明明 WHERE 条件已经把值定死了,DISTINCT 却还在全表扫描?
作为一名数据库爱好者,我遇到过不少因为DISTINCT导致的性能事故,这篇文章带你拆解金仓数据库的两种优化路径,顺便看看达梦是怎么处理的。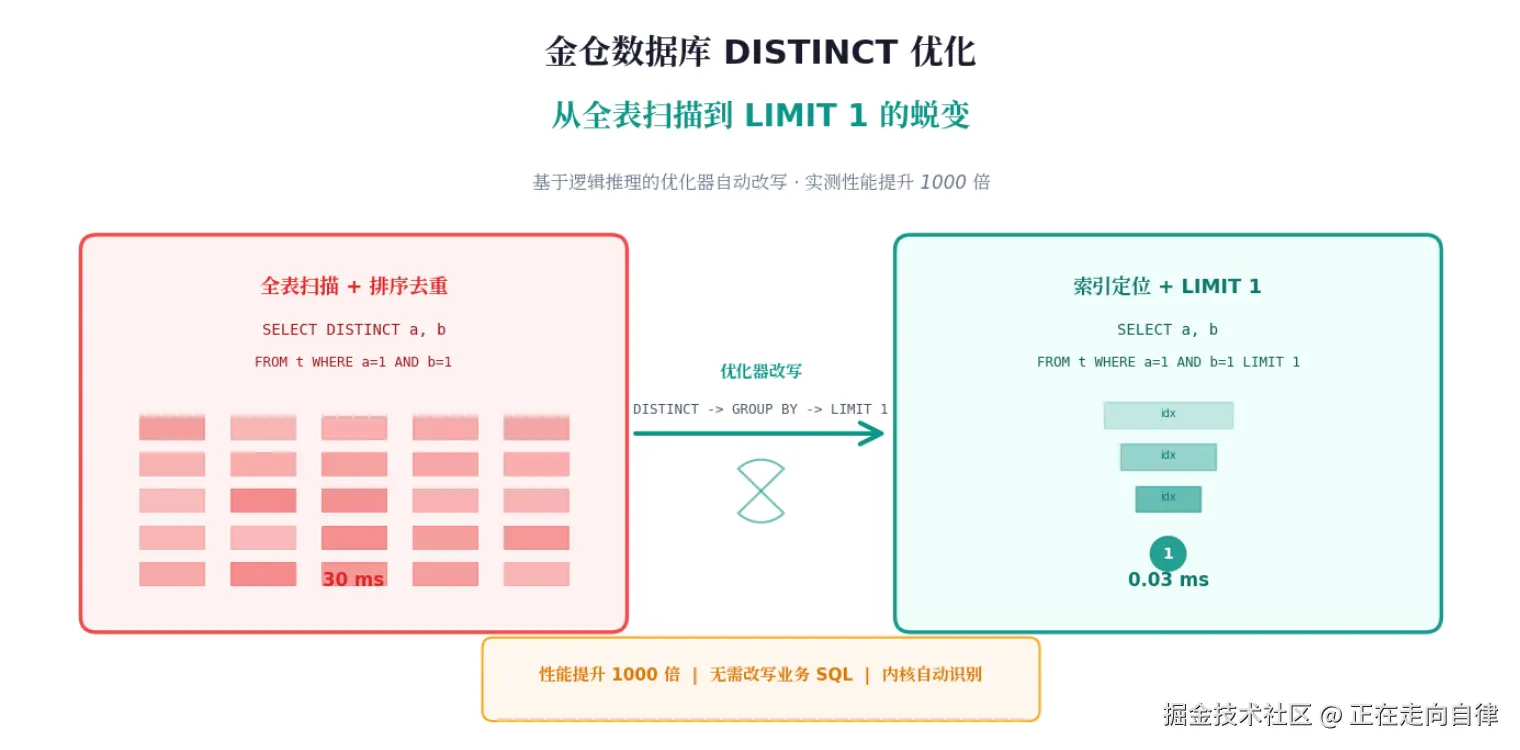
之前收到一个开发同学的求助:线上有一条 SQL 跑得很慢,表里才几百万数据,查了快 2 秒。我一看语句,长这样:
sql
SELECT DISTINCT order_status, pay_status
FROM orders
WHERE order_id = 10086 AND user_id = 20001;他很不理解:order_id 和 user_id 一起已经能唯一定位一条订单了,order_status 和 pay_status 不就是固定的两个值吗?为什么还要扫这么久?
我点开执行计划------全表扫描,然后排序去重。果然,数据库没有做他想象中的"聪明优化"。
这不是个例。DISTINCT 在很多人手里就是一把"钝刀",用起来顺手,但砍下去很痛。今天我们就以金仓数据库的实际优化为例,聊聊数据库内核是怎么把这种低效查询救回来的,顺便对比一下达梦数据库的做法。
痛点还原:为什么 DISTINCT 这么"死心眼"?
先看一条最简单的语句:
css
SELECT DISTINCT a, b FROM t1 WHERE a = 1 AND b = 1;从逻辑上讲,a 和 b 都被 WHERE 条件固定成了 1,那所有满足条件的记录里的 (a,b) 肯定都是 (1,1),去重后也就一行。正常人的思维是:找到第一条就直接返回,完事。
但大多数数据库的执行逻辑是:
- 根据
a=1 and b=1扫描所有符合条件的行 - 把结果集排序或者放进哈希表
- 去重后输出
哪怕你只有一行符合条件,它也要先扫完再说。当 a 和 b 的选择性不高时,这个"扫完"意味着扫成千上万行,再排序,性能自然崩了。
我们可以在金仓数据库中先手动关闭优化,看下原始执行计划的样子:
ini
-- 关闭 DISTINCT 改写优化
SET enable_distinct_to_groupby = off;
SET enable_limit1_for_distinct = off;
-- 查看原始执行计划
EXPLAIN (ANALYZE, BUFFERS)
SELECT DISTINCT a, b FROM t1 WHERE a = 1 AND b = 1;可以看到计划中仍然出现 HashAggregate 或 Unique(排序去重)节点,并且扫描了所有满足条件的行。
金仓数据库的两种优化路径
金仓数据库在内核层面对 DISTINCT 做了两类改写,分别对应不同的场景。GUC 参数可以控制是否开启,默认是打开的。
优化一:DISTINCT → GROUP BY
第一类改写比较简单:把 SELECT DISTINCT 转成 GROUP BY。
sql
-- 原始 SQL
SELECT DISTINCT product_id, category_id
FROM inventory
WHERE warehouse_id = 'WH001';
-- 内核改写后
SELECT product_id, category_id
FROM inventory
WHERE warehouse_id = 'WH001'
GROUP BY product_id, category_id;这样做有什么好处?
GROUP BY可以复用主键信息做键值消除 。如果product_id已经是唯一的,那分组操作其实可以直接跳过,不需要真正的聚合。- 在多核环境下,
GROUP BY比DISTINCT更容易触发并行扫描,充分利用 CPU 资源。
实测数据:2000 万行的测试表,原查询 464ms,改写后 249ms,提升约 46%。
当然,这个转换不是无脑的。优化器必须判断语义是否等价,尤其是 NULL 值的处理------DISTINCT 认为所有 NULL 相等,GROUP BY 也认为 NULL 属于同一组,这里是一致的。但如果目标列中有函数、窗口函数等复杂表达式,改写就要谨慎了。
你可以通过下面两条命令,直观对比优化开关对执行计划的影响:
vbnet
-- 开启 DISTINCT → GROUP BY 优化
SET enable_distinct_to_groupby = on;
-- 再次查看执行计划
EXPLAIN (ANALYZE, BUFFERS)
SELECT DISTINCT product_id, category_id
FROM inventory
WHERE warehouse_id = 'WH001';执行计划中的 Group 节点会标注出"键值消除"的信息,且扫描行数可能大幅降低。
优化二:目标列被常值固定时,直接用 LIMIT 1
第二类改写才是真正的"大杀器"。它的核心判断条件是:SELECT 列表中的所有去重字段,是否都能被 WHERE 条件确定为常量?
如果能,那么整个 DISTINCT 就是多余的,因为结果集最多只有一行。
还是用开头的例子:
sql
SELECT DISTINCT order_status, pay_status
FROM orders
WHERE order_id = 10086 AND user_id = 20001;金仓的优化器会做这样几步推理:
- WHERE 条件中
order_id=10086和user_id=20001直接限定了这两个字段的值; - 假设这两个字段的组合是唯一的(或者即使不唯一,
order_status和pay_status在该条件下的取值也完全一样),那么去重后的结果只有一行; - 因此,原查询可以安全地改写为:
ini
SELECT order_status, pay_status
FROM orders
WHERE order_id = 10086 AND user_id = 20001
LIMIT 1;这个改写的效果有多夸张?看测试数据:
| 场景 | 优化前耗时 | 优化后耗时 | 提升倍数 |
|---|---|---|---|
| 单表固定条件 | 30 ms | 0.03 ms | 1000x |
| 两表 INNER JOIN | 12 ms | 0.08 ms | 150x |
第二个例子是带连接的:
sql
SELECT DISTINCT s1.a, s2.b
FROM s1
INNER JOIN s2 ON s1.a = s2.b
WHERE s1.a = 5;优化器会做等值传递:s1.a=5 且 s1.a = s2.b → s2.b = 5。于是两个目标列都被固定为 5,整个查询变成 LIMIT 1 版本。从扫完所有数据再连接去重,变成找到一条就返回。
跟达梦数据库比一下
同样的最小化用例,拿到达梦 V8 上执行:
css
EXPLAIN SELECT DISTINCT a, b FROM distinct_1 WHERE a = 1 AND b = 1;从输出的执行计划来看,达梦仍然走的是常规 DISTINCT 路径:先扫描所有满足条件的行,然后去重。它没有尝试做 LIMIT 1 的改写。
这里没有谁对谁错,只是设计哲学的差异:
这里没有谁对谁错,只是设计哲学的差异:
- 达梦偏向保守,严格遵循 SQL 标准语义,不轻易做语义层面的改写,避免踩坑。
- 金仓更激进一些,愿意在优化器里嵌入常量传递、谓词传递等推理模块,主动识别可优化的模式。当然,金仓也不是瞎改------内部有一套严格的等价性校验,只有确认目标列被常值固定、没有窗口函数/集合操作/外连接空值补全等干扰因素时,才会触发 LIMIT 1 改写。
从技术深度上看,金仓的优化器在"逻辑推理"这个维度上走得更远。对于业务上大量存在"DISTINCT + 强过滤条件"场景的系统来说,这种优化带来的收益是非常直接的。
写在最后
DISTINCT 本身没错,错的是数据库在应该"抄近道"的时候选择了"走大路"。金仓数据库通过两条优化路径------转 GROUP BY 和转 LIMIT 1------让优化器具备了识别特殊场景并走捷径的能力。
对于开发同学来说,了解这些优化特性有两个实际帮助:
- 写 SQL 时不用刻意把
DISTINCT改成GROUP BY或加LIMIT 1,数据库内核可能已经帮你做了。 - 当你在其他数据库上遇到类似慢查询时,可以手动尝试改写,验证一下是不是优化器的"锅"。
最后留个思考题:如果你的业务查询是这样的------SELECT DISTINCT very_long_text FROM huge_table WHERE id = 1,你觉得数据库能优化到什么程度?欢迎评论区讨论。