本次实验把 Oracle 容器作为源端,通过达梦 DTS 将 Oracle 侧对象迁移到达梦数据库。实验素材来自已解压的 metadata_only.epidm.epi.tar,其中包含两个 Oracle Data Pump 导出文件:
metadata_only.epidm.epi/EPI.dmpmetadata_only.epidm.epi/EPIDM.dmp
导出日志中可以看到参数 content=metadata_only,说明该 dump 只包含用户、表、索引、视图、过程等元数据信息,不包含表内业务数据。因此本实验更适合验证 Oracle 结构导入和 DTS 结构迁移流程;如果需要验证真实数据迁移,还需要准备包含数据的 full 或 data_only 类型 dump。
一、实验环境
| 项目 | 配置 |
|---|---|
| 容器平台 | Docker Desktop + WSL2 |
| Oracle 容器名 | oracle23free |
| Oracle 镜像 | gvenzl/oracle-free:23-slim |
| Oracle 端口 | 1521 |
| Oracle 服务名 | FREEPDB1 |
| Oracle 管理用户 | SYSTEM |
| 导入文件 | EPI.dmp、EPIDM.dmp |
| 源 schema | EPI、EPIDM |
| 目标端 | 达梦数据库 |
| 迁移工具 | 达梦 DTS |
二、实验目标
- 将
EPI.dmp和EPIDM.dmp导入 Oracle 23 Free 容器。 - 在 Oracle 中确认 schema、表、视图、存储过程等对象是否生成。
- 使用达梦 DTS 连接 Oracle 源端,将对象迁移到达梦目标库。
- 总结迁移中需要注意的字符集、CLOB、metadata_only dump 等问题。
三、导入文件准备
在 WSL 终端中,将本地解压出来的 dump 文件复制到 Oracle 容器内:
bash
docker exec oracle23free mkdir -p /tmp/oracle_imp
docker cp "/mnt/c/Users/Berndan Hu/Desktop/毕设/归档/打印版(1)/metadata_only.epidm.epi/EPI.dmp" \
oracle23free:/tmp/oracle_imp/EPI.dmp
docker cp "/mnt/c/Users/Berndan Hu/Desktop/毕设/归档/打印版(1)/metadata_only.epidm.epi/EPIDM.dmp" \
oracle23free:/tmp/oracle_imp/EPIDM.dmp
docker exec oracle23free chmod -R 777 /tmp/oracle_imp这里使用 /tmp/oracle_imp 作为 Oracle Data Pump 的导入目录。路径中包含空格和中文时,WSL 下需要用引号包住完整路径。
四、创建 Oracle Data Pump 目录对象
进入 Oracle:
bash
docker exec -it oracle23free sqlplus system/Oracle_123456@FREEPDB1创建 Data Pump 目录对象:
sql
CREATE OR REPLACE DIRECTORY IMP AS '/tmp/oracle_imp';
GRANT READ, WRITE ON DIRECTORY IMP TO SYSTEM;
SELECT directory_name, directory_path
FROM dba_directories
WHERE directory_name = 'IMP';如果查询结果中能看到 /tmp/oracle_imp,说明目录对象已经创建成功。
五、导入 EPI 和 EPIDM
impdp 是操作系统命令,不是 SQL 命令。如果当前停在 SQL> 提示符下,需要先退出 SQL*Plus:
sql
EXIT;回到 WSL 终端后,再执行 Data Pump 导入。下面两条命令会把两个 dump 文件中包含的 schema 元数据全部导入到 Oracle 容器中。
1. 先创建目标 schema 用户
如果直接导入时出现下面的错误:
text
ORA-31625: Schema EPIDM is needed to import this object, but is unaccessible
ORA-01435: user does not exist
ORA-23306: schema EPIDM does not exist说明 dump 中的用户对象没有在当前 Oracle 23 Free 环境中成功创建。可以先手动创建 EPI 和 EPIDM 用户,再导入 schema 下的其他对象。
进入 Oracle:
bash
docker exec -it oracle23free sqlplus system/Oracle_123456@FREEPDB1执行:
sql
CREATE USER EPI IDENTIFIED BY EPI
DEFAULT TABLESPACE USERS
TEMPORARY TABLESPACE TEMP
QUOTA UNLIMITED ON USERS;
CREATE USER EPIDM IDENTIFIED BY EPIDM
DEFAULT TABLESPACE USERS
TEMPORARY TABLESPACE TEMP
QUOTA UNLIMITED ON USERS;
GRANT CONNECT, RESOURCE, CREATE VIEW, CREATE PROCEDURE, CREATE SEQUENCE,
CREATE TYPE, CREATE TRIGGER, CREATE SYNONYM, CREATE DATABASE LINK
TO EPI;
GRANT CONNECT, RESOURCE, CREATE VIEW, CREATE PROCEDURE, CREATE SEQUENCE,
CREATE TYPE, CREATE TRIGGER, CREATE SYNONYM, CREATE DATABASE LINK
TO EPIDM;
EXIT;如果用户已经存在,CREATE USER 会提示用户已存在,这时不用重复创建,确认权限授予后继续导入即可。
2. 导入 dump 中的元数据对象
导入 EPI.dmp:
bash
docker exec -it oracle23free impdp system/Oracle_123456@FREEPDB1 \
directory=IMP \
dumpfile=EPI.dmp \
logfile=impEPI.log \
schemas=EPI \
content=metadata_only \
transform=segment_attributes:n \
exclude=user,statistics导入 EPIDM.dmp:
bash
docker exec -it oracle23free impdp system/Oracle_123456@FREEPDB1 \
directory=IMP \
dumpfile=EPIDM.dmp \
logfile=impEPIDM.log \
schemas=EPIDM \
content=metadata_only \
transform=segment_attributes:n \
exclude=user,statistics这里的"全部导入"指导入 dump 文件中包含的全部业务元数据对象,包括表、索引、视图、序列、过程、函数、触发器等。用户对象已在前一步手动创建,因此导入时使用 exclude=user 跳过 dump 中的用户创建语句。由于原始导出文件本身是 content=metadata_only,即使导入命令完整执行,也不会产生业务数据行。
content=metadata_only 与导出文件类型保持一致;transform=segment_attributes:n 用于忽略原库中的部分存储属性,减少从 Oracle 11g 导入到 Oracle 23 Free 时因为表空间、存储参数差异导致的报错;exclude=user,statistics 用于跳过用户创建和旧统计信息,后续可以在目标库中重新收集统计信息。
如果误在 SQL> 中输入了 docker exec 或 impdp 命令,并出现 SP2-0734,说明 SQL*Plus 没有识别该命令,实际没有执行导入,也不需要回滚。直接输入 EXIT; 退出后,在 WSL 终端重新执行上述命令即可。
如果 impdp 已经执行但最后查询 dba_tables、dba_objects 时 EPI 和 EPIDM 都没有对象,说明没有形成有效导入结果,也不需要回退。按上面的步骤先创建用户,再重跑导入即可。
如果导入过程中出现大量旧环境相关错误,可以使用更适合迁移实验的精简导入参数:
bash
docker exec -it oracle23free impdp system/Oracle_123456@FREEPDB1 \
directory=IMP \
dumpfile=EPI.dmp \
logfile=impEPI_clean.log \
schemas=EPI \
content=metadata_only \
transform=segment_attributes:n \
remap_tablespace=EPI_TS:USERS \
remap_tablespace=EPI_INDEX:USERS \
exclude=user,role_grant,default_role,tablespace_quota,object_grant,job,statistics
bash
docker exec -it oracle23free impdp system/Oracle_123456@FREEPDB1 \
directory=IMP \
dumpfile=EPIDM.dmp \
logfile=impEPIDM_clean.log \
schemas=EPIDM \
content=metadata_only \
transform=segment_attributes:n \
remap_tablespace=EPIDM_TS:USERS \
remap_tablespace=EPIDM_INDEX:USERS \
exclude=user,role_grant,default_role,tablespace_quota,object_grant,job,statistics这版命令会保留表、索引、视图、序列、过程、函数、触发器等主体对象,跳过旧环境中的用户创建、角色授权、默认角色、表空间配额、对象授权、定时任务和旧统计信息。对本次 DTS 迁移实验来说,这些被跳过的对象不是核心迁移对象。
六、导入结果检查
进入 Oracle:
bash
docker exec -it oracle23free sqlplus system/Oracle_123456@FREEPDB1检查 schema 下表数量:
sql
SELECT owner, COUNT(*) AS table_count
FROM dba_tables
WHERE owner IN ('EPI', 'EPIDM')
GROUP BY owner
ORDER BY owner;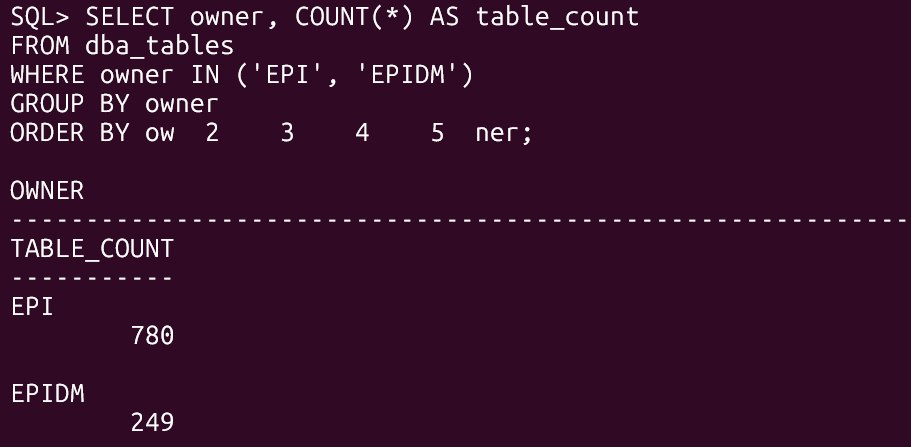
检查对象类型分布:
sql
SELECT owner, object_type, COUNT(*) AS object_count
FROM dba_objects
WHERE owner IN ('EPI', 'EPIDM')
GROUP BY owner, object_type
ORDER BY owner, object_type;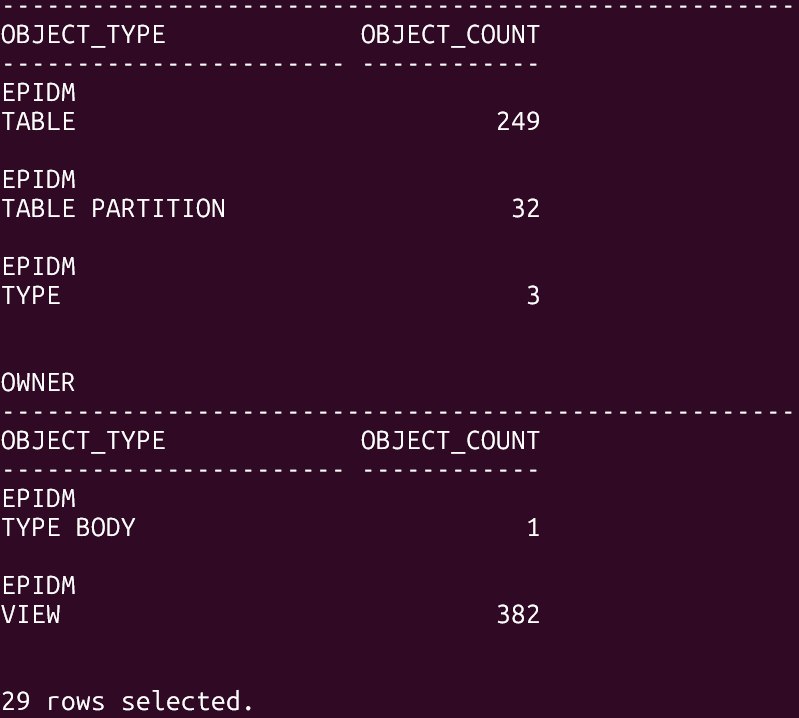
如果需要查看具体表名:
sql
SELECT owner, table_name
FROM dba_tables
WHERE owner IN ('EPI', 'EPIDM')
ORDER BY owner, table_name;
由于 dump 是 metadata_only,表结构可以导入,但表内数据通常为空。可以选择一张表验证:
sql
SELECT COUNT(*) FROM EPI.表名;如果返回 0,这与 metadata_only 导出类型一致,不代表导入失败。
七、达梦 DTS 迁移配置
本节参照达梦官方 Oracle 迁移到 DM8 常见问题 进行配置,核心思路是把对象迁移拆开做:先迁移表定义,再迁移表数据,最后补约束和索引。官方文档中也提到迁移前需要确认版本、JDK、迁移顺序,并建议大表、大字段对象单独迁移;对于 Oracle 兼容性,还可将达梦静态参数 COMPATIBLE_MODE 调整为 2,重启数据库后生效。
本次实验在目标达梦库中增加了 Oracle 兼容模式参数调整:
sql
SP_SET_PARA_VALUE(2, 'COMPATIBLE_MODE', 2);COMPATIBLE_MODE 是静态参数,修改后需要重启数据库。该参数只能提高部分 Oracle 语法兼容性,不能保证视图、触发器、函数、包等复杂对象全部自动转换成功。
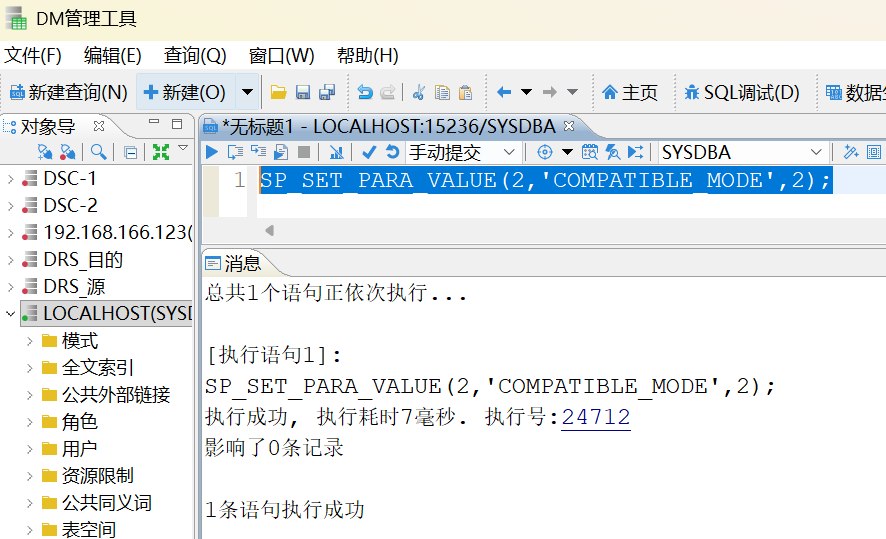
创建 DTS 迁移任务时,源端选择 Oracle,目标端选择达梦数据库。Oracle 源端使用前面 Docker 容器中导入好的 FREEPDB1 服务,迁移对象只选择业务 schema EPI 和 EPIDM,不迁移 Oracle 系统用户。
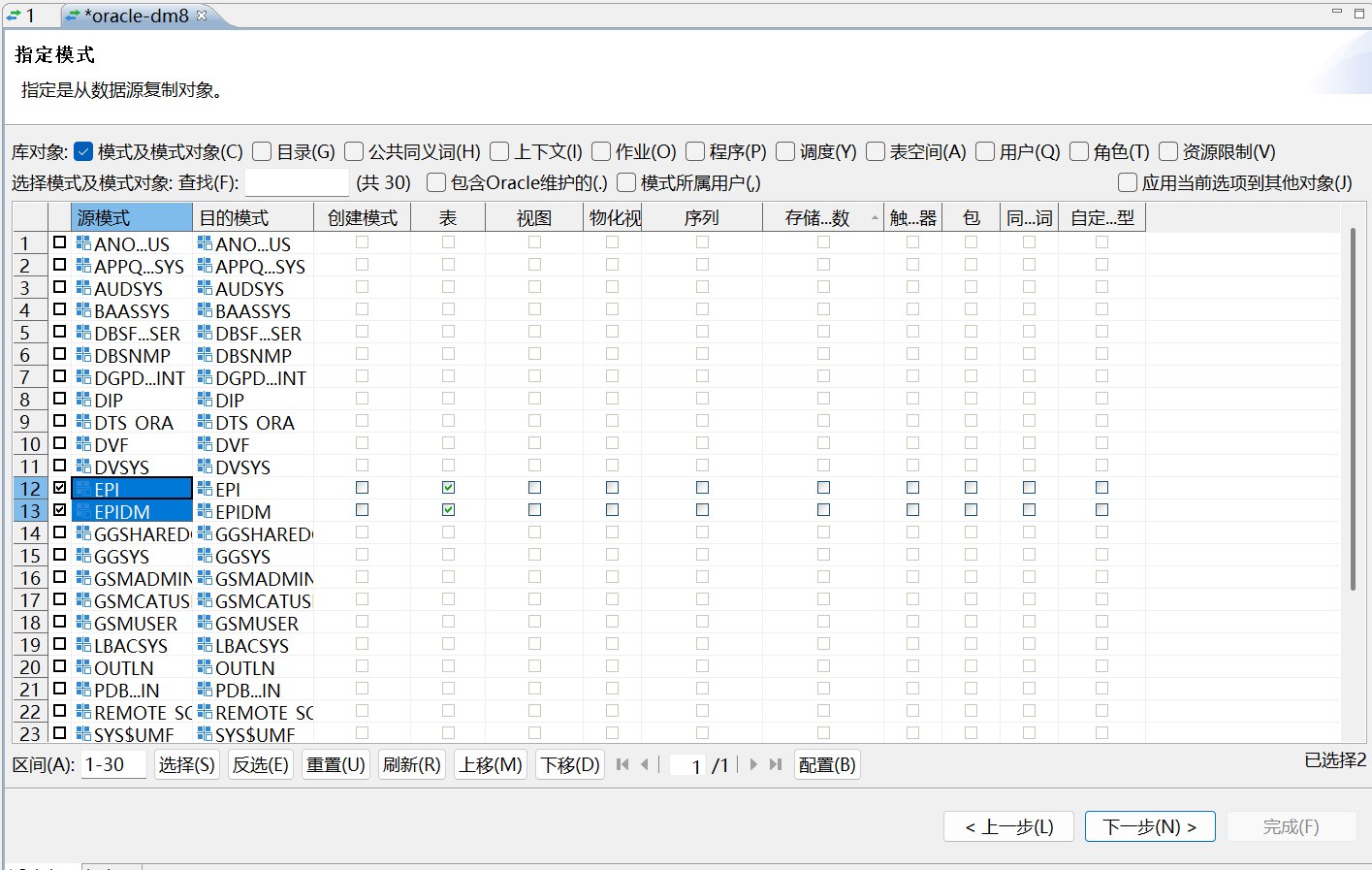
源端和目标端连接成功后,进入对象选择页面。这里不要选择全部 schema,也不要勾选 Oracle 维护对象,只保留 EPI 和 EPIDM。系统 schema 中存在大量 Oracle 内部对象,迁移到达梦没有意义,还会增加无关报错。
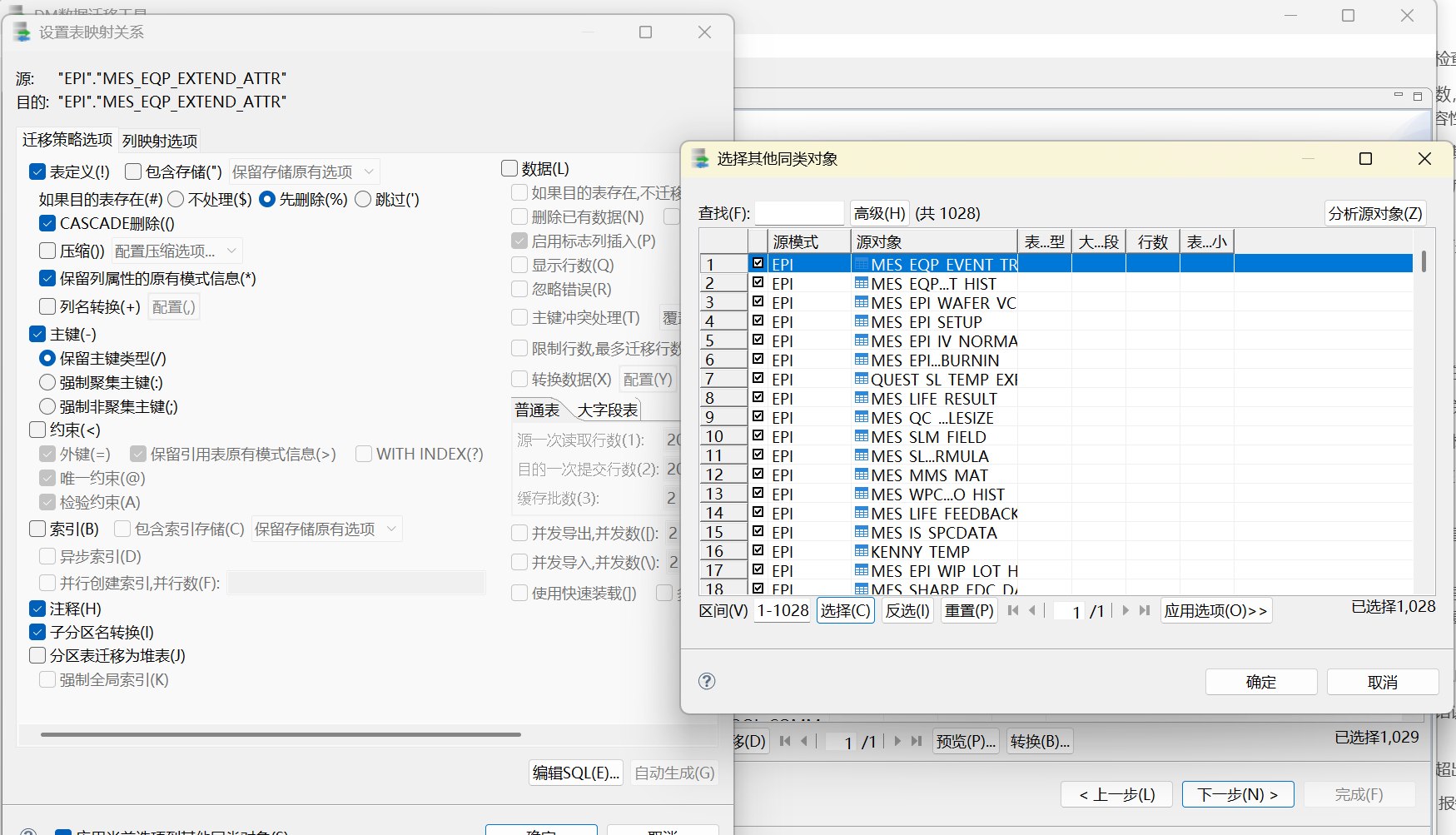
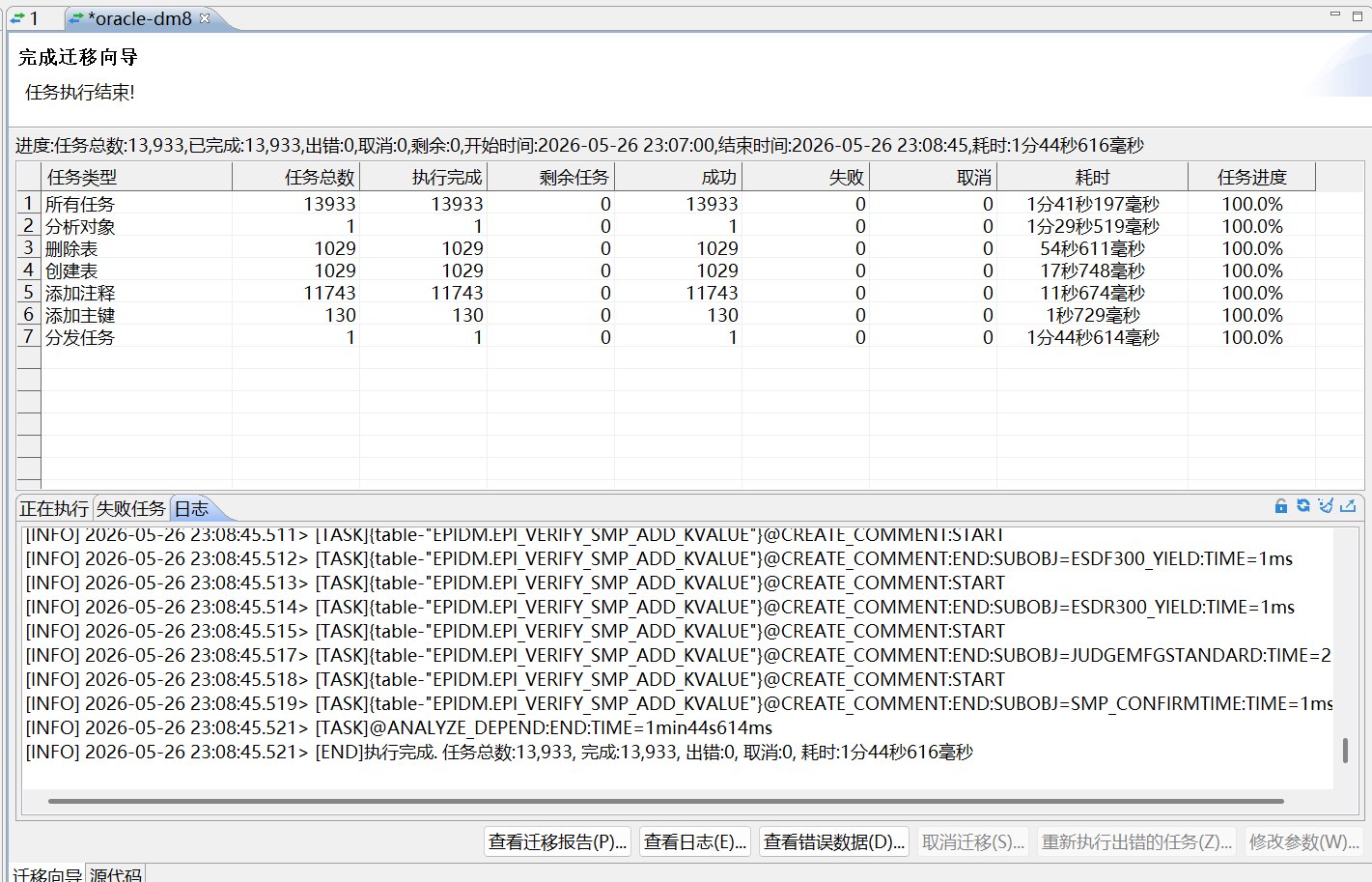
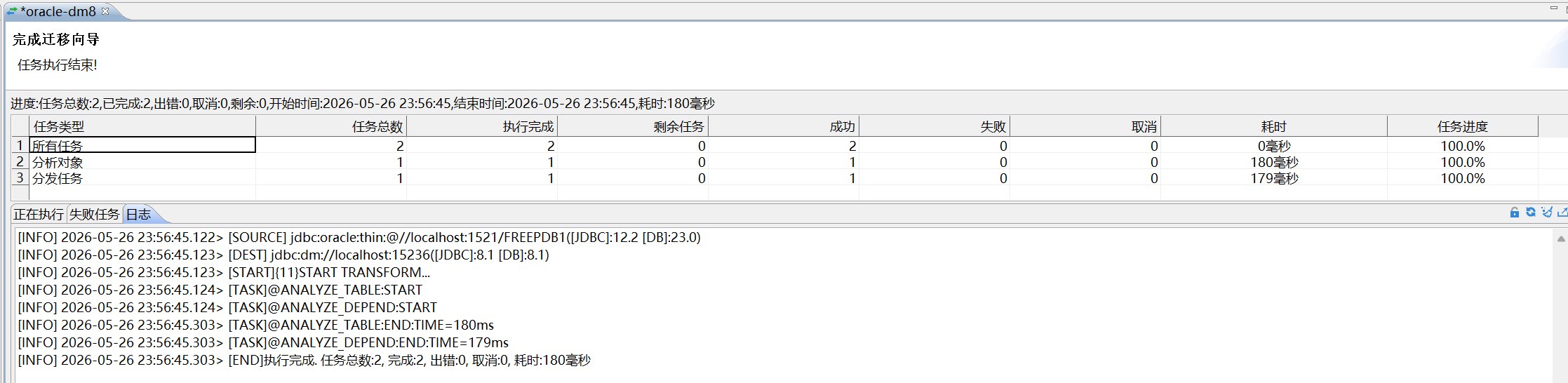
本次迁移最终按以下步骤拆分执行:
| 步骤 | 迁移内容 | 说明 |
|---|---|---|
| 第一步 | 表定义 | 只创建表结构,不迁移数据、约束、索引 |
| 第二步 | 表数据 | 只迁移数据,目标表沿用第一步创建的结构 |
| 第三步 | 约束和索引 | 补主键、唯一约束、外键和普通索引 |
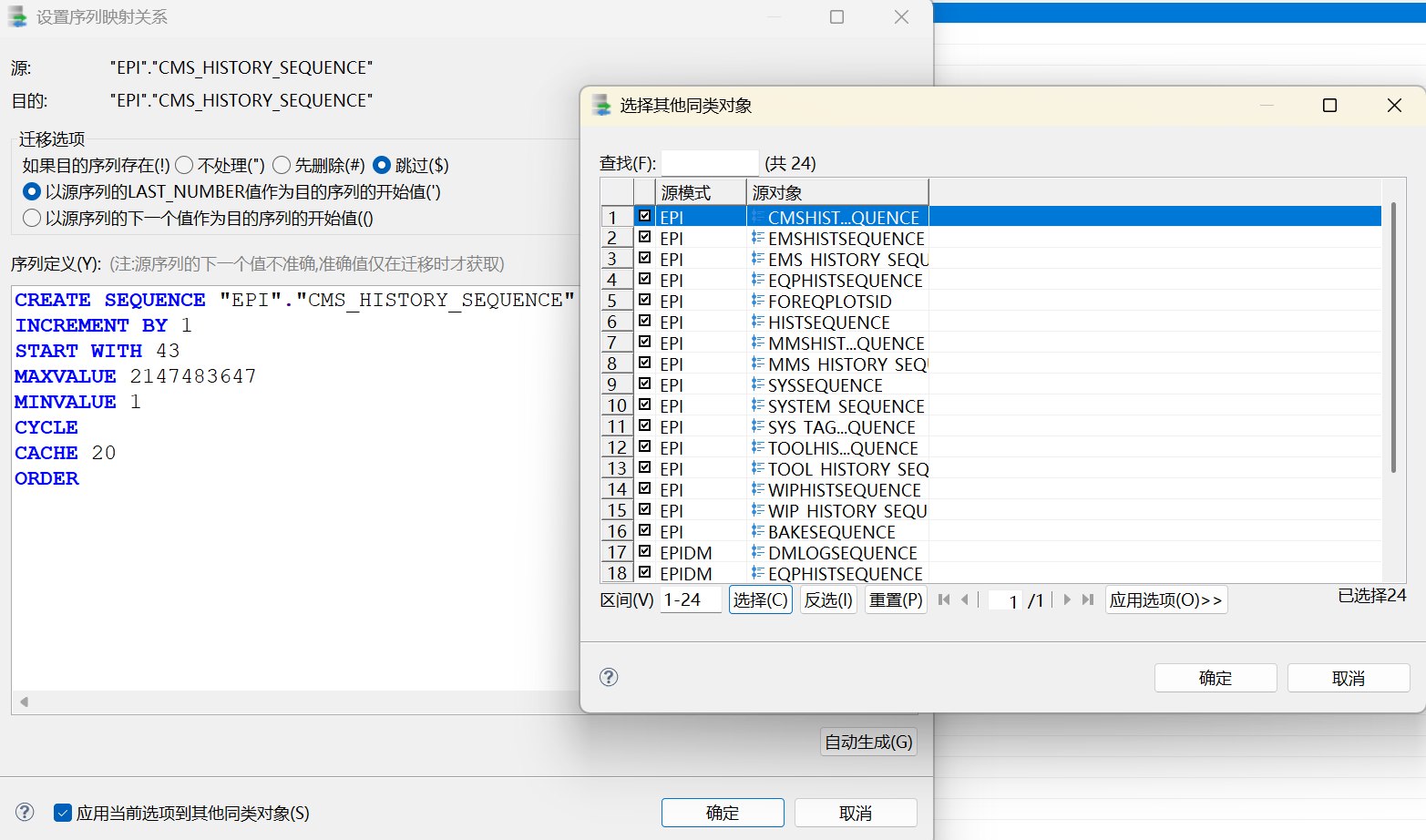
| 第四步 | 序列准备尝试 | 该步实际还勾选了表,导致转换界面仍显示表级规则 |
| 第五步 | 序列 | 只勾选序列,作为第四步的修正执行 |
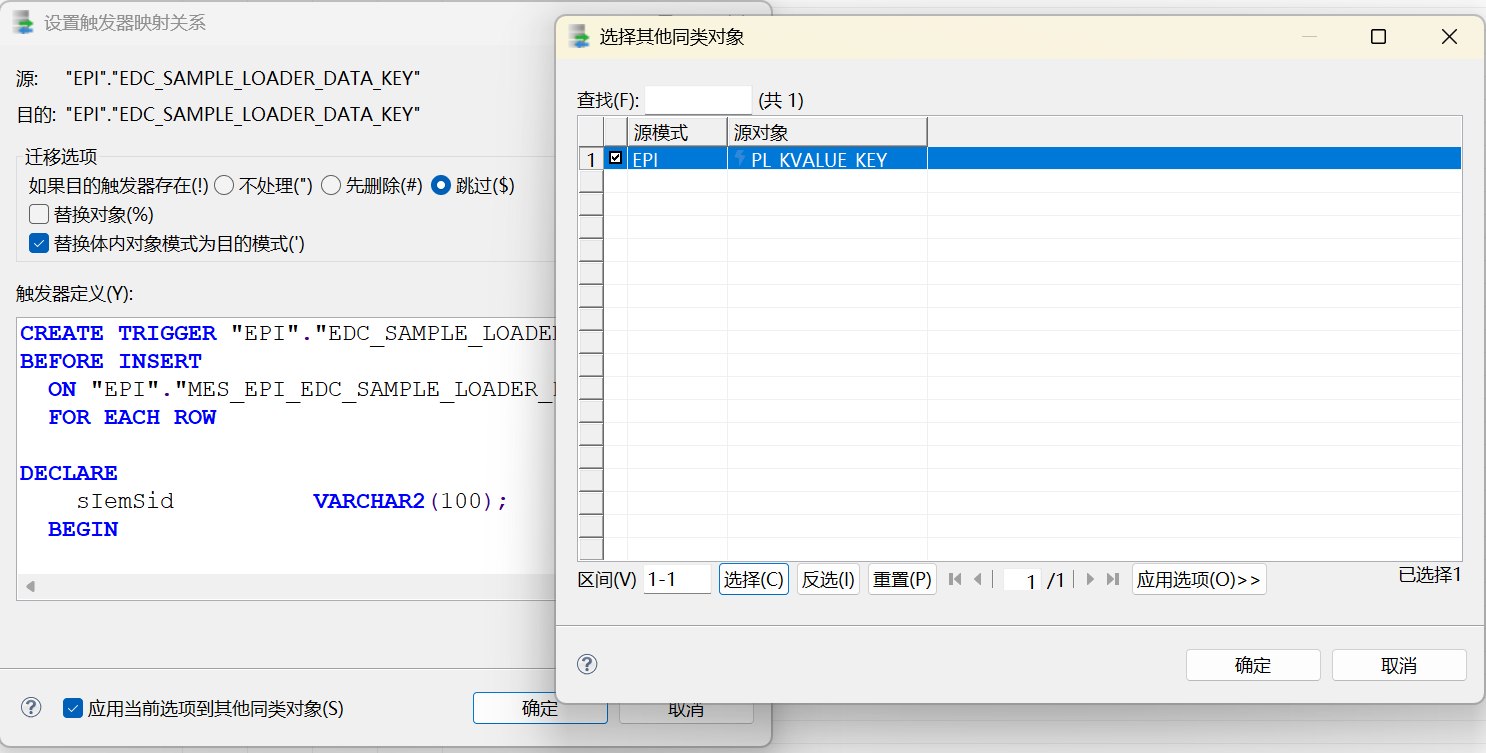
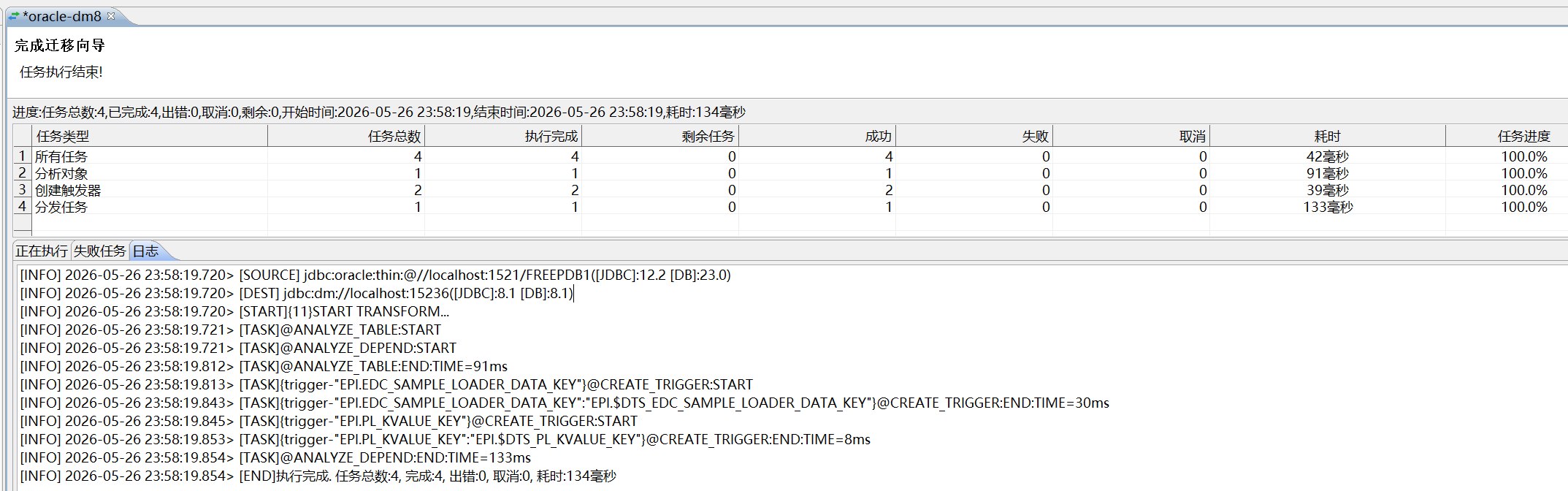
| 第六步 | 触发器 | 只迁移触发器,依赖前面已存在的表 |
| 第七步 | 普通视图 | 只迁移普通视图,不同时迁移物化视图 |
前三步与官方 FAQ 中"表定义、数据、约束索引分步迁移"的做法一致。后续的序列、触发器、普通视图单独迁移,是为了避免复杂对象和表对象混在一起,导致错误定位困难。
从原理上看,DTS 不是物理备份还原,也不是直接复制 Oracle 数据文件,而是通过数据库连接在源端读取元数据和数据,再在目标端生成并执行对应的 DDL、DML。一次迁移任务大致会经历以下过程:
- 读取源端数据字典,分析 schema、表、字段、数据类型、主键、索引、视图、触发器等对象定义。
- 按内置转换规则把 Oracle 对象转换成达梦对象,例如数据类型、字段长度、默认值、约束、索引和部分 SQL 语法。
- 在目标达梦库执行建表、建索引、加约束、创建视图等 DDL。
- 如果勾选数据迁移,则从 Oracle 分批查询数据,再通过批量插入写入达梦,并按设置的批量行数提交。
- 对视图、触发器、过程等对象,DTS 会先分析依赖和列信息。例如迁移视图前,日志中可以看到它会执行类似
SELECT * FROM "EPIDM"."DMV_LOT_CREATE_INFO" WHERE 1=2的 SQL 来获取视图列结构。
推荐按"表定义 -> 数据 -> 约束索引 -> 序列 -> 触发器 -> 视图 -> 物化视图"的顺序迁移,本质上是按照对象依赖关系从底层到上层推进。表是最底层对象,数据依赖表,主键、外键、索引依赖表和数据,触发器依赖表和序列,视图依赖表、函数或其他视图,物化视图又依赖普通视图、基表和刷新机制。
分步迁移还有两个好处。第一,性能更稳定:先导入数据再建索引、加约束,可以减少导入过程中不断维护索引和检查约束的开销。第二,错误更容易定位:如果把表、数据、索引、触发器、视图一次性全选,日志里会混在一起,难以判断是表结构问题、数据问题,还是复杂对象兼容性问题。
第一步只迁移表定义。转换配置中保留表定义相关选项,暂不迁移数据、主键、外键、索引等对象。这样可以先保证目标端表结构落地,避免数据迁移时目标表不存在。
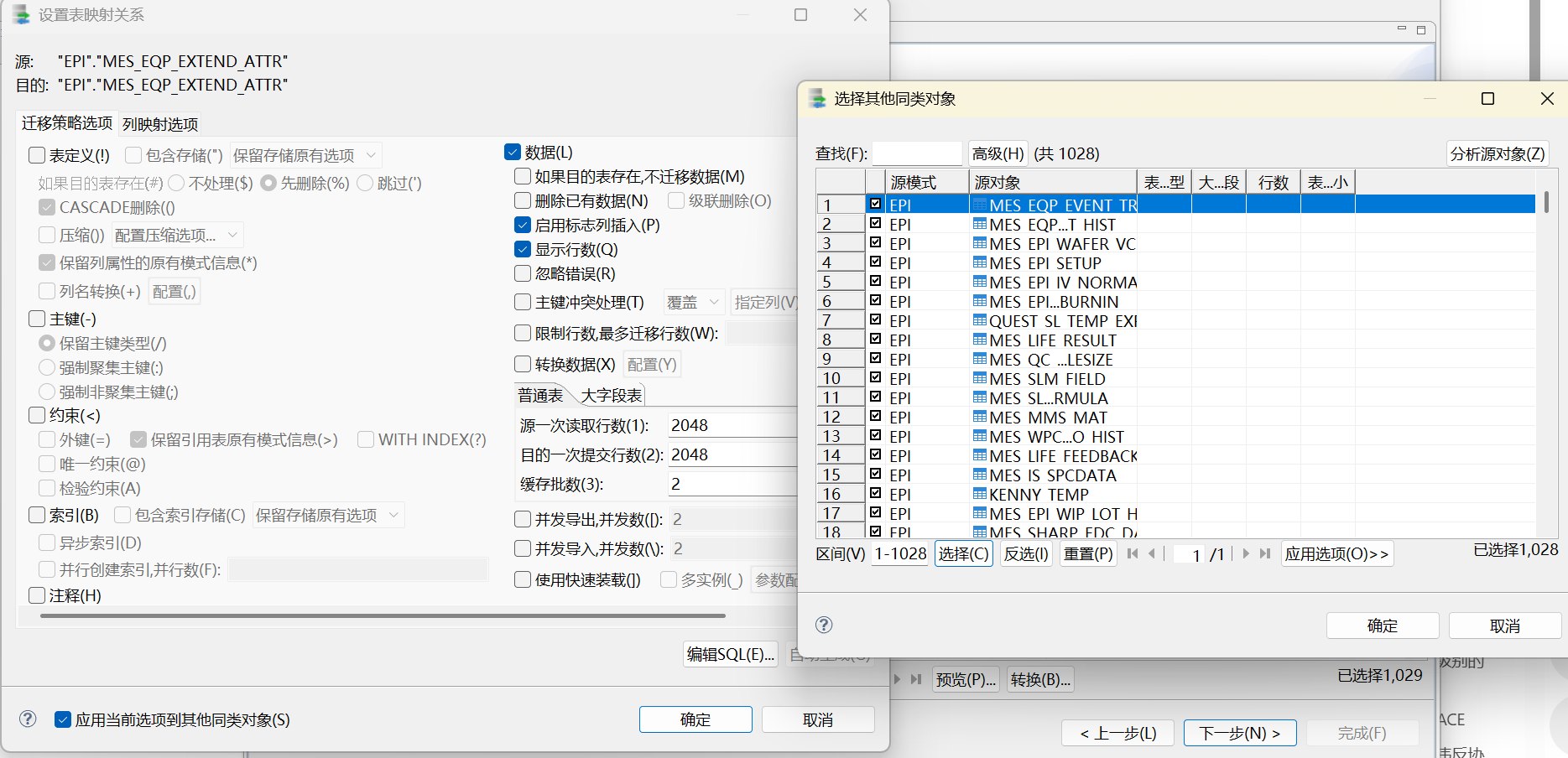
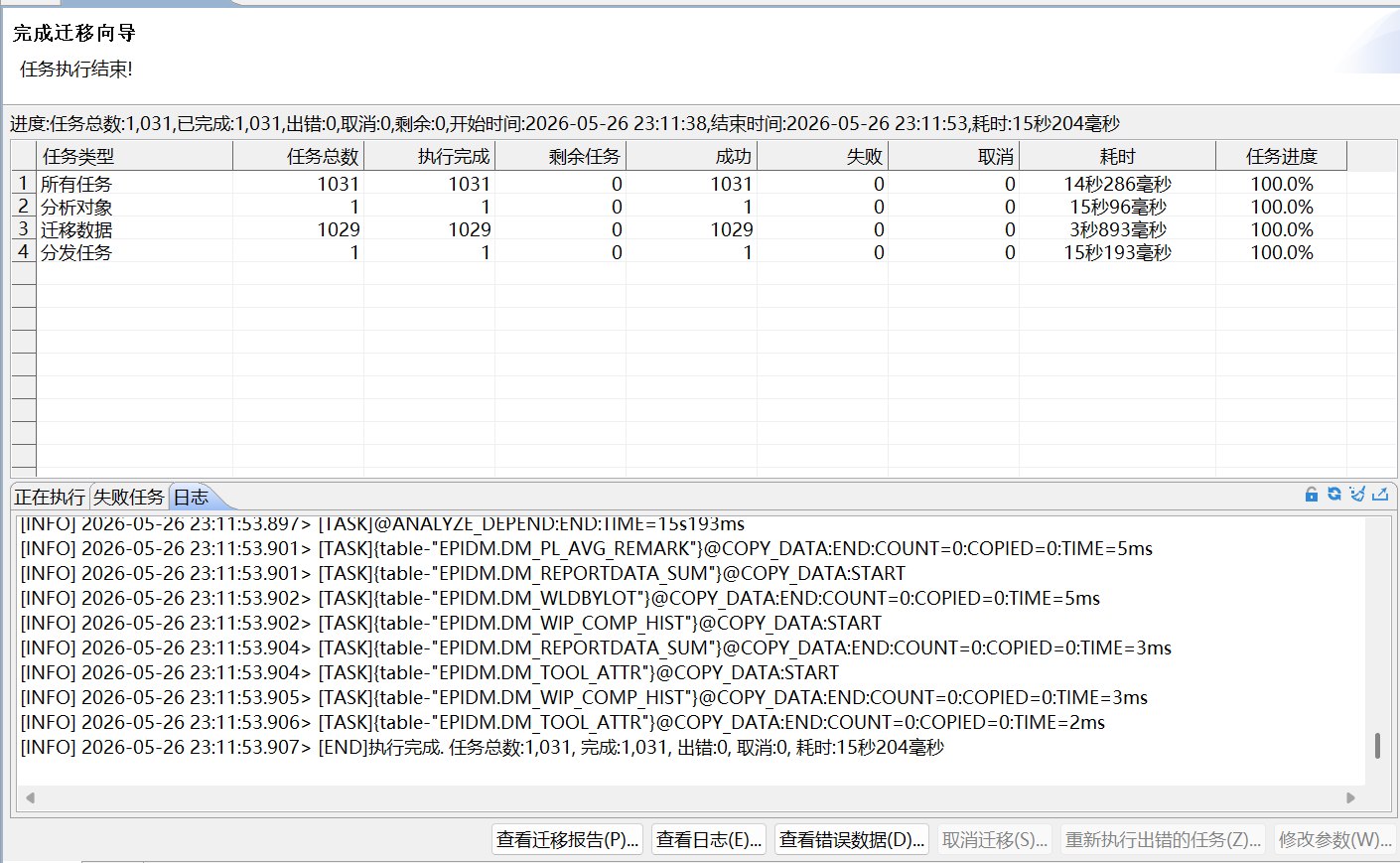
第二步只迁移数据。由于本次 Oracle dump 本身是 metadata_only,源端大部分业务表没有真实数据,因此数据迁移行数为空或很少是正常现象,不代表表结构迁移失败。
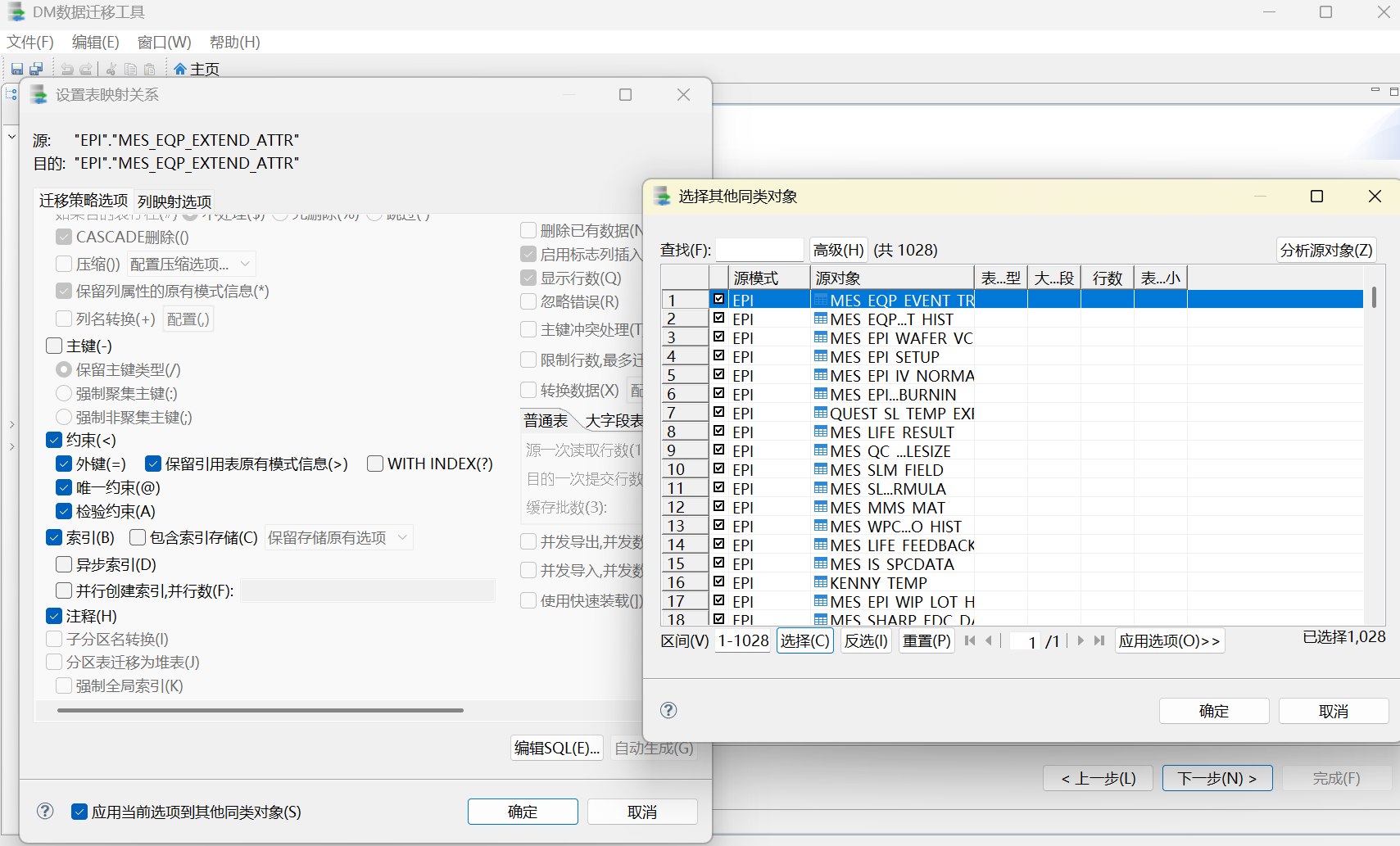
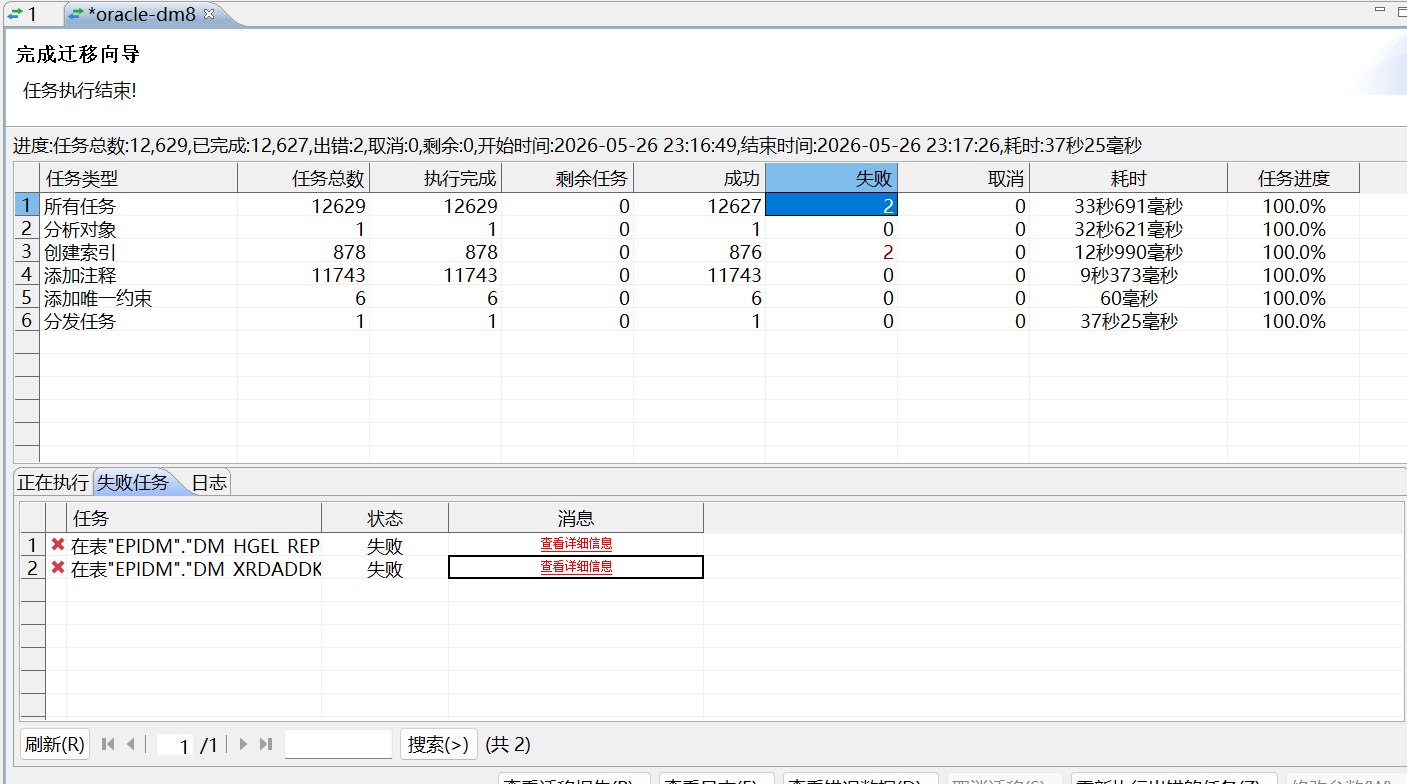
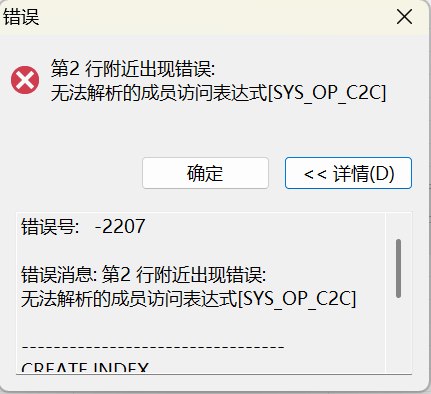
第三步迁移约束和索引。这里主要补充第一步没有迁移的主键、唯一约束、外键、校验约束和索引。第三步出现的两条失败 SQL 与 Oracle 内部函数索引有关:
sql
CREATE INDEX "INDEX256247779694600"
ON "EPIDM"."DM_HGEL_REPORT"(SYS_OP_C2C("LOT"));
CREATE INDEX "INDEX256254113886900"
ON "EPIDM"."DM_XRDADDKVALUEVIEW_TEST"(SYS_OP_C2C("COMPONENTID"));SYS_OP_C2C 是 Oracle 内部转换函数,达梦无法直接解析这类函数索引。因此这两条索引可以在本次迁移中忽略,后续如果业务查询确实需要,再在达梦侧按普通列索引重新创建。
第四步原本是准备继续迁移后续对象,但实际配置时仍勾选了表对象,所以进入"转换"后看到的仍然是表映射关系和表级迁移策略。这也是第四步报错集中在主键、唯一约束、索引重复创建上的原因。
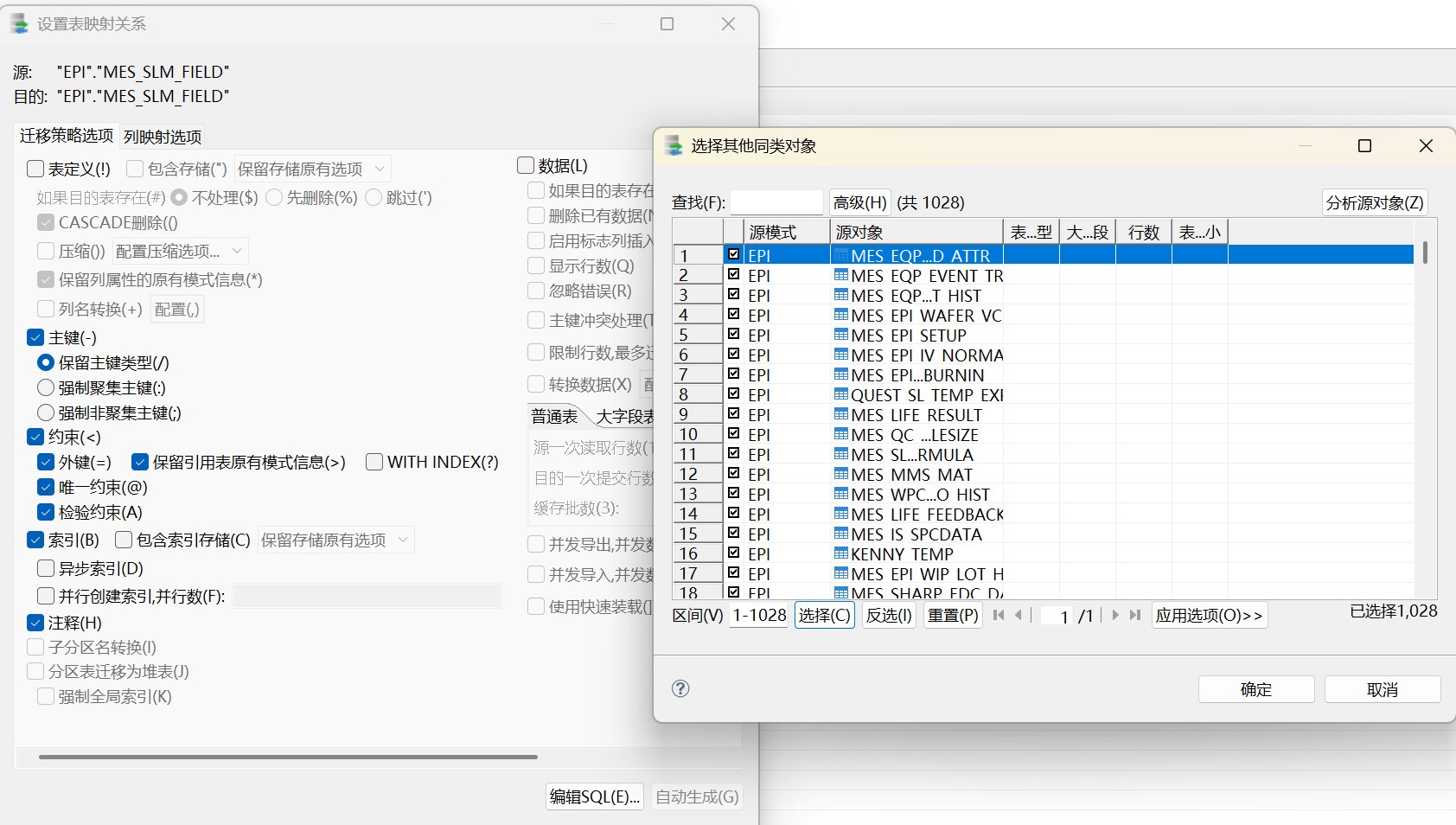
第四步和第五步准确来说属于同一类补充对象迁移。第五步只勾选序列,不再勾选表对象,配置才是干净的序列迁移。序列不依赖表数据,但应用、触发器或过程可能会引用序列,因此放在触发器之前迁移更便于后续对象解析。
第六步迁移触发器。触发器通常依赖表、列、序列或过程,因此放在表结构、数据、约束索引和序列之后执行。本次配置只选择触发器对象,不再重复勾选表对象,避免 DTS 再次尝试创建表级约束或索引。
第七步迁移普通视图。这里仅勾选"视图",不同时勾选"物化视图"。普通视图本身不保存数据,只保存查询定义;如果源端 Oracle 视图已经无效,或者视图 SQL 中包含达梦不能直接兼容的 Oracle 写法,就会在这一阶段集中报错。
普通视图迁移完成后,再根据需要单独迁移物化视图。物化视图比普通视图依赖更重,通常依赖基表、普通视图和刷新机制,因此不建议和普通视图混在同一个任务中迁移。

Oracle 源端连接信息:
text
数据库类型:Oracle
主机:localhost
端口:1521
服务名:FREEPDB1
用户名:SYSTEM
密码:Oracle_123456
迁移 schema:EPI、EPIDM达梦目标端连接信息根据本机达梦实例填写,常见端口为:
text
主机:localhost
端口:5236
用户名:SYSDBA
密码:SYSDBA 或实际密码DTS 任务建议:
- 如果只是验证结构迁移,也不建议一次性勾选所有对象,应按表定义、数据、约束索引、序列、触发器、视图等顺序拆分执行。
- 如果后续拿到包含数据的 dump,先在 Oracle 中完成数据导入,再用 DTS 迁移数据。
- 迁移前确认目标端是否已有同名对象,避免因为对象已存在导致重复创建失败。
- 如果目标端要保留原有结构,迁移策略应选择只迁数据或跳过已存在对象。
八、常见问题记录
1. dump 导入后没有数据
本实验中的导出日志显示:
text
content=metadata_only这表示 dump 只包含元数据,不包含业务数据。导入后有表结构但没有表数据是正常现象。
2. impdp 提示目录或文件不存在
优先检查三点:
bash
docker exec oracle23free ls -lh /tmp/oracle_imp
sql
SELECT directory_name, directory_path
FROM dba_directories
WHERE directory_name = 'IMP';还要确认 impdp 命令中的 dumpfile 名称与容器内文件名完全一致。
3. impdp 出现大量 ORA-39083
ORA-39083 表示某一类对象创建失败,需要结合后面的具体错误判断影响范围。
常见情况:
ORA-01919: Role ... does not exist:源库是 Oracle 11g 企业版,导入到 Oracle 23 Free 后,部分 Java、OLAP、APEX、Spatial 等旧角色不存在。对表结构迁移影响不大。ORA-01917: user or role 'EPISELECT' does not exist:源库里有给EPISELECT账号或角色的授权,当前环境没有创建该账号。DTS 使用SYSTEM读取源 schema 时可以先忽略。ORA-00959: tablespace ... does not exist:源库表空间如EPI_TS、EPI_INDEX在容器库里不存在。可通过remap_tablespace=原表空间:USERS处理。ORA-39082: created with compilation warnings:函数、视图或包已创建,但编译有警告或依赖对象缺失。迁移表结构时可以先记录,后续再单独处理。
判断是否需要回退的依据不是错误数量,而是主体对象是否已经导入。先执行第六节的对象数量检查,如果 EPI、EPIDM 下已经有表、序列、过程等对象,通常可以继续做 DTS 迁移验证。
4. 同一个 schema 不要同时跑多个 impdp
如果一个 impdp 任务还在执行,又新开窗口对同一个 dump、同一个 schema 再跑一次导入,后启动的任务通常会出现:
text
ORA-39151: Table "EPIDM"."表名" exists. All dependent metadata and data will be skipped due to table_exists_action of skip
ORA-31684: Object type ... already exists这表示前一个任务已经创建了部分对象,后一个任务发现对象已存在,于是快速跳过。后一个任务跑得快,不代表导入更完整。
出现这种情况时,不要继续叠加第三次导入。应先让正在执行的旧任务完成,或者在旧任务的 Import> 提示符中执行:
text
STATUS确认进度。如果只需要表结构、不需要视图和包体,可以在 Import> 中停止旧任务:
text
STOP_JOB=IMMEDIATE停止后先做对象数量检查,再决定是否需要清理 schema 后重导。
本次实验中,旧的 EPIDM 导入任务最终完成,日志显示:
text
Job "SYSTEM"."SYS_IMPORT_SCHEMA_01" completed with 141 error(s)
elapsed 0 00:33:20剩余错误主要集中在 VIEW 创建后的编译警告,例如:
text
ORA-39082: Object type VIEW:"EPIDM"."..." created with compilation warnings这类信息表示视图对象已经创建,但由于依赖对象、DBLINK、函数、包或旧库环境差异,当前无法完全编译通过。对本次 Oracle 到达梦 DTS 迁移实验而言,只要表、序列、约束等主体对象已经存在,就可以继续进行 DTS 迁移验证。
5. Oracle 连接失败
先确认容器运行状态:
bash
docker ps
docker logs -f oracle23free如果 Oracle 尚未初始化完成,需要等待日志出现数据库 ready 相关信息后再连接。
6. 中文或 CLOB 出现问号
需要先判断源端数据是否已经损坏。Oracle 端可检查字符集:
sql
SELECT parameter, value
FROM nls_database_parameters
WHERE parameter IN ('NLS_CHARACTERSET', 'NLS_NCHAR_CHARACTERSET');
SELECT USERENV('LANGUAGE') FROM dual;正常应优先使用 AL32UTF8。如果源端查询结果中已经出现 ?,说明迁移前数据已经被写坏,DTS 只能迁移当前实际内容。
九、实验结论
本次实验的关键点在于区分 Oracle Data Pump 文件的内容类型。metadata_only dump 可以用于恢复 Oracle schema 结构,再通过达梦 DTS 验证从 Oracle 到达梦的对象迁移流程,但不能用于验证真实业务数据迁移。
如果后续需要完整验证 Oracle 到达梦的数据迁移,应重新准备包含数据的 Oracle dump,导入 Oracle 容器后再执行 DTS 迁移。迁移前应先在 Oracle 源端确认字符集、表数据、CLOB 内容均显示正常,避免把源端已经损坏的数据继续迁移到达梦。
十、DTS 迁移报错分析
本次 DTS 迁移按步骤拆开后,主要报错集中在第三步、第四步和第七步。需要注意的是,第四步和第五步准确来说是同一类"补充对象迁移":第四步误勾选了表对象,因此日志中出现大量表级重复创建错误;第五步只勾选序列后,才是本次实验中真正用于迁移序列的配置。
本次用于分析的日志文件包括:
所有日志.txt错误日志.txt错误sql.sql第四步错误日志.txt第四步错误sql.sql迁移普通视图错误日志.txt迁移普通视图错误sql.sql
1. 第三步:约束和索引迁移报错
第三步的目标是补充主键、唯一约束、外键、校验约束和索引。该步中需要重点关注的是 Oracle 内部函数索引无法在达梦中直接创建,例如:
sql
CREATE INDEX "INDEX256247779694600"
ON "EPIDM"."DM_HGEL_REPORT"(SYS_OP_C2C("LOT"));
CREATE INDEX "INDEX256254113886900"
ON "EPIDM"."DM_XRDADDKVALUEVIEW_TEST"(SYS_OP_C2C("COMPONENTID"));报错为:
text
无法解析的成员访问表达式[SYS_OP_C2C]SYS_OP_C2C 是 Oracle 内部转换函数,通常由 Oracle 为字符集或字符类型转换生成。达梦不能直接解析这类 Oracle 内部函数索引,因此这两条索引不影响主体表结构和数据迁移,可以在本次实验中忽略。后续如果查询确实依赖这些列,再在达梦侧补建普通索引即可:
sql
CREATE INDEX 索引名 ON EPIDM.DM_HGEL_REPORT(LOT);
CREATE INDEX 索引名 ON EPIDM.DM_XRDADDKVALUEVIEW_TEST(COMPONENTID);2. 第四步:误勾选表对象导致重复创建
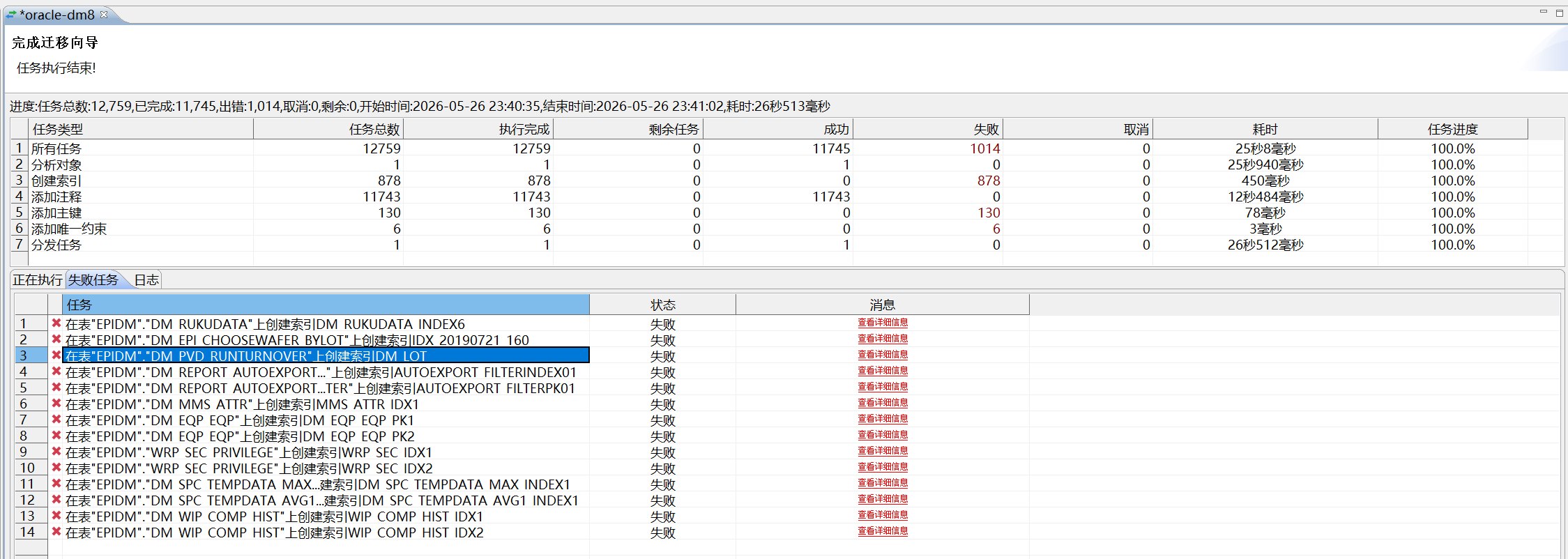
第四步的错误日志统计如下:
| 失败阶段 | 数量 | 主要原因 |
|---|---|---|
CREATE_INDEX |
878 | 索引已经在第三步创建,再次创建时报重复 |
ADD_PRIMARY_KEY |
130 | 主键已经存在,再次添加时报重复 |
ADD_UNIQUE |
6 | 唯一约束已经存在,再次添加时报重复 |
典型报错包括:
text
表中已存在这样的唯一关键字或主键
此列列表已索引这类错误不是新的迁移失败,而是第四步配置时仍勾选了表对象,DTS 再次执行表级约束和索引迁移导致的重复创建。由于第三步已经迁移过约束和索引,第四步如果只是为了迁移序列,就不应该继续勾选表映射里的主键、外键、约束和索引。
因此第五步只勾选"序列"是对第四步配置的修正。序列迁移时不需要进入表映射关系中配置主键、索引、外键等表级规则。
3. 第七步:普通视图迁移报错
第七步只迁移普通视图。日志显示:
text
总共402个对象,实际分析402个,分析失败130个目标端创建阶段统计如下:
| 失败阶段 | 数量 | 主要原因 |
|---|---|---|
CREATE_VIEW |
200 | Oracle 视图 SQL 无法直接在达梦中解析 |
ANALYZE_TABLE |
1 | DTS 分析源端视图列信息时失败 |
普通视图迁移失败主要有两类原因。
第一类是 Oracle 源端视图本身已经无效。日志中大量出现:
text
ORA-04063: view "EPIDM"."..." 有错误DTS 在迁移前会执行类似下面的 SQL 分析源端对象:
sql
SELECT * FROM "EPIDM"."DMV_LOT_CREATE_INFO" WHERE 1=2;如果 Oracle 源端视图已经是 invalid,DTS 读取视图结构时就会失败。这部分问题与目标达梦无关,通常和源端导入时缺少依赖对象、DBLINK、函数、包或旧环境对象有关。
第二类是视图 SQL 能从 Oracle 读出来,但不能直接在达梦中创建。迁移普通视图错误sql.sql 中失败视图大量包含中文列名和中文别名,例如:
sql
CREATE OR REPLACE VIEW "EPIDM"."DMV_MES_EPI_WIP_LOT" ("炉次号","工单",...)
AS
SELECT LOT.LOT AS 炉次号,
LOT.WO AS 工单,
...达梦报错通常为:
text
第 3 行, 第 19 列[?]附近出现错误:
语法分析出错这里的 ? 多数对应中文标识符或 DTS 转换后无法识别的位置。Oracle 中能直接使用的中文别名、层次查询、部分函数写法,迁移到达梦后需要手工加双引号或改写 SQL。
例如中文别名应改为:
sql
SELECT LOT.LOT AS "炉次号",
LOT.WO AS "工单"此外,普通视图 SQL 中还存在 Oracle 特有或高风险写法,例如:
(+ )旧式外连接,需要改写为LEFT JOINCONNECT BY、START WITHSYS_CONNECT_BY_PATHDECODEROWNUM- 部分重复列名或重复别名
因此普通视图迁移失败不代表表和数据迁移失败。视图本身只是 SQL 定义,复杂视图需要后续按业务重要性逐个改写。
4. 本次实验处理建议
本次实验可以将迁移结果分为两类看待:
| 对象类型 | 处理结论 |
|---|---|
| 表定义 | 作为主体迁移结果重点检查 |
| 表数据 | 由于 dump 是 metadata_only,无数据或少量数据属于正常现象 |
| 主键、唯一约束、普通索引 | 第三步已迁移,第四步重复报错可忽略 |
| Oracle 内部函数索引 | 跳过,必要时在达梦侧重建普通索引 |
| 序列 | 单独迁移,不要勾选表对象 |
| 触发器 | 放在表、序列之后单独迁移 |
| 普通视图 | 失败较多,需要按业务重要性手工改写 |
| 物化视图 | 建议最后单独迁移,依赖普通视图和刷新机制,失败概率更高 |
如果要继续清理视图问题,应先在 Oracle 源端查询无效视图:
sql
SELECT owner, object_name, status
FROM dba_objects
WHERE owner IN ('EPI', 'EPIDM')
AND object_type = 'VIEW'
AND status <> 'VALID'
ORDER BY owner, object_name;
SELECT owner, name, type, line, position, text
FROM dba_errors
WHERE owner IN ('EPI', 'EPIDM')
AND type = 'VIEW'
ORDER BY owner, name, sequence;确认源端有效后,再挑选关键视图迁移到达梦。普通视图和物化视图不建议一次性全量迁移后直接作为成功标准。