在平常的程序开发中,不避免要进行多表关联查询,虽然行业普遍规范是要求尽量少用 JOIN 的,但在一些后台管理功能、报表功能中,还是需要进行多表关联查询。在一些入行不久的研发同学中,可能直接上手就写 JOIN 语句,而不去关注是否写得正确,今天就来分享一些在日常开发中使用 JOIN时,一些很容易被忽视,但一旦踩上就会让你抓狂的问题,JOIN 的驱动表选错了,性能差几十倍都是轻的。
说起来有点讽刺,可能很多人写了好几年 SQL,JOIN 连接查询也写了无数条,但从来没有思考过一个问题:MySQL 到底是先扫哪张表?驱动表是怎么决定的?如果它选错了,我该怎么办?
这种忽视在数据量小的时候没什么感觉,但等到生产环境某张表涨到千万级,你就会发现同一条 SQL,原来只要 50 毫秒,现在要 8 秒,而且你改来改去索引都没用。
今天这篇文章,我就来手把手带你搞清楚 JOIN 驱动表这件事。下面这张图是本文的核心,先收藏再看。
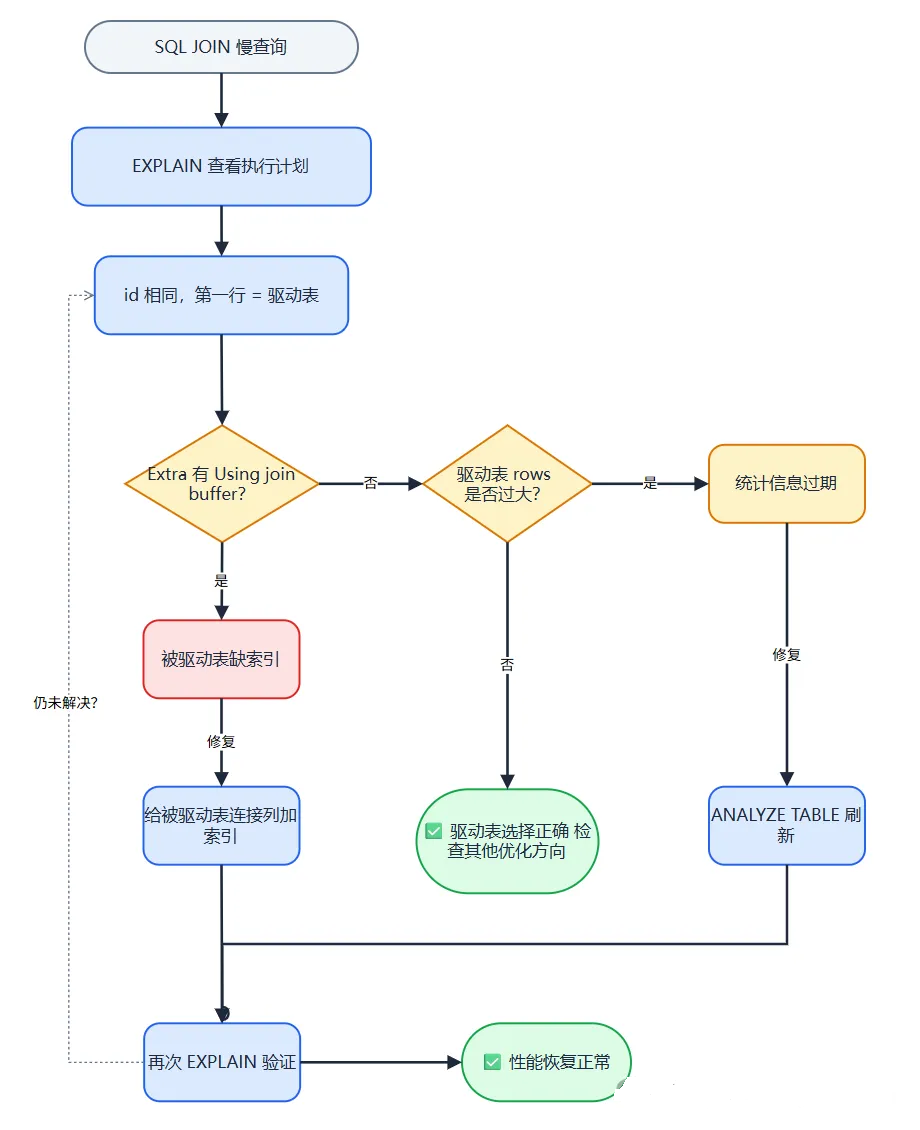
图1:JOIN 驱动表排查流程图 --- SQL 变慢后,按这张图走一遍,90% 的 JOIN 慢查询问题都能定位到。先收藏再看。
一、从一个真实例子说起
下面,来看一条 SQL(缩减),是之前做一个内容平台项目里使用到。当时有一个接口,功能是查询某个分类下的文章列表,并带上作者信息,SQL 大概是这样的:
SELECT a.id, a.title, a.content, u.nickname, u.avatar
FROM articles a
JOIN users u ON a.author_id = u.id
WHERE a.category_id = 12
ORDER BY a.created_at DESC
LIMIT 20;这条 SQL 在测试环境跑得很好,响应 30 毫秒以内。但某天上线后,运营反映文章列表页加载很慢,有时候要 6 秒才出来。
DBA 拉出慢查询日志,经过一翻查找,最后确定是这条 SQL 引起的,在高峰期执行时间飙到了 5~8 秒。
当时的研发第一反应就说是不是索引的问题,于时赶紧 EXPLAIN 一下这条 SQL :
EXPLAIN SELECT a.id, a.title, a.content, u.nickname, u.avatar
FROM articles a
JOIN users u ON a.author_id = u.id
WHERE a.category_id = 12
ORDER BY a.created_at DESC
LIMIT 20;输出结果如下:
+----+-------------+-------+------+------------------+---------+---------+------------------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+------------------+---------+---------+------------------+---------+-------------+
| 1 | SIMPLE | u | ALL | PRIMARY | NULL | NULL | NULL | 1200000 | NULL |
| 2 | SIMPLE | a | ref | idx_author_cat | idx... | 8 | u.id | 320 | Using where |
+----+-------------+-------+------+------------------+---------+---------+------------------+---------+-------------+大家看这个输出结果有什么问题?结合在上一篇文章中介绍的 EXPLAIN 的使用,你能发现问题吗?
来看下,users 表排在第一行,它是驱动表。而 users 表有 120 万条 用户数据,type 是 ALL,也就是全表扫描。这个输出表时:MySQL 先全扫了 120 万用户,再对每个用户去 articles 表里找文章。研发瞬间晕,是不是搞反了,他原以为是用 articles 来当驱动表去关联。
articles 加了 WHERE category_id = 12,过滤后只有 300 多条,理论上应该是先从 articles 拿这 300 条,再去 users 找对应用户信息才对。
这个例子说明了:驱动表选错了,而且错得很离谱。
二、驱动表是什么,MySQL 怎么选?
在讲怎么优化 JOIN连表 之前,我们需要先把 JOIN连表 原理搞清楚,这样你以后看到问题一眼就能判断,并能自行解决。
2.1 什么是驱动表
JOIN 查询不是两张表"同时扫描",实际上是有先后顺序的,在MySQL 的内部是有一个嵌套循环(Nested Loop)来处理这件事的:
for each row in 驱动表(外层循环){
for each row in 被驱动表(内层循环){
if 满足 JOIN 条件 → 输出到结果集
}
}驱动表就是外层循环那张表,它的每一行都会触发一次对被驱动表的查找。被驱动表是内层循环,每次被从驱动表过来的一行"驱动"着去查。
所以:
-
驱动表的行数决定了外层循环跑多少次
-
被驱动表每次被查,最好能走索引(否则就是每次都全表扫)
2.2 MySQL 怎么决定谁是驱动表
这个是由 MySQL 优化器根据 代价模型(Cost Model) 来决定,简单来说:它会估算两种顺序的总成本,然后选便宜的那一个。看到这里,你可能心理在想,那这个代价模型有那些影响因素呢?
根据 MySQL 官方的资料,影响这个决策的核心因素有三个:
| 因素 | 解释 |
|---|---|
| 过滤后的行数 | WHERE 条件过滤后,哪张表剩的行少,哪张表更适合当驱动表 |
| 被驱动表是否有索引 | 被驱动表有索引,每次查找是 O(log N);没索引就是全表扫 |
| 统计信息的准确性 | 优化器基于采样估算,如果统计信息过期,可能会选错 |
优化的核心原则 :小表驱动大表。这里的"小",不是指表的总行数,而是指过滤后实际要循环的行数。
2.3 用行数来验证一下差距
上面提到了代价模型,其中涉及到行数估算,下面还是拿刚才的例子来演示,让你感受一下这个过程。
方案 A:users(120万)驱动 articles(300条,有索引)
外层循环:120 万次
每次内层查找:走索引,约 log(500万) ≈ 23 次 I/O
总 I/O 估算:120万 × 23 ≈ 2760 万次方案 B:articles(300条)驱动 users(120万,走主键索引)
外层循环:300 次
每次内层查找:走主键索引,约 log(120万) ≈ 20 次 I/O
总 I/O 估算:300 × 20 ≈ 6000 次差了 4600 倍。这可不是玄学,这可是实实在在的数学。所以,优化器在统计信息准确的情况下,一定会选方案 B,可是它选了方案 A,这说明它的判断出问题了。那到底是那里有问题?
三、在 EXPLAIN 里如何看驱动表
从上面的分析可以看到,寻找驱动表对于 JOIN 连接很重要,若你没办法一眼就看出来,可以借助 EXPLAIN 执行计划来看,下面来看下,它没有那么神乎。
看的规则很简单 :EXPLAIN 输出结果中,id 相同时,从上到下第一张表就是驱动表。
+----+-------+------+
| id | table | type |
+----+-------+------+
| 1 | users | ALL | ← 驱动表(外层循环)
| 1 | articles | ref | ← 被驱动表(内层循环)
+----+-------+------+除了看驱动表,同时,还需要关注 Extra 列,那里有一个信号要特别注意:
Using join buffer (hash join) 或 Using join buffer (Block Nested Loop)
若这个提示出现在被驱动表那行,表明:被驱动表没有索引可用,MySQL 不得不把驱动表的数据缓存到 join buffer 里,然后批量比对。
这个信号通常说明两件事:
-
被驱动表的连接列上没有索引
-
这个 JOIN 的效率有优化空间
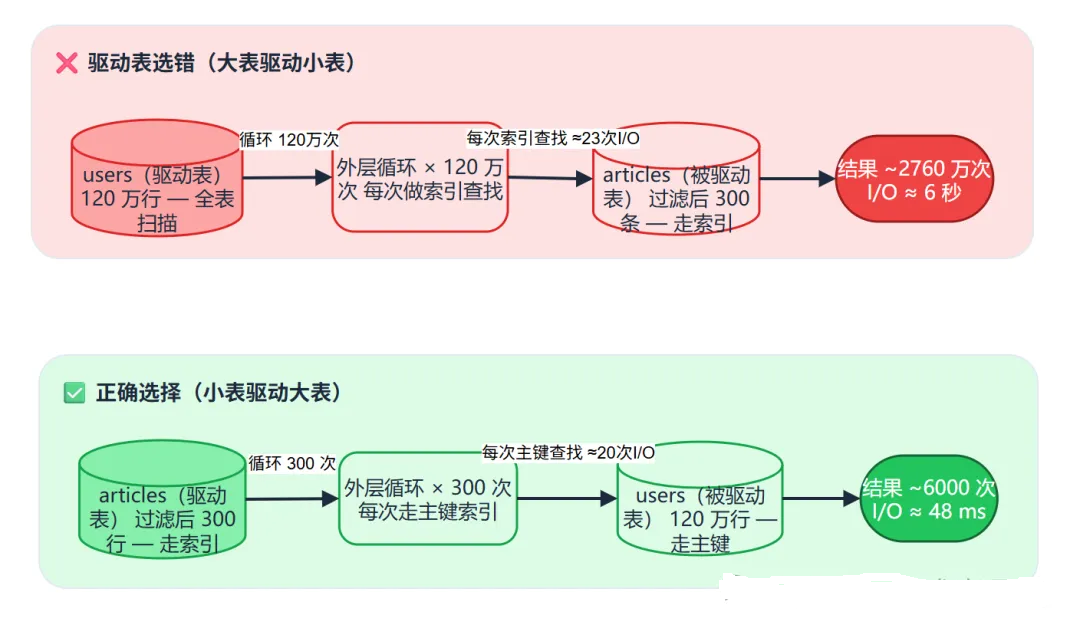
图2:NLJ 嵌套循环原理 --- 左边是大表驱动小表(错),右边是小表驱动大表(对)。循环次数的差异,决定了性能的天壤之别。
四、为什么优化器会选错
回到上面的问题,在2个方案对比中,明显有一个小表当驱动表应该选择,但为什么 MySQL 优化器却选错了驱动表?是不是 MySQL 傻了,当然不是。
出现 MySQL 选错驱动表,通常来有以下几种常见的原因:
原因 1:记录行数统计信息过期
MySQL 优化器依赖表的统计信息来估算行数。users 表如果最近刚做过大批量写入,统计信息还没更新,优化器可能还以为 users 只有几万行。
验证方法:
-- 查看 users 表的统计信息
SHOW TABLE STATUS LIKE 'users'\G
-- 或者
SELECT table_name, table_rows, data_length, update_time
FROM information_schema.tables
WHERE table_name = 'users';如果 table_rows 和实际相差很大,说明统计信息过期了。
修复方法:
ANALYZE TABLE users;
ANALYZE TABLE articles;执行完再 EXPLAIN 看看,通常优化器就会选对了。
原因 2:连接列缺索引
这是一个比较常见的问题,很多人在建表初期,可能没有考虑到后期会使用到多表关联,从而没有建立相关索引,回顾下,你是否也有做这种情况。来演示个例子,比如 articles.author_id 没有索引:
-- articles 表
CREATE TABLE articles (
id BIGINT PRIMARY KEY,
author_id BIGINT, -- 没有索引!
category_id INT,
title VARCHAR(200),
...
);这时候不管谁当驱动表,被驱动表都得全表扫。但如果 articles 当驱动表,300 行 × 全表扫 120 万 users = 灾难。
这种情况下,给 author_id 加索引是最重要的事:
ALTER TABLE articles ADD INDEX idx_author_id (author_id);加完索引,再 EXPLAIN,你会看到 articles 上来当驱动表,users 走主键索引------一切都对了。
原因 3:WHERE 过滤条件没有用上
有时候优化器估算的过滤率和实际偏差很大,比如:
-- articles 里 category_id = 12 的文章只有 300 条
-- 但优化器估算有 50000 条(因为采样不均匀)
WHERE a.category_id = 12优化器觉得 articles 过滤后还剩 50000 条,users 只有 120 万,于是选了 users 当驱动表(因为它觉得 articles 的结果集"不够小")。
这种情况可以用 MySQL 8.0 的直方图来辅助优化器:
-- 为 category_id 建立直方图,帮助优化器更准确地估算值分布
ANALYZE TABLE articles UPDATE HISTOGRAM ON category_id WITH 256 BUCKETS;直方图告诉优化器每个 category_id 的值分布情况,优化器就能更准确地估算过滤后的行数。
五、常见的几种典型驱动表问题
好了,上面对 JOIN 驱动表的知识进行讲解,也给出了一些示例,这里,我梳理了过往项目的实际经验,总结了几种常遇到的问题,你可以对照着看,是否也有做这种情况:
问题一:大表被当驱动表
特征:EXPLAIN 第一行是中行数多的大表,type 是 ALL 或 index
示例:
-- 错误情况
| 1 | users | ALL | 1200000 行 | ← 大表在前,全表扫
| 1 | articles | ref | 15 行 |修复 :通常是统计信息过期,执行 ANALYZE TABLE 后重新观察
问题二:被驱动表无索引
特征 :EXPLAIN 里看到 Using join buffer (hash join) 或 Using join buffer (Block Nested Loop)
示例:
| 1 | articles | ref | 300 行 |
| 1 | orders | ALL | 5000000 行 | Using join buffer (hash join)修复 :在 orders 表的连接列上加索引
-- 假设连接条件是 articles.id = orders.article_id
ALTER TABLE orders ADD INDEX idx_article_id (article_id);问题三:过滤条件没有配套索引
特征 :EXPLAIN 里 articles 的 type 是 ALL,但 WHERE category_id = 12 应该能过滤大量数据
修复:在过滤列加索引
ALTER TABLE articles ADD INDEX idx_category_id (category_id);
-- 或者加组合索引(过滤+连接+排序一起覆盖)
ALTER TABLE articles ADD INDEX idx_cat_author_created (category_id, author_id, created_at);问题四:强制指定驱动顺序(STRAIGHT_JOIN)
如果分析之后,你确认 MySQL 的选择是错的,但一时没法改表结构(比如加索引需要走审批流程),可以用 STRAIGHT_JOIN 强制指定连接顺序:
-- STRAIGHT_JOIN:强制 FROM 后第一张表作为驱动表
SELECT a.id, a.title, u.nickname
FROM articles a
STRAIGHT_JOIN users u ON a.author_id = u.id
WHERE a.category_id = 12
ORDER BY a.created_at DESC
LIMIT 20;注意 :STRAIGHT_JOIN 是应急手段,不是长期方案。因为它绕过了优化器的判断,一旦数据分布变了,原来"正确"的顺序可能就不对了。加完索引或更新完统计信息后,记得把它去掉。
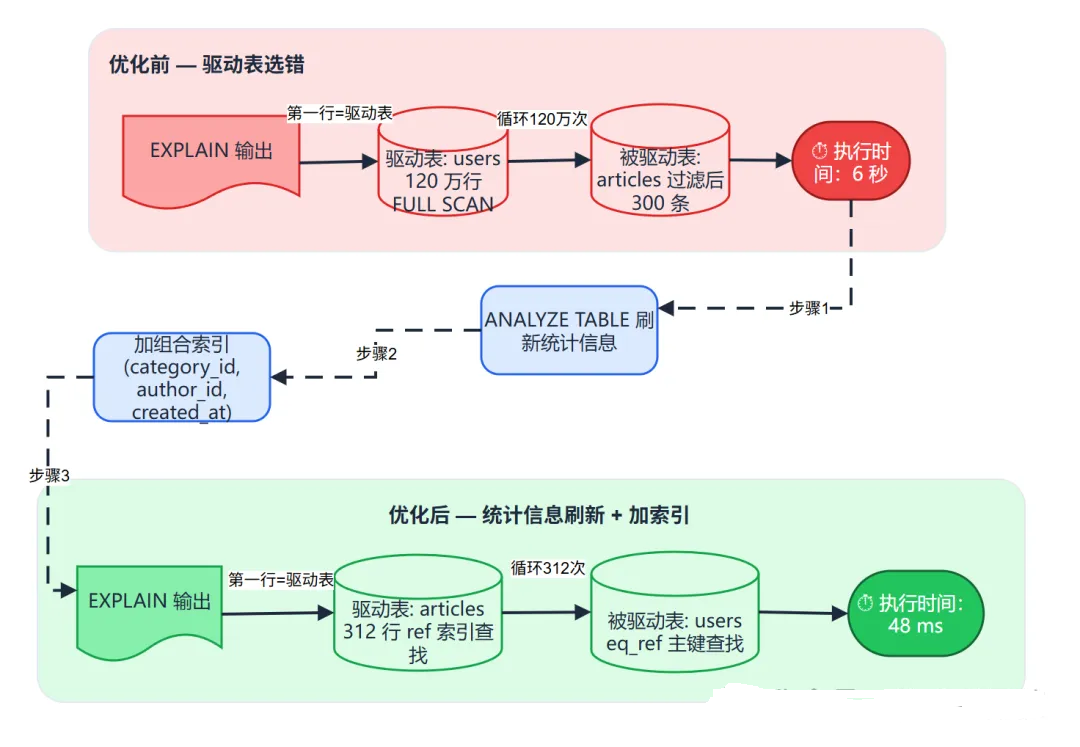
图3:优化前后对比 --- 上面是优化前(users 驱动,6 秒),下面是三步修复后(articles 驱动,48 毫秒)。
ANALYZE TABLE+ 组合索引,效果立竿见影。
六、实操:一个完整的排查与优化案例
我们回到开头那个 articles + users 的例子,完整走一遍排查流程。
第一步:定位慢 SQL
-- 开启慢查询日志
SET GLOBAL slow_query_log = ON;
SET GLOBAL long_query_time = 1;
-- 或者用 performance_schema 查当前在跑的慢 SQL
SELECT digest_text, avg_timer_wait/1000000000 AS avg_ms
FROM performance_schema.events_statements_summary_by_digest
ORDER BY avg_timer_wait DESC
LIMIT 10;第二步:EXPLAIN 确认驱动表问题
EXPLAIN SELECT a.id, a.title, a.content, u.nickname, u.avatar
FROM articles a
JOIN users u ON a.author_id = u.id
WHERE a.category_id = 12
ORDER BY a.created_at DESC
LIMIT 20;看到 users 排第一,type 是 ALL,120 万行------确认是驱动表选错。
第三步:刷新统计信息
ANALYZE TABLE articles;
ANALYZE TABLE users;第四步:再次 EXPLAIN
EXPLAIN SELECT ...(同上);这次结果:
+----+-------+------------+-------+-----------------------+---------+---------+-------+-----+-------------+
| id | table | type | key | key_len | ref | rows | Extra |
+----+-------+------------+-------+-----------------------+---------+---------+-------+-----+-------------+
| 1 | a | ref | idx_cat_author_created | 4 | const | 312 | Using where; Using index |
| 1 | u | eq_ref | PRIMARY | 8 | a.author_id | 1 | NULL |
+----+-------+------------+-------+-----------------------+---------+---------+-------+-----+-------------+articles 上来了,312 行做外层循环,users 走主键索引每次找 1 行。
执行时间:从 6 秒 → 48 毫秒。
第五步:补充组合索引(可选,但推荐)
如果 articles 表的查询模式比较固定(按 category + 排序),可以加一个覆盖索引:
ALTER TABLE articles
ADD INDEX idx_cat_created_cover (category_id, created_at DESC, author_id, id, title);这样过滤、排序、连接列都在索引里,不需要回表,Extra 会显示 Using index,性能还能再提升一截。
七、三种 JOIN 算法的横向对比
MySQL 8.0 里实际上有三种 JOIN 算法,搞清楚它们,你就能理解 Extra 里各种提示的含义:
| 算法 | 触发条件 | EXPLAIN Extra | 性能 |
|---|---|---|---|
| NLJ(嵌套循环) | 被驱动表有索引 | 无特殊提示 | ✅ 最好 |
| Hash Join | MySQL 8.0.18+,无索引等值连接 | Using join buffer (hash join) |
⚠️ 中等 |
| BNL(块嵌套循环) | < 8.0.20,无索引 | Using join buffer (Block Nested Loop) |
❌ 最差,8.0.20 起废弃 |
NLJ 是最优的。它利用被驱动表上的索引,外层每循环一次,内层只需要几次 I/O。
Hash Join 虽然没有 NLJ 快,但比老的 BNL 强多了,特别是连接列没有索引的情况下,它是当前(8.0.20+)的兜底方案。
如果你在 EXPLAIN 里看到 Using join buffer (hash join),说明被驱动表没有合适的索引------这是一个给连接列加索引的信号。
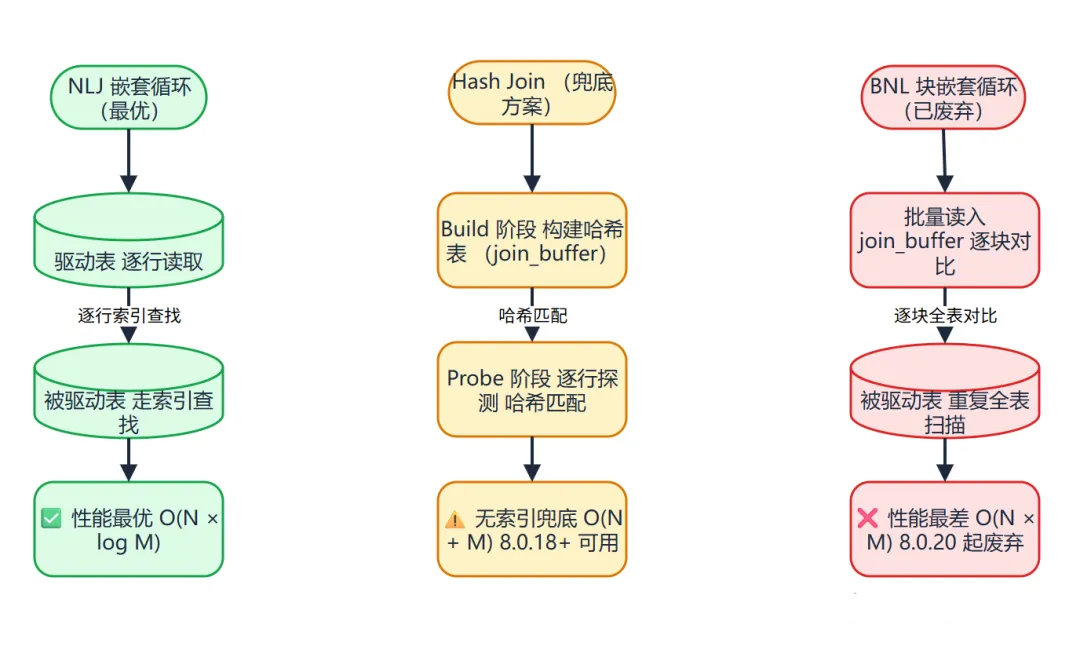
图4:MySQL 8.0 三种 JOIN 算法 --- 从左到右性能递减。
Using join buffer (hash join)出现在 Extra 里,就是提醒你:该给被驱动表加索引了。
八、JOIN 优化总结与速查表
一句话总结 JOIN 的相关知识点
| 核心知识点 | 一句话总结 |
|---|---|
| 驱动表 | 外层循环那张表,行数决定循环次数 |
| 被驱动表 | 内层循环那张表,必须有索引才高效 |
| 选择原则 | 过滤后行数少的表当驱动表(小表驱动大表) |
| EXPLAIN 读法 | id 相同时,第一行=驱动表 |
| Using join buffer | 被驱动表无索引,需要加索引的信号 |
| NLJ | 最优算法,前提是被驱动表有索引 |
| Hash Join | 8.0.18+ 的兜底算法,无索引时使用 |
| STRAIGHT_JOIN | 强制指定驱动顺序,应急用,不推荐长期使用 |
| ANALYZE TABLE | 刷新统计信息,解决优化器估算偏差 |
| 直方图 | 解决值分布不均匀导致的估算偏差 |
速查表,帮你快速定位问题
| 场景 | EXPLAIN 特征 | 解决方案 |
|---|---|---|
| 大表被选为驱动表 | 第一行 rows 很大,type=ALL | 执行 ANALYZE TABLE,刷新统计信息 |
| 被驱动表无索引 | Extra 显示 Using join buffer |
给被驱动表的连接列加索引 |
| 过滤条件没有索引 | 驱动表 rows 估算偏大 | 给 WHERE 条件列加索引,或建直方图 |
| 优化器持续选错 | 刷新统计后仍然不对 | 临时用 STRAIGHT_JOIN,同时查根因 |
| 多 JOIN 性能差 | 多个 Using join buffer |
逐个分析,从最外层驱动表开始修 |
| 值分布不均匀 | 统计信息准确但仍选错 | 使用直方图:ANALYZE TABLE ... UPDATE HISTOGRAM ON col |
写在最后
我在做代码 Review 时,经常看到这样的情况:一个 JOIN 写了两三层,索引也加了,但偏偏慢,改来改去摸不到头绪。
很多时候根因不是索引本身,而是驱动表搞反了。优化器做了一个基于统计信息的判断,但那个统计信息不准,或者没有足够的信息(比如缺了直方图),导致它做了一个在你看来不可思议的选择。
理解驱动表,记住三个动作:
-
EXPLAIN 看第一行,确认谁是驱动表
-
检查 Extra 有没有
Using join buffer,有的话给被驱动表加索引 -
统计信息过期就执行
ANALYZE TABLE,90% 的问题到这里就解了
写在最后:驱动表选错这件事,不是 MySQL 的 bug,而是它在用不完整的信息做决策。你给它更准确的信息(索引+统计信息+直方图),它就会做出正确的判断。从这个角度来看,学会看 EXPLAIN,就是学会跟 MySQL 的优化器"沟通"。
下期预告 :说完了 JOIN 的执行顺序,下一篇聊另一个高频踩坑:
NOT IN遇到 NULL 值,结果集莫名其妙变空------一个很多人踩了之后还没搞清楚原因的经典问题。记得星标,别错过。