
开篇聊几句
我接触过不少做物联网、智慧工厂、新能源监控的团队,大家最常问的一个问题是:"数据库选哪款好?"
这个问题表面上简单,背后其实藏着一连串隐性成本。我见过有团队前期图省事直接套用 MySQL,扛了半年还行,第二年开始天天救火;也见过技术栈追新选了某款热门时序库,结果发现社区跟不上、生态没人对接,迁移代价比重做还大。
数据库选型的本质不是"哪个跑得快",而是"哪个能陪我们走得远"。 这篇文章不打算堆 benchmark 数据,而是想从工程实践的角度,聊聊时序场景下到底该怎么挑数据库,以及 Apache IoTDB 凭什么在这两年成了越来越多企业的默认选项。
一、先认清时序数据的"基因"
时序数据本质上是一种被时间串起来的数据流。它不像订单、用户那种业务实体,而更像是一条永不停歇的传送带,每秒都有新货物(数据点)从设备端送上来。
它有几个非常鲜明的特征:
写多读少,且写入永远进行时。 一个中型工厂几千台设备,每秒钟都在产生新数据,写入压力是 7×24 小时持续输出,不存在"业务低谷"。
几乎不更新。 历史数据就是历史,写下来就基本不动了,最多删个过期的。
时间维度是查询主轴。 查"昨天 14:00 到 15:00 这台设备的温度曲线",比查"这台设备所有数据"重要一万倍。
数据冷热极度不均衡。 最近一小时的数据可能被查上千次,三年前的数据可能一个月才被翻一次。
这些特征决定了------用通用数据库去硬扛时序负载,就像让长跑运动员去举重,不是不行,是怎么练都别扭。时序数据库的存在本身,就是为了给这种"不对称负载"提供一个对称的解法。
二、那些 benchmark 测不出来的坑
很多团队踩坑,不是因为没做技术调研,而是调研的方向偏了。性能压测谁都会做,但有些问题压测根本暴露不出来,得等数据真正堆起来之后才显形。我整理了几个最容易被忽视的:
坑一:长跑稳定性
压测往往跑几十分钟、几小时就出报告。但生产环境是连续跑几年。后台 compaction 会不会越来越慢?内存会不会缓慢泄漏?磁盘碎片化后写入抖动会不会越来越明显?这些只有真实跑过几个月才能看出来。
坑二:压缩比差几倍,硬件账单差一个数量级
同样存一年数据,压缩比 3:1 和压缩比 15:1,对应的存储成本可能差 5 倍以上。在数据量动辄 TB、PB 起步的场景下,这是真金白银的差距。
坑三:建模和业务对不上
工厂的设备天然是有层级的------园区 → 厂区 → 车间 → 产线 → 设备 → 测点。如果数据库只支持扁平的"表 + tag"模型,你就得在应用层手工拼装这种层级,运维和扩展都很痛苦。
坑四:单机和集群是两套东西
有些方案单机版玩得很顺,但要上集群得换一套部署、换一套 API、甚至换一套引擎。试点阶段是单机,上生产要扩容时发现"白玩了",这种事并不少见。
坑五:周边生态空白
数据库不是孤岛。数据进来之后要喂给 BI 看板、流处理引擎、机器学习平台、告警系统。如果这些生态对接全靠自研,那后续每加一个能力都得开新坑。
我的建议是:把这五个维度做成一张表,每个候选方案打分,比看 benchmark 有用得多。
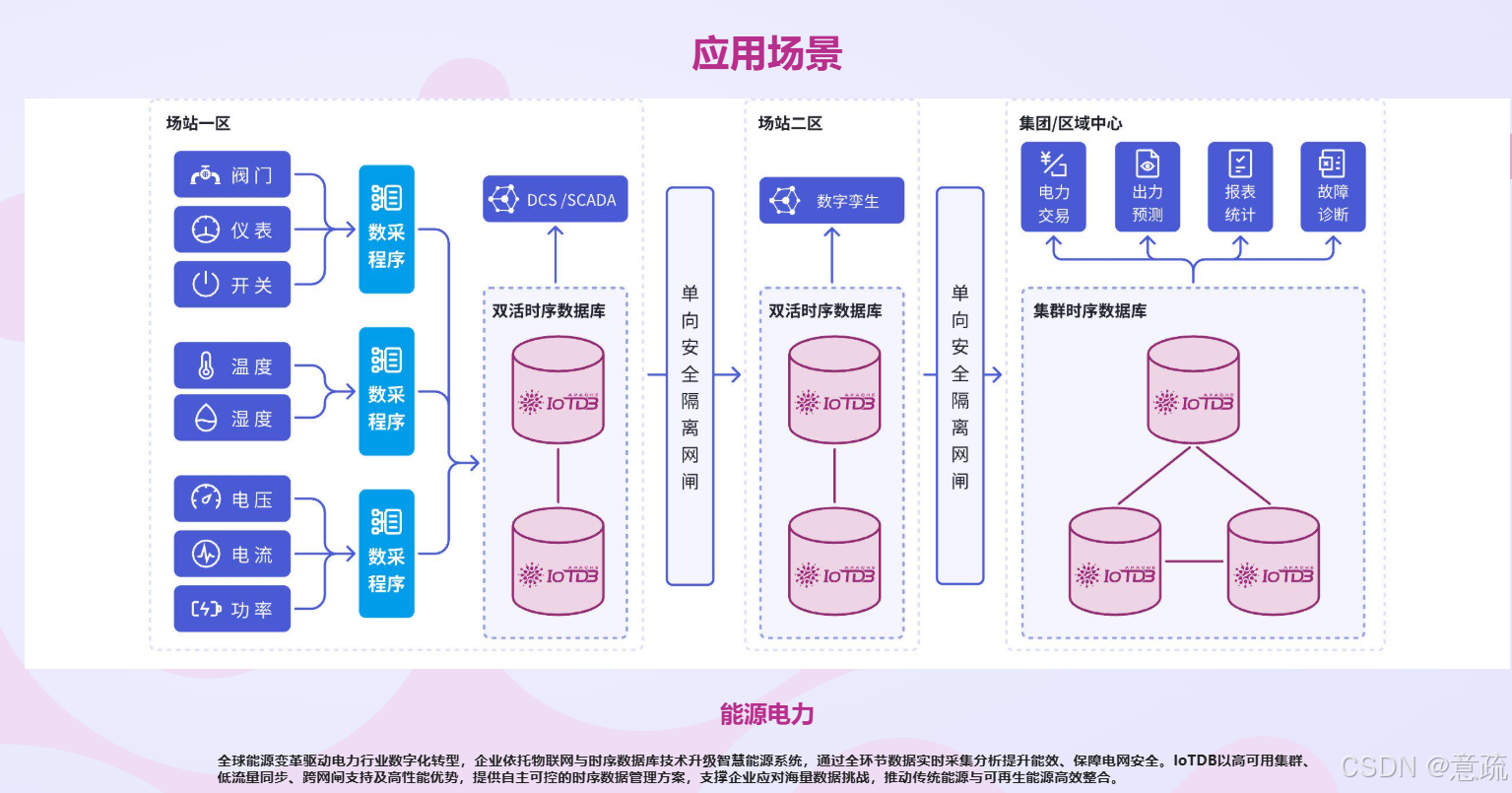
三、用这五个维度审视 Apache IoTDB
回到 Apache IoTDB,把上面的"坑"逐个对照,可以看到它的设计意图非常清楚:
评估维度 IoTDB 的应对
长跑稳定性 专为持续高频写入设计,单节点支撑百万级测点持续接入
存储成本 针对时序特征定制的编码 + 压缩策略,压缩比通常达到 10 倍以上
数据建模 原生树形结构(root.园区.车间.设备.测点),与工业层级一一对应
集群演进 单机与分布式架构统一,从 PoC 直接平滑过渡到生产集群
生态对接 官方支持 Spark、Flink、Kafka、Grafana、Hadoop、MQTT 等主流组件
其中我最欣赏的是树形数据模型。这不是花架子,它解决的是工业场景里最现实的问题------设备天然有层级,数据天然要按层级管理。下面用几段 SQL 看看这种设计有多顺手。

四、五段 SQL,看 IoTDB 的"原生时序感"
这几段示例对应 IoTDB 官方文档的常用语法,按照"从写入到查询"的顺序排开。
写入:路径即建模
sql
INSERT INTO root.ln.wf02.wt02(timestamp, status) VALUES(1, true);
INSERT INTO root.ln.wf02.wt02(timestamp, hardware) VALUES(1, 'v1');注意 root.ln.wf02.wt02 这种写法------这不是字符串拼接,是 IoTDB 真正的存储路径。路径本身就是建模,不需要先 CREATE TABLE,也不需要在应用层维护"工厂-车间-设备"的映射关系。
一次写入多个测点
真实设备一次采集往往同时上报多个指标(温度、压力、转速......),IoTDB 让你一条 SQL 搞定:
sql
INSERT INTO root.ln.wf02.wt02(timestamp, status, hardware) VALUES (2, false, 'v2');批量写入:贴合真实流量
数据上来基本是成批的,不是一条一条的:
多个指标一起查:
sql
SELECT status, temperature
FROM root.ln.wf01.wt01
WHERE time > 2017-11-01T00:05:00.000
AND time < 2017-11-01T00:12:00.000;时间是一等公民,不需要为它单独建索引、写函数。
降采样和最新值:时序场景的"高频动作"
时序数据库和"普通数据库+时间字段"的差距,在这里体现得最明显:
-- 按天聚合,做趋势图
sql
SELECT count(status), max_value(temperature)
FROM root.ln.wf01.wt01
GROUP BY ([2017-11-01T00:00:00, 2017-11-07T23:00:00), 1d);
-- 查最新状态,用于实时大屏
SELECT LAST status
FROM root.ln.wf01.wt01;时间窗口聚合是写日报、周报、告警曲线时几乎天天用到的能力;LAST 查询则是面向"这台设备现在怎么样"这种实时问题的专门优化。
这些 SQL 想表达的不是"IoTDB 支持 SQL",而是它的 SQL 语义是为时序量身定制的。 在通用数据库里要实现同样的效果,往往要写一长串子查询 + 窗口函数 + 临时表,还跑不快。
五、这套方案适合什么样的项目
结合实际落地的案例来看,IoTDB 在以下几类场景里跑得比较稳:
能源与电力:变电站、风电场、光伏电站的遥测数据,对长周期保留和高可靠要求极高。
智能制造:产线状态监测、设备综合效率(OEE)分析、质量追溯,特别吃树形建模的红利。
车联网与轨道交通:车辆 CAN 总线数据回传、列车故障回溯、驾驶行为分析。
通用 IoT 平台:作为底层存储承接百万级设备接入,向上输出给 BI、AI、告警等多条业务线。
这几类场景有个共同特征:数据量大、保留周期长、查询模式多样、对存储成本敏感。这恰好是 IoTDB 最擅长的舞台。
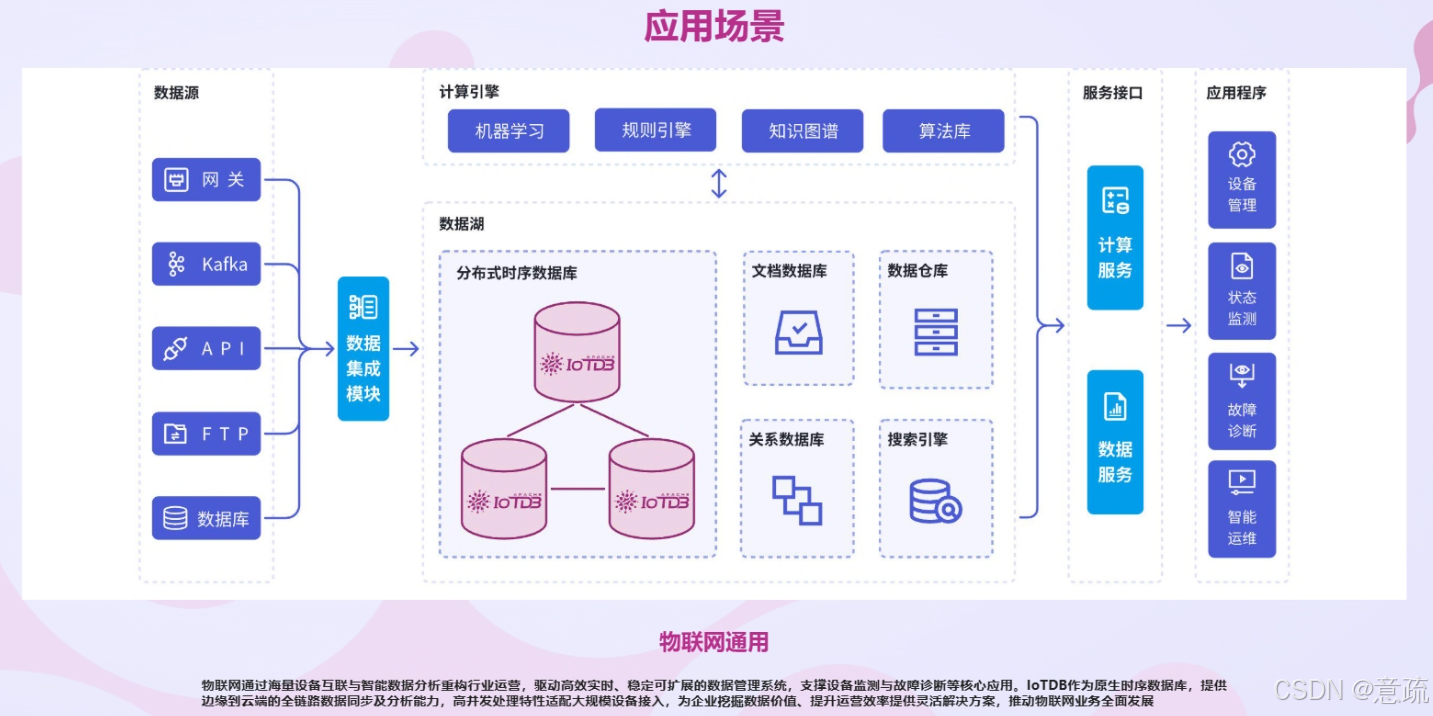
六、从试点到生产,落地节奏怎么排
我观察过不少团队的引入路径,比较稳的节奏一般是这样:
第一阶段:PoC 试点
用开源版搭单机环境,把数据从某条产线接进来跑一段时间,验证写入、查询、压缩比是否满足预期。
第二阶段:扩展到生产
试点没问题后,平滑切换到集群部署,把更多产线、更多车间的数据接进来。因为 IoTDB 单机和集群架构是统一的,这一步不需要换引擎、不需要重新建模。
第三阶段:考虑企业级支持
当业务规模做大、对 SLA 要求变高之后,可以引入官方的企业级方案(Timecho 提供)来获得行业 know-how 和技术兜底。
这种"开源验证 → 平滑扩容 → 企业兜底"的递进路径,对企业来说风险可控、节奏自由。
写在最后
数据库选型这件事,看似是技术决策,本质是战略决策。选对了,几年之内不会有大动作;选错了,迟早要付出迁移代价------而数据库迁移在所有技术债里属于最贵的那种。
时序场景尤其特殊,它对写入持续性、压缩效率、查询灵活性、生态完整度都有比通用场景高得多的要求。Apache IoTDB 之所以值得在选型清单上认真评估,不是因为它在某项 benchmark 上领先,而是因为它从骨子里就是为时序数据设计的------从数据模型到 SQL 语义,从单机架构到集群演进,从开源生态到企业支持,每一层都对得上时序场景的真实需求。
如果你的项目正在工业互联网、能源、制造、车联网或者泛 IoT 这几个方向上推进,那么花点时间认真评估一下 IoTDB,几乎可以肯定不会浪费。
参考资料:
Apache IoTDB 开源版:https://iotdb.apache.org/zh/Download/
IoTDB 企业版(Timecho):https://timecho.com