目录
[三、什么是 BIO](#三、什么是 BIO)
[五、BIO 为什么性能差](#五、BIO 为什么性能差)
一、什么是流
可以理解为:数据传输的管道
文件 → JVM程序 属于 输入流
JVM程序 → 文件 属于 输出流
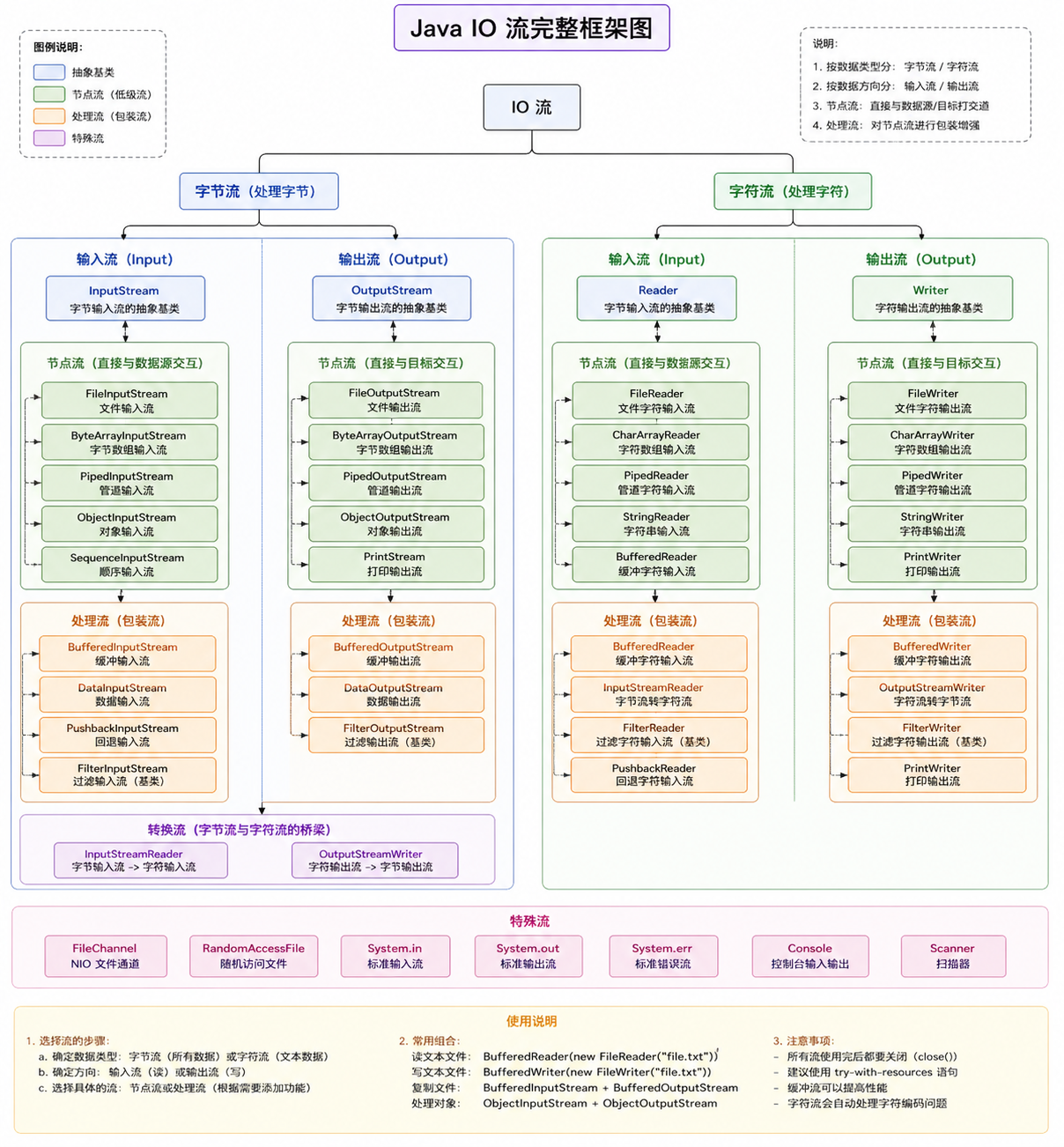
二、JavaIO流框架图
三、什么是 BIO
BIO = Blocking I/O 同步阻塞 IO
- 同步:读写操作顺序执行,做完一件才做下一件
- 阻塞:线程调用
read()/write()时,没有数据就一直卡死等待,不释放线程 - JDK1.4 之前唯一 IO 模型,传统文件 IO、老式 Socket 通信都是 BIO
- 传统网络 BIO 服务端,一个客户端连接对应一个独立线程
BIO 是最基础的 IO 模型,线程发起 IO 操作后会一直阻塞,直到读写完成才继续执行
四、BIO为什么会阻塞、阻塞发生在哪里
先看demo
java
ServerSocket serverSocket = new ServerSocket(8080);
Socket socket = serverSocket.accept();
InputStream inputStream = socket.getInputStream();
byte[] bytes = new byte[1024];
int len = inputStream.read(bytes);accept()阻塞
java
Socket socket = serverSocket.accept();作用:等待客户端连接
如果没有客户端连接:
- 当前线程会进入 WAIT 状态
- CPU 不再执行这个线程
- 直到有客户端建立 TCP 连接
这就是 阻塞等待连接
用户线程
↓
JVM
↓
操作系统 socket API
↓
内核等待客户端连接
如果连接没来:线程挂起(阻塞)
read() 阻塞
java
int len = inputStream.read(bytes);作用:从 socket 缓冲区读取数据
如果:
- 客户端已经连接
- 但是没有发送数据
那么:线程继续阻塞
因为操作系统发现:socket 接收缓冲区为空
于是:线程睡眠等待数据到来
等客户端真正发送数据后:网卡 → 内核缓冲区 → 用户缓冲区
read 才返回数据
五、BIO 为什么性能差
BIO(Blocking I/O)性能差,根本原因不是"读写慢",而是:
BIO 的并发模型成本太高
核心问题:
一个连接通常对应一个线程(One Connection One Thread)
大量线程会导致:
- 内存占用巨大
- CPU 上下文切换严重
- 线程调度开销巨大
- 大量线程处于无意义阻塞状态
就会导致系统吞吐量急剧下降
BIO 的工作模型
传统 BIO 服务端:
java
while (true) {
Socket socket = serverSocket.accept();
new Thread(() -> {
handler(socket);
}).start();
}每来一个客户端:创建一个线程
线程内部:inputStream.read(),会阻塞等待数据
BIO 性能差的核心原因
1. 大量线程创建成本高
线程不是轻量对象,每个线程都需要:
- JVM 栈内存
- 程序计数器
- 本地方法栈
- Thread 对象
- OS 内核线程资源
例如:默认线程栈:1MB
如果有10000 个连接
可能仅线程栈就:10000 × 1MB = 10GB
还不算:
- Thread 对象
- 内核资源
- JVM 元数据
所以:高并发下内存直接爆炸
2. 大量阻塞线程浪费资源
现实场景:大多数连接其实是空闲的
比如:
- 用户建立连接但不发数据
- 长连接心跳
- 慢请求
- 网络延迟
但 BIO 中:线程必须一直陪着连接
即使:99% 时间没数据,线程也不能释放
于是出现:大量线程在睡觉,但是还占用了大量的资源,导致线程资源浪费
3. CPU 上下文切换严重
线程多了以后:CPU 需要不断切换线程
什么是上下文切换?
CPU 执行线程 A:保存 A 的执行现场
切到线程 B:恢复 B 的执行现场
包括:
- 寄存器
- 程序计数器
- 栈信息
- CPU cache
4. 阻塞导致 CPU 利用率低
BIO 的问题:线程一旦 read(),没数据就挂起
于是:CPU可能空闲,线程却很多
表现为:load 很高、CPU 却不高
因为:
- 系统忙于调度线程
- 不是忙于真正计算
5. 内核态/用户态频繁切换
BIO 每次 IO:
用户态
↓
内核态
↓
阻塞等待
↓
唤醒
↓
返回用户态
频繁系统调用:
- accept
- read
- write
会产生:用户态与内核态切换成本
高并发下非常明显
连接1 → 线程1(阻塞)
连接2 → 线程2(阻塞)
连接3 → 线程3(阻塞)
连接4 → 线程4(阻塞)
...
连接10000 → 线程10000(阻塞)
问题:线程 ≈ 连接数 导致系统性能降低或宕机
六、按数据类型区分
1. 字节流(Byte Stream)
- 文件字节:
FileInputStream/FileOutputStream - 缓冲字节:
BufferedInputStream/BufferedOutputStream - 对象流:
ObjectInputStream/ObjectOutputStream
以:**字节(byte)**为单位处理数据
顶级抽象类
输入:InputStream
输出:OutputStream
可以处理所有数据:
- 图片
- 视频
- 文件
- 音频
- 文本
2. 字符流(Character Stream)
- 文件字符:
FileReader/FileWriter - 缓冲字符:
BufferedReader/BufferedWriter(常用,带 readLine) - 打印流:
PrintWriter(自动换行、自动刷新) - 转换流:
InputStreamReader/OutputStreamWriter
以:**字符(char)**为单位处理
本质:字节 + 编码
顶级抽象类
输入:Reader
输出:Writer
专门处理文本
例如:
- txt
- json
- xml
- csv
为什么会有字符流?
因为:一个中文 ≠ 一个字节
例如 UTF-8:
| 字符 | 字节数 |
|---|---|
| A | 1 |
| 中 | 3 |
如果直接按字节读取可能乱码
所以:字符流自动处理编码与解码
七、按方向
输入流
由外部读取到Java内存中
输出流
由java内存中输出到别的地方,例如控制台、本地文件
八、核心流讲解
FileInputStream / FileOutputStream(基础字节流)
特点:一个字节一个字节读写,速度慢,无缓冲。 示例:复制文件
java
// 读
FileInputStream fis = new FileInputStream("a.jpg");
// 写
FileOutputStream fos = new FileOutputStream("b.jpg");
byte[] buf = new byte[1024];
int len;
while ((len = fis.read(buf)) != -1) {
fos.write(buf, 0, len);
}
fis.close();
fos.close();FileReader / FileWriter(基础字符流)
只适合文本,不能处理图片 / 视频 ,默认跟随系统编码,不推荐使用 FileReader/FileWriter,因为无法指定编码,极易乱码
缓冲流 Buffered
原理:自带缓冲区,先读到内存缓冲区,批量读写,速度大幅提升
- 字节缓冲:
BufferedInputStream/BufferedOutputStream - 字符缓冲:
BufferedReader(readLine()读一行)/BufferedWriter
示例:BufferedReader 读文本
java
BufferedReader br = new BufferedReader(new FileReader("test.txt"));
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
br.close();转换流
FileReader 不能指定编码,必须用转换流:
InputStreamReader(字节流, "UTF-8")字节 → 字符,指定编码OutputStreamWriter(字节流, "UTF-8")字符 → 字节,指定编码
java
BufferedReader br = new BufferedReader(
new InputStreamReader(new FileInputStream("test.txt"),"UTF-8")
);九、使用注意
- 字节流万能,字符流只文本
- 基础流慢,缓冲流最快
- 要指定编码不乱码 → 用转换流
- 读写对象 → 对象流 + 序列化
- 用完必须 close(),释放资源(try‑with‑resources 自动关闭)
优雅关闭资源try‑with‑resources
java
try (BufferedReader br = new BufferedReader(new FileReader("a.txt"))) {
String s = br.readLine();
} catch (IOException e) {
e.printStackTrace();
}