你好,我是小 G。拖了蛮久,来填坑了。
Spec Coding 很早之前就有群友提到说建议写一下。确实还蛮重要的,工作中能用到,面试也开始问了。
这里以我想的一个真实工作场景的例子作为开场。
上周和同事聊天,他问我还在折腾 Spec Coding 干嘛。原话大概是:"Claude Code 都能自己写代码了,你花时间写规范不是多此一举?"
我当时没忍住怼了一句:"AI 写出来的屎山代码,你来维护?"
他愣了一下。
说实话我理解他的想法。AI 写代码确实快,扔一句需求过去,几秒钟一个函数就出来了,跑起来还挺像那么回事。Demo、脚本、一次性页面,这么搞没毛病。
但问题是------你把这套玩法搬到一个多人协作、要长期维护的项目里,过两周再回来看那段代码,你大概率不想碰,也不敢碰。
因为需求里没写清的部分,AI 自己脑补了;边界条件你没提,它按"常见写法"猜了一个;你们团队的错误码格式、权限校验约定,AI 一个都不知道。它只是按照训练数据里出现频率最高的方案,给你拼了一段"看起来能跑"的代码。
这篇文章聊 Spec Coding 的核心思路,内容不少,建议收藏。通过本文你将搞懂:
- Vibe Coding 和 Spec Coding 的实际差别,以及什么时候该用哪个
- 完整的 Spec Coding 落地流程,从写需求到让 AI 按规矩执行
- Spec 在主流 AI IDE(Cursor、Claude Code、Copilot 等)里怎么配、怎么管、怎么防止 AI 越界
Vibe Coding 不是不能用
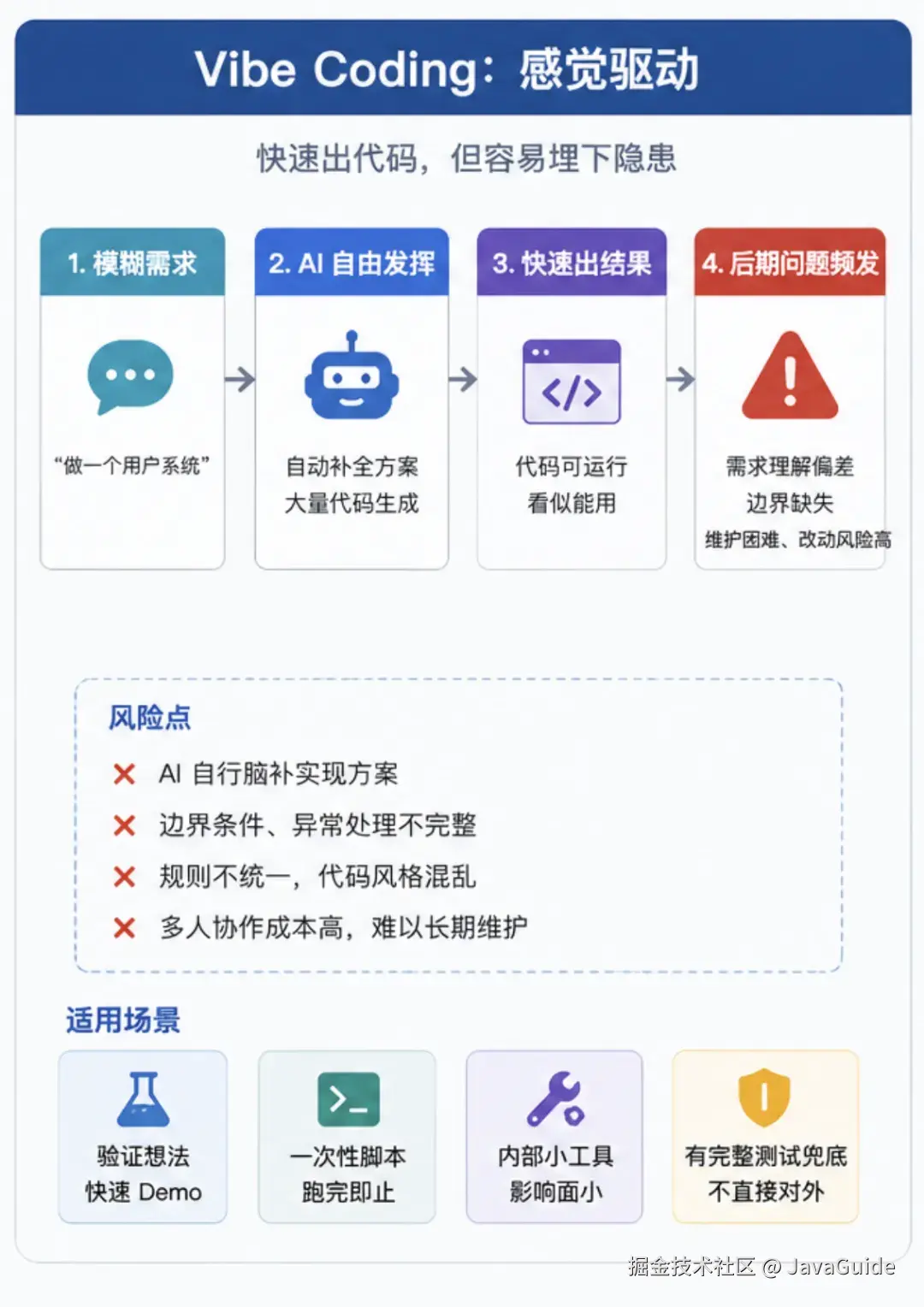
Vibe Coding(氛围编程),凭感觉走。给 AI 一句模糊的意图,它就直接开始输出代码。
Karpathy 最早提这个词时,说的也是那种把需求丢给 AI、顺着感觉不断调整、甚至暂时不太管代码细节的写法。
Vibe Coding 不是原罪。下面这些场景,用它反而很合适:
- 验证一个想法,先写个 Demo 看看效果
- 写一次性脚本,跑完就扔
- 做内部小工具,影响面很小
- AI 写完后,有完整测试兜底,而且不直接暴露给外部用户
这些情况下,硬写一大堆 Spec 反而是浪费时间。
真正的问题是:很多人验证完想法之后,顺手就把 Vibe 出来的代码推上了生产。
这就不一样了。
Demo 阶段你可以靠感觉走,因为错了就改,坏了就删。生产代码不行,它后面会接数据库、接支付、接用户数据、接别人的维护成本。你今天省下来的半小时,可能会变成后面几天的排查时间。
我的判断标准就一条: 这段代码要活多久?
- 两天就扔掉的脚本,Vibe 够了。写 Spec 反而拖效率。
- 3-5 天这种中间地带,可以写轻量 Spec。不用展开完整设计,只写关键约束和验收标准,半小时差不多能搞定。
- 超过一周的代码,只要需要别人维护、涉及数据持久化、接入外部接口,就别裸 Vibe。至少要把约束、边界和验收标准写清楚。
而且,很多时候搭配轻量级 Spec 也没问题,不需要太死板。
轻量 Spec 可以简单到这种程度:
diff
## 任务目标
实现一个订单导出接口,支持按时间范围导出 CSV。
## 关键约束
- 单次导出最多 5000 条
- 时间范围不能超过 31 天
- 必须校验用户权限,只能导出当前租户的数据
- 查询必须命中 order_tenant_time_idx 联合索引
- 导出失败要记录失败原因,不能只返回 unknown error
## 验收标准
- 正常导出 CSV,字段顺序符合产品约定
- 超过 5000 条时返回明确错误
- 越权租户数据不能被导出
- 单元测试覆盖空时间、越界时间、无权限、无数据四种场景Spec Coding 到底是什么
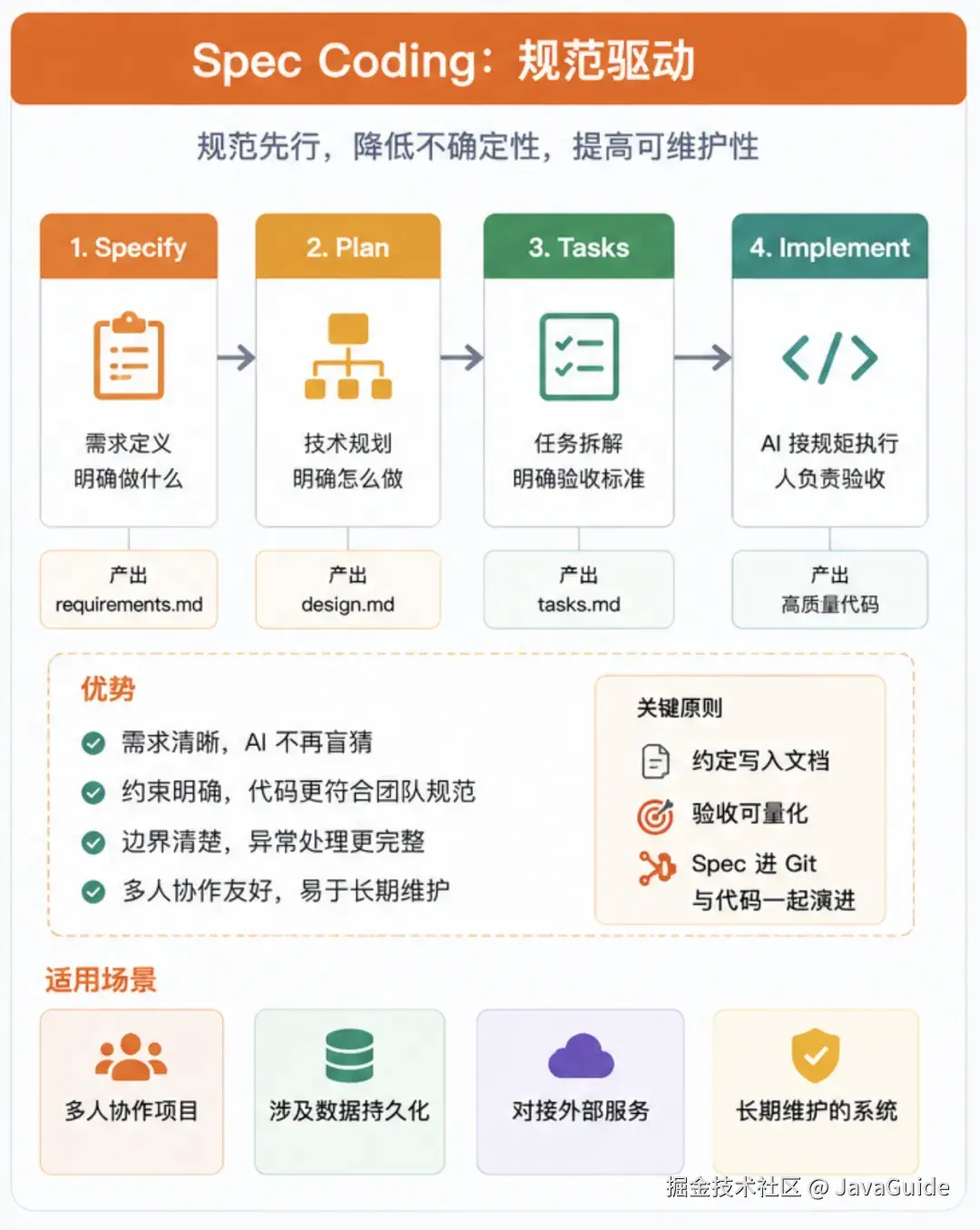
Spec Coding,直译过来叫规范驱动编程。简单来说就是:先把规范写清楚,再让 AI 干活。
平时让 AI 写代码,很多人会直接丢一句:
帮我做一个用户系统。
AI 当然能写,而且看起来还挺像那么回事。但问题也在这里:你没告诉它用户系统到底长什么样,它就只能自己猜。
用户怎么注册?邮箱能不能重复?密码怎么存?接口失败时返回什么格式?哪些功能这期不做?管理员有没有禁用用户的能力?这些东西如果一开始没写清楚,AI 不会停下来反问你,它大概率会先补一套自己觉得合理的方案。
Spec Coding 做的事情,就是把这些规则提前写下来。
这里的 Spec 不是随便写两句需求,而是一份 AI 能照着执行的技术约定。接口、数据结构、错误码、边界条件、安全要求、技术栈限制,甚至哪些操作不允许碰,都要写在里面。
它和 Vibe Coding 的差别,也就在这。
Vibe Coding 更像是你给 AI 一个大方向,然后让它自由发挥。代码生成出来以后,你再去验收、改 bug、补细节。短平快的小脚本这么干没啥问题,甚至很爽。
但项目稍微复杂一点,就容易出事。等你发现 AI 理解错了,代码已经写了一堆。你回头查,也很难说清楚到底是需求没讲明白,还是 AI 自己乱发挥。
简单总结下 Spec Coding 和 Vibe Coding 的差别:AI 的行为是由你定义的,还是由它猜的?
四步落地
一般会把 Spec Coding 拆成四步:Specify、Plan、Tasks、Implement。
| 阶段 | 干什么 | 产出 | 关键动作 |
|---|---|---|---|
| Specify | 产品定义 | requirements.md |
明确功能、用户、痛点,定"做什么" |
| Plan | 技术规划 | design.md |
定技术栈、架构、契约,定"怎么做" |
| Tasks | 任务拆解 | tasks.md |
拆成原子任务,写验收标准 |
| Implement | AI 执行 | - | AI 按 Spec 干活,人验收 |
理解起来其实很简单,核心就是先写清楚要做什么,再写清楚怎么做,然后拆任务,最后交给 AI 执行。
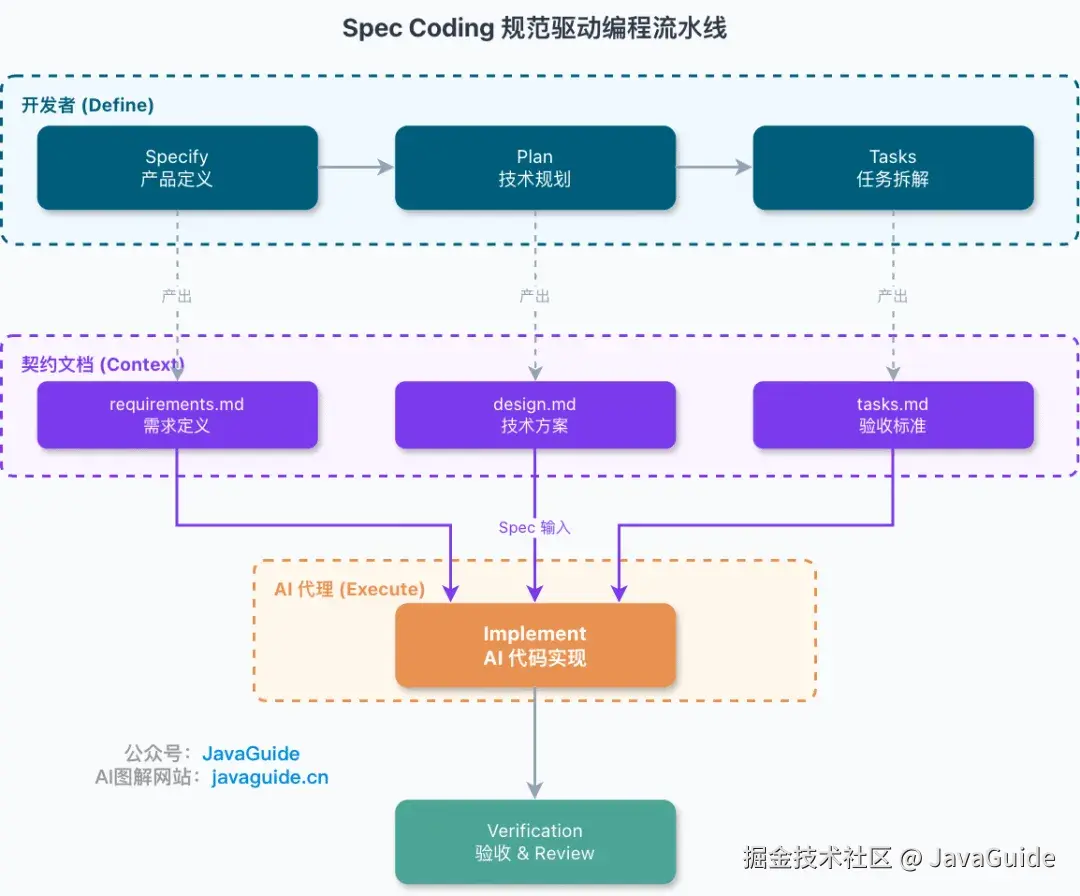
Specify:先搞清楚做什么
第一步是 Specify,产出一般是 requirements.md,或者叫 spec.md。
这一步有点像写 PRD,但面向的使用者是 AI。
所以,它不能只写方向,得把边界也写出来。
比如你写一句:
做一个用户系统。
人看着没问题,AI 看了就开始猜了:用户怎么注册?邮箱能不能重复?密码有啥要求?第三方登录做不做?管理员能不能禁人?被禁了数据怎么办?
你不写,它就自己定。
更稳一点的写法是:
支持邮箱注册和登录;邮箱必须唯一;密码长度至少 8 位;暂不支持第三方登录;管理员可以禁用用户;用户被禁用后不能登录,但历史数据保留。
这句话让 AI 知道哪些能做,哪些不能做,哪些边界不能碰。
Plan:敲定技术方案
第二步是 Plan,一般会落到 design.md 或 plan.md 里。
这一步很多人会跳过,觉得反正 AI 会写代码,让它自己发挥就行。
然后问题就来了。
你没说用哪个 Java 版本,它可能给你写 Java 8 的代码;你没说 Spring Boot 版本,它可能按旧写法来;你没说错误码格式,它就每个接口返回一套;你没说分层方式,它可能 Controller 里直接写业务逻辑;你没说表字段怎么命名,它也会按自己的习惯来。
所以 design.md 不用写得特别重,但几个关键约束得先定下来。
比如先写成这样就够用:
markdown
## 技术栈
- 语言: Java 21 (LTS)
- 框架: Spring Boot 3.2.x
- 数据库: PostgreSQL 16
- 缓存: Redis 7.x
## 架构设计
- 分层: Controller → Service → Repository
- 通信: REST API + gRPC(内部服务)
- 部署: Docker + Kubernetes
## 接口约定
- API 规范: OpenAPI 3.0
- 错误码: 统一格式 {"code": "USER_NOT_FOUND", "message": "..."}
- 日志格式: JSON,必须包含 trace_id你可能会想:这不就是设计文档吗?
确实有点像。
但区别在于,传统设计文档主要是给人看的。人看完知道大方向,剩下很多细节可以靠团队习惯补上。比如密码不能明文存、错误码要统一、日志里要带 trace_id,这些东西在成熟团队里通常不用反复强调。
AI 不一样。
你没写,它就猜。猜对了还好,猜错了就得你回来返工。
拿密码存储举个例子。你只写一句"登录要安全",对人来说可能够了,但对 AI 来说太宽了。它也许知道不能明文存密码,也可能给你整一个看着像安全、实际不该用的方案。
更稳的做法是把规则写死:
密码使用 bcrypt 哈希存储。
bcrypt cost 默认设置为 12,可根据服务器性能在 10-14 之间调整。
bcrypt 自带随机盐,数据库只保存哈希值,不保存明文密码。这段看着有点细,但它把"安全"这个大词拆成了 AI 能执行的几条具体规则。
错误处理也一样。别写"接口失败时返回友好提示",这句话基本没约束力。AI 可能这个接口返回 error,那个接口返回 message,还有的地方直接抛异常。
直接写清楚:
css
{
"code": "USER_NOT_FOUND",
"message": "用户不存在",
"trace_id": "xxx"
}再补一段状态码约定:
参数错误返回 400。
未登录返回 401。
无权限返回 403。
资源不存在返回 404。
邮箱重复、用户名重复这类冲突返回 409。这样 AI 至少知道该往哪个方向写。
说到底,design.md 主要是为了减少 AI 自己补设定。你把技术栈、接口格式、错误码、日志、并发、安全这些规则提前写好,后面让 AI 写代码时,它就不太容易跑偏。
Tasks:任务要小到能验收
第三步是 Tasks,一般会写到 tasks.md 里。
这里不要一上来就让 AI "完成用户模块"。这个范围太大了。注册、登录、查询、禁用、权限、参数校验、异常处理、单元测试,全都塞在一个任务里,AI 很容易写着写着漏东西。最后你看代码时,还得一项一项往回补。
但也别拆得太碎。创建 UserDTO、添加 email 字段、写一个空的 Service 方法------这种任务看起来很细,实际会把人折腾死。你维护任务列表的时间,可能比让 AI 写代码还长。
我比较喜欢的粒度是:一个 Task 对应一个 API、一张表的核心操作,或者一个能独立验收的小功能。
比如用户注册接口,可以这么写:
ini
### Task-001: 用户注册接口
描述:实现用户注册,包含参数校验、密码加密和用户入库。
验收标准:
- [ ] POST /api/v1/users 成功时返回 201
- [ ] 密码使用 bcrypt 加密后存储
- [ ] 邮箱唯一,重复注册返回 409
- [ ] 返回体必须包含 user_id、email、created_at
- [ ] 分支覆盖率(branch coverage)不低于 80%
预估工时:2h这里真正值钱的是验收标准。"保证安全""代码优雅""性能要好"------这种话写了跟没写差不多,AI 不知道你心里的安全到底指什么,优雅要优雅到什么程度。
但密码用 bcrypt,重复邮箱返回 409,返回体里有 user_id、email、created_at,分支覆盖率不低于 80%------这些东西都能跑测试验证,不用靠感觉。
覆盖率阈值别机械套。纯逻辑模块做到 80% 以上通常合理;如果涉及大量外部依赖、异步流程和复杂 mock,可以放宽到 60-70%,把重点放在关键分支组合有没有覆盖。
Implement:让 AI 干活
提示词不用搞得很玄学,直接把相关 Spec 塞进去就行:
css
请根据以下 Spec 实现 Task-001。
需求说明:
[粘贴 requirements.md 相关段落]
技术约束:
[粘贴 design.md 相关段落]
任务验收标准:
[粘贴 tasks.md 里的 Task-001]这里有个坑:不要把所有 Spec 一股脑塞进上下文。
单次会话里,我会优先放三类内容:
- 全局约束,比如代码风格、错误码格式、日志规范;
- 当前任务的需求说明;
- 当前任务的验收标准。
其他内容按需补,不要为了"完整"把所有文档都贴进去。
一般来说,单次输入控制在 3000-8000 tokens 会更稳一点,大致相当于 1-2 份 Spec 文档,再加 1-2 个相关代码文件。超过这个范围,就拆会话。
别指望模型在一个特别长的上下文里什么都顾得上。上下文越长,关键信息越可能被淹在中间,最后反而漏掉最重要的约束。
我自己会遵守三条原则:
第一,约定写进文档,不要只写在聊天里。聊天记录下次很可能接不上,文档才是可以复用的上下文。
第二,验收标准能量化就量化。"高性能"没法验收,QPS > 1000、P95 < 200 ms、branch coverage >= 80% 才能验收。
第三,Spec 要进 Git,跟代码一起走。代码变了,Spec 也要改。不然后面继续让 AI 开发,它拿到的就是一份过期说明。
这一步走通后,AI 不会突然变聪明,但乱猜的空间会小很多。
接下来还有个很现实的问题:这些 Spec 到底放哪里,怎么让工具每次都读到?
Spec 在 AI IDE 里怎么落地
写完 Spec 之后,有个问题经常被忽略:这些文件到底放哪里?怎么让 AI 自动读到?
主流工具都有自己的规范文件机制:
| 工具 | 规范文件位置 | 作用域 | 加载方式 |
|---|---|---|---|
| Cursor | .cursor/rules/*.mdc(新版)或 .cursorrules(旧版) |
项目级 / 全局 | 新版支持 frontmatter,可设 Always apply 或按文件 glob 自动附加 |
| Claude Code | CLAUDE.md(根目录和子目录均可) |
项目级 / 目录级 | 进入目录自动加载 |
| GitHub Copilot | .github/copilot-instructions.md |
仓库级 | 自动注入每次请求 |
| Windsurf | .windsurfrules |
项目级 | 自动加载 |
| Aider | CONVENTIONS.md(仓库根目录) |
项目级 | 通过 --read CONVENTIONS.md,或在 .aider.conf.yml 里用 read: 自动加载 |
到这里,另一个问题也会冒出来:Cursor、Claude Code、Copilot 这些是日常写代码的入口,那 Superpowers、Spec-Kit、Open Spec、Kiro、BMAD-METHOD 这些专门围绕 Spec Coding 的工具,到底该怎么选?
这个问题展开会比较长,我准备放到下一篇单独聊。这里先把 Spec 怎么写、怎么放、怎么管住 AI 说清楚。
知道放哪之后,还有一个问题:哪些 Spec 每次都注入,哪些按需带上?
实际操作中,我一般分成两层。
几乎每个会话都要带上的(必须注入):
- 技术栈:版本和关键库写明,比如 Go 1.21 + Gin + GORM + PostgreSQL 14。别让 AI 自己猜版本号。
- 代码风格:贴一段 150-200 行的示例代码,展示命名、错误处理、注释、返回格式。别只写抽象原则,一段参考实现比十条规则管用。
- 边界条件:用三色标签(后面会说)划清楚什么能做、什么要问、什么绝不能碰。
这些放工具的 always-on 规则文件里,每次会话自动注入。
当前任务相关时才带的(按需注入):
- 项目愿景:一两句话说清为啥做这个项目,比如"把用户服务从单体拆出来,用 Go 重写,API 兼容"。新任务开始时带一次就行。
- 命令清单 :列出 build、test、run 命令,比如
make build、go test ./...。有执行任务时带上。 - 目录结构:树状图说清代码、测试、文档分别放哪。涉及新增文件时才需要。
- Git 规范:分支名、commit message、PR 要求。涉及 Git 操作时带上。
这么分的原因很直接:全局约束几乎每次都要遵守,值得常驻。其他的按任务加,避免上下文里堆太多不相关的内容。Spec 塞越多,AI 反而越容易漏掉真正重要的那几条。
三色标签:AI 能干什么、不能干什么
AI 遇到拿不准的操作时,到底该自己决定还是停下来问你?
三种颜色,三种权限。
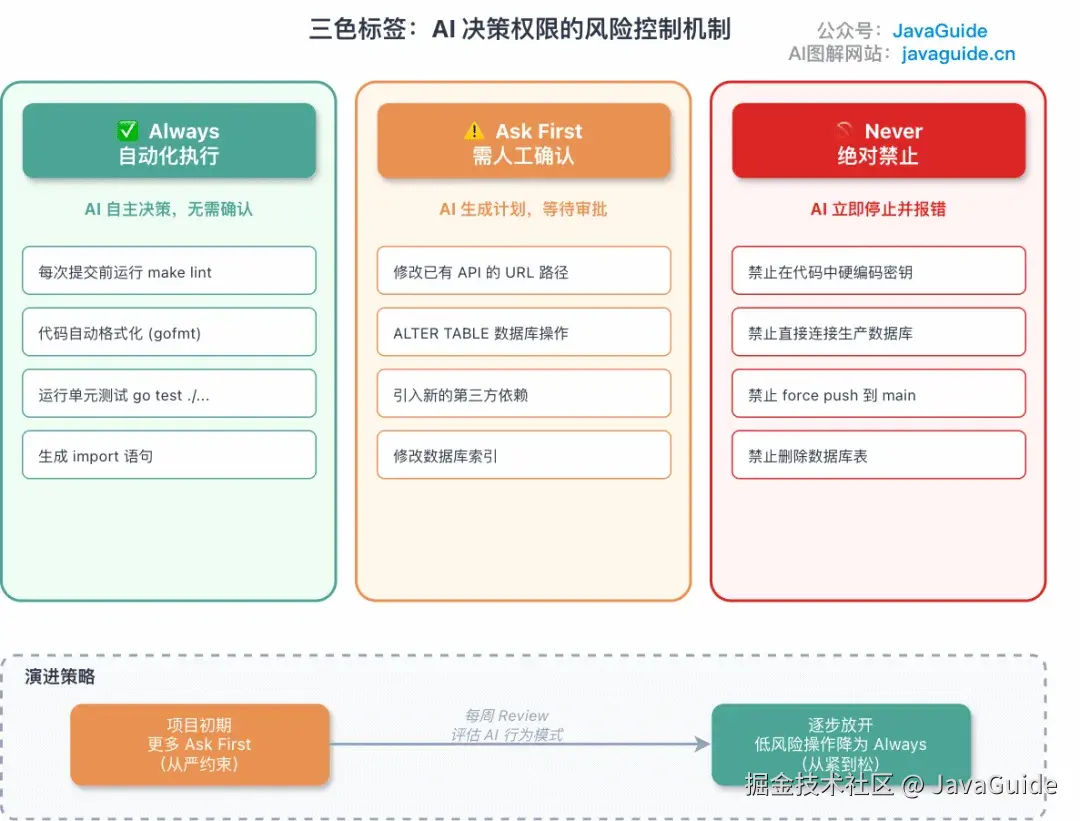
- ✅ Always(自动执行) :代码检查、测试、格式化这些,AI 自己拍板就行。比如提交前自动跑
make lint。 - ⚠️ Ask first(需确认):可能影响其他模块的变更,AI 出方案等你审。改数据库索引、改 API 路由这种就属于这类。
- 🚫 Never(绝对禁止):直连生产库、提交密钥、删线上数据。AI 碰到就必须停,报错。
落地的时候有几件事容易忽略。
刚开始宁严勿松。 Ask First 多放点,跑一周后看哪些操作 AI 每次都做对了,再放到 Always。
规则必须写具体。 "重要变更需确认"这句话 AI 没法执行,它不知道什么算"重要"。得写成"修改已有 API 的 URL 路径需确认"。"小心操作数据库"也不行,要写"ALTER TABLE 操作需确认"。
Never 规则不能只靠 AI 自觉。 只在文档里写"禁止直连生产库",并不能真的拦住它。AI 不会主动检查自己的输出是否违规。Never 规则需要多层防线:
- Spec 声明:影响 AI 生成倾向,但拦不住
- 配置模板 :
.env.example里不放真实密钥,AI 就没东西可复制 - Pre-commit hook:正则扫密钥硬编码、生产环境连接串,提交时自动拦截
- AI IDE 配置 :
.cursorignore阻止 Cursor 读取.env.production之类的文件
越重要的 Never 规则,越要推进到 CI 层做硬性检查。停在"文档里有写"这一步,迟早出事。
每周回头看一次。AI 是不是动不动就停下来问?那 Ask First 里有些操作可以放行了。AI 有没有偷偷干不该干的事?有就补 Never。项目里有没有冒出新的敏感操作?加进去。
项目大了,Spec 怎么管
小项目 Spec 少,手动往上下文里丢就行。模块多了之后全塞上下文就废了,AI 看着一堆和当前任务无关的约束,反而更容易跑偏。
按规模选策略。
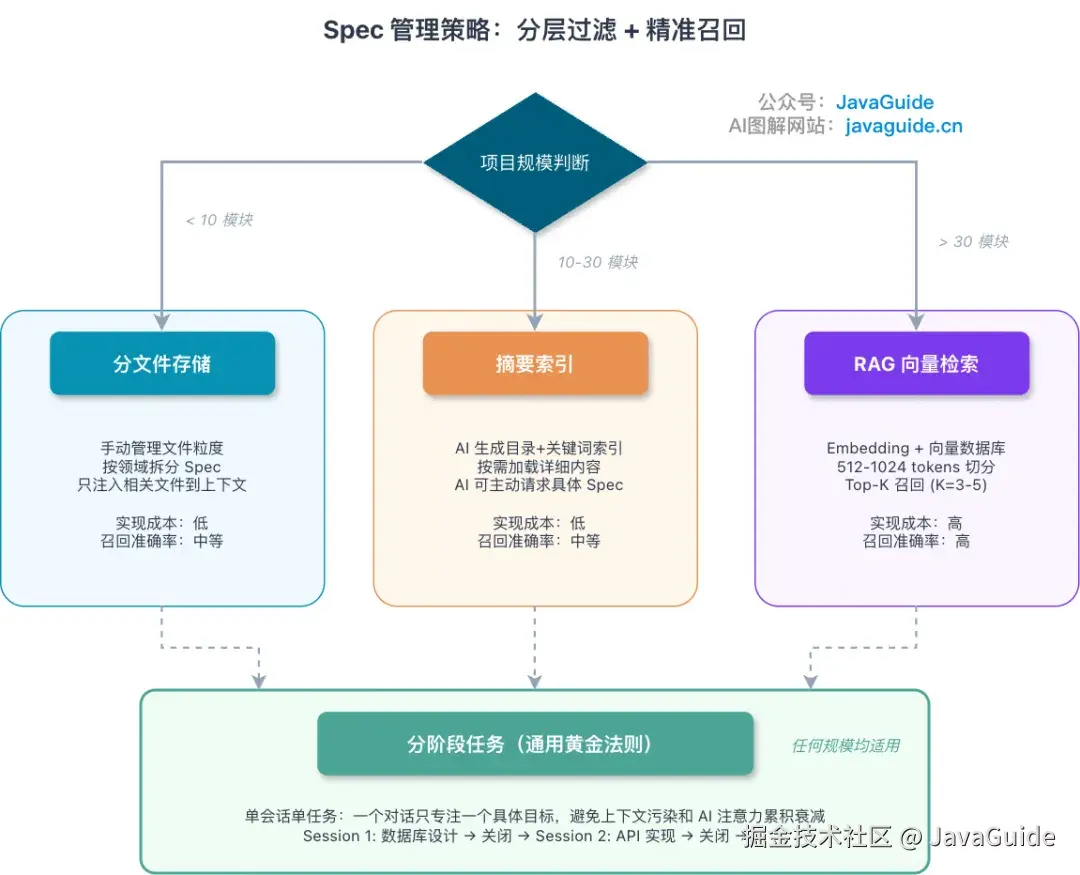 Spec 管理策略:分层过滤 + 精准召回
Spec 管理策略:分层过滤 + 精准召回
10 个模块以内:分文件存储
按领域拆就行:
csharp
specs/
├── global/ # 全局约束
│ ├── conventions.md # 代码规范
│ └── architecture.md # 架构概览
├── backend/ # 后端规格
│ ├── api/
│ ├── service/
│ └── persistence/
├── frontend/ # 前端规格
└── shared/ # 共享契约
└── dto.md每次只把当前任务相关的两三个文件丢进去,别贪多。
10-30 个模块:摘要索引
手动挑文件开始累了,就让 AI 先生成一份目录加关键词索引:
bash
## Spec 索引
- [数据库设计](specs/db/schema.md) - 关键词: PostgreSQL, 索引优化
- [用户 API](specs/backend/api/user.md) - 关键词: REST, JWT, 鉴权
- [订单服务](specs/backend/service/order.md) - 关键词: 事务, 幂等需要细节时让 AI 主动来要,不用全量灌进去。
30 个模块以上:RAG 向量检索
手动选文件不现实了,得上 RAG。Embedding 模型选 text-embedding-3-small/large,向量库看规模:Chroma 适合本地,Pinecone 适合云端,Milvus 适合企业级。Chunk 策略按语义单元切,一个 Task 或一个 API 定义为一个 chunk,默认控制在 512-1024 tokens 之间。Top-K 召回 3-5 条,加相似度阈值 > 0.7。
但十个模块的项目搞向量库,纯属给自己找事。什么时候人工选上下文开始痛苦了,什么时候再上。
不分规模都管用的一条:单会话单任务
bash
Session 1: 数据库设计
├── 输入: global/conventions.md + backend/db/
├── 输出: 完成实体设计
└── 关闭会话
Session 2: API 实现
├── 输入: Session 1 产出 + backend/api/
├── 输出: 完成 Controller
└── 关闭会话上下文干净,AI 就不会被前面任务的边角料带跑。这条比什么花哨的检索策略都管用。
领域知识为什么这么重要
AI 训练数据再多,也不知道你项目里那些特定的规则,你得主动告诉它。
举个例子:你做了一个商城项目,其中有一个规则是优惠券和秒杀不能叠加。这个规则你不写进 Spec,AI 很可能就把两个折扣都算上了。代码能跑,测试也可能过,但业务直接错了。
这类知识一般可以分成几种:
- 业务规则:优惠券和秒杀不能叠加,同一用户每天只能领取一次奖励
- 技术约束:订单分页必须走指定联合索引;深分页(> 100 页)改用游标,禁止全表扫描
- 历史债务:第三方上传接口只支持 5 MB,超过就会报错,所以代码里要提前校验
- 性能基线:单表查询控制在 50 ms 内;关键接口超过 200 ms 要考虑降级或兜底
这些东西是 AI 写代码时的边界。
现在很多 Spec-Driven Development 的思路就是把 Spec 从"写给人看的文档"变成"约束 AI 生成代码的规则"。
不要认为 Spec 只是前期用用,后续实现、校验和维护时都需要。
不过,只把规则写进去还不够,最好再加一段自检清单。因为 AI 很容易写完功能就结束,不会主动回头确认这些隐含约束。
完成自检清单
任务写完之后,不要让 AI 直接说一句"已完成"。
至少让它按清单自己过一遍。比如完成 Task-001 后,必须逐项确认:
- 所有 API 错误返回都符合统一格式
- 数据库查询命中了指定联合索引
- 优惠券和秒杀的互斥逻辑已正确实现
- 单元测试覆盖了空值、越界、并发等边界场景
- 分支覆盖率(branch coverage)>= 80%
- 圈复杂度 <= 10
如果有哪一项没法确认,不能糊弄过去,要把原因写出来。
AI 很容易把代码写完当成任务完成。可真实项目里,功能能跑只是第一步,错误格式、索引命中、边界测试、复杂度控制,这些才是后面少背锅的地方。
多代理协作的坑
有人会问:一个 AI 不够用,多搞几个行不行?
可以,但坑比你想的多。
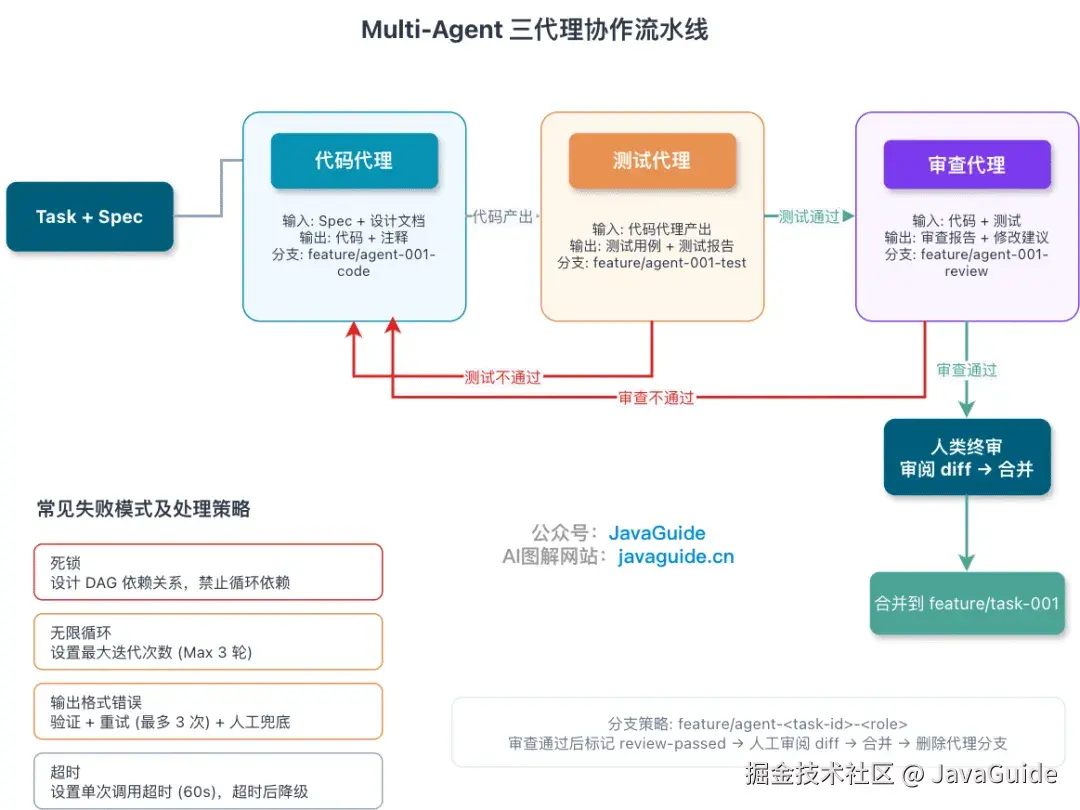 Multi-Agent 三代理协作流水线
Multi-Agent 三代理协作流水线
三代理协作的思路是代码、测试、审查各管一段,流水线推进。代码代理接到 Task 写功能,写完交给测试代理出用例跑测试,通过后再交给审查代理看代码质量,最后人类终审合并。
有个坑必须提前说清:测试代理在自己的分支上写测试,但被测代码在代码代理的分支上。这两个分支是平行的,测试代理要么先 merge 代码分支,要么根本跑不起来。
两种能跑通的模式:
串行同分支(推荐起步)。 三个代理在同一个 feature 分支上按顺序 commit,用 commit message 前缀区分角色。简单,没有合并冲突,适合大多数项目。
sql
git commit -m "[code] implement user registration API"
git commit -m "[test] add unit tests for user registration"
git commit -m "[review] fix null check in email validation"链式继承(代理能力已验证后)。 测试代理从代码分支 checkout,审查代理从测试分支 checkout,最后从审查分支 merge 回主线。分支之间是继承关系而不是平行关系,每个代理都能看到前一个代理的产出。
多代理翻车的场景不少:死锁(A 等 B、B 等 A,设计时确保依赖是 DAG)、无限循环(代理自我迭代停不下来,设最大轮次 Max 3)、输出格式错误(JSON 解析失败,加校验和重试,最多 3 次)。提前设好这些兜底,能避开大部分问题。
老实说,多代理这块我自己也还在摸索,目前的经验是串行同分支模式能覆盖八成场景,复杂编排除非团队有人专门维护,否则翻车概率不低。
Spec 不是写完就扔的
跑了几个项目后,有几个习惯固定下来了。
渐进细化。 别想着一口气写出完美 Spec。先写高层大纲,让 AI 把骨架跑起来,再一个模块一个模块补细节。
模块化组织。 API、数据库、样式规范、错误码、权限规则各一个文件。每次只给 AI 当前任务用得到的上下文。
持续迭代。 每次 Code Review 发现问题,或者 AI 又把同一个坑踩了一遍,回去改 Spec。只改代码不改规范,下次照样犯。
这里有个高频翻车场景值得特别说一下:Task-001 完成时 Spec 规定错误格式是 {"code": "USER_NOT_FOUND", "message": "..."},两周后 Spec 更新加了 trace_id 字段,但 Task-001 的代码已经没人管了。规范和实现就这么悄悄跑偏了。
应对办法:Spec 变更时做影响范围评估。可以在每个 Spec 文件里维护一个"依赖此文件的模块"列表,Spec 更新时主动触发受影响模块的回归测试。CI 流水线里加一条判断:Spec 文件有变动,自动跑相关模块的测试。
分享几套 Spec 模板
我常用的就这三种,按场景选一个就行。
模板一:OpenAPI 风格,适合 API 开发
markdown
## API:POST /api/v1/users
### 基本信息
- **端点**:`/api/v1/users`
- **方法**:POST
### 请求参数
| 字段 | 类型 | 必填 | 约束 | 示例 |
| -------- | ------ | ---- | --------------------------- | ---------------- |
| email | string | 是 | 邮箱格式 | user@example.com |
| password | string | 是 | 8-32 字符,包含大小写和数字 | - |
### 响应格式
- **201 Created**:用户创建成功
```json
{"id": "uuid", "email": "user@example.com", "created_at": "..."}
```
- **409 Conflict**:邮箱已存在
```json
{"code": "EMAIL_ALREADY_EXISTS", "message": "Email already exists"}
```
### 验收标准
- [ ] 密码用 bcrypt,cost=12
- [ ] 邮箱唯一性由数据库唯一索引保证
- [ ] 分支覆盖率(branch coverage)>= 80%模板二:Gherkin 风格,适合 BDD
vbnet
Feature: 用户登录
Scenario: 使用有效凭据登录
Given 用户已注册邮箱 "test@example.com" 和密码 "Password123"
When 用户提交登录请求
Then 返回 200 状态码和 JWT token
And token 有效期 24 小时
Scenario: 使用无效密码登录
Given 用户已注册邮箱 "test@example.com"
When 用户用错误密码提交登录
Then 返回 401
And 错误信息为 "Invalid credentials"
And 不暴露具体是邮箱还是密码错模板三:Checklist 风格,适合代码审查
ini
## Code Review Checklist
### 功能性
- [ ] 实现符合 Spec 描述
- [ ] 边界条件已处理:空值、越界、并发
- [ ] 错误处理完善
### 质量
- [ ] 函数长度 <= 50 行
- [ ] 圈复杂度 <= 10
- [ ] 无重复代码(DRY)
### 安全
- [ ] 无敏感信息硬编码
- [ ] 输入已验证/转义
- [ ] 权限检查已加踩过的坑
说几个我自己踩过的。
约束写太死了,AI 连正常的灵活性都没有。比如你把 Service 层每个方法签名都定好,AI 连个参数名都不敢改。Spec 定的是边界,不是逐行伪代码。
反过来,约束写少了更常见。关键边界没定义,AI 就自己猜。猜对了算运气,猜错了算日常。我有一个项目,AI 用了 MD5 存密码,就是因为 Spec 里没写用什么加密算法。
Spec 改了没同步,这个最隐蔽。代码和文档慢慢就跑偏了,AI 下次拿到的还是旧版规范,写出来的代码自然也对不上。
还有一个:只写不验。Spec 写了一大堆,但没接到 CI 里,最后变成形式主义。写完没人检查,跟没写差不多。
最重要的是,一定一定一定要上 Git,多多小步提交,懂得都懂!