目录
[1. 向量数据库](#1. 向量数据库)
[2. PgVector 应用场景](#2. PgVector 应用场景)
[二、关于 PgVector](#二、关于 PgVector)
[1. PgVector 是什么](#1. PgVector 是什么)
[2. PgVector 可以做什么](#2. PgVector 可以做什么)
[三、Windows11 环境下安装详解](#三、Windows11 环境下安装详解)
[1. 安装方式汇总](#1. 安装方式汇总)
[2. 前置环境准备](#2. 前置环境准备)
[(1)安装 PostgreSQL 16](#(1)安装 PostgreSQL 16)
[2.安装 PgVector](#2.安装 PgVector)
[3. 重启 PostgreSQL 服务](#3. 重启 PostgreSQL 服务)
[四、PgVector 功能测试](#四、PgVector 功能测试)
[1. 连接 PostgreSQL](#1. 连接 PostgreSQL)
[2. 创建测试数据库](#2. 创建测试数据库)
[3. 启用 PgVector 扩展](#3. 启用 PgVector 扩展)
[4. 基础实例测试](#4. 基础实例测试)
一、前言
1. 向量数据库
随着大模型、AI 检索、智能推荐、图文匹配等业务快速落地,向量检索 成为技术架构中不可或缺的一环。文本、图片、音频、视频等非结构化数据,都会通过 Embedding 模型转化为多维向量,业务依靠向量相似度完成匹配、搜索、聚类等操作。传统关系型数据库无法高效处理海量向量的相似度计算,专用向量数据库应运而生。但独立部署向量库会增加运维成本、数据同步成本与架构复杂度。在此背景下,基于传统数据库扩展实现向量能力的方案,凭借低侵入、易集成、复用原有生态等优势,成为中小型项目、个人开发、企业内部系统的首选。

2. PgVector 应用场景
PgVector 作为 PostgreSQL 生态下的向量扩展,完美融合了关系型数据库的事务能力与向量检索能力,典型应用场景如下:

- AI 语义检索:知识库、问答系统、文档检索,将文本向量化后实现语义匹配;
- 多媒体检索:图片、音频、视频以向量形式存储,实现以图搜图、相似音视频查找;
- 个性化推荐:用户行为、内容特征向量化,完成商品、内容智能推荐;
- 数据分析与聚类:用户分群、内容归类、异常检测等向量聚类场景;
- 混合查询业务 :同时需要结构化数据查询 + 向量相似度检索的混合业务,无需拆分多套存储。
本文基于 Windows 11 系统,搭配主流的 PostgreSQL 16 版本,手把手完成 PgVector 安装、配置与功能验证,适合开发、测试、学习环境使用,如需在生产环境进行使用,可以切换至Linux环境进行安装配置更佳。
二、关于 PgVector
1. PgVector 是什么
PgVector 是一款开源 PostgreSQL 扩展插件 ,由 ankane 团队维护,原生为 PostgreSQL 增加向量数据类型与向量检索能力。它不改变 PostgreSQL 原有架构,以扩展形式运行,兼容 PostgreSQL 完整生态(事务、索引、JOIN、备份恢复、权限管理等)。目前支持 PostgreSQL多个版本,兼容主流操作系统,同时提供源码编译、容器、包管理等多种部署方式,是目前Postgres 体系中使用最广泛的向量检索扩展。
2. PgVector 可以做什么
- 多类型向量存储:支持普通浮点向量、半精度向量、二进制向量、稀疏向量,适配不同精度与存储需求;
- 丰富距离算法:内置 L2 距离、内积、余弦距离、L1 距离、汉明距离、杰卡德距离,覆盖绝大多数相似度计算场景;
- 双层检索模式 :支持精确检索 (百分百召回)与近似最近邻检索(牺牲少量召回换取极致速度);
- 专业向量索引:提供 HNSW、IVFFlat 两大主流向量索引,应对千万级甚至亿级向量数据检索优化;
- 全量 SQL 兼容:使用标准 SQL 完成向量增删改查、条件过滤、聚合计算,学习成本极低;
- ACID 事务保障:继承 PostgreSQL 事务特性,向量数据同样支持事务、回滚、并发控制,数据安全性更高。
简单来说:有了 PgVector,你的 PostgreSQL 就能直接当作「关系型数据库 + 向量数据库」二合一存储使用。为什么要提基于PG生态的,很多中小企业,我们的存储和计算的能力都放在数据库中。由于技术储备的同学其实没有那么多,因此我们尽量精简技术栈,降低运维的难度。熟悉的PostGIS就是基于PG的GIS扩展,我们很多的业务都可以基于PostGIS来进行开展。
三、Windows11 环境下安装详解
这里介绍一下博主的开发环境,使用的Window11操作系统,64位。设备硬件信息如下:
如果大家的开发环境是在Linux中的,看到这里就可以划走了。言归正传,下面继续深入对PgVector进行讲解。
1. 安装方式汇总
一般来讲,PgVector 主要有 4 种安装方案,大家可根据自身环境选择:
- 源码编译安装:Linux、Mac、Windows 通用,自由度最高,可自定义版本,本文重点讲解 Windows 源码编译;
- Docker 容器部署:一键拉起集成 Postgres + PgVector 的镜像,适合快速体验、测试环境;
- 包管理器安装:Linux 发行版、macOS 可通过 APT、YUM、Homebrew 等直接安装,Windows 支持 conda 安装;
- 云托管服务:各大云厂商托管 PostgreSQL 服务大多已预装 PgVector,无需手动部署。
对于 Windows 11 本地开发、调试场景,这里我们使用最简单的方法,使用预编译的版本进行安装。
2. 前置环境准备
(1)安装 PostgreSQL 16
首先确保系统已安装 **PostgreSQL 16,**根据环境的需要,也可以安装更高的版本,步骤简述:
- 前往 PostgreSQL 官网下载 Windows 安装包(PostgreSQL 16.x);
- 双击安装,自定义安装路径(本文默认路径:
D:\Program Files\PostgreSQL\16),设置超级管理员postgres密码; - 保持默认端口
5432,完成安装,启动 PostgreSQL 服务。
关键记录:PostgreSQL 根目录
PGROOT=D:\Program Files\PostgreSQL\16,后续编译需要用到。
2.安装 PgVector
这里我们使用一种的简单的方法来安装PgVector。当然,大家可以通说自定义编译的方式进行安装。如果大家仅为了学习和使用PgVector,可以参考本文的使用预编译的方式进行安装。
- 下载windows预编译文件
在浏览器中输入以下地址,可以找到已经编译好的PgVector的编译版本,
bash
https://github.com/andreiramani/pgvector_pgsql_windows/releases?page=1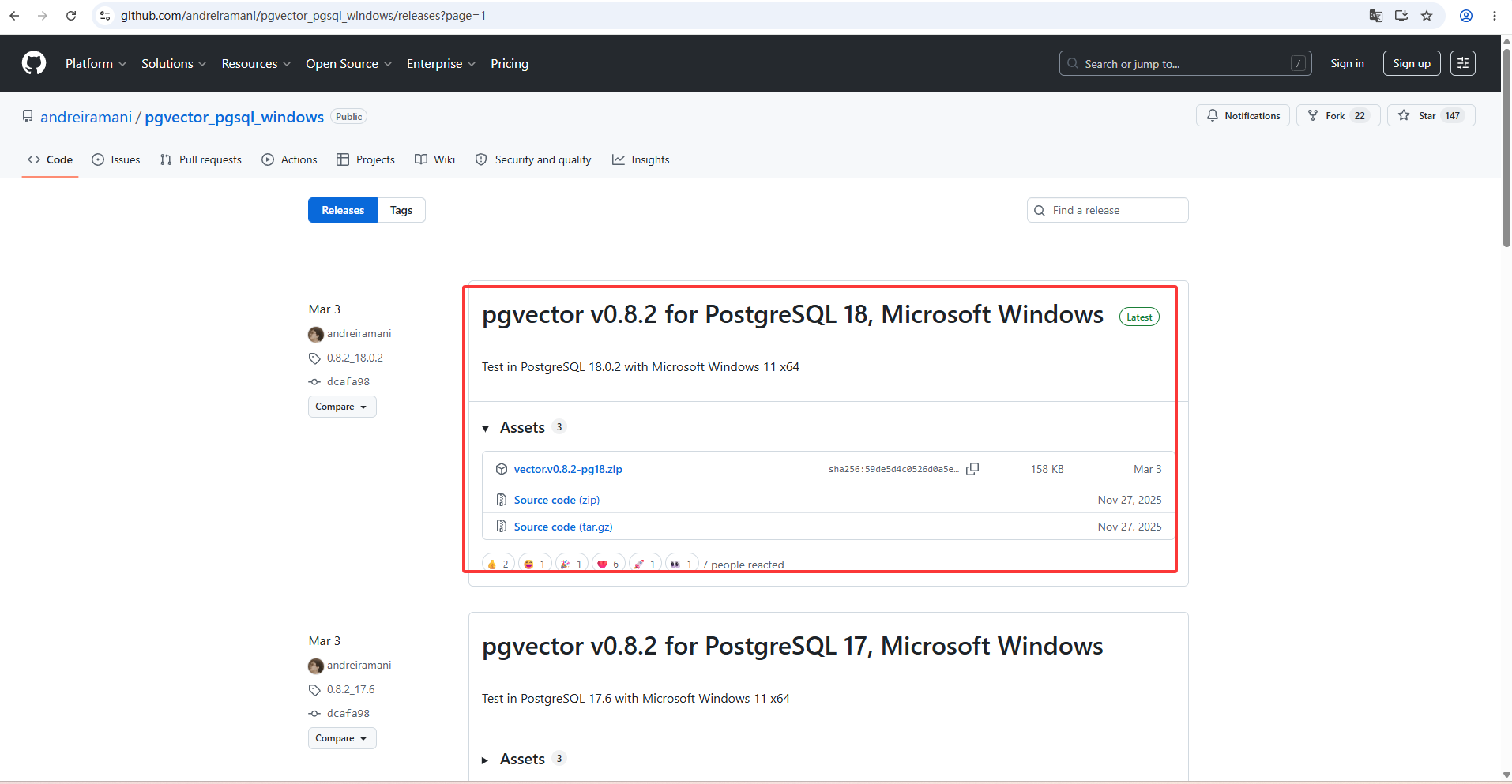
- 下载适配PostgreSQL16版本的PgVector(本文使用稳定版 v0.8.2)
bash
https://github.com/andreiramani/pgvector_pgsql_windows/releases/tag/0.8.2_16.1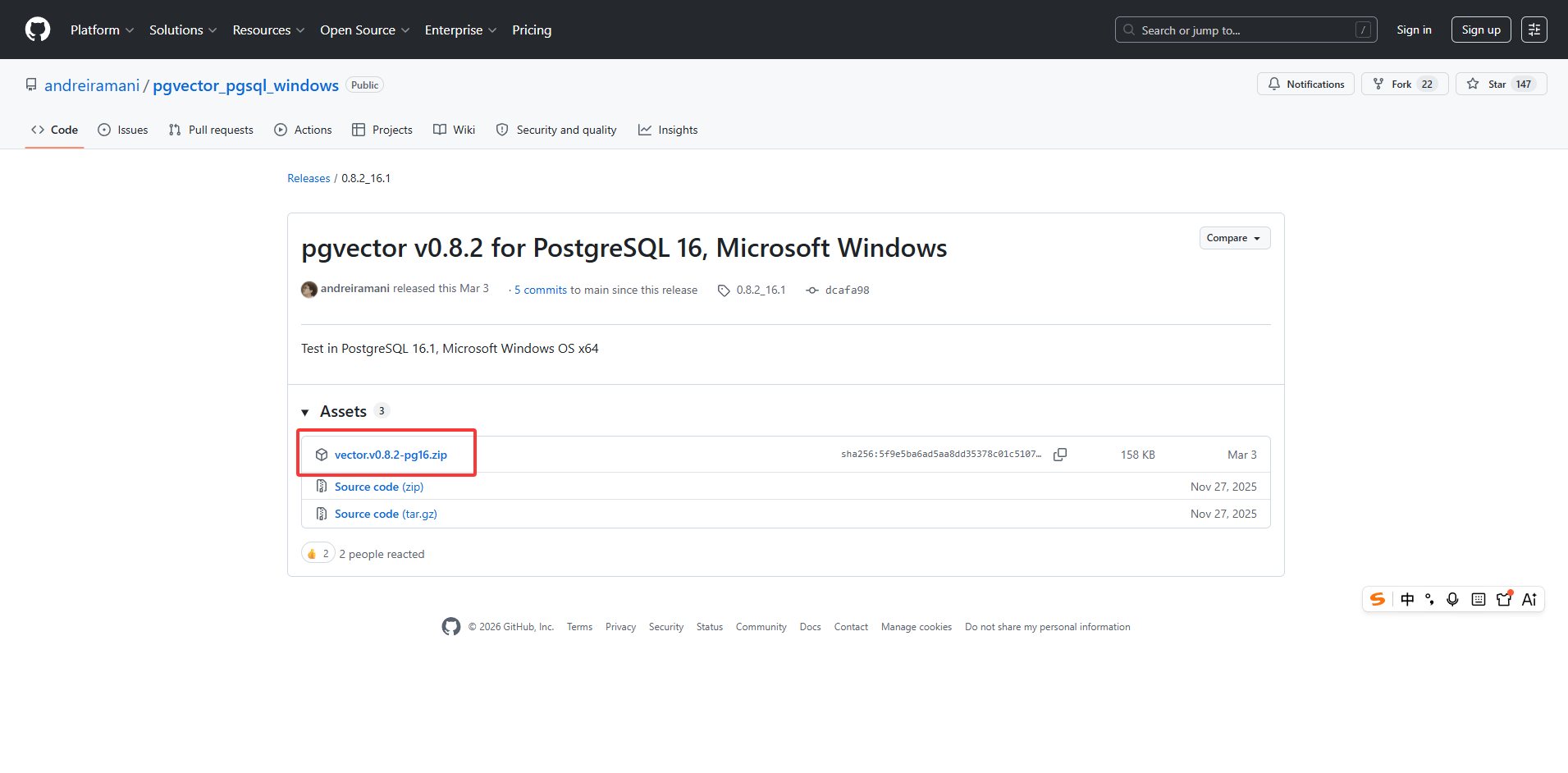
需要注意的是,大家在下载时根据本地的实际环境和软件版本来选择下载。
- 解压文件
- 覆盖PG16安装目录
将上面解压出来的文件夹,除了readme.txt之外,都复制到PG16的安装目录下,复制过去之后,选择覆盖所有。
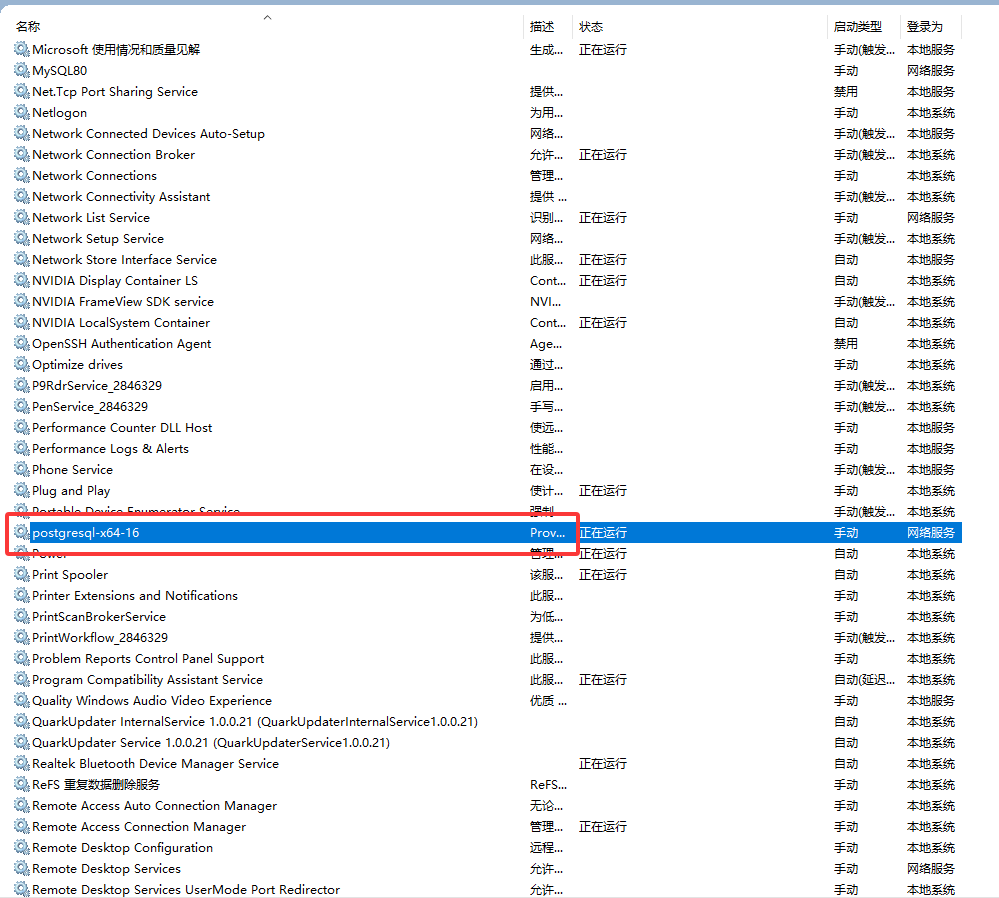
3. 重启 PostgreSQL 服务
安装完成后,重启 PostgreSQL 服务使扩展生效:
- 按下
Win + R输入services.msc打开服务列表; - 找到
postgresql-x64-16服务,右键重启。
四、PgVector 功能测试
本节通过标准 SQL 完成「创建数据库 → 启用扩展 → 建表 → 插入向量 → 相似度检索」全流程,验证前面的PgVector安装环境可用性。
1. 连接 PostgreSQL
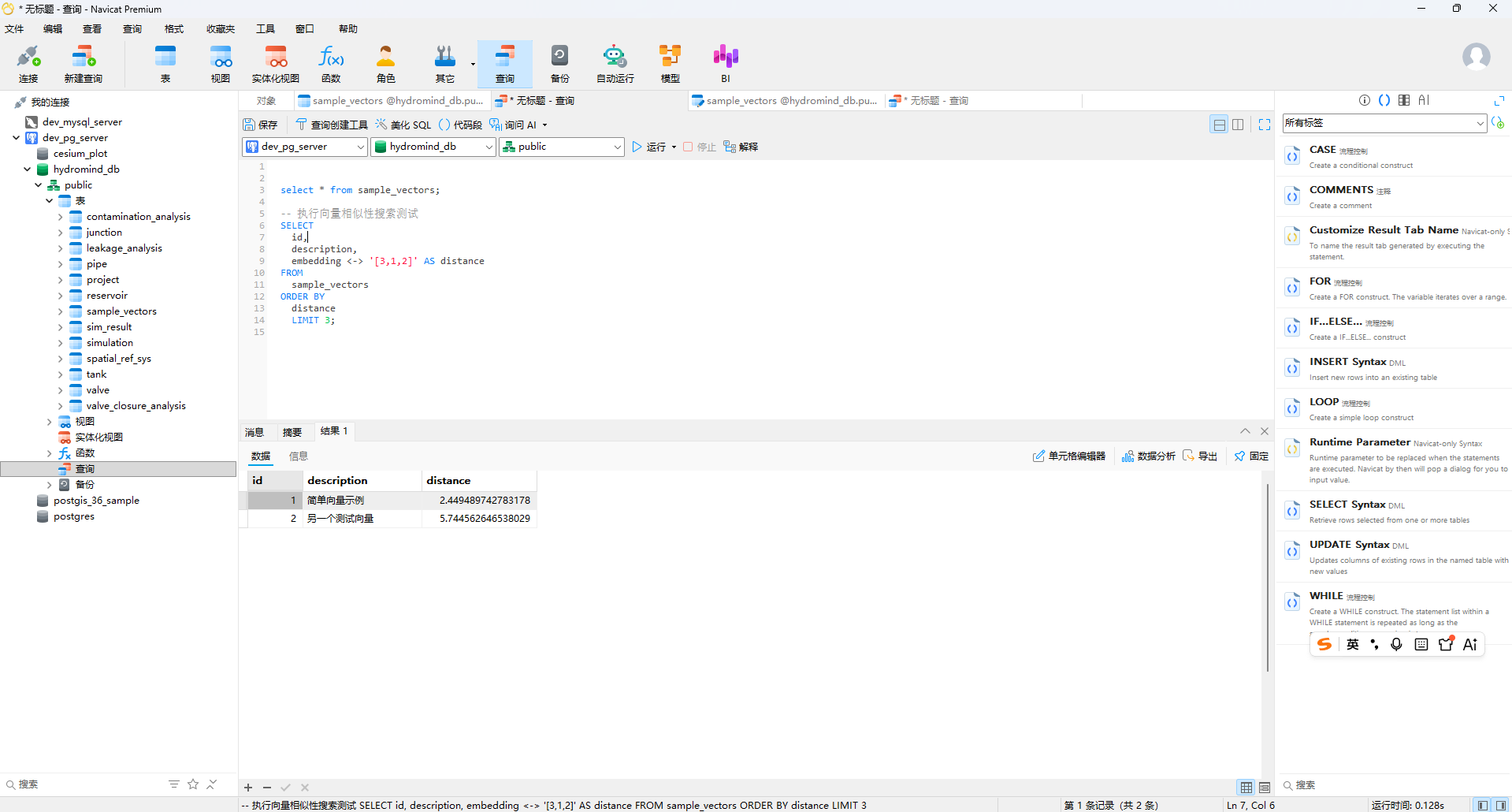
使用任意客户端连接(PostgreSQL 自带 psql、DBeaver、Navicat、pgAdmin 均可),本文以Navicat17为例:
2. 创建测试数据库
bash
-- 创建向量测试库
CREATE DATABASE hydromind_db;3. 启用 PgVector 扩展
每个数据库都需要单独执行一次启用命令:
CREATE EXTENSION IF NOT EXISTS vector;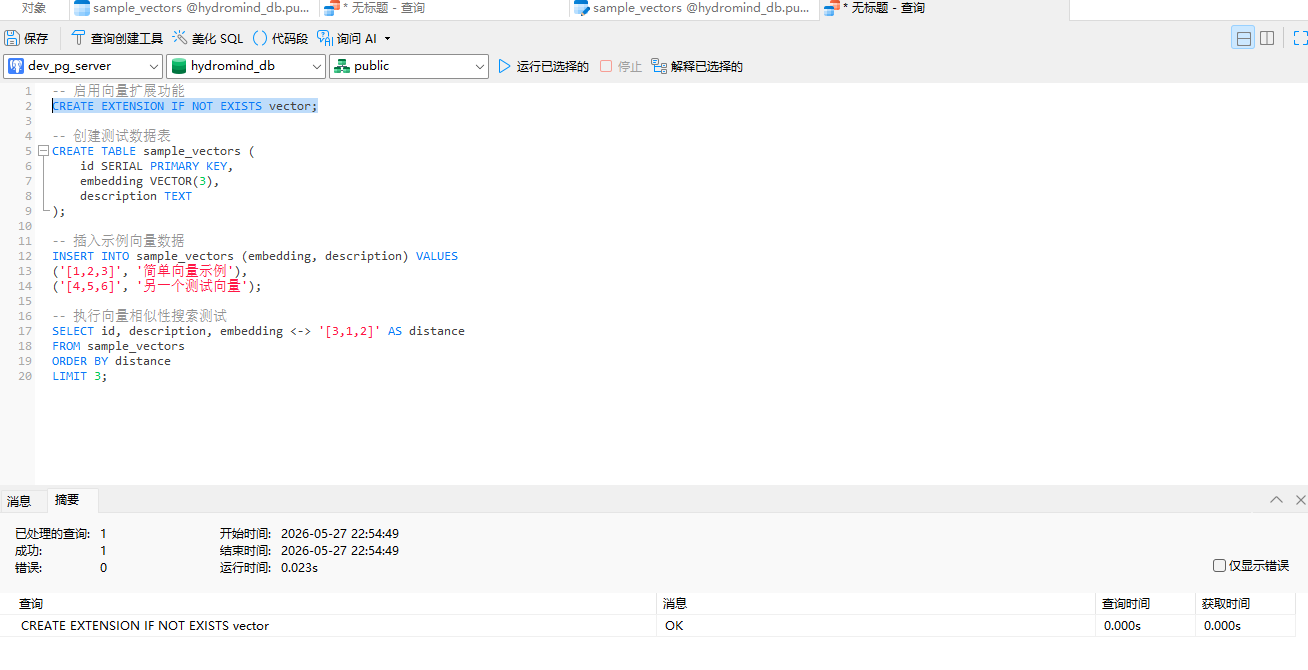
执行无报错,代表 PgVector 扩展加载成功。
4. 基础实例测试
(1)创建带向量字段的数据表
创建一张测试表,包含自增主键与 3 维向量 字段:
bash
-- 创建测试数据表
CREATE TABLE sample_vectors (
id SERIAL PRIMARY KEY,
embedding VECTOR(3),
description TEXT
);(2)插入向量数据
向量以数组格式写入:
bash
-- 插入示例向量数据
INSERT INTO sample_vectors (embedding, description) VALUES
('[1,2,3]', '简单向量示例'),
('[4,5,6]', '另一个测试向量');(3)余弦距离查询
演示另一种常用相似度算法(余弦距离):
bash
-- 执行向量相似性搜索测试
SELECT id, description, embedding <-> '[3,1,2]' AS distance
FROM sample_vectors
ORDER BY distance
LIMIT 3;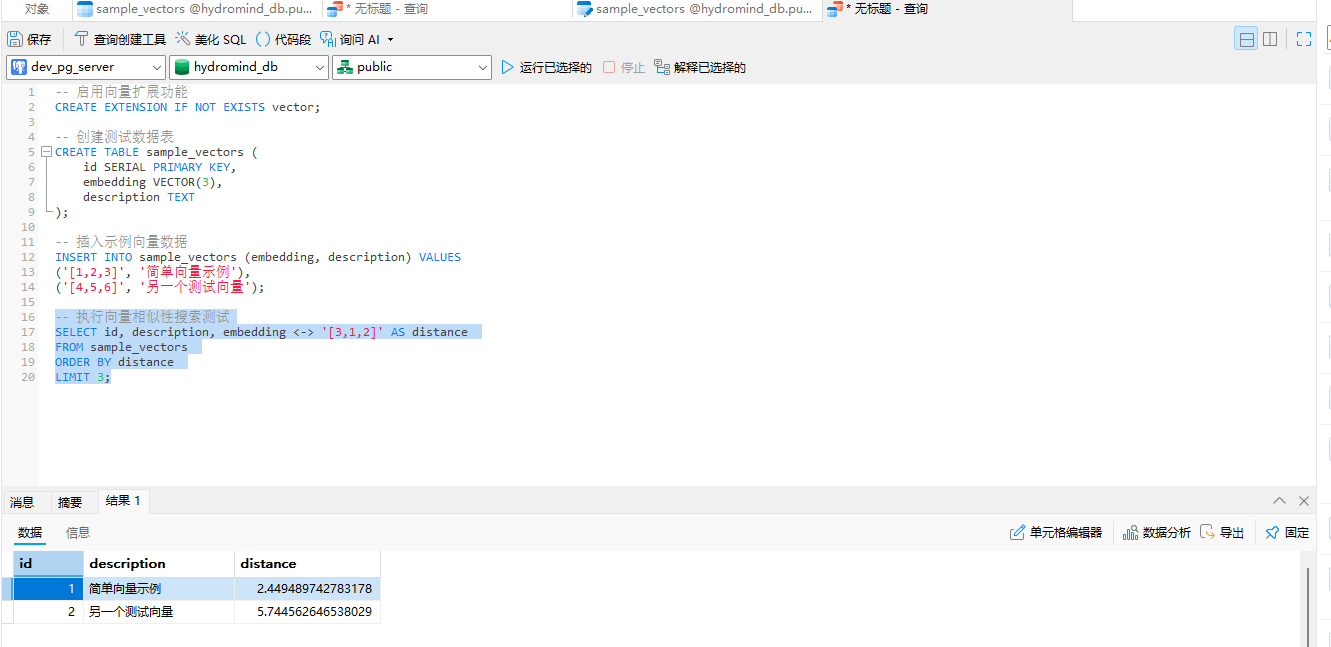
以上 SQL 全部正常执行、返回结果,说明 PostgreSQL 16 + PgVector0.8.2 在 Windows11 环境部署完成。
五、总结
- 本文基于 Windows 11 + PostgreSQL 16,使用预编译安装的方式完成 PgVector 部署,适配本地开发、学习、测试场景,步骤完整且可落地;
- PgVector 作为 Postgres 生态的向量扩展,兼顾关系型数据库的稳定性与向量检索的能力,大幅简化 AI 检索类项目的架构与运维;
- 基础测试仅演示了向量增查与基础距离算法,后续可进一步探索 HNSW/IVFFlat 向量索引、高维向量、混合条件查询等高级用法。
如果是生产环境,建议优先考虑 Linux 部署或 Docker 容器化方案;个人学习、本地调试,Windows 这套方案完全够用。行文仓促,定有不足之处,欢迎各位朋友在评论区批评指正,不胜感激。