做一套可落地的 AI 视频翻译系统,关键不是把 ASR、翻译、配音、字幕几个模型简单串起来,而是把"输入、音频切分、转写、说话人、翻译、合成、对齐、导出"做成一条稳定的数据管线。比较稳的架构可以拆成 7 层:输入层、ASR 层、说话人分离层、NMT 层、TTS 层、后处理层和任务编排层。
如果目标是面向内容出海、课程本地化、短剧翻译或企业视频多语种交付,系统设计要优先考虑三件事:时间轴不能乱、角色声音不能串、最终产物要能直接发布。
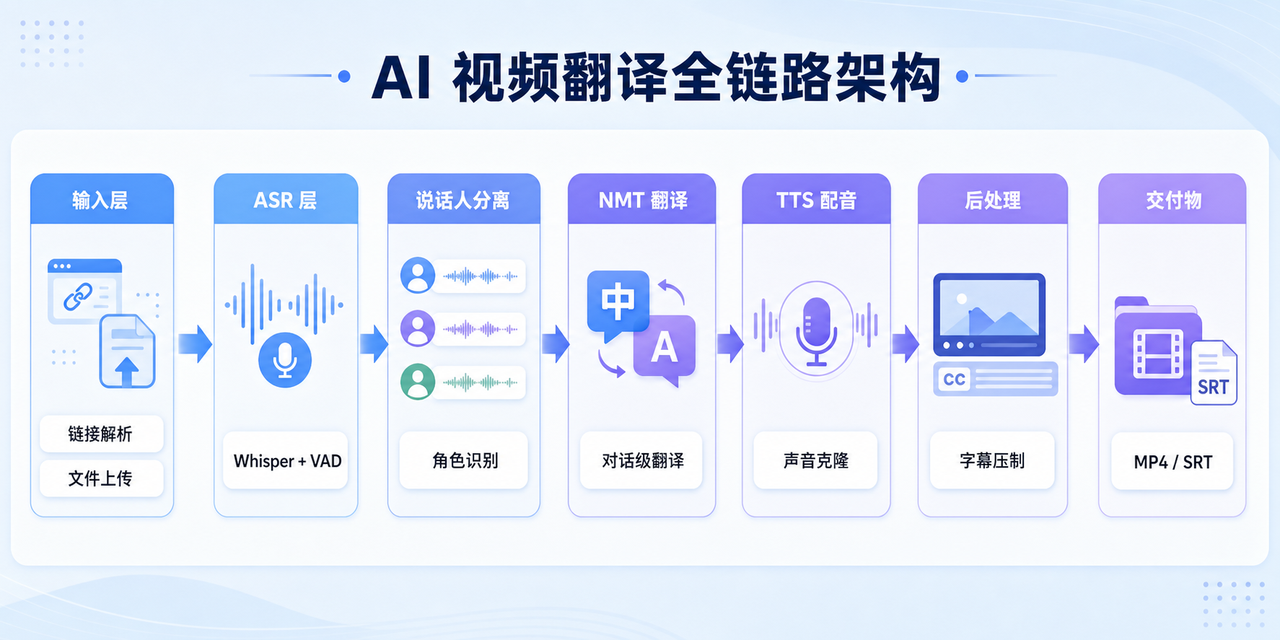
1. 整体架构怎么拆?
一条完整的视频翻译 pipeline 可以这样理解:
这里最容易被低估的是"中间数据结构"。如果每一层只传文本,后面一定会出问题。更合理的做法是从 ASR 开始就维护 segment 数据:
这类结构可以同时服务翻译、配音、字幕和审核。视频翻译系统的主数据不是"文本",而是带时间轴、角色和状态的语音片段。
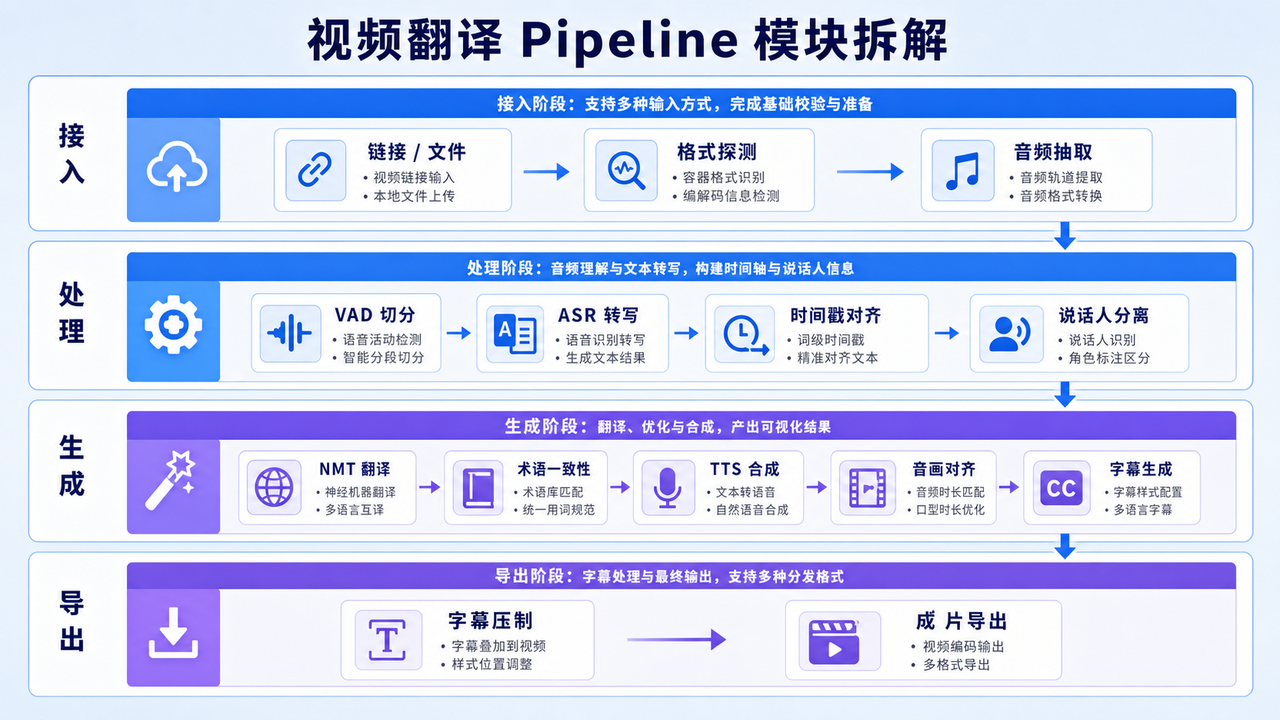
2. 输入层:链接解析和文件上传要先做工程兜底
输入层看起来简单,实际决定了整条链路的稳定性。常见输入有两类:一类是 YouTube、TikTok、网盘、对象存储等链接;另一类是本地上传的视频文件。
工程上建议至少做 5 个动作:
-
链接解析:识别来源、鉴权状态、文件大小、下载方式。
-
文件入库:统一转成内部任务 ID,避免后续模块依赖原始 URL。
-
格式探测:读取分辨率、帧率、时长、音轨、编码格式。
-
音频抽取:转成 ASR 更友好的 wav / flac 中间格式。
-
任务切片:长视频按时长、静音区间或章节拆分,避免单任务超时。
这一层不建议直接把视频丢给 ASR。更好的做法是先用 FFmpeg 做标准化,把多种输入收敛成统一的音频和视频元信息。输入层的目标不是"拿到文件",而是把不可控素材变成可计算、可追踪、可恢复的任务对象。
3. ASR 层:Whisper + VAD 是常见组合,但时间戳要单独处理
ASR 层通常承担三件事:语音活动检测、语音转写、时间戳生成。Whisper 适合做多语种 ASR 基座,OpenAI 官方介绍中提到 Whisper 使用了大规模多语种、多任务监督数据训练,适合跨语言转写场景。
但工程落地时,Whisper 不是"直接跑一下就结束"。更常见的组合是:
-
VAD 先切掉静音和非语音区间,降低无效推理。
-
Whisper 负责生成初始转写和粗时间戳。
-
forced alignment 或类似方案补齐词级时间戳。
-
后处理模块做标点、断句、重复片段过滤和置信度标记。
技术选型可以这样判断:
-
Whisper 原版:适合多语种转写基座,生态成熟,但长视频时间戳需要额外校正。
-
faster-whisper:适合对推理速度有要求的批量任务,部署时更容易控制显存。
-
WhisperX:适合需要词级时间戳、强制对齐和说话人信息结合的场景。
-
纯云 ASR API:适合快速上线,但成本、可控性和多语种一致性要单独评估。
ASR 层的输出质量会直接影响后面的翻译和配音。尤其是短剧、访谈、课程这类长内容,如果 ASR 断句错了,NMT 会翻错语义边界,TTS 也会在错误位置停顿。

4. 说话人分离:不要等到 TTS 阶段才处理角色
说话人分离的目标是回答一个问题:这一段话是谁说的。常见做法是使用 speaker diarization 模型,比如 pyannote.audio 这类工具链,它覆盖语音活动检测、说话人变化检测、重叠语音检测、speaker embedding 等模块。
这一层的工程难点不在"能不能识别出 speaker",而在三个边界:
-
重叠语音:两个人同时说话时,不能简单归给音量更大的人。
-
短句切换:短剧和访谈里一句话可能只有 1-2 秒,角色切换频繁。
-
时间轴合并:ASR 的 segment 和 diarization 的 speaker turn 往往不是一一对应。
比较稳的做法是先得到 ASR segment,再把 diarization 结果按时间重叠比例映射回 segment。如果一个 segment 内出现多位说话人,就拆分或标记为待人工复核。
对于视频翻译平台来说,说话人分离不是锦上添花。它决定了后续声音克隆、角色配音和字幕说话人标记能否保持一致。
5. NMT 层:句级翻译快,对话级翻译更适合视频
NMT 层最常见的取舍是:按句翻译,还是按上下文翻译。
句级翻译的优点是快、便宜、容易并行,适合信息密度不高的教程、口播、新闻切片。问题是它容易丢上下文,比如代词、称呼、剧情反转、上一句埋下的梗。
对话级翻译会把相邻 segment、speaker、场景上下文一起传入翻译模型,更适合短剧、访谈、课程和影视解说。它的成本更高,也更考验 prompt、术语表和长度控制。
实际架构里可以采用混合策略:
-
口播类视频:默认句级翻译,增加术语表和风格约束。
-
多角色剧情:按场景或 30-90 秒窗口做对话级翻译。
-
课程培训:按章节翻译,保证概念和术语一致。
-
短视频广告:翻译后增加本地化改写,优先保证目标市场表达自然。
如果要引入 SeamlessM4T 这类多模态、多语种翻译模型,可以把它放在"语音到文本翻译"或"语音到语音翻译"的实验链路中。但在可控交付场景里,级联式 pipeline 仍然有优势:每一步可检查、可回滚、可人工修订。
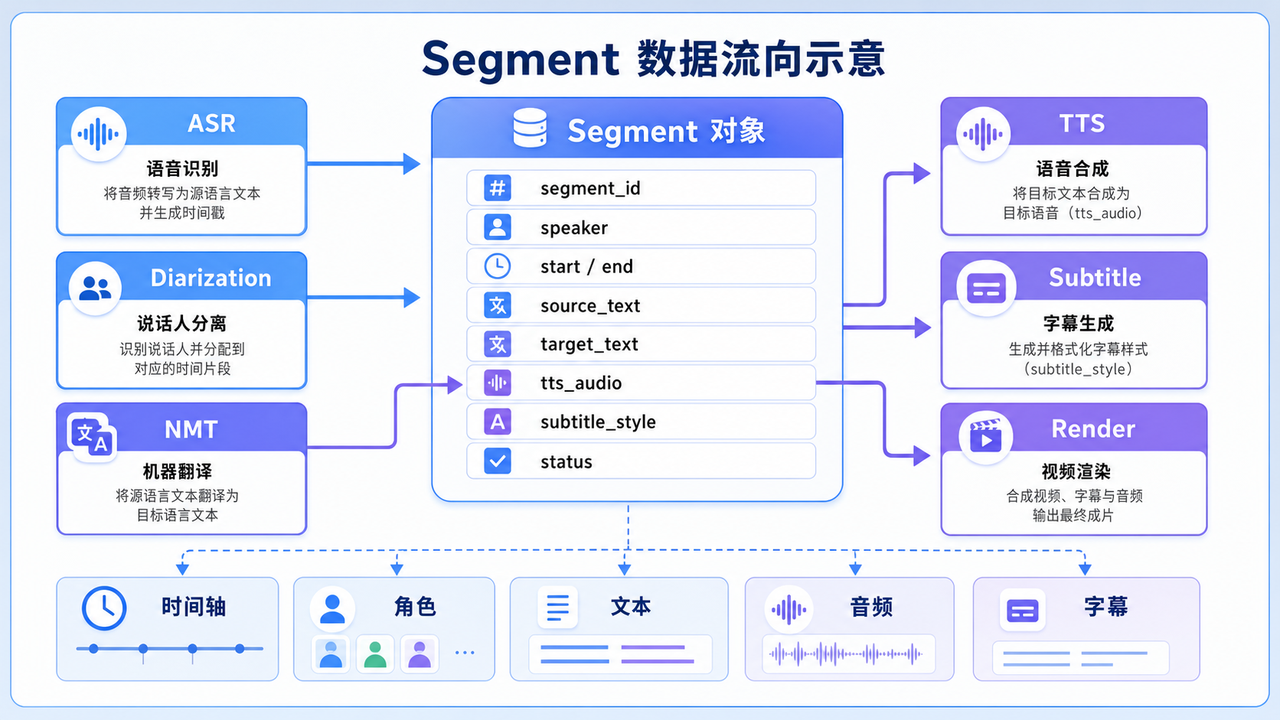
6. TTS 层:声音克隆不是只看像不像,还要看能否对齐
TTS 层负责把目标语言文本合成为目标语音。对于视频翻译来说,单纯"声音像"不够,还要满足三个条件:
-
语速可控:合成音频不能明显长于原片段。
-
情绪稳定:不能每个 segment 的音色、音量、情绪都漂移。
-
角色一致:同一个 speaker 在全片中要保持同一套声音参数。
技术选型上可以分成几类:
-
通用 TTS:稳定、速度快,适合课程、说明书、企业培训。
-
声音克隆 TTS:适合人物感更强的视频,但需要控制授权和素材质量。
-
跨语言 voice cloning:适合出海内容本地化,但要额外检查发音、情绪和时间轴。
-
人工配音混合方案:适合高价值内容,AI 先出初版,人工做精修。
TTS 层建议输出独立音频片段,而不是一口气生成整条视频音轨。片段化输出可以让后处理层做 time-stretch、静音填充、交叉淡入淡出,也方便对单句返工。
7. 后处理层:音画对齐、字幕生成和字幕压制是交付关键
后处理层决定最终视频能不能发布。它通常包含 4 个动作:
-
音画对齐:把每个 TTS 片段放回原始时间轴。
-
时长修正:通过语速调整、静音裁剪、片段重排解决超长问题。
-
字幕生成:输出 SRT / VTT / ASS,保留开始时间、结束时间和目标语文本。
-
字幕压制:用 FFmpeg 或渲染服务把字幕烧录进视频。
字幕有两种交付方式:软字幕和硬字幕。软字幕适合平台支持字幕轨的场景,方便后续修改;硬字幕适合短视频平台、广告素材和需要直接发布的版本。FFmpeg 的 subtitles filter 是常见的字幕压制方案,但实际部署时要注意字体、换行、编码、字号和安全边距。
这一层还要处理一个经常被忽略的问题:源视频已经有硬字幕怎么办?如果原视频自带烧录字幕,直接压新字幕会重叠。更完整的方案是先做字幕区域检测和擦除,再压制目标语字幕。这个环节会增加耗时,但对短剧、影视解说和搬运类素材很关键。
8. 任务编排:一站式平台真正难在状态管理
当视频从 1 条变成 100 条,系统难点会从"模型效果"转向"任务编排"。一个可用的视频翻译平台至少要维护这些状态:
-
pending:任务已提交,等待下载或上传完成。
-
extracting:正在抽取音频和元信息。
-
transcribing:正在 ASR。
-
diarizing:正在说话人分离。
-
translating:正在翻译。
-
synthesizing:正在生成配音。
-
rendering:正在合成视频和字幕。
-
review:等待用户预览或人工修订。
-
completed / failed:交付完成或失败待重试。
每一层都要能失败重试,不能因为 TTS 某一句失败就让整条视频从 ASR 重新开始。更合理的方案是把 segment 作为最小重试单元,把视频任务作为聚合对象。
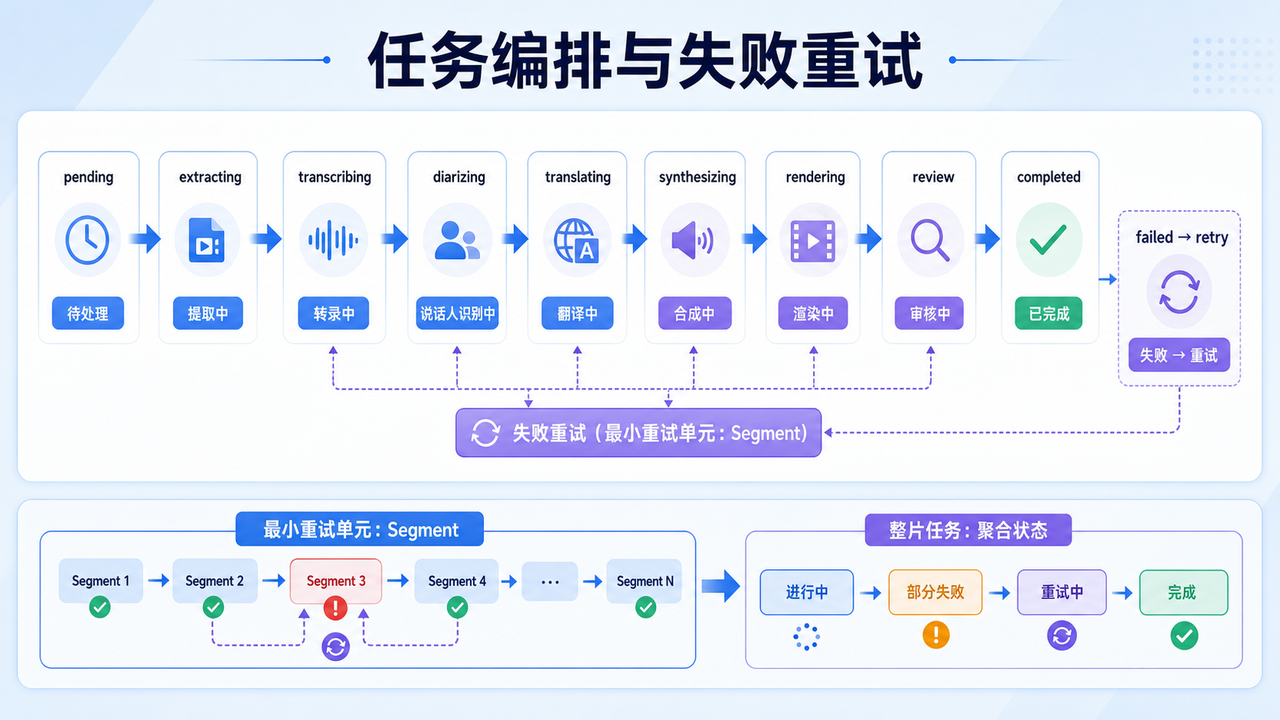
以上架构已在一个面向出海场景的视频翻译平台中落地验证。以 VividDub 这类一站式 AI 视频翻译平台为例,它把链接或文件提交、AI 语音识别、文本翻译、声音克隆、AI 配音、字幕生成、字幕压制和硬字幕擦除放在同一条工作流里,适合需要持续处理多语种视频资产的内容团队、studio 和企业本地化团队。
这种平台型架构的价值不只是"少切几个工具",而是让 ASR、NMT、TTS、字幕和导出围绕同一个任务状态运行。对批量出海内容来说,稳定的中间数据结构和可追踪任务状态,比单点模型能力更重要。
9. 实际落地时的技术边界
最后给几个工程判断:
-
如果只是给一条视频做字幕翻译,ASR + NMT + SRT 生成就够了。
-
如果要做目标语配音,必须增加说话人分离、TTS 和音画对齐。
-
如果要处理短剧、访谈和多人视频,speaker diarization 应该前置,而不是后置补救。
-
如果要批量交付多语种版本,任务编排、失败重试、素材归档和版本管理必须从第一版就设计。
-
如果源视频有硬字幕,字幕擦除和重新压制要作为独立模块,不要混在字幕生成里。
一站式 AI 视频翻译的核心不是"把视频翻译成另一种语言"这么简单,而是把语音、文本、角色、时间轴、字幕和成片导出放进同一套工程化链路。只有这条链路稳定,AI 视频翻译才适合从单次试用走向持续生产。