hugging Face):易用Transformer RL
总结
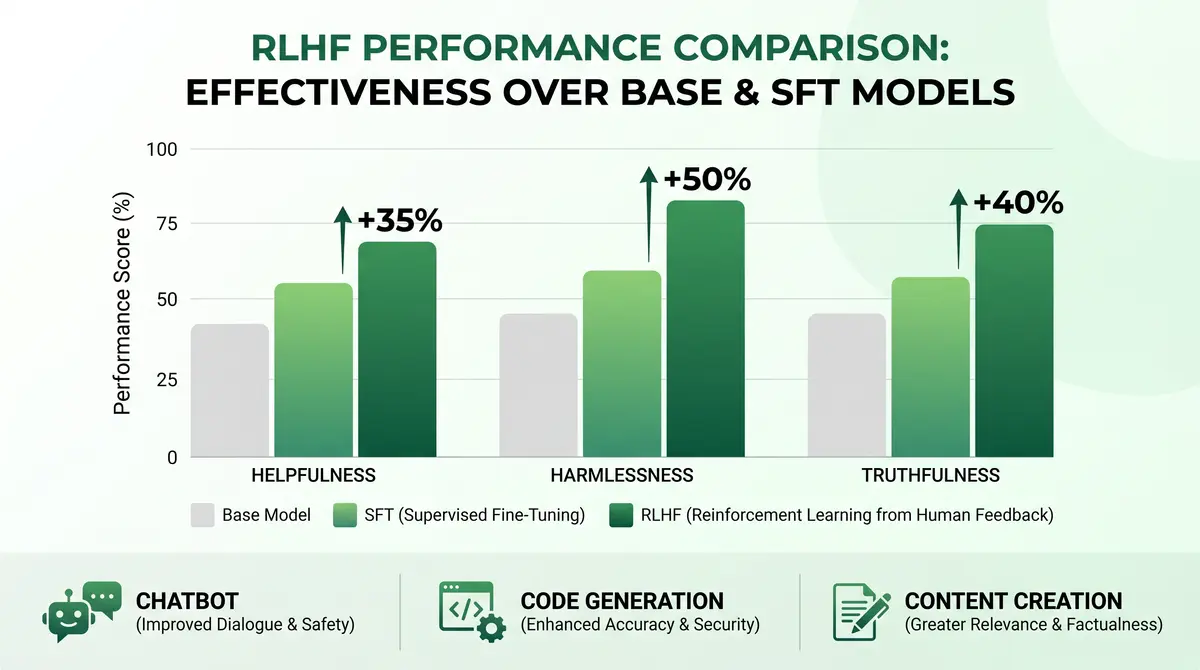
RLHF通过结合监督学习、偏好建模和强化学习,成功解决了大语言模型与人类意图对齐的核心挑战。三阶段训练流程(SFT→奖励模型→PPO优化)已成为业界标准,支撑了ChatGPT等现象级应用。
技术要点:
-
奖励建模:将主观偏好转化为可优化信号
-
KL约束:平衡探索与保守,防止能力退化
-
PPO算法:稳定的策略梯度方法
-
数据质量:高质量比较数据是成功关键
RLHF不是终点,而是AI对齐研究的起点。未来研究需探索可扩展监督、因果推理和多智能体协同,实现真正可信赖的通用人工智能。
参考文献:
-
Christiano et al. (2017). Deep RL from Human Preferences. NeurIPS.
-
Ouyang et al. (2022). Training LMs with Human Feedback. NeurIPS.
-
Rafailov et al. (2023). Direct Preference Optimization. NeurIPS.