你必须非常努力,才能看起来毫不费力!
微信搜索公众号 AGIPlayer ,一起From Zero To Hero !
Anthropic 发布 security-guidance 插件,三层防线实时拦截 AI 编码安全漏洞,内部数据:PR 安全评论减少 30-40%。
5 月 26 号,Anthropic 的开发者账号 @ClaudeDevs 发了一条推,7,500 多个赞,6,400 多个收藏------
"We've shipped a security-guidance plugin for Claude Code that helps identify and fix vulnerabilities as you're writing code."
就这么一句话,配了一个 28 秒的演示视频。
说实话,我看到的第一反应不是"哇好酷",而是------终于有人正经做这件事了。
视频来源:x.com/ClaudeDevs/...
一. AI 写代码的安全焦虑,不是杞人忧天
先说个让我后怕的事。
前阵子用 Claude Code 写一个内部服务的接口,让它加个查询逻辑。Claude 噼里啪啦写完了,我扫了一眼,功能没问题,commit 了。第二天 Code Review 的时候,同事指出------查询没做权限校验,任何登录用户都能拉到全量数据。
这不是 Claude 的 bug,是我让它"加查询"的时候,压根没提权限的事。AI 不会主动帮你补全你没说的安全逻辑。
这就是 Vibe Coding 的核心矛盾:你越信任 AI 的编码能力,就越容易忽略它不懂你的安全上下文。它写得快,但它不知道你的系统里哪些数据是敏感的、哪些接口必须鉴权、哪些输入必须过滤。
而大部分人用 AI 写代码的姿势就是------写完,扫一眼,过了。
这个安全插件,就是给这个"扫一眼"加一层机器审核。
二. 三层防线:从正则到 Agent,越深越准
这个插件的设计,我觉得挺讲究的。不是简单地把代码扔给模型说"帮我看看有没有问题",而是分了三个层次,每层的深度和成本不一样。
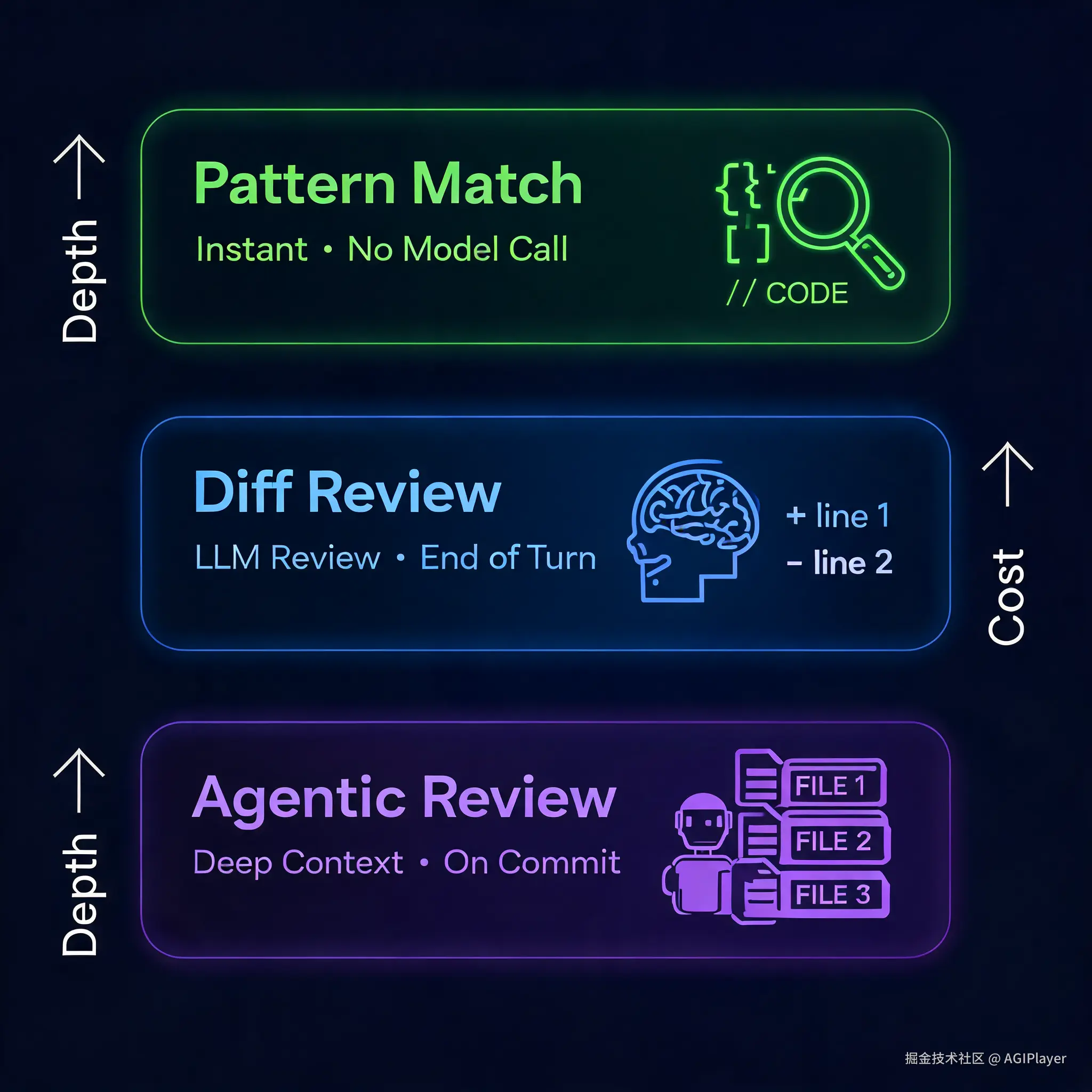 Security Guidance Plugin 三层审查架构
Security Guidance Plugin 三层审查架构
第一层:Pattern Match------正则扫描,零成本
每次 Claude 编辑文件的时候,插件会用正则匹配扫描新写入的内容。不调模型,零 API 开销,纯字符串匹配。
它关注的是那些"一看就知道危险"的模式:
eval(、new Function、os.system、child_process.exec------动态代码执行pickle------不安全的反序列化dangerouslySetInnerHTML、.innerHTML =、document.write------DOM 注入.github/workflows/下的文件修改------CI/CD 权限风险
这一层的好处是快,而且免费。坏处是只能抓已知模式,遇到稍微隐蔽的漏洞就无能为力了。
但你想,光是抓 eval( 和 pickle 这类,就已经能挡掉不少低级错误了。
第二层:Diff Review------模型审查,每轮结束
每一轮对话结束的时候(你发一条消息,Claude 干活回复,这是一轮),插件会算一个 git diff,把这一轮所有文件的变更发给一个独立的 Claude 实例做安全审查。
注意,是独立的实例。不是让写代码的那个 Claude 自己审自己,而是另起一个 Claude,从 diff 出发,带着安全审查的 prompt 来看你的改动。
这一层能抓到正则抓不到的东西:权限绕过、不安全的直接对象引用(IDOR)、注入、SSRF、弱加密......
审查在后台跑,不阻塞 Claude 的回复。如果发现了问题,Claude 会在下一轮自动修复。
每个会话最多连续触发 3 次修正,不会无限循环。
第三层:Agentic Review------深度审查,每次提交
当 Claude 通过 Bash 工具执行 git commit 或 git push 的时候,插件会启动一个更深的审查。这个审查是 Agent 式的------它会读取周围的代码,包括调用方、输入过滤、相关文件,来判断一个看起来危险的调用在你这个项目里是不是真的有问题。
这一层的设计很关键。因为很多代码单独看是危险的,但在具体上下文中是安全的。比如你有一个 eval,但它的输入已经经过了白名单过滤。如果只看 diff 会误报,但 Agent 能读到过滤逻辑,判断这是安全的。
这层把误报率压下来了。但代价是每次 commit 会多花一些 token(用的默认是 Opus 4.7),每小时最多触发 20 次。
三. 安装和使用,三行命令搞定
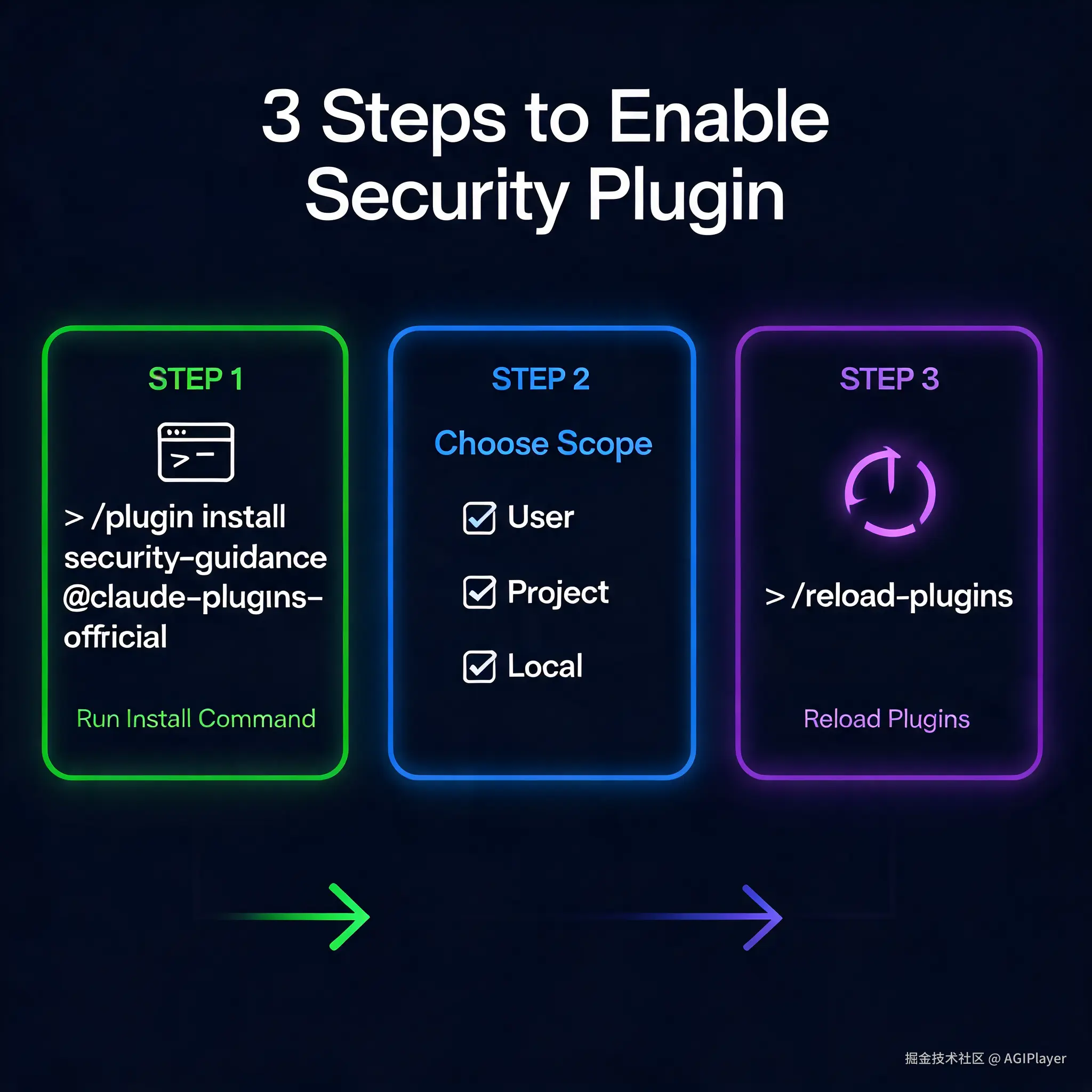 Security Guidance Plugin 安装流程
Security Guidance Plugin 安装流程
前提条件很简单:Claude Code CLI 版本 ≥ 2.1.144,Python 3.8+,工作目录是个 git 仓库。
安装就一行:
bash
/plugin install security-guidance@claude-plugins-official选个 scope(推荐 user scope,这样所有项目都生效),然后:
bash
/reload-plugins完事了。没有额外配置,没有单独的命令要记。插件装上就自动跑,你正常用 Claude Code 写代码就行。
如果你要在团队或者 Cloud Session 里启用,可以在项目的 .claude/settings.json 里加:
json
{
"enabledPlugins": {
"security-guidance@claude-plugins-official": true
}
}这样 clone 仓库的同事也能自动用上。管理员还可以在 managed settings 里组织级启用。
四. 能自定义规则,这才是重点
光靠内置的通用安全规则,肯定不够。每个项目都有自己的安全上下文,AI 不可能凭空猜到。
这个插件给了两个扩展点:
给模型审查加规则:claude-security-guidance.md
在项目根目录的 .claude/ 下放一个 Markdown 文件,用自然语言写你的安全规则。比如:
markdown
# 安全规则
- `/admin` 下的所有路由必须调用 `require_role("admin")` 后才能读数据库
- 不要在 INFO 及以上日志级别记录 `customer_id` 或 `account_number`
- Token 比较必须用 `crypto.timingSafeEqual`,不能用 `===`这些规则会被注入到模型审查的 prompt 里,作为额外的上下文。插件发现违规会报告给 Claude 让它修,但不会硬性阻止写入------它是指南,不是强制。
给正则扫描加规则:security-patterns.yaml
yaml
patterns:
- rule_name: internal_api_key
substrings: ["sk_live_", "AKIA"]
reminder: "Hardcoded API key prefix. Load credentials from the secret manager."
- rule_name: tenant_unfiltered_query
regex: "\\.objects\\.all\\(\\)"
paths: ["**/src/tenants/**"]
reminder: "Multi-tenant code must filter by org_id."支持正则和子串匹配,还能用 paths 和 exclude_paths 做文件路径过滤。最多 50 条自定义规则。
这两个扩展点的设计我觉得很聪明:claude-security-guidance.md 用自然语言,适合写策略性的规则;security-patterns.yaml 用正则,适合写确定性的硬规则。一个灵活一个精准,互补。
五. 30-40% 的 PR 安全评论减少,意味着什么?
Anthropic 在推文里说了一个数据:内部推广后,使用插件的 PR,安全相关评论减少了 30-40%。
 Anthropic 内部基准测试:PR 安全评论减少 30-40%
Anthropic 内部基准测试:PR 安全评论减少 30-40%
这个数字需要一些解读。
首先,它说的是"安全相关的 PR 评论"减少了,不是说安全问题减少了 30-40%。这两件事不一样------安全评论减少,可能是因为问题在写代码的阶段就被修掉了,也可能是因为安全审查在更早的阶段做了过滤。不管是哪种,对 Code Reviewer 来说都是好事,因为他们的精力可以集中在更复杂的问题上。
其次,这只是 Anthropic 内部的数据。他们自己的代码库和开发流程有特殊性,不能直接推广到所有团队。但作为一个参考指标,30-40% 已经说明这不是纯摆设了。
六. 它在整个安全体系里的位置
这个插件不是万能的,Anthropic 自己也说了:"Treat the plugin as one layer of defense in depth, not a complete security solution."
它在一个完整的安全体系里,处于最早的位置:
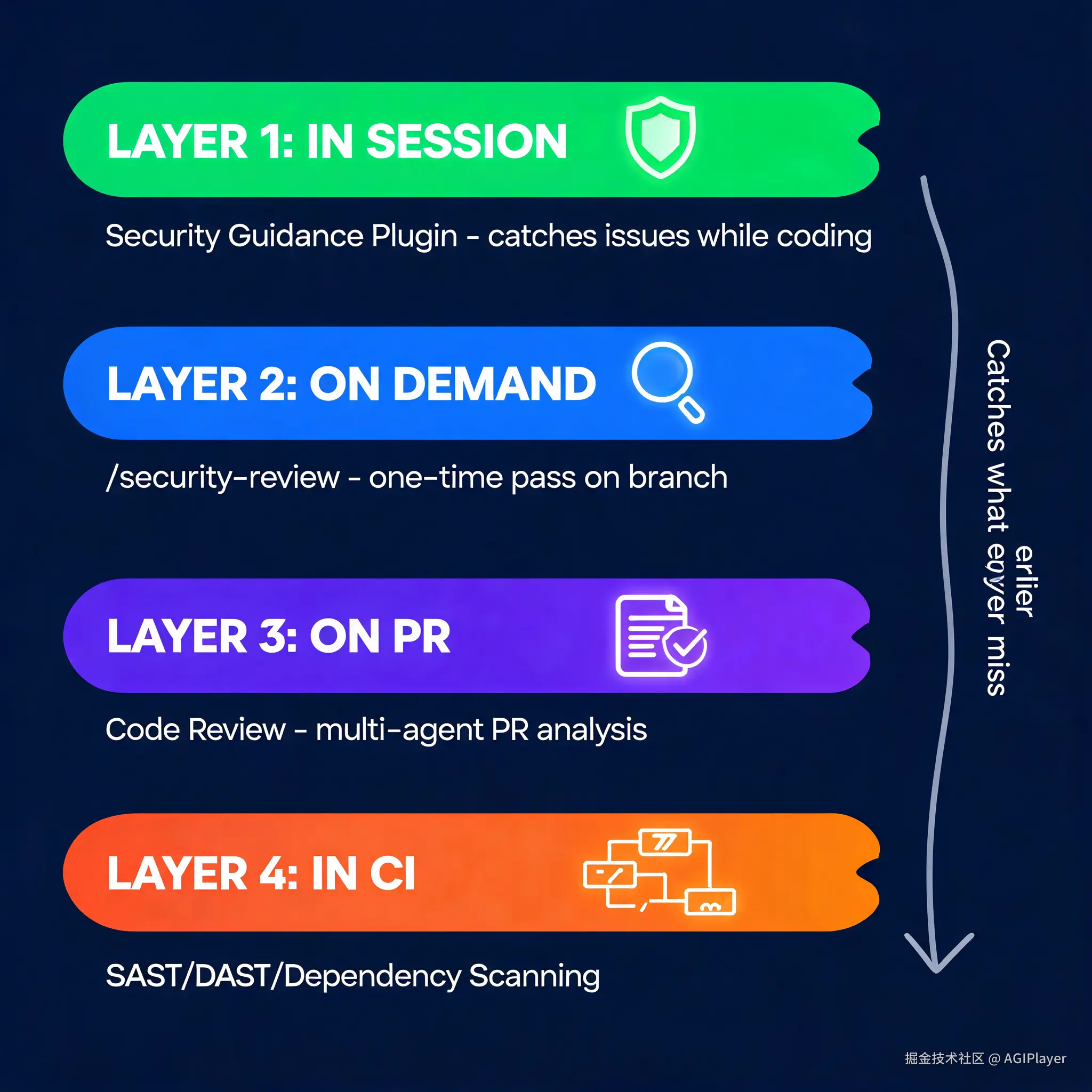 Security Guidance Plugin 在纵深防御体系中的位置
Security Guidance Plugin 在纵深防御体系中的位置
| 阶段 | 工具 | 覆盖范围 |
|---|---|---|
| 编码中 | Security Guidance Plugin | 常见漏洞,同一会话修复 |
| 按需 | /security-review 命令 |
一次性安全审查 |
| PR 阶段 | Code Review(多 Agent) | 全代码库上下文的安全+正确性审查 |
| CI 阶段 | SAST/DAST/依赖扫描 | 语言特定规则、供应链检查、策略执行 |
每一层抓住前面漏掉的。插件的价值在于减少到达后面几层的问题量,而不是替代它们。
七. 背后的技术:完全基于 Hooks
这个插件最让我觉得有意思的一个细节------它完全是用 Claude Code 的 Hooks 机制构建的,没有任何特殊的内部 API。
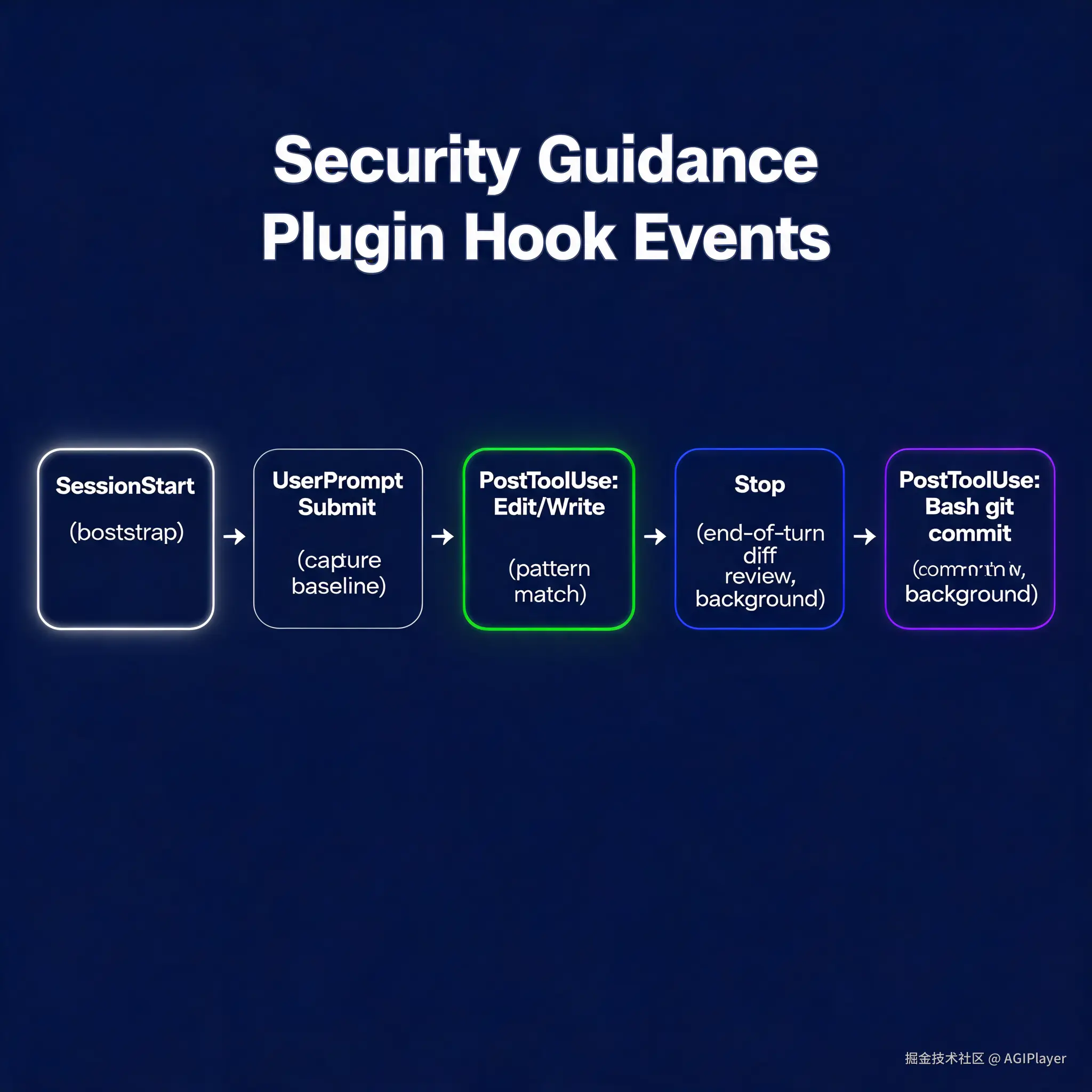 Security Guidance Plugin 注册的 Hook 事件
Security Guidance Plugin 注册的 Hook 事件
它注册了这些 Hook:
| Hook 事件 | 用途 |
|---|---|
SessionStart |
初始化 Python 虚拟环境 |
UserPromptSubmit |
捕获工作区基线,用于后续 diff |
PostToolUse(Edit/Write/NotebookEdit) |
正则扫描 |
Stop |
每轮结束的 diff 审查(后台运行) |
PostToolUse(Bash,过滤 git commit/push) |
提交审查(后台运行) |
这意味着你也可以用同样的 Hooks 机制构建自己的审查插件。Anthropic 把这个插件的源码放在了 GitHub 上,作为"从 Hook 调用模型并回传结果"的工作示例。
八. 成本、限制和我的判断
成本
第一层正则扫描不调模型,零成本。第二层 diff 审查和第三层 commit 审查会消耗额外的 token,默认用的是 Opus 4.7。你可以通过环境变量切换模型:
SECURITY_REVIEW_MODEL:控制 diff 审查用的模型SG_AGENTIC_MODEL:控制 commit 审查用的模型
如果你觉得 Opus 太贵,可以换成 Sonnet 省点钱。如果你想要更高的召回率,可以开 SG_DUAL_OR=on,并行跑两次审查合并结果,但成本翻倍。
限制
- 不阻止写入,只报告发现。安全审查结果是建议,不是强制的
- 模型审查可能漏掉漏洞,也可能误报
claude-security-guidance.md的规则是指南不是护栏------写了"忽略 XX 漏洞类型"并不会真正抑制那类发现- 只有 Claude 触发的 commit 会被审查,你自己 shell 里跑的
git commit不会 - 首次运行会创建 Python 虚拟环境并安装 Claude Agent SDK,需要 pip 和网络
我的判断
先说结论:这个插件值得装,但不要把它当成安全审查的终点。
技术判断: 三层递进的设计是当前 AI 安全工具里最合理的架构。正则做快筛、模型做语义审查、Agent 做上下文判断------每一层弥补上一层的短板。特别是第三层的 Agent 式审查能读周围代码来判断是否误报,这个设计比纯静态分析高明。
实践判断: 对我来说最大的价值不是它能抓多少漏洞,而是它让"安全审查"这件事从"写完再检查"变成了"边写边检查"。以前用 AI 写代码,安全审查总是后置的------写完代码、提交 PR、等 Reviewer 看。现在 Claude 写完一段代码,马上就能收到安全反馈,在同一个会话里修掉。这个从"后置"到"即时"的转变,比具体能抓多少种漏洞重要得多。
坦诚补充: 我还没有在大型生产项目里用这个插件跑过完整流程。上面的判断基于官方文档、源码和 Anthropic 的内部数据。实际效果可能因代码库、语言、模型版本不同而有差异。
九. 一些值得关注的细节
- 所有计划都可用:不是 Team/Enterprise 专属,Pro 和 Individual 也能用
- 可以按层关闭 :通过环境变量单独关掉某一层,比如
ENABLE_PATTERN_RULES=0 - 完全卸载也很简单 :
/plugin uninstall security-guidance@claude-plugins-official - 日志在
~/.claude/security/log.txt:排查问题的时候先看这个 - 如果你想要硬性阻止 :得配合 Hook 的
PreToolUse事件来做,插件本身不做阻止
最后说两句
AI 写代码这件事,发展速度远超安全工具的跟进速度。现在大家都在卷模型编码能力------Aider、Cursor、Claude Code、Codex------但很少有人认真想"写出来的代码安不安全"这个问题。
Anthropic 这次做的,不是什么技术突破,而是一个很务实的工程决策:在 AI 写代码的流程里嵌入安全审查,让安全问题在产生的时刻就被发现,而不是等到 Code Review 甚至上线之后。
这不是什么"AI 替代安全工程师"的故事。它更像是------你团队里多了一个人,不写代码,专门在你写代码的时候盯着你说"嘿,这里有个 eval,你确定安全吗?"
说实话,这种搭档,我挺需要的。
参考资料
- ClaudeDevs 官方公告推文:x.com/ClaudeDevs/...
- Anthropic 内部数据推文:x.com/ClaudeDevs/...
- Security Guidance Plugin 官方文档:code.claude.com/docs/en/sec...
- 插件源码仓库:github.com/anthropics/...
- Claude Code Hooks 指南:code.claude.com/docs/en/hoo...
- Claude Code 插件市场文档:code.claude.com/docs/en/dis...
- Claude Code Code Review 文档:code.claude.com/docs/en/cod...
话题标签:#ClaudeCode #AI安全 #SecurityGuidance #Anthropic #AI编程 #VibeCoding #安全审查