目录
[1、客户端 ->连接器(Connection)](#1、客户端 ->连接器(Connection))
[2、连接表 ->查询缓存(Query Cache)](#2、连接表 ->查询缓存(Query Cache))
[3、连接器 ->分析器(Parser)](#3、连接器 ->分析器(Parser))
[4.分析器 -> 优化器(Optimizer)](#4.分析器 -> 优化器(Optimizer))
[5.优化器 -> 执行器(Executor)](#5.优化器 -> 执行器(Executor))
[6、执行器 -> 存储引擎(Storage Engine)](#6、执行器 -> 存储引擎(Storage Engine))
一、整体流程总览
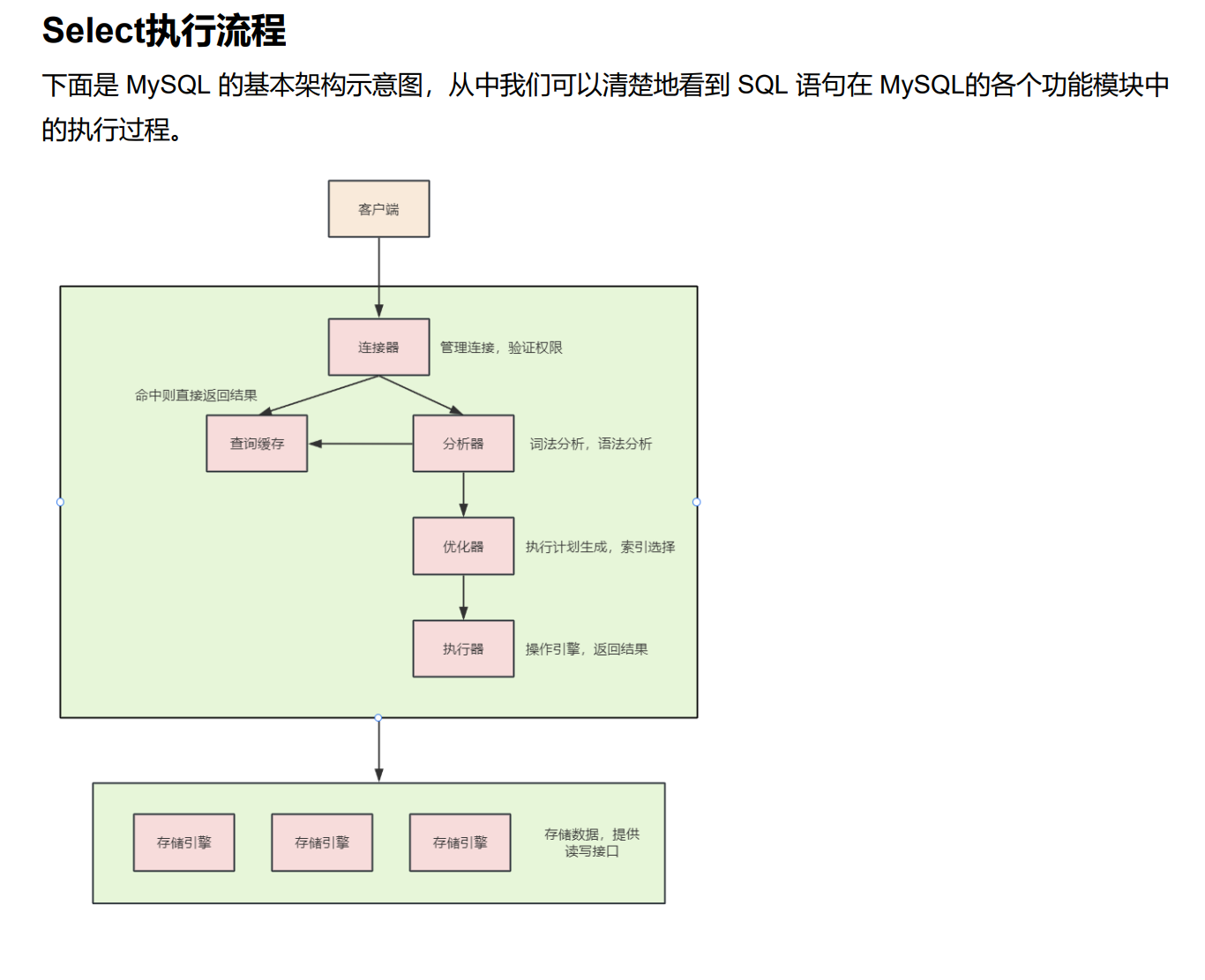
一条SELECT语句在MySQL里,从客户端发出到拿到结果,要经历这几个核心阶段:
-
连接器:建立连接、验证权限。
-
查询缓存:看看有没有现成结果。
-
分析器:词法 + 语法分析,解析 SQL。
-
优化器:生成执行计划,选索引、定执行顺序。
-
执行器:按计划调用存储引擎,拿到数据。
-
存储引擎:负责数据的读写。
二、逐渐段详细拆解
1、客户端 ->连接器(Connection)
作用:
- 管理客户端与MySQL的连接(TCP/IP、Socket等)。
- 验证用户名、密码是否正确
- 校验用户是否有对应表/列的查询权限
细节:
- 连接成功后,会维持一个会话,后续的所有请求都走这个连接。
- 权限是在连接建立时就验证好的,后续执行时不会再重复校验(除非权限被修改并刷新)。
2、连接表 ->查询缓存(Query Cache)
**注:**MySQL 8.0 版本已经彻底移除了查询缓存功能,因为它在高并发场景下效率极低,反而会拖慢性能。
作用:
- 直接用SQL语句作为key,查询结果作为value缓存起来。
- 如果缓存命中,直接返回结果,跳过后续所有步骤
为什么被移除:
只要表有任何数据修改(增删改),该表的所有缓存都会失效,高并发场景下缓存命中极低,维护成本极高
3、连接器 ->分析器(Parser)
如果缓存没命中(或没有缓存),就进入分析器阶段,分两步:
词法分析:
- 把整条SQL拆成一个个"词(Token)",比如SELECT、id、FROM、user等关键词、标识符。
语法分析:
- 根据MySQL的语法规则,检查SQL是否合法(比如少写了分号、关键词写错、表名不存在等)。
- 生成一颗抽象语法树(AST),方便后续优化器处理。
常见报错场景:
- 这里报的错一般是 You have an error in your SQL syntax,就是语法分析阶段发现的问题。
4.分析器 -> 优化器(Optimizer)
分析器只保证SQL语法正确,但"怎么执行最快"是优化器决定的。
- 核心工作:
- **生成多种执行方案:**如果多表连接的顺序、索引的选择、是否用临时表 / 排序等。
- **成本估算:**根据统计信息(索引基数、行数等),计算每个方案的执行成本。
- **选出最优执行计划:**最终确定一条执行路劲。
- 典型优化场景:
- 同一个SELECT可以选不同的索引,优化器会选成本最低的那个。
- 多表JOIN时,决定哪个表作为驱动表,减少循环次数。
- 查看方式:
- 可以用EXPLAIN SELECT ...查看优化器生成的执行计划。
5.优化器 -> 执行器(Executor)
优化器生成了执行计划,接下来就由执行器来"干活"了。
- 核心工作:
- 再次校验用户是否有操作该表 / 列的权限(防止优化阶段权限被修改)。
- 按照执行计划,调用存储引擎提供的接口(比如open table、read row)。
- 循环读取数据,过滤条件,拼接结果集。
- 和存储引擎的交互:
- 执行器只负责 "逻辑执行",数据的实际读写由存储引擎完成。
- 比如 InnoDB 提供了事务、行锁、MVCC 等能力,执行器会调用对应的接口。
6、执行器 -> 存储引擎(Storage Engine)
存储引擎是MySQL的底层模块,负责数据的持续化和读写。
- 常见引擎:
- InnoDB:MySQL 5.5+ 默认引擎,支持事务、行锁、MVCC、外键,是业务首选。
- MyISAM:不支持事务和行锁,只支持表锁,适合读多写少的场景,现在基本被淘汰。
- 工作流程:
- 执行器调用存储引擎的接口,存储引擎从磁盘 / 内存中读取数据,返回给执行器。
- 比如 InnoDB 会先从缓冲池(Buffer Pool)找数据,找不到再从磁盘读取。
三、完整示例:
以SELECT name FROM user WHERE id = 1;为例:
- 客户端发送 SQL → 连接器建立连接,验证权限。
- 连接器检查查询缓存(如果有),没命中 → 进入分析器。
- 分析器解析 SQL,拆词、语法校验,生成 AST。
- 优化器分析:id 是主键,选主键索引,生成执行计划。
- 执行器按计划调用 InnoDB 的接口,查询 id=1 的数据。
- InnoDB 从缓冲池 / 磁盘读取数据,返回给执行器。
- 执行器拼接结果,返回给客户端。
四、补充说明:为什么这个流程很重要?
理解这个流程,能帮你解决很多实际问题:
- 为什么 SELECT加了索引还是慢?→ 可能优化器没选对索引,或者统计信息过时了。
- 为什么 MySQL 8.0 之后查询缓存没了?→ 它的弊端远大于收益。
- 权限验证为什么要做两次?→ 防止优化阶段权限被修改,保证安全。