一、为什么需要 Flink CEP?
在流处理中,基础 API(Map/FlatMap/Filter)适用于单一事件的无状态转换;Window API 适用于固定时间窗口内的聚合计算。然而,面对"有序性"、"依赖性"、"时间跨度"交织的业务诉求时,传统 API 显得捉襟见肘。
例如:电商风控场景 ------ 用户在 10 秒内连续 3 次登录失败,并在随后的 1 分钟内成功登录且立即发起一笔大额支付。
如果要用普通 DataStream API 实现,我们需要自定义 KeyedProcessFunction,自己维护 ValueState/ListState,自己注册 Timer 处理超时,还要处理乱序数据。代码不仅冗长,而且极易出错。Flink CEP 正是为了解决这一痛点而生,它允许我们使用一套高度语义化的 Pattern API 来定义复杂的事件序列,并将繁琐的状态管理和时间处理交由框架底层完成。
二、Flink CEP 核心机制与原理
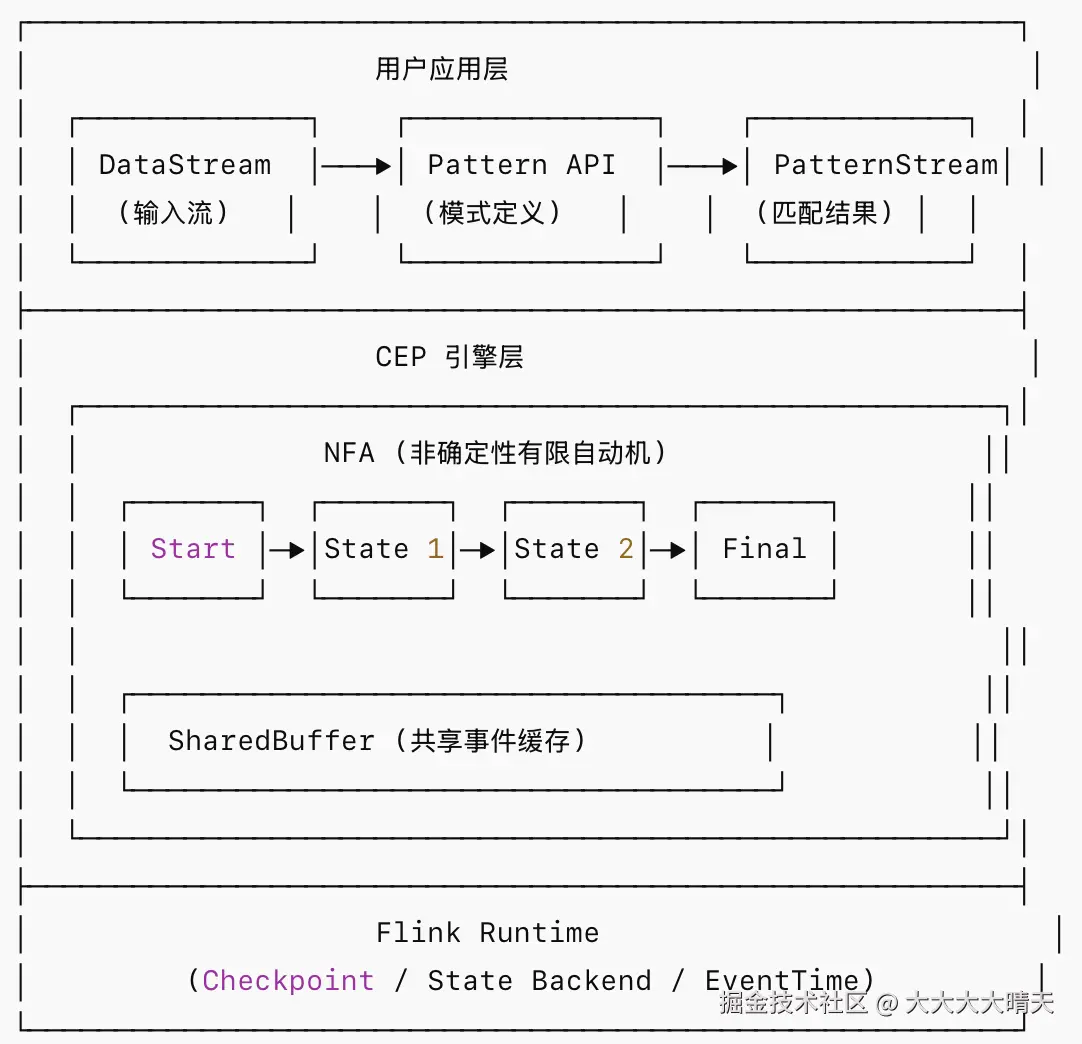
1.NFA 模式匹配原理
Flink CEP 的底层核心是 NFA(Non-deterministic Finite Automaton,非确定有限自动机)。当一个新的事件到来时,NFA 可能同时处于多个状态(即存在多个并行的匹配序列)。例如,规则是"A 后面跟着 B",如果数据流是 A1 -> A2 -> B1,当 B1 到来时,它可以与 A1 组合(匹配成功),也可以与 A2 组合(另一个匹配成功)。
Flink CEP 将我们定义的 Pattern 编译成一个 NFA 图。NFA 包含多种状态(State)和连接状态的边(State Transition)。 状态流转主要有三种动作:
- Take(采纳): 接受当前事件,进入下一个状态。
- Ignore(忽略): 忽略当前事件,保持当前状态不变(用于宽松匹配)。
- Proceed(推进): 不依赖当前事件直接进入下一个状态(通常用于处理 Optional 即可选状态)。
2.SharedBuffer 机制
为避免 NFA 实例间重复存储事件,Flink CEP 使用SharedBuffer(共享缓冲区)进行优化,这种设计显著降低了内存占用,尤其在高并发匹配场景下效果明显。

3.时间语义支持
Flink CEP 同时支持 Event Time 和 Processing Time:
- Event Time 模式下: CEP 引擎依赖 Watermark 推进,确保事件按时间戳有序处理。迟到事件(late event)在 Watermark 之后到达将被丢弃(默认行为,强烈推荐)。
- Processing Time 模式下: 事件按到达顺序处理,不保证全局有序。
三、核心配置与 API 详解
定义一个完整的 CEP 逻辑通常分为三步:定义 Pattern -> 应用 Pattern 到数据流 -> 提取匹配结果。
vbnet
// 定义模式
Pattern<Event, ?> pattern = Pattern.<Event>begin("start")
.where(SimpleCondition.of(e -> e.getType().equals("login_fail")))
.times(3)
.consecutive()
.within(Time.minutes(5));
// 应用模式到数据流
PatternStream<Event> patternStream = CEP.pattern(inputStream, pattern);
// 提取匹配结果
DataStream<Alert> alerts = patternStream.select(
(Map<String, List<Event>> match) -> {
List<Event> events = match.get("start");
return new Alert(events.get(0).getUserId(), "连续登录失败");
}
);1.模式定义(Pattern API)
CEP 提供了丰富的连续性(Contiguity)策略,这是最容易混淆的配置:
| 策略 | API | 含义 |
|---|---|---|
| 严格连续 | next() | 事件必须紧邻,中间不能有其他事件 |
| 松散连续 | followedBy() | 允许中间有不匹配的事件,但不回溯 |
| 非确定性松散连续 | followedByAny() | 允许中间有不匹配的事件,且回溯所有可能 |
| 否定模式 | notNext(),notFollowedBy() | 指定不想出现的事件类型 |
假设数据流:[a1, c, b1, b2]
Pattern.begin("a").next("b")-> 无匹配 (因为中间隔了 c)Pattern.begin("a").followedBy("b")-> 匹配[a1, b1]Pattern.begin("a").followedByAny("b")-> 匹配[a1, b1]和[a1, b2]
2.量词(Quantifiers)
scss
// 恰好出现 N 次
.times(3)
// 出现 N 到 M 次
.times(2, 4)
// 出现 1 次或多次
.oneOrMore()
// 出现 N 次或更多
.timesOrMore(2)
// 可选(出现 0 次或 1 次)
.optional()
// 贪婪模式(尽可能多匹配)
.oneOrMore().greedy()3.条件(Conditions)
csharp
// 简单条件 - 只依赖当前事件
.where(SimpleCondition.of(event -> event.getPrice() > 100))
// 迭代条件 - 可访问之前已匹配的事件
.where(new IterativeCondition<Event>() {
@Override
public boolean filter(Event value, Context<Event> ctx) {
// ctx.getEventsForPattern("previous") 获取之前匹配的事件
double sum = 0;
for (Event e : ctx.getEventsForPattern("previous")) {
sum += e.getAmount();
}
return sum + value.getAmount() > 1000;
}
})
// 组合条件
.where(condition1).or(condition2) // OR
.where(condition1).where(condition2) // AND (链式调用即AND)4.超时处理(侧输出)
dart
OutputTag<TimeoutEvent> timeoutTag = new OutputTag<>("timeout"){};
SingleOutputStreamOperator<CompleteEvent> result = patternStream.select(
timeoutTag,
// 超时处理
(Map<String, List<Event>> pattern, long timestamp) -> {
return new TimeoutEvent(pattern.get("start").get(0));
},
// 正常匹配处理
(Map<String, List<Event>> pattern) -> {
return new CompleteEvent(pattern);
}
);
// 获取超时侧输出
DataStream<TimeoutEvent> timeoutStream = result.getSideOutput(timeoutTag);四、最佳实践
- 控制模式复杂度
scss
// ❌ 避免过于宽泛的量词
.oneOrMore() // 无上限,可能产生大量部分匹配;需配合设置 until() 终止条件
// ✅ 设置合理上限
.times(1, 10) // 限制最大匹配次数- 前置过滤
ini
// ✅ 在进入 CEP 前过滤无关事件,减少 NFA 处理压力
DataStream<Event> filtered = inputStream
.filter(e -> relevantTypes.contains(e.getType()));
PatternStream<Event> patternStream = CEP.pattern(filtered.keyBy(...), pattern);- 合理选择连续性策略
makefile
性能开销: followedByAny > followedBy > next
(最高) (中等) (最低)
原因: followedByAny 会为每个匹配事件创建新的 NFA 分支- 状态管理
less
// ✅ 推荐:使用 KeyedStream,按业务主键分区
DataStream<Event> keyedStream = inputStream.keyBy(Event::getUserId);
// ✅ 推荐:设置合理的 within 时间,避免状态无限增长
pattern.within(Time.minutes(30));
// ✅ 推荐:使用 RocksDB State Backend 应对大状态
env.setStateBackend(new EmbeddedRocksDBStateBackend());
// ❌ 避免:不设置 within 且模式复杂,导致状态膨胀- 动态规则的变通方案
- 多版本作业 + 蓝绿部署
- 基于 BroadcastState + ProcessFunction 自实现
- 作业变更重启(接受延迟)