LLMOps 入门指南:从模型部署到生产级监控
大模型落地不只是调 API------本文带你系统了解 LLMOps 的核心组件,从 Prompt 管理到监控告警,搭建一条最小可用的 LLMOps 流水线。
一、引言
2024 年以来,大语言模型(LLM)的应用从 Demo 阶段加速迈入生产环境。无论是客服机器人、代码助手,还是内部知识库问答,越来越多的团队正在把 LLM 能力嵌入核心业务链路。但随之而来的问题也很直接:Prompt 改了怎么管理?模型输出质量怎么保证?Token 成本怎么控制?线上出了问题怎么排查?
传统 MLOps 聚焦在模型训练、特征工程、模型版本管理,而 LLMOps 关注的是完全不同的命题------你通常不训练模型,而是在编排提示词、管理模型调用链、评估输出质量、监控成本和延迟。如果把 MLOps 比作造车工厂的产线管理,那 LLMOps 更像是管理一支远程司机的车队------你需要知道每一趟行程花了多少钱、走了什么路线、服务好不好。
读完这篇文章,你将获得:
- 对 LLMOps 核心组件的全局认知
- 了解 Prompt 管理、模型网关、评估体系和监控四大支柱
- 能够设计一套最小可用的 LLMOps 技术方案
二、LLMOps 全景图
在深入每个组件之前,先用一张全景图建立整体认知:
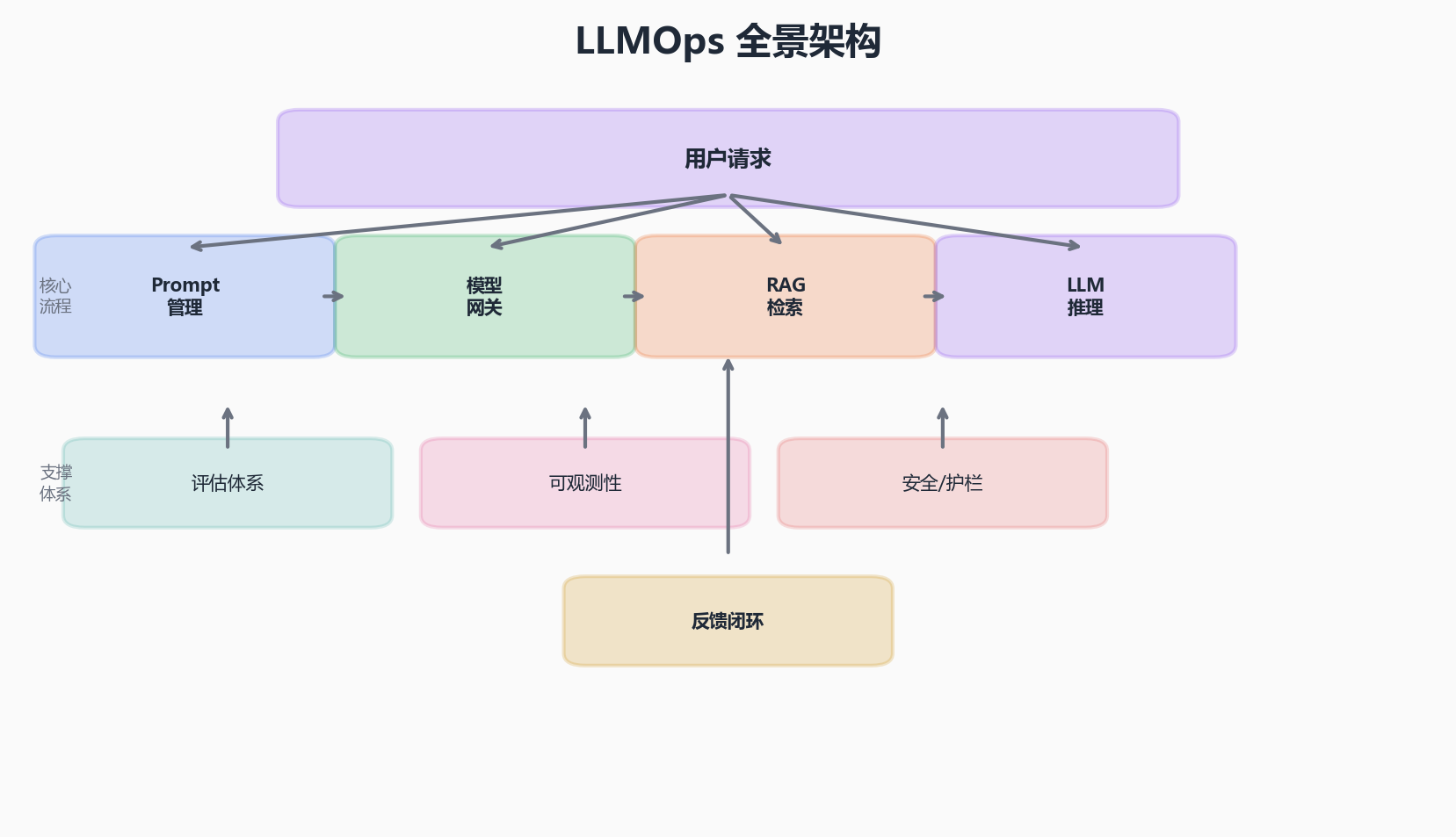
LLMOps 的生命周期通常包括以下几个阶段:
- Prompt 开发与实验:编写、版本化、A/B 测试 Prompt
- 模型服务化:通过统一网关接入多种模型(OpenAI、Claude、开源模型)
- 评估与测试:离线评估 + 在线评估,确保输出质量
- 可观测性与监控:Trace、Token 用量、延迟、错误率
- 反馈闭环:用户反馈 → 数据沉淀 → Prompt 迭代
下面我们逐一展开。
三、核心组件详解
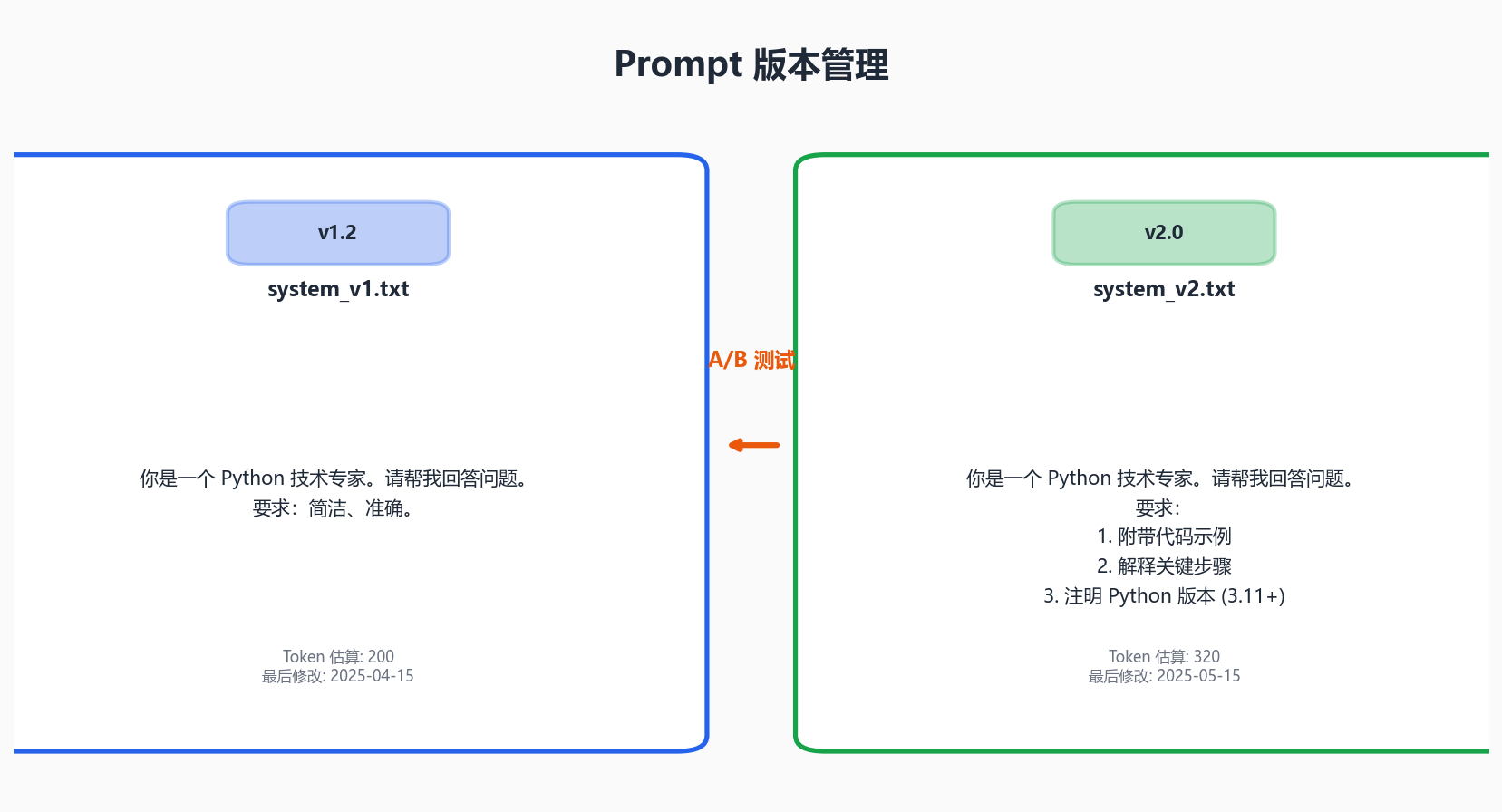
3.1 Prompt 管理:别再把 Prompt 写死在代码里
痛点 :很多团队起步时直接把 Prompt 写在 prompt = "你是一个..." 里,随着 Prompt 变多、变长、需要 A/B 测试,代码里散落着一堆魔法字符串,改一个词就得走一遍发布流程。
解决方案:将 Prompt 与代码分离,纳入版本管理。
项目结构示例:
prompts/
├── chatbot/
│ ├── system_v1.txt
│ ├── system_v2.txt
│ └── few_shot_examples.json
├── summarizer/
│ └── system.txt
└── eval/
└── test_cases.json关键实践:
- 语义化版本:Prompt 变更也应有版本号,能快速回滚。可以使用 Git 管理,配合 CI 自动部署
- A/B 测试:同一请求路由到不同 Prompt 版本,对比用户反馈或自动评分,用数据驱动 Prompt 迭代
- 变量模板:使用 Jinja2 或类似模板引擎,运行时注入用户输入、上下文等变量
python
# 示例:使用 Jinja2 管理 Prompt 模板
from jinja2 import Template
template = Template("""
你是一个{{ role }}。请根据以下{{ context_type }}回答问题。
上下文:
{{ context }}
用户问题:{{ question }}
要求:{{ requirements }}
""")
prompt = template.render(
role="Python 技术专家",
context_type="代码仓库",
context=retrieved_docs,
question=user_query,
requirements="回答简洁,附带代码示例"
)
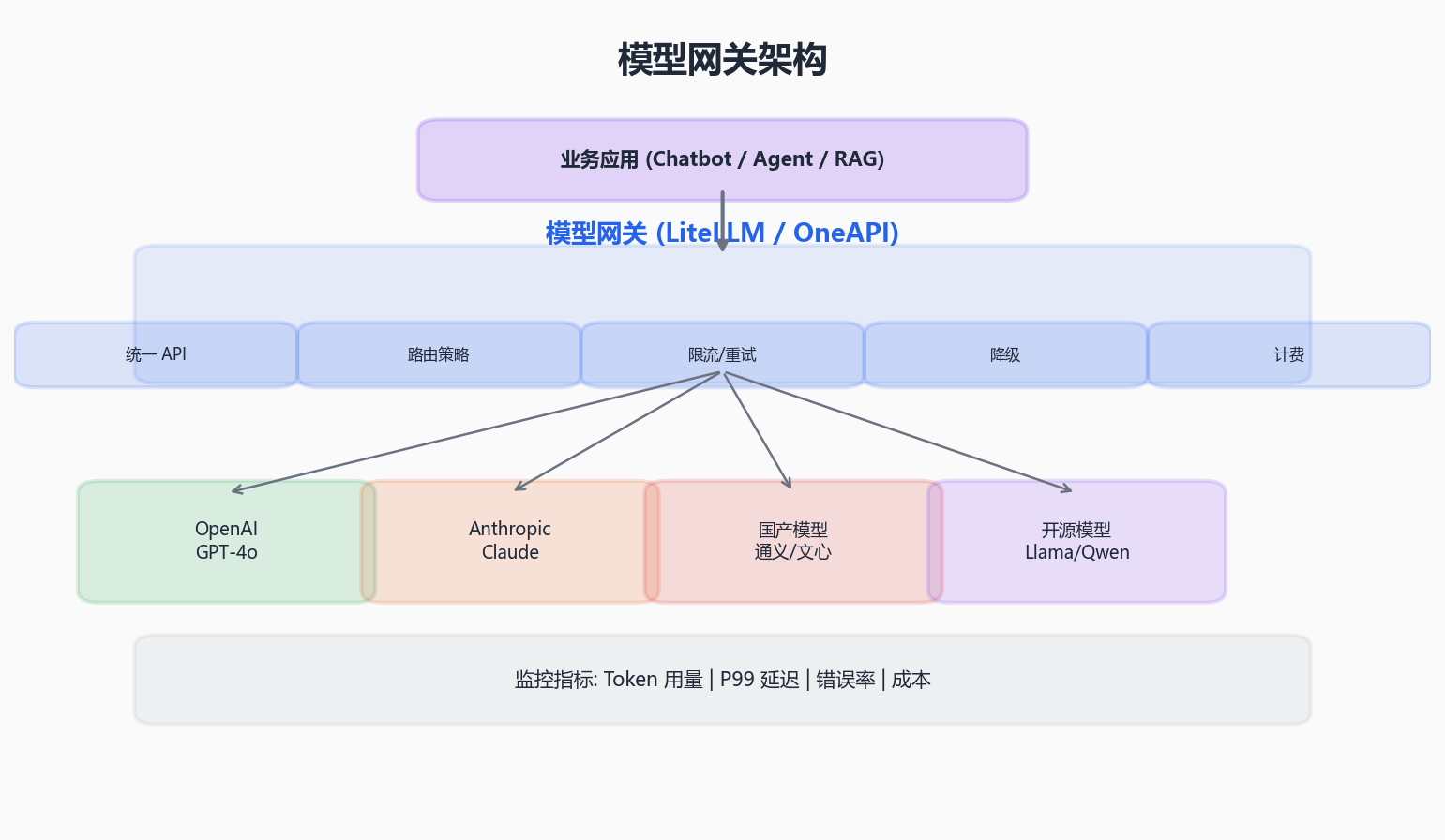
3.2 模型网关:统一入口,灵活切换
痛点 :业务代码直接调用 openai.ChatCompletion.create()、anthropic.messages.create(),每换一个模型就要改代码;想做 fallback、限流、负载均衡时,发现已经没有统一入口可加这些逻辑。
解决方案 :在应用和模型之间加一层模型网关。
网关的核心能力:
| 能力 | 说明 |
|---|---|
| 统一 API | 对上暴露 OpenAI 兼容接口,对下适配不同模型厂商 |
| 路由策略 | 按模型名、成本、延迟自动选择最优模型 |
| 限流/重试 | 防止打爆 API 配额,自动重试 + 指数退避 |
| 降级/Fallback | 主模型不可用时自动切到备用模型 |
| 计费追踪 | 记录每次调用的 Token 消耗和费用 |
主流选择:
- LiteLLM:开源,支持 100+ 模型,部署简单,社区活跃
- OneAPI:国内生态,支持多家国产模型(通义千问、文心一言等)
- 自建网关:基于 Nginx + Lua 或 Go 自研,适合有定制需求的团队
python
# LiteLLM 示例:统一调用不同模型
import litellm
# 调 OpenAI
response = litellm.completion(
model="openai/gpt-4o",
messages=[{"role": "user", "content": "你好"}]
)
# 切到 Claude,只改 model 参数
response = litellm.completion(
model="anthropic/claude-sonnet-4-6",
messages=[{"role": "user", "content": "你好"}]
)
# 自动 fallback 配置
litellm.completion(
model="openai/gpt-4o",
messages=[{"role": "user", "content": "你好"}],
fallbacks=["anthropic/claude-haiku-4-5"] # 主模型挂了自动切
)
3.3 评估体系:模型输出好不好,不能只靠"感觉"
痛点:上线前靠人工"跑几条看看",上线后靠用户投诉发现问题。这种方式既不可靠也不可扩展。
评估层次:
第一层:单元级评估(离线)
├── 断言式:输出长度、是否包含关键词、JSON 格式校验
├── 相似度式:与参考答案比较(BERTScore、Rouge-L)
└── LLM-as-Judge:用一个 LLM 给另一个 LLM 的输出打分
第二层:场景级评估(离线)
├── 测试用例集:覆盖边界情况、对抗样本
└── 回归测试:Prompt 变更后跑全量评测集
第三层:在线评估(生产)
├── 用户反馈:点赞/点踩、举报
├── 行为指标:采纳率(代码补全场景)、点击率(搜索场景)
└── 自动采样:采样线上请求做离线复评实操建议:
- 从 LLM-as-Judge 起步:成本低,覆盖率高,适合快速搭建
- 建立评测数据集:至少包含 50-100 条典型 query,覆盖 happy path 和 edge case
- CI 集成:每次 Prompt 变更自动跑评测,低于阈值不允许合并
python
# 简单的 LLM-as-Judge 评估示例
def evaluate_response(query, response, criteria):
judge_prompt = f"""
请对以下回答按标准评分(1-5 分):
用户问题:{query}
AI 回答:{response}
评分标准:{criteria}
返回 JSON 格式:{{"score": 整数, "reason": "评分理由"}}
"""
result = llm_call(judge_prompt)
return json.loads(result)
score = evaluate_response(
query="如何在 Python 中处理大文件?",
response=actual_output,
criteria="准确性、完整性、代码是否可运行"
)
3.4 可观测性:线上出问题,10 分钟定位还是 2 小时?
痛点:用户反馈"AI 回答质量变差了",但没有 Trace、没有日志,只能猜可能是 Prompt 改了、模型升级了、还是检索的上下文有问题。
LLM 应用的可观测性比传统后端更复杂,因为:
- 每次调用涉及多个环节:检索 → Prompt 拼接 → LLM 调用 → 后处理
- 需要追踪非确定性输出:同样的输入不一定产生同样的输出
- 成本维度是独有的:Token 消耗 = 真金白银
核心观测维度:
| 维度 | 关键指标 | 用途 |
|---|---|---|
| 调用链/Trace | 调用链路、每步耗时 | 定位瓶颈 |
| 质量 | 用户反馈评分、LLM-as-Judge 评分 | 发现质量劣化 |
| 成本 | Token 消耗、费用(按次/按用户) | 成本控制 |
| 安全 | 敏感信息泄露检测、注入攻击检测 | 安全审计 |
工具推荐:
- LangFuse(开源):Trace + 评估 + 成本 + Prompt 管理,一站式
- LangSmith(商业):LangChain 官方,生态集成好
- Phoenix(Arize):侧重质量评估和漂移检测
python
# LangFuse 集成示例(以 LangChain 为例)
from langfuse.callback import CallbackHandler
langfuse_handler = CallbackHandler(
secret_key="sk-lf-...",
public_key="pk-lf-...",
host="https://cloud.langfuse.com"
)
# 一行代码接入 Trace
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
chain = prompt | ChatOpenAI(model="gpt-4o")
result = chain.invoke(
{"input": "解释什么是 RAG"},
config={"callbacks": [langfuse_handler]}
)
# LangFuse 会自动记录:Prompt 内容、模型参数、
# Token 消耗、耗时、输出内容四、搭建最小可用的 LLMOps 流水线
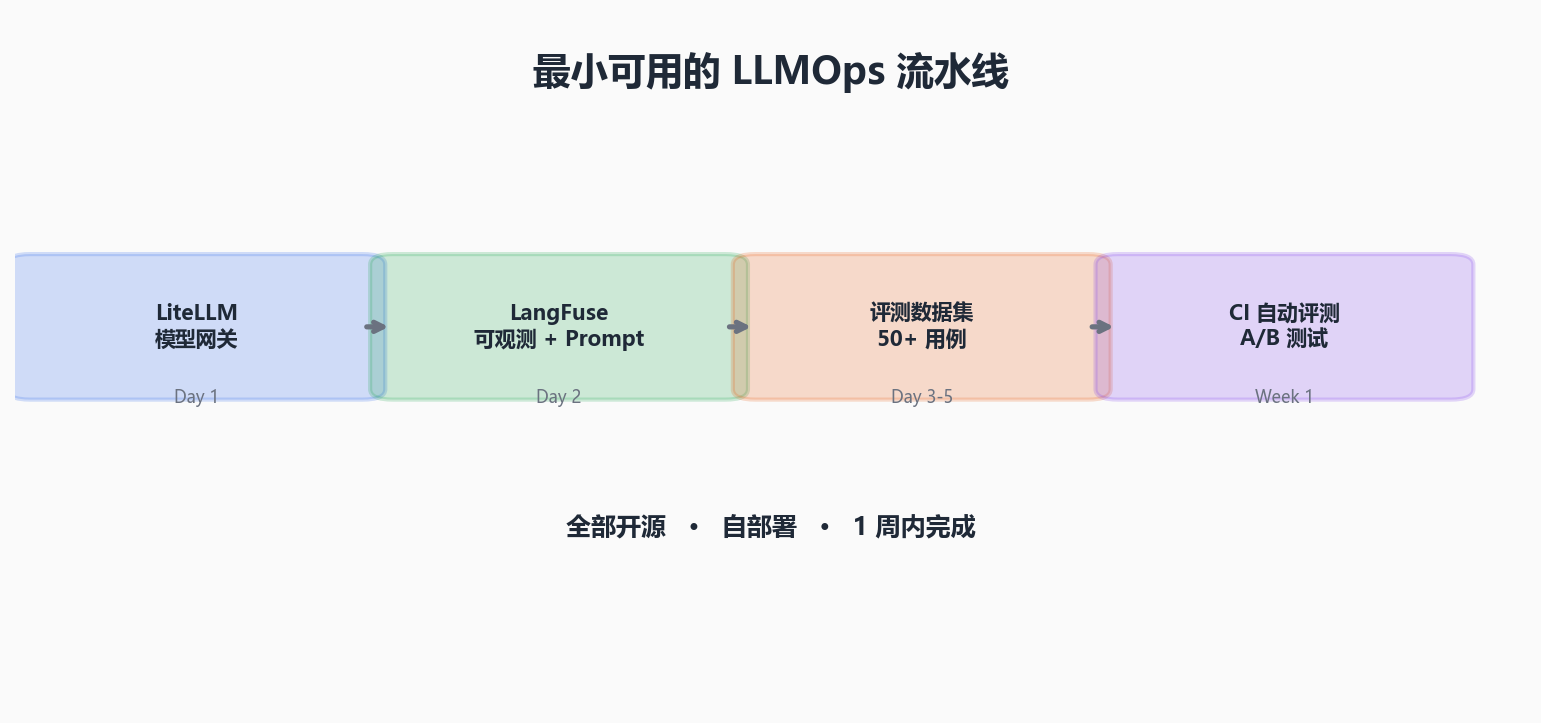
如果你现在就要从零搭一套 LLMOps,推荐最小组合:
LiteLLM(模型网关)
+ LangFuse(可观测 + Prompt 管理 + 评估)
+ 一组评测用例(50+ 条)
+ CI 自动跑评测起步步骤:
- 第 1 天:部署 LiteLLM 做网关,所有 LLM 调用走网关
- 第 2 天:接入 LangFuse,自动采集 Trace 和成本
- 第 3-5 天:整理 Prompt 模板、建立评测数据集
- 第 1 周结束:CI 中集成评测,开始 A/B 测试
五、常见问题
Q:小团队(2-3 人)需要 LLMOps 吗?
A:需要,但可以简化。至少做到:(1) Prompt 放 Git 管理;(2) 接入免费版 LangFuse 看 Trace;(3) 准备 30 条评测用例。这三件事的成本加起来不到半天,但能省下未来无数排错时间。
Q:LLMOps 工具这么多,选开源还是商业?
A:建议从开源起步。LangFuse 开源版能满足大多数需求;当团队规模 > 10 人或合规要求高时,再评估商业版或自研。
Q:微调模型也要 LLMOps 吗?
A:需要,但组件侧重不同。微调场景多了数据版本管理、训练实验追踪,更像传统 MLOps + LLMOps 的叠加。
六、总结
- LLMOps 不是 MLOps 的子集:它关注的不是训练流水线,而是 Prompt 迭代、模型调用编排和输出评估
- 四大支柱:Prompt 管理、模型网关、评估体系、可观测性------缺一不可
- 最小起步:LiteLLM + LangFuse + 评测数据集,一周内可搭建完成
- 评估是灵魂:没有自动化评估,Prompt 迭代就是盲飞
- 成本可观测是刚需:每个 Token 都是钱,看不见就管不了
LLMOps 还在快速发展期,工具的 API 和最佳实践每个月都在变。建议关注 LangFuse、LiteLLM 这两个项目的 Release Notes,它们基本代表了 LLMOps 社区的方向。