目录
写在前面
learn-claude-code 项目目前有两条教程线,一条是之前的 s12 章节的,另一条是最近更新的 s20 章节的,大家如果刚学习这个项目的话推荐直接看最新的 s20 章节的教程即可,由于博主之前学习过 s12 章节的内容,因此打算把 s20 章节中新增章节的内容给补充学习,内容重复的章节博主这边就跳过了。
下面是旧版到新版的对应关系:
| Legacy 12-lesson track | Current 20-lesson track | Topic |
|---|---|---|
| old s01 | new s01 | Agent Loop |
| old s02 | new s02 | Tool Use |
| old s03 | new s05 | TodoWrite |
| old s04 | new s06 | Subagent |
| old s05 | new s07 | Skill Loading |
| old s06 | new s08 | Context Compact |
| old s07 | new s12 | Task System |
| old s08 | new s13 | Background Tasks |
| old s09 | new s15 | Agent Teams |
| old s10 | new s16 | Team Protocols |
| old s11 | new s17 | Autonomous Agents |
| old s12 | new s18 | Worktree Isolation |
| new only | s03, s04, s09, s10, s11, s14, s19, s20 | Permission, Hooks, Memory, System Prompt, Error Recovery, Cron, MCP, Comprehensive Agent |
从上表中我们可以看出我们需要补充的内容包括 s03、s04、s09、s10、s11、s14、s19 以及 s20 八个章节的内容。
新版学习路径如下:
主线:能动手 → 能做复杂任务 → 能记住和恢复 → 能长期运行 → 能协作 → 能扩展并合体
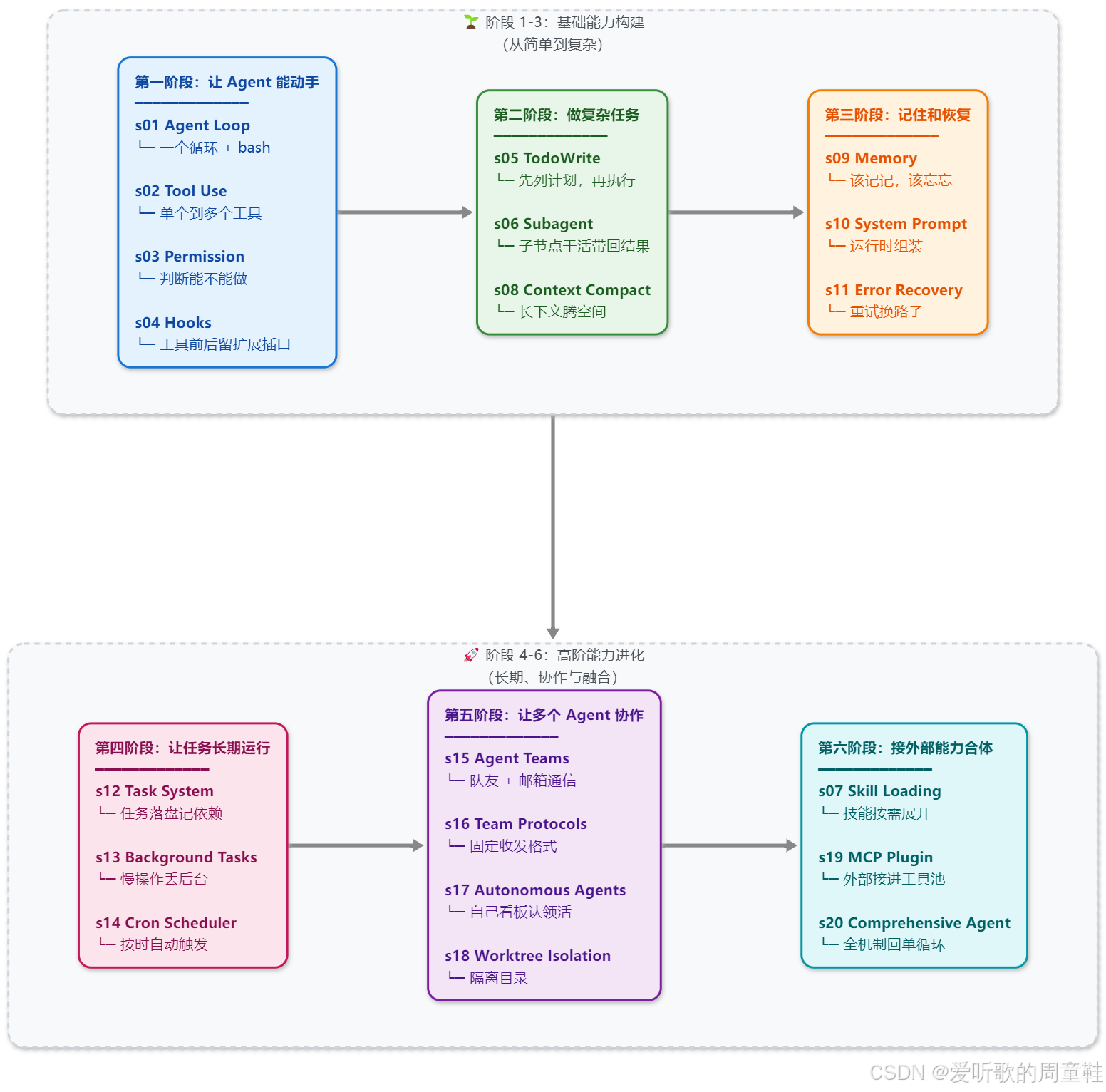
前言
在上篇文章 Learn-Claude-Code | 笔记 | Tools & Execution | s01 The Agent Loop | s02 Tools 中,我们介绍了开源项目 learn-claude-code 前两个章节 s01: The Agent Loop 和 s02: Tool Use 的内容,这篇文章我们继续跟着教程文档来学习工具与执行相关内容,记录下个人学习笔记,和大家一起分享交流😄
Note:本篇文章主要学习记录 新版教程 第一部分 Tools & Execution 中 s03: Permission 章节的内容。
github :https://github.com/shareAI-lab/learn-claude-code
reference :https://chatgpt.com/
1. s03: Permission
如果说 s01 让我们看到了一个 Agent 最基础的循环结构,s02 让模型从单一 bash 扩展到了 read_file、write_file、edit_file、glob 等多个工具,那么到了 s03,系统开始面对一个非常现实的问题:工具越多,Agent 能触达真实世界的能力越强,风险也越高。
在 s02 中,文件类工具已经有 safe_path() 做路径沙箱,但 bash 本身仍然是一个很大的安全面。模型只要调用了 shell,就有可能提出一些破坏性命令。教程文档里也说得很直接:安全不能靠 "相信模型不会乱来",而要靠代码在工具执行前先拦一层。
所以 s03 的核心变化可以概括成一句话:
模型仍然负责提出工具调用,但运行时必须先判断这个工具调用能不能执行。
也就是说,从这一节开始,Agent Loop 不再是 "模型说执行什么,程序就立刻执行什么",而是在模型和工具 handler 之间插入了一个新的中间层:Permission Pipeline。
2. 问题
在 s02 里,工具系统已经比 s01 更强了。模型不再只能通过 bash 做所有事情,而是可以直接调用专门的文件工具,比如 read_file、write_file、edit_file。这些工具有一个明显好处:它们可以在 handler 内部做约束,比如通过 safe_path() 防止路径逃出当前工作区。
但是,s02 仍然存在一个明显问题:bash 工具过于自由。
文件工具可以限制路径,但 shell 命令本身很难天然安全。模型如果想 "清理一下项目",它可能会调用删除类命令;如果模型理解错了用户意图,或者 prompt 里出现了危险指令,就可能触发一些不该执行的操作。
这里的关键不是 "模型会不会故意作恶",而是:只要运行时把执行权完全交给模型,风险就已经存在。
因此 s03 要解决的问题不是 "让模型更听话",而是:
在每一个工具真正执行之前,先由程序侧判断它属于 allow、ask 还是 deny。
这也是 Permission 这一节的核心定位:它不是新增一个业务工具,而是在工具执行前增加一层安全路由。
3. 解决方案
s03 的解决方案非常克制:s02 的 agent loop 基本不动,只在工具 handler 执行之前插入 check_permission() 。
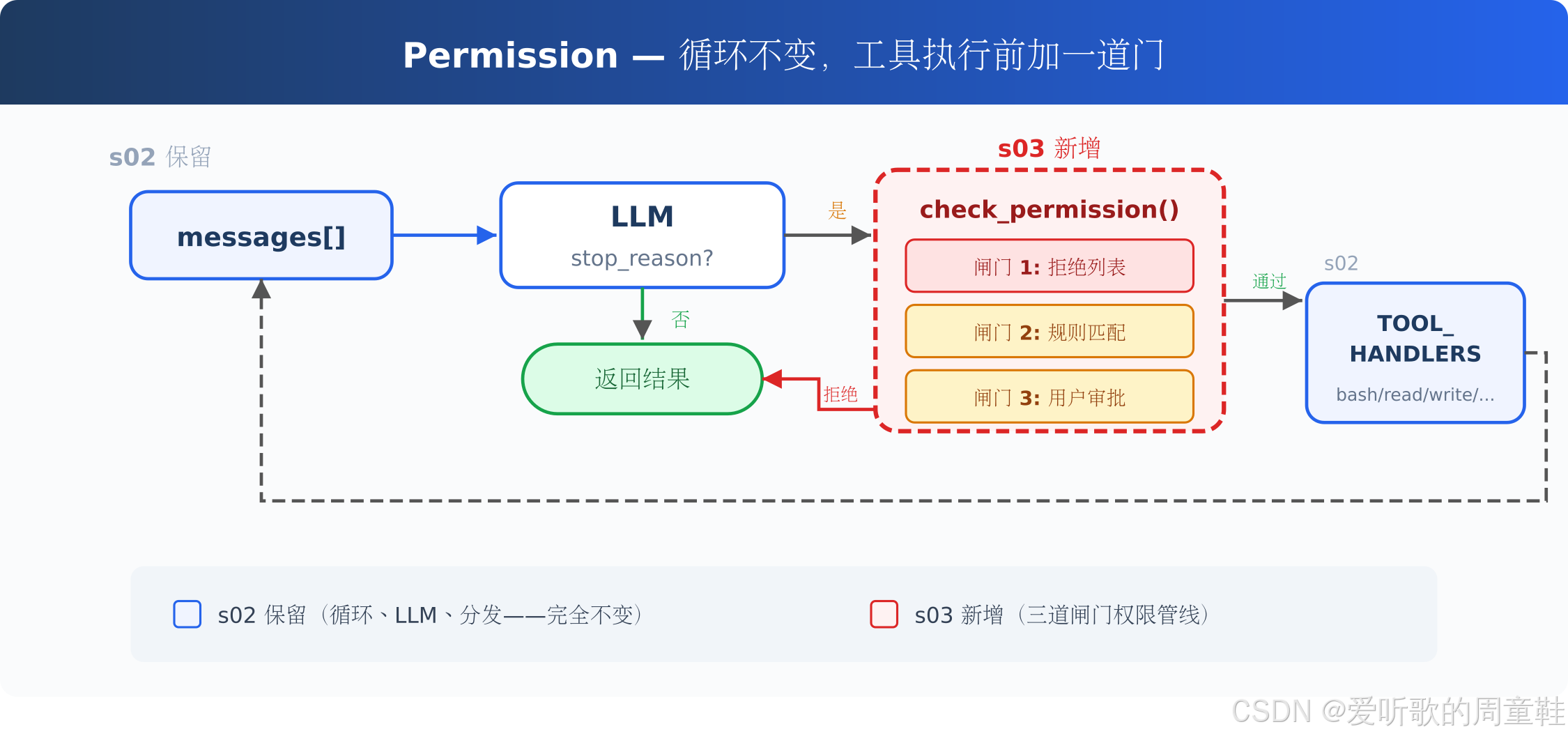
上图把 s03 和 s02 的关系讲清楚了:s03 并没有重写 Agent Loop,而是在 s02 原有循环中,给工具执行前插入了一层 check_permission()。
左侧的 messages[] -> LLM -> stop_reason? 仍然是 s02 已经建立起来的主线。如果模型没有产生工具调用,就直接返回结果;如果模型产生了 tool_use,原来 s02 会直接进入 TOOL_HANDLERS 执行,而 s03 在这里多加了一道权限检查。
图中红色虚线框里的 check_permission() 就是 s03 的新增部分。它内部包含三道闸门:拒绝列表、规则匹配、用户审批 。只有当这三道闸门最终给出允许结果时,请求才会继续流向右侧的 TOOL_HANDLERS。如果被拒绝,则不会执行 handler,而是返回一个拒绝结果给 Agent Loop。
所以这里想表达的核心不是 "权限系统很复杂",而是:权限系统的位置非常关键,它卡在 LLM 提出工具调用之后、工具 handler 真正执行之前。 也就是说,模型仍然可以提出工具调用,但真正是否执行,开始由 harness 层决定。
也就是说,s03 不是重写循环,不是重写工具系统,而是在原来的工具分发前面加一道门。教程文档把这个设计总结为三道闸门:先硬拒绝,再规则匹配,最后需要时让用户审批;三道都没命中,才直接执行。
整体流程可以理解为:
shell
Tool call
|
v
Gate 1: hard deny
|
v
Gate 2: permission rules
|
v
Gate 3: user approval
|
v
Tool handler这三道闸门分别对应三种结果:
第一类是 allow 。比如读取工作区内的 README.md,它是只读操作,不会写文件,也不会执行 shell,因此可以直接放行。
第二类是 ask。比如删除某个本地临时目录,这种操作不一定绝对禁止,但它可能造成不可逆影响,所以不能自动执行,而是应该暂停下来问用户。
第三类是 deny。比如包含 root 删除、sudo、关机、格式化磁盘等高危模式的命令,这类操作不应该进入 handler,更不应该让用户随手确认后执行,而是直接拒绝。
这套机制最重要的地方在于:权限判断发生在工具执行之前。
也就是说,模型仍然可以 "提出" 一个工具调用,但能不能真正跑起来,由运行时决定。这就把 "模型建议" 和 "系统执行" 分开了:模型负责生成意图,Permission Pipeline 负责判断这条意图是否允许落地。
4. Permission Desk 流程图分析
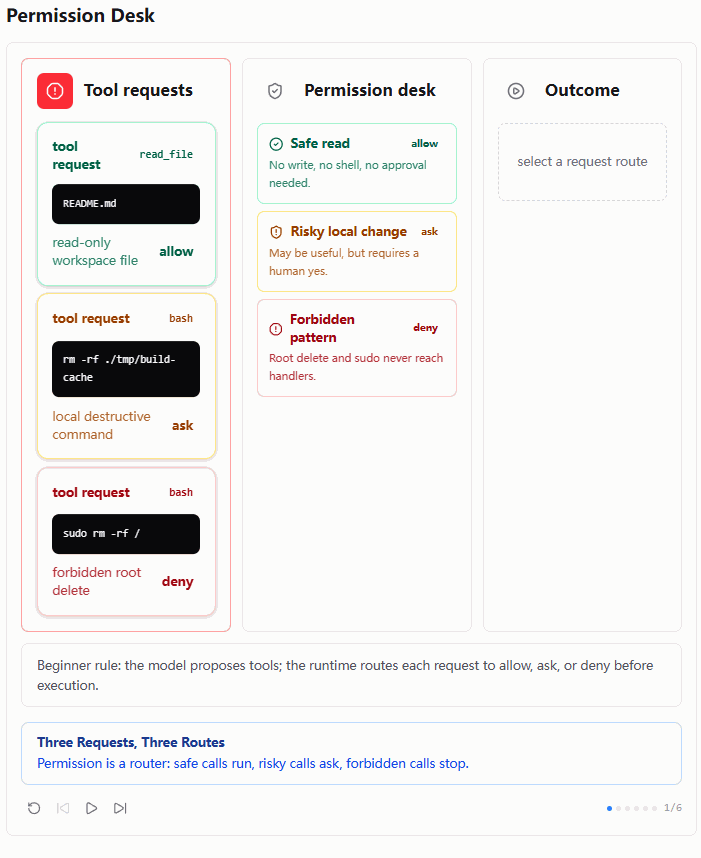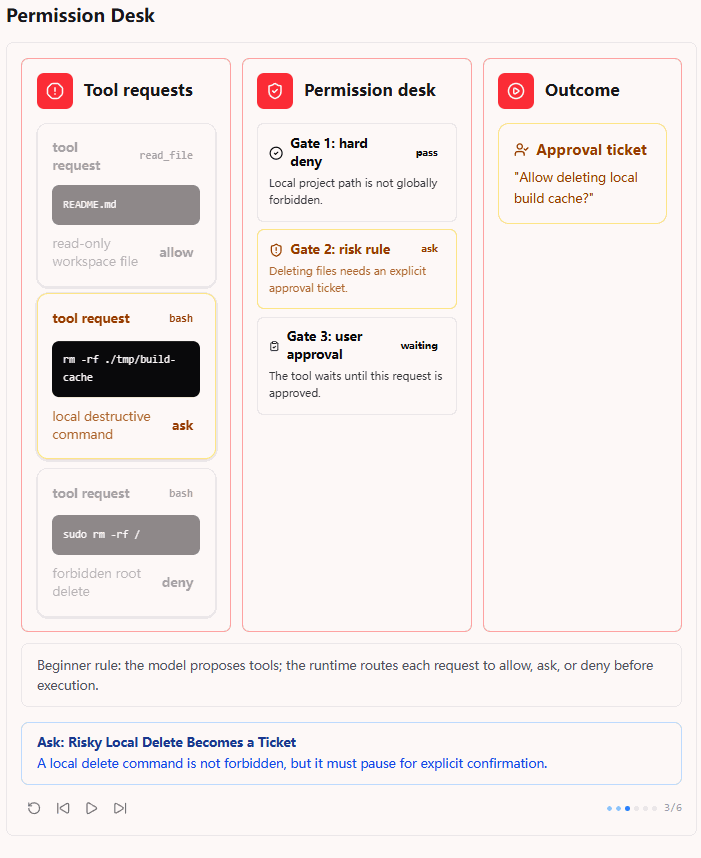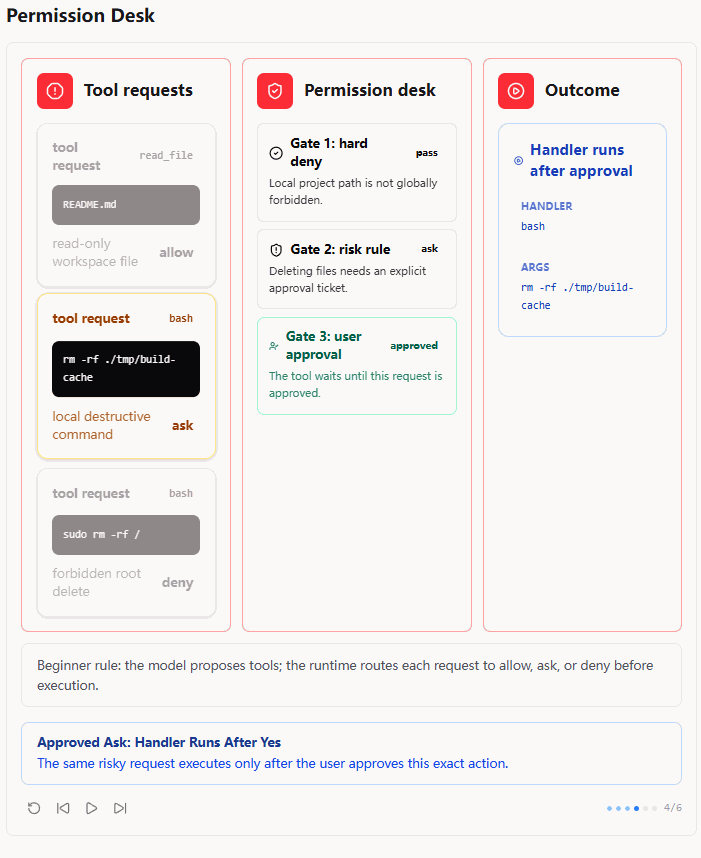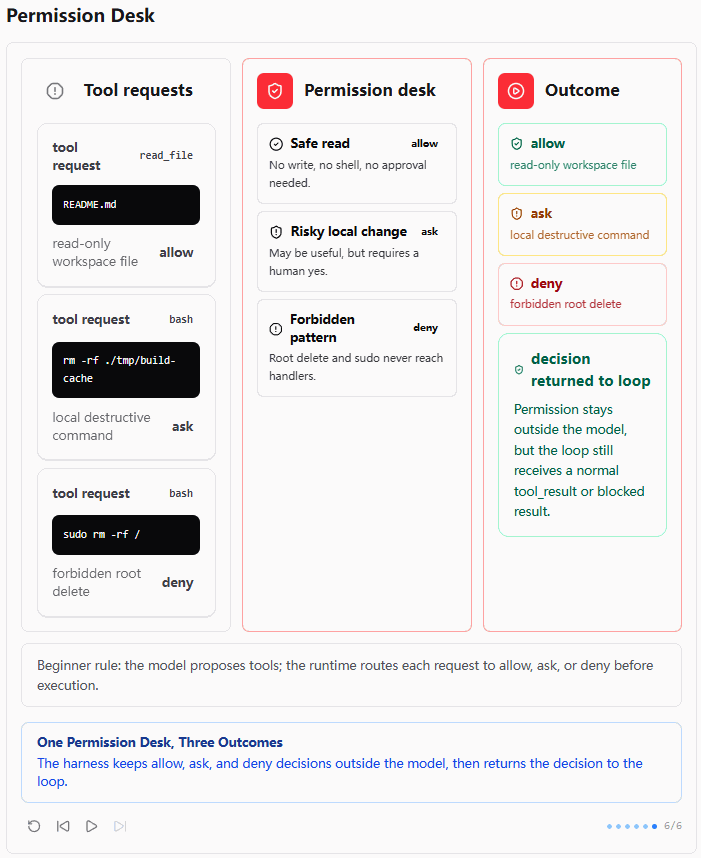
这一节教程配了 6 张 Permission Desk 图,它们非常适合用来理解 s03 的整体心智模型。图中左边是模型提出的 tool requests,中间是 permission desk,右边是最终 outcome。
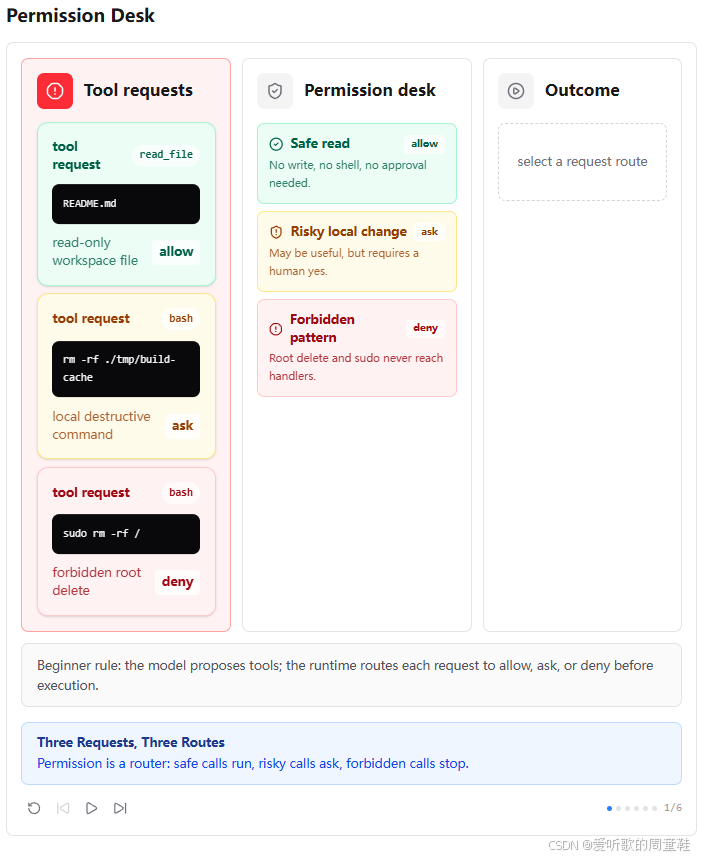
第一张图先展示了三类典型请求:
read_file README.mdbash rm -rf ./tmp/build-cachebash sudo rm -rf /
它们分别对应三条路线:
shell
safe read -> allow
risky local change -> ask
forbidden pattern -> deny这张图最重要的地方在于,它把权限系统的定位讲清楚了:Permission 不是工具本身,而是工具请求的路由器。
模型仍然可以生成各种工具调用,但每个调用都要先被送到 Permission Desk 里分类。分类结果不是 "模型自己决定",而是运行时根据规则判断。
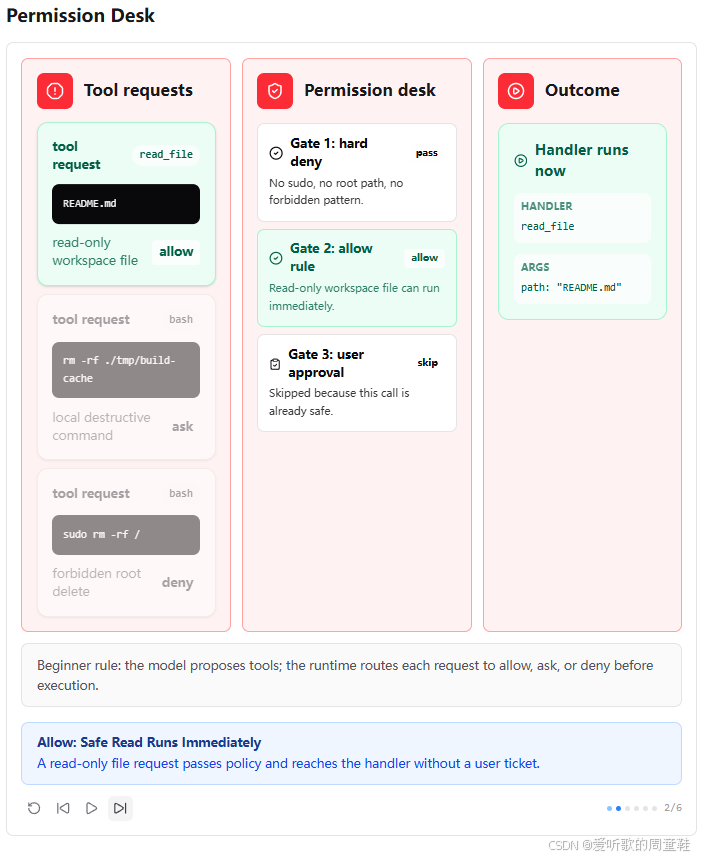
第二张图展示的是安全读取场景。read_file README.md 首先经过 Gate 1,发现没有硬拒绝模式;再经过 Gate 2,命中安全读规则;由于这个请求已经被判定为安全,所以 Gate 3 用户审批会被跳过,handler 可以立刻运行。
这对应代码里的逻辑就是:如果没有命中 deny,也没有命中 ask 规则,check_permission() 返回 True,然后原来的 handler 正常执行。也就是说,Permission Pipeline 不是为了让所有操作都变慢,而是为了让安全操作自动通过。
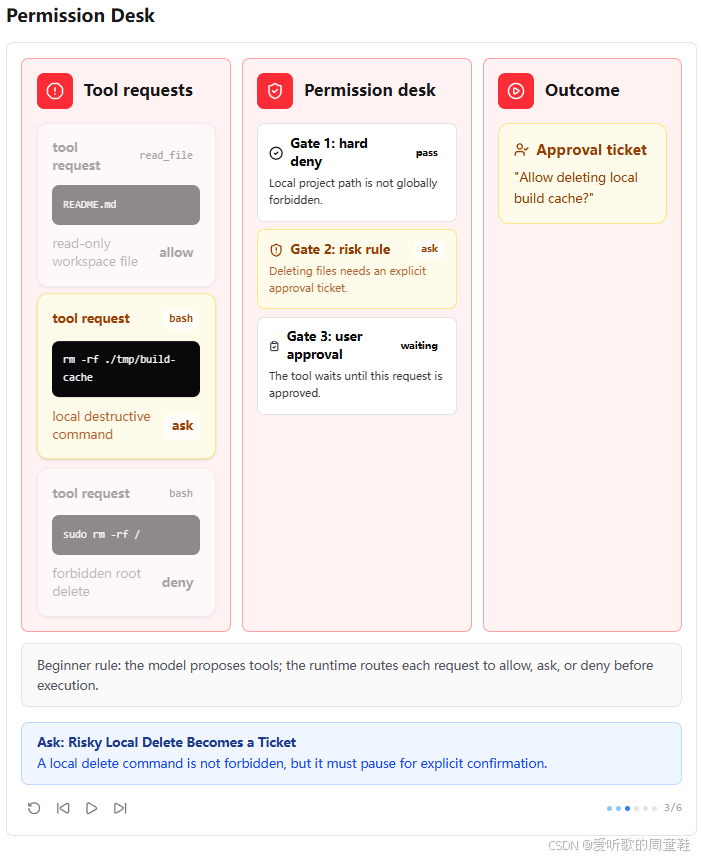
第三张图展示的是风险操作。比如 rm -rf ./tmp/build-cache 这种本地删除操作,它不是 root 删除,也不是 sudo,因此 Gate 1 不会直接拒绝;但它包含删除行为,会在 Gate 2 被判定为潜在破坏性命令,于是进入 Gate 3,生成一个 approval ticket。
这一步非常关键,因为它说明 s03 并不是把所有风险操作都简单粗暴地 deny 掉,而是引入了一个中间状态:ask。
也就是说,Permission Pipeline 不是二分类,而是三分类:
- allow:直接执行
- ask:暂停等用户确认
- deny:直接拒绝
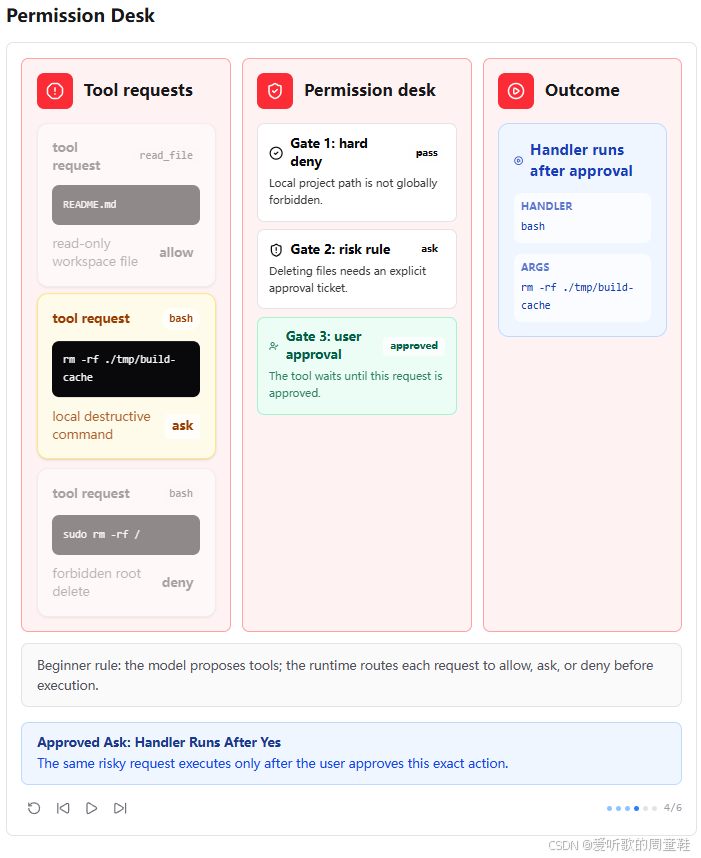
第四张图展示的是用户审批通过之后的结果。前面被标记为 ask 的命令,只有在用户明确批准之后,handler 才会真正运行。
这一点很重要:approval ticket 批准的是这一次具体工具调用,而不是永久放开所有类似命令。
也就是说,用户批准的不是 "以后所有删除操作都允许",而是 "这个具体的 rm -rf ./tmp/build-cache 可以执行"。这让系统既能处理必要的风险操作,又不会把风险扩大成长期权限。
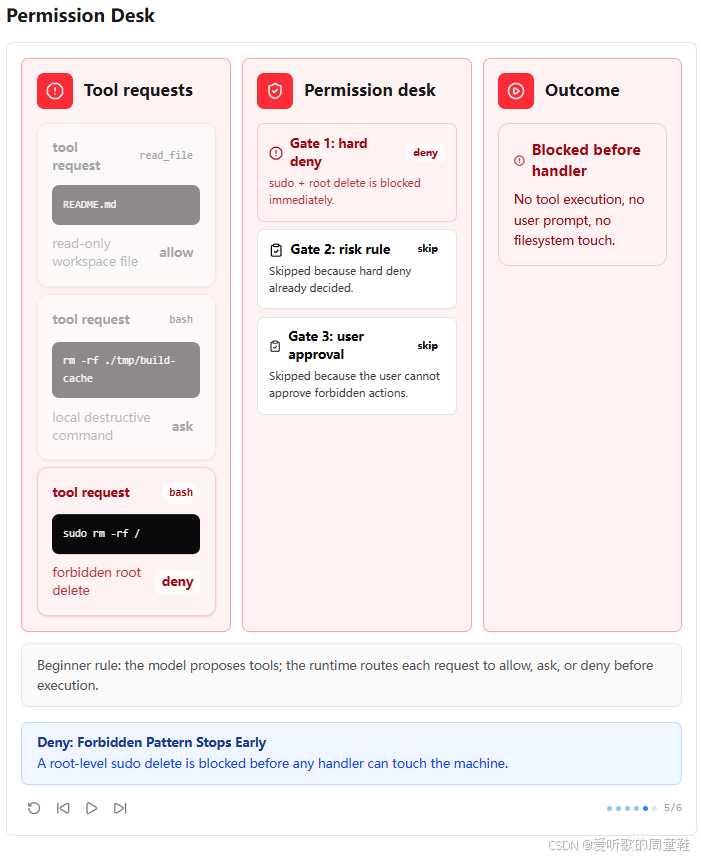
第五张图展示的是硬拒绝场景。sudo rm -rf / 这种命令会在 Gate 1 就被 hard deny 拦住。后面的 Gate 2、Gate 3 都会跳过,handler 根本不会被调用。
这张图最值得强调的是:deny 优先级最高。
也就是说,某些操作不应该进入 "问用户" 阶段,因为它们本身就属于绝对禁止的模式。Permission Pipeline 的第一道闸门就是为了挡住这类请求。
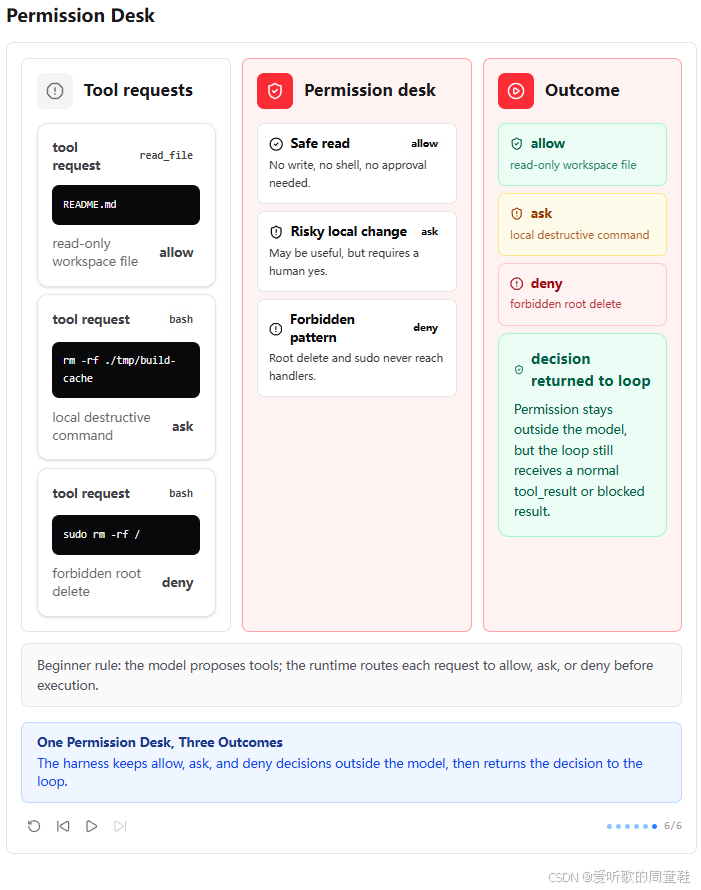
最后一张图做了总收束:三种请求进入同一个 Permission Desk,最后产生三种结果:
shell
allow -> handler runs now
ask -> wait for approval
deny -> blocked before handler这里还有一句很关键的话:decision returned to loop。
也就是说,Permission Pipeline 并不是脱离 Agent Loop 的独立系统。它最终仍然要把结果以 tool_result 或 blocked result 的形式返回给模型,让模型继续下一轮推理。
所以 s03 的机制不是把模型排除在外,而是让模型看到:这个工具请求被允许了、被拒绝了,或者需要用户审批。这样,Agent Loop 仍然保持闭环,只是工具执行前多了一层运行时安全判断。
完整动画演示如下图所示:
5. 工作原理(代码分析)
在正式分析代码之前,我们先来看看教程文档中提供的 permission pipeline 整体流程图:

这张图对应的就是代码里的 check_permission() 主流程。它把一次工具调用进入权限系统之后的路径拆成三步:先经过硬拒绝列表,再经过规则匹配,如果规则命中,则进入用户审批。
第一道闸门是硬拒绝。它对应代码中的 DENY_LIST 和 check_deny_list(),专门处理 rm -rf /、sudo、shutdown 这类永远不应该继续往下走的命令。只要这一层命中,就直接得到 deny,不会再进入用户审批。
第二道闸门是规则匹配。它对应 PERMISSION_RULES 和 check_rules(),处理的是上下文相关的风险操作,比如写工作区外、执行删除命令、修改系统路径等。它和第一道闸门不同:命中规则并不意味着立刻拒绝,而是说明这次调用需要用户确认。
第三道闸门是用户审批。它对应 ask_user()。当第二道闸门判断某次工具调用有风险时,程序会暂停,把工具名、参数和原因展示给用户,让用户决定是否允许。用户允许才继续执行 handler;用户拒绝则返回 Permission denied.。
所以这张图和代码是一一对应的:
python
check_deny_list() -> check_rules() -> ask_user()最终会产生三种结果:
- allow:直接执行工具
- ask:暂停等待用户确认
- deny:不执行工具,返回拒绝结果
这也解释了为什么 s03 的核心变化只需要插入一个 check_permission(block):三道闸门都被封装在这个函数里,Agent Loop 不需要理解每条规则的细节,只需要根据返回值决定要不要调用 handler。
看完 Permission Desk 的整体心智模型和 permission pipeline 之后,接下来我们正式进入 s03_permission_code.py。文件开头已经把这一节的核心机制写得非常清楚:
python
"""
s03_permission.py - Permission System
Three gates inserted before tool execution:
Gate 1: Hard deny list (rm -rf /, sudo, ...)
Gate 2: Rule matching (write outside workspace? destructive cmd?)
Gate 3: User approval (pause and wait for confirmation)
Only one line added to the agent loop:
if not check_permission(block):
continue
"""这段注释里最重要的不是 "Three gates",而是最后那句:Only one line added to the agent loop。也就是说,s03 的设计目标不是让 loop 变复杂,而是在保持 s02 工具分发结构基本不变的前提下,把权限检查插到工具执行之前。代码文件也明确标出了这一点:s03 是在 s02 多工具 Agent 的基础上增加权限管线。
首先,s03 保留了 s02 的工具实现。比如 safe_path()、run_bash()、run_read()、run_write()、run_edit()、run_glob() 这些函数依然存在:
python
def safe_path(p: str) -> Path:
path = (WORKDIR / p).resolve()
if not path.is_relative_to(WORKDIR):
raise ValueError(f"Path escapes workspace: {p}")
return path这里说明文件工具自身仍然有路径沙箱。也就是说,s03 并没有废掉 s02 的工具级保护,而是在它外面又加了一层执行前权限判断。这样就形成了两层安全结构:
- permission pipeline:决定能不能执行这个工具调用
- tool handler:执行时继续做自己的局部校验
这点很重要,因为权限系统不是替代 handler 内部安全检查,而是提前做一层全局路由。
接着看 s02 保留下来的工具定义和 dispatch map:
python
TOOLS = [
{"name": "bash", "description": "Run a shell command.", ...},
{"name": "read_file", "description": "Read file contents.", ...},
{"name": "write_file", "description": "Write content to a file.", ...},
{"name": "edit_file", "description": "Replace exact text in a file once.", ...},
{"name": "glob", "description": "Find files matching a glob pattern.", ...},
]
TOOL_HANDLERS = {
"bash": run_bash,
"read_file": run_read,
"write_file": run_write,
"edit_file": run_edit,
"glob": run_glob,
}这一部分和 s02 的思想完全一致:TOOLS 给模型看,告诉模型有哪些工具可以调用;TOOL_HANDLERS 给运行时用,告诉程序每个工具名对应哪个 Python 函数。s03 并没有改变这个分层,而是在 TOOL_HANDLERS 真正执行之前多走一次权限检查。
真正新增的内容,从下面这段开始:
python
# NEW in s03: Three-Gate Permission Pipeline第一道闸门是硬拒绝列表:
python
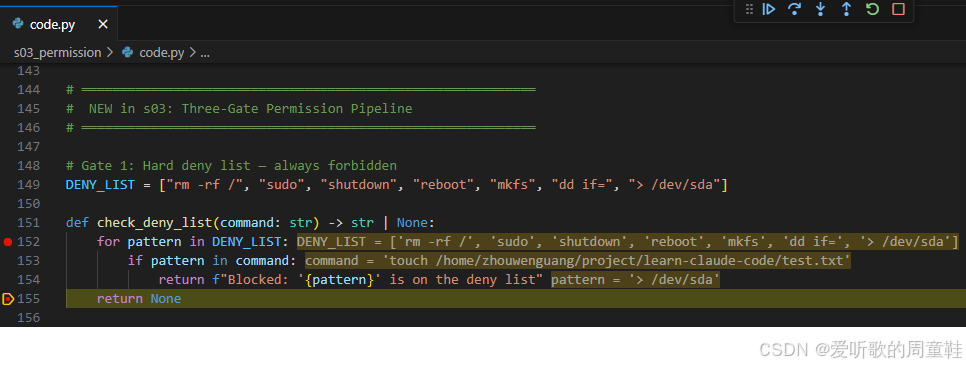
DENY_LIST = ["rm -rf /", "sudo", "shutdown", "reboot", "mkfs", "dd if=", "> /dev/sda"]
def check_deny_list(command: str) -> str | None:
for pattern in DENY_LIST:
if pattern in command:
return f"Blocked: '{pattern}' is on the deny list"
return None这一层的特点是:只针对永远不应该执行的高危模式。
如果命中,就直接返回阻止原因,后面不再进入规则匹配,也不会问用户。代码里也只在 block.name == "bash" 时检查 deny list,因为这些高危模式主要来自 shell 命令。
不过这里要注意,教程也明确提醒过:教学版使用简单字符串匹配只是为了讲清楚机制,不是生产级安全方案。真实系统里,shell 展开、命令别名、路径变体都可能绕过简单匹配,所以生产版需要更复杂的权限管线。
第二道闸门是规则匹配:
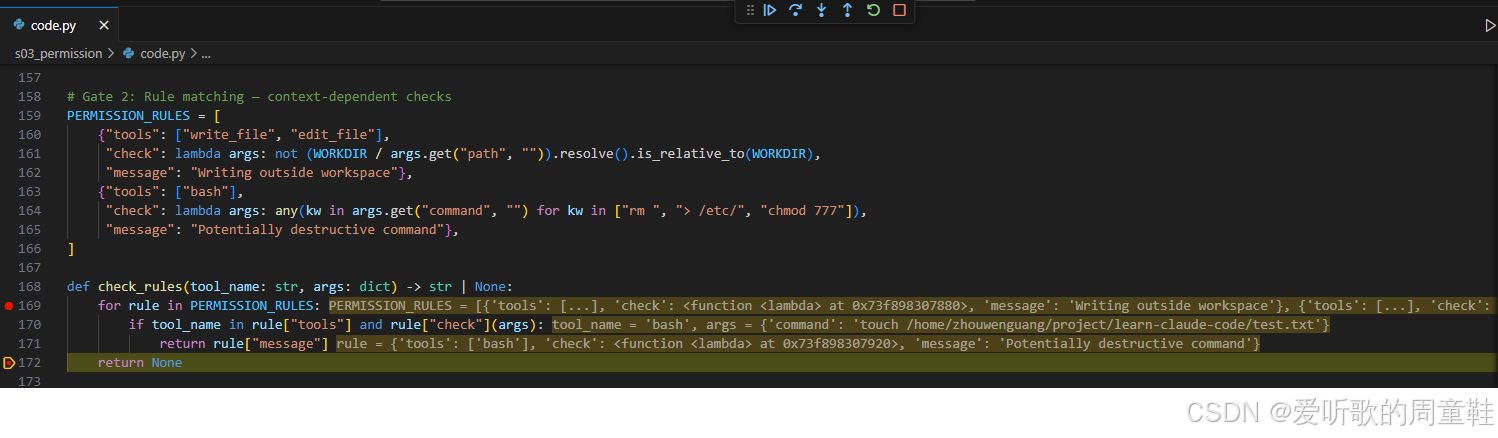
python
PERMISSION_RULES = [
{
"tools": ["write_file", "edit_file"],
"check": lambda args: not (WORKDIR / args.get("path", "")).resolve().is_relative_to(WORKDIR),
"message": "Writing outside workspace",
},
{
"tools": ["bash"],
"check": lambda args: any(kw in args.get("command", "") for kw in ["rm ", "> /etc/", "chmod 777"]),
"message": "Potentially destructive command",
},
]这层和 deny list 的区别在于:它不是绝对禁止,而是判断 "这个操作是否需要用户确认"。比如写工作区外、删除文件、修改系统目录、过宽权限变更,这些都不一定是永远不能做,但不能由模型自动决定。
所以 check_rules() 的作用就是遍历这些规则:
python
def check_rules(tool_name: str, args: dict) -> str | None:
for rule in PERMISSION_RULES:
if tool_name in rule["tools"] and rule["check"](args):
return rule["message"]
return None只要某条规则命中,就返回对应 reason。注意这里返回的不是 False,而是一个 message。因为规则命中不代表立刻拒绝,而是要进入第三道闸门:用户审批。
第三道闸门就是 ask_user():
python
def ask_user(tool_name: str, args: dict, reason: str) -> str:
print(f"\n\033[33m⚠ {reason}\033[0m")
print(f" Tool: {tool_name}({args})")
choice = input(" Allow? [y/N] ").strip().lower()
return "allow" if choice in ("y", "yes") else "deny"这一段非常直观:如果规则认为这次工具调用有风险,程序就暂停,把原因、工具名、参数都展示给用户,然后等待用户输入 y/yes。如果用户不明确同意,默认就是 deny。
这也体现了一个很重要的安全设计:默认拒绝比默认允许安全。
如果用户直接回车,或者输入其他内容,这次工具调用都会被拒绝。
最后,三道闸门被 check_permission() 串起来:
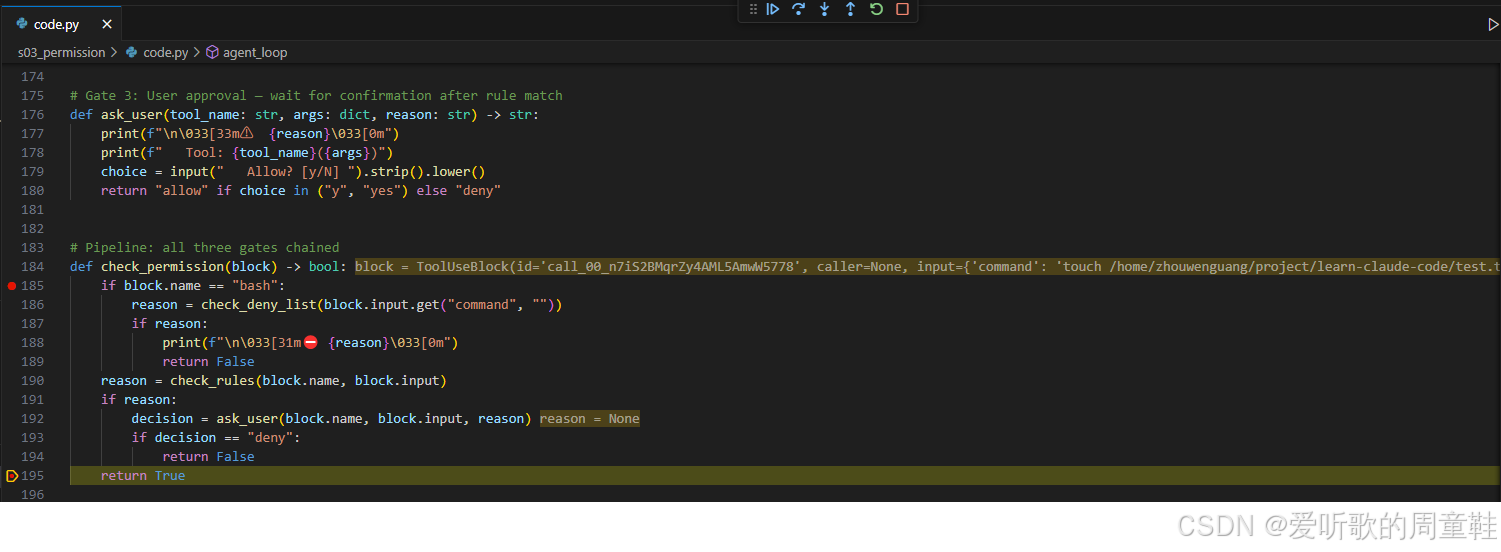
python
def check_permission(block) -> bool:
if block.name == "bash":
reason = check_deny_list(block.input.get("command", ""))
if reason:
print(f"\n\033[31m⛔ {reason}\033[0m")
return False
reason = check_rules(block.name, block.input)
if reason:
decision = ask_user(block.name, block.input, reason)
if decision == "deny":
return False
return True这段代码的顺序非常重要:
第一步,先查硬拒绝。如果是 bash,先看命令里有没有命中 DENY_LIST。命中就直接 False,不执行,不询问。
第二步,再查规则。如果工具名和参数命中某条风险规则,就进入 ask_user()。
第三步,如果用户拒绝,也返回 False。如果用户允许,或者没有命中任何规则,就返回 True。
所以 check_permission() 的返回值非常简单:
- True -> 可以执行 handler
- False -> 不允许执行 handler
而真正和 agent loop 连接起来的地方,在下面这段:
python
for block in response.content:
if block.type != "tool_use":
continue
print(f"\033[36m> {block.name}\033[0m")
# s03 change: run through permission pipeline before executing
if not check_permission(block):
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": "Permission denied."
})
continue
handler = TOOL_HANDLERS.get(block.name)
output = handler(**block.input) if handler else f"Unknown: {block.name}"
results.append({"type": "tool_result", "tool_use_id": block.id, "content": output})这就是 s03 最核心的代码变化。和 s02 相比,真正新增的其实就是:
python
if not check_permission(block):
results.append(...)
continue但这一行的位置非常关键:它正好卡在 模型生成 tool_use 之后,handler 执行之前。也就是说,模型已经提出了工具调用,但程序还没有真正碰文件系统、跑 shell、改代码。Permission Pipeline 就是在这个边界上做判断。
如果权限拒绝,程序不会静默跳过,而是追加一个普通的 tool_result:
python
"content": "Permission denied."这就保证了 Agent Loop 仍然完整。模型下一轮仍然能看到:刚才那次工具调用被权限系统拒绝了,然后它可以根据这个结果重新规划下一步。教程文档也强调,s02 的循环完全保留,唯一变化就是工具执行前插入 check_permission()。
所以从代码角度看,s03 的真正价值并不是 "多了几个 if 判断",而是第一次把工具调用拆成了两个阶段:
shell
model proposes tool call
runtime authorizes tool call
handler executes tool call这一步非常关键。因为从 s03 开始,模型不再直接拥有执行权,而只是拥有 "申请执行" 的能力。真正是否执行,由 harness 层的权限管线决定。
博主在给定下面的提示词情况下:
shell
Create a file called test.txt in the current directory想通过调试看看整个过程发生了什么,我们来具体分析下:
第一次 Loop
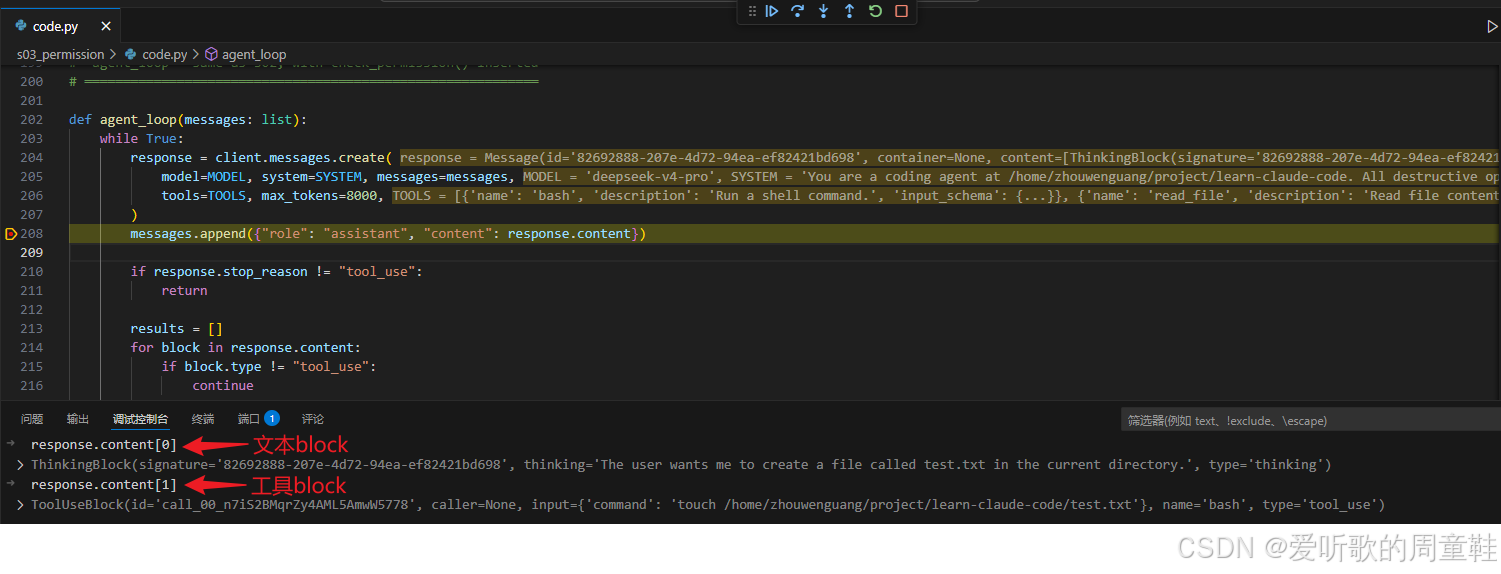
模型第一次响应结果
工具调用权限检查
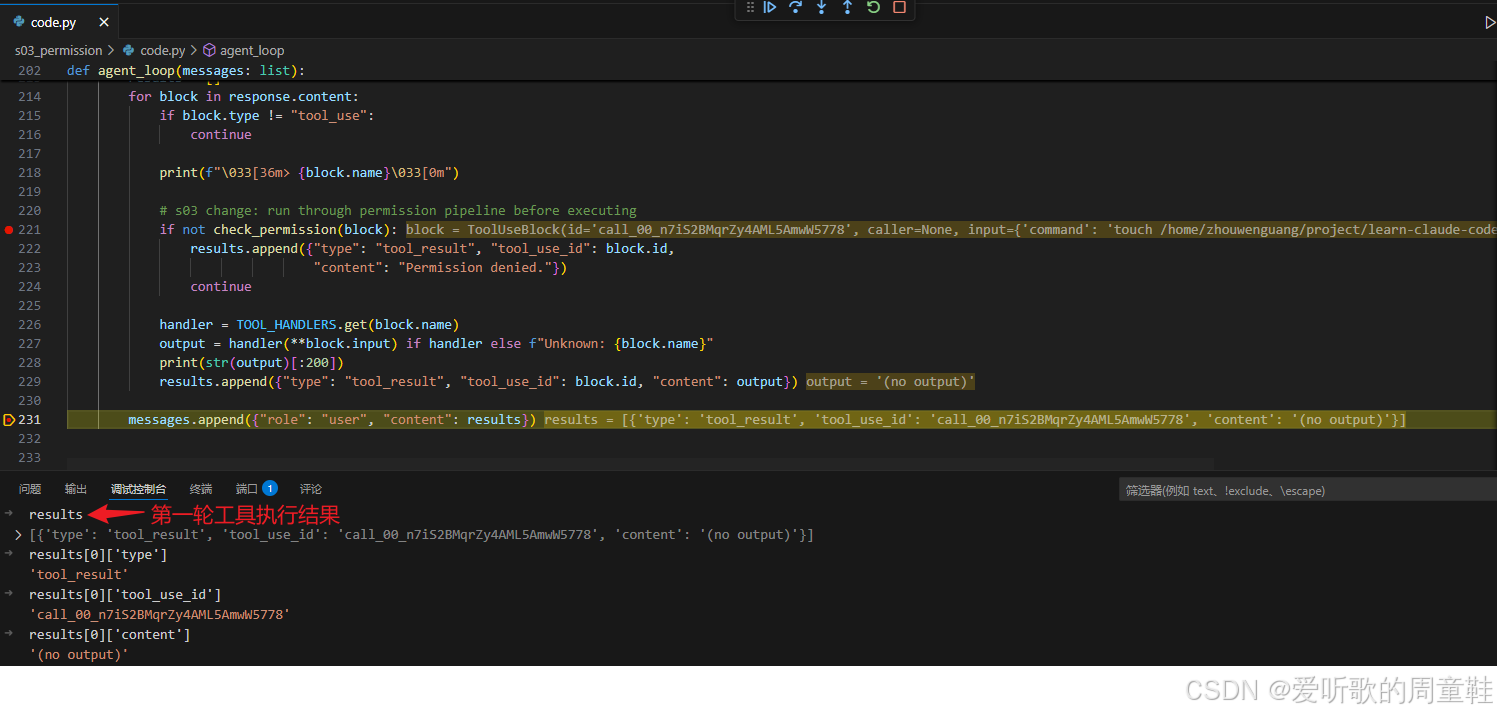
工具第一次执行结果
在第一次 loop 中,模型收到用户请求后,并没有直接返回最终答案,而是先产生了一个工具调用。从调试图可以看到,response.content 中包含两个 block:前面是 ThinkingBlock,说明模型理解到用户想在当前目录创建一个 test.txt;后面是 ToolUseBlock,调用的是 bash 工具,命令为:
shell
touch /home/zhouwenguang/project/learn-claude-code/test.txt这一步其实非常典型:从模型视角看,它只是提出了一个 "我想执行 bash 命令" 的申请。真正是否能执行,还没有发生。
接下来进入 s03 新增的权限管线。程序在 agent loop 中遍历到这个 tool_use block 后,并没有马上执行 TOOL_HANDLERS["bash"],而是先调用:
python
if not check_permission(block):
...先看 Gate 1,也就是 check_deny_list()。调试图里可以看到,当前命令是 touch .../test.txt,而 DENY_LIST 中包含的是 rm -rf /、sudo、shutdown、reboot、mkfs、dd if=、> /dev/sda 这类高危模式。由于 touch 命令没有命中任何硬拒绝模式,所以 check_deny_list() 最终返回 None,说明第一道闸门通过。
然后进入 Gate 2,也就是 check_rules()。这里会遍历 PERMISSION_RULES,检查当前工具名和参数是否命中风险规则。调试图里可以看到,当前工具名是 bash,参数是:
shell
{"command": "touch /home/zhouwenguang/project/learn-claude-code/test.txt"}而 bash 相关规则主要检查命令中是否包含 rm 、> /etc/、chmod 777 等潜在破坏性模式。当前只是创建一个空文件,不涉及删除、不涉及系统目录重定向,也不涉及危险权限修改,因此 check_rules() 同样返回 None。
由于前两道闸门都没有返回风险原因,所以第三道 ask_user() 不会触发。程序直接走到 check_permission() 的最后:
python
return True也就是说,这次工具调用被权限系统判定为安全,可以继续执行 handler。
随后 agent loop 才真正进入工具执行阶段:
python
handler = TOOL_HANDLERS.get(block.name)
output = handler(**block.input)因为当前工具名是 bash,所以最终执行的是 run_bash()。touch 命令本身没有标准输出,因此工具结果中返回的是:
shell
(no output)最后,这个结果会被包装成标准的 tool_result,追加回 messages:
python
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": "(no output)"
})所以第一次 loop 的完整过程可以概括为:
shell
用户请求创建文件
↓
模型提出 bash 工具调用
↓
Gate 1:未命中 hard deny
↓
Gate 2:未命中风险规则
↓
Gate 3:无需用户审批
↓
handler 真正执行 touch
↓
返回 tool_result: (no output)这里最值得强调的一点是:即便这只是一个简单的 touch 命令,s03 也不会让它绕过权限系统直接执行 。所有工具调用都必须先经过 check_permission(),只不过这次请求足够安全,所以最终被自动放行。
第二次 Loop
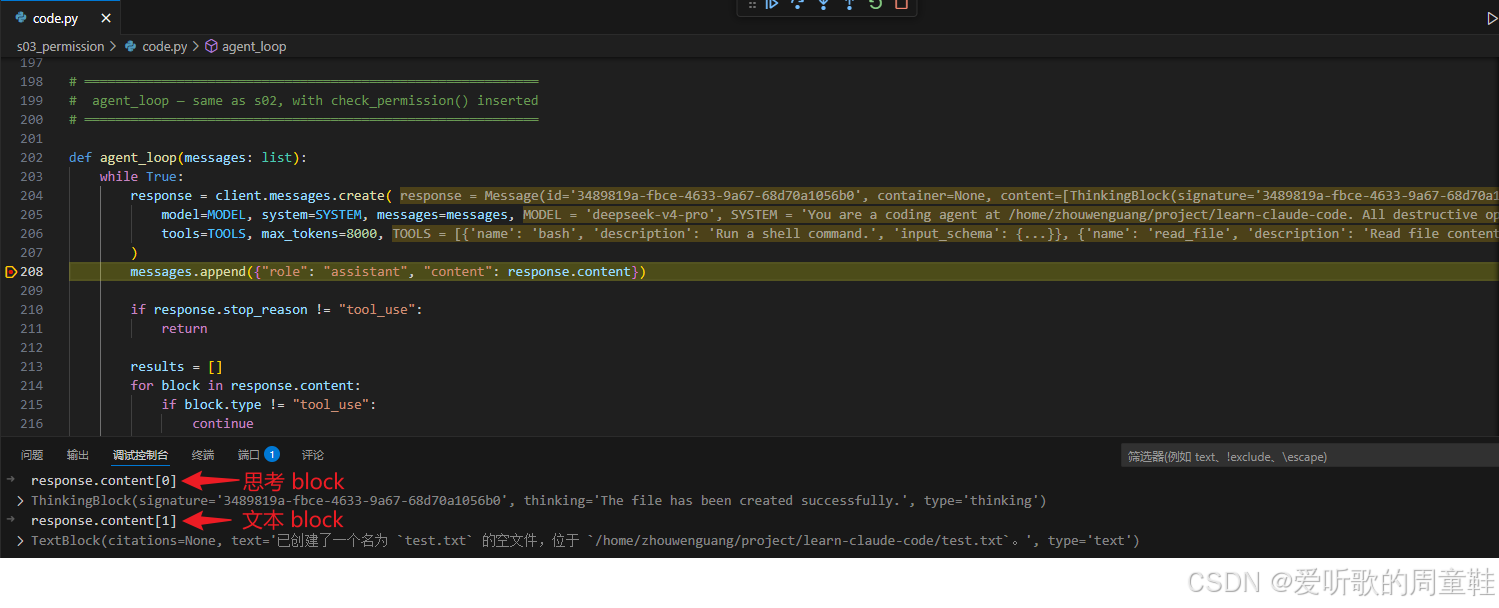
模型第二次响应结果
第二次 loop 中,模型拿到了上一轮工具返回的结果:
shell
(no output)虽然 touch 命令没有输出内容,但对模型来说,这已经表示工具调用正常完成,没有报错。于是这一次 response.content 中不再包含新的 ToolUseBlock,而是只包含思考 block 和文本 block。
从调试图可以看到,模型最终返回的文本大意是:
shell
已创建了一个名为 test.txt 的空文件,位于 /home/zhouwenguang/project/learn-claude-code/test.txt。由于这一轮没有新的工具调用,因此:
python
if response.stop_reason != "tool_use":
return会直接结束 agent loop。
所以第二次 loop 的意义在于:权限系统不会改变 Agent Loop 的闭环方式 。第一轮工具调用被允许并执行后,结果仍然以标准 tool_result 的形式回到上下文;第二轮模型读取这个结果,再生成最终回答。换句话说,s03 只是把 "工具调用能不能执行" 这件事加上了运行时审查,并没有破坏原来的模型-工具-结果-再推理流程。
从这次调试可以很清楚地看到,s03 的权限系统并不是一个额外的业务功能,而是插在工具执行边界上的一层统一路由:模型可以申请执行工具,但工具是否真的执行必须先经过 Permission Pipeline。
这就是 s03 相对于 s02 最关键的变化。s02 中,模型生成 tool_use 后基本就会直接进入 handler;而 s03 中,模型生成 tool_use 只代表"申请执行",只有当 check_permission() 返回 True 后,handler 才会真正运行。
OK,以上就是 s03 Permission 工作原理的完整分析了。
那大家感兴趣的话可以试试下面这些 prompt 感受下这个工具执行权限检查加入后的一些变化:
1. Create a file called test.txt in the current directory(应该直接通过)
2. Delete all temporary files in /tmp(bash + rm 会触发闸门 2)
3. What files are in the current directory?(只读,全部通过)
4. Try to write a file to /etc/something(写工作区外,触发闸门 2)
6. 相对于 s02 的变更
| 组件 | 之前 (s02) | 之后 (s03) |
|---|---|---|
| 安全模型 | 无(信任模型) | 三道闸门权限管线 |
| 新函数 | --- | check_deny_list, check_rules, ask_user, check_permission |
| 循环 | 直接执行所有工具 | 执行前插入 check_permission() |
7. 小结
s03 Permission 是新版 learn-claude-code 中非常关键的一节。它虽然代码量不大,但系统意义很大:从这一节开始,Agent 不再是 "模型提出工具调用,程序立刻执行",而是变成了 "模型提出工具调用,运行时先判断权限,再决定是否执行"。
这一节最值得记住的核心思想是:
不要信任模型,要信任运行时边界。
模型可以提出任何工具调用,但真正能不能落地,必须交给 harness 层判断。安全读取可以直接通过;风险操作需要用户确认;绝对危险的命令应该在 handler 执行前就被拦住。
这也是 s03 相对于 s02 的最大升级:s02 解决的是 "模型如何调用多个工具",s03 解决的是 "模型调用工具之前,系统要不要允许它执行"。从这里开始,Agent 的工具系统不再只是一个 dispatch map,而开始具备最基础的权限治理能力。
当然,当前教学版的权限系统仍然是简化版。它用字符串匹配模拟 deny list,用简单规则模拟 risk matching,用命令行输入模拟用户审批。真实 Claude Code 的权限系统会更复杂,包括多来源规则、hooks、工具自身校验、classifier 自动审批和子 Agent 权限冒泡等机制。教程文档也明确说明,教学版是为了降低理解门槛,把生产版复杂机制收缩成 deny / ask / allow 三道闸门。
但正因为它足够简单,我们反而更容易看清楚 Permission 的本质:
Permission 不是让模型更安全,而是在模型和真实世界之间加一个由代码控制的执行闸门。
OK,以上就是本期想要分享的全部内容了。
结语
本篇文章我们围绕新版教程 s03 Permission 这一节,从问题出发,结合 Permission Desk 流程图与代码实现,完整梳理了 Agent 在工具执行前是如何通过三道闸门建立最基础权限治理能力的。
相比 s01 的 Agent Loop 和 s02 的 Tool Use,s03 最本质的变化并不是新增了某个工具,而是在模型与真实执行之间,第一次正式插入了一层 "运行时边界"。从这一节开始,模型不再天然拥有执行权,而只是拥有"申请执行"的能力;真正是否允许落地,开始由 harness 层的 Permission Pipeline 决定。
从工程视角来看,这一步其实非常关键。前面的章节解决的是 "模型如何调用工具",而 s03 开始回答另一个更现实的问题:模型调用了工具之后,系统到底该不该让它执行。 这意味着 Agent 系统的关注点,第一次从 "能力扩展" 进入到了 "能力约束"。
而 Permission Pipeline 的设计也非常克制:既没有推翻原有 Agent Loop,也没有重写工具系统,而只是把
check_permission()精准地插入在tool_use → handler的边界上。正因为它的位置足够清晰,所以整个权限模型也变得非常容易理解:
- deny:绝对危险,直接阻止
- ask:存在风险,需要用户确认
- allow:安全请求,自动放行
这三种结果,本质上对应的是系统对 "模型意图" 的不同信任等级。
进一步来看,s03 的意义并不只是 "增加安全检查",而是让整个 Agent 系统第一次建立起一种非常重要的工程认知:模型负责生成意图,运行时负责决定这些意图能否真正影响世界。
也正因为如此,Permission 的价值并不在于它今天拦住了多少危险命令,而在于它正式把 "执行控制权" 从模型侧收回到了系统侧。从这一刻开始,Agent 不再只是一个会调用工具的循环,而开始逐渐演化为一个具备运行时治理能力的系统。
如果说 s01 建立的是 Agent 的 "行动能力",s02 建立的是 Agent 的 "工具能力",那么 s03 建立的,就是 Agent 最基础的 "边界意识"。而这一步,也正是后面 Hooks、Memory、Error Recovery 等机制能够继续向上扩展的重要前提。
下篇文章我们将来学习新版教程 s04 Hooks 章节的内容,敬请期待🤗