15 Logical Storage Structures(15 逻辑存储结构)
本章描述逻辑存储结构的性质及其相互关系。这些结构由 Oracle AI Database 创建和识别,而操作系统对此并不感知。
- Introduction to Logical Storage Structures(逻辑存储结构简介)
Oracle AI Database 为数据库中的所有数据分配逻辑空间。 - Overview of Data Blocks(数据块概述)
Oracle AI Database 以称为数据块(Data Block,也称为 Oracle 块或页(Page))的单元来管理数据库数据文件中的逻辑存储空间。数据块是数据库 I/O 的最小单元。 - Overview of Extents(区概述)
区(Extent)是由逻辑上连续的数据块组成的数据库存储单元。由于 RAID 条带化和文件系统实现,数据块在磁盘上可能是物理分散的。 - Overview of Segments(段概述)
段(Segment)是区的集合,包含表空间中某个逻辑存储结构的所有数据。 - Overview of Tablespaces(表空间概述)
表空间(Tablespace)是段的逻辑存储容器。
Introduction to Logical Storage Structures(逻辑存储结构简介)
Oracle AI Database 为数据库中的所有数据分配逻辑空间。
数据库空间分配的逻辑单元包括数据块、区、段和表空间。在物理层面,数据存储在磁盘的数据文件中。数据文件中的数据存储在操作系统块中。
下图是物理和逻辑存储的实体关系图。图中的"鸡爪"符号表示一对多关系。
Figure 15-1 Logical and Physical Storage(图15-1 逻辑与物理存储)
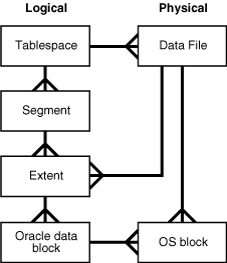
- Logical Storage Hierarchy(逻辑存储层次结构)
一个段包含一个或多个区,每个区又包含多个数据块。 - Logical Space Management(逻辑空间管理)
Oracle AI Database 必须使用逻辑空间管理来跟踪和分配表空间中的区。
相关参考:
- "Physical Storage Structures"(物理存储结构)
Logical Storage Hierarchy(逻辑存储层次结构)
一个段包含一个或多个区,每个区又包含多个数据块。
下图展示了表空间中数据块、区和段之间的关系。在此示例中,一个段有两个区,存储在不同的数据文件中。
Figure 15-2 Segments, Extents, and Data Blocks Within a Tablespace(图15-2 表空间中的段、区和数据块)
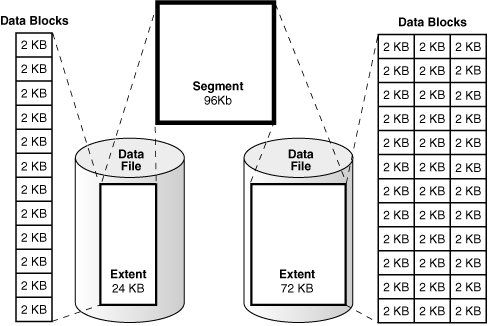
从最低粒度级别到最高级别,Oracle AI Database 按如下方式存储数据:
-
数据块(Data Block)是 Oracle AI Database 中最小的逻辑数据存储单元。
一个逻辑数据块对应于特定字节数的持久存储,例如 2 KB。数据块是 Oracle AI Database 可以使用或分配的最小存储单元。
传统上,数据文件存储在磁盘或固态硬盘(SSD)上。Oracle AI Database 也支持持久内存(PMEM)用于存储数据库文件。无论底层数据物理上如何存储,Oracle 进程始终读写逻辑数据块。
-
区(Extent)是为存储特定类型信息而分配的一组逻辑上连续的数据块。
在前面的图形中,24 KB 的区有 12 个数据块,而 72 KB 的区有 36 个数据块。
-
段(Segment)是为特定数据库对象(例如表)分配的一组区。
例如,
employees(员工)表的数据存储在其自己的数据段中,而employees表的每个索引存储在其自己的索引段中。每个消耗存储空间的数据库对象都由一个单独的段组成。 -
表空间(Tablespace)是包含一个或多个段的数据库存储单元。
每个段属于且仅属于一个表空间。因此,段的所有区都存储在同一个表空间中。在一个表空间内,一个段可以包含来自多个数据文件的区,如前面的图形所示。例如,一个段的某个区可能存储在
users01.dbf中,而另一个区存储在users02.dbf中。单个区绝不能跨数据文件。
相关参考:
- "Introduction to Physical Storage Structures"(物理存储结构简介)
Logical Space Management(逻辑空间管理)
Oracle AI Database 必须使用逻辑空间管理来跟踪和分配表空间中的区。
当数据库对象需要一个区时,数据库必须有一种方法来找到并分配它。同样,当对象不再需要一个区时,数据库必须有一种方法将释放的区变为可用。
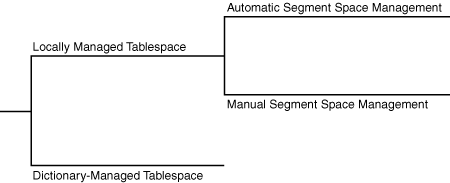
Oracle AI Database 根据您创建的表空间类型来管理表空间内的空间。您可以创建以下任一类型的表空间:
- Locally managed tablespaces(本地管理的表空间)(默认)
数据库使用表空间自身中的位图来管理区。因此,本地管理的表空间会留出一部分表空间用于位图。在表空间内,数据库可以使用自动段空间管理(ASSM)或手动段空间管理(MSSM)来管理段。 - Dictionary-managed tablespaces(字典管理的表空间)
数据库使用数据字典来管理区。
图 15-3 显示了表空间中逻辑空间管理的备选方案。
Figure 15-3 Logical Space Management(图15-3 逻辑空间管理)
- Locally Managed Tablespaces(本地管理的表空间)
本地管理的表空间在数据文件头部维护一个位图,以跟踪数据文件主体中的已用空间和空闲空间。 - Dictionary-Managed Tablespaces(字典管理的表空间)
字典管理的表空间使用数据字典来管理其区。
相关参考:
- "Overview of the Data Dictionary"(数据字典概述)
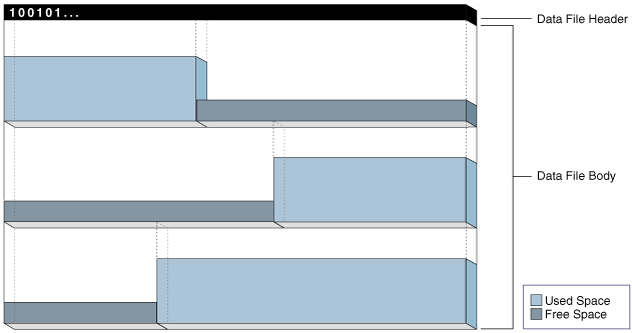
Locally Managed Tablespaces(本地管理的表空间)
本地管理的表空间在数据文件头部维护一个位图,以跟踪数据文件主体中的已用空间和空闲空间。
每个位对应一组块。当分配或释放空间时,Oracle AI Database 会更改位图中的值以反映块的新状态。
下图是位图管理存储的概念性表示。头部中的 1 表示已用空间,而 0 表示空闲空间。
Figure 15-4 Bitmap-Managed Storage(图15-4 位图管理的存储)
本地管理的表空间具有以下优点:
- 避免使用数据字典来管理区
如果消耗或释放区中的空间导致另一个操作消耗或释放数据字典表或撤销段中的空间,则字典管理的表空间中可能发生递归操作。 - 自动跟踪相邻的空闲空间
通过这种方式,数据库无需合并空闲区。 - 自动确定本地管理的区的大小
或者,在本地管理的表空间中,所有区可以具有相同的大小,并覆盖对象存储选项。
注意:Oracle 强烈建议使用带有自动段空间管理的本地管理表空间。
段空间管理是从包含段的表空间继承的属性。在本地管理的表空间内,数据库可以自动或手动管理段。例如,表空间 users 中的段可以自动管理,而表空间 tools 中的段则手动管理。
- Automatic Segment Space Management(自动段空间管理)
自动段空间管理(ASSM)方法使用位图来管理表空间中的空间。 - Manual Segment Space Management(手动段空间管理)
传统的手动段空间管理(MSSM)方法使用称为空闲列表(Free List)的链表来管理段中的空闲空间。
Automatic Segment Space Management(自动段空间管理)
自动段空间管理(ASSM)方法使用位图来管理表空间中的空间。
位图提供以下优点:
- 简化管理
ASSM 避免了手动为许多存储参数确定正确设置的需要。只有一个关键的 SQL 参数控制空间分配:PCTFREE。此参数指定为将来更新而在块中保留的空间百分比(请参阅 "Percentage of Free Space in Data Blocks"(数据块中的空闲空间百分比))。 - 增加并发性
多个事务可以搜索不同的空闲数据块列表,从而减少争用和等待。对于许多标准工作负载,使用 ASSM 的应用程序性能优于使用 MSSM 且经过良好调优的应用程序的性能。 - 在 Oracle Real Application Clusters (Oracle RAC) 环境中,空间与实例的动态亲和性
ASSM 效率更高,并且是永久、本地管理的表空间的默认设置。
注意:本章所有关于逻辑存储空间的讨论都假定使用 ASSM。
Manual Segment Space Management(手动段空间管理)
传统的手动段空间管理(MSSM)方法使用称为空闲列表(Free List)的链表来管理段中的空闲空间。
对于具有空闲空间的数据库对象,空闲列表跟踪高水位标志(High Water Mark,HWM)以下的数据块,HWM 是段空间中已用空间和尚未使用空间之间的分界线。当使用块时,数据库根据需要将块放入空闲列表或从空闲列表中移除。
除了 PCTFREE 之外,MSSM 还要求您使用诸如 PCTUSED、FREELISTS 和 FREELIST GROUPS 之类的 SQL 参数来控制空间分配。PCTUSED 设置当前已使用的块中必须存在的空闲空间百分比,数据库才能将其放入空闲列表。例如,如果您在 CREATE TABLE 语句中将 PCTUSED 设置为 40,则在块空间使用率低于 40% 之前,您不能向该段中的块插入行。
例如,假设您向表中插入一行。数据库检查表的空闲列表,寻找第一个可用块。如果该行不适合该块,并且块中的已用空间大于或等于 PCTUSED,则数据库将该块从列表中移除,并搜索另一个块。如果您从块中删除行,则数据库会检查块中的已用空间现在是否小于 PCTUSED。如果是,则数据库将该块放在空闲列表的开头。
一个对象可能有多个空闲列表。这样,对表执行 DML 的多个会话可以使用不同的列表,从而减少争用。每个数据库会话在其会话期间只使用一个空闲列表。
如图 15-5 所示,您还可以创建一个具有一个或多个空闲列表组(Free List Groups)的对象,这些组是空闲列表的集合。每个组都有一个管理组中各个进程空闲列表的主空闲列表(Master Free List)。空闲列表(特别是空闲列表组)的空间开销可能很大。
Figure 15-5 Free List Groups(图15-5 空闲列表组)
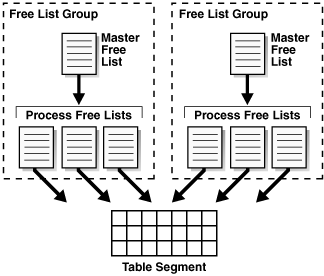
手动管理段空间可能很复杂。您必须调整 PCTFREE 和 PCTUSED 以减少行迁移并避免浪费空间。例如,如果段中每个已用块都是半满的,且 PCTUSED 为 40,则数据库不允许向这些块中的任何一个插入数据。由于微调空间分配参数很困难,Oracle 强烈建议使用 ASSM。在 ASSM 中,PCTFREE 决定新行是否可以插入到块中,但它不使用空闲列表,并忽略 PCTUSED。
相关参考:
- "Chained and Migrated Rows"(链接行和迁移行)
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解本地管理的表空间
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解有关自动段空间管理的更多信息
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解诸如
PCTFREE和PCTUSED的存储参数
Dictionary-Managed Tablespaces(字典管理的表空间)
字典管理的表空间使用数据字典来管理其区。
每当分配区或释放区以供重用时,Oracle AI Database 都会更新数据字典中的表。例如,当表需要一个区时,数据库会查询数据字典表,并搜索空闲区。如果数据库找到空间,它会修改一个数据字典表并在另一个表中插入一行。这样,数据库通过修改和移动数据来管理空间。
数据库在后台为获取数据库对象空间而执行的 SQL 是递归 SQL(Recursive SQL)。频繁使用递归 SQL 会对性能产生负面影响,因为对数据字典的更新必须序列化。默认的本地管理表空间避免了此性能问题。
相关参考:
《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何将表空间从字典管理迁移到本地管理。
Overview of Data Blocks(数据块概述)
Oracle AI Database 以称为数据块(Data Block,也称为 Oracle 块或页(Page))的单元来管理数据库数据文件中的逻辑存储空间。数据块是数据库 I/O 的最小单元。
- Data Blocks and Operating System Blocks(数据块与操作系统块)
在物理层面,数据库数据存储在由操作系统块组成的磁盘文件中。 - Data Block Format(数据块格式)
每个数据块都有一种格式或内部结构,使数据库能够跟踪块中的数据和空闲空间。无论数据块包含表、索引还是表簇数据,此格式都相似。 - Data Block Compression(数据块压缩)
数据库可以使用表压缩来消除数据块中的重复值。本节描述使用压缩的数据块的格式。 - Space Management in Data Blocks(数据块中的空间管理)
当数据库自下而上填充数据块时,行数据与块头部之间的空闲空间量会减少。 - Overview of Index Blocks(索引块概述)
索引块(Index Block)是一种特殊类型的数据块,其空间管理方式与表块不同。Oracle AI Database 使用索引块来管理索引中的逻辑存储空间。
Data Blocks and Operating System Blocks(数据块与操作系统块)
在物理层面,数据库数据存储在由操作系统块组成的磁盘文件中。
操作系统块(Operating System Block)是操作系统可以读取或写入的最小数据单元。相比之下,Oracle 块是一种逻辑存储结构,其大小和结构对操作系统是未知的。
下图显示操作系统块的大小可能与数据块不同。数据库以数据块为单位请求数据,而不是操作系统块。
Figure 15-6 Data Blocks and Operating System Blocks(图15-6 数据块与操作系统块)
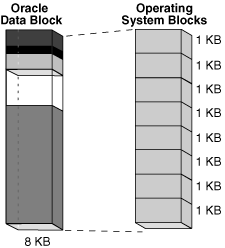
当数据库请求数据块时,操作系统将此操作转换为对持久存储中数据的请求。数据块与操作系统块的逻辑分离具有以下含义:
-
应用程序不需要确定数据在磁盘上的物理地址。
-
数据库数据可以在多个物理磁盘上进行条带化或镜像。
-
Database Block Size(数据库块大小)
每个数据库都有一个数据库块大小。
-
Tablespace Block Size(表空间块大小)
您可以创建单独的、其块大小与
DB_BLOCK_SIZE设置不同的表空间。
Database Block Size(数据库块大小)
每个数据库都有一个数据库块大小。
DB_BLOCK_SIZE 初始化参数在创建数据库时设置其数据块大小。该大小为 SYSTEM 和 SYSAUX 表空间设置,并且是所有其他表空间的默认值。数据库块大小无法更改,除非重新创建数据库。
如果未设置 DB_BLOCK_SIZE,则默认数据块大小是特定于操作系统的。数据库的标准数据块大小为 4 KB 或 8 KB。如果数据块和操作系统块的大小不同,则数据块大小必须是操作系统块大小的倍数。
相关参考:
- 《Oracle AI Database Reference》(《Oracle AI 数据库参考》),了解
DB_BLOCK_SIZE初始化参数 - 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》)和《Oracle AI Database Performance Tuning Guide》(《Oracle AI 数据库性能调优指南》),了解如何选择块大小
Tablespace Block Size(表空间块大小)
您可以创建单独的、其块大小与 DB_BLOCK_SIZE 设置不同的表空间。
当将可传输表空间移动到不同平台时,非标准块大小可能很有用。
相关参考:
《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何为表空间指定非标准块大小
Data Block Format(数据块格式)
每个数据块都有一种格式或内部结构,使数据库能够跟踪块中的数据和空闲空间。无论数据块包含表、索引还是表簇数据,此格式都相似。
下图显示了未压缩数据块的格式。
Figure 15-7 Data Block Format(图15-7 数据块格式)
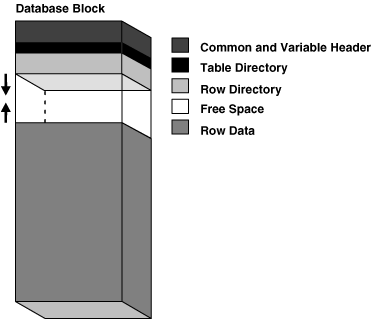
- Data Block Overhead(数据块开销)
Oracle AI Database 使用块开销来管理块本身。块开销不可用于存储用户数据。 - Row Format(行格式)
块的行数据部分包含实际数据,例如表行或索引键条目。正如每个数据块都有内部格式一样,每一行也都有行格式,使数据库能够跟踪行中的数据。
相关参考:
- "Data Block Compression"(数据块压缩),了解压缩块
Data Block Overhead(数据块开销)
Oracle AI Database 使用块开销来管理块本身。块开销不可用于存储用户数据。
如"Data Block Format"(数据块格式)所示,块开销包括以下部分:
-
块头(Block Header)
此部分包含关于块的通用信息,包括磁盘地址和段类型。对于事务管理的块,块头包含活动和历史事务信息。
每个更新块的事务都需要一个事务条目(Transaction Entry)。Oracle AI Database 最初在块头中为事务条目预留空间。在分配给支持事务更改的段的数据块中,当头部空间耗尽时,空闲空间也可以容纳事务条目。事务条目所需的空间取决于操作系统。但是,在大多数操作系统中,事务条目大约需要 23 字节。
-
表目录(Table Directory)
对于堆组织表,此目录包含关于其行存储在此块中的表的元数据。在表簇中,多个表可以将行存储在同一个块中。
-
行目录(Row Directory)
对于堆组织表,此目录描述块的数据部分中行的位置。数据库可以将行放置在块底部的任何位置。行地址记录在行目录向量的其中一个槽中。
rowid 指向特定的文件、块和行号。例如,在 rowid
AAAPecAAFAAAABSAAA中,末尾的AAA代表行号。行号是行目录中条目的索引。行目录条目包含指向数据块上行位置的指针。如果数据库在块内移动行,则数据库会更新行目录条目以修改指针。rowid 保持不变。数据库在行目录中分配空间后,即使在删除行之后也不会回收此空间。因此,一个当前为空但以前最多有 50 行的块,仍然会为行目录分配 100 字节。只有在会话向该块插入新行时,数据库才会重用此空间。
块开销的某些部分是固定大小的,但总大小是可变的。平均而言,块开销总计为 84 到 107 字节。
Row Format(行格式)
块的行数据部分包含实际数据,例如表行或索引键条目。正如每个数据块都有内部格式一样,每一行也都有行格式,使数据库能够跟踪行中的数据。
Oracle AI Database 将行存储为变长记录。一行包含在一个或多个部分中。每个部分称为一个行片段(Row Piece)。每个行片段都有行头和列数据。
下图显示了行的格式。
Figure 15-8 The Format of a Row Piece(图15-8 行片段的格式)
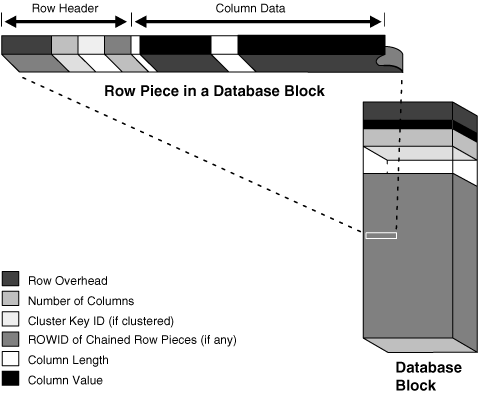
- Row Header(行头)
Oracle AI Database 使用行头来管理存储在块中的行片段。 - Column Data(列数据)
在行头之后,列数据部分存储行中的实际数据。行片段通常按CREATE TABLE语句中列出的顺序存储列,但此顺序不能保证。例如,LONG类型的列最后创建。 - Rowid Format(Rowid 格式)
Oracle AI Database 使用 rowid 唯一地标识一行。在内部,rowid 是一种结构,它持有数据库访问一行所需的信息。rowid 不是物理存储在数据库中,而是根据存储数据的文件和数据块推断出来的。
Row Header(行头)
Oracle AI Database 使用行头来管理存储在块中的行片段。
行头包含如下信息:
- 行片段中的列
- 位于其他数据块中的行片段
如果整行可以插入到单个数据块中,那么 Oracle AI Database 会将该行存储为一个行片段。但是,如果所有行数据无法插入到单个块中,或者更新导致现有行超出其块的大小,那么数据库会将行存储在多个行片段中。一个数据块通常每行只包含一个行片段。 - 表簇的簇键(Cluster keys)
完全包含在一个块中的行至少有 3 字节的行头。
相关参考:
- "Chained and Migrated Rows"(链接行和迁移行)
- "Overview of Table Clusters"(表簇概述)
Column Data(列数据)
在行头之后,列数据部分存储行中的实际数据。行片段通常按 CREATE TABLE 语句中列出的顺序存储列,但此顺序不能保证。例如,LONG 类型的列最后创建。
如"Row Format"(行格式)中的图所示,对于行片段中的每一列,Oracle AI Database 分别存储列长度和数据。所需空间取决于数据类型。如果列的数据类型是变长的,则容纳一个值所需的空间可以随着数据的更新而增减。
每一行在数据块头的行目录中都有一个槽。该槽指向行的开头。
相关参考:
"Table Storage"(表存储)和"Index Storage"(索引存储)
Rowid Format(Rowid 格式)
Oracle AI Database 使用 rowid 唯一地标识一行。在内部,rowid 是一种结构,它持有数据库访问一行所需的信息。rowid 不是物理存储在数据库中,而是根据存储数据的文件和数据块推断出来的。
扩展 rowid 包括数据对象编号。此 rowid 类型对每行的物理地址使用 base 64 编码。编码字符为 A-Z, a-z, 0-9, +, 和 /。
示例 15-1 ROWID Pseudocolumn(示例 15-1:ROWID 伪列)
以下示例查询 ROWID 伪列,以显示 employees 表中员工 100 所在行的扩展 rowid:
sql
SQL> SELECT ROWID FROM employees WHERE employee_id = 100;
ROWID
------------------
AAAPecAAFAAAABSAAA下图说明了扩展 rowid 的格式。
Figure 15-9 ROWID Format(图15-9 ROWID 格式)

扩展 rowid 以四部分格式显示,OOOOOOFFFBBBBBBRRR,该格式分为以下组件:
- OOOOOO
数据对象编号标识段(示例查询中的AAAPec数据对象)。每个数据库段都分配有一个数据对象编号。同一段中的模式对象(例如表簇)具有相同的数据对象编号。 - FFF
相对于表空间的数据文件编号,标识包含该行的数据文件(示例查询中的文件AAF)。 - BBBBBB
数据块编号,标识包含该行的块(示例查询中的块AAAABS)。块号是相对于其数据文件的,而不是其表空间。因此,具有相同块号的两行可能位于同一表空间的不同数据文件中。 - RRR
行号,标识块中的行(示例查询中的行AAA)。
在给行片段分配 rowid 之后,在特殊情况下 rowid 可能会改变。例如,如果启用了行移动,则由于分区键更新、闪回表操作、收缩表操作等,rowid 可能会改变。如果禁用了行移动,则如果使用 Oracle AI 数据库实用程序导出和导入行,rowid 可能会改变。
注意:在内部,数据库执行行移动时,就如同该行被物理删除并重新插入一样。但是,行移动被视为更新,这对触发器有影响。
相关参考:
- "Rowid Data Types"(Rowid 数据类型)
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解 rowid
Data Block Compression(数据块压缩)
数据库可以使用表压缩(Table Compression)来消除数据块中的重复值。本节描述使用压缩的数据块的格式。
使用基本表压缩和高级行压缩的数据块格式与未压缩的块基本相同。不同之处在于,块开头的一个符号表(Symbol Table)存储了行和列的重复值。数据库将这些值的出现替换为对符号表的短引用。
示例 15-2 Format of Compressed Data Blocks(示例 15-2:压缩数据块的格式)
假设以下行存储在一个用于七列 sales 表的数据块中:
2190,13770,25-NOV-00,S,9999,23,161
2225,15720,28-NOV-00,S,9999,25,1450
34005,120760,29-NOV-00,P,9999,44,2376
9425,4750,29-NOV-00,I,9999,11,979
1675,46750,29-NOV-00,S,9999,19,1121当对此表应用基本表压缩或高级行压缩时,数据库将重复值替换为符号引用。以下压缩的概念性表示显示符号 * 替换了 29-NOV-00,% 替换了 9999:
2190,13770,25-NOV-00,S,%,23,161
2225,15720,28-NOV-00,S,%,25,1450
34005,120760,*,P,%,44,2376
9425,4750,*,I,%,11,979
1675,46750,*,S,%,19,1121表 15-1 概念性地表示了将符号映射到值的符号表。
表 15-1 符号表
| 符号(Symbol) | 值(Value) | 列(Column) | 行(Rows) |
|---|---|---|---|
* |
29-NOV-00 |
3 | 958-960 |
% |
9999 |
5 | 956-960 |
相关参考:
"Table Compression"(表压缩)
Space Management in Data Blocks(数据块中的空间管理)
当数据库自下而上填充数据块时,行数据与块头部之间的空闲空间量会减少。
在更新期间,数据块中的空闲空间也可能缩小,例如当将尾随空值更改为非空值时。数据库管理数据块中的空闲空间以优化性能并避免浪费空间。
注意:本节假设使用自动段空间管理。
- Percentage of Free Space in Data Blocks(数据块中的空闲空间百分比)
PCTFREESQL 参数设置数据块中保留为用于更新现有行的空闲空间的最小百分比。PCTFREE对于防止行迁移和避免浪费空间很重要。 - Optimization of Free Space in Data Blocks(数据块中空闲空间的优化)
虽然空闲空间的百分比不能小于PCTFREE,但空闲空间量可以更大。例如,将PCTFREE设置为 20% 可防止空闲空间总量降至块的 5%,但允许块的 50% 为空闲空间。 - Chained and Migrated Rows(链接行和迁移行)
Oracle AI Database 使用链接和迁移来管理太大而无法放入单个块的行。
Percentage of Free Space in Data Blocks(数据块中的空闲空间百分比)
PCTFREE SQL 参数设置数据块中保留为用于更新现有行的空闲空间的最小百分比。PCTFREE 对于防止行迁移和避免浪费空间很重要。
例如,假设您创建一个只需要偶尔更新的表,其中大多数更新不会增加现有数据的大小。您在 CREATE TABLE 语句中指定 PCTFREE 参数,如下所示:
sql
CREATE TABLE test_table (n NUMBER) PCTFREE 20;图 15-10 显示了 PCTFREE 设置为 20 如何影响空间管理。随着时间的推移,数据库向块中添加行,导致行数据向上增长,朝向块头,而块头自身也向下扩展,朝向行数据。PCTFREE 设置确保至少 20% 的数据块是空闲的。例如,数据库阻止 INSERT 语句填充块,以至于行数据和头部加起来占用了块总空间的 90%,只留下 10% 的空闲空间。
Figure 15-10 PCTFREE(图15-10 PCTFREE)
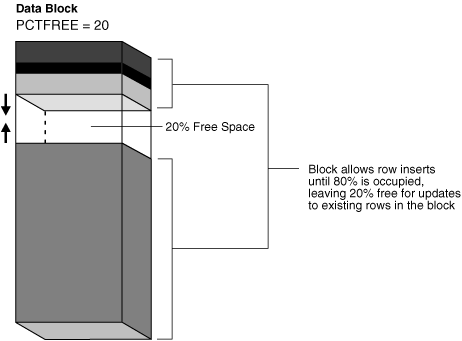
注意 :此讨论不适用于 LOB 数据类型,它们不使用
PCTFREE存储参数或空闲列表。
相关参考:
- 《Oracle AI Database SecureFiles and Large Objects Developer's Guide》(《Oracle AI 数据库 SecureFiles 和大对象开发人员指南》)
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
PCTFREE参数的语法和语义
Optimization of Free Space in Data Blocks(数据块中空闲空间的优化)
虽然空闲空间的百分比不能小于 PCTFREE,但空闲空间量可以更大。例如,将 PCTFREE 设置为 20% 可防止空闲空间总量降至块的 5%,但允许块的 50% 为空闲空间。
- Optimization by Increasing Free Space(通过增加空闲空间进行优化)
某些 DML 语句可以增加数据块中的空闲空间。 - Optimization by Coalescing Fragmented Space(通过合并碎片空间进行优化)
释放的空间可能与数据块中主要的空闲区域连续,也可能不连续。不连续的空闲空间称为碎片空间(Fragmented Space)。
Optimization by Increasing Free Space(通过增加空闲空间进行优化)
某些 DML 语句可以增加数据块中的空闲空间。
以下语句可以增加空间:
DELETE语句- 将现有值更新为更小值,或增加现有值并强制行迁移的
UPDATE语句 - 在使用高级行压缩的表上的
INSERT语句
如果INSERT语句用数据填充了块,则数据库会调用块压缩,这可能导致块具有更多的空闲空间。
释放的空间在以下条件下可供 INSERT 语句使用:
- 如果
INSERT语句与释放空间的语句在同一事务中,并且位于该语句之后,则此语句可以使用该空间。 - 如果
INSERT语句与释放空间的语句(可能由其他用户运行)在不同的事务中,并且需要空间,则此语句可以使用已释放的空间,但前提是另一事务已提交。
相关参考:
《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解高级行压缩
Optimization by Coalescing Fragmented Space(通过合并碎片空间进行优化)
释放的空间可能与数据块中主要的空闲区域连续,也可能不连续。不连续的空闲空间称为碎片空间(Fragmented Space)。
下图显示了一个具有不连续空闲空间的数据块。
Figure 15-11 Data Block with Fragmented Space(图15-11 具有碎片空间的数据块)
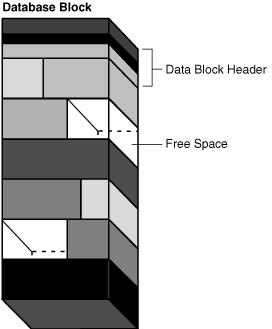
仅当以下条件为真时,Oracle AI Database 才会自动透明地合并数据块的空闲空间:
INSERT或UPDATE语句尝试使用一个包含足够空闲空间以容纳新行片段的块。- 空闲空间是碎片化的,以至于无法将行片段插入到该块的连续区域中。
合并后,空闲空间量与操作前的量相同,但空间现在是连续的。图 15-12 显示了合并空闲空间后的数据块。
Figure 15-12 Data Block After Coalescing Free Space(图15-12 合并空闲空间后的数据块)
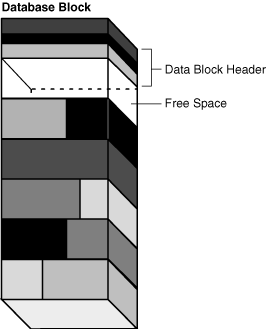
Oracle AI Database 仅在上述情况下执行合并,因为否则会由于数据块中空闲空间的持续合并而降低性能。
Chained and Migrated Rows(链接行和迁移行)
Oracle AI Database 使用链接和迁移来管理太大而无法放入单个块的行。
注意:标准表中的链接行不同于区块链表中的行链。Oracle AI Database 使用不同的技术来管理区块链表中的行。
可能出现以下情况:
-
行在首次插入时太大,无法容纳在一个数据块中。
在行链接(Row Chaining)中,Oracle AI Database 将行的数据存储在一个或多个为该段保留的数据块链中。行链接最常发生在大型行中。示例包括包含
LONG或LONG RAW数据类型列的行,或者具有大量列的行。在这些情况下的行链接是不可避免的。 -
最初适合一个数据块的行被更新,使得总行长度增加,但不足以容纳更新后行的空闲空间。
在行迁移(Row Migration)中,Oracle AI Database 将整行移动到一个新数据块,前提是该行能够适应新块。迁移行的原始行片段包含一个指向包含迁移行的新块的指针或"转发地址"。迁移行的 rowid 不会改变。
-
行具有 255 列以上。
Oracle AI Database 在一个行片段中最多只能存储 255 列。因此,如果您将一行插入具有 1000 列的表,则数据库会创建 4 个行片段,通常跨多个块链接。
图 15-13 描述了在一个数据块中插入一个大行。该行对于左侧块来说太大,因此数据库通过将第一个行片段放在左侧块中,第二个行片段放在右侧块中来链接该行。
Figure 15-13 Row Chaining(图15-13 行链接)
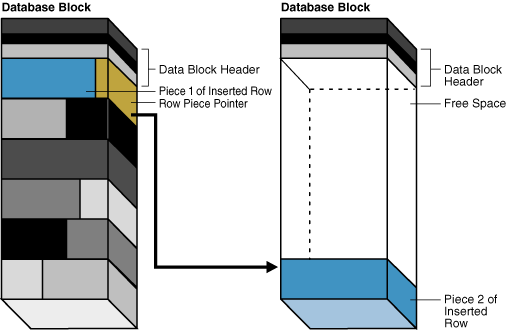
在图 15-14 中,左侧块包含一行,该行被更新后对于块来说太大了。数据库将整行移动到右侧块,并在左侧块中留下一个指向迁移行的指针。
Figure 15-14 Row Migration(图15-14 行迁移)
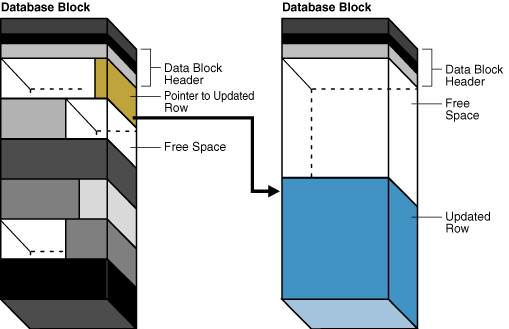
当行被链接或迁移时,检索数据所需的 I/O 会增加。发生这种情况是因为 Oracle AI Database 必须扫描多个块才能检索行的信息。例如,如果数据库执行一次 I/O 来读取索引,执行一次 I/O 来读取未迁移的表行,那么获取迁移行的数据就需要额外一次 I/O。
段顾问(Segment Advisor),既可以手动运行也可以自动运行,是 Oracle AI Database 的一个组件,它识别有空间可供回收的段。顾问可以就具有大量空闲空间或过多链接行的对象提供建议。
相关参考:
- "Row Storage"(行存储)和"Rowids of Row Pieces"(行片段的 Rowid)
- "Overview of Blockchain Tables"(区块链表概述)
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何回收浪费的空间
- 《Oracle AI Database Performance Tuning Guide》(《Oracle AI 数据库性能调优指南》),了解如何减少链接行和迁移行
Overview of Index Blocks(索引块概述)
索引块(Index Block)是一种特殊类型的数据块,其空间管理方式与表块不同。Oracle AI Database 使用索引块来管理索引中的逻辑存储空间。
- Types of Index Blocks(索引块的类型)
索引包含根块、分支块和叶块。 - Storage of Index Entries(索引条目的存储)
索引条目以与数据块中表行相同的方式存储在索引块中。块部分中的索引条目不是以二进制顺序存储的,而是以堆的方式存储。 - Reuse of Slots in an Index Block(索引块中槽的重用)
数据库可以重用索引块内的空间。 - Coalescing an Index Block(合并索引块)
索引合并(Coalescing)会原地压缩现有的索引数据,并且如果重组释放了块,则会将空闲块留在索引结构中。因此,合并不会为其他用途释放索引块,也不会导致索引重新分配块。
Types of Index Blocks(索引块的类型)
索引包含根块、分支块和叶块。
块类型定义如下:
- 根块(Root Block)
此块标识索引的入口点。 - 分支块(Branch Blocks)
数据库在搜索索引键时导航通过分支块。 - 叶块(Leaf Blocks)
这些块包含指向关联行的索引键值 rowid。叶块按排序顺序存储键值,以便数据库可以高效地搜索一系列键值中的所有行。
Storage of Index Entries(索引条目的存储)
索引条目以与数据块中表行相同的方式存储在索引块中。块部分中的索引条目不是以二进制顺序存储的,而是以堆的方式存储。
数据库管理索引块中的行目录的方式与数据块中的目录不同。行目录中的条目(而不是索引块主体中的条目)按键值排序。例如,在行目录中,索引键 000000 的目录条目排在索引键 111111 的目录条目之前,依此类推。
行目录中条目的排序提高了索引扫描的效率。在范围扫描中,数据库必须读取范围中指定的所有索引键。数据库遍历分支块以识别包含第一个键的叶块。由于行目录中的条目已排序,数据库可以使用二分查找在范围中找到第一个索引键,然后按顺序遍历行目录中的条目,直到找到最后一个键。这样,数据库避免了读取叶块主体中的所有键。
相关参考:
"Data Block Overhead"(数据块开销)
Reuse of Slots in an Index Block(索引块中槽的重用)
数据库可以重用索引块内的空间。
例如,应用程序可能将一个值插入到列中,然后又删除该值。当一行需要空间时,数据库可以重用先前由已删除值占用的索引槽。
索引块通常比堆组织表块拥有多得多的行。能够在单个索引块中存储许多行,使得数据库更容易维护索引,因为它避免了频繁地为了存储新数据而分裂块。
索引不能自行合并,尽管您可以使用带有 REBUILD 或 COALESCE 选项的 ALTER INDEX 语句手动合并它。例如,如果用值 1 到 500000 填充一列,然后删除所有偶数行,那么索引将包含 250,000 个空槽。只有当数据库可以插入适合包含空槽的索引块的数据时,才会重用该槽。
Coalescing an Index Block(合并索引块)
索引合并(Coalescing)会原地压缩现有的索引数据,并且如果重组释放了块,则会将空闲块留在索引结构中。因此,合并不会为其他用途释放索引块,也不会导致索引重新分配块。
Oracle AI Database 不会自动压缩索引:您必须运行带有 REBUILD 或 COALESCE 选项的 ALTER INDEX 语句。
图 15-15 显示了合并前 employees.department_id 列的索引。前三个叶块仅部分填充,如灰色填充线所示。
Figure 15-15 Index Before Coalescing(图15-15 合并前的索引)
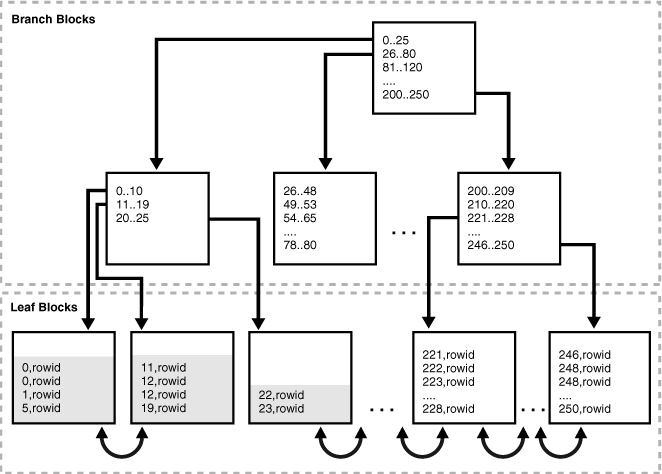
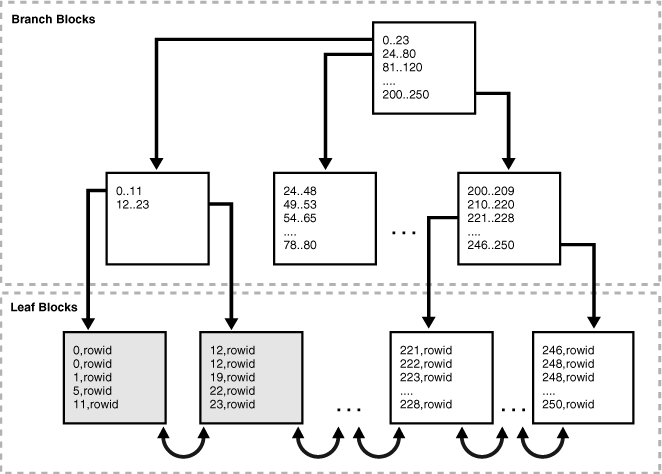
图 15-16 显示了图 15-15 中的索引在合并后的样子。前两个叶块现在已满,如灰色填充线所示,而第三个叶块已被释放。
Figure 15-16 Index After Coalescing(图15-16 合并后的索引)
相关参考:
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何合并和重建索引
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
COALESCE语句
Overview of Extents(区概述)
区(Extent)是由逻辑上连续的数据块组成的数据库存储单元。由于 RAID 条带化和文件系统实现,数据块在磁盘上可能是物理分散的。
- Allocation of Extents(区的分配)
默认情况下,当创建段时,数据库为其分配一个初始区。一个区总是包含在一个数据文件中。 - Deallocation of Extents(区的释放)
通常,用户段的区不会返回给表空间,除非您使用DROP语句删除该对象。 - Storage Parameters for Extents(区的存储参数)
每个段都由以区为单位表示的存储参数定义。这些参数控制 Oracle AI Database 如何为段分配空闲空间。
Allocation of Extents(区的分配)
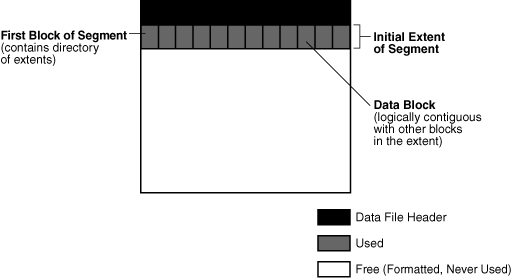
默认情况下,当创建段时,数据库为其分配一个初始区。一个区总是包含在一个数据文件中。
尽管尚未向段添加数据,但初始区中的数据块是专门为该段保留的。每个段的第一个数据块都包含该段中区的目录。图 15-17 展示了一个数据文件中的一个段的初始区,该文件此前未包含任何数据。
Figure 15-17 Initial Extent of a Segment(图15-17 段的初始区)
如果初始区已满,并且需要更多空间,则数据库会自动为此段分配一个增量区(Incremental Extent)。增量区是随后为段创建的区。
分配算法取决于表空间是本地管理的还是字典管理的。在本地管理的情况下,数据库搜索数据文件的位图以查找相邻的空闲块。如果数据文件空间不足,则数据库会查找另一个数据文件。一个段的区始终位于同一个表空间中,但可能位于不同的数据文件中。
图 15-18 显示数据库可以在表空间中的任何数据文件中为一个段分配区。例如,该段可以在 users01.dbf 中分配初始区,在 users02.dbf 中分配第一个增量区,然后在 users01.dbf 中分配下一个区。
Figure 15-18 Incremental Extent of a Segment(图15-18 段的增量区)
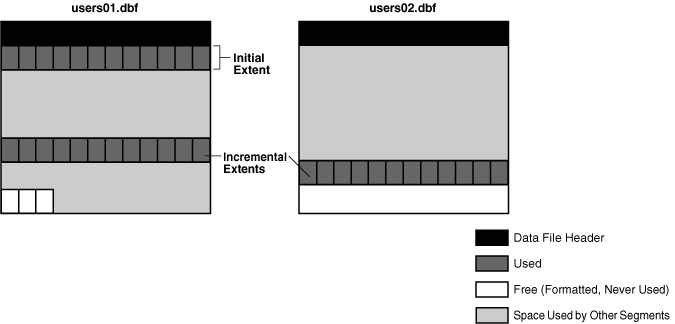
新分配的区的块,尽管是空闲的,但可能并非没有旧数据。在 ASSM 中,Oracle AI Database 在开始使用区时,会根据需要格式化新分配的区的块。
注意:本节适用于串行操作,其中一个服务器进程(Server Process)解析并运行一条语句。数据库在并行 SQL 语句中以不同方式分配区,这涉及多个服务器进程。
相关参考:
- "Segment Space and the High Water Mark"(段空间与高水位标志)
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何手动分配区
Deallocation of Extents(区的释放)
通常,用户段的区不会返回给表空间,除非您使用 DROP 语句删除该对象。
例如,如果您删除了表中的所有行,数据库不会回收这些数据块以供表空间中的其他对象使用。您也可以使用 DBMS_SPACE_ADMIN 包来删除段。
注意 :在撤销段中,如果指定了
OPTIMAL大小,或者数据库处于自动撤销管理模式,Oracle AI Database 会定期释放一个或多个区。
在某些情况下,您可以手动释放空间。Oracle 段顾问(Segment Advisor)根据对象中的碎片程度,帮助判断对象是否有可供回收的空间。以下技术可以释放区:
- 使用联机段收缩来回收段中的碎片空间。段收缩是一种联机、原地的操作。通常,数据压缩可以带来更好的缓存利用率,并且在全表扫描中需要读取更少的块。
- 将非分区表或表分区的数据移动到新段,并可选地移动到一个您有配额的不同表空间。
- 重建或合并索引。
- 截断表或表簇,这将删除所有行。默认情况下,Oracle AI Database 释放由已删除行使用的所有空间,但
MINEXTENTS存储参数指定的空间除外。从 Oracle Database 11g 第 2 版 (11.2.0.2) 开始,您还可以将TRUNCATE与DROP ALL STORAGE选项一起使用来删除整个段。 - 释放未使用的空间,这将释放数据库段高水位标志末端未使用的空间,并使该空间可供表空间中的其他段使用。
当区被释放时,对于本地管理的表空间,Oracle AI Database 会修改数据文件中的位图,以将回收的区反映为可用空间。已释放区的块中的任何数据都将变得不可访问。
相关参考:
- "Coalescing an Index Block"(合并索引块)
- "Undo Tablespaces"(撤销表空间)
- "Segment Space and the High Water Mark"(段空间与高水位标志)
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何回收段空间
Storage Parameters for Extents(区的存储参数)
每个段都由以区为单位表示的存储参数定义。这些参数控制 Oracle AI Database 如何为段分配空闲空间。
存储设置按以下优先顺序确定,列表中位置更高的设置会覆盖位置更低的设置:
- 段存储子句
- 表空间存储子句
- Oracle AI Database 默认值
本地管理的表空间可以具有统一的区大小,或者由系统自动确定的可变区大小:
- 对于统一区,您可以指定区大小,或使用 1 MB 的默认大小。表空间中的所有区都具有此大小。本地管理的临时表空间只能使用这种分配类型。
- 对于自动分配的区,Oracle AI Database 会确定附加区的最佳大小。
对于本地管理的表空间,某些存储参数不能在表空间级别指定。但是,您可以在段级别指定这些参数。在这种情况下,数据库会一起使用所有参数来计算段的初始大小。内部算法决定每个后续区的大小。
相关参考:
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解创建本地管理的表空间时的区管理注意事项
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解存储子句中的选项
Overview of Segments(段概述)
段(Segment)是区的集合,包含表空间中某个逻辑存储结构的所有数据。
例如,Oracle AI Database 分配一个或多个区来形成表的数据段。数据库还分配一个或多个区来形成表上索引的索引段。
Oracle AI Database 自动或手动管理段空间。本节假设使用 ASSM。
- User Segments(用户段)
数据库中的单个数据段存储一个用户对象的数据。 - Temporary Segments(临时段)
在处理查询时,Oracle AI Database 经常需要临时工作区用于 SQL 语句执行的中间阶段。 - Undo Segments(撤销段)
Oracle AI Database 维护事务操作的记录,统称为撤销数据(Undo Data)。 - Segment Space and the High Water Mark(段空间与高水位标志)
为了管理空间,Oracle AI Database 跟踪段中块的状态。高水位标志(High Water Mark,HWM)是段中的一个点,超过该点的数据块是未格式化且从未使用过的。
相关参考:
"Logical Space Management"(逻辑空间管理),了解有关 ASSM 的更多信息
User Segments(用户段)
数据库中的单个数据段存储一个用户对象的数据。
存在不同类型的段。用户段的示例如下:
- 表、表分区或表簇
- LOB 或 LOB 分区
- 索引或索引分区
每个非分区对象和对象分区都存储在其自己的段中。例如,如果一个索引有五个分区,那么就有五个段包含索引数据。
- User Segment Creation(用户段创建)
默认情况下,数据库使用延迟段创建(Deferred Segment Creation),仅在创建表、索引和分区时更新数据库元数据。
User Segment Creation(用户段创建)
默认情况下,数据库使用延迟段创建(Deferred Segment Creation),仅在创建表、索引和分区时更新数据库元数据。
当用户向表或分区插入第一行时,数据库会为该表或分区、其 LOB 列及其索引创建段。延迟段创建避免了不必要地使用数据库资源。例如,安装应用程序可能会创建数千个对象,消耗大量磁盘空间。其中许多对象可能永远不会被使用。
DBMS_SPACE_ADMIN 包管理空对象的段。您可以使用此 PL/SQL 包执行以下操作:
- 为没有创建段的空表或分区手动物化段
- 从当前已分配空段的空表或分区中移除段
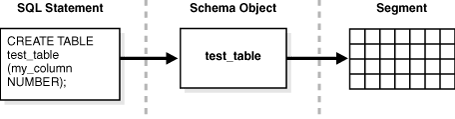
为了更好地说明对象创建和段创建之间的关系,假设禁用了延迟段创建。您创建一个表,如下所示:
sql
CREATE TABLE test_table (my_column NUMBER);如图 15-19 所示,数据库为该表创建一个段。
Figure 15-19 Creation of a User Segment(图15-19 用户段的创建)
当您创建一个带有主键或唯一键的表时,Oracle AI Database 会自动为此键创建一个索引。再次假设禁用了延迟段创建。您创建一个表,如下所示:
sql
CREATE TABLE lob_table (my_column NUMBER PRIMARY KEY, clob_column CLOB);图 15-20 显示 lob_table 的数据存储在一个段中,而隐式创建的索引位于不同的段中。此外,CLOB 数据存储在其自己的段中,与其关联的 CLOB 索引一样。因此,CREATE TABLE 语句导致创建四个不同的段。
Figure 15-20 Multiple Segments(图15-20 多个段)
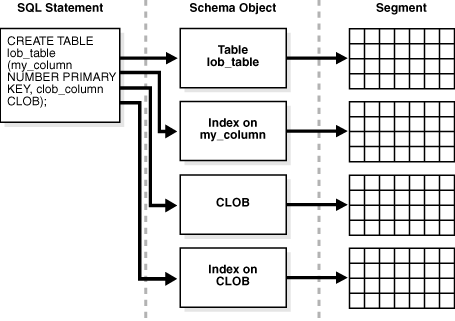
注意:一个表的段和该表的索引不必占用相同的表空间。
创建段时,数据库会分配一个或多个区。对象的存储参数决定了如何为每个段分配区。这些参数影响与该对象关联的数据段的数据检索和存储效率。
相关参考:
- 《Oracle AI Database SecureFiles and Large Objects Developer's Guide》(《Oracle AI 数据库 SecureFiles 和大对象开发人员指南》),了解内部 LOB
- "Storage Parameters for Extents"(区的存储参数)
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何管理延迟段创建
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
CREATE TABLE语法
Temporary Segments(临时段)
在处理查询时,Oracle AI Database 经常需要临时工作区用于 SQL 语句执行的中间阶段。
可能需要临时段(Temporary Segment)的典型操作包括排序、哈希和合并位图。创建索引时,Oracle AI Database 也会将索引段放入临时段,然后在索引完成时将它们转换为永久段。
如果操作可以在内存中执行,Oracle AI Database 不会创建临时段。但是,如果无法使用内存,数据库会自动在磁盘上分配临时段。
- Allocation of Temporary Segments for Queries(为查询分配临时段)
Oracle AI Database 在用户会话期间根据需要为查询分配临时段,并在查询完成时删除它们。对临时段的更改不会记录在联机重做日志中,但对临时段的空间管理操作除外。 - Allocation of Segments for Temporary Tables and Indexes(为临时表和索引分配段)
Oracle AI Database 可以为临时表及其索引分配临时段。
Allocation of Temporary Segments for Queries(为查询分配临时段)
Oracle AI Database 在用户会话期间根据需要为查询分配临时段,并在查询完成时删除它们。对临时段的更改不会记录在联机重做日志中,但对临时段的空间管理操作除外。
数据库在分配给用户的临时表空间中创建临时段。表空间的默认存储特性决定了临时段中区的特性。由于临时段的分配和释放频繁发生,最佳实践是至少为临时段创建一个专用表空间。数据库将 I/O 分布到磁盘上,并避免临时段碎片化 SYSTEM 和其他表空间。
注意 :当
SYSTEM是本地管理时,必须在数据库创建时定义一个默认临时表空间。不能将本地管理的SYSTEM表空间用于默认临时存储。
相关参考:
- "Overview of the Online Redo Log"(联机重做日志概述)
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何创建临时表空间
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
CREATE TEMPORARY TABLESPACE的语法和语义
Allocation of Segments for Temporary Tables and Indexes(为临时表和索引分配段)
Oracle AI Database 可以为临时表及其索引分配临时段。
临时表保存的数据仅在事务或会话期间存在。每个会话只能访问为其自身分配的区,不能访问为其他会话分配的区。
Oracle AI Database 在首次向全局临时表执行 INSERT 时为该表分配段,而对于私有临时表,则仅在需要时分配段。插入可以显式发生,也可以因为 CREATE TABLE AS SELECT 而发生。数据库会为该表及其索引分配段,为索引创建根页,并分配任何 LOB 段。
当前用户的临时表空间为临时表分配段。例如,分配给 user1 的临时表空间是 temp1,分配给 user2 的临时表空间是 temp2。在这种情况下,user1 将临时数据存储在 temp1 的段中,而 user2 将临时数据存储在 temp2 的段中。
相关参考:
- "Overview of Temporary Tables"(临时表概述)
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何创建临时表
Undo Segments(撤销段)
Oracle AI Database 维护事务操作的记录,统称为撤销数据(Undo Data)。
Oracle AI Database 使用撤销数据来执行以下操作:
- 回滚活动事务
- 恢复已终止的事务
- 提供读一致性(Read Consistency)
- 执行某些逻辑闪回操作
Oracle AI Database 将撤销数据存储在数据库内部,而不是外部日志中。撤销数据存储在块中,这些块的更新方式与数据块类似,对这些块的更改会生成重做记录。这样,Oracle AI Database 可以高效地访问撤销数据,而无需读取外部日志。
永久对象的撤销数据存储在撤销表空间(Undo Tablespace)中。Oracle AI Database 提供了一种全自动机制,称为自动撤销管理模式(Automatic Undo Management Mode),用于管理撤销段和撤销表空间中的空间。
数据库将撤销数据分为两个流。临时撤销流(Temporary Undo Stream)仅封装由临时对象更改生成的撤销记录,而永久撤销流(Permanent Undo Stream)仅封装永久对象的撤销记录。数据库独立管理临时和永久撤销。撤销分离通过以下方式减少存储并提高性能:
- 使您能够配置最适合永久表和临时表工作负载的永久和撤销表空间大小
- 减少写入联机重做日志的重做大小
- 避免备份临时撤销数据的需要
在 Active Data Guard 实例上,对全局临时表的 DML 需要在临时撤销段中生成撤销。
- Undo Segments and Transactions(撤销段与事务)
当事务启动时,数据库将该事务绑定(分配)到当前撤销表空间中的一个撤销段,从而绑定到一个事务表(Transaction Table)。在极少数情况下,如果数据库实例没有指定的撤销表空间,则该事务会绑定到系统撤销段。 - Transaction Rollback(事务回滚)
当发出ROLLBACK语句时,数据库使用撤销记录来回滚未提交事务对数据库所做的更改。 - Temporary Undo Segments(临时撤销段)
临时撤销段(Temporary Undo Segment)是仅用于临时撤销数据的可选空间管理容器。
相关参考:
- "Use of the Online Redo Log"(联机重做日志的使用)
- "Temporary Undo Segments"(临时撤销段)
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解临时撤销段
- 《Oracle AI Database Reference》(《Oracle AI 数据库参考》),了解
TEMP_UNDO_ENABLED初始化参数
Undo Segments and Transactions(撤销段与事务)
当事务启动时,数据库将该事务绑定(分配)到当前撤销表空间中的一个撤销段,从而绑定到一个事务表(Transaction Table)。在极少数情况下,如果数据库实例没有指定的撤销表空间,则该事务会绑定到系统撤销段。
多个活动事务可以同时写入同一个撤销段或不同的段。例如,事务 T1 和 T2 可以都写入撤销段 U1,或者 T1 可以写入 U1 而 T2 写入撤销段 U2。
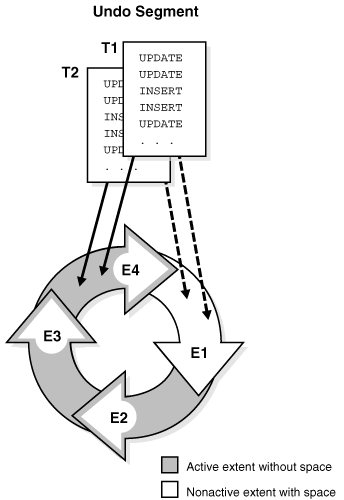
从概念上讲,撤销段中的区形成一个环。事务写入一个撤销区,然后写入环中的下一个区,以此类推,循环进行。图 15-21 显示了两个事务 T1 和 T2,它们开始在一个撤销段的第三个区 (E3) 中写入,并继续写入第四个区 (E4)。
Figure 15-21 Ring of Allocated Extents in an Undo Segment(图15-21 撤销段中已分配区的环)
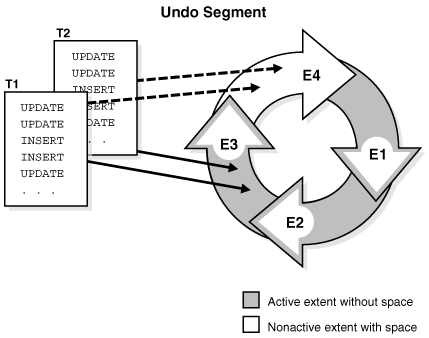
在任何给定时间,事务仅顺序写入撤销段中的一个区,这称为该事务的当前区(Current Extent)。多个活动事务可以同时写入同一个当前区或不同的当前区。图 15-21 显示了事务 T1 和 T2 同时写入区 E3。在一个撤销区内,一个数据块只包含一个事务的数据。
随着当前撤销区填满,第一个需要空间的事务会检查环中下一个已分配区的可用性。如果下一个区不包含活动事务的数据,则该区成为当前区。现在,所有需要空间的事务都可以写入这个新的当前区。在图 15-22 中,当 E4 满时,T1 和 T2 继续写入 E1,覆盖 E1 中的非活动撤销数据。
Figure 15-22 Cyclical Use of Allocated Extents in an Undo Segment(图15-22 撤销段中已分配区的循环使用)
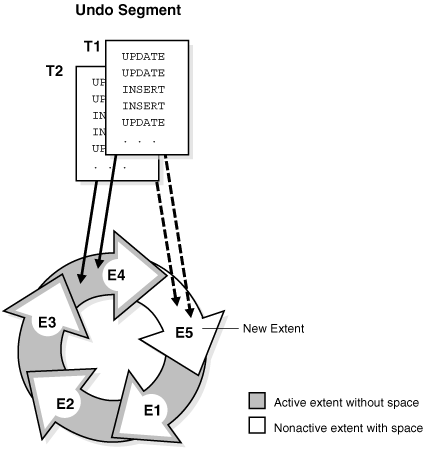
如果下一个区确实包含活动事务的数据,则数据库必须分配一个新的区。图 15-23 显示了一个场景,其中 T1 和 T2 正在写入 E4。当 E4 填满时,事务无法继续写入 E1,因为 E1 包含活动的撤销条目。因此,数据库为此撤销段分配一个新区 (E5)。事务继续写入 E5。
Figure 15-23 Allocation of a New Extent for an Undo Segment(图15-23 为撤销段分配新区)
相关参考:
《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何管理撤销段
Transaction Rollback(事务回滚)
当发出 ROLLBACK 语句时,数据库使用撤销记录来回滚未提交事务对数据库所做的更改。
在恢复期间,数据库会回滚任何从联机重做日志应用到数据文件的未提交更改。撤销记录通过为在同一时间访问数据的用户(而另一个用户正在更改数据)维护数据的"前像"(Before Image),来提供读一致性(Read Consistency)。
Temporary Undo Segments(临时撤销段)
临时撤销段(Temporary Undo Segment)是仅用于临时撤销数据的可选空间管理容器。
对临时表所做的更改的撤销记录既是会话特定的,也仅对读一致性和事务回滚有用。在 Oracle Database 12c 之前,数据库始终将这些记录存储在联机重做日志中。由于对临时对象的更改不会记录在联机重做日志中,将临时对象的撤销写入临时撤销段可以节省联机重做日志和归档重做日志文件中的空间。数据库不记录对撤销的更改或对临时表的更改,从而提高了性能。
您可以设置 TEMP_UNDO_ENABLED 初始化参数,使得临时表将撤销数据存储在临时撤销段中。当此参数为 TRUE 时,数据库会从临时表空间分配临时撤销段。
相关参考:
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解临时撤销段
- 《Oracle AI Database Reference》(《Oracle AI 数据库参考》),了解
TEMP_UNDO_ENABLED初始化参数
Segment Space and the High Water Mark(段空间与高水位标志)
为了管理空间,Oracle AI Database 跟踪段中块的状态。高水位标志(High Water Mark,HWM)是段中的一个点,超过该点的数据块是未格式化且从未使用过的。
MSSM 使用空闲列表来管理段空间。在表创建时,段中没有块被格式化。当会话首次向表中插入行时,数据库搜索空闲列表以查找可用块。如果数据库找不到可用块,它会预格式化一组块,将它们放入空闲列表,并开始向这些块中插入数据。在 MSSM 中,全表扫描读取 HWM 以下的所有块。
ASSM 不使用空闲列表,因此必须以不同方式管理空间。当会话首次向表中插入数据时,数据库格式化一个单独的位图块,而不是像 MSSM 那样预格式化一组块。位图块跟踪段中块的状态,取代了空闲列表。数据库使用位图查找空闲块,然后在用数据填充之前格式化每个块。ASSM 将插入分散到各个块中,以避免并发问题。
ASSM 段中的每个数据块都处于以下状态之一:
- 高于 HWM
这些块是未格式化且从未使用过的。 - 低于 HWM
这些块处于以下状态之一:- 已分配,但当前未格式化且未使用
- 已格式化并包含数据
- 已格式化但因数据被删除而为空
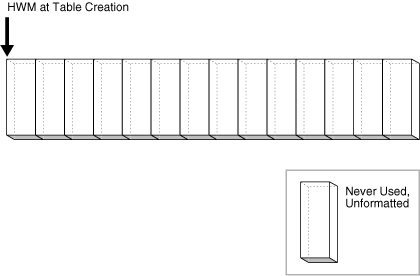
图 15-24 将 ASSM 段描述为一系列水平块。在表创建时,HWM 位于段的最左端。由于尚未插入任何数据,段中的所有块都是未格式化且从未使用过的。
Figure 15-24 HWM at Table Creation(图15-24 表创建时的 HWM)
假设一个事务向段中插入行。数据库必须分配一组块来保存这些行。已分配的块落在 HWM 之下。数据库格式化这组中的一个位图块以容纳元数据,但不预格式化组中的其余块。
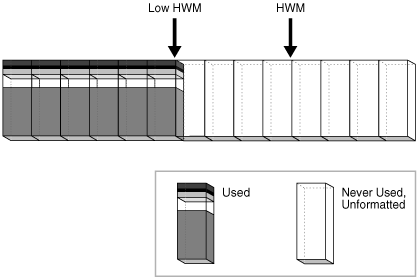
在图 15-25 中,HWM 以下的块已分配,而 HWM 以上的块既未分配也未格式化。随着插入的发生,数据库可以写入任何有可用空间的块。低高水位标志(Low High Water Mark,Low HWM)标志着一个点,低于该点的所有块已知都是已格式化的,因为它们要么包含数据,要么以前包含过数据。
Figure 15-25 HWM and Low HWM(图15-25 HWM 与 Low HWM)
在图 15-26 中,数据库在 HWM 和 Low HWM 之间选择一个块并写入它。数据库同样可以轻松选择 HWM 和 Low HWM 之间的任何其他块,或者 Low HWM 以下任何有可用空间的块。在图 15-26 中,新填充块两侧的块是未格式化的。
Figure 15-26 HWM and Low HWM(图15-26 HWM 与 Low HWM)
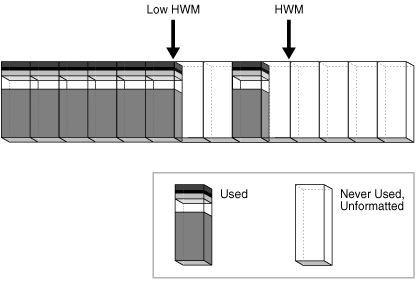
Low HWM 在全表扫描中很重要。由于 HWM 以下的块仅在使用时才被格式化,因此某些块可能尚未格式化,如图 15-26 所示。出于这个原因,数据库读取位图块以获取 Low HWM 的位置。数据库读取 Low HWM 以下的所有块,因为已知它们是已格式化的,然后仔细读取 Low HWM 和 HWM 之间仅已格式化的块。
假设一个新事务向表中插入行,但位图表明在 HWM 之下没有足够的空闲空间。在图 15-27 中,数据库将 HWM 向右推进,分配一组新的未格式化块。
Figure 15-27 Advancing HWM and Low HWM(图15-27 推进 HWM 和 Low HWM)
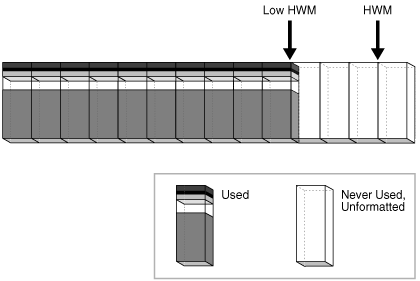
当 HWM 和 Low HWM 之间的块变满时,HWM 向右推进,Low HWM 推进到旧 HWM 的位置。随着数据库随时间推移插入数据,HWM 继续向右前进,而 Low HWM 始终尾随其后。除非您手动重建、截断或收缩对象,否则 HWM 永不后退。
相关参考:
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何联机收缩段
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
TRUNCATE TABLE的语法和语义
Overview of Tablespaces(表空间概述)
表空间(Tablespace)是段的逻辑存储容器。
段是消耗存储空间的数据库对象,如表和索引。在物理层面,表空间将数据存储在一个或多个数据文件或临时文件中。
- Tablespaces in a Multitenant Environment(多租户环境中的表空间)
在 CDB 中,每个 PDB 和应用程序根都有自己的表空间集。 - Permanent Tablespaces(永久表空间)
永久表空间(Permanent Tablespace)将持久的模式对象分组。表空间中对象的段物理存储在数据文件中。 - Temporary Tablespaces(临时表空间)
临时表空间(Temporary Tablespace)包含仅在会话期间持续的瞬态数据。临时表空间中不能驻留任何永久模式对象。临时文件存储临时表空间数据。 - Tablespace Modes(表空间模式)
表空间模式决定了表空间的可访问性。 - Tablespace File Size(表空间文件大小)
表空间要么是大文件表空间(Bigfile Tablespace),要么是小文件表空间(Smallfile Tablespace)。就执行未显式引用数据文件或临时文件的 SQL 语句而言,这些表空间没有区别。
Tablespaces in a Multitenant Environment(多租户环境中的表空间)
在 CDB 中,每个 PDB 和应用程序根都有自己的表空间集。
每个 CDB 根、PDB 和应用程序根都必须有 SYSTEM 和 SYSAUX 表空间。下图显示了一个典型容器中的表空间。
Figure 15-28 Tablespaces(图15-28 表空间)
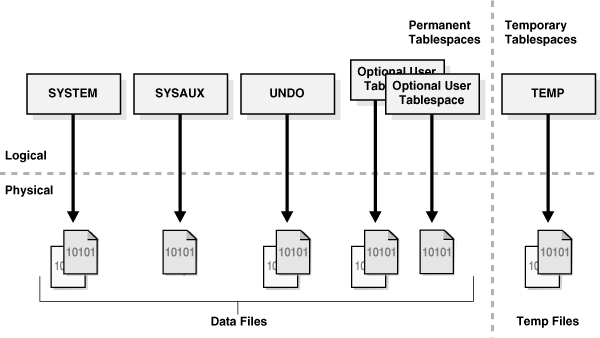
CDB 包含以下内容:
-
一个控制文件
-
一个联机重做日志
-
一个或多个撤销表空间
只有拥有适当权限且其当前容器为 CDB 根的公共用户才能创建撤销表空间。在任何给定时间,CDB 都处于以下任一撤销模式:
- 本地撤销模式(Local Undo Mode)
在这种情况下,每个 PDB 都有其自己的撤销表空间。如果 CDB 使用本地撤销模式,那么数据库会自动在每个 PDB 中创建一个撤销表空间。本地撤销模式提供了诸如能够执行 PDB 的热克隆和快速重定位 PDB 等优点。此外,本地撤销模式提供了一定程度的隔离,并支持更快速的拔插和指定时间点恢复操作。
在 Oracle Real Application Clusters (RAC) 集群中,PDB 在其中打开的每个节点都需要一个本地撤销表空间。例如,如果您将 PDB 从双节点集群移动到四节点集群,并且 PDB 在所有节点中打开,那么数据库会自动创建所需的额外撤销表空间。如果您再将 PDB 移回,则可以删除多余的撤销表空间。 注意:默认情况下,数据库配置助手(DBCA)创建的新 CDB 会启用本地撤销。 - 共享撤销模式(Shared Undo Mode)
在单实例 CDB 中,只存在一个活动的撤销表空间。对于 Oracle RAC CDB,每个实例存在一个活动的撤销表空间。在所有容器的数据字典和相关视图中,所有撤销表空间都是可见的。
撤销模式适用于整个 CDB,这意味着要么每个容器都使用共享撤销,要么每个容器都使用本地撤销。您可以在 CDB 中切换撤销模式,但这需要重新启动数据库。
- 本地撤销模式(Local Undo Mode)
-
每个容器都有
SYSTEM和SYSAUX表空间CDB 根、每个应用程序根以及每个 PDB 都有其自己的
SYSTEM和SYSAUX表空间。每个容器也有其自己的一组数据字典表,描述驻留在该容器中的对象。 -
零个或多个用户创建的表空间
在典型用例中,每个 PDB 都有其自己的一组非系统表空间。这些表空间包含 PDB 中用户自定义模式和对象的数据。您可以通过在
CREATE PLUGGABLE DATABASE或ALTER PLUGGABLE DATABASE语句中使用STORAGE子句来限制 PDB 的数据文件使用的存储量。数据字典存储在 PDB 内部,这使其具有可移植性。您可以从一个 CDB 拔下一个 PDB,并将其插入到另一个 CDB 中。
-
每个容器都有一组临时文件
CDB 根有一个默认临时表空间,每个应用程序根、应用程序 PDB 和 PDB 也各有一个默认临时表空间。
示例 15-3 CDB in Local Undo Mode(示例 15-3:处于本地撤销模式的 CDB)
此示例展示了一个具有两个 PDB(hrpdb 和 salespdb)的 CDB 的物理存储架构的各个方面。在此示例中,数据库使用本地撤销模式,因此在 CDB 根、hrpdb 和 salespdb 中都有撤销数据文件。
Figure 15-29 Physical Architecture of a CDB in Local Undo Mode(图15-29 本地撤销模式下 CDB 的物理架构)
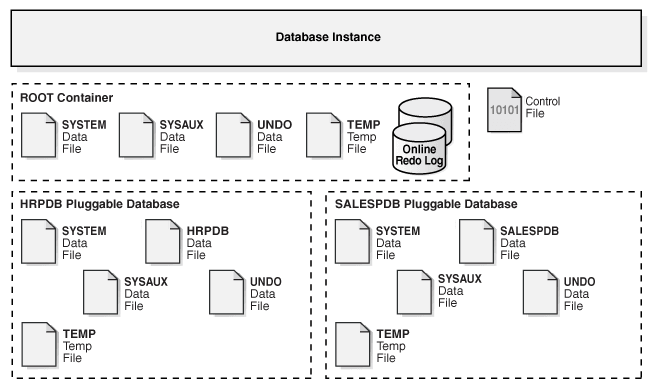
相关参考:
"Data Dictionary Separation in a CDB"(CDB 中的数据字典分离)
Permanent Tablespaces(永久表空间)
永久表空间(Permanent Tablespace)将持久的模式对象分组。表空间中对象的段物理存储在数据文件中。
每个数据库用户都被分配一个默认的永久表空间。一个非常小的数据库可能只需要默认的 SYSTEM 和 SYSAUX 表空间。但是,Oracle 建议您至少创建一个表空间用于存储用户和应用程序数据。您可以使用表空间来实现以下目标:
-
为数据库数据控制磁盘空间分配
-
为数据库用户分配配额(空间限额或限制)
-
使各个表空间联机或脱机,而不影响整个数据库的可用性
-
执行各个表空间的备份和恢复
-
使用 Oracle Data Pump 实用程序导入或导出应用程序数据
-
创建一个可传输表空间(Transportable Tablespace),您可以将其从一个数据库复制或移动到另一个数据库,甚至可以跨平台操作
通过传输表空间来移动数据,其速度可能比导出/导入或卸载/加载相同数据快几个数量级,因为传输表空间只涉及复制数据文件和集成表空间元数据。在传输表空间时,您也可以移动索引数据。
-
The SYSTEM Tablespace(SYSTEM 表空间)
SYSTEM表空间是数据库创建时随附的一个必要的管理表空间。Oracle AI Database 使用SYSTEM来管理数据库。 -
The SYSAUX Tablespace(SYSAUX 表空间)
SYSAUX表空间是SYSTEM表空间的辅助表空间。 -
Undo Tablespaces(撤销表空间)
撤销表空间(Undo Tablespace)是保留给系统管理的撤销数据的本地管理表空间。
-
Shadow Tablespaces(影子表空间)
影子表空间(Shadow Tablespace)是旨在用于影子丢失写保护(Shadow Lost Write Protection)的大文件表空间。
相关参考:
- 《Oracle AI Database Utilities》(《Oracle AI 数据库实用程序》)
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何传输表空间
- 《Oracle AI Database Utilities》(《Oracle AI 数据库实用程序》),了解 Oracle Data Pump
The SYSTEM Tablespace(SYSTEM 表空间)
SYSTEM 表空间是数据库创建时随附的一个必要的管理表空间。Oracle AI Database 使用 SYSTEM 来管理数据库。
SYSTEM 表空间包括以下信息,所有信息均归 SYS 用户所有:
- 数据字典
- 包含数据库管理信息的表和视图
- 已编译的存储对象,如触发器、过程和包
SYSTEM 表空间的管理方式与任何其他表空间类似,但需要更高级别的权限,并且在某些方面受到限制。例如,您不能重命名或删除 SYSTEM 表空间。
默认情况下,Oracle AI Database 将所有新创建的用户表空间设置为本地管理。在具有本地管理 SYSTEM 表空间的数据库中,您无法创建字典管理的表空间(已弃用)。但是,如果您手动执行 CREATE DATABASE 语句并接受默认值,那么 SYSTEM 表空间是字典管理的。您可以将现有的字典管理 SYSTEM 表空间迁移到本地管理的格式。
注意 :Oracle 强烈建议您使用数据库配置助手(DBCA)创建新数据库,以便默认情况下所有表空间(包括
SYSTEM)都是本地管理的。
相关参考:
- "Online and Offline Tablespaces"(联机和脱机表空间),了解有关
SYSTEM表空间永久联机状态的信息 - 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何创建或迁移到本地管理的
SYSTEM表空间 - 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
CREATE DATABASE的语法和语义
The SYSAUX Tablespace(SYSAUX 表空间)
SYSAUX 表空间是 SYSTEM 表空间的辅助表空间。
由于 SYSAUX 是许多 Oracle AI Database 特性和产品的默认表空间(这些特性和产品以前需要自己的表空间),因此它减少了数据库所需的表空间数量。它还减少了 SYSTEM 表空间上的负载。
数据库创建或升级时会自动创建 SYSAUX 表空间。在正常的数据库操作期间,数据库不允许删除或重命名 SYSAUX 表空间。如果 SYSAUX 表空间变得不可用,核心数据库功能仍然可以运行。使用 SYSAUX 表空间的数据库特性可能会失败,或者功能受限。
相关参考:
《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解 SYSAUX 表空间
Undo Tablespaces(撤销表空间)
撤销表空间(Undo Tablespace)是保留给系统管理的撤销数据的本地管理表空间。
与其他永久表空间一样,撤销表空间包含数据文件。这些文件中的撤销块分组在区中。
- Automatic Undo Management Mode(自动撤销管理模式)
撤销表空间要求数据库处于默认的自动撤销模式(Automatic Undo Mode)。 - Automatic Undo Retention(自动撤销保留)
撤销保留期(Undo Retention Period)是 Oracle AI Database 在覆盖旧撤销数据之前尝试保留它的最短时间。
相关参考:
"Undo Segments"(撤销段)
Automatic Undo Management Mode(自动撤销管理模式)
撤销表空间要求数据库处于默认的自动撤销模式(Automatic Undo Mode)。
自动模式消除了手动管理撤销段的复杂性。数据库会自动调整自身,以提供尽可能最佳的撤销数据保留,从而满足可能需要此数据的长时间运行查询。
Oracle AI Database 的全新安装会自动创建一个撤销表空间。较早版本的 Oracle AI Database 可能不包含撤销表空间,而是使用传统的回滚段,这被称为手动撤销管理模式(Manual Undo Management Mode)。Oracle AI Database 包含一个撤销顾问(Undo Advisor),它提供有关撤销环境的建议并帮助实现自动化。
一个数据库可以包含多个撤销表空间,但一次只能使用一个。当实例尝试打开数据库时,Oracle AI Database 会自动选择第一个可用的撤销表空间。如果没有可用的撤销表空间,则实例在没有撤销表空间的情况下启动,并将撤销数据存储在 SYSTEM 表空间中。不建议将撤销数据存储在 SYSTEM 中。
相关参考:
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解自动撤销管理
- 《Oracle AI Database Upgrade Guide》(《Oracle AI 数据库升级指南》),了解如何迁移到自动撤销管理模式
Automatic Undo Retention(自动撤销保留)
撤销保留期(Undo Retention Period)是 Oracle AI Database 在覆盖旧撤销数据之前尝试保留它的最短时间。
撤销保留很重要,因为长时间运行的查询可能需要较旧的块映像来提供读一致性(Read Consistency)。此外,某些 Oracle 闪回特性可能依赖于撤销数据的可用性。
通常,希望尽可能长时间地保留旧的撤销数据。事务提交后,不再需要撤销数据来进行回滚或事务恢复。如果撤销表空间有新事务的空间,数据库可以保留旧的撤销数据。当可用空间不足时,数据库开始覆盖已提交事务的旧撤销数据。
Oracle AI Database 自动为当前的撤销表空间提供尽可能最佳的撤销保留。数据库收集使用统计信息,并根据这些统计信息和撤销表空间的大小来调整保留期。如果撤销表空间配置了 AUTOEXTEND 选项,并且未指定最大大小,则撤销保留调优会有所不同。在这种情况下,数据库会将撤销保留期调整为略长于运行时间最长的查询的持续时间(如果空间允许)。
相关参考:
《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解有关自动调优撤销保留的更多详细信息
Shadow Tablespaces(影子表空间)
影子表空间(Shadow Tablespace)是旨在用于影子丢失写保护(Shadow Lost Write Protection)的大文件表空间。
注意 :影子丢失写保护与使用
DB_LOST_WRITE_PROTECT初始化参数和备用数据库配置的丢失写保护无关。
- Purpose of Shadow Tablespaces(影子表空间的目的)
影子丢失写保护提供对丢失写(Lost Write)的快速检测和即时响应。 - How Shadow Tablespaces Work(影子表空间如何工作)
丢失写保护需要两个表空间:一个影子表空间,以及一个块被影子表空间跟踪的非影子表空间。 - User Interface for Shadow Tablespaces(影子表空间的用户界面)
您可以使用ALTER PLUGGABLE DATABASE命令启用和禁用影子丢失写保护。 - Example: Configuring Lost Write Protection(示例:配置丢失写保护)
此示例为一组表空间启用影子丢失写跟踪。
Purpose of Shadow Tablespaces(影子表空间的目的)
影子丢失写保护提供对丢失写(Lost Write)的快速检测和即时响应。
当 I/O 子系统确认块写入完成,而实际上写入并未发生,或者当块的前一个映像覆盖了当前映像时,就会发生数据块丢失写。
未检测到的丢失写可能导致数据损坏,因为不正确的数据可能用于其他 DML 事务。例如,一个事务可能从一个表中读取旧的不正确数据,然后基于此数据更新数百个其他表。这样,数据损坏可能会传播到整个数据库。
影子丢失写保护提供以下好处:
- 它在标准 DML、SQL*Loader 常规路径加载、直接路径加载和 RMAN 备份消耗丢失写之前检测到它。
- 您可以为特定的表空间和数据文件启用影子丢失写保护。您不需要跟踪所有数据。
- 您可以更换一个影子表空间为另一个,以更改其配置或位置。
- 您可以暂停和恢复表空间或数据文件的影子丢失写保护。
- 您可以使用单个
ALTER DATABASE ... LOST WRITE PROTECTION语句为 PDB 启用或禁用它。PROP$表指示是否为 PDB 启用了跟踪。
相关参考:
《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解有关 LOST WRITE PROTECTION 子句的更多信息
How Shadow Tablespaces Work(影子表空间如何工作)
丢失写保护需要两个表空间:一个影子表空间,以及一个块被影子表空间跟踪的非影子表空间。
下图提供了一个示例场景。表空间 TBS1 和 TBS2 中的数据文件由一个影子表空间跟踪。只有表空间 TBS3 中的数据文件 DBF6 被影子表空间跟踪。
(此处原文包含一段示意图描述,但文本不完整,似乎是数据库更新触发器的示例代码,与影子表空间的工作机制描述不符,翻译时已基于上下文的逻辑一致性,仅翻译与影子表空间直接相关的描述部分。)
*Oracle Database
Update Trigger
BEGIN
. . . Insert Trigger
BEGIN
. . . Delete Trigger
BEGIN
. . .Data Dictionary
Table t
Database Application
Program code
.
.
UPDATE t SET ...;
.
.
INSERT INTO t ...;
.
.
DELETE FROM t ...;
*
一个被跟踪的数据文件映射到影子表空间中的一个影子区(Shadow Extent)。被跟踪数据文件中的每个数据块在影子块中都有一个对应的条目。此条目包含被跟踪数据块的 SCN。当从磁盘读取被跟踪的数据块时,影子丢失写保护会将影子表空间中该块的 SCN 与被跟踪数据块中最近一次写入的 SCN 进行比较。如果影子条目的 SCN 大于正在读取的数据块的 SCN,则发生了丢失写,从而提示错误。
影子区的大小会留有显著的额外空间,以防止数据文件的自动调整大小导致影子区增长过大。如果手动或自动调整了被跟踪数据文件的大小,并且影子区需要增长,那么数据库会尝试调整跟踪数据的大小。如果影子表空间中没有足够的空间,则数据库会向警报日志写入警告,并尽可能多地跟踪数据块。
相关参考:
《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何管理影子丢失写保护
User Interface for Shadow Tablespaces(影子表空间的用户界面)
您可以使用 ALTER PLUGGABLE DATABASE 命令启用和禁用影子丢失写保护。
要使影子丢失写保护能够保护特定的表空间或数据文件,必须满足以下条件:
-
您必须已通过使用
ALTER PLUGGABLE DATABASE ENABLE LOST WRITE PROTECTION语句为整个 PDB 启用了影子丢失写保护。注意:在 CDB 中,如果您在根中启用了影子丢失写保护,那么 PDB 不会继承它。您必须为要保护的每个 PDB 启用影子丢失写保护。
-
您必须已通过使用
ENABLE LOST WRITE PROTECTION子句为要保护的表空间或数据文件启用了影子丢失写保护。当您为表空间启用影子丢失写保护时,该表空间的所有数据文件都将受到保护,并且添加到该表空间的任何数据文件也会受到保护。请注意,您不能为临时表空间或另一个丢失写表空间启用丢失写保护。
-
您必须已通过使用带有
LOST WRITE PROTECTION子句的CREATE BIGFILE TABLESPACE语句创建了一个或多个影子表空间。Oracle AI Database 自动将被跟踪的数据文件分配到特定的影子表空间。您无法指定哪个影子表空间用于特定的数据文件。
以下数据字典视图监控影子表空间:
DBA_TABLESPACES
通过查询显示哪些表空间是影子表空间。DBA_DATA_FILES.LOST_WRITE_PROTECT
显示是否为数据文件启用了丢失写保护USER_TABLESPACES.LOST_WRITE_PROTECT
显示是否为特定表空间打开了丢失写保护。DBA_DATA_FILES不表示是否为表空间打开了丢失写保护:您必须改为查看USER_TABLESPACES。
相关参考:
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何使用影子表空间管理丢失写保护
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
CREATE TABLESPACE语句 - 《Oracle AI Database Reference》(《Oracle AI 数据库参考》),了解
DBA_TABLESPACES
Example: Configuring Lost Write Protection(示例:配置丢失写保护)
此示例为一组表空间启用影子丢失写跟踪。
在此示例中,您的目标是保护 PDB 内的 salestbs 和 hrtbs 表空间。您还要保护 oetbs 表空间中的 oetbs01.dbf 数据文件,并且仅保护此数据文件。您执行以下操作:
-
以管理员身份登录到 PDB。
-
创建一个单独的影子表空间,如下所示:
sqlCREATE BIGFILE TABLESPACE shadow_lwp1 DATAFILE 'shadow_lwp1_df' SIZE 10M LOST WRITE PROTECTION; -
为该 PDB 启用丢失写保护,如下所示:
sqlALTER DATABASE ENABLE LOST WRITE PROTECTION; -
为
salestbs和hrtbs表空间启用影子丢失写保护,如下所示:sqlALTER TABLESPACE salestbs ENABLE LOST WRITE PROTECTION; ALTER TABLESPACE hrtbs ENABLE LOST WRITE PROTECTION; -
为
oetbs01.dbf数据文件启用影子丢失写保护,如下所示:sqlALTER DATABASE DATAFILE 'oetbs01.dbf' ENABLE LOST WRITE PROTECTION;
相关参考:
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何管理影子表空间
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
CREATE TABLESPACE语句
Temporary Tablespaces(临时表空间)
临时表空间(Temporary Tablespace)包含仅在会话期间持续的瞬态数据。临时表空间中不能驻留任何永久模式对象。临时文件存储临时表空间数据。
临时表空间可以提高不适合放在内存中的多个排序操作的并发性。这些表空间还可以提高排序期间空间管理操作的效率。
- Shared and Local Temporary Tablespaces(共享和本地临时表空间)
临时表空间可以是共享的或本地的。 - Default Temporary Tablespaces(默认临时表空间)
每个数据库用户账户都被分配一个默认的共享临时表空间。如果数据库包含本地临时表空间,那么每个用户账户也会被分配默认的本地临时存储。
Shared and Local Temporary Tablespaces(共享和本地临时表空间)
临时表空间可以是共享的或本地的。
共享临时表空间(Shared Temporary Tablespace)将临时文件存储在共享磁盘上,以便所有数据库实例都可以访问该临时空间。相反,本地临时表空间(Local Temporary Tablespace)为每个数据库实例存储单独的、非共享的临时文件。本地临时表空间对于 Oracle Real Application Clusters 或 Oracle Flex Clusters 非常有用。
您可以为只读和读写数据库实例创建本地临时表空间。当许多只读实例访问单个数据库时,本地临时表空间可以提高涉及排序、哈希聚合和连接的查询的性能。其优点是:
- 通过使用本地磁盘存储而不是共享磁盘存储来提高 I/O 性能
- 避免昂贵的跨实例临时空间管理
- 通过消除磁盘上的空间元数据管理来提高实例启动性能
下表比较了共享和本地临时表空间的特性。
表 15-2 共享和本地临时表空间
| 共享临时表空间(Shared Temporary Tablespace) | 本地临时表空间(Local Temporary Tablespace) |
|---|---|
使用 CREATE TEMPORARY TABLESPACE 语句创建。 |
使用 CREATE LOCAL TEMPORARY TABLESPACE 语句创建。 注意 :本地临时表空间始终是大文件表空间,但创建语句中不需要 BIGFILE 关键字。 |
| 为数据库创建单个临时表空间。 | 为每个数据库实例创建单独的临时表空间。FOR LEAF 选项仅为只读实例创建表空间。FOR ALL 选项为所有实例(包括只读和读写实例)创建表空间。 |
| 支持表空间组。 | 不支持表空间组。 |
| 将临时文件元数据存储在控制文件中。 | 将所有实例通用的临时文件元数据存储在控制文件中,而实例特定的元数据(例如,分配的位图、当前临时文件大小和文件状态)存储在 SGA 中。 |
相关参考:
"Introduction to the Oracle AI Database Instance"(Oracle AI 数据库实例简介)
Default Temporary Tablespaces(默认临时表空间)
每个数据库用户账户都被分配一个默认的共享临时表空间。如果数据库包含本地临时表空间,那么每个用户账户也会被分配默认的本地临时存储。
您可以使用 CREATE USER 或 ALTER USER 语句为用户账户指定不同的临时表空间。对于未指定不同临时表空间的用户,Oracle AI Database 使用系统级别的默认临时表空间。
- Creation of Default Temporary Tablespaces(默认临时表空间的创建)
创建数据库时,默认临时存储取决于SYSTEM表空间是否为本地管理。 - Access to Temporary Storage(对临时存储的访问)
如果为用户分配了临时表空间,则数据库首先访问它;否则,数据库访问默认临时表空间。数据库在为查询访问某个临时表空间后,不会切换到另一个。
相关参考:
《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解有关 CREATE USER 语句的更多信息
Creation of Default Temporary Tablespaces(默认临时表空间的创建)
创建数据库时,默认临时存储取决于 SYSTEM 表空间是否为本地管理。
下表显示了 Oracle AI Database 在创建数据库时如何选择默认临时表空间。
表 15-3 默认临时表空间的创建
SYSTEM 表空间是否为本地管理? |
CREATE DATABASE 语句是否指定了默认临时表空间? |
那么数据库... |
|---|---|---|
| 是 | 是 | 将指定的表空间用作默认值。 |
| 是 | 否 | 创建一个临时表空间。 |
| 否 | 是 | 将指定的表空间用作默认值。 |
| 否 | 否 | 使用 SYSTEM 作为默认临时存储。数据库在警报日志中写入一条警告,提示建议使用默认临时表空间。 |
创建数据库后,您可以使用 ALTER DATABASE DEFAULT TEMPORARY TABLESPACE 语句更改数据库的默认临时表空间。
注意:您不能将默认临时表空间变为永久的。
相关参考:
- "Permanent and Temporary Data Files"(永久和临时数据文件)
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何创建默认临时表空间
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
CREATE DATABASE和ALTER DATABASE的DEFAULT TEMPORARY TABLESPACE子句的语法
Access to Temporary Storage(对临时存储的访问)
如果为用户分配了临时表空间,则数据库首先访问它;否则,数据库访问默认临时表空间。数据库在为查询访问某个临时表空间后,不会切换到另一个。
用户查询可以访问共享或本地临时存储。此外,一个用户可以有一个为其只读实例分配的默认本地临时表空间,以及一个为读写实例分配的不同的默认本地临时表空间。
对于读写实例,数据库给予共享临时表空间更高的优先级。对于只读实例,数据库给予本地临时表空间更高的优先级。如果数据库实例是读写的,则数据库按以下顺序搜索空间:
- 是否已为用户分配共享临时表空间?
- 是否已为用户分配本地临时表空间?
- 数据库默认临时表空间是否有空间?
如果对上述任一问题的回答为是,则数据库停止搜索并从指定的表空间分配空间;否则,从数据库默认本地临时表空间分配空间。
如果数据库实例是只读的,则数据库按以下顺序搜索空间:
- 是否已为用户分配本地临时表空间?
- 分配的数据库默认本地临时表空间是否有空间?
- 是否已为用户分配共享临时表空间?
如果对上述任一问题的回答为是,则数据库停止搜索并从指定的表空间分配空间;否则,从数据库默认共享临时表空间分配空间。
Tablespace Modes(表空间模式)
表空间模式决定了表空间的可访问性。
- Read/Write and Read-Only Tablespaces(读/写和只读表空间)
每个表空间都处于一种写模式,指定是否可以对其进行写操作。 - Online and Offline Tablespaces(联机和脱机表空间)
只要数据库处于打开状态,表空间就可以联机(可访问)或脱机(不可访问)。
Read/Write and Read-Only Tablespaces(读/写和只读表空间)
每个表空间都处于一种写模式,指定是否可以对其进行写操作。
互斥的模式如下:
- 读/写模式(Read/Write Mode)
用户可以读取和写入表空间。所有表空间最初都创建为读/写。SYSTEM和SYSAUX表空间以及临时表空间是永久的读/写,这意味着它们不能被设为只读。 - 只读模式(Read-Only Mode)
阻止对表空间中的数据文件进行写操作。只读表空间可以驻留在只读介质上,例如 DVD 或 WORM 驱动器。
只读表空间消除了对数据库中大型静态部分执行备份和恢复的需要。只读表空间不会更改,因此不需要重复备份。如果在介质故障后恢复数据库,则无需恢复只读表空间。
相关参考:
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何将表空间更改为只读或读/写模式
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
ALTER TABLESPACE的语法和语义 - 《Oracle AI Database Backup and Recovery User's Guide》(《Oracle AI 数据库备份和恢复用户指南》),了解有关恢复的更多信息
Online and Offline Tablespaces(联机和脱机表空间)
只要数据库处于打开状态,表空间就可以联机(可访问)或脱机(不可访问)。
表空间通常处于联机状态,以便其数据可供用户使用。SYSTEM 表空间和临时表空间不能脱机。
表空间可以自动或手动脱机。例如,您可以使表空间脱机以进行维护或备份和恢复。当遇到某些错误时,例如当数据库写入器(DBW)进程多次尝试写入数据文件失败时,数据库会自动使表空间脱机。尝试访问脱机表空间中的表的用户会收到错误。
当表空间脱机时,数据库会执行以下操作:
- 数据库不允许后续的 DML 语句引用脱机表空间中的对象。脱机表空间不能由除 Oracle AI Database 以外的任何实用程序读取或编辑。
- 具有已完成的引用该表空间中数据的语句的活动事务,在事务级别不会受到影响。
- 数据库将与那些已完成的语句相对应的撤销数据保存在
SYSTEM表空间中的一个延迟撤销段(Deferred Undo Segment)中。当表空间重新联机时,数据库会在需要时将撤销数据应用到该表空间。
相关参考:
- "Online and Offline Data Files"(联机和脱机数据文件)
- "Database Writer Process (DBW)"(数据库写入器进程(DBW))
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何更改表空间可用性
Tablespace File Size(表空间文件大小)
表空间要么是大文件表空间(Bigfile Tablespace),要么是小文件表空间(Smallfile Tablespace)。就执行未显式引用数据文件或临时文件的 SQL 语句而言,这些表空间没有区别。
区别如下:
- 小文件表空间可以包含多个数据文件或临时文件,但这些文件不能像大文件表空间那样大。这是默认的表空间类型。
- 大文件表空间包含一个非常大的数据文件或临时文件。这种类型的表空间可以执行以下操作:
- 增加数据库的存储容量
数据库中数据文件的最大数量是有限的,因此增加每个数据文件的大小会增加总存储量。 - 减轻管理许多数据文件和临时文件的负担
大文件表空间通过消除添加新文件和处理多个文件的需要,简化了 Oracle Managed Files 和自动存储管理(Oracle ASM)的文件管理。 - 对表空间而不是单个文件执行操作
大文件表空间使表空间成为磁盘空间管理、备份和恢复等的主要单元。
- 增加数据库的存储容量
大文件表空间仅支持具有 ASSM 的本地管理表空间。但是,本地管理的撤销和临时表空间可以是大文件表空间,即使段是手动管理的也是如此。
从 Oracle AI Database 26ai 开始,默认将 SYSTEM、SYSAUX 和 USER 表空间创建为大文件表空间。从先前版本升级的数据库保留其表空间类型。
相关参考:
- 《Oracle AI Database Backup and Recovery User's Guide》(《Oracle AI 数据库备份和恢复用户指南》),了解有关备份和恢复的更多信息
- 《Oracle AI Database Administrator's Guide》(《Oracle AI 数据库管理员指南》),了解如何管理大文件表空间