R语言相关性分析完整教程:从Pearson/Spearman方法选择到corrplot可视化
一、引言
环境因子如何影响生物多样性?这是生态学研究中的核心问题之一。回答这个问题,往往从相关性分析开始------通过计算环境变量与多样性指数之间的相关系数,快速判断哪些因子与群落结构变化密切相关。
然而,相关性分析并非"一个函数走天下":Pearson、Spearman、Kendall三种方法各有适用场景,选错方法可能导致错误结论。更关键的是,计算出相关系数只是第一步------如何用corrplot将结果清晰、美观地可视化,同样是论文写作中不可忽视的技能。
本文以一份环境-多样性综合数据为例,系统演示从方法选择、相关计算到corrplot可视化的完整流程,帮你建立起清晰的相关性分析工作流。
二、相关分析方法如何选择?
三种方法的本质区别在于对数据的假设不同:
| 方法 | 数据类型 | 正态性要求 | 关系形式 | 异常值敏感性 |
|---|---|---|---|---|
| Pearson | 连续变量 | 需要 | 线性关系 | 敏感 |
| Spearman | 连续/有序变量 | 不需要 | 单调关系 | 不敏感 |
| Kendall | 连续/有序变量 | 不需要 | 单调关系 | 不敏感 |
选择策略:
- 先做正态性检验------对每个变量运行Shapiro-Wilk检验,看数据是否服从正态分布
- 全部正态 → Pearson相关------经典参数方法,统计效力最高
- 部分/全部非正态 → Spearman相关------秩相关方法,生态学中最常用的选择,适用范围最广
- 样本量小(n < 30)且结(tied ranks)较多 → Kendall's τ------小样本下更稳健
实践中,生态学数据(多样性指数、环境因子)往往不满足正态分布,因此Spearman相关是默认推荐方法。如果你不确定选哪种,直接选Spearman基本不会错。
三、数据准备
本文使用仿真生成的生态学数据,包含50个样方的12个变量:
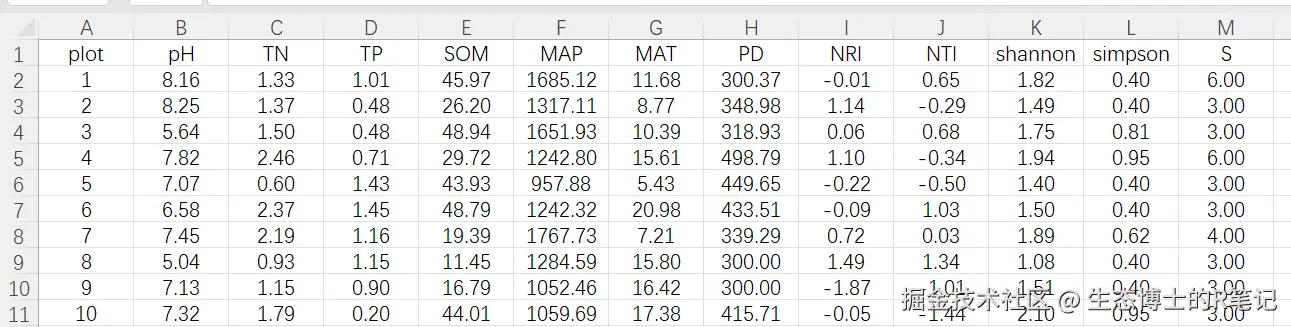
环境因子(6个):
| 变量 | 含义 | 单位 | 范围 |
|---|---|---|---|
| pH | 土壤pH | --- | 4.5 ~ 8.5 |
| TN | 总氮 | g/kg | 0.5 ~ 3.0 |
| TP | 总磷 | g/kg | 0.2 ~ 1.5 |
| SOM | 土壤有机质 | g/kg | 10 ~ 60 |
| MAP | 年均降水量 | mm | 800 ~ 1800 |
| MAT | 年均温 | ℃ | 5 ~ 25 |
多样性指数(6个):
| 变量 | 含义 | 说明 |
|---|---|---|
| PD | 系统发育多样性 | 群落系统发育分支长度总和 |
| NRI | 净亲缘关系指数 | >0表示系统发育聚集 |
| NTI | 最近分类单元指数 | >0表示末端亲缘关系聚集 |
| shannon | Shannon-Wiener指数 | 综合反映物种丰富度和均匀度 |
| simpson | Simpson指数 | 反映优势种集中程度 |
| S | 物种丰富度 | 样方中的物种数 |
r
# 读取数据
df <- read.csv("alpha_diversity.csv", header = TRUE)
head(df) # 查看前6行数据文件 alpha_diversity.csv 可在同一目录下找到,直接复制代码即可运行。
四、核心操作:相关性计算
第一步:正态性检验
在决定用哪种相关方法之前,先对每个变量做Shapiro-Wilk正态性检验:
r
# 正态性检验
p_values <- sapply(df, function(x) shapiro.test(x)$p.value)
norm_table <- data.frame(
Variable = names(df),
p_value = round(p_values, 4),
Normal = ifelse(p_values > 0.05, "Yes", "No")
)
print(norm_table)绝大多数环境因子和多样性指数的p值小于0.05,不服从正态分布。因此,本文以Spearman相关为主进行后续分析。
第二步:计算相关系数
R提供了 cor() 函数,一行代码即可计算三种相关系数:
r
# 三种方法一次搞定
pearson_r <- cor(df, method = "pearson")
spearman_r <- cor(df, method = "spearman")
kendall_r <- cor(df, method = "kendall")对比三种方法的结果可以发现:数值上有所差异,但正负方向和相对大小基本一致。如果某个变量对在Spearman下显著而在Pearson下不显著,往往是因为数据中存在非线性单调关系------这正是Spearman的优势所在。
第三步:同时获取相关系数和p值
cor() 只返回相关系数矩阵,不提供显著性检验。使用Hmisc包的 rcorr() 函数可以同时计算两者:
r
library(Hmisc)
res <- rcorr(as.matrix(df), type = "spearman")
res$r # 相关系数矩阵
res$P # p值矩阵结果解读示例(以pH与shannon为例):
- 相关系数 r = 0.54:中等程度正相关
- p < 0.001:极显著
- 含义:pH越高,Shannon多样性指数越高,说明土壤酸碱度是影响该群落多样性的重要因子
第四步:导出结果
r
write.csv(round(res$r, 3), "spearman_corr_coef.csv")
write.csv(round(res$P, 4), "spearman_p_values.csv")五、从基础到标准:corrplot可视化三步进阶
corrplot包是R语言中最受欢迎的相关矩阵可视化工具。下面从最基础的默认图开始,逐步优化到论文标准级别。
第一步:基础图------一行代码出图
corrplot() 不设置任何参数时,默认用彩色圆圈显示相关系数------蓝色代表正相关,红色代表负相关,颜色深浅反映相关强弱:
r
library(corrplot)
corrplot(res$r)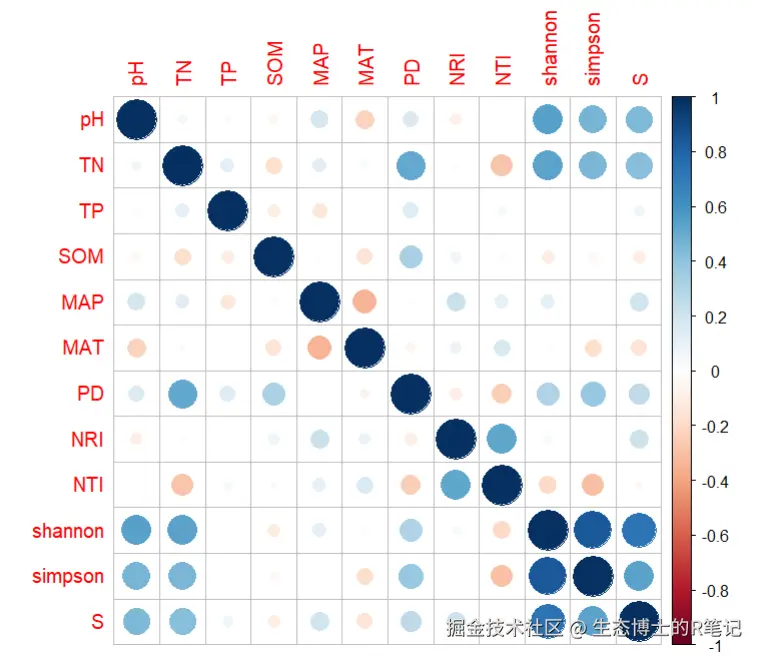 这是最简单的corrplot图,能看到变量之间的大致相关模式,但缺少变量名标签、排序杂乱,不适合直接用于论文。下面逐步优化。
这是最简单的corrplot图,能看到变量之间的大致相关模式,但缺少变量名标签、排序杂乱,不适合直接用于论文。下面逐步优化。
第二步:进阶图------自定义配色与上下三角混合
在上一步基础上做三项改进:(1) 用 order = "AOE" 按相关结构自动聚类排列;(2) 上三角用彩色圆圈,下三角用数字精确显示相关系数;(3) 自定义蓝-白-红三段配色:
r
corrplot(res$r, order = "AOE", type = "upper", tl.pos = "d",
tl.col = "black", tl.cex = 0.8,
col = colorRampPalette(c("#0072B5", "white", "#BC3C29"))(200))
corrplot(res$r, add = TRUE, type = "lower", method = "number",
order = "AOE", diag = FALSE, tl.pos = "n", cl.pos = "n",
col = "black", number.cex = 0.7)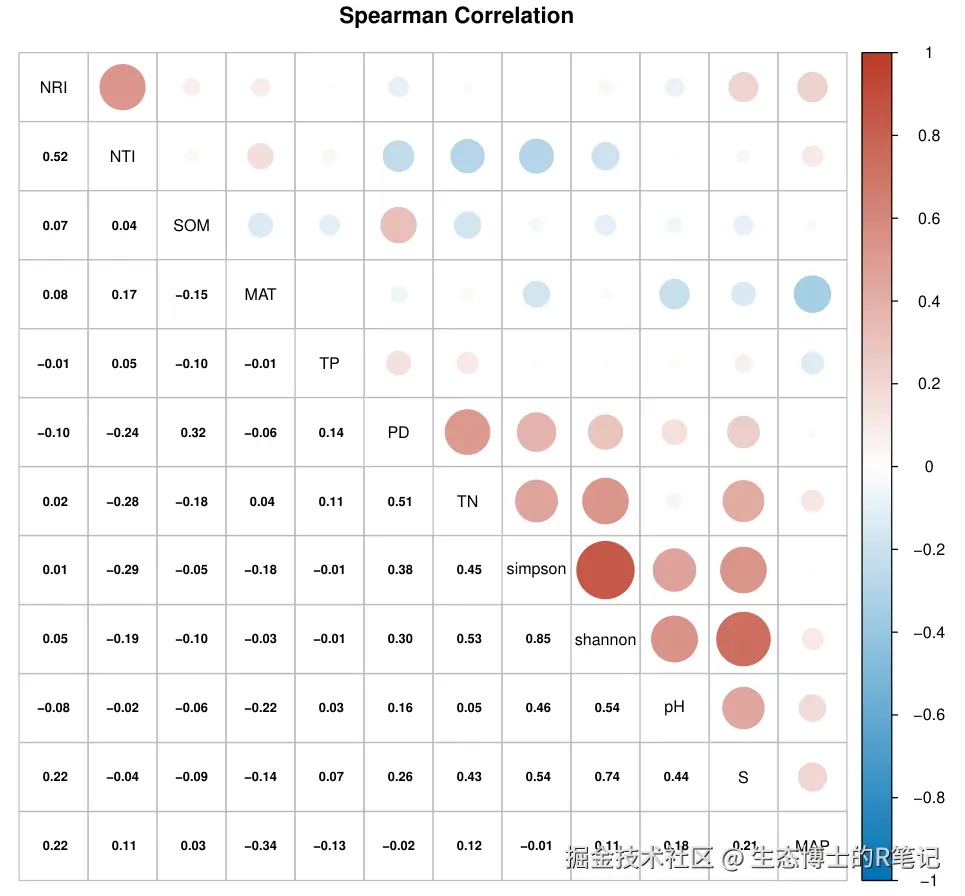 参数解析:
参数解析:
| 参数 | 作用 | 本图设置 |
|---|---|---|
order = "AOE" |
按特征值角度排序,让结构更清晰 | 自动聚类排列 |
type = "upper" |
只绘制上三角 | 第一层绘上三角 |
method = "number" |
用数字显示相关系数 | 第二层绘数字 |
tl.pos = "d" |
对角线显示变量名 | 避免重叠 |
add = TRUE |
叠加图层 | 实现上下三角混合 |
col = colorRampPalette(...) |
自定义配色 | 蓝色-白色-红色三段渐变色 |
第三步:标准图------显著性星号标注(论文标准)
这是期刊论文中最常用的corrplot形式------所有相关系数都显示,显著的相关自动添加星号标注(* p<0.05, ** p<0.01, *** p<0.001),不显著的相关正常显示但无星号:
r
p_mat <- res$P
diag(p_mat) <- 1
order_aoe <- corrMatOrder(res$r, order = "AOE")
corrplot(res$r[order_aoe, order_aoe], type = "upper", tl.pos = "d",
tl.col = "black", tl.cex = 0.8,
col = colorRampPalette(c("#0072B5", "white", "#BC3C29"))(200),
p.mat = p_mat[order_aoe, order_aoe],
sig.level = c(0.001, 0.01, 0.05),
insig = "label_sig",
pch.cex = 1.0, pch.col = "black")
corrplot(res$r[order_aoe, order_aoe], add = TRUE, type = "lower",
method = "number", diag = FALSE, tl.pos = "n", cl.pos = "n",
col = "black", number.cex = 0.7)关键参数 :p.mat传入p值矩阵,sig.level设三个显著性阈值(0.001/0.01/0.05)------注意必须从小到大排列 ,insig = "label_sig"表示在显著相关旁标注星号。注意需要预计算AOE排序(corrMatOrder)并同时应用到相关系数矩阵和p值矩阵上,确保上下三角对齐。
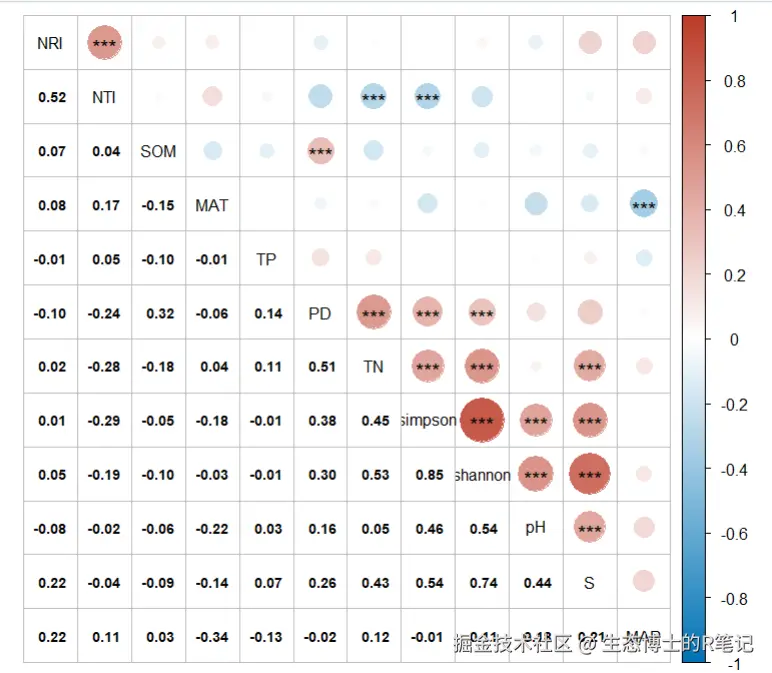
六、结果解读
从corrplot中可以清晰看到环境-多样性关系的整体格局:
1. 环境因子与多样性:
- pH 与shannon (r = 0.54, p < 0.001)、simpson (r = 0.46, p < 0.001)、S(r = 0.44, p < 0.01)均呈显著正相关------中性偏碱环境可能有利于该区域物种共存。
- TN与多样性指数的关系类似(r ≈ 0.43~0.53),氮有效性是限制多样性的另一关键因子。
- SOM与多样性关系较弱,仅与PD有弱正相关(r = 0.32, p < 0.05)。
2. 多样性指数之间的关系:
- shannon与simpson呈强正相关(r = 0.85),这符合预期------两个α多样性指数反映的信息高度重叠。
- shannon与S也高度正相关(r = 0.74),因为Shannon指数本身受丰富度影响。
- NRI与NTI中度正相关(r = 0.53),两者从不同层面反映系统发育结构,趋势一致。
3. 方法选择的启示:
对比Pearson和Spearman的结果可以发现,大部分显著相关的方向一致,但相关系数大小略有差异。当数据偏离正态时,Spearman的秩相关更为稳健。在实际论文中,建议以Spearman为主,同时可在附件中提供三种方法的结果对比表。
七、完整可运行代码
以下为自包含R脚本,复制到RStudio或命令行即可运行:
r
# ============================================================
# 相关性分析完整流程:Pearson / Spearman / Kendall + corrplot
# ============================================================
# 首次运行请先安装包:
# install.packages(c("Hmisc", "corrplot"))
library(Hmisc)
library(corrplot)
# --- 读取数据 ---
df <- read.csv("alpha_diversity.csv", header = TRUE)
# --- 正态性检验 ---
p_vals <- sapply(df, function(x) shapiro.test(x)$p.value)
data.frame(Variable = names(df), p_value = round(p_vals, 4),
Normal = ifelse(p_vals > 0.05, "Yes", "No"))
# --- 三种相关方法 ---
cor(df, method = "pearson")
cor(df, method = "spearman")
cor(df, method = "kendall")
# --- Spearman + p值 ---
res <- rcorr(as.matrix(df), type = "spearman")
res$r # 相关系数
res$P # p值
# --- 可视化:从基础图到标准图 ---
# 1) 基础图:默认 corrplot
pdf("corrplot_basic.pdf", width = 10, height = 8)
corrplot(res$r)
dev.off()
# 2) 进阶图:自定义配色 + 上下三角混合
pdf("corrplot_color.pdf", width = 10, height = 8)
corrplot(res$r, order = "AOE", type = "upper", tl.pos = "d",
tl.col = "black", tl.cex = 0.8,
col = colorRampPalette(c("#0072B5", "white", "#BC3C29"))(200))
corrplot(res$r, add = TRUE, type = "lower", method = "number",
order = "AOE", diag = FALSE, tl.pos = "n", cl.pos = "n",
col = "black", number.cex = 0.7)
dev.off()
# 3) 标准图:显著性星号标注(论文标准)
p_mat <- res$P; diag(p_mat) <- 1
order_aoe <- corrMatOrder(res$r, order = "AOE")
pdf("corrplot_significance.pdf", width = 10, height = 8)
corrplot(res$r[order_aoe, order_aoe], type = "upper", tl.pos = "d",
tl.col = "black", tl.cex = 0.8,
col = colorRampPalette(c("#0072B5", "white", "#BC3C29"))(200),
p.mat = p_mat[order_aoe, order_aoe],
sig.level = c(0.001, 0.01, 0.05), insig = "label_sig",
pch.cex = 1.0, pch.col = "black")
corrplot(res$r[order_aoe, order_aoe], add = TRUE, type = "lower",
method = "number", diag = FALSE, tl.pos = "n", cl.pos = "n",
col = "black", number.cex = 0.7)
dev.off()替换为自己的数据:
- 准备一个CSV文件,第一行为变量名,每一行为一个样方
- 确保变量包括连续数值型数据(分类变量不适用)
- 将
read.csv("alpha_diversity.csv")中的文件名替换为你的数据文件名
八、实用技巧总结
corrplot参数速查表:
| 参数 | 常用值 | 作用 |
|---|---|---|
method |
"circle" / "number" / "color" / "pie" |
图形样式 |
type |
"upper" / "lower" / "full" |
显示三角区域 |
order |
"AOE" / "hclust" / "FPC" |
变量排序方式 |
tl.cex |
0.6 ~ 1.0 | 变量名字体大小 |
number.cex |
0.5 ~ 0.8 | 数字标签字体大小 |
col |
colorRampPalette(...)(200) |
自定义色板 |
add |
TRUE / FALSE |
是否为叠加图层 |
diag |
TRUE / FALSE |
是否显示对角线 |
cl.pos |
"r" / "n" |
图例位置("n"为隐藏) |
方法选择速查:
数据是否正态?→ 是 → Pearson 数据是否正态?→ 否 / 不确定 → Spearman 样本量小(n < 30)+ 结较多?→ Kendall
常见注意事项:
- 相关性不意味着因果关系------即使r = 0.9也不能说"A导致B"
- 多重比较问题:12个变量有66对比较,部分显著可能由随机因素造成。严格时可做Bonferroni或FDR校正
- corrplot的
order = "AOE"会自动聚类排列,让相关模式更清晰,推荐默认使用
如果对你有帮助,欢迎 点赞 + 收藏。需要 R 语言数据处理服务,也欢迎私信交流。