文档说明
整合基础、核心语法、动态 SQL、缓存、高级特性、源码、生态整合、生产调优、避坑面试全知识点,无遗漏全覆盖,可直接保存离线使用
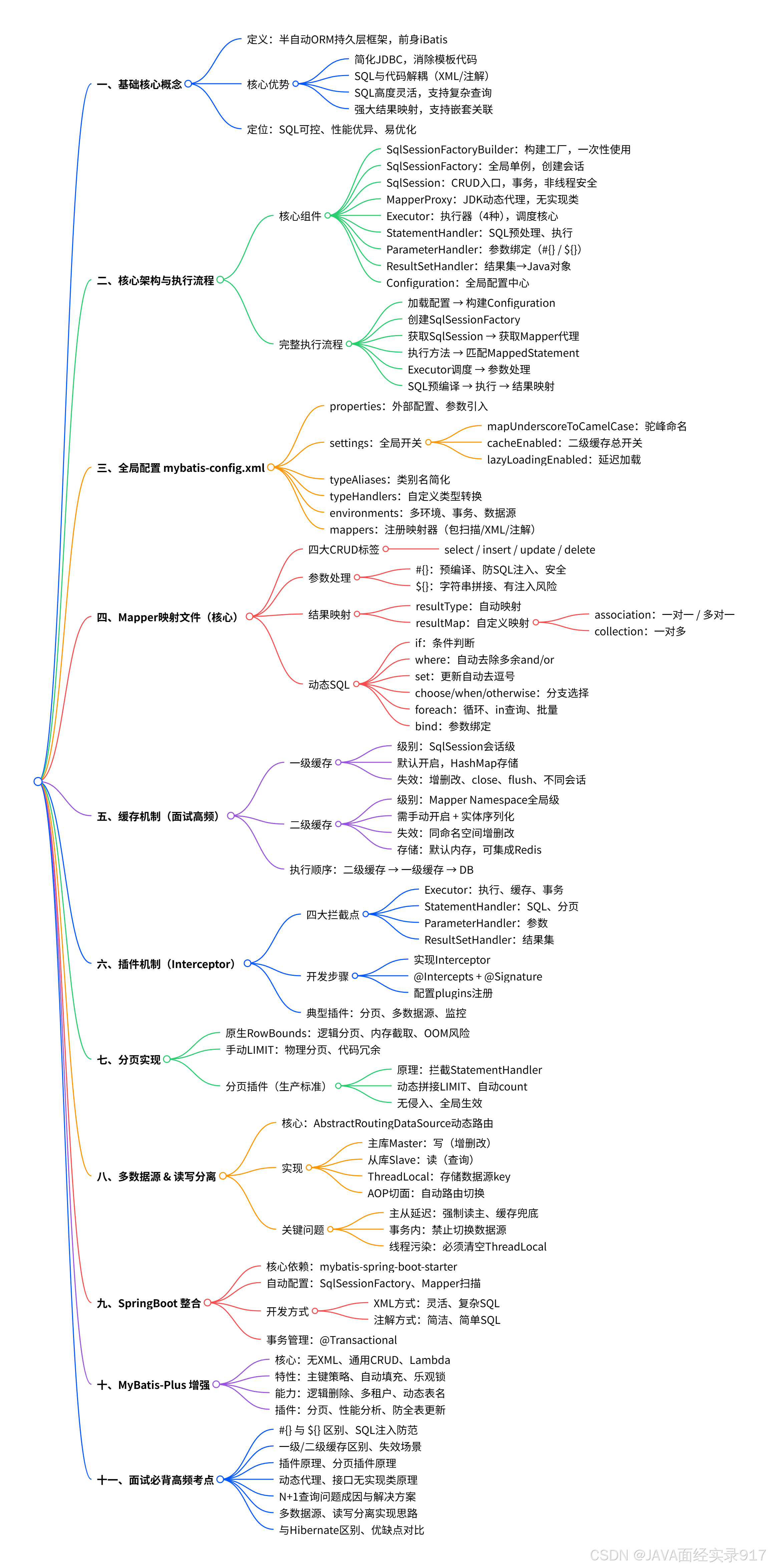
目录
-
基础认知与环境搭建
-
全局配置核心要点
-
参数传递与 SQL 语法
-
结果集映射体系
-
动态 SQL 全套语法
-
缓存机制原理与使用
-
高级拓展特性
-
插件拦截器机制
-
核心源码架构
-
生态框架整合
-
逆向工程开发工具
-
生产调优与实战坑点
-
高频面试核心考点
MyBatis 全体系思维导图(高清文字版)
一、基础认知与环境搭建
1. 框架定位
MyBatis 是一款**>轻量级、半自动化、开源的 Java 持久层ORM框架**,专注于数据库操作与代码解耦,摒弃了JDBC硬编码的冗余繁琐,同时规避了全自动ORM框架的笨重与灵活性不足问题,是目前企业Java项目主流的持久层解决方案。
一、核心核心特性
-
半自动化ORM:实体与数据库字段自动映射,SQL语句由开发者手动编写,兼顾开发效率与SQL可控性
-
SQL与代码解耦:支持XML/注解两种方式管理SQL,绝大多数复杂SQL可独立配置在XML文件中,业务代码更简洁
-
轻量无侵入:框架体积小、依赖少、无需侵入业务代码,接入简单、移植性强
-
高度灵活:支持自定义映射、动态SQL、插件扩展,适配复杂业务、多数据库、读写分离等各类场景
二、主流持久层框架精准对比
-
原生JDBC:底层原生操作,需手动注册驱动、创建连接、编写硬编码SQL、手动封装结果集,代码冗余、极易出错、存在SQL注入风险,仅用于底层学习,不用于项目开发
-
Hibernate(全自动ORM):完全屏蔽SQL,通过对象操作数据库,开发效率高,但SQL不可控、查询冗余、性能调优困难,不适合复杂业务与大数据场景,目前企业基本淘汰
-
JPA:基于Hibernate封装的规范,通过方法名、注解自动生成SQL,轻量化便捷,但复杂多表查询、动态条件查询适配性差,灵活性不足
-
MyBatis :折中方案,可控性、灵活性、性能、开发效率均衡,适配绝大多数企业级业务,是互联网、传统项目的首选持久层框架
三、适用场景
-
复杂业务系统:多表联查、动态条件查询、批量操作、自定义复杂SQL场景
-
高性能需求系统:需要精准优化SQL、控制查询粒度、规避冗余查询的项目
-
多数据库适配、读写分离、分库分表的分布式项目
四、框架短板
-
基础CRUD需要手动编写SQL,相比JPA原生语法更繁琐(可通过MyBatis-Plus补齐短板)
-
原生无自动分页、逻辑删除、乐观锁等工程化特性,需依赖插件或自定义开发
2. 核心四大组件(完整版 · 含原理+生命周期+面试点)
MyBatis 整个运行体系完全依托四大核心组件运转,四者层层依赖、各司其职,是源码阅读、面试必考核心,也是理解 MyBatis 工作流程的基石。
① Configuration 全局配置类(全局唯一)
-
核心作用 :MyBatis 的总容器,加载、存储、管理所有全局配置信息。
-
存储内容:全局设置、别名、插件、环境配置、数据源、事务工厂、所有 Mapper 映射信息、SQL 节点、缓存配置。
-
生命周期 :项目启动加载一次,全局常驻、单例复用。
-
底层本质:解析 XML/注解配置后,将所有配置封装为 Java 对象,贯穿整个 MyBatis 生命周期。
-
面试要点:所有配置最终都会汇聚到 Configuration,不存在配置散落情况。
② SqlSessionFactory 会话工厂(全局单例)
-
核心作用 :生产 SqlSession 的工厂对象,负责初始化 MyBatis 环境。
-
核心职责:加载配置文件、初始化 Configuration、创建数据库会话。
-
生命周期 :项目启动创建一次,全局单例,全程不重复创建。
-
底层原理:通过 SqlSessionFactoryBuilder 构建,读取配置生成完整工厂实例。
-
面试考点:禁止频繁 new 工厂,会造成配置重复加载、资源浪费。
③ SqlSession 数据库会话(请求级)
-
核心作用 :MyBatis 操作数据库的核心入口,负责执行 SQL、管理事务、操作缓存。
-
核心能力:增删改查、事务提交/回滚、获取 Mapper 代理、清空一级缓存。
-
生命周期 :单次请求/单次数据库操作,用完即关,不复用。
-
线程安全 :非线程安全,绝对不能全局注入、多线程共享。
-
内置特性:自带一级缓存、维护当前事务状态。
-
面试高频:Spring 整合后,SqlSession 由 Spring 动态管理,自动关闭、自动事务控制。
④ Mapper(映射器:接口+XML/注解)
-
核心作用 :SQL 与业务代码的绑定桥梁,定义数据库操作方法与具体 SQL。
-
组成结构:Mapper 接口(方法定义) + Mapper XML/注解(SQL 定义)。
-
工作原理:MyBatis 通过 JDK 动态代理为接口生成代理对象,无需手写实现类。
-
生命周期:全局单例,Spring 容器统一管理。
-
线程安全 :线程安全,可全局注入、多线程共用。
-
核心优势:完全解耦,业务层只调用接口,无需关心 SQL 执行细节。
四大组件执行依赖关系
项目启动 → 加载配置生成 Configuration → 构建 SqlSessionFactory → 运行时获取 SqlSession → 通过 SqlSession 获取 Mapper 代理 → 执行数据库操作
3. 环境依赖(完整版 · 原生+SpringBoot+作用解析)
MyBatis 项目环境依赖分为:原生Java项目依赖 、SpringBoot整合项目依赖,所有依赖均适配企业主流版本,同时附带每个依赖的核心作用、必备原因、避坑说明,是项目搭建、环境报错排查的核心依据。
3.1 原生Java项目核心依赖
适用于纯Java测试、零基础入门Demo,无Spring环境
-
mybatis核心包:框架核心源码,包含所有配置解析、SQL执行、映射、缓存、插件全套能力
-
数据库驱动包:适配对应数据库,如mysql-connector-java、ojdbc,实现Java与数据库连接通信
-
日志依赖包:slf4j、logback,用于输出SQL执行日志、调试日志,方便开发排错
-
单元测试包:junit,用于测试CRUD、事务、缓存功能
3.2 SpringBoot企业项目依赖(主流)
企业99%项目使用 SpringBoot + MyBatis 整合开发,以下为必备全套依赖,缺一不可
-
mybatis-spring-boot-starter(核心整合依赖):SpringBoot官方整合包,自动完成SqlSessionFactory创建、Mapper扫描、事务适配,无需手动配置整合逻辑
-
spring-boot-starter-jdbc:提供Spring JDBC基础能力、事务管理、数据源适配,是MyBatis运行的基础容器依赖
-
数据库驱动:MySQL8/5.7、Oracle对应驱动,注意版本与数据库版本匹配,避免连接报错
-
连接池依赖(默认内置HikariCP):SpringBoot2.x+默认集成高性能Hikari连接池,管理数据库连接,避免频繁创建销毁连接,提升并发性能
-
lombok(可选必备):简化实体类代码,自动生成get/set、构造方法、toString,企业开发标配
-
分页插件pagehelper(常用拓展):弥补原生无分页能力,实现物理分页
3.3 完整Maven依赖示例(SpringBoot标准版)
XML
<!-- MyBatis SpringBoot 整合启动器 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
<!-- Spring JDBC 基础依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- MySQL 数据库驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- 连接池(SpringBoot默认内置,无需额外引入) -->
<!-- Lombok 简化实体类 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- 单元测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>3.4 依赖版本适配规则(避坑重点)
-
SpringBoot 2.x 对应 mybatis-starter 2.x 版本,SpringBoot 3.x 必须使用 3.x 版本,版本不匹配会启动报错
-
MySQL8.0+ 必须使用8.x驱动,废弃5.x驱动,否则出现时区、认证协议报错
-
禁止同时引入 mybatis 原生包 + mybatis-spring 整合包,会出现类冲突、容器初始化异常
3.5 环境依赖核心注意事项
-
所有数据库操作必须依赖连接池,禁止原生频繁创建Connection,极易造成数据库连接耗尽
-
runtime范围的驱动包,仅运行时生效,编译阶段不参与打包,精简项目体积
-
整合环境下,无需手动创建SqlSessionFactory、SqlSession,全部由Spring容器自动托管
总结:
Maven 引入 mybatis 核心包、数据库驱动、连接池、mybatis-spring 整合包
4. 基础 CRUD 流程(完整版 · 原生+SpringBoot实战流程)
MyBatis 标准开发流程统一遵循:实体类 → Mapper接口 → Mapper映射文件/注解SQL → 业务调用 → 测试执行,分为原生独立开发流程、SpringBoot整合开发流程两种,是所有MyBatis开发的底层基础。
4.1 完整开发步骤(通用标准流程)
-
创建数据库表:设计数据表字段、主键、索引,作为数据持久化载体
-
创建实体类(POJO):属性与数据表字段一一对应,推荐使用驼峰命名,配合全局驼峰转换配置自动映射
-
创建Mapper接口:定义CRUD抽象方法,无方法实现,仅声明数据库操作行为
-
编写Mapper XML/注解SQL:绑定接口方法与具体SQL语句,完成参数映射、结果集映射
-
配置全局文件:配置数据源、环境、映射文件路径、全局参数
-
获取会话执行SQL:通过SqlSession获取Mapper代理对象,调用方法完成数据库操作
-
事务控制与资源释放:执行完毕提交/回滚事务,关闭SqlSession释放资源
4.2 原生MyBatis完整CRUD执行流程(非Spring环境)
-
读取 mybatis-config.xml 全局配置文件,加载所有配置信息,生成 Configuration 全局配置对象
-
通过 SqlSessionFactoryBuilder 构建 SqlSessionFactory 全局工厂对象
-
通过工厂 openSession() 方法创建 SqlSession 数据库会话
-
SqlSession 获取对应 Mapper 接口的动态代理对象
-
调用Mapper接口CRUD方法,MyBatis拦截代理方法,解析对应SQL
-
完成参数绑定、SQL预编译、执行数据库操作、结果集封装映射
-
手动执行 commit() 提交事务 / rollback() 回滚事务
-
关闭 SqlSession,释放数据库连接资源,清空一级缓存
4.3 SpringBoot整合CRUD执行流程(企业主流)
SpringBoot自动托管所有核心对象,无需手动创建工厂和会话,简化开发
-
项目启动自动加载 application.yml 配置,初始化数据源、MyBatis全局配置
-
自动创建 SqlSessionFactory、SqlSessionTemplate 会话模板
-
通过包扫描自动注册所有Mapper接口,生成代理对象注入Spring容器
-
业务层 @Autowired 注入Mapper对象,直接调用CRUD方法
-
Spring自动管理SqlSession生命周期:方法执行前创建、执行后自动关闭
-
通过 @Transactional 注解统一管理事务,无需手动编码控制
4.4 四大基础CRUD核心说明
-
查询(Select):支持单条查询、列表查询、条件查询,可返回实体、List、Map、基本类型,默认走一级缓存
-
新增(Insert) :新增数据,支持主键回填,执行后清空当前Mapper缓存
-
修改(Update):更新表数据,动态SQL可实现局部字段更新,自动刷新缓存
-
删除(Delete):物理删除数据,清空对应命名空间缓存,无返回值/返回影响行数
4.5 CRUD开发核心规范与避坑点
-
命名绑定规范:Mapper XML的namespace必须对应Mapper接口全类名,标签id必须与接口方法名完全一致,否则绑定失败
-
资源规范:原生环境必须手动关闭SqlSession,否则会造成数据库连接泄露
-
事务规范:增删改必须开启事务控制,查询无需事务,提升执行效率
-
SQL规范:查询禁止使用 select *,按需指定字段,减少网络传输与映射开销
-
缓存规范:增删改操作会自动清空一、二级缓存,保证数据一致性
4.6 XML与注解开发适用场景
-
注解开发:简单CRUD、无动态条件的简单SQL,代码简洁、开发快速
-
XML开发:复杂联表查询、动态SQL、批量操作、超长SQL,可读性强、便于维护、解耦性高
实体类→Mapper 接口→XML / 注解 SQL→会话调用测试
4.7 实战前置准备
以通用用户表为例,统一代码演示载体,数据库脚本:
sql
CREATE TABLE `user` (
`id` INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID',
`user_name` VARCHAR(30) NOT NULL COMMENT '用户名',
`age` INT COMMENT '年龄',
`email` VARCHAR(50) COMMENT '邮箱',
`create_time` DATETIME COMMENT '创建时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';对应实体类 User.java(适配驼峰自动映射)
java
import lombok.Data;
import java.util.Date;
@Data
public class User {
private Integer id;
private String userName;
private Integer age;
private String email;
private Date createTime;
}4.8 原生MyBatis完整CRUD代码(非Spring)
1)全局核心配置 mybatis-config.xml
XML
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 全局驼峰自动转换 -->
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
<setting name="cacheEnabled" value="true"/>
</settings>
<!-- 环境配置 -->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/test?useSSL=false&serverTimezone=Asia/Shanghai"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<!-- 绑定Mapper映射文件 -->
<mappers>
<mapper resource="mapper/UserMapper.xml"/>
</mappers>
</configuration>2)Mapper接口 UserMapper.java
java
import org.apache.ibatis.annotations.Param;
import java.util.List;
public interface UserMapper {
// 根据ID查询
User selectUserById(Integer id);
// 新增用户
int insertUser(User user);
// 修改用户
int updateUser(User user);
// 删除用户
int deleteUserById(Integer id);
// 条件查询列表
List<User> selectUserList(@Param("userName") String userName);
}3)Mapper映射文件 UserMapper.xml
XML
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="UserMapper">
<!-- 根据ID查询 -->
<select id="selectUserById" resultType="User">
SELECT id,user_name,age,email,create_time FROM user WHERE id = #{id}
</select>
<!-- 新增用户,主键回填 -->
<insert id="insertUser" useGeneratedKeys="true" keyProperty="id">
INSERT INTO user(user_name,age,email,create_time)
VALUES(#{userName},#{age},#{email},#{createTime})
</insert>
<!-- 修改用户 -->
<update id="updateUser">
UPDATE user SET user_name=#{userName},age=#{age},email=#{email} WHERE id=#{id}
</update>
<!-- 删除用户 -->
<delete id="deleteUserById">
DELETE FROM user WHERE id=#{id}
</delete>
<!-- 条件查询 -->
<select id="selectUserList" resultType="User">
SELECT id,user_name,age,email,create_time FROM user
<where>
<if test="userName != null and userName != ''">
AND user_name LIKE CONCAT('%',#{userName},'%')
</if>
</where>
</select>
</mapper>4)原生测试执行代码
java
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.InputStream;
import java.util.Date;
public class MybatisTest {
public static void main(String[] args) throws IOException {
// 1. 加载全局配置
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
// 2. 构建会话工厂(全局单例)
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(inputStream);
// 3. 创建会话,手动提交事务
SqlSession sqlSession = factory.openSession(false);
// 4. 获取Mapper代理对象
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
// 新增测试
User user = new User();
user.setUserName("测试用户");
user.setAge(20);
user.setEmail("test@163.com");
user.setCreateTime(new Date());
userMapper.insertUser(user);
// 手动提交事务
sqlSession.commit();
System.out.println("新增用户ID:" + user.getId());
// 查询测试
User resUser = userMapper.selectUserById(user.getId());
System.out.println("查询结果:" + resUser);
// 关闭会话,释放资源
sqlSession.close();
}
}4.9 SpringBoot整合完整CRUD代码(企业主流)
1)application.yml 核心配置
XML
# 数据源配置
spring:
datasource:
url: jdbc:mysql://localhost:3306/test?useSSL=false&serverTimezone=Asia/Shanghai&allowMultiQueries=true
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
# MyBatis配置
mybatis:
mapper-locations: classpath:mapper/*.xml
configuration:
map-underscore-to-camel-case: true # 驼峰自动映射
cache-enabled: true # 开启二级缓存2)启动类(开启Mapper扫描)
java
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.example.mapper") // 扫描Mapper接口
public class MybatisApplication {
public static void main(String[] args) {
SpringApplication.run(MybatisApplication.class, args);
}
}3)Mapper接口(同原生,无需改动)
4)Mapper XML文件(同原生,无需改动)
5)业务测试代码(SpringBoot单元测试)
java
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Date;
import java.util.List;
@SpringBootTest
public class UserMapperTest {
// 自动注入线程安全的Mapper代理对象
@Autowired
private UserMapper userMapper;
@Test
void testInsert() {
User user = new User();
user.setUserName("SpringBoot用户");
user.setAge(25);
user.setEmail("spring@163.com");
user.setCreateTime(new Date());
userMapper.insertUser(user);
System.out.println("新增ID:" + user.getId());
}
@Test
void testSelect() {
User user = userMapper.selectUserById(1);
System.out.println("单条查询:" + user);
List<User> userList = userMapper.selectUserList("用户");
System.out.println("条件查询列表:" + userList);
}
@Test
void testUpdate() {
User user = new User();
user.setId(1);
user.setUserName("修改后的用户");
user.setAge(26);
userMapper.updateUser(user);
}
@Test
void testDelete() {
userMapper.deleteUserById(1);
}
}4.10 CRUD代码核心补充说明
-
主键回填原理 :XML中
useGeneratedKeys="true"开启自增主键回填,keyProperty指定实体主键属性,新增后自动赋值ID -
事务差异 :原生必须手动 commit/rollback;SpringBoot 通过
@Transactional自动管控事务 -
缓存机制:查询自动走一级缓存,增删改自动清空当前命名空间缓存
-
防注入 :所有参数使用
#{}预编译占位符,彻底杜绝SQL注入风险 -
资源管控:SpringBoot自动管理SqlSession生命周期,无需手动关闭,避免连接泄露
5. 事务提交模式(完整版 · 原生+Spring+原理+坑点+面试)
MyBatis 事务分为原生手动事务 与Spring 托管自动事务,是保证数据一致性的核心,也是生产报错、面试高频考点,核心区分在于 SqlSession 的创建方式与事务控制权。
5.1 原生 MyBatis 事务核心模式
原生环境无 Spring 事务托管,事务完全由开发者手动控制,核心依赖 openSession() 传参 决定提交模式。
-
openSession(true) ------ 自动提交事务 参数为 true,开启自动提交模式;每执行一条增删改 SQL,立即自动提交事务,无需手动 commit()。 适用场景 :单条独立增删改、无需事务回滚的简单操作。 缺点:多条SQL无法保证原子性,任意SQL失败无法回滚,不适合业务事务场景。
-
openSession(false) / 无参 ------ 手动提交事务(默认) 默认不传参等价于 false,事务默认不自动提交,所有增删改操作数据只存在于事务缓冲区,未落地数据库。 必须手动执行 :
sqlSession.commit()提交事务、数据落地;sqlSession.rollback()回滚事务、数据撤销。 适用场景:多SQL联动业务、需要保证原子性、成功统一提交、失败整体回滚的核心业务。
5.2 原生事务完整代码示例
java
// 手动事务模式(企业开发原生首选)
SqlSession sqlSession = factory.openSession(false);
try {
// 多条数据库操作,事务统一管理
userMapper.insertUser(user1);
userMapper.insertUser(user2);
// 全部执行成功,手动提交
sqlSession.commit();
} catch (Exception e) {
// 任意异常,整体回滚,保证数据一致
sqlSession.rollback();
e.printStackTrace();
} finally {
// 必须关闭会话,释放连接
sqlSession.close();
}5.3 SpringBoot 整合事务模式(企业主流)
Spring 完全接管 MyBatis 事务,无需手动 openSession、commit、rollback,通过 AOP 动态管控事务生命周期。
-
无注解默认规则:查询方法默认无事务、自动执行;增删改方法默认单条自动提交,多条SQL不保证原子性。
-
@Transactional 注解事务(核心):加在方法/类上,开启声明式事务。 方法正常执行完毕:自动提交事务; 方法抛出异常(默认RuntimeException):自动回滚事务。
java
import org.springframework.transaction.annotation.Transactional;
@Transactional
public void batchAddUser() {
// 多条数据库操作,原子性保证
userMapper.insertUser(user1);
userMapper.insertUser(user2);
// 任意异常自动回滚,无需手动编码
}5.4 特殊事务模式:Batch 批量事务
MyBatis 专属批量事务执行器,解决高频批量插入性能问题
-
创建方式:
factory.openSession(ExecutorType.BATCH,false) -
原理:SQL 语句预编译缓存,不立即提交,累积多条后统一批量提交,大幅减少数据库IO交互
-
注意:必须手动 commit 统一提交,中途异常需整体回滚
-
适用场景:大批量数据导入、批量新增/修改业务
5.5 事务核心特性与底层规则
-
事务隔离性:未提交事务的数据,其他会话无法查询到,避免脏读
-
一级缓存与事务联动:同一事务内,所有查询复用一级缓存,事务提交/关闭后清空缓存
-
二级缓存事务机制:事务未提交,二级缓存不更新,避免脏缓存数据
-
SqlSession 事务绑定:一个 SqlSession 对应一个独立事务,会话关闭事务结束
5.6 生产高频坑点(必记)
-
原生默认手动事务,不写 commit 会导致数据永久不入库,无任何报错,极难排查
-
自动提交模式无法保证多SQL原子性,严禁用于转账、订单等核心业务
-
Spring 事务仅对RuntimeException默认回滚,受检异常需手动配置回滚规则
-
Batch批量模式下,主键回填失效,无法直接获取新增ID
-
事务中禁止嵌套过多业务逻辑,避免事务超时、锁等待超时
5.7 面试高频考点
-
openSession(true/false) 区别、适用场景
-
原生事务为什么必须手动 commit?不提交会出现什么问题?
-
Spring 事务与 MyBatis 原生事务的区别
-
Batch 批量事务原理与优缺点
-
事务与一级、二级缓存的联动机制
6. 线程安全结论(完整版 · 原理+坑点+面试必背)
MyBatis 核心对象线程安全是面试高频、生产极易踩坑 的核心知识点,直接决定项目是否出现并发脏数据、连接泄露、事务混乱问题。核心结论:SqlSession、SqlSessionTemplate 非线程安全;SqlSessionFactory、Mapper代理对象 线程安全。
6.1 四大核心对象线程安全汇总
-
Configuration :全局单例、线程安全,项目启动一次性加载,只读不写,多线程共享无并发问题。
-
SqlSessionFactory :全局单例、线程安全,仅负责创建 SqlSession,无成员变量状态,多线程可同时调用。
-
SqlSession :非线程安全(重点),内部维护事务、缓存、数据库连接、执行状态成员变量,多线程共享会导致事务错乱、数据覆盖、连接串用。
-
Mapper 代理对象 :线程安全,Spring 托管的 Mapper 是无状态代理,每次调用方法都会从线程池获取独立 SqlSession,天然支持多线程并发。
6.2 为什么 SqlSession 非线程安全?(底层原理)
SqlSession 内部包含大量线程私有状态变量 :一级缓存、事务状态、当前连接、执行器对象、未提交SQL队列。 若多线程共用同一个 SqlSession:线程A的事务、缓存、连接会被线程B覆盖,造成事务混乱、数据脏写、SQL执行错乱、连接耗尽等诡异问题,且问题偶发、极难排查。
6.3 为什么 Mapper 接口是线程安全的?
Spring 整合 MyBatis 后,注入的 Mapper 并非原生 SqlSession 获取的瞬时对象,而是MapperFactoryBean 生成的无状态代理 。 每次执行 Mapper 方法时,都会通过 Spring 事务同步器,从当前线程独立获取新的 SqlSession,执行完毕自动关闭,线程之间完全隔离,无状态共享,因此线程安全。
6.4 生产正确 & 错误用法(必记避坑)
错误用法(绝对禁止)
-
将 SqlSession 定义为全局成员变量、静态变量,多线程共享
-
工具类缓存 SqlSession 对象、长期复用会话
-
原生环境不关闭 SqlSession,反复使用同一个会话
正确用法(企业标准)
-
SqlSession:方法级、请求级使用,用完即关,不存储、不复用
-
SqlSessionFactory:项目启动初始化一次,全局静态单例
-
Mapper:@Autowired 全局注入,在 Service/Controller 中任意并发调用
6.5 Spring 环境线程安全增强说明
-
Spring 通过 SqlSessionTemplate 封装 SqlSession,自动实现线程隔离
-
支持事务绑定:同一事务内复用同一个 SqlSession,保证事务一致性
-
事务结束/方法结束自动关闭会话,彻底杜绝连接泄露与并发问题
6.6 面试满分标准答案
问:MyBatis 的 SqlSession 和 Mapper 是线程安全的吗?为什么?
答: 1. SqlSession 非线程安全 :内部持有事务状态、一级缓存、数据库连接等可变成员变量,多线程共享会引发并发错乱问题,必须请求级/方法级独享。 2. Mapper 代理对象线程安全 :Spring 托管的 Mapper 是无状态代理,每次调用都会绑定当前线程独立的 SqlSession,线程之间数据隔离,支持高并发。 3. SqlSessionFactory、Configuration 全局单例线程安全,仅做创建与读取操作,无状态修改。
SqlSession 非线程安全;Mapper 代理对象线程安全,可全局注入使用
二、全局配置核心要点
1. 配置加载优先级(完整版 · 底层规则+覆盖机制+面试必背)
MyBatis 配置存在多层级覆盖机制,不同位置的配置生效权重不同,优先级直接决定项目最终运行参数,是解决配置不生效、参数冲突问题的核心依据,同时为面试高频考点。
1.1 完整优先级从高到低排序(权威最终版)
方法参数注解 > Mapper局部XML配置 > SpringBootyml/yaml配置 > 原生mybatis-config全局配置 > MyBatis框架默认配置
核心规则:局部配置覆盖全局配置,代码动态配置覆盖静态文件配置,项目自定义配置覆盖框架默认配置。
1.2 各层级配置详解与覆盖规则
-
① 注解/方法动态配置(最高优先级) 包含:Mapper接口注解(@Select、@Update、@Options)、方法级动态参数配置。 特性:作用于单条SQL、单个方法,优先级最高,会覆盖所有全局、XML静态配置。 实战场景:通过@Options单独为某条SQL开启/关闭缓存、设置超时时间、主键回填规则,仅当前方法生效。
-
② Mapper映射文件局部XML配置 包含:单个Mapper.xml内部的resultMap、sql片段、statement标签属性、缓存配置。 特性:命名空间级配置,仅覆盖当前Mapper文件的全局配置,不影响其他Mapper。 适用场景:部分模块需要特殊映射规则、独立缓存策略、差异化SQL配置。
-
③ SpringBoot yml/yaml 整合配置 包含:application.yml中mybatis.configuration全局参数。 特性:Spring整合环境专属,全局生效,优先级高于原生核心配置文件,统一接管项目所有MyBatis全局参数。 注意:SpringBoot项目中,优先读取yml配置,原生mybatis-config.xml配置会被部分覆盖。
-
④ 原生 mybatis-config.xml 全局配置 包含:settings全局参数、别名、插件、环境配置、数据源、映射注册。 特性:原生项目核心全局配置,所有Mapper默认继承该配置;Spring项目中优先级低于yml配置。
-
⑤ MyBatis 框架默认配置(最低优先级) 框架内置默认参数,无任何自定义配置时生效,是所有配置的兜底规则。 例如:默认开启一级缓存、关闭二级缓存、关闭驼峰命名转换等。
1.3 典型配置覆盖实战案例
案例1:驼峰命名规则覆盖 1、框架默认:mapUnderscoreToCamelCase=false(关闭) 2、mybatis-config.xml 设置为 true(全局开启) 3、yml 文件设置为 false(全局关闭,覆盖原生配置) 最终生效:false,以SpringBootyml配置为准。
案例2:单方法缓存策略覆盖 1、全局配置开启二级缓存 2、某Mapper查询方法通过@Options(useCache = false) 最终生效:当前方法关闭缓存,全局其他方法正常开启缓存,注解局部配置优先级最高。
1.4 核心底层原理
-
MyBatis 启动时逐层加载配置,后加载的高优先级配置会覆盖先加载的低优先级配置,最终汇总为一份完整的 Configuration 全局配置。
-
局部配置仅作用于当前作用域(方法/单个Mapper),全局配置作用于整个项目所有Mapper。
-
Spring环境下,MyBatisAutoConfiguration自动配置类会优先解析yml配置,覆盖原生config配置,实现Spring统一管控。
1.5 生产避坑重点
-
SpringBoot项目中,尽量统一使用yml配置,避免同时配置yml+mybatis-config.xml,防止配置冲突、生效混乱。
-
局部特殊配置优先使用MapperXML或注解配置,不修改全局配置,保证项目整体统一性。
-
排查配置不生效问题,优先按照优先级从高到低排查是否被上层配置覆盖。
1.6 面试满分标准答案
问:MyBatis 配置加载优先级是什么?为什么SpringBoot中yml配置优先级高于原生xml?
答: 1. 配置优先级从高到低:注解动态配置 > Mapper局部XML > SpringBootyml配置 > 原生mybatis-config.xml > 框架默认配置。 2. 核心原则:局部覆盖全局、自定义覆盖默认、动态代码配置覆盖静态文件配置。 3. SpringBoot环境中,自动配置类优先加载yml自定义配置,后覆盖原生全局XML配置,实现Spring生态统一管控,因此yml配置优先级更高。
总结:
注解 > 局部 XML 配置 > mybatis-config 全局配置 > 框架默认配置
2. 常用全局开关(完整版 · 参数释义+默认值+生产配置+坑点)
MyBatis 全局开关统一在 settings 标签(原生xml)或 mybatis.configuration (SpringBoot yml)中配置,全局生效、影响所有Mapper执行逻辑,是项目规范化、性能调优、避坑的核心配置,以下为企业必配高频开关。
2.1 字段映射核心开关(开发必备)
-
mapUnderscoreToCamelCase 默认值 :false 作用 :开启数据库下划线字段 <=> Java实体驼峰属性自动映射(如 user_name → userName) 生产配置 :true(企业全员开启) 避坑点:开启后无需手动配置resultMap映射基础字段,若字段名严重不匹配,仍需自定义resultMap;禁止部分开启部分关闭,全局统一规范。
-
autoMappingBehavior 默认值 :PARTIAL 可选值 :NONE(关闭自动映射)、PARTIAL(非嵌套自动映射)、FULL(全部嵌套自动映射) 作用 :控制结果集自动映射匹配粒度 生产建议:默认PARTIAL即可,FULL易引发关联映射错乱,不推荐开启。
2.2 缓存核心开关(性能调优)
-
cacheEnabled 默认值 :true(一级缓存默认开启,二级缓存总开关) 作用 :全局缓存总开关,控制所有Mapper的二级缓存是否生效,不影响一级缓存 生产规则:普通业务开启;金融、支付、实时库存等高一致性业务建议关闭二级缓存,避免数据脏读。
-
localCacheScope 默认值 :SESSION 可选值 :SESSION(会话级缓存)、STATEMENT(语句级缓存) 作用 :控制一级缓存生效范围 生产场景:高并发实时查询业务改为STATEMENT,单次SQL执行后清空缓存,保证数据实时性。
2.3 延迟加载开关(关联查询优化)
-
lazyLoadingEnabled 默认值 :false 作用 :全局延迟加载总开关,开启后关联对象(一对一/一对多)仅在调用时加载 优势 :减少冗余联表查询,提升单表查询性能 搭配配置:需同时关闭 aggressiveLazyLoading 激进懒加载。
-
aggressiveLazyLoading 默认值 :true(3.4.2之前默认开启,新版默认关闭) 作用 :激进懒加载,开启后任意属性调用都会触发所有关联数据加载 生产建议 :统一关闭,实现按需精准加载。
2.4 SQL执行与超时控制(防雪崩)
-
defaultStatementTimeout 默认值 :无(不限制) 作用 :全局SQL执行超时时间(单位:秒),超时自动终止SQL,防止慢查询阻塞数据库 生产必配:设置3~5秒,避免单条慢SQL拖垮整个数据库连接池。
-
defaultFetchSize 默认值 :无 作用 :批量查询每次拉取数据行数,适配大数据量查询,避免一次性加载内存溢出 适用场景:数据导出、批量数据同步业务。
2.5 日志与调试开关(开发排错)
- logImpl 默认值 :自动适配 作用 :指定MyBatis日志输出实现(SLF4J、LOG4J、STDOUT_LOG等) 生产规范:开发环境打印完整SQL日志,生产环境关闭SQL详情打印,仅保留异常日志。
2.6 空值与参数兼容开关(适配异常)
-
jdbcTypeForNull 默认值 :OTHER 作用 :指定null参数对应的JDBC类型,解决部分数据库null赋值报错问题 坑点:Oracle数据库必须配置为NULL,否则空值插入会报类型不匹配异常。
-
callSettersOnNulls 默认值 :false 作用 :查询结果为null时,是否调用实体setter方法赋值null 适用场景:需要覆盖原有对象属性、清空字段值的业务场景。
2.7 批量与执行器开关(高性能场景)
- defaultExecutorType 默认值 :SIMPLE 可选值 :SIMPLE(普通执行)、REUSE(复用预处理SQL)、BATCH(批量执行) 作用 :全局默认SQL执行器类型 生产用法:常规业务SIMPLE;批量导入业务临时指定BATCH执行器,不全局开启。
2.8 企业标准统一配置(可直接复制)
1)SpringBoot yml 标准配置(推荐)
XML
mybatis:
configuration:
# 下划线驼峰自动映射
map-underscore-to-camel-case: true
# 关闭激进懒加载,按需加载
aggressive-lazy-loading: false
# 开启全局延迟加载
lazy-loading-enabled: true
# SQL超时5秒,防慢查询
default-statement-timeout: 5
# 一级缓存语句级,保证实时性
local-cache-scope: STATEMENT
# 适配Oracle空值
jdbc-type-for-null: NULL2)原生 mybatis-config.xml 标准配置
XML
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
<setting name="defaultStatementTimeout" value="5"/>
<setting name="localCacheScope" value="STATEMENT"/>
<setting name="jdbcTypeForNull" value="NULL"/>
</settings>2.9 面试高频总结
-
最常用核心开关:驼峰映射、延迟加载、SQL超时、缓存作用域
-
生产最大坑点:全局开启二级缓存导致数据不一致、激进懒加载失效、Oracle空值未适配报错
-
优先级:代码注解配置 > 局部Mapper配置 > 全局settings配置
-
mapUnderscoreToCamelCase:下划线字段自动映射驼峰属性
-
cacheEnabled:二级缓存总开关
-
lazyLoadingEnabled:全局延迟加载开关
-
statementTimeout:SQL 执行超时时间,防慢查询阻塞
3. 多环境配置(完整版 · 原生+SpringBoot+切换原理+生产规范)
MyBatis 支持多套环境隔离配置 ,可针对开发、测试、预发、生产配置不同的数据源、事务管理器、参数参数,实现一套代码多环境无缝切换,避免频繁改配置、打包出错,是企业项目标准化部署的核心配置。
3.1 核心作用与适用场景
-
环境隔离:dev开发库、test测试库、prod生产库完全隔离,杜绝开发操作生产数据
-
一键切换:无需修改业务代码,仅修改环境标识即可切换数据库与配置
-
差异化适配:不同环境可配置不同连接池参数、超时时间、日志级别、事务规则
-
部署规范:适配CI/CD自动化部署,不同环境打包自动加载对应配置
3.2 原生mybatis-config.xml多环境配置(底层原理)
通过 environments 全局标签配置多套环境,default 属性指定默认生效环境,每个 environment 对应一套独立数据库配置。
核心组成:事务管理器(transactionManager) + 数据源(dataSource),每套环境独立配置,互不干扰。
XML
<!-- 多环境全局配置,default指定默认环境 -->
<environments default="dev">
<!-- 开发环境 -->
<environment id="dev">
<!-- JDBC事务管理器,原生手动事务 -->
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/dev_db?useSSL=false&serverTimezone=Asia/Shanghai"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
<!-- 测试环境 -->
<environment id="test">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://192.168.1.100:3306/test_db?useSSL=false&serverTimezone=Asia/Shanghai"/>
<property name="username" value="test"/>
<property name="password" value="test123"/>
</dataSource>
</environment>
<!-- 生产环境 -->
<environment id="prod">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://192.168.1.200:3306/prod_db?useSSL=true&serverTimezone=Asia/Shanghai"/>
<property name="username" value="prod_user"/>
<property name="password" value="Prod@123456"/>
</dataSource>
</environment>
</environments>3.3 原生代码动态切换环境
可在代码中手动指定环境ID,实现运行时动态切换数据库环境,适配多环境测试场景。
java
// 加载配置
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
// 指定加载test测试环境
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(inputStream,"test");
// 后续所有操作均使用测试库环境
SqlSession sqlSession = factory.openSession();3.4 SpringBoot企业级多环境配置(主流规范)
SpringBoot 废弃原生 environments 配置,通过多配置文件+激活环境实现环境隔离,更灵活、更适配自动化部署。
标准多环境文件结构
-
application.yml:公共全局配置(MyBatis全局开关、扫描路径、日志)
-
application-dev.yml:开发环境数据源、调试配置
-
application-test.yml:测试环境数据源配置
-
application-prod.yml:生产环境数据源、关闭调试日志
1)公共配置 application.yml
XML
# 公共MyBatis配置,所有环境生效
mybatis:
mapper-locations: classpath:mapper/*.xml
configuration:
map-underscore-to-camel-case: true
default-statement-timeout: 5
# 激活默认开发环境
spring:
profiles:
active: dev2)开发环境 application-dev.yml
XML
spring:
datasource:
url: jdbc:mysql://localhost:3306/dev_db?useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
# 开发环境开启完整SQL日志
logging:
level:
com.example.mapper: debug3)生产环境 application-prod.yml
XML
spring:
datasource:
url: jdbc:mysql://192.168.1.200:3306/prod_db?useSSL=true&serverTimezone=Asia/Shanghai
username: prod_user
password: Prod@123456
driver-class-name: com.mysql.cj.jdbc.Driver
# 生产关闭详细SQL日志,提升性能、保护敏感信息
logging:
level:
com.example.mapper: info3.5 环境切换三种方式(企业实操)
-
配置文件切换:修改 application.yml 中 spring.profiles.active 属性,本地开发常用
-
启动命令动态指定 (部署常用):
java -jar project.jar --spring.profiles.active=prod -
IDE运行配置指定:开发工具内直接选择运行环境,无需改代码
3.6 多环境差异化配置细则
-
数据源差异:不同环境数据库地址、账号密码、库名完全隔离
-
日志差异:开发打全量SQL日志,生产仅打印异常日志
-
连接池差异:开发连接数小、超时时间短;生产连接池参数优化适配高并发
-
缓存差异:开发可关闭二级缓存方便调试,生产开启缓存提升性能
3.7 生产高频避坑点
-
禁止多环境配置混用:SpringBoot项目优先yml环境配置,原生environments配置会失效,避免双重配置冲突
-
生产禁止开启调试日志:避免SQL、数据库账号密码明文泄露,引发安全风险
-
环境隔离必须彻底:严禁测试环境指向生产数据库,导致数据误删误改
-
打包环境校验:上线前务必确认激活prod环境,防止打包带dev配置上线
3.8 面试满分考点总结
-
原生MyBatis通过 environments 标签 实现多环境配置,default 指定默认环境
-
SpringBoot 放弃原生环境配置,使用多profile文件实现环境隔离,更适配工程化
-
多环境核心价值:环境隔离、一键切换、适配自动化部署、规避人为配置错误
-
配置优先级:动态命令指定环境 > 配置文件激活环境 > 默认环境
总结:
environment 标签区分开发 / 测试 / 生产库,default 指定默认运行环境
4. 数据库厂商适配(databaseIdProvider 完整版 · 原理+配置+多库兼容+实战)
MyBatis 内置数据库厂商适配机制 ,通过 databaseId 实现一套项目兼容多数据库(MySQL、Oracle、SQL Server、PostgreSQL),解决不同数据库语法、函数、分页、主键生成差异问题,是多数据库适配、通用中台项目的核心配置,彻底避免多套代码适配不同数据库的冗余问题。
4.1 核心适配原理
-
MyBatis 启动时通过 databaseIdProvider 自动识别当前连接的数据库厂商,生成唯一 databaseId 标识
-
Mapper XML 中可通过
databaseId属性标记适配不同数据库的 SQL 节点 -
程序运行时自动匹配当前数据库的SQL执行,不匹配的SQL节点自动忽略
-
优先级:带 databaseId 的SQL > 无标识通用SQL,精准实现差异化适配
4.2 全局配置(原生 mybatis-config.xml)
在全局配置文件中注册数据库厂商识别器,支持自定义厂商别名,适配主流数据库
XML
<!-- 数据库厂商适配配置 -->
<databaseIdProvider type="DB_VENDOR">
<!-- 自定义数据库别名,简化标识 -->
<property name="MySQL" value="mysql"/>
<property name="Oracle" value="oracle"/>
<property name="SQL Server" value="sqlserver"/>
<property name="PostgreSQL" value="postgresql"/>
</databaseIdProvider>配置说明:
-
type="DB_VENDOR":MyBatis 内置默认数据库识别器,通过驱动连接信息自动识别厂商
-
key(如MySQL、Oracle):框架原生识别名称,不可随意修改
-
value(如mysql、oracle):自定义简写标识,用于Mapper SQL匹配
4.3 SpringBoot yml 等效配置(企业主流)
SpringBoot 环境无需编写 xml 节点,直接通过配置开启数据库适配
XML
mybatis:
configuration:
# 开启数据库厂商识别
database-id-provider: DB_VENDOR
# 可自定义厂商别名(高版本MyBatis支持)
configuration-properties:
MySQL: mysql
Oracle: oracle
SQL Server: sqlserver4.4 Mapper XML 多数据库SQL适配实战
核心用法:相同id的SQL标签,通过databaseId区分数据库,实现一套接口适配多库
XML
<mapper namespace="com.example.mapper.UserMapper">
<!-- 通用SQL:所有数据库都生效(兜底) -->
<select id="getUserCount" resultType="int">
SELECT COUNT(*) FROM user
</select>
<!-- MySQL专属分页、语法适配 -->
<select id="getUserList" resultType="User" databaseId="mysql">
SELECT id,user_name,age,email FROM user LIMIT #{offset},#{pageSize}
</select>
<!-- Oracle专属分页、语法适配 -->
<select id="getUserList" resultType="User" databaseId="oracle">
SELECT * FROM (
SELECT id,user_name,age,email,ROWNUM rn FROM user
WHERE ROWNUM <= #{offset}+#{pageSize}
) WHERE rn > #{offset}
</select>
<!-- MySQL自增主键新增 -->
<insert id="insertUser" useGeneratedKeys="true" keyProperty="id" databaseId="mysql">
INSERT INTO user(user_name,age,email) VALUES(#{userName},#{age},#{email})
</insert>
<!-- Oracle序列主键新增 -->
<insert id="insertUser" databaseId="oracle">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
SELECT SEQ_USER.NEXTVAL FROM DUAL
</selectKey>
INSERT INTO user(id,user_name,age,email) VALUES(#{id},#{userName},#{age},#{email})
</insert>
</mapper>4.5 主流数据库语法差异化适配场景
-
分页语法差异(最常用) MySQL:LIMIT 偏移量,条数 Oracle:ROWNUM 嵌套分页 SQL Server:TOP / OFFSET FETCH
-
主键生成差异 MySQL:自增主键 auto_increment,useGeneratedKeys 回填 Oracle:序列 Sequence 生成主键,selectKey 提前获取
-
函数差异 时间函数:NOW()(MySQL)、SYSDATE(Oracle) 字符串拼接:CONCAT()(MySQL)、|| 拼接(Oracle)
-
特殊语法差异 空值处理、分页语法、批量插入语法、模糊查询匹配规则
4.6 内置变量 _databaseId 动态适配
MyBatis 提供内置上下文变量 _databaseId,可在SQL中动态判断数据库类型,实现单语句多库兼容
XML
<select id="getUserByTime" resultType="User">
SELECT * FROM user
<where>
<if test="_databaseId == 'mysql'">
create_time > NOW() - INTERVAL 1 DAY
</if>
<if test="_databaseId == 'oracle'">
create_time > SYSDATE - 1
</if>
</where>
</select>4.7 执行优先级规则(核心)
-
优先执行匹配当前databaseId的SQL节点
-
若无匹配节点,执行无databaseId的通用SQL
-
禁止同一id下多个相同databaseId的SQL,会启动报错
4.8 生产避坑重点
-
别名统一规范:自定义databaseId别名全局统一,避免Mapper配置不一致导致适配失效
-
通用SQL兜底:多库适配必须保留无标识通用SQL,防止新增数据库类型适配遗漏
-
语法严格区分:禁止MySQL、Oracle语法混用,否则适配后SQL执行报错
-
版本适配:低版本MyBatis对PostgreSQL、SQL Server识别存在兼容问题,建议升级3.5+版本
-
避免过度适配:单一数据库项目无需开启此配置,仅多库兼容项目使用
4.9 面试高频考点
-
MyBatis 如何实现多数据库厂商适配?核心组件是什么?
-
databaseId 匹配优先级、通用SQL与适配SQL的执行规则
-
MySQL与Oracle分页、主键生成的适配差异
-
_databaseId 内置变量的使用场景
面试满分总结:通过 databaseIdProvider 自动识别数据库厂商,结合 Mapper 中 databaseId 属性或 _databaseId 内置变量,实现差异化SQL适配,一套代码兼容多类数据库,适配企业多库通用项目。
databaseIdProvider 适配 MySQL、Oracle 语法差异化 SQL
5. 空值兼容配置(完整版 · 报错原理+全场景配置+多库适配+生产避坑)
MyBatis 空值兼容配置是解决Null参数数据库适配报错、字段空值写入异常、跨数据库空值不兼容的核心配置,尤其适配 Oracle、PostgreSQL 等严格类型数据库,彻底解决 MySQL 正常运行、其他数据库空值报错的跨库兼容问题,是多数据库项目必备基础配置。
5.1 空值报错核心底层原理
MyBatis 执行 SQL 预编译时,会为每个占位符参数匹配对应的 JDBC 数据类型。当传入参数为 null 时,MyBatis 默认无法自动识别该空值对应的 JDBC 类型:
-
MySQL 数据库容错性极高,对无类型的 null 值默认兼容,不会报错
-
Oracle、PostgreSQL、SQL Server 属于强类型数据库,空值必须指定明确 JDBC 类型,否则抛出 无效的列类型、数据类型不匹配 异常
-
未配置空值兼容时,null 参数默认携带未知类型,跨库场景直接执行失败
5.2 核心配置参数详解
① jdbcTypeForNull(全局空值类型适配)
核心作用:统一指定所有 null 参数默认对应的 JDBC 类型,全局解决空值类型不匹配问题。
-
框架默认值:OTHER(未知类型,强类型数据库不兼容)
-
企业生产标配值:NULL
-
适配场景:所有字段空值插入、更新、条件查询,全局统一生效
-
核心价值:无需在每个 XML 占位符手动指定 jdbcType,全局一劳永逸兼容空值
② callSettersOnNulls(空值字段赋值控制)
核心作用:控制查询结果字段为 null 时,是否调用实体类 setter 方法赋值 null。
-
默认值:false(不调用setter,实体字段保留默认初始值)
-
可选开启:true(查询出null字段时,强制覆盖实体属性为null)
-
适用场景:需要字段空值覆盖、数据对比、字段重置的业务场景
5.3 完整配置方式(原生XML + SpringBoot YML)
1)原生 mybatis-config.xml 全局配置
XML
<settings>
<!-- 全局null参数默认JDBC类型,适配Oracle等强类型数据库 -->
<setting name="jdbcTypeForNull" value="NULL"/>
<!-- 空值字段强制赋值null,覆盖实体默认值 -->
<setting name="callSettersOnNulls" value="true"/>
</settings>2)SpringBoot yml 企业标准配置(主流)
XML
mybatis:
configuration:
# 全局空值JDBC类型适配,解决Oracle空值报错
jdbc-type-for-null: NULL
# 空值字段强制赋值null,精准同步数据库空值状态
call-setters-on-nulls: true5.4 局部手动兼容写法(兜底方案)
若未开启全局空值配置,可通过局部占位符指定 jdbcType 单独适配空值,优先级高于全局配置,适合个别特殊字段兼容。
XML
<!-- 空值字段手动指定JDBC类型,适配Oracle -->
<update id="updateUserInfo">
UPDATE user
SET user_name = #{userName,jdbcType=VARCHAR},
age = #{age,jdbcType=INTEGER},
email = #{email,jdbcType=VARCHAR}
WHERE id = #{id}
</update>常用字段jdbcType对应规则:
-
字符串字段:jdbcType=VARCHAR
-
数字字段:jdbcType=INTEGER、BIGINT、DECIMAL
-
时间字段:jdbcType=TIMESTAMP、DATE
-
大文本字段:jdbcType=CLOB
5.5 多数据库空值适配差异
-
MySQL:容错性强,默认OTHER类型可兼容空值,无需特殊配置,但建议统一开启全局配置,保持多库一致性
-
Oracle :严格校验类型,必须配置jdbcTypeForNull=NULL,否则所有null参数操作直接报错
-
PostgreSQL/SQL Server:强类型校验,同Oracle,依赖全局空值配置兼容
5.6 生产高频坑点(必避)
-
跨库兼容坑:本地MySQL开发正常,测试环境Oracle报错,90%是未配置空值类型导致
-
数据不一致坑:未开启callSettersOnNulls时,数据库null字段会映射为实体默认值(int默认0、字符串默认空串),导致前后端数据不一致
-
冗余配置坑:开启全局jdbcTypeForNull后,无需所有字段手动加jdbcType,避免冗余代码
-
动态SQL空值坑:动态if判断中的null参数,必须依赖全局配置,否则分支生效后空值参数报错
5.7 典型报错与解决方案
-
报错信息 :ORA-00932: 数据类型不一致: 应为 -, 但却获得 BINARY 原因 :Oracle空参数无指定JDBC类型,默认OTHER类型不兼容 解决:配置 jdbcTypeForNull=NULL
-
报错信息 :无效的列类型: 1111 原因 :null参数未匹配有效JDBC类型 解决:全局空值配置 + 特殊字段局部jdbcType兜底
5.8 面试高频考点总结
-
为什么MySQL空值不报错,Oracle空值会报错?
-
jdbcTypeForNull 核心作用与生产配置值
-
callSettersOnNulls 开启前后的实体字段赋值差异
-
全局空值配置与局部jdbcType配置优先级
面试满分总结:
通过配置 jdbcTypeForNull=NULL 全局适配多数据库空值类型,解决Oracle等强类型数据库空值报错;
通过 callSettersOnNulls=true 保证数据库空值与实体字段精准映射,彻底解决跨库空值兼容、数据不一致问题。
6. Mapper 扫描规则(完整版·原生+SpringBoot、原理+配置+坑点+面试)
Mapper扫描是MyBatis绑定Mapper接口与XML映射文件 、注册Mapper代理对象的核心环节,核心目的是让框架自动识别数据库操作接口与对应SQL,无需手动注册每一个Mapper,分为原生MyBatis扫描规则 和SpringBoot整合扫描规则两套体系,是解决Mapper找不到、绑定失败、注入异常的核心知识点。
6.1 原生MyBatis Mapper扫描规则(mybatis-config.xml)
原生环境通过全局配置文件中的 <mappers> 标签注册Mapper资源,支持四种扫描注册方式,优先级、适用场景各不相同,仅注册成功的Mapper才可被SqlSession调用。
方式一:资源路径注册(resource)------ 推荐本地项目
语法:<mapper resource="mapper/UserMapper.xml"/>
规则:基于**类路径(classpath)**查找XML文件,适配传统Maven项目资源目录结构
适用场景:XML文件统一存放在resources/mapper目录下,路径清晰、适配性强
限制:只能注册XML映射文件,无法直接扫描Mapper接口
方式二:绝对路径注册(url)------ 极少使用
语法:<mapper url="file:///D:/project/mapper/UserMapper.xml"/>
规则:通过本地磁盘绝对路径加载Mapper文件
缺点:项目移植性极差,不同设备路径不同,严禁用于正式项目,仅适用于本地临时测试
方式三:类全限定名注册(class)------ 接口XML同名同目录专用
语法:<mapper class="com.example.mapper.UserMapper"/>
核心规则:Mapper接口与XML文件必须同名、同包同级目录
原理:框架通过接口全类名,自动查找同目录下同名XML映射文件,自动绑定
适用场景:接口与XML严格统一存放的项目,精简配置
方式四:包批量扫描(package)------ 批量注册首选
语法:<package name="com.example.mapper"/>
规则:批量扫描指定包下所有Mapper接口,自动匹配同目录同名XML文件
优势:无需逐个注册Mapper,批量生效,适配多Mapper模块项目
硬性要求:接口与XML必须同名、同包,否则扫描绑定失败
6.2 SpringBoot整合Mapper扫描规则(企业主流)
SpringBoot彻底简化原生扫描配置,摒弃mybatis-config.xml手动注册,通过注解扫描+配置文件路径绑定双重机制实现Mapper注册,是企业项目标准用法。
6.2.1 核心扫描注解:@MapperScan
加在项目启动类上,实现全局包批量扫描,一次性注册所有Mapper接口,优先级最高。
java
// 单包扫描:指定单个Mapper包路径
@MapperScan("com.example.mapper")
// 多包扫描:多个模块Mapper批量扫描
@MapperScan({"com.example.mapper","com.example.system.mapper"})核心规则:
-
自动扫描指定包及其子包下所有被MyBatis识别的Mapper接口
-
自动为接口生成动态代理对象,注入Spring容器,可直接@Autowired注入使用
-
无需在接口上添加任何注解,纯接口即可被扫描识别
6.2.2 单接口注解:@Mapper
若不使用@MapperScan批量扫描,可在单个Mapper接口 上添加@Mapper注解,单独注册当前接口。
-
缺点:多模块项目需逐个添加,冗余繁琐,不利于统一维护
-
适用场景:仅少量临时Mapper、单体小型项目
-
优先级:@MapperScan批量扫描 > 单接口@Mapper注解
6.2.3 XML文件路径绑定配置
SpringBoot通过yml配置指定XML映射文件扫描路径,解决接口与XML不同目录的场景,打破原生同名同目录限制。
XML
mybatis:
# 扫描指定目录下所有XML映射文件,支持通配符
mapper-locations: classpath:mapper/*.xml,classpath:mapper/**/*.xml配置规则:
-
支持通配符
*(当前目录所有XML)、**(递归子目录所有XML) -
可实现接口在Java目录、XML在resources目录的分离存放,适配企业标准项目结构
-
该配置仅绑定XML文件,接口仍需通过@MapperScan扫描注册
6.3 Mapper绑定核心必备规则(全局通用)
无论原生还是SpringBoot环境,Mapper接口与XML文件绑定必须满足核心规则,否则启动报错、SQL绑定失败。
-
命名空间强制匹配 :XML文件的
namespace属性必须等于Mapper接口完整全类名(包名+类名),大小写完全一致 -
方法ID强制匹配:XML中select、insert、update、delete标签的id,必须与Mapper接口抽象方法名完全一致
-
唯一绑定原则:一个XML命名空间对应唯一一个Mapper接口,禁止多接口共用一个XML、多XML绑定一个接口
-
返回值匹配规则:XML的resultType/resultMap必须与接口方法返回值类型匹配,否则映射报错
6.4 企业标准项目目录规范(适配扫描规则)
SpringBoot项目通用规范,完美适配默认扫描规则,无需特殊配置:
Mapper接口路径:com.example.project.mapper(Java源码目录)
XML映射文件路径:resources/mapper(资源文件目录)
配套配置:@MapperScan扫描接口包 + mapper-locations扫描XML目录6.5 生产高频坑点(必避)
-
扫描范围遗漏:多模块项目未配置多包扫描,导致部分模块Mapper无法注入,报NoSuchBeanDefinitionException
-
namespace写错:包名、类名大小写不一致,导致接口与XML绑定失败,报绑定异常
-
XML未被扫描:接口扫描成功,但mapper-locations配置错误,XML文件未加载,调用方法报SQL不存在
-
重复扫描冲突:同时使用@MapperScan和全局mybatis-config.xml扫描,导致Mapper重复注册报错
-
目录不匹配:原生模式下接口与XML不同名不同目录,未配置资源路径,扫描失效
6.6 面试高频考点总结
-
SpringBoot中 @Mapper 和 @MapperScan 的区别、适用场景
-
Mapper接口与XML文件绑定的核心必要条件
-
原生四种Mapper注册方式的优缺点与适配场景
-
项目报Mapper注入失败、SQL找不到的核心排查思路
面试满分总结:
原生MyBatis通过mappers标签的resource/class/url/package四种方式注册Mapper;
SpringBoot通过@MapperScan批量扫描接口、mapper-locations绑定XML文件,核心绑定规则为XML的namespace对应接口全类名、标签id对应接口方法名,满足规则即可实现SQL与代码的完美解耦绑定。
总结:
包路径扫描、注解扫描,绑定接口与 XML 映射文件
三、参数传递与 SQL 语法
1. 两种取值符号区别
-
#{}:预编译占位符,防止 SQL 注入,推荐日常使用
-
${}:字符串直接拼接,仅用于动态表名、排序字段
2. 全场景传参方式(完整版·实战代码+原理+坑点+面试)
MyBatis 传参是开发核心基础,适配所有业务参数传递场景,包含单基本类型、多参数、实体类、Map集合、数组/List集合、嵌套参数、内置默认参数七大场景,每种场景附带标准代码、底层解析规则、生产规范与避坑点,彻底解决参数绑定失败、取值为空、类型匹配异常问题。
2.1 单基本类型传参(String/Integer/Long等)
适用于单条件查询、单字段更新、根据唯一主键删除等单参数业务场景,是最简单的传参方式。
核心规则:
-
Mapper接口方法定义单个基本类型参数,无需注解修饰
-
XML中直接通过
#{参数名}取值,参数名可自定义(推荐与方法参数名一致) -
MyBatis 3.4+ 自动识别单参数,无需额外配置
实战代码
Mapper接口:
java
// 根据ID查询单条数据(单Integer参数)
User selectUserById(Integer id);
// 根据用户名查询用户(单String参数)
List<User> selectUserByUserName(String userName);Mapper XML:
XML
<select id="selectUserById" resultType="User">
SELECT id,user_name,age,email FROM user WHERE id = #{id}
</select>
<select id="selectUserByUserName" resultType="User">
SELECT id,user_name,age,email FROM user WHERE user_name = #{userName}
</select>避坑点 :单参数场景禁止使用 ${} 拼接,存在SQL注入风险;参数名可随意修改,不影响解析。
2.2 多参数传参(@Param注解绑定·企业主流)
适用于多条件组合查询、多字段更新、批量条件筛选等多参数场景,是企业开发最常用的传参方式。
核心原理:
-
多参数必须通过
@Param("参数名")注解绑定参数别名 -
MyBatis 将多个参数封装为 Map 集合,key为注解定义的别名,value为传入参数值
-
XML中通过注解别名取值,与方法参数名无关,解耦性更强
实战代码
Mapper接口:
java
// 多条件分页查询(页码+条数+用户名模糊查询)
List<User> selectUserByPage(
@Param("userName") String userName,
@Param("offset") Integer offset,
@Param("pageSize") Integer pageSize
);Mapper XML:
XML
<select id="selectUserByPage" resultType="User">
SELECT id,user_name,age,email FROM user
<where>
<if test="userName != null and userName != ''">
AND user_name LIKE CONCAT('%',#{userName},'%')
</if>
</where>
LIMIT #{offset},#{pageSize}
</select>核心规范与坑点:
-
多参数必须加@Param,否则MyBatis无法识别参数名称,抛出参数绑定异常
-
注解别名全局唯一,禁止重复命名
-
XML取值必须与注解别名完全一致,区分大小写
2.3 实体类传参(POJO/DTO·新增/更新首选)
适用于新增、全量/局部更新、实体条件查询场景,参数较多时优先使用,简化方法参数列表。
核心规则:
-
方法参数为自定义实体类(POJO/DTO),无需@Param注解
-
XML中直接通过
#{实体属性名}取值,遵循实体类属性名(驼峰命名) -
自动适配动态SQL,支持非空字段动态传参
实战代码
Mapper接口:
java
// 新增用户(实体传参)
int insertUser(User user);
// 动态更新用户(非空字段更新)
int updateUser(User user);Mapper XML:
XML
<insert id="insertUser" useGeneratedKeys="true" keyProperty="id">
INSERT INTO user(user_name,age,email,create_time)
VALUES(#{userName},#{age},#{email},#{createTime})
</insert>
<update id="updateUser">
UPDATE user
<set>
<if test="userName != null and userName != ''">user_name=#{userName},</if>
<if test="age != null">age=#{age},</if>
<if test="email != null and email != ''">email=#{email}</if>
</set>
WHERE id=#{id}
</update>避坑重点:
-
取值必须写实体属性名,而非数据库字段名
-
基本类型默认值(int默认0、boolean默认false)会导致动态SQL误判,建议实体属性统一使用包装类(Integer、Boolean)
2.4 Map集合传参(动态不定参数场景)
适用于参数不固定、动态条件多变、无对应实体类的临时业务场景,灵活度最高。
核心规则:
-
方法参数为Map<String,Object>,无需注解
-
XML中通过
#{map的key名}取值,key为代码中存入Map的键名 -
支持任意类型参数,无需提前定义实体字段
实战代码
Mapper接口:
java
// 动态多条件查询,参数不固定
List<User> selectUserByMap(Map<String,Object> paramMap);调用代码:
java
Map<String,Object> paramMap = new HashMap<>();
paramMap.put("userName", "测试");
paramMap.put("minAge", 18);
paramMap.put("maxAge", 30);
List<User> userList = userMapper.selectUserByMap(paramMap);Mapper XML:
XML
<select id="selectUserByMap" resultType="User">
SELECT id,user_name,age,email FROM user
<where>
<if test="userName != null and userName != ''">
AND user_name LIKE CONCAT('%',#{userName},'%')
</if>
<if test="minAge != null">
AND age >= #{minAge}
</if>
<if test="maxAge != null">
AND age <= #{maxAge}
</if>
</where>
</select>生产规范:固定参数业务优先用实体类,Map传参可读性差、无参数校验,仅用于临时动态场景。
2.5 数组/List集合传参(批量操作核心)
专门适配批量查询、批量删除、批量更新场景,配合foreach标签实现集合遍历,是批量业务必备传参方式。
核心分类与规则:
-
数组传参:适用于固定类型批量参数
-
List集合传参:企业主流,适配动态长度批量数据
-
无需注解,XML中通过foreach标签遍历,支持item、index、separator等属性
实战代码(List批量查询)
Mapper接口:
java
// 根据ID集合批量查询
List<User> selectUserByIdList(@Param("idList") List<Integer> idList);
// 根据ID数组批量删除
int deleteUserByIdArray(@Param("idArray") Integer[] idArray);Mapper XML:
XML
<!-- List集合批量查询 -->
<select id="selectUserByIdList" resultType="User">
SELECT id,user_name,age,email FROM user
WHERE id IN
<foreach collection="idList" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</select>
<!-- 数组批量删除 -->
<delete id="deleteUserByIdArray">
DELETE FROM user WHERE id IN
<foreach collection="idArray" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</delete>关键坑点:
-
集合/数组参数必须加@Param别名,否则foreach无法识别collection
-
collection取值必须与注解别名一致,List、数组不可混用
-
需做非空判断,避免空集合导致SQL语法报错
2.6 嵌套参数传参(实体嵌套实体/集合)
适用于复杂业务DTO、嵌套关联参数场景,比如查询条件DTO中包含用户信息、标签集合等嵌套参数。
核心规则 :通过 外层参数.内层属性 链式取值
实战示例
XML
<!-- DTO嵌套参数取值 -->
<select id="selectUserByDto" resultType="User">
SELECT * FROM user
<where>
<if test="query.userName != null">AND user_name = #{query.userName}</if>
<if test="query.age != null">AND age = #{query.age}</if>
</where>
</select>2.7 MyBatis内置默认参数(无需手动传参)
MyBatis 自带2个全局内置参数,可直接在所有XML中使用,无需接口传参,适配通用场景。
-
_parameter:代表当前接口传入的所有参数,单参数、多参数、实体参数均可通过该变量获取
-
_databaseId:当前项目适配的数据库厂商标识(mysql/oracle/sqlserver),用于动态适配多库SQL
实战用法
XML
<!-- 利用_databaseId动态适配多库时间查询 -->
<select id="getUserByTime" resultType="User">
SELECT * FROM user
<where>
<if test="_databaseId == 'mysql'">create_time > NOW() - INTERVAL 1 DAY</if>
<if test="_databaseId == 'oracle'">create_time > SYSDATE - 1</if>
</where>
</select>2.8 传参优先级与底层解析规则
参数取值优先级(从高到低):
-
@Param 注解自定义别名(最高)
-
实体类/Map 自定义属性key
-
方法原生参数名(需开启编译参数保留参数名)
-
MyBatis 内置默认参数(兜底)
2.9 面试高频考点总结
-
多参数为什么必须加@Param注解?不加会报什么错?
-
实体传参为什么推荐使用包装类而非基本类型?
-
List/数组批量传参的核心注意事项?
-
Map传参和实体传参的适用场景与优缺点对比?
-
_parameter、_databaseId 内置参数的作用?
总结:
-
基础类型、实体类、Map 集合、数组、多参数 @Param 注解
-
内置默认参数:_parameter、_databaseId
3. 主键回填(完整版·多库实现+原理+实战+坑点+面试)
主键回填是MyBatis新增业务的核心能力,指数据插入数据库生成主键后,自动将主键值回写到实体类对象中 ,无需手动查询数据库获取新增ID,极大简化新增后主键复用逻辑(如新增后关联插入子表数据)。主流分为MySQL自增主键回填 、Oracle序列主键回填两种核心方案,适配不同数据库主键生成机制。
3.1 核心基础概念
-
作用场景:单表新增、批量新增、主从表关联新增(主表新增后需用主键绑定子表数据)
-
核心价值:避免新增后执行额外SQL查询主键,减少数据库IO,提升代码简洁性
-
核心前提:数据库已配置主键生成规则(MySQL自增、Oracle序列)
3.2 MySQL 自增主键回填(企业主流)
MySQL采用 auto_increment 自增主键,主键由数据库自动生成,MyBatis通过专属标签属性实现回填,配置极简。
3.2.1 核心配置属性
-
useGeneratedKeys:开启自增主键回填能力,true=开启,false=关闭
-
keyProperty:指定实体类中接收主键的属性名(必须和实体主键字段完全一致)
-
keyColumn(可选):指定数据库主键字段名,字段名与实体属性驼峰匹配时可省略
3.2.2 完整实战代码
Mapper接口(无需特殊注解,普通新增方法即可):
java
// 新增用户,自动回填主键ID
int insertUser(User user);Mapper XML映射文件(核心回填配置):
XML
<!-- MySQL自增主键回填标准写法 -->
<insert id="insertUser" useGeneratedKeys="true" keyProperty="id">
INSERT INTO user(user_name,age,email,create_time)
VALUES(#{userName},#{age},#{email},#{createTime})
</insert>业务调用测试:
java
User user = new User();
user.setUserName("主键回填测试");
user.setAge(22);
userMapper.insertUser(user);
// 直接获取数据库生成的自增主键,无需额外查询
System.out.println("新增用户主键ID:" + user.getId());3.3 Oracle 序列主键回填(适配强类型数据库)
Oracle无自增主键,主键通过自定义序列(Sequence) 生成,需通过 selectKey 标签 手动实现主键查询与回填,分为前置获取和后置获取。
3.3.1 前置准备:创建Oracle序列
sql
-- 创建用户表主键序列,从1开始自增
CREATE SEQUENCE SEQ_USER_ID
START WITH 1
INCREMENT BY 1
NOCACHE;3.3.2 selectKey 核心属性
-
keyProperty:绑定实体类接收主键的属性名
-
resultType:主键数据类型(int/long)
-
order:取值BEFORE/AFTER,Oracle序列需前置获取,固定为BEFORE
3.3.3 完整实战代码
XML
<!-- Oracle序列主键回填标准写法 -->
<insert id="insertUser">
<!-- 前置查询序列生成主键,回填到实体id属性 -->
<selectKey keyProperty="id" resultType="int" order="BEFORE">
SELECT SEQ_USER_ID.NEXTVAL FROM DUAL
</selectKey>
-- 携带回填的主键插入数据
INSERT INTO user(id,user_name,age,email)
VALUES(#{id},#{userName},#{age},#{email})
</insert>3.4 两种主键回填方式核心区别
| 对比维度 | MySQL自增回填 | Oracle序列回填 |
|---|---|---|
| 核心配置 | useGeneratedKeys + keyProperty | selectKey 标签手动配置 |
| 主键生成时机 | 插入数据后数据库生成 | 插入数据前序列预生成 |
| order属性 | 无需配置 | 固定BEFORE(前置获取) |
| 适用场景 | MySQL、PostgreSQL自增主键 | Oracle、国产数据库序列主键 |
总结:
-
MySQL 自增主键自动回填
-
Oracle 序列方式主键获取回填
4. 批量执行器(Batch执行模式·完整版原理+实战+坑点+调优)
MyBatis 批量执行器是专门解决大批量增删改数据IO低效 问题的核心执行模式,区别于普通逐条执行模式,通过预编译SQL缓存、累积SQL批量提交的机制,大幅减少数据库网络交互与事务提交次数,是数据导入、批量更新、批量迁移场景的核心优化方案,原生无需依赖第三方插件,性能远超普通循环执行。
4.1 核心底层原理
普通执行器(Simple)每次执行增删改SQL,都会完成一次「预编译→数据库交互→事务提交」完整流程,大批量数据操作会产生大量数据库IO,极易导致性能瓶颈、连接池耗尽。
Batch批量执行器核心机制:
-
SQL预编译复用:相同结构的SQL仅首次预编译,后续直接复用编译后的SQL模板,减少编译开销
-
语句累积执行:多条SQL先缓存至本地事务缓冲区,不立即提交数据库,达到阈值后统一批量提交
-
单次IO批量落地:数百上千条SQL仅需一次或少量几次数据库交互,极大降低网络IO损耗
-
事务统一管控:批量操作归属同一事务,支持整体提交、异常整体回滚,保证数据原子性
4.2 三大执行器对比(核心区分)
| 执行器类型 | 核心特性 | 适用场景 | 性能表现 |
|---|---|---|---|
| Simple(默认普通执行器) | 每条SQL独立编译、独立提交、立即生效 | 单条CRUD、少量数据操作、实时业务 | 小数据量高效,大批量极度低效 |
| Reuse(复用执行器) | 复用预编译SQL,每条SQL独立提交 | 重复结构SQL、中等数据量操作 | 优于Simple,无批量提交优化 |
| Batch(批量执行器) | SQL预编译复用+累积批量提交,延迟落地 | 大批量导入、批量更新、批量删除、数据迁移 | 大批量数据性能提升10~100倍 |
4.3 两种实战实现方式(原生+SpringBoot)
4.3.1 原生MyBatis批量执行(基础标准版)
通过 SqlSession 工厂指定执行器类型创建批量会话,手动管控提交与回滚,是最基础的批量实现方式。
java
import org.apache.ibatis.executor.ExecutorType;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
// 开启批量执行会话:指定Batch执行器、手动事务提交
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false);
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
try {
// 批量插入1000条数据,仅累积不立即提交
for (int i = 0; i < 1000; i++) {
User user = new User();
user.setUserName("批量用户" + i);
user.setAge(20 + i);
userMapper.insertUser(user);
}
// 累积完成,统一批量提交,一次性落地数据库
sqlSession.commit();
} catch (Exception e) {
// 异常整体回滚,保证数据一致
sqlSession.rollback();
e.printStackTrace();
} finally {
// 关闭会话,释放资源
sqlSession.close();
}4.3.2 SpringBoot批量执行(企业主流)
SpringBoot环境通过 SqlSessionTemplate 绑定批量执行器,无需手动管理会话,适配Spring事务体系,工程化更强。
java
import org.apache.ibatis.executor.ExecutorType;
import org.mybatis.spring.SqlSessionTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.Resource;
@Service
public class UserBatchService {
// 注入批量会话模板
@Resource
private SqlSessionTemplate sqlSessionTemplate;
@Transactional(rollbackFor = Exception.class)
public void batchInsertUser() {
// 获取批量执行Mapper
UserMapper userMapper = sqlSessionTemplate.getMapper(UserMapper.class);
for (int i = 0; i < 1000; i++) {
User user = new User();
user.setUserName("Spring批量用户" + i);
user.setAge(22);
userMapper.insertUser(user);
}
// 自动批量提交、异常自动回滚
}
}4.4 批量执行核心特性与限制(必记)
-
主键回填失效:Batch模式下SQL预编译后批量执行,新增数据主键不会立即回填到实体类,循环体内无法获取新增ID,需批量执行完毕后通过SQL查询主键
-
一级缓存延迟更新:批量操作数据未提交前,一级缓存不会同步更新,当前会话查询无法读取未提交的批量数据
-
仅支持同结构SQL批量:仅相同模板的增删改SQL可复用预编译,不同结构SQL无法批量优化
-
无自动分批机制:原生Batch不会自动拆分大批量数据,超量数据易触发MySQL超长SQL异常,需手动分批
-
查询实时性失效:批量未提交前,数据库无数据,跨会话查询不到未落地的批量数据
4.5 生产最优实践(分批批量执行)
针对原生批量无分批、超长报错问题,企业标准方案为 Batch执行器 + 手动分批,兼顾性能与稳定性。
java
// 分批阈值:单次批量500条(适配MySQL默认SQL长度限制)
private static final int BATCH_SIZE = 500;
public void batchInsertByPage(List<User> userList) {
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false);
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
try {
for (int i = 0; i < userList.size(); i++) {
userMapper.insertUser(userList.get(i));
// 每累积500条提交一次
if (i > 0 && i % BATCH_SIZE == 0) {
sqlSession.commit();
// 清空本地缓存,避免内存累积溢出
sqlSession.clearCache();
}
}
// 提交剩余未处理数据
sqlSession.commit();
} catch (Exception e) {
sqlSession.rollback();
throw new RuntimeException("批量新增失败");
} finally {
sqlSession.close();
}
}4.6 生产高频坑点(必避)
-
批量后获取ID为空:误用Batch模式后在循环内获取主键ID,因回填失效导致空指针,需批量完成后统一查询
-
大批量SQL超长报错 :未分批直接上万条批量执行,超出MySQL
max_allowed_packet限制,触发SQL语法异常 -
内存溢出风险:大批量数据累积不提交、不清空缓存,导致会话内存持续占用,引发OOM
-
事务超时:超大批量单次事务执行时间过长,触发数据库事务超时、锁等待超时
-
混用查询导致数据错乱:批量未提交时穿插查询操作,读取不到未落地数据,引发业务逻辑异常
4.7 调优参数配置
配合数据库参数优化批量执行效率,企业标配配置:
-
MySQL :调大
max_allowed_packet允许更大批量SQL,开启批量插入优化 -
分批阈值:常规业务500~1000条/批,超大字段数据200~300条/批
-
缓存清理 :每批次提交后强制
clearCache(),释放会话内存
4.8 面试高频考点总结
-
Batch批量执行器的底层优化原理?和普通执行器的核心区别?
-
为什么批量执行时主键回填失效?如何解决?
-
原生Batch批量的优缺点,生产为什么必须手动分批?
-
批量操作出现数据不一致、SQL超长报错的排查与解决方案?
面试满分总结:
MyBatis Batch批量执行器通过复用SQL预编译、累积SQL批量提交,大幅减少数据库IO交互,适配大批量增删改场景;
核心短板为主键回填失效、无自动分批,生产需采用「Batch执行器+固定分批提交+缓存清理」方案,兼顾性能与数据稳定性,同时规避事务超时、SQL超长、内存溢出等问题。
总结:
BATCH 执行模式,批量提交 SQL,减少数据库交互次数
5. 存储过程调用(完整版·实战语法+入参出参+游标结果集+坑点面试)
存储过程是数据库端预编译的一组SQL语句集合,可封装复杂批量逻辑、事务逻辑、多表联动查询,MyBatis 支持原生调用数据库存储过程,完美适配老旧系统迁移、数据库复杂运算、批量数据处理、多结果集返回 场景。核心通过 call 语法 实现,支持入参、出参、游标多结果集、多返回值,以下为全套企业实战用法、配置规范与避坑要点。
5.1 核心前置配置与规则
-
调用语法 :MyBatis 固定使用
{call 存储过程名(参数)}标准语法调用,适配 MySQL、Oracle 主流数据库 -
全局配置:无需额外开启开关,MyBatis 原生支持存储过程调用,直接通过 mapper 标签编写即可
-
参数分类:IN(入参)、OUT(出参)、INOUT(出入参),适配不同传参取值场景
-
执行特性:存储过程在数据库端预编译执行,执行效率高,适合高频复杂固定逻辑,灵活性低于动态SQL
5.2 基础准备:创建数据库存储过程(MySQL示例)
以用户数据查询、数据统计、批量处理场景为例,创建三类常用存储过程,用于后续MyBatis调用实战演示。
1. 带入参、出参的单值返回存储过程:根据用户ID查询用户名,同时返回状态码
sql
DELIMITER //
CREATE PROCEDURE proc_get_user_info(
IN user_id INT, -- 入参:用户ID
OUT user_name VARCHAR(30), -- 出参:用户名
OUT status INT -- 出参:查询状态码
)
BEGIN
SELECT user_name INTO user_name FROM user WHERE id = user_id;
IF user_name IS NULL THEN
SET status = 0; -- 0-查询无数据
ELSE
SET status = 1; -- 1-查询成功
END IF;
END //
DELIMITER ;2. 带游标多结果集存储过程:根据年龄区间批量查询用户列表
sql
DELIMITER //
CREATE PROCEDURE proc_get_user_list(IN min_age INT, IN max_age INT)
BEGIN
-- 直接返回结果集(游标形式)
SELECT * FROM user WHERE age BETWEEN min_age AND max_age;
END //
DELIMITER ;3. 出入参复用存储过程:累加运算,实现参数双向传递
sql
DELIMITER //
CREATE PROCEDURE proc_data_calc(INOUT num INT)
BEGIN
SET num = num + 10;
END //
DELIMITER ;5.3 场景一:入参+出参单值调用(企业高频)
适用于单数据查询、数据校验、状态返回、简单运算场景,通过实体/Map接收出入参,获取存储过程返回的多个出参结果。
1)Mapper接口定义
java
import org.apache.ibatis.annotations.Param;
import java.util.Map;
// 调用带出入参的存储过程,Map接收多返回值
void getUserInfo(@Param("param") Map<String,Object> param);2)Mapper XML调用配置(核心)
XML
<!-- 调用存储过程:入参+多出参 -->
<select id="getUserInfo" statementType="CALLABLE">
{call proc_get_user_info(
#{param.userId,mode=IN,jdbcType=INTEGER},
#{param.userName,mode=OUT,jdbcType=VARCHAR},
#{param.status,mode=OUT,jdbcType=INTEGER}
)}
</select>核心属性说明:
-
statementType="CALLABLE":固定配置,标识当前SQL为存储过程调用,必须配置
-
mode属性:IN=入参、OUT=出参、INOUT=出入参,精准匹配存储过程参数类型
-
jdbcType:必须指定参数数据库类型,避免类型转换报错
3)业务调用测试代码
java
Map<String,Object> paramMap = new HashMap<>();
// 传入入参
paramMap.put("userId", 1);
// 调用存储过程
userMapper.getUserInfo(paramMap);
// 获取出参返回结果
String userName = (String) paramMap.get("userName");
Integer status = (Integer) paramMap.get("status");
System.out.println("查询状态:" + status + ",用户名:" + userName);5.4 场景二:游标多结果集调用(批量数据返回)
适用于批量数据查询、多表数据返回、报表统计场景,存储过程通过游标返回数据集,MyBatis自动映射为实体List集合。
1)Mapper接口定义
java
List<User> getUserListByAge(@Param("minAge") Integer minAge, @Param("maxAge") Integer maxAge);2)Mapper XML调用配置
XML
<!-- 调用返回结果集的存储过程 -->
<select id="getUserListByAge" resultType="User" statementType="CALLABLE">
{call proc_get_user_list(#{minAge,mode=IN},#{maxAge,mode=IN})}
</select>3)业务调用测试
java
List<User> userList = userMapper.getUserListByAge(18, 30);
System.out.println("批量查询用户列表:" + userList);5.5 场景三:INOUT出入参复用调用
适用于参数二次加工、数据运算、原值修改返回场景,参数既作为入参传入,又作为出参返回修改后的值。
1)Mapper接口定义
java
void dataCalc(@Param("num") Integer num);2)Mapper XML调用配置
XML
<select id="dataCalc" statementType="CALLABLE">
{call proc_data_calc(#{num,mode=INOUT,jdbcType=INTEGER})}
</select>5.6 Oracle存储过程适配差异
Oracle存储过程无直接返回结果集语法,需通过游标出参实现多数据返回,核心适配规则:
-
游标参数必须定义为
mode=OUT,jdbcType=CURSOR,resultMap=自定义映射ID -
调用语法兼容
{call 存储过程()},无需修改格式 -
必须手动指定resultMap映射游标返回的字段,保证数据封装正常
5.7 生产高频坑点(必避)
-
缺失statementType属性 :未配置
statementType="CALLABLE"会导致调用失败,报SQL语法错误 -
出参未指定jdbcType:出参必须声明数据库类型,否则无法接收返回值,参数为空
-
参数mode混淆:入参写OUT、出参写IN,导致参数传递异常、数据无法返回
-
多结果集映射错乱:存储过程返回多表数据时,需单独定义resultMap精准映射,避免字段赋值错乱
-
事务嵌套冲突:存储过程内部自带事务逻辑时,禁止外部嵌套Spring事务,避免事务失效、数据错乱
-
参数数量不匹配:调用参数数量、顺序、类型必须与存储过程定义完全一致,严格匹配数据库定义
5.8 适用场景与优缺点总结
优点:
-
SQL预编译,数据库端执行,批量运算性能更高
-
封装复杂数据库逻辑,简化业务层代码,减少网络IO交互
-
支持多入参、多出参、多结果集,适配复杂统计、批量处理场景
缺点:
-
存储过程绑定数据库,可移植性差,换库需重写逻辑
-
逻辑固化,无法动态调整,灵活性远不如MyBatis动态SQL
-
调试困难、版本管理繁琐,不适合互联网快速迭代项目
生产适用场景 :老旧系统维护、固定批量数据处理、数据库复杂运算、报表统计,新型互联网项目不推荐大量使用
5.9 面试高频考点
-
MyBatis调用存储过程必须配置什么核心属性?作用是什么?
-
IN/OUT/INOUT三种参数模式的区别与适用场景
-
MySQL与Oracle存储过程调用的核心差异
-
存储过程调用参数为空、返回值获取失败的排查思路
-
存储过程相较于动态SQL的优缺点与生产选型依据
面试满分总结:
MyBatis通过 {call} 语法调用存储过程,需配置 statementType="CALLABLE" 标识调用类型;
支持IN入参、OUT出参、INOUT出入参三种参数模式,可适配单值返回、游标多结果集返回场景;优势是批量运算性能高、简化业务代码,短板是可移植性差、灵活性低、调试繁琐,仅适用于老旧系统与固定批量业务场景。
四、结果集映射体系
1. 基础映射(完整版·原理+实战+区别+避坑)
MyBatis基础映射是结果集封装的核心底层能力,核心作用是将数据库查询的二维结果集,自动/手动封装为Java实体、基本类型、集合、Map等对象 ,所有关联映射、复杂映射都基于基础映射延伸。基础映射仅包含两大核心标签:resultType(自动映射) 、resultMap(手动自定义映射),二者适配不同业务场景,是开发必备、面试高频考点。
1.1 resultType 自动映射(默认核心)
resultType是MyBatis默认的自动映射方案,无需手动配置字段与属性对应关系,满足命名规则即可自动封装结果集,开发简洁、适用于绝大多数简单查询场景。
1.1.1 核心映射规则
-
精准同名匹配 :数据库字段名与Java实体属性名完全一致,自动映射生效
-
驼峰下划线自动适配 :开启全局
mapUnderscoreToCamelCase=true后,数据库下划线字段(user_name)自动匹配实体驼峰属性(userName),企业开发标配 -
忽略大小写:字段与属性名大小写不敏感(数据库字段默认不区分大小写),UserName与username可正常映射
-
未匹配字段置空:查询字段无对应实体属性、或属性无对应查询字段,不会报错,对应属性自动赋值为null
1.1.2 支持的返回类型(全覆盖)
resultType可配置各类返回值类型,覆盖所有基础查询场景:
-
自定义实体类:如User、Order,适配单表完整字段查询
-
基本数据类型:Integer、String、Long、Double,适配单字段统计查询(数量、名称、ID)
-
集合嵌套载体:List、Set无需单独配置,resultType写泛型类型即可
-
Map集合:resultType="java.util.Map",动态字段查询,无固定实体场景
-
void:无返回值,适配纯增删改、无需结果返回的操作
1.1.3 实战标准代码
场景:开启驼峰映射,查询用户基础信息,自动封装User实体
XML
<!-- 自动映射:数据库user_name → 实体userName -->
<select id="selectUserById" resultType="User">
SELECT id,user_name,age,email,create_time FROM user WHERE id = #{id}
</select>1.1.4 核心优缺点
-
优点:零配置、代码简洁、开发高效,适配90%单表简单查询
-
缺点:灵活性差,无法适配字段名不一致、字段类型不匹配、自定义字段、嵌套关联场景
1.2 resultMap 手动自定义映射(高阶通用)
resultMap是手动精准映射方案,可自定义数据库字段与Java属性的对应关系、处理类型转换、忽略字段、自定义映射规则,是复杂映射的核心,完美弥补resultType的短板,适配所有特殊查询场景。
1.2.1 核心标签结构与属性
完整resultMap包含4个核心子标签,各司其职,覆盖所有映射需求:
-
id:resultMap唯一标识,供SQL语句引用,全局唯一
-
type:绑定对应的Java实体类全路径/别名
-
id标签:标识主键字段,用于缓存匹配、关联查询去重、提升映射效率(必填优化项)
-
result标签:普通字段映射,指定数据库column与实体property对应关系
-
jdbcType(可选):指定数据库字段类型,解决类型转换异常
-
javaType(可选):指定Java属性类型,适配枚举、自定义类型
1.2.2 完整实战案例(字段名不一致适配)
场景:数据库字段为user_name、user_age,实体属性为name、age,名称完全不匹配,自动映射失效,需手动配置resultMap
XML
<!-- 自定义结果集映射规则 -->
<resultMap id="UserResultMap" type="User">
<!-- 主键映射:必写,优化缓存与关联查询 -->
<id column="id" property="id"/>
<!-- 普通字段手动映射:数据库字段 → 实体属性 -->
<result column="user_name" property="name"/>
<result column="user_age" property="age"/>
<result column="email" property="email"/>
</resultMap>
<!-- 引用自定义映射规则 -->
<select id="selectUserByCustomMap" resultMap="UserResultMap">
SELECT id,user_name,user_age,email FROM user WHERE id = #{id}
</select>1.2.3 高级特性:字段忽略、默认值、类型转换
-
忽略数据库字段:SQL查询字段无需全部映射,resultMap中未配置的字段自动忽略,不封装到实体
-
自定义类型转换:结合TypeHandler实现数据库字符串与Java枚举、JSON字段的自动转换
-
别名适配:支持SQL字段别名映射,适配多表联查同名字段场景
1.2.4 核心优缺点
-
优点:灵活性极强、映射精准、支持特殊字段适配、支持关联嵌套映射、适配复杂业务
-
缺点:配置繁琐、代码量多,简单查询场景冗余
1.3 resultType与resultMap 核心区别(面试必背)
|--------|------------------|----------------------|
| 对比维度 | resultType(自动映射) | resultMap(手动映射) |
| 映射方式 | 框架自动匹配字段与属性 | 开发者手动指定映射关系 |
| 灵活性 | 低,仅支持同名/驼峰匹配 | 极高,适配所有特殊场景 |
| 适用场景 | 单表简单查询、字段命名规范场景 | 字段不匹配、联表查询、嵌套关联、类型转换 |
| 配置复杂度 | 零配置,直接指定类型 | 需手动编写映射规则,配置繁琐 |
| 关联查询支持 | 不支持一对一、一对多嵌套 | 完美支持嵌套关联映射 |
1.4 生产核心规范与避坑点(必记)
-
规范1:优先使用自动映射:项目统一开启驼峰命名转换,字段命名规范的单表查询,一律用resultType,简化代码
-
规范2:统一复用resultMap:同一实体的自定义映射全局定义一次,所有SQL统一引用,避免重复配置、映射不一致
-
规范3:主键id标签必写:resultMap中必须配置<id/>标签,否则关联查询、缓存匹配会出现数据错乱、重复数据问题
-
坑点1:驼峰映射未开启导致字段为空:数据库下划线字段、实体驼峰属性,未开启全局配置,自动映射失效,属性值为null
-
坑点2:resultType与resultMap混用:同一select标签只能二选一,同时配置会启动报错
-
坑点3:字段类型不匹配报错:数据库时间类型、枚举类型,自动映射失败,必须用resultMap+TypeHandler手动转换
-
坑点4:多表联查字段重名覆盖:联表查询存在同名字段,自动映射会相互覆盖,必须用resultMap指定别名映射
1.5 面试高频满分考点
-
resultType的自动映射原理?驼峰命名映射的开启条件?
-
resultType和resultMap的区别、各自适用场景?
-
为什么resultMap必须配置id主键标签?不配置会有什么问题?
-
查询字段和实体属性不一致时,如何解决映射为空问题?
-
多表联查出现字段值覆盖的原因及解决方案?
核心总结:基础映射分为自动映射(resultType)与手动映射(resultMap),规范场景优先用resultType提升开发效率,特殊复杂场景用resultMap保证映射精准;全局开启驼峰映射是企业标配,resultMap主键标签是关联查询与缓存的核心基础,二者互补适配所有单表、多表基础查询场景。
-
resultType:字段与属性名一致自动映射
-
resultMap:自定义手动映射,解决名称不一致场景
2. 关联关系映射(完整版·原理+实战+懒加载+坑点+面试)
MyBatis 关联关系映射是解决数据库多表关联、Java实体嵌套封装 的核心能力,专门用于处理一对一、一对多数据表关联场景,自动将联表查询的多维结果集,封装为Java嵌套实体对象,彻底告别手动封装关联数据的冗余代码。核心依托 association(一对一) 、collection(一对多) 两大标签实现,搭配嵌套结果、嵌套查询两种模式,适配所有多表关联业务,同时配套延迟加载机制优化查询性能,是开发高阶业务、面试高频核心考点。
2.1 核心前置认知
2.1.1 关联关系适配场景
-
一对一:单表数据唯一对应另一张表单条数据,如「用户-用户详情」「订单-订单详情」「员工-工号信息」
-
一对多:单表数据对应另一张表多条数据,如「用户-多张订单」「分类-多个商品」「部门-多名员工」
2.1.2 核心标签作用
-
association :封装单个嵌套实体对象,适配一对一关联,属性为单个对象
-
collection :封装嵌套集合对象,适配一对多关联,属性为List/Set集合
2.1.3 两种通用查询模式
-
嵌套结果(联表查询) :单条SQL联表查询所有关联数据,一次性封装完成,性能更高,无多余数据库请求
-
嵌套查询(分步查询) :先查主表、再通过子查询查关联表,支持延迟加载,按需加载关联数据
2.2 一对一关联映射(association)
2.2.1 业务场景与实体结构
场景:一个用户对应一条用户详情信息(一对一)
主表:user(用户表),
关联表:user_info(用户详情表),
关联字段:user.id = user_info.user_id
嵌套实体结构:
java
// 用户主实体
@Data
public class User {
private Integer id;
private String userName;
private Integer age;
// 一对一嵌套:单个用户详情对象
private UserInfo userInfo;
}
// 用户详情关联实体
@Data
public class UserInfo {
private Integer id;
private String phone;
private String address;
private Integer userId;
}2.2.2 方式一:嵌套结果模式(联表查询·高性能首选)
核心:通过一条JOIN联表SQL查询主表+关联表全部数据,借助resultMap的association标签自动封装嵌套实体,仅一次数据库交互,生产主流用法。
XML
<!-- 一对一关联映射ResultMap -->
<resultMap id="UserWithInfoResultMap" type="User">
<!-- 主表用户主键 -->
<id column="id" property="id"/>
<result column="user_name" property="userName"/>
<result column="age" property="age"/>
<!-- 一对一关联封装用户详情 -->
<association property="userInfo" javaType="UserInfo">
<id column="info_id" property="id"/>
<result column="phone" property="phone"/>
<result column="address" property="address"/>
<result column="user_id" property="userId"/>
</association>
</resultMap>
<!-- 联表查询用户+详情数据 -->
<select id="getUserWithInfoById" resultMap="UserWithInfoResultMap">
SELECT
u.id,u.user_name,u.age,
ui.id info_id,ui.phone,ui.address,ui.user_id
FROM user u
LEFT JOIN user_info ui ON u.id = ui.user_id
WHERE u.id = #{id}
</select>2.2.3 方式二:嵌套查询模式(分步查询·支持懒加载)
核心:分两次SQL查询,先查主表用户数据,再根据用户ID子查询详情数据,优势是支持延迟加载,按需触发关联查询。
XML
<!-- 分步查询:根据用户ID查询详情 -->
<select id="getUserInfoByUserId" resultType="UserInfo">
SELECT id,phone,address,user_id FROM user_info WHERE user_id = #{userId}
</select>
<!-- 主表查询映射,关联子查询 -->
<resultMap id="UserWithInfoLazyMap" type="User">
<id column="id" property="id"/>
<result column="user_name" property="userName"/>
<result column="age" property="age"/>
<!-- 关联分步查询:column为传入子查询的参数列,select为子查询方法ID -->
<association
property="userInfo"
select="com.example.mapper.UserMapper.getUserInfoByUserId"
column="id"
fetchType="lazy"/>
</resultMap>
<!-- 主查询用户数据 -->
<select id="getUserLazyInfoById" resultMap="UserWithInfoLazyMap">
SELECT id,user_name,age FROM user WHERE id = #{id}
</select>2.2.4 association核心属性说明
-
property:主实体中嵌套关联对象的属性名,必须与实体字段一致
-
javaType:关联实体的Java类型,必填,指定封装对象类型
-
select:分步查询的子查询方法全路径ID
-
column:主查询结果中传递给子查询的字段/主键
-
fetchType:lazy(延迟加载)/eager(立即加载),优先级高于全局配置
2.3 一对多关联映射(collection)
2.3.1 业务场景与实体结构
场景:一个用户对应多条订单数据(一对多)
主表:user(用户表),关联表:order(订单表),关联字段:user.id = order.user_id
嵌套实体结构:
java
// 用户主实体
@Data
public class User {
private Integer id;
private String userName;
// 一对多嵌套:订单集合
private List<Order> orderList;
}
// 订单关联实体
@Data
public class Order {
private Integer id;
private String orderNo;
private Double amount;
private Integer userId;
}2.3.2 方式一:嵌套结果模式(联表查询·性能最优)
通过LEFT JOIN联表查询,MyBatis自动根据主键去重,将多条订单数据封装为集合,单次SQL完成查询封装。
XML
<!-- 一对多关联映射ResultMap -->
<resultMap id="UserWithOrderResultMap" type="User">
<!-- 主表主键:必须配置,用于自动去重合并数据 -->
<id column="id" property="id"/>
<result column="user_name" property="userName"/>
<!-- 一对多封装订单集合 -->
<collection property="orderList" ofType="Order">
<id column="order_id" property="id"/>
<result column="order_no" property="orderNo"/>
<result column="amount" property="amount"/>
<result column="order_user_id" property="userId"/>
</collection>
</resultMap>
<!-- 用户关联订单联表查询 -->
<select id="getUserWithOrderById" resultMap="UserWithOrderResultMap">
SELECT
u.id,u.user_name,
o.id order_id,o.order_no,o.amount,o.user_id order_user_id
FROM user u
LEFT JOIN `order` o ON u.id = o.user_id
WHERE u.id = #{id}
</select>2.3.3 方式二:嵌套查询模式(分步查询·懒加载适配)
先查用户信息,再根据用户ID批量查询对应订单集合,支持延迟加载,适合关联数据量大、无需每次都查询关联数据的场景。
XML
<!-- 分步查询:根据用户ID查询订单列表 -->
<select id="getOrderListByUserId" resultType="Order">
SELECT id,order_no,amount,user_id FROM `order` WHERE user_id = #{userId}
</select>
<!-- 一对多分步查询映射 -->
<resultMap id="UserWithOrderLazyMap" type="User">
<id column="id" property="id"/>
<result column="user_name" property="userName"/>
<!-- 关联订单集合分步查询 -->
<collection
property="orderList"
select="com.example.mapper.UserMapper.getOrderListByUserId"
column="id"
fetchType="lazy"/>
</resultMap>
<!-- 主查询用户数据 -->
<select id="getUserLazyOrderById" resultMap="UserWithOrderLazyMap">
SELECT id,user_name FROM user WHERE id = #{id}
</select>2.3.4 collection核心属性说明
-
property:主实体中集合属性名(如orderList)
-
ofType:集合中存储的实体类型(区别于javaType,集合泛型类型)
-
select/column/fetchType:用法与association完全一致,适配分步查询与懒加载
2.4 延迟加载机制(核心优化·面试高频)
2.4.1 核心原理
延迟加载(懒加载)仅适用于嵌套分步查询,查询主表数据时,不立即查询关联数据,仅在代码中调用关联属性时,才触发子查询加载关联数据,大幅减少无效SQL查询,提升查询性能。
2.4.2 全局懒加载配置(yml)
XML
mybatis:
configuration:
# 开启全局延迟加载总开关
lazy-loading-enabled: true
# 关闭激进懒加载(默认新版关闭)
aggressive-lazy-loading: false2.4.3 核心特性
-
按需加载:不调用关联属性,不执行关联SQL,避免冗余查询
-
就近优先:方法级fetchType配置优先于全局配置
-
懒加载缓存:同一会话内,加载过的关联数据会缓存,重复调用无需重复查询
2.4.4 激进懒加载说明
-
aggressive-lazy-loading=true:任意属性调用,都会触发所有懒加载关联数据加载
-
aggressive-lazy-loading=false(推荐):仅调用指定关联属性时,才加载对应数据,精准按需加载
2.5 两种查询模式核心对比(生产选型必看)
|------|-------------------|---------------------|
| 对比维度 | 嵌套结果(联表查询) | 嵌套查询(分步查询) |
| 查询次数 | 单次SQL查询 | 多次SQL分步查询 |
| 性能表现 | 性能高,无多余IO | 常规场景略低效,存在N+1风险 |
| 延迟加载 | 不支持,一次性加载全部数据 | 支持精准懒加载 |
| 适用场景 | 确定需要关联数据、小数据量关联查询 | 关联数据量大、按需使用、复杂多关联场景 |
2.6 生产高频坑点(必避)
-
坑点1:一对多映射未写id主键标签 :导致主表数据无法去重,出现多条重复主数据、关联数据错乱,一对多resultMap必须配置主表id标签
-
坑点2:分步查询N+1查询问题:批量查询主表数据时,会循环触发N次关联子查询,数据库IO暴增,解决方案:优先联表查询、或批量子查询优化
-
坑点3:字段别名重复覆盖:联表查询同名字段未起别名,导致主表/关联表字段值相互覆盖,必须手动指定唯一别名
-
坑点4:懒加载失效:未开启全局lazy-loading-enabled、或被激进懒加载覆盖、或使用了立即加载配置,导致懒加载不生效
-
坑点5:集合泛型配置错误:collection误用javaType代替ofType,导致集合封装失败、类型转换异常
-
坑点6:关联数据null空值:关联查询使用INNER JOIN,无关联数据时主数据丢失,业务场景优先使用LEFT JOIN
2.7 N+1查询问题(原理+解决方案·面试必考)</h5 id="1472">2.7.1 问题成因使用嵌套分步查询 批量查询主数据时:先执行1次SQL查询全部主数据(N条),再为每条主数据单独执行1次关联子查询,最终产生 1+N 次SQL查询 ,即N+1问题,大批量数据场景会严重拖垮性能。2.7.2 解决方案最优方案 :批量查询场景统一使用嵌套结果联表查询 ,单次SQL完成所有数据查询,彻底规避N+1折中方案 :分步查询改造为批量IN查询 ,一次查询全部关联数据,内存匹配封装,减少查询次数辅助方案:合理使用懒加载,仅按需加载关联数据,减少无效查询2.8 面试满分核心考点
-
association和collection标签的作用、适用场景、核心属性区别?
-
嵌套结果与嵌套查询的区别、性能差异、生产选型依据?
-
MyBatis延迟加载的实现原理、全局配置、优缺点?
-
N+1查询问题的成因、危害、三种解决方案?
-
一对多映射为什么必须配置id主键标签?不配置会出现什么问题?
-
懒加载失效的常见原因排查思路?
核心总结:
一对一关联用association封装单个实体,一对多关联用collection封装集合;
嵌套结果联表查询性能最优,适合固定关联查询,嵌套分步查询支持懒加载,适合按需查询场景;
生产需规避N+1查询、字段覆盖、数据重复等坑点,通过主键映射、合理选型、懒加载优化保证查询性能与数据准确性。
3. 两种查询模式(完整版·原理+实战+性能+坑点+根治N+1)
MyBatis 多表关联查询仅分为嵌套结果查询(联表查询) 、**嵌套查询(分步子查询)**两种核心模式,所有一对一、一对多关联场景均基于这两种模式实现。两种模式核心差异体现在SQL执行次数、性能、懒加载支持、适用场景,是生产开发选型、面试高频核心考点,下面做全维度补全解析。
3.1 嵌套结果查询(联表多字段封装模式)
3.1.1 核心原理
通过单条LEFT JOIN/RIGHT JOIN/INNER JOIN联表SQL ,一次性查询主表+关联表的所有字段数据,MyBatis依托自定义resultMap,根据主键ID自动去重合并数据,将扁平的联表结果集,自动封装为Java嵌套实体/集合对象,全程仅一次数据库IO交互。
3.1.2 核心执行流程
编写联表SQL查询全量数据 → 数据库返回扁平多行结果集 → MyBatis根据resultMap主键匹配 → 自动合并重复主表数据、封装关联嵌套数据 → 最终返回完整嵌套实体。
3.1.3 核心优势
-
性能最优:仅执行1次SQL,无多余数据库IO,彻底规避N+1查询问题,适配批量、分页、大数据量关联查询
-
数据一致性高:单次SQL查询,基于数据库事务快照,无数据延迟、数据不一致问题
-
配置稳定:无跨Mapper调用、无参数传递,报错率极低,生产稳定性强
3.1.4 核心短板
-
不支持延迟加载:无论业务是否需要关联数据,都会一次性查询封装所有关联数据,小场景存在轻微性能冗余
-
复杂多表联表臃肿:三张及以上表联查时,SQL语句冗长、可读性差、维护难度高
-
无法按需裁剪数据:全局一次性加载所有嵌套关联数据,无法灵活控制加载字段
3.1.5 生产适用场景
-
明确需要同时使用主表+关联表数据的业务场景
-
批量查询、分页查询、列表展示类关联业务
-
对查询性能要求高、禁止出现N+1问题的高并发场景
-
表关联数量少(1-2张表)、SQL简洁的关联查询
3.2 嵌套查询(分步子查询模式)
3.2.1 核心原理
拆分两次及以上独立SQL分步查询:
第一步查询主表数据,获取主表主键/关联字段;
第二步通过子查询查询关联表数据,通过字段传参绑定主从数据,最终由MyBatis整合封装为嵌套实体。该模式核心依托association/collection的select、column属性实现。
3.2.2 核心执行流程
执行主查询SQL获取主数据集合 → 提取主数据关联字段 → 作为参数传入子查询SQL → 查询关联数据 → 内存中匹配合并主从数据 → 封装嵌套实体。
3.2.3 核心优势
-
支持延迟加载(核心亮点) :可配置全局/局部懒加载,不用不查、按需加载,大幅减少无效SQL查询
-
SQL解耦性强:主查询、子查询拆分,单条SQL简洁,多表关联时代码可读性、可维护性极高
-
灵活度高:可单独优化主查询/子查询SQL,支持差异化配置查询条件、字段
3.2.4 核心短板(致命坑点)
-
存在N+1查询风险:查询N条主数据时,会额外触发N次子查询,总共1+N次SQL请求,大批量数据场景严重拖垮数据库性能
-
数据一致性较弱:多次SQL查询,非同一数据库快照,高并发下可能出现主从数据短暂不一致
-
配置繁琐:需要定义独立子查询方法、配置参数传递,多关联场景配置冗余
3.2.5 生产适用场景
-
关联数据量大、无需每次都加载关联数据,需要按需懒加载的场景
-
三张及以上多表关联,联表SQL过于复杂、难以维护的场景
-
详情页查询、单条主数据查询,无批量查询压力的场景
-
关联数据需要单独权限、单独条件过滤的差异化场景
3.3 两种模式全维度精准对比(生产选型表)
|---------|-----------------|-----------------|
| 对比维度 | 嵌套结果(联表查询) | 嵌套查询(分步查询) |
| SQL执行次数 | 单次SQL执行 | 1次主查询+N次子查询 |
| 查询性能 | 极高,无多余IO,无N+1问题 | 单条查询性能高,批量查询性能差 |
| 延迟加载 | 不支持,全量加载数据 | 完美支持按需懒加载 |
| SQL可维护性 | 简单关联简洁,多表关联臃肿 | 拆分清晰,多表关联维护简单 |
| 数据一致性 | 强,单次快照查询 | 较弱,多次查询存在时差 |
| 批量查询适配 | 完美适配,生产首选 | 严禁使用,极易引发性能雪崩 |
| 核心隐患 | 无性能隐患,仅小场景冗余 | N+1查询性能问题 |
3.4 N+1问题完整根治方案(生产必用)
N+1问题仅存在于嵌套分步查询模式,是生产高频性能坑点,提供三种分级解决方案:
-
最优根治方案(优先) :批量、分页、列表查询场景,统一改用嵌套结果联表查询,单次SQL完成全量数据查询,彻底杜绝N+1隐患
-
折中优化方案 :保留分步查询结构,改造子查询为批量IN查询,先查询所有主数据ID,一次性批量查询全部关联数据,由1+N次查询优化为2次查询
-
规避方案:开启懒加载+精准控制调用,仅单条详情查询使用分步查询,禁止批量循环调用关联属性
3.5 生产高频避坑细则
-
坑点1:嵌套结果数据重复 :一对多联表查询必须在resultMap配置主表id主键标签,否则MyBatis无法去重,导致主数据重复、关联数据错乱
-
坑点2:联表字段覆盖:多表联查同名字段必须手动起唯一别名,再通过resultMap映射,避免字段值相互覆盖
-
坑点3:懒加载失效:嵌套查询必须同时开启全局懒加载、关闭激进懒加载,且方法级fetchType不覆盖全局配置,才能实现按需加载
-
坑点4:批量分步查询:绝对禁止在List集合循环中调用分步查询关联属性,会直接触发大规模N+1查询,拖垮数据库
-
坑点5:INNER JOIN数据丢失:关联查询优先使用LEFT JOIN,无关联数据时保留主数据,避免业务数据缺失
3.6 面试满分总结(必背)
MyBatis关联查询分为嵌套结果联表查询、嵌套分步查询两种模式。
嵌套结果通过单条联表SQL一次性查询全量数据,性能高、无N+1问题、数据一致性强,适配批量、分页、高并发查询;
嵌套分步查询拆分多条SQL,支持延迟加载、SQL解耦性强,适配单条详情、多表复杂关联场景,但存在N+1性能隐患。生产选型遵循批量列表用联表、单条详情用懒加载分步查询的核心原则,通过主键去重、批量IN优化、合理选型规避所有坑点。
4. 延迟加载机制(完整版·原理+配置+执行流程+坑点+面试满分)
MyBatis延迟加载(又称懒加载)是针对多表关联嵌套查询的性能优化机制 ,核心思想为「主数据立即加载,关联数据按需加载」。查询主实体数据时,不执行关联表SQL,仅在代码主动调用嵌套关联属性时,才触发子查询加载关联数据,彻底规避无效SQL查询、减少数据库IO开销,是关联查询核心优化手段,仅适配嵌套分步查询模式,嵌套结果联表查询不支持延迟加载。
4.1 核心底层原理
MyBatis 依托Javassist动态字节码增强技术实现延迟加载,对存在嵌套关联属性的实体类,运行时动态生成代理子类,重写关联属性的getter方法:
-
查询主数据时,仅封装主表字段数据,嵌套关联属性赋值为代理占位对象,不执行任何关联SQL;
-
当程序调用关联属性的getter方法时,代理对象拦截方法调用,触发预定义的子查询SQL;
-
执行子查询获取关联数据,完成属性赋值后返回结果,实现按需加载;
-
同一会话内加载过的关联数据会缓存,重复调用无需重复查询。
4.2 完整开启配置(全局+局部)
4.2.1 SpringBoot全局配置(yml,企业标配)
延迟加载默认关闭,需手动开启全局总开关,同时关闭激进懒加载,实现精准按需加载:
XML
mybatis:
configuration:
# 全局开启延迟加载总开关(默认false关闭)
lazy-loading-enabled: true
# 关闭激进懒加载(新版默认false,旧版需手动配置)
aggressive-lazy-loading: false
# 可选:懒加载查询超时控制
default-statement-timeout: 34.2.2 原生mybatis-config.xml全局配置
XML
<configuration>
<settings>
<!-- 开启全局延迟加载 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 关闭激进懒加载 -->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
</configuration>4.2.3 局部优先级配置(覆盖全局)
可在 association/collection 标签中通过 fetchType 属性单独控制单条关联的加载策略,优先级高于全局配置:
-
fetchType="lazy":局部开启延迟加载(优先全局配置)
-
fetchType="eager":局部关闭延迟加载,立即加载关联数据
示例:
XML
<collection
property="orderList"
select="com.example.mapper.UserMapper.getOrderListByUserId"
column="id"
fetchType="lazy"/>4.3 两种懒加载模式核心区别
4.3.1 精准懒加载(aggressiveLazyLoading=false,推荐)
企业生产唯一推荐模式,按需精准触发:仅当代码调用某一个嵌套关联属性时,仅加载该属性对应的关联数据,其他关联数据仍保持懒加载状态。
示例:用户实体同时嵌套用户详情、订单列表,仅调用getUserInfo() 时,只查询用户详情,不查询订单数据,极致减少无效查询。
4.3.2 激进懒加载(aggressiveLazyLoading=true,废弃不推荐)
老旧版本默认模式,触发即全量加载:只要调用实体中任意一个属性(普通属性/关联属性),就会一次性加载该实体所有嵌套关联数据,失去懒加载按需优化的意义,极易造成性能冗余,生产环境一律关闭。
4.4 完整执行流程拆解
-
主查询执行:执行嵌套分步查询的主SQL,查询主表数据,封装主实体普通字段;
-
代理占位赋值:嵌套关联属性被赋值为MyBatis动态代理占位对象,无真实数据,无关联SQL执行;
-
属性调用拦截:代码调用关联属性getter方法,代理对象拦截调用;
-
子查询执行:自动触发预配置的关联子查询,查询关联表数据;
-
数据封装缓存:封装关联数据赋值给实体属性,同时存入当前会话一级缓存;
-
结果返回:返回完整嵌套数据,同会话重复调用直接读取缓存。
4.5 懒加载缓存联动机制
-
一级缓存复用:同一个SqlSession会话内,已加载的懒加载关联数据会缓存,重复调用关联属性不会重复执行SQL;
-
缓存失效同步:会话内执行增删改操作、手动清空缓存、关闭会话后,懒加载缓存同步失效;
-
二级缓存适配:开启二级缓存后,懒加载数据会纳入二级缓存管理,实现跨会话共享。
4.6 生产适用场景与禁用场景
4.6.1 核心适用场景
单条数据详情查询,关联数据量大、非必展示字段;
实体嵌套多层关联(一对一+一对多),全量加载性能冗余;
大部分业务场景仅使用主数据,极少使用关联数据;
多表关联复杂场景,联表SQL冗长、维护成本高。
4.6.2 禁用/不适用场景
批量查询、分页列表查询(极易触发N+1性能问题);
业务固定需要同时使用主数据+关联数据;
高并发高频查询场景,优先使用联表查询保证性能;
嵌套结果联表查询模式(本身不支持懒加载)。
4.7 生产高频坑点与解决方案
- 坑点1:懒加载失效
原因:未开启全局lazy-loading-enabled、激进懒加载未关闭、局部fetchType覆盖全局、使用联表查询模式。
解决方案:统一开启全局配置、关闭激进懒加载、分步查询按需配置局部懒加载。
- 坑点2:批量查询触发N+1雪崩
原因:循环遍历主数据列表,调用懒加载关联属性,循环触发子查询。
解决方案:批量场景放弃懒加载,改用嵌套结果联表查询。
- 坑点3:序列化空对象问题
原因:未调用关联属性时,关联属性为代理占位对象,序列化出现空值/异常。
解决方案:序列化前主动判断、按需加载,或配置序列化忽略未加载懒加载属性。
- 坑点4:事务内懒加载数据不一致
原因:多次懒加载查询处于同一事务,读取事务未提交数据。
解决方案:核心事务业务优先使用联表查询,保证数据快照一致性。
4.8 面试高频满分考点
- 问:MyBatis延迟加载的实现原理?
答:基于Javassist动态字节码增强,运行时为实体生成代理子类,拦截关联属性getter方法;主查询仅加载主数据,调用关联属性时才触发子查询,实现按需加载。
- 问:精准懒加载和激进懒加载的区别?
答:精准懒加载仅加载当前调用的关联属性数据;激进懒加载调用任意属性都会加载全部关联数据,性能冗余,生产必须关闭。
- 问:延迟加载会引发什么性能问题?如何解决?
答:批量查询场景会触发N+1查询问题;
解决方案:批量列表用联表查询,单条详情用懒加载,规避循环调用关联属性。
- 问:延迟加载的生效前提是什么?
答:必须开启全局lazy-loading-enabled、关闭激进懒加载、使用嵌套分步查询模式,三者缺一不可。
4.9 核心总结
延迟加载是MyBatis针对分步关联查询 的核心性能优化,核心价值是「按需加载、减少无效IO」;生产必须开启精准懒加载、关闭激进懒加载,严格遵循单条详情用懒加载、批量列表用联表查询的选型原则,规避N+1性能坑点,兼顾灵活性与查询性能。
按需加载关联数据,减少无效查询;可配置激进懒加载策略
5. 多类型返回值(完整版·全类型实战+场景+坑点+面试)
MyBatis 支持丰富的返回值类型,适配所有业务查询场景,涵盖基本类型、实体对象、List集合、Map、DTO、分页对象、Void空返回值七大核心类型。所有返回值无需额外复杂配置,依托resultType、resultMap即可实现,下面逐一拆解实战语法、适用场景、核心规范与生产避坑点,全覆盖面试考点。
5.1 基础返回规则(核心前提)
-
resultType:用于简单映射、无嵌套关联的返回值,指定返回值全类名/别名,自动映射字段
-
resultMap:用于字段不匹配、嵌套关联、自定义映射场景,优先级高于resultType
-
单条数据用单个对象返回,多条数据必须用集合接收,严禁单对象接收多结果集
-
数据库NULL值会自动适配Java默认值,不会直接报错,需业务层判空处理
5.2 基本数据类型返回值(String/Integer/Long/Double)
5.2.1 适用场景
单行单列简单查询:统计数量、查询单个字段值、状态查询、字符串名称查询等极简场景。
5.2.2 实战代码示例
Mapper接口:
java
// 查询用户总数(Integer)
Integer selectUserCount();
// 查询用户昵称(String)
String selectUserNameById(Integer id);
// 查询订单总金额(Double)
Double selectOrderTotalAmount();Mapper XML:
XML
<!-- 查询总数,返回Integer -->
<select id="selectUserCount" resultType="Integer">
SELECT COUNT(*) FROM user
</select>
<!-- 查询单个字符串字段,返回String -->
<select id="selectUserNameById" resultType="String">
SELECT user_name FROM user WHERE id = #{id}
</select>
<!-- 查询浮点数值,返回Double -->
<select id="selectOrderTotalAmount" resultType="Double">
SELECT SUM(amount) FROM `order`
</select>5.2.3 核心坑点
-
查询结果为NULL时,基本包装类型会接收null,不会报错,业务层必须判空,避免空指针
-
禁止使用基本数据类型(int/long)接收,NULL赋值会直接抛出类型转换异常,必须用包装类
5.3 单个实体对象返回值
5.3.1 适用场景
根据主键/唯一条件查询单条完整数据,如根据ID查询用户详情、根据订单号查询订单信息。
5.3.2 实战代码示例
Mapper接口:
java
// 单实体返回
User selectUserById(Integer id);Mapper XML:
XML
<!-- 实体返回,resultType写实体别名/全类名 -->
<select id="selectUserById" resultType="User">
SELECT id,user_name,age,email,create_time FROM user WHERE id = #{id}
</select>5.3.3 核心规范与坑点
-
开启驼峰自动映射后,数据库下划线字段自动适配实体驼峰属性,无需手动配置resultMap
-
若查询结果为空,返回null,业务层需判空,避免属性调用空指针
-
查询结果多条时会抛出数据异常,单实体查询必须保证查询条件唯一
5.4 List集合返回值(最常用)
5.4.1 适用场景
条件批量查询、无分页列表查询、模糊查询,返回多条数据集合,是企业开发最常用的返回类型。
5.4.2 实战代码示例
Mapper接口:
java
// 集合返回,无需泛型写法,MyBatis自动封装
List<User> selectUserList(@Param("userName") String userName);Mapper XML:
XML
<!-- 集合查询,resultType写泛型实体类型 -->
<select id="selectUserList" resultType="User">
SELECT id,user_name,age,email,create_time FROM user
<where>
<if test="userName != null and userName != ''">
AND user_name LIKE CONCAT('%',#{userName},'%')
</if>
</where>
</select>5.4.3 核心特性与坑点
-
空结果安全 :无查询数据时,返回空集合(size=0),不会返回null,无需判空,直接遍历即可
-
resultType只需写集合泛型类型,无需写List,MyBatis自动识别集合类型封装
-
支持基本类型集合:List<String>、List<Integer>,适配批量ID、名称查询场景
5.5 Map返回值(灵活动态返回)
5.5.1 适用场景
查询字段不固定、临时字段统计、动态字段返回、无需定义实体的临时查询场景,灵活适配多变查询需求。
5.5.2 两种Map返回模式
模式1:单条Map返回(Map<String,Object>)
单条数据动态返回,key为数据库字段名,value为字段值,适配临时单数据查询。
java
// 接口定义
Map<String,Object> selectUserMapById(Integer id);
XML
<select id="selectUserMapById" resultType="Map">
SELECT id,user_name,age,email FROM user WHERE id = #{id}
</select>模式2:List<Map<String,Object>> 批量Map返回
多条动态数据返回,适配字段不固定的列表查询。
java
List<Map<String,Object>> selectUserMapList();5.5.3 核心坑点
-
Map的key默认是数据库原始字段名(下划线),不会自动驼峰转换,需手动适配
-
无字段类型约束,取值需强转,易出现类型转换异常,禁止核心业务使用
-
可读性、可维护性差,仅用于临时统计、动态查询,不建议长期使用
5.6 自定义DTO返回值(企业核心常用)
5.6.1 适用场景
多表联查、字段裁剪、聚合查询、前端定制化返回场景,隔离数据库实体与前端返回数据,是企业规范开发首选。
5.6.2 实战示例
自定义DTO(前端返回实体):
java
@Data
public class UserOrderDTO {
// 用户字段
private Integer userId;
private String userName;
// 订单聚合字段
private Integer orderCount;
private Double totalAmount;
}Mapper接口与XML:
java
List<UserOrderDTO> selectUserOrderDTOList();
XML
<select id="selectUserOrderDTOList" resultType="com.example.dto.UserOrderDTO">
SELECT
u.id AS userId,
u.user_name AS userName,
COUNT(o.id) AS orderCount,
SUM(o.amount) AS totalAmount
FROM user u
LEFT JOIN `order` o ON u.id = o.user_id
GROUP BY u.id,u.user_name
</select>5.6.3 核心规范
-
DTO字段命名统一使用驼峰,SQL查询字段通过AS别名适配DTO属性名
-
禁止直接返回数据库实体PO,通过DTO脱敏、裁剪字段,保证接口安全性
-
无嵌套关联的DTO直接用resultType,有嵌套关联需自定义resultMap
5.7 分页对象返回值(生产必备)
5.7.1 适用场景
所有列表分页查询场景,基于PageHelper插件实现,返回分页结果对象,包含数据列表、总条数、总页数、页码等分页参数。
5.7.2 实战示例
无需单独改写SQL,只需业务层分页包装:
java
@Test
void testPageQuery() {
// 开启分页:页码1,每页10条
PageHelper.startPage(1,10);
// 普通列表查询
List<User> userList = userMapper.selectUserList(null);
// 封装分页结果
PageInfo<User> pageInfo = new PageInfo<>(userList);
System.out.println("总条数:" + pageInfo.getTotal());
System.out.println("分页数据:" + pageInfo.getList());
}5.7.3 核心特性
-
MyBatis原生无分页返回类型,依托PageHelper插件自动拦截SQL生成分页语句
-
分页返回无需修改Mapper返回值,通过PageInfo包装普通List即可
-
支持总条数、总页数、是否首尾页、分页导航等全套参数
5.8 Void空返回值(增删改专用)
5.8.1 适用场景
新增、修改、删除操作,无需返回数据,仅需执行数据库变更。
5.8.2 实战示例
java
// 无返回值新增
void insertUser(User user);
// 无返回值修改
void updateUser(User user);
// 无返回值删除
void deleteUserById(Integer id);5.8.3 补充说明
-
void返回值默认不接收数据库影响行数,若需要判断执行结果,可改为int返回值(返回影响行数)
-
增删改标签无需配置resultType,配置无效
5.9 所有返回值全维度对比(生产选型表)
|--------|--------------|-----------------|-------|
| 返回值类型 | 适用场景 | 优缺点 | 生产推荐度 |
| 基本类型 | 单行单列统计、单字段查询 | 简洁高效,仅适配简单场景 | ⭐⭐⭐⭐⭐ |
| 单个实体PO | 单条完整数据查询 | 规范简洁,适配单主键查询 | ⭐⭐⭐⭐ |
| List集合 | 批量列表、条件查询 | 空结果安全,适配所有列表场景 | ⭐⭐⭐⭐⭐ |
| Map | 临时动态字段、统计查询 | 灵活但不规范,可读性差 | ⭐⭐ |
| 自定义DTO | 联表查询、前端接口返回 | 安全规范、字段可控,解耦前后端 | ⭐⭐⭐⭐⭐ |
| 分页对象 | 所有分页列表业务 | 开箱即用,适配企业分页需求 | ⭐⭐⭐⭐⭐ |
| Void | 增删改无返回场景 | 简洁,无需处理返回结果 | ⭐⭐⭐⭐ |
5.10 生产通用规范(必遵守)
-
查询优先用DTO:所有对外接口、联表查询统一使用自定义DTO返回,禁止直接返回PO实体
-
列表必用List:多条数据严禁用Map、单实体接收,避免数据异常
-
简单统计用基本类型:数量、金额、状态查询优先使用包装类基本类型
-
杜绝滥用Map:核心业务禁止使用Map返回,仅用于临时统计脚本
-
空值统一处理:单实体、基本类型返回需判空,集合无需判空
5.11 面试高频考点(必背)
-
MyBatis List集合返回值为空时返回null还是空集合?(答:空集合,无需判空)
-
基本类型返回值为什么必须用包装类?(答:避免NULL赋值基本类型抛异常)
-
Map返回值的优缺点与生产禁用场景?
-
PO与DTO的区别,为什么企业接口必须返回DTO?
-
单实体查询返回多条数据会出现什么问题?(答:抛出TooManyResultsException)
核心总结:MyBatis多返回值各司其职,简单单列用基本类型、单条数据用实体、多条数据用List、动态临时数据用Map、业务接口用DTO、分页场景用PageInfo、增删改无返回用void,严格遵循生产选型规范,可规避90%的返回值映射异常。
基本类型、List、Map、DTO、分页对象、void 空返回
6. 联表映射坑点(生产高频致命坑+完整解决方案+实战案例)
MyBatis联表映射(一对一、一对多联表查询)是开发中报错率最高、问题最隐蔽的模块,多数问题为无报错但数据错乱、数据丢失、数据重复,极难排查。下面汇总企业生产100%踩过的核心坑点,配套底层原因、规避规范、落地解决方案与实战代码。
6.1 坑点一:同名字段覆盖,数据赋值错乱(最高频)
核心问题现象
多表联查时,多张表存在相同字段名(如 id、name、create_time),未做别名区分,导致后查询的表字段值覆盖前表字段值,最终实体数据错乱、属性值匹配错误,无控制台报错,仅业务数据异常。
底层原理
数据库返回的扁平结果集中,同名字段会被合并覆盖,MyBatis 按字段名映射赋值,无法区分不同表的同名字段,最终只会保留最后一个字段的值,造成主表/关联表数据错乱。
生产错误示例
XML
<!-- 错误写法:user、order表均有id、create_time字段,无别名 -->
<select id="getUserOrder" resultMap="UserOrderResultMap">
SELECT u.id,u.user_name,o.id,o.create_time FROM user u LEFT JOIN `order` o ON u.id = o.user_id
</select>根治解决方案
联表SQL中所有同名字段手动定义唯一别名,通过别名区分不同表字段,同时在resultMap中绑定别名映射,彻底规避覆盖问题。
正确实战写法
XML
<select id="getUserOrder" resultMap="UserOrderResultMap">
SELECT
u.id AS user_id,
u.user_name,
u.age,
o.id AS order_id,
o.amount,
o.create_time AS order_create_time
FROM user u LEFT JOIN `order` o ON u.id = o.user_id
</select>
<resultMap id="UserOrderResultMap" type="com.example.vo.UserOrderVO">
<id property="userId" column="user_id"/>
<result property="userName" column="user_name"/>
<result property="orderId" column="order_id"/>
<result property="orderCreateTime" column="order_create_time"/>
</resultMap>6.2 坑点二:一对多联表查询主数据重复(经典坑点)
核心问题现象
主表一对一关联查询正常,一对多联表查询时,主表数据重复封装,一条主数据对应多条子数据,最终返回多条一模一样的主实体,仅子数据不同,导致列表数据冗余、统计数量错误。
底层原理
数据库联表查询会返回扁平多行结果集,一条主数据匹配N条子数据,就会生成N行数据。若resultMap未配置主表主键标识,MyBatis无法识别重复主数据,不会自动合并,最终重复创建主实体。
根治解决方案
一对多resultMap中,必须为主表主键配置 <id> 标签,MyBatis会根据主键自动去重、合并主数据,将多条子数据封装为集合,完美解决数据重复问题。
正确配置示例
XML
<!-- 必须配置主表id标签,实现自动去重合并 -->
<resultMap id="UserOrderListMap" type="com.example.po.User">
<!-- 主表主键:核心去重关键 -->
<id property="id" column="user_id"/>
<result property="userName" column="user_name"/>
<result property="age" column="age"/>
<!-- 一对多集合封装 -->
<collection property="orderList" ofType="com.example.po.Order">
<id property="id" column="order_id"/>
<result property="amount" column="amount"/>
</collection>
</resultMap>6.3 坑点三:INNER JOIN 导致主数据丢失
核心问题现象
使用内连接INNER JOIN联表查询时,部分主表数据无关联子数据会被直接过滤丢失,业务列表数据不全、统计总数偏少。
底层原理
INNER JOIN 匹配规则为「主表、关联表数据完全匹配才返回结果」,无关联数据的主数据会被数据库直接过滤,不进入结果集。
生产规范与解决方案
-
通用业务查询 :一律使用 LEFT JOIN 左连接,保留所有主表数据,无子数据时关联字段为null,保证数据完整性;
-
精准匹配查询:仅需要同时存在主从数据的场景,才使用 INNER JOIN;
-
右连接慎用:禁止随意使用 RIGHT JOIN,代码可读性差、排查问题困难,统一以主表左连接为准。
6.4 坑点四:resultType 嵌套映射失效,关联数据为null
核心问题现象
联表查询存在嵌套实体、集合属性时,使用 resultType 接收数据,嵌套关联数据始终为null,仅主表普通字段正常赋值。
底层原理
resultType 仅支持平级字段自动映射,无法识别实体中的嵌套对象、集合属性;嵌套关联映射必须依靠 resultMap 手动绑定字段与实体属性。
解决方案
-
简单单表、无嵌套字段:使用 resultType,简洁高效;
-
所有联表嵌套查询(一对一/一对多):必须自定义 resultMap,禁止使用 resultType。
6.5 坑点五:嵌套查询N+1性能雪崩(联表选型错误)
核心问题现象
批量列表、分页查询场景,使用嵌套分步查询(association/collection+select),查询N条主数据触发N次子查询,数据库IO暴增,高并发下直接拖垮服务。
底层原理
分步查询模式下,主查询返回N条数据,会循环执行N次子查询,形成1+N次SQL查询,批量数据场景性能极差。
根治选型规范
-
批量/分页/列表查询 :优先 嵌套结果联表查询,单次SQL完成全量查询,无N+1问题;
-
单条详情查询:可使用分步懒加载查询,按需加载关联数据,兼顾性能与灵活性。
6.6 坑点六:懒加载失效,关联数据全量加载
核心问题现象
配置了延迟加载,但联表关联数据仍一次性全部加载,无法实现按需加载,性能冗余。
核心原因
-
使用了嵌套结果联表查询(天生不支持懒加载);
-
全局未关闭激进懒加载,触发任意属性即加载全部关联数据;
-
局部fetchType、注解配置覆盖全局懒加载规则。
解决方案
懒加载仅适用于嵌套分步查询,严格区分两种联表模式,不混用配置。
6.7 坑点七:联表查询字段冗余、性能低效
核心问题现象
联表查询习惯性写 select *,查询大量无用字段,增加网络传输、结果集映射开销,大数据量分页查询性能卡顿。
生产规范
所有联表查询禁止使用 select *,按需查询业务所需字段,手动指定字段并配置别名,精简结果集,提升查询性能。
6.8 联表映射生产通用避坑规范(必背)
-
多表联查必加字段别名,杜绝同名字段覆盖错乱;
-
一对多联表必须配置主表<id>标签,实现数据自动去重合并;
-
业务列表联表优先LEFT JOIN,保证主数据不丢失;
-
嵌套关联查询一律用resultMap,禁止resultType;
-
批量分页用联表结果查询,单条详情用分步懒加载查询;
-
联表禁止select *,按需裁剪字段,优化查询性能;
-
多表联查超过3张表,拆分查询,避免SQL臃肿难维护。
6.9 面试高频考点总结
问:MyBatis一对多联表查询为什么会出现主数据重复?怎么解决?
答:联表查询返回扁平多行结果集,MyBatis默认按行封装实体,无主键去重逻辑,导致主数据重复;解决方案是在resultMap中配置主表<id>主键标签,MyBatis会根据主键自动合并重复主数据,封装子数据为集合,彻底解决重复问题。
问:联表查询同名字段数据错乱的根本原因和解决方案?
答:多表同名字段无别名,数据库结果集字段覆盖,MyBatis映射赋值错乱;解决方案是所有同名字段自定义唯一别名,通过resultMap绑定别名映射,区分不同表字段。
处理字段别名重复、同名字段赋值错乱问题
7. N+1 查询问题
懒加载易触发,解决方案:联表查询、批量查询优化
五、动态 SQL 全套语法
1. 动态SQL全套常用标签(语法+实战+坑点+面试)
MyBatis动态SQL是核心高频考点,彻底解决传统JDBC、静态SQL的参数拼接冗余、语法报错、条件适配差等问题,支持条件判断、分支选择、循环遍历、SQL片段复用、字符串处理等能力,所有标签基于OGNL表达式解析,适配所有复杂业务查询、更新、批量操作场景。以下为企业开发必用、面试必考的全量常用标签。
1.1 <if> 条件判断标签(最常用)
核心作用:非空、非空字符串条件判断,动态拼接SQL片段,满足条件则拼接,不满足则不生效,适配多可选参数查询场景。
核心规则:仅支持OGNL表达式判断,可判空、判长度、数值比较、集合非空。
标准语法&实战示例
XML
<!-- 多条件动态查询:用户名、年龄、邮箱可选条件 -->
<select id="selectUserByCondition" resultType="User">
SELECT id,user_name,age,email,create_time FROM user
<where>
<!-- 判断字符串非空 -->
<if test="userName != null and userName != ''">
AND user_name LIKE CONCAT('%',#{userName},'%')
</if>
<!-- 判断数值非空 -->
<if test="age != null">
AND age = #{age}
</if>
<!-- 判断字符串+模糊匹配 -->
<if test="email != null and email != ''">
AND email = #{email}
</if>
</where>
</select>生产避坑点
-
字符串必须同时判断
!= null and != '',只判null会导致空字符串误查 -
数值类型(Integer、Long)只需判
!= null,无需判空字符串 -
if标签内SQL前缀建议加and/or,搭配where标签自动剔除多余前缀,无语法报错风险
1.2 <where> 条件前缀自动处理标签
核心作用 :替代手动书写WHERE关键字,自动完成剔除首个多余AND/OR、保留有效条件、无条件时不生成WHERE关键字,彻底解决动态条件拼接语法报错问题。
底层原理:MyBatis解析SQL后,扫描where标签内拼接的SQL片段,自动清理开头冗余的and/or,无任何条件时清空where语句。
核心优势:无需手动处理条件拼接前缀,零SQL语法错误,动态查询标配。
避坑要点 :仅能剔除开头多余and/or,无法剔除末尾多余连接符
1.3 <choose><when><otherwise> 多分支选择标签
核心作用 :类似Java的 switch-case-default 分支逻辑,多条件互斥匹配,只生效首个满足条件的分支,所有分支均不满足则执行otherwise默认分支。
适用场景:优先级筛选、互斥条件查询(如:优先按ID查询,无ID按用户名查询,默认查全部)。
实战示例
XML
<select id="selectUserByPriority" resultType="User">
SELECT * FROM user
<where>
<choose>
<!-- 优先级1:ID不为空,按ID精准查询 -->
<when test="id != null">
id = #{id}
</when>
<!-- 优先级2:ID为空、用户名不为空,按用户名模糊查询 -->
<when test="userName != null and userName != ''">
user_name LIKE CONCAT('%',#{userName},'%')
</when>
<!-- 默认分支:无条件筛选,查询全部 -->
<otherwise>
1=1
</otherwise>
</choose>
</where>
</select>核心特性
-
多个when条件互斥生效,从上到下匹配,命中即终止后续判断
-
otherwise为可选默认分支,不写则无匹配条件时不拼接任何SQL
-
区别于多if标签:if是多条件叠加,choose是单条件互斥
1.4 <trim> 自定义截取修饰标签(万能补全)
核心作用 :万能SQL修饰标签,可自定义前缀、后缀、前缀截取、后缀截取,是where、set标签的底层万能实现,适配复杂SQL拼接场景。
四大核心属性
-
prefix:拼接SQL前缀(如WHERE、SET)
-
suffix:拼接SQL后缀
-
prefixOverrides:剔除开头指定的关键字(and/or、逗号)
-
suffixOverrides:剔除末尾指定的关键字(逗号、and/or)
实战场景1:替代where标签,自定义剔除规则
XML
<trim prefix="WHERE" prefixOverrides="AND|OR">
<if test="userName != null">
AND user_name = #{userName}
</if>
<if test="age != null">
OR age = #{age}
</if>
</trim>实战场景2:动态更新去尾逗号(替代set标签)
XML
<update id="updateUserDynamic">
UPDATE user
<trim prefix="SET" suffixOverrides=",">
<if test="userName != null and userName != ''">
user_name = #{userName},
</if>
<if test="age != null">
age = #{age},
</if>
<if test="email != null and email != ''">
email = #{email},
</if>
</trim>
WHERE id = #{id}
</update>核心价值 :解决动态更新语句末尾多余逗号报错问题,比set标签更灵活,适配所有特殊拼接场景。
1.5 <set> 动态更新专用标签
核心作用 :动态更新语句专属标签,自动拼接SET关键字,自动剔除末尾多余逗号,无更新字段时不拼接SET语句,避免SQL语法报错。
实战示例(企业标准动态更新)
XML
<update id="updateUserSelective">
UPDATE user
<set>
<if test="userName != null and userName != ''">
user_name = #{userName},
</if>
<if test="age != null">
age = #{age},
</if>
<if test="email != null and email != ''">
email = #{email},
</if>
<if test="createTime != null">
create_time = #{createTime}
</if>
</set>
WHERE id = #{id}
</update>避坑要点
-
仅用于update更新语句,不可用于查询
-
自动去除末尾逗号,但无法去除开头多余关键字
-
所有可选更新字段均用if包裹,实现局部动态更新,保留原有未传参字段值
1.6 <foreach> 循环遍历标签(批量操作核心)
核心作用 :遍历集合、数组参数,实现IN查询、批量新增、批量更新、批量删除,是批量操作唯一核心标签。
完整五大属性(必考)
-
collection:必填,遍历的参数类型(List/Collection/Array/Map),接口传List直接写list,数组写array
-
item:遍历单个元素的变量名,自定义
-
index:遍历索引,集合为下标、Map为key
-
open:循环整体拼接前缀(如IN查询左括号()
-
close:循环整体拼接后缀(如IN查询右括号))
-
separator:元素之间的分隔符(逗号、分号)
实战1:IN批量查询
java
<select id="selectUserByIdList" resultType="User">
SELECT * FROM user
WHERE id IN
<foreach collection="idList" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</select>实战2:批量新增数据
XML
<insert id="batchInsertUser">
INSERT INTO user(user_name,age,email,create_time)
VALUES
<foreach collection="userList" item="user" separator=",">
(#{user.userName},#{user.age},#{user.email},#{user.createTime})
</foreach>
</insert>生产避坑&面试考点
-
参数为List集合,collection固定写
list;数组参数固定写array -
MySQL单条SQL长度有限制,批量数据超过1000条必须拆分批次,防止SQL超长报错
-
foreach批量新增不支持主键批量回填,需单独处理
-
禁止用foreach循环单条插入,性能极差,必须使用批量VALUES拼接
1.7 <sql><include> SQL片段复用标签
核心作用:抽取通用SQL片段(通用查询字段、通用条件、排序规则),全局复用,减少代码冗余,统一SQL规范,便于后期维护。
核心特性 :支持静态复用、动态传参复用,作用域为当前Mapper文件,可结合mapper映射全局复用。
完整实战示例
XML
<!-- 1. 定义通用SQL片段:通用查询字段 -->
<sql id="userCommonField">
id,user_name,age,email,create_time
</sql>
<!-- 2. 引用复用片段 -->
<select id="selectUserAll" resultType="User">
SELECT <include refid="userCommonField"/> FROM user
</select>
<!-- 3. 带参数复用(高级用法) -->
<sql id="userCondition">
<if test="status != null">
AND status = #{status}
</if>
</sql>避坑要点
-
sql片段禁止包含WHERE、SET等关键字,保证复用灵活性
-
refid必须与sql的id完全一致,同文件直接写id,跨文件需写全路径命名空间.id
-
通用字段片段优先复用,杜绝重复书写相同查询字段
1.8 <bind> 变量绑定标签
核心作用 :自定义绑定变量,封装参数、拼接字符串,解决模糊查询拼接冗余、数据库语法兼容问题,适配多数据库、统一模糊查询写法。
核心优势:无需在SQL中拼接%符号,避免数据库语法差异,防止SQL注入,代码更整洁。
实战示例:通用模糊查询
XML
<select id="selectUserLikeName" resultType="User">
<!-- 绑定模糊查询变量,统一拼接前后% -->
<bind name="likeUserName" value="'%' + userName + '%'"/>
SELECT * FROM user WHERE user_name LIKE #{likeUserName}
</select>生产价值:兼容MySQL、Oracle等所有数据库模糊查询语法,无需适配不同数据库拼接规则,统一代码规范。
1.9 <foreach>批量操作&SQL长度限制补充
承接前文简略说明,补充生产核心限制与解决方案:MySQL默认单条SQL最大长度为4M,大批量foreach拼接SQL会超出限制,引发数据包过长报错。
生产解决方案
-
批量数据拆分:单次批量操作控制在500-1000条以内
-
超大批量使用MyBatis Batch执行器分批提交
-
禁止一次性拼接上万条数据的SQL语句,避免数据库解析超时
1.10 动态SQL核心面试总结
-
if+where:常规多条件动态查询标配,解决and/or语法错误
-
choose-when:互斥优先级条件查询,替代多if叠加
-
trim:万能SQL修饰,适配所有特殊拼接场景
-
set:动态局部更新核心,自动去除尾逗号
-
foreach:批量查询、增删改唯一方案,注意SQL长度限制
-
sql+include:代码复用,统一SQL规范
-
bind:统一模糊查询,兼容多数据库
-
if:条件非空判断
-
where:自动剔除首尾多余 and/or
-
choose/when/otherwise:多分支选择
-
trim:自定义前缀后缀截取
-
foreach:集合遍历,批量增删改、in 查询
-
include/sql:SQL 片段复用,支持传参复用
-
bind:绑定变量,便捷模糊查询
2. foreach 完整属性(全量详解+规则+实战坑点+面试满分)
<foreach>是MyBatis动态SQL中专门用于集合、数组遍历的核心标签,支撑批量查询、批量新增、批量修改、批量删除等所有批量操作,是企业开发和面试必考重点,下面完整拆解六大核心属性、适配规则、参数匹配、生产规范与高频坑点。
2.1 foreach 六大完整核心属性(全覆盖)
foreach标签包含collection、item、index、open、close、separator六大核心属性,各司其职,缺一可缺,全部掌握才能适配各类批量场景。
- collection(必填)
核心作用:指定需要遍历的参数集合/数组,是最核心、最容易出错的属性。
固定匹配规则:
-
接口参数为 List集合 :collection 值固定写 list
-
接口参数为 Array数组 :collection 值固定写 array
-
接口参数为 Set集合 :collection 值固定写 collection
-
接口参数为 Map集合 :遍历key写 keys 、遍历value写 values
-
自定义参数名(@Param指定):优先使用自定义参数名,覆盖默认规则
避坑点:未使用@Param注解时,必须遵循默认命名规则,否则参数找不到,直接报错。
- item(选填,推荐必写)
核心作用:遍历过程中,单个元素的变量名,自定义命名(如id、user、item)。
使用规则:遍历集合时,通过#{item属性名}获取元素值,批量对象遍历必备。
示例:遍历User集合,item="user",取值为#{user.userName}、#{user.age}。
- index(选填)
核心作用:遍历索引标识
-
遍历List/Array:index代表遍历下标(从0开始)
-
遍历Map:index代表Map的key值
适用场景:需要序号、分组排序、Map键值对匹配的特殊批量场景。
- open(选填)
核心作用:循环整体拼接的前缀字符串,仅在循环开始前拼接一次。
高频用法:IN查询左括号 open="(",包裹所有遍历元素。
- close(选填)
核心作用:循环整体拼接的后缀字符串,仅在循环结束后拼接一次。
高频用法:IN查询右括号 close=")",配合open完成语句闭合。
- separator(选填)
核心作用:遍历元素之间的分隔符,自动拼接在每两个元素中间,不会首尾冗余。
高频用法:批量参数逗号分隔 separator=","
核心优势:自动处理分隔符,无需手动判断首尾元素,杜绝多余逗号报错。
2.2 不同参数类型完整实战示例
2.2.1 遍历List集合(ID批量查询)
XML
<select id="selectUserByIdList" resultType="User">
SELECT id,user_name,age FROM user
WHERE id IN
<foreach collection="list" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</select>2.2.2 遍历自定义参数名(@Param注解)
Mapper接口:List<User> selectUserByIds(@Param("idList") List<Integer> idList);
XML
<select id="selectUserByIds" resultType="User">
SELECT * FROM user WHERE id IN
<foreach collection="idList" item="uid" open="(" close=")" separator=",">
#{uid}
</foreach>
</select>2.2.3 遍历对象集合(批量新增)
XML
<insert id="batchInsertUser">
INSERT INTO user(user_name,age,email) VALUES
<foreach collection="userList" item="user" separator=",">
(#{user.userName},#{user.age},#{user.email})
</foreach>
</insert>2.2.4 遍历Map集合
XML
<foreach collection="map" index="key" item="value" separator=",">
${key} = #{value}
</foreach>2.3 生产高频致命坑点(必记)
-
collection参数名错乱报错:无@Param注解必须严格遵循list/array/collection默认命名,自定义参数名必须匹配注解名称,是开发最高频报错点。
-
分隔符冗余问题:严禁手动在元素后加逗号,separator会自动拼接元素间分隔符,手动添加会导致SQL语法错误。
-
超大批量SQL溢出 :MySQL单条SQL默认最大4M,foreach批量拼接数据超过1000条必须拆分批次,否则抛出数据包过大异常。
-
批量新增主键回填失效:foreach批量拼接VALUES新增,不支持useGeneratedKeys主键回填,无法直接获取新增数据ID,需单独处理。
-
空集合遍历报错:未做非空判断时,空List/数组会生成空SQL片段,导致语法异常,批量操作前需校验参数非空。
2.4 优化规范(企业生产标准)
-
所有foreach批量操作,外层必须搭配
<if test="集合 != null and 集合.size() >0">非空校验,规避空参数SQL报错。 -
批量操作阈值控制在500-1000条/次,超大批量采用分批提交,保障数据库性能稳定。
-
简单批量查询优先用foreach,超大数据量批量新增优先使用MyBatis Batch执行器。
2.5 面试高频满分考点
- 问:foreach标签collection属性默认取值规则?
答:无@Param注解时,List集合取list、数组取array、Set集合取collection;自定义注解参数名优先使用自定义名称。
- 问:foreach的separator会不会产生首尾多余分隔符?
答:不会,separator仅在两个元素中间拼接,自动忽略首尾,无冗余字符,无需手动处理。
- 问:foreach批量新增的优缺点?
答:优点是单条SQL完成批量插入、IO效率高;缺点是有SQL长度限制、不支持主键批量回填。
3. OGNL 表达式(完整版语法+实战写法+特殊判空+面试必背)
OGNL(Object-Graph Navigation Language)是MyBatis动态SQL的唯一表达式解析引擎,所有动态标签(if、choose、foreach、bind等)的条件判断、属性取值、集合遍历、逻辑运算均基于OGNL表达式实现。区别于Java语法,OGNL有专属的判空、运算、取值规则,是动态SQL不报错、条件精准生效的核心,也是开发高频踩坑、面试常问知识点。
3.1 核心基础规则
-
MyBatis动态SQL标签的
test属性仅支持OGNL表达式,不支持原生Java语法; -
表达式中可直接获取入参对象、属性、集合、参数变量,无需getter方法;
-
支持常规逻辑运算、比较运算、集合运算、空值判断,语法简洁;
-
OGNL表达式自动忽略空指针,属性为null时不会抛出空指针异常。
3.2 高频基础取值语法
适配实体参数、普通参数、自定义注解参数的取值场景
-
普通参数取值 :直接写参数名,如
userName、age、id -
实体属性取值 :对象.属性,如
user.userName、user.createTime -
注解参数取值 :@Param定义的参数名,如
idList、queryParam -
内置常量取值 :支持
null、''(空字符串)、数字、布尔值
3.3 最全判空语法(生产必用,避坑核心)
严格区分字符串、数值、集合、对象的判空规则,杜绝条件失效、空指针、SQL拼接异常
3.3.1 字符串类型判空(String)
必须同时判断非null + 非空字符串,仅判null会导致空字符串匹配异常
XML
<!-- 正确写法:全覆盖判空 -->
<if test="userName != null and userName != ''"></if>
<!-- 错误写法:仅判null,空字符串会进入条件,引发无效SQL -->
<if test="userName != null"></if>3.3.2 数值类型判空(Integer、Long、Double)
数值类型无空字符串概念,仅需判断!= null,无需多余判断
XML
<!-- 正确写法 -->
<if test="age != null"></if>
<if test="status != null"></if>
<!-- 错误写法:数值判空字符串无效,冗余且易出错 -->
<if test="age != null and age != ''"></if>3.3.3 集合/数组判空(List、Set、Array)
OGNL专属集合长度判断,同时校验非空且元素数量大于0,避免空集合遍历报错
XML
<!-- List/Set集合判空 -->
<if test="idList != null and idList.size() > 0"></if>
<!-- 数组判空 -->
<if test="idArray != null and idArray.length > 0"></if>3.3.4 实体对象判空
判断入参实体对象是否为null,避免调用属性时报错
XML
<if test="user != null"></if>3.4 逻辑与比较运算语法
重点:OGNL表达式中不支持 &&、||,必须使用英文单词替代
-
与运算 :用
and替代& -
&或运算 :用
or替代|| -
非运算 :用
not替代!
XML
<!-- 多条件与运算 -->
<if test="userName != null and userName != '' and age != null"></if>
<!-- 多条件或运算 -->
<if test="id != null or userName != null"></if>
<!-- 非空取反 -->
<if test="not (userName != null and userName != '')"></if>数值比较支持:>、<、>=、<=、==、!=,无需转义,直接使用即可。
3.5 特殊场景高阶写法(生产必备)
3.5.1 字符串模糊匹配判断
判断字符串是否包含指定字符,适配特殊条件筛选
XML
<!-- 判断用户名是否包含指定字符 -->
<if test="userName != null and userName.contains('admin')"></if>3.5.2 数值区间判断
XML
<!-- 年龄在18-60区间 -->
<if test="age != null and age >= 18 and age <= 60"></if>3.5.3 字符串长度判断
XML
<!-- 用户名长度大于2 -->
<if test="userName != null and userName.length() > 2"></if>3.5.4 集合包含元素判断
XML
<!-- 判断集合中是否包含指定ID -->
<if test="idList.contains(1)"></if>3.6 高频坑点汇总(生产致命错误)
-
逻辑符号错误 :test表达式中使用
&&、||直接导致动态SQL解析失败、项目启动报错,必须用and/or; -
判空规则混乱:数值类型判空字符串、字符串只判null,导致条件匹配异常、数据查询不全;
-
空集合未校验:foreach遍历前未判断集合size>0,空集合拼接空SQL,触发语法报错;
-
语法大小写错误 :OGNL表达式区分大小写,size()、length()、contains() 小写生效,大写报错;
-
禁止分号结尾:test表达式末尾不能加分号,否则解析异常。
3.7 面试满分考点
-
问:MyBatis动态SQL的test属性用什么表达式?为什么不能用Java原生语法? 答:使用OGNL表达式,MyBatis底层专门通过OGNL解析test条件,不支持Java的&&、||、!等语法,必须使用and/or/not替代。
-
问:字符串、数值、集合的OGNL判空区别? 答:字符串需判null+空字符串;数值仅判null;集合需同时判null+元素长度大于0。
-
问:OGNL表达式会报空指针异常吗? 答:不会,OGNL内置空值安全机制,访问null对象的属性不会抛出空指针,直接判定条件不成立。
判空、集合判断、属性取值,特殊空对象 / 空集合判断写法
4. 批量操作限制(完整版 · 底层限制+报错原理+生产优化+避坑面试)
MyBatis 基于foreach拼接SQL、批量执行器实现批量操作,存在数据库层面限制、框架特性限制、性能限制、语法限制四大核心瓶颈,是生产环境批量导入、批量更新高频报错、性能卡顿的核心原因,以下为全量限制解析、报错根源、标准化解决方案与面试考点。
4.1 核心限制一:MySQL单条SQL长度限制(最致命、最高频报错)
限制规则
MySQL 数据库默认配置 max_allowed_packet=4MB ,该参数定义了单条SQL语句、数据包的最大允许长度,超过阈值会直接抛出Packet for query is too large 数据包过大异常,SQL执行失败。
底层成因
MyBatis foreach批量新增/修改/查询,是将所有数据拼接为单条超大SQL语句一次性提交数据库,数据量越大,拼接后的SQL文本越长,极易触发MySQL数据包长度限制。
生产阈值规范
-
普通字符串数据:单次批量操作控制在 500~800条
-
含大文本、长字段数据:单次控制在100~300条
-
严禁单次拼接1000条以上数据,规避SQL超长报错
解决方案
-
代码分批拆分(推荐、通用方案):通过Java代码对集合分页切割,将大集合拆分为多个小批次,循环批量执行,从根源规避SQL超长问题,适配所有环境,无需修改数据库配置。
-
数据库参数调优(辅助方案):适当调高max_allowed_packet参数(最大可调整为16MB~32MB),但不建议无限调大,会增加数据库内存开销、引发解析超时。
4.2 核心限制二:foreach批量新增主键回填失效
限制规则
MyBatis 中通过 foreach + 多VALUES拼接 实现的批量新增,不支持 useGeneratedKeys 主键自动回填,新增后实体集合的主键ID全部为null,无法直接获取新增数据主键。
底层原理
单条新增语句的主键回填,依赖MyBatis单次SQL执行后的主键结果集解析;而批量拼接的多VALUES语句,数据库仅返回最后一条新增数据的主键,框架无法批量解析全量主键,因此全局回填失效。
生产解决方案
-
小批量数据:放弃foreach拼接,使用MyBatis Batch批量执行器,可支持主键回填;
-
大批量数据:新增后通过业务唯一字段批量查询主键ID,或使用雪花算法、UUID手动生成主键,脱离数据库自增主键依赖;
-
折中方案:拆分小批次批量新增,单次少量数据可兼容主键回填。
4.3 核心限制三:批量操作索引失效与性能衰减
限制规则
超大批量的in查询、批量更新、批量删除,会导致数据库索引失效、全表扫描、事务超时、锁表风险,高并发场景极易拖垮数据库。
具体问题表现
-
IN查询超限:IN条件中参数超过1000个,MySQL索引失效,触发全表扫描,查询性能断崖式下跌;
-
批量更新锁表:大批量更新数据会占用行锁、表锁,锁等待超时,阻塞其他业务SQL;
-
事务超时:单批次批量操作耗时过长,超过数据库、Spring事务超时阈值,触发事务回滚、操作失败。
优化规范
-
IN查询参数严格控制在1000个以内,超量自动拆分多段IN查询合并结果;
-
批量更新/删除采用小批次、高频次执行,释放数据库锁资源;
-
核心业务批量操作添加事务超时手动配置,避免默认超时中断。
4.4 核心限制四:动态批量SQL语法容错限制
限制规则
foreach批量操作极度依赖参数非空校验,空集合、空数组直接触发SQL语法报错,无任何容错机制。若遍历的List/Array为空,会生成不完整的空SQL片段,导致数据库解析失败。
强制生产规范
所有foreach批量标签外层,必须嵌套OGNL非空判断,杜绝空参数执行:
XML
<!-- 批量操作强制非空校验 -->
<if test="idList != null and idList.size() > 0">
<foreach collection="idList" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</if>4.5 两大批量实现方式优缺点与限制对比(生产选型核心)
| 批量实现方式 | 核心优势 | 核心限制/缺点 | 适用场景 |
|---|---|---|---|
| foreach拼接SQL批量 | 单次IO、执行速度快、无需额外配置 | SQL长度限制、无主键批量回填、超量索引失效 | 中小批量数据(500条内)、无需获取主键 |
| Batch执行器批量 | 无SQL长度限制、支持主键回填、IO开销低 | 事务手动管控、异常回滚复杂、不适合超大数据量 | 小批量精准新增、需要获取主键ID场景 |
4.6 生产终极批量优化方案(企业标准)
-
通用适配方案:集合分批切割 + foreach批量SQL + 非空校验,兼容90%以上批量业务;
-
精准新增方案:小批量数据使用Batch执行器,兼顾性能与主键回填;
-
超大批量方案:万级以上数据采用文件导入、MyBatis批量分批+异步执行,避免阻塞主线程;
-
查询优化方案:IN参数拆分、分段查询结果合并,规避索引失效问题。
4.7 面试高频满分考点
- 问:MyBatis foreach批量新增为什么不能回填主键?
答:foreach批量拼接多VALUES语句,数据库仅返回最后一条主键,MyBatis无法解析全量主键信息,因此批量回填失效,仅单条新增支持主键回填。
- 问:批量操作报数据包过大异常的原因和解决方案?
答:原因是MySQL默认单条SQL最大4MB,批量拼接SQL超出长度限制;解决方案为代码分批切割数据,优先小批次批量执行,可辅助调优数据库max_allowed_packet参数。
- 问:IN查询参数过多有什么问题?怎么解决?
答:参数超1000个会导致索引失效、全表扫描,性能暴跌;解决方案是拆分参数集合,分段查询后合并结果。
六、缓存机制原理与使用
1. 一级缓存(默认开启)
一级缓存是MyBatis原生默认开启、无需手动配置 的本地缓存,是MyBatis最基础的缓存机制,底层基于 PerpetualCache 实现(HashMap存储),全程由SqlSession自主管理,用于优化单次数据库会话内的重复查询性能,减少重复SQL执行与数据库IO交互。
1.1 核心基础属性
-
缓存级别:SqlSession 会话级缓存(本地缓存)
-
默认状态:全局默认开启,无手动开启开关,仅可通过局部配置关闭
-
存储介质:内存(JVM内存),会话生命周期内常驻
-
生效范围 :同一个SqlSession、同一个Mapper、同一条SQL、相同参数的查询请求
-
核心作用:单次会话内重复查询直接读取内存缓存数据,无需访问数据库,大幅提升单次会话查询性能
1.2 底层执行原理
每次执行查询SQL时,MyBatis会生成唯一的缓存Key(由Mapper命名空间+方法ID+SQL语句+查询参数+分页参数组合生成):
-
优先根据缓存Key查询当前SqlSession的一级缓存;
-
缓存命中:直接返回内存数据,不执行数据库查询;
-
缓存未命中:执行SQL查询数据库,将结果存入一级缓存后返回数据;
-
缓存仅在当前会话生效,无法跨会话共享。
1.3 完整生效条件(缺一不可)
-
同一个 SqlSession 数据库会话(未关闭、未清空)
-
调用同一个 Mapper 接口方法
-
查询 SQL 语句、传入参数完全一致
-
查询分页参数、排序规则完全一致
-
当前方法未单独关闭一级缓存
1.4 全部失效场景(生产高频考点)
一级缓存为会话级缓存,触发以下场景会立即清空当前SqlSession所有缓存数据,缓存彻底失效:
-
会话关闭 :调用
sqlSession.close()关闭会话,缓存内存直接释放 -
事务提交/回滚:当前会话执行commit()、rollback()后,自动清空一级缓存
-
执行增删改操作:同一会话内执行insert、update、delete任意操作,清空全部一级缓存(保证数据一致性)
-
手动清空缓存 :调用
sqlSession.clearCache()手动强制清空缓存 -
跨会话查询:不同SqlSession之间缓存完全隔离,无法共享
-
局部关闭缓存 :通过
@Options(useCache = false)关闭单方法缓存
1.5 一级缓存开关配置
-
全局作用域控制 :通过
localCacheScope全局参数调整缓存范围(yml/xml配置) - SESSION(默认):会话级缓存,整个会话复用缓存 - STATEMENT:语句级缓存,单次SQL执行后立即清空缓存(等效关闭一级缓存) -
单方法局部关闭:注解方式精准关闭单个查询的一级缓存,不影响全局
java
// 单方法关闭一级缓存
@Options(useCache = false)
User selectUserById(Integer id);1.6 生产核心坑点(必避)
-
脏数据问题:同一会话中,查询数据后手动修改数据库数据,再执行相同查询,会读取缓存旧数据,无法获取最新库数据
-
事务内数据一致性隐患:长事务会话中,重复查询会复用缓存,无法感知数据库实时数据变更
-
Spring环境缓存失效错觉 :Spring默认每次请求/方法都会创建新SqlSession,因此Spring整合环境下一级缓存几乎不生效,这是企业开发最易误解的点
1.7 面试满分标准答案
问:MyBatis一级缓存的原理、范围与失效场景?
答:
-
一级缓存是MyBatis默认开启的SqlSession会话级内存缓存,底层基于HashMap实现,无需手动配置;
-
生效范围仅限同一个数据库会话,跨会话无法共享,Spring环境因会话自动销毁,一级缓存基本失效;
-
同一会话内相同SQL重复查询直接读取缓存,减少数据库IO;
-
触发增删改、事务提交/回滚、会话关闭、手动清空缓存,均会导致一级缓存失效,保障会话内数据基础一致性。
总结:
-
级别:SqlSession 会话级缓存
-
生效范围:同一次会话相同查询
-
失效场景:增删改操作、会话关闭、会话清空、不同会话查询
2. 二级缓存(手动开启)
二级缓存是MyBatis跨SqlSession共享、Mapper命名空间级 的全局缓存,默认关闭,需要手动配置开启。底层默认基于 PerpetualCache 实现(内存存储),生命周期贯穿整个项目运行期间,主要用于优化跨请求、跨会话的重复查询性能,大幅减少数据库高频重复查询IO,是MyBatis生产性能调优的核心手段之一。
2.1 核心基础属性
-
缓存级别:Mapper命名空间级全局缓存(跨SqlSession、跨请求共享)
-
默认状态:全局默认关闭,需手动逐层配置开启
-
存储介质:JVM内存,默认本地缓存,可自定义拓展Redis/Ehcache分布式缓存
-
生效范围 :同一Mapper命名空间、跨任意SqlSession、相同SQL+参数的查询请求
-
核心作用:项目全局复用查询缓存数据,解决一级缓存仅会话内生效的短板,适配高频查询、低变更业务场景
-
淘汰策略:默认 LRU(最少最近使用),自动淘汰长期未访问的缓存数据,避免内存溢出
-
刷新机制:默认先进先出、定时清理,支持自定义缓存过期规则
2.2 完整开启四大必备条件(缺一不可)
二级缓存开启存在层级依赖,必须同时满足以下条件,否则缓存无法生效,是开发高频踩坑点:
-
全局总开关开启:MyBatis全局配置中开启cacheEnabled(默认true,无需手动改,建议显式配置)
-
Mapper文件局部开启 :需要使用缓存的Mapper.xml文件中添加
<cache/>标签,开启当前命名空间缓存 -
实体类序列化 :查询返回的实体类必须实现
Serializable序列化接口,支持缓存数据序列化存储与传输 -
事务正常提交:SqlSession执行完毕、事务正常提交/关闭后,查询数据才会存入二级缓存(事务未提交不缓存)
2.3 分步开启实战配置
2.3.1 全局配置(yml/xml)
SpringBoot yml配置(全局开启二级缓存总开关):
XML
mybatis:
configuration:
cache-enabled: true # 全局二级缓存总开关,默认开启原生mybatis-config.xml配置:
XML
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>2.3.2 Mapper映射文件开启缓存
在对应Mapper.xml根节点添加 <cache/>标签,当前文件所有查询方法默认开启二级缓存:
XML
<mapper namespace="com.example.mapper.UserMapper">
<!-- 开启当前命名空间二级缓存,全局生效 -->
<cache/>
</mapper>2.3.3 实体类实现序列化
java
import lombok.Data;
import java.io.Serializable;
import java.util.Date;
@Data
// 必须实现Serializable接口,支持二级缓存序列化存储
public class User implements Serializable {
private Integer id;
private String userName;
private Integer age;
private String email;
private Date createTime;
}2.4 二级缓存执行原理与流程
二级缓存优先级高于一级缓存 ,查询执行顺序:二级缓存 → 一级缓存 → 数据库
-
客户端发起查询请求,MyBatis优先查询当前Mapper命名空间的二级缓存;
-
二级缓存命中:直接返回缓存数据,无需查询一级缓存和数据库;
-
二级缓存未命中:查询当前SqlSession一级缓存,命中则直接返回;
-
一、二级缓存均未命中:执行SQL查询数据库,返回结果;
-
核心规则:事务提交、SqlSession关闭后,本次查询结果才会存入二级缓存,供后续所有会话共享。
2.5 精准开关配置(局部控制)
支持全局开启、局部关闭,精准控制单条SQL缓存策略,适配差异化业务场景:
- 单方法关闭二级缓存:通过@Options注解局部关闭,不影响其他方法
java
// 当前查询方法不使用二级缓存,实时查询数据库
@Options(useCache = false)
User selectUserById(Integer id);- 单方法刷新缓存:增删改操作默认刷新缓存,可手动配置刷新规则
2.6 二级缓存失效场景(全覆盖)
二级缓存为命名空间级缓存,以下场景会清空当前Mapper命名空间所有二级缓存数据:
-
当前Mapper执行任意 insert、update、delete 增删改操作,自动清空缓存,保证数据一致性;
-
手动调用缓存刷新方法,强制清空二级缓存;
-
项目重启、重新部署,内存缓存数据全部清空;
-
关闭全局cacheEnabled总开关,所有二级缓存彻底失效;
-
方法单独配置useCache=false,当前查询不命中、不写入缓存。
核心特点 :增删改仅清空当前命名空间缓存,不会影响其他Mapper的二级缓存,缓存隔离性更强。
2.7 一级缓存与二级缓存核心区别(对比总结)
|-------------|----------------|------------------|
| 对比维度 | 一级缓存 | 二级缓存 |
| 缓存级别 | SqlSession 会话级 | Mapper 命名空间级(全局) |
| 默认状态 | 默认开启,不可关闭 | 默认关闭,需手动开启 |
| 生效范围 | 仅同一会话内共享 | 跨会话、跨请求全局共享 |
| 数据存入时机 | 查询执行完成立即存入 | 事务提交/会话关闭后存入 |
| 失效条件 | 会话关闭、增删改、事务提交 | 当前命名空间增删改、项目重启 |
| Spring环境有效性 | 基本失效(会话自动销毁) | 全程有效,适配Spring环境 |
2.8 生产高频坑点(必避)
-
实体未序列化报错:未实现Serializable接口,会导致二级缓存写入失败、项目无报错但缓存不生效;
-
跨命名空间数据联动脏读:表关联数据分布在不同Mapper,A表更新、B表缓存未刷新,引发数据不一致;
-
实时业务数据滞后:二级缓存数据持久化在内存,高实时性业务(支付、库存、订单)会读取旧数据,严禁开启;
-
事务内缓存延迟生效:未提交事务的查询数据,不会存入二级缓存,其他会话无法读取未提交数据,避免脏数据共享;
-
缓存堆积内存溢出:超大批量数据、无过期策略的缓存长期堆积,占用JVM内存,需自定义缓存过期规则。
2.9 适用与禁用场景(生产规范)
✅ 推荐开启场景
-
高频查询、低频更新的静态业务数据(字典、配置、地区、分类数据);
-
后台管理系统、非实时统计报表、基础配置查询;
-
跨请求重复查询、数据库访问压力大的业务场景。
❌ 禁止开启场景
-
金融、支付、库存、订单等高一致性、高实时性业务;
-
频繁增删改、数据实时变动的业务模块;
-
多表关联、跨Mapper联动查询的复杂业务,极易出现缓存数据不一致。
2.10 面试满分考点
- 问:二级缓存的开启条件?为什么实体类需要序列化?
答:需同时满足全局cacheEnabled开启、Mapper添加<cache/>标签、实体类序列化、事务提交四大条件;二级缓存需要将对象序列化后存入内存,反序列化读取,因此必须实现Serializable接口。
- 问:一级缓存和二级缓存的执行顺序与优先级?
答:查询优先级:二级缓存 > 一级缓存 > 数据库;二级缓存全局共享,优先级更高,命中后直接返回数据,不再查询一级缓存。
- 问:二级缓存为什么事务提交后才生效?
答:为了保证数据一致性,未提交的事务数据存在回滚可能,暂不存入二级缓存,避免无效、脏缓存数据被全局共享。
- 问:二级缓存的优缺点?生产如何选型?
答:优点是全局共享、减少数据库IO、提升查询性能;缺点是存在数据滞后、一致性风险;仅适用于低频更新、高频查询的静态业务,实时金融业务需关闭。
核心总结:
二级缓存是命名空间级全局共享缓存,默认关闭、需四条件开启,事务提交后生效,增删改清空当前命名空间缓存,适配静态高频查询业务,禁用实时高一致性业务。
总结:
-
级别:Mapper 命名空间级,跨会话共享
-
开启条件:全局开关、mapper 标签开启、实体类序列化
-
淘汰策略:默认 LRU 最少使用淘汰
3. 缓存失效与刷新(完整版 · 被动清空+主动刷新+同步方案+生产规范)
MyBatis 一、二级缓存拥有独立的失效与刷新机制,默认以被动自动清空 为主、手动主动刷新为辅,核心设计目标是保障数据库数据与缓存数据一致性。不同缓存层级的失效范围、触发规则、刷新逻辑差异极大,是解决生产缓存脏数据、数据不一致问题的核心知识点,同时为面试高频考点。
3.1 一级缓存失效与刷新规则(会话级)
一级缓存无手动刷新方法,仅支持被动清空,所有失效场景均会清空当前SqlSession的全部缓存数据,无法精准清空单条缓存。
3.1.1 自动被动失效场景(全覆盖)
-
会话终止失效 :调用
sqlSession.close()关闭数据库会话,一级缓存内存直接释放,缓存彻底失效。 -
事务操作失效 :当前SqlSession执行
commit()提交、rollback()回滚事务后,自动清空全部一级缓存,避免会话内旧数据残留。 -
增删改操作失效:同一会话内执行任意insert、update、delete操作,无论操作是否成功、是否提交事务,都会清空当前会话所有一级缓存,防止查询到未更新的缓存旧数据。
-
跨查询条件失效:相同Mapper方法,若查询参数、分页参数、排序规则、SQL语句发生变化,会生成全新缓存Key,原有缓存失效,重新查询数据库。
3.1.2 手动强制清空方式
原生提供专属API,可主动清空当前会话一级缓存,适用于会话内手动修改数据库数据、需实时刷新缓存的场景:
java
// 手动清空当前SqlSession全部一级缓存
sqlSession.clearCache();3.1.3 一级缓存刷新核心特点
-
仅作用于当前会话,不影响其他SqlSession缓存;
-
无精准删除能力,仅支持全量清空当前会话缓存;
-
Spring环境下会话自动销毁,无需手动刷新,天然规避缓存脏数据问题。
3.2 二级缓存失效与刷新规则(命名空间级)
二级缓存为全局共享缓存,支持自动被动清空 和手动精准刷新,失效范围为当前Mapper命名空间,隔离性更强,是生产缓存管控的重点。
3.2.1 自动被动失效(默认机制)
二级缓存核心一致性机制:当前命名空间任意增删改,清空当前命名空间全部二级缓存,精准隔离、互不干扰。
-
触发操作:Mapper内的insert、update、delete语句执行完成(无论事务是否提交);
-
失效范围:仅清空当前Mapper命名空间所有缓存数据,其他Mapper缓存完全保留;
-
生效时机:SQL执行完毕后立即清空,避免后续查询读取旧缓存数据。
示例:UserMapper执行用户更新操作,仅清空UserMapper的二级缓存,OrderMapper、RoleMapper缓存不受任何影响。
3.2.2 手动主动刷新/清空方案(生产必备)
针对跨表关联、手动数据库更新、特殊业务场景,可主动清空二级缓存,解决自动刷新机制覆盖不到的场景。
方式一:全局关闭单方法缓存(临时刷新)
通过注解让单次查询不读取、不写入缓存,直接走数据库查询,实现实时刷新效果:
java
@Options(useCache = false, flushCache = true)
User selectUserById(Integer id);参数说明: useCache=false:本次查询不使用二级缓存; flushCache=true:执行该查询前清空当前命名空间缓存。
方式二:增删改强制刷新缓存(默认开启)
MyBatis默认增删改标签 flushCache="true",可手动显式配置,确保缓存强制清空:
XML
<update id="updateUser" flushCache="true">
UPDATE user SET user_name=#{userName} WHERE id=#{id}
</update>方式三:代码动态清空二级缓存(精准刷新)
通过SqlSession主动清空指定命名空间二级缓存,适配复杂业务场景:
java
// 获取配置对象,清空指定命名空间二级缓存
Configuration configuration = sqlSession.getConfiguration();
// 清空UserMapper对应二级缓存
configuration.getCache("com.example.mapper.UserMapper").clear();3.3 高频缓存一致性问题解决方案(生产核心)
3.3.1 跨命名空间缓存不同步问题
问题成因:多表关联查询场景下,A表(UserMapper)更新、B表(OrderMapper)未更新,A的缓存自动清空,但B的缓存保留,关联查询时出现数据脏读。
解决方案:
-
关联业务模块统一关闭二级缓存,保证数据实时一致性;
-
主表更新后,手动清空关联从表的二级缓存;
-
复杂关联业务采用查询实时数据库、不走缓存的策略。
3.3.2 事务内缓存延迟生效问题
规则 :事务未提交时,查询数据仅存入一级缓存,不存入二级缓存,其他会话无法读取未提交数据。
解决方案:核心业务事务执行完毕后,确保事务正常提交,缓存数据才会对外共享,杜绝脏数据扩散。
3.4 缓存刷新生产规范(企业标准)
-
默认规则:优先使用MyBatis自动缓存刷新机制,增删改自动清空对应命名空间缓存,减少手动干预;
-
手动刷新场景:仅用于跨表更新、SQL手动修改、第三方修改数据库等特殊场景,禁止滥用手动清空;
-
实时业务规范:支付、库存、订单等高实时业务,直接关闭二级缓存,从根源避免缓存不一致;
-
静态数据规范:字典、配置等静态数据,无需频繁刷新,可长期复用缓存,仅在数据更新时主动清空;
-
批量操作规范:批量增删改执行完成后,自动清空对应命名空间缓存,无需额外手动刷新。
3.5 面试高频满分考点
- 问:一、二级缓存刷新机制有什么区别?
答:一级缓存仅支持当前会话全量清空,无精准刷新能力,会话、事务、增删改都会触发失效;二级缓存是命名空间级精准刷新,仅清空当前操作Mapper缓存,支持手动精准清空、按需刷新,隔离性更强。
- 问:跨Mapper关联查询为什么会出现缓存脏数据?怎么解决?
答:二级缓存按命名空间隔离,A Mapper更新仅清空自身缓存,关联的B Mapper缓存不会刷新,导致关联查询脏读;解决方案为关联业务关闭二级缓存,或手动同步清空关联Mapper缓存。
- 问:flushCache注解属性的作用?默认值是什么?
答:增删改语句默认flushCache=true,执行后自动清空二级缓存;查询语句默认false,可手动开启强制刷新缓存,保证数据实时性。
核心总结:
一级缓存会话级全量失效、无精准刷新;
二级缓存命名空间精准刷新、自动+手动双机制;
跨模块关联业务需手动同步缓存或关闭缓存,保障数据一致性。
总结:
增删改自动清空对应缓存,支持手动刷新缓存
4. 缓存生产问题(全量避坑+故障复盘+解决方案)
MyBatis一、二级缓存在生产环境极易引发脏数据、数据不一致、缓存穿透、缓存击穿、内存溢出等线上故障,多数问题偶发且排查难度大,本章节汇总企业高频缓存生产问题、成因、复现场景及标准化解决方案,是生产落地、故障排查、面试拔高的核心内容。
4.1 核心问题一:缓存脏数据(最高频线上故障)
4.1.1 一级缓存脏数据(事务内数据滞后)
故障场景:同一事务内,先查询数据存入一级缓存,后续通过自定义SQL、第三方接口、手动修改数据库数据,再次查询相同条件数据,依然读取缓存旧数据,无法获取最新数据库数据。
底层成因:一级缓存为会话级缓存,同一会话内查询数据后,只要未执行增删改、事务提交、手动清空缓存,缓存数据会永久复用,不会主动同步数据库最新数据。
生产解决方案:
-
短事务业务:事务内数据修改后,手动调用
sqlSession.clearCache()清空一级缓存; -
长事务业务:全局配置 localCacheScope=STATEMENT,关闭会话级缓存,每次查询直连数据库,彻底规避脏数据;
-
禁止在同一事务内混合执行数据库修改、重复查询操作,拆分业务逻辑。
4.1.2 二级缓存跨命名空间脏数据(复杂业务重灾区)
故障场景:多表关联业务中,A表(UserMapper)执行更新操作,二级缓存自动清空,但关联的B表(OrderMapper、RoleMapper)缓存未刷新,后续关联查询读取B表旧缓存数据,导致整体数据错乱。
底层成因 :MyBatis二级缓存严格按Mapper命名空间隔离,仅清空当前操作Mapper的缓存,不会联动刷新其他关联Mapper缓存,多表联动场景天然存在缓存不同步问题。
生产解决方案:
-
核心关联业务:直接关闭二级缓存,放弃缓存提升,优先保证数据一致性;
-
静态关联业务:主表更新后,代码手动清空所有关联从表的二级缓存;
-
统一规范:多表联查、跨Mapper业务,禁止使用二级缓存。
4.1.3 二级缓存事务延迟脏数据
故障场景:事务内新增/修改数据,未提交事务时,当前会话可查询到最新数据,其他请求查询到的是旧缓存数据,事务提交后数据才同步,短暂时间出现数据不一致。
底层成因 :二级缓存仅在事务提交、会话关闭后才会写入,未提交事务的数据仅存在一级缓存,全局缓存未更新,导致读写不一致。
解决方案:核心业务避免长事务,缩短事务执行周期,减少数据不一致窗口期。
4.2 核心问题二:缓存穿透(空数据缓存失效)
故障定义 :查询数据库不存在的数据(如不存在的ID、无效参数),缓存无匹配数据,每次请求都会直连数据库,高频恶意请求会压垮数据库。
MyBatis专属成因:MyBatis缓存Key基于查询参数生成,空结果不会写入一、二级缓存,导致空查询永久穿透缓存。
生产解决方案:
-
业务层判空拦截:参数非法、数据不存在的请求直接拦截,不执行SQL查询;
-
空值缓存兜底:自定义逻辑,对高频空查询参数缓存空结果,设置短过期时间;
-
结合Redis布隆过滤器:过滤不存在的业务ID,杜绝无效数据库查询。
4.3 核心问题三:缓存击穿(热点数据失效雪崩)
故障定义 :高频热点数据二级缓存过期/清空,瞬间大量并发请求直接访问数据库,导致数据库瞬时压力骤增。
MyBatis专属触发场景:热点数据所在Mapper执行增删改操作,全局清空该命名空间缓存,大量并发查询同时穿透缓存。
生产解决方案:
-
热点数据禁止使用MyBatis二级缓存,改用Redis分布式缓存,精准控制过期时间;
-
更新热点数据时,采用先更新数据库、后更新缓存策略,避免缓存瞬间失效;
-
添加并发锁:缓存失效瞬间,通过分布式锁控制数据库查询并发量。
4.4 核心问题四:缓存内存溢出(OOM隐患)
故障场景:大批量数据查询、无过期策略的静态数据长期缓存,JVM内存持续占用,引发内存溢出、项目卡顿。
底层成因 :MyBatis默认二级缓存为永久内存缓存,仅支持LRU最少淘汰策略,无主动过期、主动清理机制,海量数据会持续堆积内存。
生产解决方案:
-
禁用原生内存二级缓存,替换为Redis分布式缓存,配置过期时间、内存淘汰策略;
-
大批量列表查询、统计查询,单独关闭二级缓存,禁止缓存海量结果集;
-
定期清理静态数据缓存,数据更新后主动清空缓存。
4.5 核心问题五:Spring环境缓存失效误区(高频踩坑)
误区问题 :开发者默认开启一级缓存,认为可复用查询数据,实际Spring整合MyBatis后,一级缓存几乎完全失效。
成因原理 :Spring通过SqlSessionTemplate自动管理会话生命周期,每次方法执行完毕自动关闭SqlSession,一级缓存随会话销毁,无法实现请求内复用。
生产规范:Spring环境放弃一级缓存使用,完全依赖二级缓存+Redis分布式缓存做性能优化,无需配置一级缓存参数。
4.6 各业务场景缓存开关强制规范(生产红线)
4.6.1 ❶ 强制关闭二级缓存场景(高一致性业务)
-
金融支付、订单交易、库存扣减、账单流水等实时核心业务;
-
频繁增删改、数据秒级变动的业务模块;
-
多表关联、跨Mapper联动查询的复杂业务;
-
对账、统计、结算类精准数据业务。
4.6.2 ❷ 推荐开启二级缓存场景(高并发静态业务)
-
系统字典、全局配置、地区数据、分类标签等静态数据;
-
后台管理系统非实时报表、基础信息查询;
-
高频查询、日更/月更、低频修改的业务数据。
4.7 线上缓存故障排查流程(标准化)
-
第一步:定位缓存层级:判断脏数据来自一级缓存(事务内)还是二级缓存(跨请求);
-
第二步:检查刷新机制:确认增删改操作是否触发缓存清空、是否存在跨命名空间未刷新问题;
-
第三步:校验缓存配置:检查全局cacheEnabled、localCacheScope、方法级useCache配置是否冲突;
-
第四步:规避一致性风险:高实时业务临时关闭缓存,优先恢复线上服务;
-
第五步:优化缓存策略:针对性替换分布式缓存、添加过期策略、拆分关联业务。
4.8 面试高频考点(生产向)
-
问:Spring环境下MyBatis一级缓存为什么基本失效? 答:Spring自动托管SqlSession,每次请求/方法结束自动关闭会话,一级缓存随会话销毁,无法复用,仅原生环境生效。
-
问:MyBatis二级缓存最大的生产弊端是什么?如何解决? 答:最大弊端是命名空间隔离导致跨表关联缓存脏读,解决方案为关联业务关闭二级缓存,或手动联动刷新关联缓存。
-
问:如何解决MyBatis缓存穿透、击穿问题? 答:空参数拦截+空值缓存解决穿透;热点数据替换分布式缓存、加锁限流解决击穿;高并发业务禁用原生二级缓存。
5. 分布式缓存扩展(企业生产必优方案)
MyBatis原生二级缓存为单机内存缓存 ,仅适用于单节点项目,在集群部署、分布式微服务场景下存在缓存不共享、数据不一致、内存溢出、无过期策略 等致命问题。生产环境通常摒弃原生本地二级缓存,整合Redis/Ehcache分布式缓存替代,实现跨服务、跨节点缓存共享,支持缓存过期、淘汰、持久化,适配集群高并发场景。本节详解主流分布式缓存整合方案、配置实战、底层原理与生产规范。
5.1 原生二级缓存致命短板(集群场景必替换原因)
-
单机隔离问题 :原生缓存存储在单节点JVM内存,微服务集群多节点部署时,各节点缓存独立,数据更新后仅单节点缓存清空,其他节点残留旧数据,引发集群脏数据。
-
无过期淘汰机制:默认LRU淘汰策略无自定义过期时间,静态海量数据长期堆积,极易导致JVM内存溢出。
-
无持久化能力:项目重启、服务扩容后缓存全部清空,瞬间大量请求穿透数据库,引发数据库雪崩。
-
功能单一:不支持缓存预热、过期时间、缓存统计、手动精准删除,无法适配生产精细化管控需求。
5.2 主流分布式缓存选型对比
|---------|------------------------------------|----------------------------|----------------------------------|
| 缓存框架 | 核心优势 | 缺点 | 适用场景 |
| Redis | 分布式共享、支持过期时间、持久化、高并发、支持多种数据结构、集群稳定 | 需额外部署中间件、网络IO轻微损耗 | 微服务集群、高并发、大数据量缓存、需要持久化场景(企业主流首选) |
| Ehcache | 内嵌无需部署、内存+磁盘双存储、缓存速度快、原生适配MyBatis | 分布式能力弱、集群配置复杂、高并发性能弱于Redis | 单体项目、中小型应用、无需跨服务缓存共享场景 |
5.3 MyBatis整合Redis分布式缓存(企业标准方案)
核心思路:自定义MyBatis缓存实现类,实现Cache接口,将二级缓存数据存储到Redis,替代原生本地内存缓存,实现集群全局缓存共享。
5.3.1 核心依赖引入(Maven)
SpringBoot项目需引入Redis核心依赖,适配缓存序列化与读写:
XML
<!-- Redis核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 序列化工具 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>5.3.2 自定义Redis缓存实现类(核心代码)
实现MyBatis Cache接口,重写缓存增删查逻辑,对接Redis实现分布式存储:
java
import org.apache.ibatis.cache.Cache;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
/**
* MyBatis Redis分布式缓存实现
* 替代原生本地二级缓存,支持集群共享、过期时间
*/
@Component
public class MyBatisRedisCache implements Cache {
// 缓存命名空间ID(对应Mapper命名空间)
private final String id;
// Redis缓存默认过期时间:30分钟(可自定义)
private static final long CACHE_EXPIRE_TIME = 30 * 60;
// 构造方法初始化缓存命名空间
public MyBatisRedisCache(String id) {
this.id = id;
}
// 注入RedisTemplate
private final RedisTemplate<String, Object> redisTemplate = ApplicationContextUtil.getBean(RedisTemplate.class);
/**
* 存入缓存
*/
@Override
public void putObject(Object key, Object value) {
ValueOperations<String, Object> ops = redisTemplate.opsForValue();
// key拼接命名空间,避免全局缓存冲突
ops.set(id + ":" + key, value, CACHE_EXPIRE_TIME, TimeUnit.SECONDS);
}
/**
* 获取缓存
*/
@Override
public Object getObject(Object key) {
ValueOperations<String, Object> ops = redisTemplate.opsForValue();
return ops.get(id + ":" + key);
}
/**
* 删除指定缓存
*/
@Override
public Object removeObject(Object key) {
String cacheKey = id + ":" + key;
Object value = getObject(key);
redisTemplate.delete(cacheKey);
return value;
}
/**
* 清空当前命名空间所有缓存
*/
@Override
public void clear() {
// 模糊删除当前Mapper所有缓存
redisTemplate.delete(redisTemplate.keys(id + ":*"));
}
/**
* 获取缓存数量(可选实现)
*/
@Override
public int getSize() {
return redisTemplate.keys(id + ":*").size();
}
@Override
public String getId() {
return this.id;
}
}5.3.3 工具类获取Spring容器Bean
解决MyBatis缓存类无法直接注入Spring Bean的问题:
java
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.stereotype.Component;
@Component
public class ApplicationContextUtil implements ApplicationContextAware {
private static ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext context) throws BeansException {
applicationContext = context;
}
// 静态获取Bean
public static <T> T getBean(Class<T> clazz) {
return applicationContext.getBean(clazz);
}
}5.3.4 Mapper文件指定分布式缓存
在需要开启分布式缓存的Mapper.xml中,替换默认缓存为自定义Redis缓存:
XML
<mapper namespace="com.example.mapper.UserMapper">
<!-- 指定自定义Redis分布式缓存实现 -->
<cache type="com.example.cache.MyBatisRedisCache"/>
<!-- 原有SQL语句不变 -->
</mapper>5.3.5 全局配置保留二级缓存总开关
yml配置保持全局缓存开启,保障自定义缓存生效:
XML
mybatis:
configuration:
cache-enabled: true # 开启二级缓存总开关,适配自定义分布式缓存5.4 Ehcache缓存整合方案(中小型项目适配)
Ehcache是MyBatis官方原生支持的缓存框架,无需复杂自定义实现,配置简单、内嵌无中间件,适合单体项目、中小型应用。
5.4.1 引入依赖
XML
<!-- MyBatis适配Ehcache依赖 -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-ehcache</artifactId>
<version>1.2.2</version>
</dependency>5.4.2 新增ehcache.xml核心配置
resources目录下创建缓存配置文件,自定义过期时间、内存容量、持久化规则:
XML
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false">
<!-- 磁盘缓存存储路径 -->
<diskStore path="java.io.tmpdir/ehcache"/>
<!-- 默认缓存配置 -->
<defaultCache
maxElementsInMemory="10000"
eternal="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="3600"
overflowToDisk="true"
diskPersistent="false"/>
<!-- MyBatis二级缓存专属配置 -->
<cache name="mybatisCache"
maxElementsInMemory="5000"
eternal="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="3600"
overflowToDisk="true"/>
</ehcache>5.4.3 Mapper开启Ehcache缓存
XML
<mapper namespace="com.example.mapper.DictMapper">
<!-- 开启官方Ehcache缓存 -->
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
</mapper>5.5 分布式缓存核心优势(对比原生二级缓存)
-
集群数据一致:跨服务、跨节点共享缓存,彻底解决集群部署脏数据问题。
-
支持过期管控:自定义缓存过期时间,避免内存堆积、永久缓存脏数据。
-
持久化保障:Redis支持RDB/AOF持久化,服务重启不丢失缓存,规避重启雪崩。
-
精细化管控:支持精准删除、批量清空、缓存统计,适配生产运维需求。
-
高并发适配:Redis高性能IO,支撑集群高并发查询场景,远超原生内存缓存。
5.6 生产落地规范与避坑要点
-
缓存隔离规范:通过Mapper命名空间+自定义Key前缀实现缓存隔离,避免不同模块缓存Key冲突。
-
过期时间适配:静态数据(字典、配置)设置较长过期时间(1-2小时),动态低频数据设置30分钟,杜绝永久缓存。
-
读写一致性规范:严格遵循「更新数据库→清空缓存」流程,增删改操作自动清空对应命名空间分布式缓存。
-
禁用混合缓存:项目中禁止同时使用原生二级缓存+分布式缓存,避免缓存层级混乱、数据错乱。
-
序列化规范:所有缓存实体统一序列化规则,避免Redis序列化/反序列化失败导致缓存不生效。
-
空值缓存兜底:对高频空查询配置短时间空值缓存,杜绝缓存穿透问题。
5.7 面试高频考点
- 问:为什么微服务集群必须替换MyBatis原生二级缓存?
答:原生二级缓存是单机JVM内存缓存,集群多节点缓存不共享,数据更新后各节点缓存状态不一致,导致跨请求脏数据,无法适配分布式场景,必须替换为Redis等分布式共享缓存。
- 问:MyBatis自定义分布式缓存的核心原理?
答:实现MyBatis顶级Cache接口,重写缓存增删查清核心方法,将原本存储在JVM内存的缓存数据,迁移到Redis等分布式中间件存储,依托MyBatis缓存机制自动触发读写,无侵入替换原生缓存。
- 问:Redis分布式缓存如何解决缓存雪崩问题?
答:通过自定义缓存过期时间、持久化机制、空值缓存兜底,避免服务重启缓存全量失效、热点数据同时过期引发的数据库雪崩。
总结:
整合 Redis/Ehcache 替换默认本地二级缓存
6. 事务缓存特性(完整版·原理+规则+坑点+面试)
MyBatis 缓存与事务深度绑定,一、二级缓存拥有独立的事务联动机制,核心设计目标是规避事务脏数据、保证多会话数据隔离性。事务状态直接决定缓存的写入、更新、失效、可见规则,是解决事务内数据不一致、跨会话缓存脏读的核心底层机制,也是生产踩坑、面试高频核心考点。
6.1 核心总规则
事务未提交,二级缓存数据对外不可见;一级缓存仅当前会话可见,事务回滚后彻底失效。一二级缓存的事务隔离机制相互独立,联动管控数据一致性。
6.2 一级缓存与事务的联动特性(会话级)
一级缓存隶属于当前SqlSession,与事务强绑定,生命周期完全跟随事务与会话。
-
事务内缓存即时生效:同一事务中,查询数据会立即存入一级缓存,后续重复查询直接复用缓存,无需访问数据库,大幅减少事务内DB交互次数。
-
事务回滚缓存清空 :若事务执行异常触发
rollback()回滚,当前会话一级缓存会被强制全量清空,彻底废弃事务内所有缓存数据,避免残留无效脏数据。 -
事务提交缓存清空 :事务执行
commit()提交成功后,一级缓存同样会全量清空,防止当前会话复用旧事务数据,保证后续查询数据新鲜度。 -
跨事务缓存隔离:不同事务对应不同SqlSession,一级缓存相互独立,事务之间完全无法共享缓存数据,天然隔离事务数据。
6.3 二级缓存与事务的联动特性(全局级核心)
二级缓存是跨会话全局缓存,为了杜绝未提交事务的脏数据全局扩散,MyBatis设计了事务延迟写入机制,这是二级缓存最核心的事务特性。
-
未提交事务:数据仅存临时缓存 :事务执行过程中,所有查询、新增、修改的数据只会存入当前会话一级缓存,不会写入全局二级缓存,其他会话、其他请求完全无法读取本次事务的未提交数据。
-
事务成功提交:批量写入二级缓存 :当事务正常执行
commit()提交完毕、数据库数据落地后,本次事务所有查询结果、更新数据,才会统一批量写入对应命名空间的二级缓存,对外全局可见。 -
事务失败回滚:彻底丢弃缓存数据 :事务回滚时,临时存储在一级缓存的事务数据直接清空,零数据写入二级缓存,无效、回滚数据不会污染全局缓存。
-
事务中增删改延迟刷新缓存:事务内执行的insert、update、delete操作,不会立即清空二级缓存,仅在事务提交成功后,才会清空对应命名空间旧缓存,同步最新数据状态。
6.4 事务缓存完整执行流程
-
开启数据库事务,创建独立SqlSession,初始化空一级缓存;
-
事务内执行查询:数据存入一级缓存,复用查询,不写入二级缓存;
-
事务内执行增删改:更新数据库临时数据,清空当前一级缓存,不刷新二级缓存;
-
场景1:事务提交成功:一级缓存数据同步写入二级缓存,清空一级缓存,全局缓存更新完毕;
-
场景2:事务回滚失败:清空全部一级缓存,无任何数据写入二级缓存,二级缓存保持旧数据,无脏数据污染;
-
事务结束,关闭SqlSession,一级缓存彻底销毁。
6.5 Spring事务与MyBatis缓存联动规则
Spring整合环境下,事务由AOP管控,缓存特性适配Spring事务机制,核心规则如下:
-
同一事务共享SqlSession :Spring事务内所有数据库操作复用同一个SqlSession,一级缓存可在当前事务内跨方法复用,减少重复查询。
-
事务边界决定缓存生命周期:Spring事务开启→创建会话、初始化缓存;事务结束(提交/回滚)→销毁会话、清空一级缓存、同步二级缓存。
-
传播性事务缓存隔离:REQUIRES_NEW 独立事务会新建SqlSession,拥有独立缓存,与父事务缓存完全隔离,互不影响。
6.6 生产高频坑点(必避)
-
事务内查询数据外部无法生效:未提交事务的查询数据仅当前会话可见,其他用户查询不到最新数据,新手易误以为缓存失效。
-
长事务导致缓存数据滞后:长事务执行过程中,数据库数据已变更但未提交,二级缓存未更新,其他会话长期读取旧缓存数据,引发短暂数据不一致。
-
事务回滚后缓存残留误区:无需担心回滚后缓存脏数据,事务回滚会强制清空一级缓存,且不会写入二级缓存,数据绝对安全。
-
批量事务缓存失效问题:Batch批量事务模式下,SQL预编译不立即提交,二级缓存不会实时刷新,批量提交后才会统一更新缓存,期间存在数据延迟。
6.7 生产最佳实践
-
缩短事务周期:核心业务尽量使用短事务,减少缓存数据不一致的时间窗口,提升数据实时性。
-
实时业务禁用二级缓存:金融、库存、订单等高实时事务业务,关闭二级缓存,事务提交后直查数据库。
-
事务内避免重复查询:利用一级缓存事务内复用特性,减少事务内重复DB查询,提升事务执行性能。
-
异常事务主动清空缓存:自定义异常捕获逻辑,事务回滚后手动清空缓存,兜底杜绝脏数据残留。
6.8 面试满分考点
- 问:为什么事务未提交时,修改的数据其他会话查询不到?
答:MyBatis二级缓存采用事务延迟写入机制,未提交事务的数据仅存储在当前会话一级缓存,不会写入全局二级缓存,其他会话无法感知未提交事务数据,天然实现事务隔离,避免脏数据全局扩散。
- 问:事务提交/回滚后,一二级缓存分别会发生什么变化?
答:
① 一级缓存:无论提交或回滚,都会全量清空、随会话销毁;
② 二级缓存:提交成功后同步更新写入、清空旧缓存,回滚则无任何操作,保留原有缓存数据。
- 问:Spring事务内,一级缓存是否可以跨方法复用?为什么?
答:可以复用。Spring同一事务内共享同一个SqlSession,一级缓存生命周期贯穿整个事务,事务内所有方法可共享缓存数据,事务结束后才会销毁。
核心总结
-
一级缓存:事务内复用、事务结束清空、仅当前会话可见;
-
二级缓存:事务延迟写入、提交生效、回滚丢弃,保障全局数据一致;
-
事务缓存隔离是MyBatis规避脏数据、实现多会话数据安全的核心机制。
七、高级拓展特性
1. 分页处理(完整版 · 原生缺陷+PageHelper实战+原理+避坑+面试)
MyBatis 原生不提供成熟物理分页能力,仅内置简易内存分页工具,生产环境完全依赖PageHelper分页插件 实现标准物理分页。分页是企业开发高频功能,也是面试常考点,核心区分内存分页(低效) 与物理分页(高效),下面全覆盖讲解两种方案、生产实战、底层原理与高频坑点。
1.1 原生分页:RowBounds 内存分页(不推荐生产)
1.1.1 核心原理
RowBounds 是 MyBatis 原生自带分页对象,无需引入额外依赖,其核心分页逻辑不在数据库层面,而是在内存层面 。执行逻辑为:执行完整 SQL 查询出全部数据,加载到 JVM 内存后,通过内存偏移量和条数截取实现分页效果。
1.1.2 基础使用方式
java
// offset:起始偏移量,limit:每页条数
RowBounds rowBounds = new RowBounds(0, 10);
// 第二个参数传入分页对象,无需修改Mapper、SQL
List<User> userList = sqlSession.selectList("com.example.mapper.UserMapper.selectUserList", null, rowBounds);1.1.3 致命缺陷(生产禁用)
-
性能极差:无论分页条数多少,都会查询数据库全量数据,大数据量下会查询数万、数十万条数据,严重拖慢数据库和程序性能。
-
内存溢出风险:海量数据查询会一次性加载全部数据到JVM内存,极易引发OOM内存溢出。
-
无总数返回:不自动返回数据总条数、总页数,无法实现前端分页组件的页码渲染。
-
仅支持内存截取:无法利用数据库索引、分页优化机制,完全丧失数据库分页性能优势。
1.1.4 适用场景
仅适用于数据量极小、固定少量数据 的内部简易查询,正式业务、大数据量场景绝对禁止使用。
1.2 企业主流方案:PageHelper 物理分页(生产标配)
PageHelper 是 MyBatis 生态最主流的分页插件,基于 MyBatis 拦截器机制实现,无需修改业务SQL、无侵入,自动对查询SQL进行拦截、拼接分页语句,实现数据库级物理分页,同时自动统计总条数、总页数,适配所有数据库,是企业唯一标准分页方案。
1.2.1 核心优势
-
纯物理分页:底层自动拼接 limit(MySQL)、rownum(Oracle)分页语句,仅查询当前页数据,性能极高。
-
无侵入开发:无需改动原有Mapper接口、XML SQL,一行代码开启分页。
-
自动分页适配:自动适配MySQL、Oracle、SQLServer等多数据库,无需手动修改分页语法。
-
自动统计总数:自动执行count查询,返回总条数、总页数、当前页、每页条数等完整分页参数。
-
参数灵活可控:支持页码分页、偏移量分页、排序、参数合理化修正。
1.2.2 SpringBoot 完整依赖配置
版本适配:SpringBoot2.x 适配 5.x 版本,SpringBoot3.x 适配 6.x 版本
XML
<!-- PageHelper 分页插件依赖 -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>5.1.4</version>
</dependency>1.2.3 全局yml核心配置(生产标准)
XML
# PageHelper分页配置
pagehelper:
helper-dialect: mysql # 指定数据库方言,自动适配分页语法
reasonable: true # 开启参数合理化:页码<1默认查第一页,页码超出总页数默认查最后一页
support-methods-arguments: true # 支持通过Mapper接口参数传递分页参数
params: pageNum=pageNum,pageSize=pageSize # 自定义分页参数映射
auto-count: true # 自动开启总数统计
page-size-zero: false # 禁止pageSize=0时查询全部数据,规避大数据量风险1.2.4 标准实战代码(企业通用)
无需修改Mapper接口、XML SQL,原有查询逻辑完全复用
1、原有Mapper接口
java
List<User> selectUserList(@Param("userName") String userName);2、原有XML SQL
XML
<select id="selectUserList" resultType="User">
SELECT id,user_name,age,email,create_time FROM user
<where>
<if test="userName != null and userName != ''">
AND user_name LIKE CONCAT('%',#{userName},'%')
</if>
</where>
</select>3、业务层分页调用(核心)
java
@Test
void testPageQuery() {
// 开启分页:pageNum=1(第一页),pageSize=10(每页10条)
PageHelper.startPage(1, 10);
// 紧跟分页方法,执行查询(仅紧邻的第一条查询生效)
List<User> userList = userMapper.selectUserList("用户");
// 封装分页结果对象
PageInfo<User> pageInfo = new PageInfo<>(userList);
// 分页完整参数
System.out.println("当前页码:" + pageInfo.getPageNum());
System.out.println("每页条数:" + pageInfo.getPageSize());
System.out.println("总数据条数:" + pageInfo.getTotal());
System.out.println("总页数:" + pageInfo.getPages());
System.out.println("当前页数据:" + pageInfo.getList());
}1.2.5 PageInfo 核心常用参数
-
基础参数:pageNum当前页、pageSize每页条数、total总条数、pages总页数
-
页码状态:isFirstPage是否首页、isLastPage是否末页、hasNextPage是否有下一页、hasPreviousPage是否有上一页
-
数据封装:getList()获取当前页数据列表
1.3 PageHelper 底层核心原理(面试高频)
PageHelper 基于MyBatis 插件拦截器机制 实现,核心拦截 Executor.query 查询方法,
执行流程如下:
业务代码调用 PageHelper.startPage(),将分页参数存入ThreadLocal线程本地变量;
MyBatis执行查询SQL时,PageHelper拦截器感知线程内分页参数;
自动拦截原有查询SQL,**拼接数据库分页语句(limit/rownum)**生成分页查询SQL;
自动执行count统计SQL,查询数据总条数;
封装分页数据到PageInfo对象,清空ThreadLocal分页参数,避免参数污染;
返回当前页数据与完整分页信息。
核心关键点 :分页参数基于ThreadLocal隔离,仅对紧邻的第一条查询语句生效,避免全局分页错乱。
1.4 生产高频坑点与避坑方案(必记)
- 坑点1:分页参数污染(最高频)
问题:startPage()后执行多条查询,会导致后续无关查询被莫名分页,数据错乱。
解决方案:严格遵循startPage()紧跟查询语句,中间不穿插任何其他数据库操作。
- 坑点2:大数据量count查询慢
问题:千万级数据count(*)统计耗时极高,导致分页接口卡顿。
解决方案:大数量场景手动关闭自动count,自定义轻量化统计SQL,或缓存总条数。
- 坑点3:排序注入风险
问题:直接接收前端排序字段拼接SQL,存在SQL注入风险。
解决方案:校验排序字段白名单,禁止直接拼接前端参数。
- 坑点4:pageSize=0 查询全量数据
问题:前端传pageSize=0,插件默认查询全部数据,引发大数据量查询风险。
解决方案:配置 page-size-zero=false 禁用该特性。
- 坑点5:关联分页错乱
问题:多表联查、嵌套查询使用PageHelper,分页结果不准确。
解决方案:复杂关联查询手动写limit分页SQL,不依赖插件自动分页。
1.5 分页最佳生产规范
-
统一使用 PageHelper 物理分页,彻底禁用 RowBounds 内存分页;
-
全局开启参数合理化,规避非法页码参数导致的报错;
-
分页方法仅查询单表/简单联表,复杂统计分页手动实现;
-
接口统一返回PageInfo封装结果,标准化前端分页参数;
-
超大数量分页禁止全量count,采用近似统计或缓存统计方案。
1.6 面试满分考点
- 问:RowBounds和PageHelper分页的核心区别?
答:RowBounds是内存分页,查询全量数据后内存截取,大数据量性能极差、存在OOM风险;PageHelper是物理分页,拦截SQL拼接limit语句,仅查询当前页数据,性能高效,支持总数统计,是生产唯一方案。
- 问:PageHelper的实现原理?为什么不会污染其他查询?
答:基于MyBatis插件拦截器实现,通过ThreadLocal存储分页参数,仅对startPage()紧邻的第一条查询生效,查询结束后立即清空线程参数,无参数污染。
- 问:PageHelper生产最大坑点是什么?如何规避?
答:最大坑点是分页参数污染,导致后续查询异常分页;规避方案是保证分页开启代码与查询代码紧邻,无任何中间操作。
核心总结
分页优先使用 PageHelper 物理分页,摒弃原生 RowBounds 内存分页;依托插件拦截机制实现无侵入分页,严控参数污染、大数据量统计等生产问题,适配所有企业分页场景。
总结:
-
原生 RowBounds:内存分页,大数据量低效
-
PageHelper 插件:主流物理分页,企业通用方案
2. 类型处理器 TypeHandler(完整版·原理+自定义+实战+避坑+面试)
TypeHandler 是 MyBatis 核心内置组件,核心作用是实现 Java 实体类型与数据库字段类型的双向自动转换,贯穿数据入库、查询全流程。入库时将Java类型转为数据库可存储类型,查询时将数据库字段类型还原为Java实体类型,是解决特殊字段适配、类型转换异常、枚举/JSON字段映射的核心方案,企业开发高频使用,也是面试基础考点。
2.1 核心底层原理
MyBatis 在执行SQL参数赋值、结果集封装阶段,会自动匹配对应的 TypeHandler 完成类型转换,全程无侵入、自动化执行:
-
写入流程(Java→数据库):实体类Java属性 → TypeHandler 序列化转换 → JDBC 数据库字段类型 → 存入数据库
-
查询流程(数据库→Java):数据库字段原始值 → TypeHandler 反序列化转换 → Java 实体属性类型 → 封装返回实体
所有类型转换逻辑统一遵循 TypeHandler 顶层接口 规范,核心实现四大抽象方法:setParameter(写入转换)、getResult(查询转换,适配列索引/列名/存储过程)。
2.2 系统内置常用TypeHandler(开箱即用)
MyBatis 预设大量通用类型处理器,覆盖90%基础类型转换场景,无需自定义配置,默认自动生效:
-
基础类型处理器:StringTypeHandler(字符串)、IntegerTypeHandler(整型)、LongTypeHandler(长整型)、DateTypeHandler(日期)、BooleanTypeHandler(布尔值),适配常规基础类型双向转换。
-
特殊基础处理器:BigDecimalTypeHandler(高精度数值)、ByteArrayTypeHandler(字节数组)、ClobTypeHandler(大文本)、BlobTypeHandler(二进制文件),适配数据库大字段、高精度字段。
-
枚举专用处理器(重点) :EnumOrdinalTypeHandler:默认枚举处理器,通过枚举下标序号映射数据库数值,下标变更会导致数据错乱,生产慎用。
-
EnumTypeHandler:企业推荐,通过枚举字符串名称映射数据库字符串,稳定性高、可读性强,是枚举映射标准方案。
2.3 原生内置处理器缺陷(自定义开发必要性)
系统默认处理器仅适配基础数据类型,无法满足企业复杂业务场景,存在明显短板:
-
不支持 Java枚举自定义属性映射(如枚举code编码映射数据库数值);
-
不支持 JSON/数组集合字段 与数据库字符串双向转换;
-
不支持自定义特殊格式转换(如日期格式化、金额分元转换、数据脱敏);
-
默认枚举序号映射易因枚举新增删除导致历史数据错乱。
因此复杂业务必须自定义TypeHandler实现个性化类型转换。
2.4 自定义TypeHandler开发通用流程(标准化)
所有自定义类型处理器遵循统一开发规范,四步即可落地生效,适配任意自定义类型转换场景:
-
步骤1:继承通用父类:继承 BaseTypeHandler<自定义类型>,无需实现全部接口方法,仅重写核心转换方法;
-
步骤2:重写四大核心方法:实现参数写入、结果查询的双向转换逻辑;
-
步骤3:添加泛型注解:通过@MappedJdbcTypes、@MappedTypes绑定Java类型与数据库字段类型;
-
步骤4:全局注册生效:在MyBatis全局配置中注册自定义处理器,全局生效。
2.5 企业高频实战案例(可直接复用代码)
2.5.1 案例一:自定义枚举Code处理器(生产最常用)
业务场景:数据库存储枚举数字code,Java实体使用枚举对象,实现code与枚举的双向自动转换,规避原生枚举下标映射bug。
java
import org.apache.ibatis.type.BaseTypeHandler;
import org.apache.ibatis.type.JdbcType;
import org.apache.ibatis.type.MappedTypes;
import java.sql.CallableStatement;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Arrays;
// 绑定需要转换的枚举父类/具体枚举类
@MappedTypes(BaseEnum.class)
public class EnumCodeTypeHandler<T extends BaseEnum> extends BaseTypeHandler<T> {
private final Class<T> type;
// 构造方法注入枚举类型
public EnumCodeTypeHandler(Class<T> type) {
this.type = type;
}
// 入库:枚举对象 → 数据库code数值
@Override
public void setNonNullParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException {
ps.setInt(i, parameter.getCode());
}
// 查询:数据库code → 枚举对象(根据code匹配枚举)
@Override
public T getNullableResult(ResultSet rs, String columnName) throws SQLException {
return convertCodeToEnum(rs.getInt(columnName));
}
@Override
public T getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
return convertCodeToEnum(rs.getInt(columnIndex));
}
@Override
public T getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
return convertCodeToEnum(cs.getInt(columnIndex));
}
// 核心转换逻辑:根据code匹配对应枚举
private T convertCodeToEnum(Integer code) {
if (code == null) {
return null;
}
return Arrays.stream(type.getEnumConstants())
.filter(enumItem -> enumItem.getCode().equals(code))
.findFirst()
.orElse(null);
}
}
// 枚举统一父类规范
interface BaseEnum {
Integer getCode();
}
// 业务枚举示例
public enum StatusEnum implements BaseEnum {
NORMAL(1, "正常"),
DISABLE(0, "禁用");
private final Integer code;
private final String desc;
StatusEnum(Integer code, String desc) {
this.code = code;
this.desc = desc;
}
@Override
public Integer getCode() {
return code;
}
}2.5.2 案例二:JSON字段类型处理器(复杂对象存储)
业务场景:数据库用varchar存储JSON字符串,Java实体用List/自定义对象接收,实现JSON与Java对象双向自动序列化、反序列化,适配多属性存储场景。
java
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.ibatis.type.BaseTypeHandler;
import org.apache.ibatis.type.JdbcType;
import org.apache.ibatis.type.MappedJdbcTypes;
import org.apache.ibatis.type.MappedTypes;
import java.sql.CallableStatement;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.List;
// 适配Java List类型、数据库VARCHAR类型
@MappedTypes(List.class)
@MappedJdbcTypes(JdbcType.VARCHAR)
public class JsonListTypeHandler extends BaseTypeHandler<List<String>> {
private static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();
// 入库:List集合 → JSON字符串
@Override
public void setNonNullParameter(PreparedStatement ps, int i, List<String> parameter, JdbcType jdbcType) throws SQLException {
try {
ps.setString(i, OBJECT_MAPPER.writeValueAsString(parameter));
} catch (Exception e) {
throw new SQLException("JSON序列化失败", e);
}
}
// 查询:JSON字符串 → List集合
@Override
public List<String> getNullableResult(ResultSet rs, String columnName) throws SQLException {
return jsonToList(rs.getString(columnName));
}
@Override
public List<String> getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
return jsonToList(rs.getString(columnIndex));
}
@Override
public List<String> getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
return jsonToList(cs.getString(columnIndex));
}
private List<String> jsonToList(String json) throws SQLException {
if (json == null || json.isEmpty()) {
return null;
}
try {
return OBJECT_MAPPER.readValue(json, new TypeReference<List<String>>() {});
} catch (Exception e) {
throw new SQLException("JSON反序列化失败", e);
}
}
}2.6 自定义处理器全局注册方式(SpringBoot主流)
SpringBoot项目无需编写原生xml配置,通过yml一键扫描注册,全局生效:
XML
mybatis:
configuration:
# 开启自定义类型处理器扫描
default-type-handler-package: com.example.handler # 自定义处理器所在包路径原生mybatis-config.xml注册方式(适配非Spring环境):
XML
<typeHandlers>
<!-- 注册单个自定义处理器 -->
<typeHandler handler="com.example.handler.EnumCodeTypeHandler"/>
<typeHandler handler="com.example.handler.JsonListTypeHandler"/>
<!-- 批量扫描包下所有处理器 -->
<package name="com.example.handler"/>
</typeHandlers>2.7 精准指定处理器(局部优先级覆盖全局)
部分字段需要差异化转换规则时,可在Mapper XML中单独指定typeHandler,优先级高于全局配置:
XML
<!-- 查询结果映射指定处理器 -->
<result column="status" property="status" typeHandler="com.example.handler.EnumCodeTypeHandler"/>
<!-- 插入/更新参数指定处理器 -->
<insert id="insertUser">
INSERT INTO user(status, tags)
VALUES(#{status,typeHandler=com.example.handler.EnumCodeTypeHandler},
#{tags,typeHandler=com.example.handler.JsonListTypeHandler})
</insert>2.8 生产高频坑点与避坑方案
- 坑点1:枚举下标映射数据错乱
问题:使用默认EnumOrdinalTypeHandler,枚举新增/删除字段后下标改变,历史数据映射失效。 方案:统一禁用默认下标映射,自定义Code枚举处理器,通过固定code值映射数据库。
- 坑点2:JSON转换空值报错
问题:数据库字段为null/空字符串时,自定义JSON处理器反序列化抛出异常。
方案:处理器内部做空值判断,空值直接返回null,避免序列化报错。
- 坑点3:全局处理器冲突
问题:多个处理器适配同一类型,导致转换规则混乱。
方案:通过@MappedTypes精准限定适配类型,避免泛化匹配冲突,特殊字段局部单独指定处理器。
- 坑点4:未注册处理器不生效
问题:自定义处理器未配置扫描路径,导致类型转换失效、字段赋值为null。
方案:严格配置处理器包扫描路径,启动日志校验处理器加载成功。
- 坑点5:类型不匹配报错
问题:Java类型与数据库字段类型不匹配,如JSON处理器适配非字符串字段。
方案:通过@MappedJdbcTypes绑定数据库字段类型,严格限定转换范围。
2.9 企业适用场景汇总
-
枚举字段映射:状态、性别、类型等业务枚举,通过自定义code映射数据库数值;
-
复杂JSON字段存储:标签列表、拓展参数、多属性配置等,数据库存JSON、实体存对象/集合;
-
数据格式转换:金额分元自动转换、日期格式化、字符串脱敏处理;
-
特殊类型适配:自定义加密字段、二进制文件、特殊编码字符串双向转换。
2.10 面试高频考点
- 问:TypeHandler的作用是什么?底层执行时机?
答:用于Java类型与数据库字段类型双向转换,参数预编译赋值时执行Java→数据库转换,结果集封装时执行数据库→Java转换。
- 问:MyBatis默认枚举处理器的问题?如何解决?
答:默认EnumOrdinalTypeHandler基于枚举下标映射,枚举迭代会导致数据错乱;生产自定义Code类型处理器,通过固定编码映射,稳定性更强。
- 问:全局TypeHandler和局部指定的优先级?
答:局部Mapper XML指定的typeHandler优先级高于全局注册的处理器,可实现差异化转换。
核心总结
TypeHandler 是 MyBatis 类型转换核心组件,基础类型用内置处理器,枚举、JSON、特殊格式字段必须自定义处理器;全局注册统一规范,局部指定适配特殊场景,彻底解决类型转换异常、数据映射错乱问题。
实现 Java 类型与数据库类型转换;适用枚举、JSON、自定义特殊字段
3. SQL 注入防护(完整版·原理+区别+场景+规范+面试)
SQL注入是Web项目高危漏洞,MyBatis作为持久层框架,原生提供完善的防注入机制,核心核心在于区分#{}预编译占位符与${}字符串直接拼接,掌握两者使用场景、差异及规范,可彻底杜绝MyBatis层面的SQL注入风险,是开发必备、面试高频核心考点。
3.1 SQL注入核心原理
SQL注入本质是恶意用户拼接非法SQL语句,篡改原有SQL执行逻辑。开发者直接拼接前端传入的参数字符串至SQL语句中,未做预编译和参数过滤,攻击者可通过传入特殊字符(单引号、or、and、union、注释符--/#等),绕过查询条件、查询敏感数据、篡改甚至删除数据库数据。
核心危害:数据泄露、数据篡改、数据删除、权限绕过、整库脱库,是生产环境重点防护的高危漏洞。
3.2 #{} 与 ${} 核心本质与区别(必背)
MyBatis中两种参数占位符是防注入的核心,底层执行机制完全不同,安全等级、适用场景差异极大,是SQL防护的核心重点。
3.2.1 #{} 预编译占位符(安全·生产首选)
-
底层原理 :采用JDBC PreparedStatement预编译机制,SQL语句提前编译、生成执行计划,参数仅作为纯数据传入,不会参与SQL语句解析编译。
-
自动处理机制 :自动对字符串参数添加单引号、转义特殊字符(单引号、反斜杠、特殊符号),彻底屏蔽SQL语法拼接风险。
-
安全特性 :完全杜绝SQL注入,无论传入任何恶意参数,仅会被当做普通数据处理,无法篡改SQL逻辑。
-
额外优势 :预编译SQL可被数据库缓存执行计划,提升重复查询性能。
-
局限性 :仅能填充参数值,无法替代表名、字段名、排序关键字等SQL语法结构。
3.2.2 ${} 字符串直接拼接(不安全·谨慎使用)
-
底层原理:纯字符串直接拼接,无预编译机制,直接将参数内容拼接进原生SQL语句,参与SQL解析编译。
-
自动处理机制 :不做任何转义、不添加单引号,参数是什么内容,SQL就拼接什么内容。
-
安全隐患 :存在百分百SQL注入风险,恶意参数可直接篡改SQL执行逻辑。
-
优势场景:支持动态拼接表名、字段名、排序字段、排序规则(asc/desc)等语法结构,#{}无法实现。
-
核心短板:无安全防护,必须手动参数校验,禁止接收用户可控参数。
3.3 实战注入漏洞演示(直观理解)
3.3.1 危险场景:${}接收用户参数(注入漏洞)
Mapper SQL写法(高危):
XML
<select id="getUserByUserName" resultType="User">
SELECT * FROM user WHERE user_name = ${userName}
</select>前端恶意参数:admin' or '1'='1' --
最终拼接执行SQL:
SELECT * FROM user WHERE user_name = 'admin' or '1'='1' -- '
后果:条件恒成立,查询出数据库全部用户数据,造成数据泄露;若拼接删除、修改语句,可直接篡改清空数据。
3.3.2 安全场景:#{} 接收相同参数(无漏洞)
Mapper SQL写法(安全):
XML
<select id="getUserByUserName" resultType="User">
SELECT * FROM user WHERE user_name = #{userName}
</select>传入相同恶意参数,MyBatis自动转义封装,最终执行SQL:
SELECT * FROM user WHERE user_name = 'admin\' or \'1\'=\'1\' -- '
后果:恶意参数被当做普通用户名查询,无匹配数据,无法篡改SQL逻辑,彻底规避注入风险。
3.4 ${} 合法使用场景(仅这几类可使用)
开发中禁止杜绝一切用户可控参数使用${} ,仅在以下参数完全可控、固定枚举的场景允许使用:
-
动态排序:前端传排序字段、排序规则(asc/desc),后端白名单校验后拼接
-
动态表名:分表场景(按月分表、按用户分表),表名由后端规则生成,非用户传入
-
动态字段查询:固定业务字段动态查询,字段名后端枚举定义
-
批量in查询旧方案(不推荐):优先使用foreach标签替代
3.5 ${} 安全使用规范(强制落地)
但凡使用${},必须遵循以下规范,否则一律判定为代码漏洞:
-
参数白名单校验:所有传入${}的参数,必须后端定义白名单,不在白名单内直接拦截报错,拒绝非法参数
-
禁止用户直接传参 :${}参数必须由后端代码生成/枚举指定,不接收前端原始参数
-
手动特殊字符过滤:针对特殊符号(单引号、--、union、or、and)做强制过滤
-
优先替代方案:动态排序、表名场景优先使用插件、工具类封装,减少${}直接使用
3.6 高频错误场景与修复方案
| 高危错误场景 | 问题风险 | 标准修复方案 |
|---|---|---|
| 查询条件参数使用${} | 全程SQL注入高危漏洞 | 统一替换为 #{} 预编译占位符 |
| 前端直接传排序字段拼接${} | 可拼接任意SQL语句,脱库风险 | 后端白名单校验,过滤非法字段与关键字 |
| in查询使用${}拼接字符串 | 参数拼接注入风险,且格式易出错 | 使用 <foreach> 标签遍历拼接参数 |
| 未做参数校验直接使用动态表名 | 遍历查询所有数据表数据 | 表名规则后端硬编码,禁止前端传参 |
3.7 进阶防护方案(企业生产加固)
-
全局参数过滤:通过拦截器统一过滤前端参数中的SQL特殊关键字(union、select、delete、drop、-- 等)
-
数据库权限最小化:业务数据库账号仅授予增删改查权限,禁止授予删表、改表、库操作权限,降低注入危害
-
开启SQL日志审计:生产记录所有执行SQL日志,异常SQL及时告警排查
-
禁止动态SQL拼接用户参数:所有用户输入参数,强制使用#{}预编译,零例外
3.8 面试满分标准答案
- 问:#{} 和 ${} 的区别?哪个安全?为什么?
答:
-
#{} 是预编译占位符,基于PreparedStatement实现,自动转义特殊字符,彻底防止SQL注入,仅能传参数值;
-
${} 是字符串直接拼接,无预编译、无字符转义,存在SQL注入风险,可拼接SQL结构;
-
开发中优先使用#{},${}仅用于动态表名、排序等特殊场景,且必须做白名单校验。
- 问:MyBatis为什么能通过#{}杜绝SQL注入?
答:因为#{}采用预编译机制,SQL语句结构提前固定,参数仅作为数据载体,不会参与SQL语法解析,特殊字符被自动转义,无法篡改原有SQL执行逻辑,从底层规避注入风险。
- 问:${}一定存在注入漏洞吗?如何安全使用?
答:并非绝对,若参数为后端可控固定值、无用户输入则无风险;若接收前端用户参数则高危。安全使用必须做参数白名单校验、特殊字符过滤、禁止用户可控传参。
核心总结
-
常规参数查询、新增、修改、删除,统一使用 #{} 预编译,天然防注入;
-
动态表名、排序等特殊场景慎用 ${},必须做参数校验加固;
-
SQL注入防护核心:杜绝用户参数直接字符串拼接,依赖预编译机制。
4. 多数据源与读写分离(完整版·原理+动态切换+实战代码+生产调优+面试)
多数据源、读写分离是分布式项目核心能力,主要解决单库性能瓶颈、读写压力过载、业务数据隔离问题。MyBatis 本身无内置多数据源能力,可结合 Spring 动态数据源机制、AbstractRoutingDataSource 实现无侵入数据源切换,适配一主多从、多业务库隔离、读写分离、分库场景,是中高级开发、面试高频核心知识点。
4.1 核心概念与适用场景
4.1.1 核心概念区分
-
多数据源:项目连接多个独立数据库(如用户库、订单库、日志库),实现业务数据隔离,适配微服务、多模块独立数据库场景。
-
读写分离 :基于一主多从 数据库架构,主库(Master)负责写操作(增删改) ,从库(Slave)负责读操作(查询),分担数据库读写压力,提升并发查询性能。
4.1.2 生产适用场景
-
高并发互联网项目:读请求量远大于写请求,单库无法承载海量查询压力;
-
业务模块拆分:多业务独立数据库,需要一个项目统一操作多数据源;
-
数据容灾架构:主从架构实现数据备份,从库承担查询压力,主库专注写入;
-
数据隔离场景:核心业务库、日志库、统计库物理隔离,互不影响。
4.1.3 核心优势
-
性能提升:读写请求拆分,从库集群分担读压力,解决单库CPU、连接池瓶颈;
-
数据安全:主从同步实现数据备份,从库可单独做数据统计、日志查询,不影响主业务;
-
高可用:主库故障可快速切换从库,规避单库单点故障问题。
4.2 底层核心原理:AbstractRoutingDataSource
Spring 提供的 AbstractRoutingDataSource 是动态数据源切换的核心父类,也是 MyBatis 实现多数据源、读写分离的底层基石,核心设计为动态路由、线程隔离、无侵入切换。
4.2.1 核心机制
-
预先注册多个数据源(主库、从库1、从库2、业务库等)到容器;
-
通过 ThreadLocal 存储当前线程的数据源标识,实现线程级数据源隔离;
-
重写 determineCurrentLookupKey() 方法,根据标识动态选择对应数据源;
-
MyBatis 操作数据库前,Spring 自动拦截请求,路由到指定数据源,全程无侵入业务代码。
4.2.2 核心执行流程
项目启动加载多数据源配置 → 注册所有数据源至动态路由容器 → 业务方法执行前设置数据源标识 → 路由类根据标识匹配数据源 → MyBatis 基于指定数据源执行SQL → 线程结束清空数据源标识,避免参数污染。
4.3 企业主流落地方案对比
| 实现方案 | 核心原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 手动动态数据源(原生) | 基于AbstractRoutingDataSource自定义实现,注解切换数据源 | 轻量、无第三方依赖、可控性强 | 需手动封装、处理事务、负载均衡 | 中小型项目、简单读写分离 |
| Dynamic-Datasource(框架) | 基于Spring封装的动态数据源框架,一键配置 | 开箱即用、支持负载均衡、事务适配 | 轻度依赖第三方框架 | 企业主流项目、复杂多数据源 |
| Sharding-JDBC | 分片框架内置读写分离、分库分表能力 | 功能强大、支持高可用、负载均衡、故障转移 | 引入较重、配置复杂 | 大型分布式、分库分表项目 |
4.4 SpringBoot+MyBatis 原生多数据源实战(可直接复用)
4.4.1 依赖引入
无需额外特殊依赖,仅需基础JDBC、MyBatis依赖即可
XML
<!-- Spring JDBC -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- MyBatis整合依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
</dependency>
<!-- 数据库驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>4.4.2 多数据源yml配置(一主一从)
XML
# 多数据源配置
spring:
datasource:
# 主库数据源(写库)
master:
url: jdbc:mysql://localhost:3306/db_master?useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
# 从库数据源(读库)
slave:
url: jdbc:mysql://localhost:3306/db_slave?useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
# MyBatis全局配置
mybatis:
mapper-locations: classpath:mapper/*.xml
configuration:
map-underscore-to-camel-case: true4.4.3 数据源标识枚举(规范切换)
java
/**
* 数据源类型枚举
*/
public enum DataSourceType {
/** 主库(写) */
MASTER,
/** 从库(读) */
SLAVE
}4.4.4 数据源上下文工具类(线程隔离)
java
/**
* 数据源上下文,基于ThreadLocal实现线程隔离
*/
public class DataSourceContextHolder {
// 线程私有数据源标识
private static final ThreadLocal<DataSourceType> DATA_SOURCE_TYPE = new ThreadLocal<>();
/**
* 设置数据源
*/
public static void setDataSource(DataSourceType type) {
DATA_SOURCE_TYPE.set(type);
}
/**
* 获取当前数据源
*/
public static DataSourceType getDataSource() {
return DATA_SOURCE_TYPE.get() == null ? DataSourceType.MASTER : DATA_SOURCE_TYPE.get();
}
/**
* 清空数据源(防止内存泄露、参数污染)
*/
public static void clear() {
DATA_SOURCE_TYPE.remove();
}
}4.4.5 自定义动态数据源路由类
java
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
/**
* 自定义动态数据源路由器
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
/**
* 核心方法:获取当前数据源标识,动态路由
*/
@Override
protected Object determineCurrentLookupKey() {
// 从线程上下文获取数据源类型
return DataSourceContextHolder.getDataSource();
}
}4.4.6 数据源配置类(注册多数据源)
java
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.jdbc.datasource.DriverManagerDataSource;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DataSourceConfig {
// 注册主库数据源
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource masterDataSource() {
return new DriverManagerDataSource();
}
// 注册从库数据源
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaveDataSource() {
return new DriverManagerDataSource();
}
// 构建动态数据源,优先使用
@Bean
@Primary
public DataSource dynamicDataSource(DataSource masterDataSource, DataSource slaveDataSource) {
DynamicDataSource dynamicDataSource = new DynamicDataSource();
// 配置默认数据源(主库)
dynamicDataSource.setDefaultTargetDataSource(masterDataSource);
// 配置多数据源映射关系
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(DataSourceType.MASTER, masterDataSource);
dataSourceMap.put(DataSourceType.SLAVE, slaveDataSource);
dynamicDataSource.setTargetDataSources(dataSourceMap);
return dynamicDataSource;
}
}4.4.7 自定义切换注解(业务无侵入)
java
import java.lang.annotation.*;
/**
* 数据源切换注解
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DS {
DataSourceType value() default DataSourceType.MASTER;
}4.4.8 AOP切面实现自动切换(核心)
java
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.stereotype.Component;
@Aspect
@Component
public class DataSourceAspect {
// 拦截带@DS注解的方法,实现数据源切换
@Around("@annotation(ds)")
public Object around(ProceedingJoinPoint point, DS ds) throws Throwable {
try {
// 设置当前方法数据源
DataSourceContextHolder.setDataSource(ds.value());
// 执行目标方法
return point.proceed();
} finally {
// 执行完毕清空数据源,避免线程污染
DataSourceContextHolder.clear();
}
}
}4.4.9 业务层使用实战
java
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
// 写操作:默认主库,无需注解
public void addUser(User user) {
userMapper.insertUser(user);
}
// 读操作:切换从库
@DS(DataSourceType.SLAVE)
public User getUserById(Integer id) {
return userMapper.selectUserById(id);
}
}4.5 读写分离核心规范(生产强制)
-
读写严格分离:所有增删改走主库,所有查询走从库,杜绝写操作路由到从库导致数据写入失败;
-
默认主库原则:无注解指定数据源时,默认使用主库,保证写操作安全;
-
线程隔离规范:每次方法执行完毕必须清空数据源标识,防止线程复用导致数据源错乱;
-
事务绑定主库:所有开启事务的方法,强制走主库,禁止跨数据源事务,规避分布式事务问题;
-
多从库负载均衡:一主多从场景,通过随机、轮询策略选择从库,均分读压力。
4.6 生产高频坑点与解决方案
- 坑点1:主从数据延迟导致查询旧数据
问题:MySQL主从同步存在毫秒/秒级延迟,写入主库后立即查询从库,查询不到最新数据。
解决方案:写后立即读的场景强制走主库,核心实时查询业务不走从库。
- 坑点2:事务内数据源切换失效
问题:Spring事务开启后,会绑定当前数据源,事务内切换数据源不生效。
解决方案:一个事务只能使用一个数据源,禁止事务内动态切换,拆分跨库事务。
- 坑点3:线程复用导致数据源污染
问题:线程池线程复用,上一次线程的数据源标识未清空,导致本次请求数据源错乱。
解决方案:通过finally强制清空ThreadLocal数据源标识,兜底隔离。
- 坑点4:从库写入数据报错
问题:代码疏漏导致增删改操作路由到从库,从库只读报错。
解决方案:从库账号配置只读权限,权限兜底防护,同时规范注解使用。
- 坑点5:多从库负载不均
问题:固定从库路由,导致单从库压力过大。
解决方案:自定义从库轮询/随机路由策略,实现负载均衡。
4.7 进阶优化方案
-
动态数据源热刷新:支持不停机更新数据源配置,适配动态扩缩容从库;
-
数据源健康检测:定时检测从库连接状态,自动剔除故障从库,实现故障转移;
-
精准粒度切换:支持类、方法级别的精细化数据源控制,适配复杂业务;
-
读写分离+缓存联动:主库写入后更新缓存,从库查询优先走缓存,减少DB查询压力。
4.8 面试满分高频考点
- 问:MyBatis如何实现读写分离?底层原理是什么?
答:基于Spring AbstractRoutingDataSource动态数据源实现,通过ThreadLocal存储线程级数据源标识,AOP切面拦截业务方法,根据@DS注解动态路由主库或从库,主库处理写操作,从库处理读操作,全程无侵入业务代码。
- 问:读写分离最大的问题是什么?如何解决?
答:核心问题是主从数据同步延迟,导致写后查不到最新数据。
解决方案:实时查询、写后立即读场景强制走主库,非实时查询走从库,平衡性能与数据一致性。
- 问:事务中可以切换数据源吗?为什么?
答:不可以。Spring事务基于数据源绑定,事务开启时会固定当前数据源,事务生命周期内无法切换,强行切换不生效,且会引发事务混乱、数据不一致问题。
- 问:多数据源如何保证线程安全?
答:通过ThreadLocal存储每个线程独立的数据源标识,线程之间完全隔离,配合方法执行后清空机制,彻底杜绝线程复用导致的数据源污染问题。
核心总结
-
多数据源/读写分离底层依托 AbstractRoutingDataSource+ThreadLocal+AOP 实现;
-
主库负责增删改、从库负责查询,核心解决数据库读写性能瓶颈;
-
核心避坑:规避主从延迟、事务数据源固定、线程数据源污染三大问题;
-
简单场景自定义实现,复杂分布式场景优先使用Sharding-JDBC。
八、插件拦截器机制
1. 四大拦截目标(完整版·源码职责+拦截时机+实战场景)
MyBatis 插件拦截器基于责任链模式 实现,仅支持拦截四大核心核心组件,无法自定义拦截其他对象,四大组件覆盖 MyBatis 从参数封装→SQL执行→结果返回的全流程,是插件开发、数据脱敏、权限过滤、SQL优化的核心入口,也是面试高频考点。
1.1 ParameterHandler 参数处理器
-
核心职责 :负责SQL执行前的参数预处理、类型转换、参数赋值,将Java方法参数封装为JDBC可识别的参数格式
-
拦截时机:SQL预编译之后、参数赋值之前
-
可拦截核心方法:setParameters(),所有SQL参数赋值都会进入该方法
-
企业实战场景:字段自动填充(创建时间、修改时间、创建人、修改人)、参数脱敏、参数格式统一转换、空值参数预处理
-
核心特点:仅作用于SQL参数,不修改SQL语句与查询结果
1.2 StatementHandler 语句处理器(核心常用)
-
核心职责 :MyBatis SQL执行的核心中枢,负责SQL语句预处理、执行、超时控制、分页参数处理,贯穿SQL执行全流程
-
拦截时机:参数处理完成后、SQL执行前后,是唯一能修改原始SQL的拦截节点
-
可拦截核心方法:prepare()(SQL预编译)、parameterize()(参数绑定)、query()(查询执行)、update()(增删改执行)
-
企业实战场景:自动分页插件实现、数据权限SQL拼接、租户ID自动拼接、SQL日志打印、慢SQL监控、SQL防篡改校验
-
核心特点 :四大拦截中最常用、权限最高,可直接改写最终执行的SQL语句
1.3 ResultSetHandler 结果集处理器
-
核心职责 :负责SQL执行完成后,数据库结果集→Java实体对象的映射、封装、转换
-
拦截时机:SQL执行完毕、获取数据库结果集之后,实体封装返回之前
-
可拦截核心方法:handleResultSets()(处理查询结果集)、handleOutputParameters()(处理存储过程输出参数)
-
企业实战场景:查询结果自动脱敏(手机号、身份证、邮箱脱敏)、结果集字段统一转换、空数据兜底处理、枚举自动适配转换
-
核心特点:仅作用于查询返回结果,不影响SQL执行与参数赋值,增删改操作不会触发
1.4 Executor 执行器(顶层拦截)
-
核心职责:MyBatis顶层执行调度器,负责管控SQL执行、缓存调度、事务管理、批量操作调度,是四大组件的顶层入口
-
拦截时机 :所有SQL操作的最外层入口,早于StatementHandler执行,晚于会话创建
-
可拦截核心方法:query()(查询)、update()(增删改)、batch()(批量执行)、commit()/rollback()(事务提交回滚)、close()(会话关闭)
-
企业实战场景:二级缓存全局管控、SQL执行次数统计、事务监控、批量操作优化、全局SQL拦截日志
-
核心特点:拦截粒度最粗、优先级最高,管控所有数据库操作,可拦截事务、缓存、批量执行等全局行为
1.5 四大拦截器执行顺序(责任链机制)
执行前置顺序:Executor → StatementHandler → ParameterHandler
执行后置顺序:ResultSetHandler → StatementHandler → Executor
核心规则:先拦截的后执行、后拦截的先执行,多层插件遵循责任链嵌套执行逻辑
1.6 生产拦截选型规范(避坑重点)
-
修改SQL、分页、数据权限 → 优先拦截 StatementHandler
-
参数填充、参数预处理 → 优先拦截 ParameterHandler
-
结果脱敏、返回值处理 → 优先拦截 ResultSetHandler
-
全局缓存、事务、执行统计 → 优先拦截 Executor
1.7 面试满分考点
- 问:MyBatis四大拦截目标分别是什么?各自作用?
答:
-
ParameterHandler:拦截SQL参数赋值,实现参数预处理、自动填充;
-
StatementHandler:拦截SQL语句执行,支持改写SQL、分页、数据权限;
-
ResultSetHandler:拦截查询结果集,实现数据脱敏、结果转换;
-
Executor:顶层拦截,管控SQL执行、事务、缓存、批量操作。
- 问:想要实现自定义分页需要拦截哪个组件?为什么?
答:拦截StatementHandler,因为只有该组件能在SQL执行前改写原始SQL,拼接分页limit语句,实现物理分页。
- 问:四大拦截器的执行顺序是什么?
答:
前置执行:Executor > StatementHandler > ParameterHandler;
后置执行:ResultSetHandler > StatementHandler > Executor。
2. 插件核心注解使用(完整版·注解释义+标准写法+实战模板)
MyBatis插件拦截器的核心依托**@Intercepts + @Signature**双注解实现精准拦截,是自定义插件的唯一标准注解写法,可精准锁定需要拦截的组件、类、方法及参数,避免全局无效拦截,兼顾性能与精准度,所有自定义插件必须遵循该注解规范。
2.1 两大核心注解详解
2.1.1 @Intercepts 拦截器总注解
作用:标记当前类为MyBatis自定义拦截插件,声明该类具备拦截能力,是插件的核心标识注解。
核心属性:value,接收一组@Signature注解数组,可同时配置多个拦截规则,实现多方法、多组件批量拦截。
生效规则:仅被@Intercepts标记的类,才会被MyBatis插件容器扫描加载,普通类添加@Signature不生效。
2.1.2 @Signature 精准拦截签名注解
作用:精准定义拦截规则,锁定拦截的组件类型、拦截方法、方法参数,实现精细化拦截,杜绝无效拦截损耗性能。
三大必填核心属性:
-
type:指定拦截的四大核心组件类型,仅支持 Executor、StatementHandler、ParameterHandler、ResultSetHandler 四类,不可自定义其他类
-
method:指定对应组件内需要拦截的方法名,必须和源码方法名完全一致(大小写敏感)
-
args:指定拦截方法的参数类型Class数组,用于区分重载方法,精准匹配目标方法,避免重载方法拦截错乱
2.2 四大组件标准注解配置(全套可直接复用)
结合前文四大拦截目标,整理企业开发通用的标准注解写法,覆盖所有高频拦截场景,直接复制即可使用。
2.2.1 拦截 ParameterHandler 参数处理器
适用场景:参数自动填充、参数脱敏、参数格式转换,拦截参数赋值核心方法setParameters
java
@Intercepts({
@Signature(type = ParameterHandler.class,
method = "setParameters",
args = {PreparedStatement.class})
})
@Component
public class ParamFillInterceptor implements Interceptor {
// 拦截逻辑实现
}2.2.2 拦截 StatementHandler 语句处理器(最常用)
适用场景:分页、数据权限、租户SQL拼接、慢SQL监控,支持拦截SQL预编译、查询、更新方法
java
@Intercepts({
// 拦截SQL预编译方法
@Signature(type = StatementHandler.class, method = "prepare", args = {Connection.class, Integer.class}),
// 拦截查询执行方法
@Signature(type = StatementHandler.class, method = "query", args = {Statement.class, ResultHandler.class}),
// 拦截增删改执行方法
@Signature(type = StatementHandler.class, method = "update", args = {Statement.class})
})
@Component
public class SqlInterceptor implements Interceptor {
// 拦截逻辑实现
}2.2.3 拦截 ResultSetHandler 结果集处理器
适用场景:查询结果脱敏、枚举转换、结果集封装处理,仅拦截查询结果封装方法
java
@Intercepts({
@Signature(type = ResultSetHandler.class,
method = "handleResultSets",
args = {Statement.class})
})
@Component
public class DataDesensitizeInterceptor implements Interceptor {
// 拦截逻辑实现
}2.2.4 拦截 Executor 顶层执行器
适用场景:全局SQL统计、事务监控、缓存管控,拦截顶层增删改查、事务方法
java
@Intercepts({
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}),
@Signature(type = Executor.class, method = "update", args = {MappedStatement.class, Object.class}),
@Signature(type = Executor.class, method = "commit", args = {boolean.class})
})
@Component
public class SqlMonitorInterceptor implements Interceptor {
// 拦截逻辑实现
}2.3 完整插件注解+接口实现模板(企业标准)
MyBatis自定义插件必须实现 Interceptor 接口,重写三大核心方法,结合注解完成完整插件开发,以下为通用万能模板:
java
import org.apache.ibatis.executor.statement.StatementHandler;
import org.apache.ibatis.plugin.*;
import org.springframework.stereotype.Component;
import java.util.Properties;
/**
* 自定义MyBatis插件通用模板
* 示例:拦截SQL预编译,实现自定义SQL处理
*/
@Intercepts({
@Signature(type = StatementHandler.class, method = "prepare", args = {Connection.class, Integer.class})
})
@Component
public class CustomMybatisInterceptor implements Interceptor {
/**
* 核心拦截方法:目标方法执行前后触发,核心业务逻辑写在此处
*/
@Override
public Object intercept(Invocation invocation) throws Throwable {
// 目标方法执行前:自定义前置处理逻辑(如修改SQL、参数校验)
// 执行原目标方法
Object result = invocation.proceed();
// 目标方法执行后:自定义后置处理逻辑(如结果脱敏、日志打印)
return result;
}
/**
* 插件包装方法:生成代理对象,默认使用原生包装逻辑即可
*/
@Override
public Object plugin(Object target) {
// 仅对拦截目标对象生成代理,避免全局代理,提升性能
return Plugin.wrap(target, this);
}
/**
* 读取配置文件中插件自定义参数,初始化配置
*/
@Override
public void setProperties(Properties properties) {
// 可读取yml/xml中配置的插件参数,做初始化赋值
}
}2.4 SpringBoot环境插件生效配置
SpringBoot项目中,添加注解+实现接口后,无需手动注册插件,两种生效方式任选其一:
-
自动扫描(推荐):插件类添加 @Component 注解,被Spring容器扫描托管,自动加载生效
-
手动配置注册:通过MyBatis配置类手动注入插件,适合需要自定义优先级的场景
java
// 手动注册插件配置示例
@Bean
public MybatisPluginCustomizer mybatisPluginCustomizer(CustomMybatisInterceptor customInterceptor) {
return mybatisConfiguration -> mybatisConfiguration.addInterceptor(customInterceptor);
}2.5 注解使用高频坑点与避坑方案
- 坑点1:方法名/参数不匹配导致拦截失效
问题:@Signature中method方法名、args参数类型与源码不一致,大小写错误、参数顺序不对,导致拦截不生效。
方案:严格对照MyBatis源码方法签名,复制方法名与参数类型,杜绝手写出错。
- 坑点2:未限定args参数,拦截所有重载方法
问题:不配置args属性,会拦截组件所有同名重载方法,引发多余拦截、性能损耗、逻辑异常。 方案:必须精准配置args参数类型,锁定唯一目标方法。
- 坑点3:拦截非支持组件
问题:自定义type为非四大核心组件,插件加载失败、项目启动报错。
方案:仅支持Executor、StatementHandler、ParameterHandler、ResultSetHandler四类组件。
- 坑点4:重复拦截、插件冲突
问题:多个插件拦截同一方法,执行逻辑冲突、覆盖失效。
方案:通过插件执行顺序规范优先级,拆分不同拦截逻辑,避免重复拦截。
2.6 面试高频考点
- 问:MyBatis插件注解的作用是什么?核心注解有哪些?
答:用于标识自定义插件、精准定义拦截规则;核心注解为@Intercepts(标记插件)和@Signature(锁定拦截组件、方法、参数),是插件实现的核心。
- 问:@Signature注解三个属性的作用?为什么必须配置args?
答:type指定拦截组件、method指定拦截方法、args指定方法参数类型;args用于区分重载方法,精准定位唯一目标方法,避免无效拦截。
- 问:自定义插件为什么必须实现Interceptor接口?
答:MyBatis插件机制基于该接口规范实现,只有实现Interceptor并重写核心方法,配合注解才能被容器识别、生成代理对象、执行拦截逻辑。
核心总结
-
插件注解核心组合:@Intercepts + @Signature,缺一不可;
-
注解核心是精准匹配:组件类型+方法名+参数类型,杜绝模糊拦截;
-
配合Interceptor接口三大方法,可实现所有自定义插件业务场景;
-
SpringBoot环境添加@Component即可自动生效,无需复杂配置。
3. 插件完整执行顺序(责任链机制+优先级+多层插件实战)
MyBatis 自定义插件基于责任链模式 实现多层嵌套拦截,遵循 「先代理、后执行;先拦截、后收尾」 的核心规则,前置拦截与后置收尾执行顺序完全相反,是排查插件冲突、执行失效、逻辑覆盖问题的核心依据,也是面试高频考点。
3.1 单插件完整执行链路
一次SQL完整执行的插件拦截流程闭环:
插件前置拦截 → 目标核心方法执行 → 插件后置处理
具体细化链路:插件intercept()方法前置逻辑(参数预处理、SQL修改)→ invocation.proceed() 执行MyBatis原生核心方法 → 原生SQL执行、结果封装 → 回到intercept()方法后置逻辑(结果脱敏、日志统计、缓存处理)→ 最终返回结果
3.2 四大拦截器标准执行顺序(固定不变)
MyBatis 四大拦截组件存在固定的层级优先级,前置、后置执行顺序严格区分,所有插件均遵循该链路执行:
✅ 前置执行顺序(从外到内)
Executor(顶层执行器) > StatementHandler(语句处理器) > ParameterHandler(参数处理器)
✅ 后置执行顺序(从内到外)
ResultSetHandler(结果集处理器) > StatementHandler(语句处理器) > Executor(顶层执行器)
核心规则:优先级越高的组件,越先前置拦截、越晚后置收尾,形成嵌套执行闭环。
3.3 多插件叠加执行顺序(核心难点)
当项目存在多个自定义插件 (如分页插件、数据权限插件、脱敏插件、日志插件)时,执行顺序遵循:先加载的插件,前置优先执行,后置最后执行。
举例:同时开启「数据权限插件」「分页插件」「结果脱敏插件」
前置执行顺序:数据权限插件(修改SQL权限条件)→ 分页插件(拼接limit分页参数)→ 参数预处理插件
后置执行顺序:结果脱敏插件(处理返回数据)→ 分页插件后置统计 → 数据权限插件日志收尾
3.4 插件优先级控制规则
-
默认优先级:Spring容器默认加载顺序决定插件执行优先级,先注入的插件外层执行
-
手动指定优先级(推荐) :通过Spring @Order注解 控制插件优先级,数值越小,前置执行优先级越高
-
层级优先级:组件固有优先级优先于插件自定义优先级,Executor永远最外层拦截,ParameterHandler永远最内层前置拦截
3.5 生产插件执行顺序规范(避坑重点)
为避免插件逻辑覆盖、执行冲突,企业统一规范多层插件执行顺序:
-
第一层(最外层):全局监控插件(SQL日志、慢SQL统计、执行耗时监控)
-
第二层:数据权限、租户隔离插件(优先拼接SQL基础条件,保证所有查询生效)
-
第三层:分页插件(基于权限SQL二次拼接分页参数,避免分页失效)
-
第四层(最内层前置):参数自动填充、参数预处理插件
-
后置收尾层:结果脱敏、数据格式化插件(最后处理返回结果)
3.6 高频坑点与解决方案
-
坑点1:分页与数据权限插件顺序颠倒 问题:先分页、后拼接权限条件,导致分页统计总数、分页数据不准确 解决方案:权限插件优先级高于分页插件,先过滤数据、再分页
-
坑点2:后置插件顺序错乱导致脱敏失效 问题:日志插件后置优先执行,打印未脱敏原始数据,造成数据泄露 解决方案:脱敏插件优先后置执行,处理完数据后再打印日志
-
坑点3:多插件修改同一SQL相互覆盖 解决方案:统一插件修改粒度,权限、分页、排序插件分层修改,避免同一节点重复改写
3.7 面试满分标准答案
问:MyBatis多个插件同时存在,执行顺序是什么?如何控制插件优先级?
答: 1. 单层级组件执行顺序:前置 Executor > StatementHandler > ParameterHandler,后置 ResultSetHandler > StatementHandler > Executor;
-
多插件叠加遵循先加载先执行、后加载后执行,前置顺序与后置顺序相反;
-
可通过 @Order 注解手动指定插件优先级,数值越小优先级越高,同时遵循组件固有层级优先级;
-
生产需规范插件顺序:监控 > 数据权限 > 分页 > 参数填充 > 结果脱敏,规避插件冲突。
核心总结
-
插件执行核心:外层先拦截后收尾、内层后拦截先收尾;
-
四大组件执行顺序固定,不可更改;
-
多插件通过 @Order 管控优先级,适配生产多层插件场景;
-
合理的执行顺序是解决分页错乱、权限失效、数据脱敏异常的核心。
4. 企业实战场景
数据权限过滤、租户隔离、SQL 日志打印、数据脱敏、分表路由
九、核心源码架构
1. 完整执行流程
MyBatis 完整执行流程分为项目启动初始化阶段 (仅执行一次)和业务请求执行阶段(每次数据库请求都会执行),全链路贴合底层源码,细化核心类、执行动作、关键节点,是源码阅读、面试、生产问题排查的核心依据,完整闭环流程如下:
一、启动初始化阶段(全局一次性加载)
该阶段在项目启动时执行一次,完成所有配置加载、资源初始化、Mapper注册,生成全局单例核心对象,全程只加载不执行SQL。
1.加载配置文件
通过Resources工具类读取mybatis-config.xml全局配置、SpringBoot yml配置、所有Mapper XML映射文件,解析文件头部DTD/XSD约束,校验配置文件合法性。
2.创建解析器,构建Configuration全局容器
通过XMLConfigBuilder解析全局配置,通过XMLMapperBuilder解析所有Mapper映射配置,将环境参数、数据源、插件、别名、SQL节点、映射规则等所有配置,统一封装为Configuration全局唯一对象,完成所有配置的内存加载。
3.解析SQL语句,生成MappedStatement
遍历所有Mapper XML/注解SQL,解析动态SQL节点(IfSqlNode、WhereSqlNode、ForEachSqlNode等)、静态SQL,将每一条SQL语句、参数映射、结果集映射、缓存规则、超时配置等信息,封装为MappedStatement对象,注册到Configuration的Map集合中,全局缓存复用。
4.构建SqlSessionFactory会话工厂
通过SqlSessionFactoryBuilder读取完整的Configuration配置,构建全局单例SqlSessionFactory,固定数据源、事务规则、插件链、执行器规则,作为后续所有数据库会话的创建工厂。
5.Spring环境额外初始化
SpringBoot项目通过MapperScannerConfigurer扫描指定包下的Mapper接口,通过动态代理预生成Mapper代理工厂,注入Spring容器,完成接口与XML SQL的绑定注册。
二、业务请求执行阶段(单次请求闭环)
用户发起数据库请求时触发,从获取会话、代理调用、SQL解析、参数绑定、执行查询、结果映射到资源释放,完成一次完整数据库操作,全程线程隔离。
1.获取SqlSession数据库会话
通过SqlSessionFactory的openSession()方法创建会话:根据配置创建对应类型的Executor执行器(Simple/Reuse/Batch),初始化一级缓存容器、事务管理器、数据库连接信息,生成线程级独享SqlSession (非线程安全,单次请求有效)。 Spring环境由SqlSessionTemplate自动托管,从线程池获取会话,无需手动创建。
2.获取Mapper动态代理对象
SqlSession通过getMapper()方法,调用MapperProxyFactory生成JDK动态代理对象,绑定当前SqlSession和对应的MappedStatement,开发者调用Mapper接口方法本质是触发代理拦截逻辑。
3.代理拦截,定位目标SQL
触发MapperProxy.invoke()拦截方法,根据接口全类名+方法名,从Configuration容器中精准匹配对应的MappedStatement,获取预解析的SQL模板、映射规则、执行参数。
4.解析动态SQL,生成可执行语句
通过SqlSource解析SQL:静态SQL直接复用,动态SQL通过DynamicSqlSource结合OGNL表达式,根据传入参数判断拼接SQL节点(if、where、foreach等),去除冗余关键字,生成最终完整可执行SQL语句。
5.插件前置拦截(四层责任链)
按照执行优先级触发插件拦截链:Executor → StatementHandler → ParameterHandler,执行自定义插件前置逻辑(SQL修改、权限拼接、参数填充、日志统计等)。
6.创建StatementHandler,预编译SQL
Executor执行器创建StatementHandler(默认PreparedStatementHandler),获取数据库Connection连接,完成SQL预编译,固定SQL结构,杜绝SQL注入风险。
7.参数绑定与赋值
通过ParameterHandler处理器,解析方法入参(基本类型、实体、Map、集合),匹配SQL中#{} 占位符,完成参数类型转换、赋值,填充到预编译SQL中。
8.执行SQL语句
根据操作类型执行对应逻辑:查询调用query()方法、增删改调用update()方法,通过JDBC底层向数据库提交SQL,执行数据库操作。
9.事务管控
原生环境:根据openSession参数判断自动/手动提交,执行成功commit、异常rollback; Spring环境:AOP拦截事务注解,自动完成事务提交与回滚。
10.结果集封装映射
SQL执行完毕后,通过ResultSetHandler处理器,结合全局驼峰映射、自定义ResultMap规则,将数据库ResultSet原始结果集,自动封装为Java实体、List、Map等指定返回类型,同时触发结果集插件后置拦截(数据脱敏、字段格式化等)。
11.缓存更新与失效
查询操作:优先查询一级缓存,无缓存则查询数据库并写入一级缓存;开启二级缓存则同步更新二级缓存;
增删改操作:自动清空当前命名空间的一级、二级缓存,保证数据一致性。
12.资源释放,会话关闭
原生环境:手动调用close()关闭SqlSession,释放数据库连接、清空一级缓存、结束事务; Spring环境:方法执行完毕后自动关闭会话,归还连接至连接池,线程销毁清空ThreadLocal数据源标识,杜绝资源泄露。
三、全流程核心总结(面试极简版)
启动流程 :加载配置 → 解析XML/注解 → 封装Configuration → 注册MappedStatement → 构建SqlSessionFactory 执行流程:获取SqlSession → Mapper代理拦截 → 解析动态SQL → 插件拦截 → SQL预编译+参数赋值 → JDBC执行SQL → 结果集映射封装 → 缓存处理 → 事务提交 → 资源释放
四、核心链路关键特性
-
启动一次性加载所有配置与SQL模板,运行时仅做动态解析与执行,大幅提升请求性能;
-
全程插件责任链贯穿,支持无侵入扩展SQL处理逻辑;
-
缓存机制全程联动,兼顾性能与数据一致性;
-
Spring环境全自动托管生命周期,规避线程安全与资源泄露问题。
2. 四类执行器(完整版·源码原理+特性对比+实战场景+避坑面试)
MyBatis 底层通过Executor执行器 管控所有SQL执行、缓存调度、事务管理、连接复用逻辑,是MyBatis数据库操作的顶层调度核心。框架内置四类执行器:SimpleExecutor、ReuseExecutor、BatchExecutor、ClosedExecutor,四类执行器特性、底层机制、适用场景完全不同,可通过配置文件指定切换,也是生产调优、面试高频核心考点。
2.1 执行器核心概述
所有执行器均实现 Executor 顶层接口,统一封装SQL执行流程,核心差异集中在Statement语句复用、批量提交机制、缓存策略、资源复用规则 四大维度。项目默认使用 SimpleExecutor ,可通过全局配置 default-executor-type 切换执行器类型。
2.2 SimpleExecutor 简单执行器(默认执行器)
(1)核心原理
MyBatis默认执行器 ,每次执行SQL语句,都会新建一个PreparedStatement,SQL执行完毕后立即关闭Statement、释放语句资源,不做任何语句缓存与复用。
(2)核心特性
-
无Statement缓存,每条SQL独立创建、独立销毁
-
执行逻辑简单、无额外缓存开销、不易出现资源堆积问题
-
天然适配单条SQL独立执行场景,无数据错乱风险
(3)适用场景
日常绝大多数业务场景:单条查询、单条增删改、零散SQL操作,是企业项目默认使用的执行器。
(4)优缺点
-
优点:轻量稳定、无资源复用冲突、无需手动清理资源、兼容性极强
-
缺点:频繁执行同类SQL时,会重复创建预编译语句,存在少量性能损耗,不适合高频批量操作
(5)生产坑点
高并发、高频重复SQL场景下,频繁创建销毁Statement会增加JVM与数据库开销,建议切换为ReuseExecutor优化性能。
2.3 ReuseExecutor 可复用执行器
(1)核心原理
基于Statement语句缓存复用 实现,在当前SqlSession会话内,通过Map集合缓存已预编译的PreparedStatement对象,相同SQL语句直接复用已有Statement,无需重复预编译,会话关闭后统一清空缓存、释放资源。
(2)核心特性
-
会话级Statement缓存,key为SQL语句、value为预编译Statement对象
-
仅复用完全一致的SQL语句,动态参数不同不影响复用
-
大幅减少SQL预编译次数,降低数据库IO开销,提升执行效率
(3)适用场景
高频重复执行的SQL场景:循环查询、批量同结构查询、高频单表条件查询等。
(4)优缺点
-
优点:规避重复预编译开销,大幅提升重复SQL执行性能
-
缺点 :会话内会缓存大量Statement对象,长期不关闭会话会造成内存占用升高;不同参数的同SQL无法做到语句隔离,极端场景存在数据缓存错乱风险
(5)生产坑点
禁止在超长事务、长连接会话中使用,会导致大量Statement对象堆积内存,引发内存溢出;会话必须及时关闭,保证缓存资源释放。
2.4 BatchExecutor 批量执行器(高性能专属)
(1)核心原理
MyBatis专属批量优化执行器 ,核心逻辑为SQL预编译缓存+累积批量提交。执行增删改SQL时,不会立即提交数据库,而是将多条SQL语句累积缓存,等待手动commit或批量阈值触发后,统一批量提交执行,极大减少数据库网络交互次数。
(2)核心特性
-
仅对增删改操作生效,查询操作依然单条执行
-
缓存同结构SQL的预编译Statement,批量赋值、统一提交
-
大幅减少TCP网络交互、数据库事务提交次数,批量性能提升显著
-
会话内统一事务管理,批量操作要么全部成功、要么全部回滚
(3)适用场景
大批量数据处理场景:数据导入、批量新增、批量修改、数据迁移、定时任务批量更新等。
(4)优缺点
-
优点:批量操作性能天花板,极致减少数据库IO交互,适配大数据量场景
-
缺点:
-
1、批量模式下主键回填失效,无法直接获取新增数据主键ID;
-
2、SQL异常无法精准定位单条错误语句,仅能整体回滚;
-
3、缓存大量SQL语句,内存占用较高;
-
4、事务耗时变长,容易触发数据库事务超时。
(5)生产强制规范
-
批量执行完毕必须手动commit提交,否则数据永久不入库
-
大批量数据需拆分批次(单次1000-5000条),避免单次批量数据过大导致数据库卡死
-
批量操作禁止嵌套查询、复杂业务逻辑,缩短事务时长
2.5 ClosedExecutor 关闭执行器(兜底异常执行器)
(1)核心原理
MyBatis内置的异常兜底执行器,无实际执行能力,仅用于会话关闭后的状态标记。当SqlSession会话关闭、资源释放完毕后,执行器会被强制切换为ClosedExecutor,所有SQL执行操作都会直接抛出异常,防止会话关闭后重复执行数据库操作。
(2)核心特性
-
无SQL执行、无缓存、无事务能力
-
唯一作用:拦截已关闭会话的非法SQL调用,抛出异常提示会话已失效
-
属于被动触发执行器,开发者无法手动配置使用
(3)触发场景
SqlSession已执行close()关闭操作后,再次调用Mapper方法执行SQL,自动触发ClosedExecutor,抛出异常。
(4)生产意义
从底层杜绝会话关闭后的资源滥用、无效SQL执行,防止数据库连接泄露、无效请求堆积,起到底层防护作用。
2.6 四类执行器核心对比表(企业速查版)
| 执行器类型 | 语句复用 | 批量提交 | 性能特点 | 适用场景 | 默认状态 |
|---|---|---|---|---|---|
| SimpleExecutor | 不复用 | 不支持 | 稳定通用、小幅性能损耗 | 日常单条CRUD普通业务 | 默认开启 |
| ReuseExecutor | 会话内复用 | 不支持 | 高频SQL性能优异 | 重复SQL、循环查询场景 | 手动配置 |
| BatchExecutor | 会话内复用 | 支持批量提交 | 大批量操作性能极强 | 数据批量新增、修改、迁移 | 手动配置 |
| ClosedExecutor | 无 | 无 | 无执行能力 | 会话关闭后兜底防护 | 被动触发 |
3. 动态代理原理(完整版·底层源码+执行流程+面试满分解析+坑点)
MyBatis 核心核心特性:仅定义Mapper接口,无需手写实现类 ,所有Mapper接口方法调用,全部依托JDK动态代理机制生成代理对象,拦截接口方法并完成SQL执行,是MyBatis实现代码解耦、无侵入调用的核心底层原理,也是面试必考高频知识点。
3.1 核心前置认知
-
核心前提:MyBatis Mapper接口仅用于定义数据库操作方法,无实现类、无业务逻辑,属于纯声明式接口。
-
代理方式 :默认使用JDK动态代理(要求Mapper必须是接口),不使用CGLIB代理。
-
核心作用:拦截Mapper接口的所有方法调用,替代开发者手动执行SqlSession的增删改查方法,实现「接口调用即执行SQL」的效果。
-
核心优势:完全解耦,屏蔽SqlSession、SQL解析、参数绑定、结果映射等底层细节,大幅简化业务代码。
3.2 核心核心类(源码必知)
MyBatis动态代理体系由三大核心类组成,层层协作完成代理生成与方法拦截:
-
MapperProxyFactory :Mapper代理工厂,负责生成Mapper代理实例,每个Mapper接口对应一个独立的代理工厂,全局缓存复用。
-
MapperProxy :核心拦截器,实现JDK InvocationHandler接口,重写invoke方法,拦截所有Mapper接口方法调用,是动态代理的核心逻辑载体。
-
MapperMethod:方法封装工具类,解析Mapper接口方法的注解、SQL标识、参数类型、返回值类型,封装方法执行的所有元数据,实现方法与MappedStatement的绑定。
3.3 完整底层执行流程(启动+调用双阶段)
阶段一:项目启动------代理工厂初始化(一次性执行)
-
SpringBoot项目启动时,通过
@MapperScan扫描指定包下所有Mapper接口; -
MyBatis为每个Mapper接口创建专属的MapperProxyFactory代理工厂,注册到容器;
-
解析每个接口方法,匹配对应的MappedStatement(预编译的SQL配置信息),建立「接口方法+SQL语句」的映射关系;
-
Spring容器通过代理工厂生成Mapper代理对象,注入业务层,完成初始化。
阶段二:业务调用------代理方法拦截执行(每次数据库请求执行)
-
触发代理拦截 :业务代码中调用mapper.xxx()接口方法时,并非执行原生接口逻辑(接口无实现),而是触发
MapperProxy.invoke()拦截方法; -
方法类型判断:拦截后优先判断方法类型: 如果是Object通用方法(equals、hashCode、toString):直接原生执行,不走SQL逻辑;
-
如果是数据库操作方法:进入MyBatis自定义执行逻辑;
-
封装MapperMethod :根据当前调用的接口全类名+方法名,匹配预加载的MappedStatement,封装为MapperMethod对象,包含SQL类型、参数规则、返回值规则;
-
获取线程级SqlSession:从当前线程中获取绑定的SqlSession(Spring环境自动托管,原生环境手动获取);
-
执行SQL操作:MapperMethod根据SQL类型(SELECT/INSERT/UPDATE/DELETE),调用SqlSession对应的增删改查方法;
-
参数绑定与SQL执行:完成参数解析、预编译、SQL执行、事务管控;
-
结果集封装返回:将数据库结果集映射为Java实体、集合、基本类型,返回给业务层;
-
资源回收:Spring环境自动关闭SqlSession、释放连接,完成一次代理调用闭环。
3.4 核心源码关键逻辑(精简可背诵)
核心拦截方法 MapperProxy.invoke() 核心逻辑:
java
// 核心拦截逻辑伪代码
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 1. 过滤Object原生方法,无需执行SQL
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
}
// 2. 缓存MapperMethod,避免重复解析方法
MapperMethod mapperMethod = cachedMapperMethod(method);
// 3. 执行SQL并返回结果
return mapperMethod.execute(sqlSession, args);
}3.5 JDK动态代理核心限制与适配规则
-
强制接口限制:JDK动态代理仅支持代理接口,这也是MyBatis Mapper必须定义为接口、不能用抽象类的核心底层原因;
-
无状态代理 :生成的代理对象无任何成员变量、无状态,因此天然线程安全,可全局注入复用;
-
精准匹配机制:通过「类全限定名+方法名+参数」唯一匹配MappedStatement,杜绝多方法、重载方法绑定错乱;
3.6 生产核心坑点与解决方案
- 坑点1:Mapper重载方法绑定失效
问题:Mapper接口定义重载方法,无差异化注解/配置,导致代理无法精准匹配SQL,执行报错。 解决方案:MyBatis不推荐Mapper方法重载,如需重载,必须通过@Param区分参数、或单独配置SQL节点。
- 坑点2:非Mapper方法被拦截
问题:自定义Mapper通用方法(非数据库操作)被代理拦截,执行异常。
解决方案:通用工具方法提取至单独工具类,不定义在Mapper接口中。
- 坑点3:代理对象注入失败
问题:未添加@MapperScan或@Mapper注解,容器无法生成代理对象,报注入异常。
解决方案:项目启动类配置包扫描,所有Mapper接口添加标识注解。
3.7 面试满分标准答案(高频必背)
问:MyBatis Mapper接口为什么不需要实现类?底层原理是什么?
答: 1. MyBatis基于JDK动态代理实现Mapper接口无实现类调用,核心类为MapperProxyFactory、MapperProxy、MapperMethod;
-
项目启动时,框架扫描所有Mapper接口,为每个接口生成代理工厂,预解析接口方法与对应SQL的映射关系;
-
业务调用Mapper接口方法时,触发MapperProxy的invoke()方法拦截,拦截后匹配预加载的MappedStatement,通过SqlSession执行对应SQL;
-
全程无需手动编写实现类,底层通过动态代理自动完成方法拦截、SQL执行、结果封装,实现接口与SQL的解耦。
问:MyBatis的Mapper代理对象是线程安全的吗?为什么?
答:线程安全 。Mapper代理对象是JDK动态代理生成的无状态对象,无全局可变成员变量;每次方法调用都会从当前线程获取独立的SqlSession,线程之间数据完全隔离,因此支持全局注入、多线程并发调用。
3.8 核心总结
-
底层依托 JDK动态代理,核心拦截类为 MapperProxy;
-
启动绑定方法与SQL,运行拦截方法调用、自动执行数据库操作;
-
代理对象无状态、线程安全,是Spring全局注入的核心前提;
-
彻底屏蔽底层JDBC与SqlSession操作,实现极致代码解耦。
总结:
JDK 动态代理生成 Mapper 代理类,拦截接口方法执行 SQL
4. SQL 节点解析(完整版·源码原理+节点分类+动态解析流程+面试必背)
SQL节点解析是MyBatis实现动态SQL 的核心底层机制,框架不再将XML中的SQL语句作为普通字符串处理,而是通过树形节点结构拆分、解析、拼接SQL片段,结合OGNL表达式动态生成可执行SQL。所有动态标签(if、where、foreach、choose等)、静态SQL文本,都会被解析为不同的SqlNode节点,最终组装为完整SQL语句,是动态SQL生效的底层核心,也是源码阅读、面试高频考点。
4.1 核心顶层接口:SqlNode
MyBatis所有SQL节点的顶层父接口,核心定义了SQL节点的统一解析行为,所有静态、动态SQL节点均实现该接口。
(1)核心源码方法
java
// 核心解析方法:根据传入参数环境,拼接当前节点的SQL片段
boolean apply(DynamicContext context);(2)核心作用:每个SqlNode节点独立实现apply方法,根据运行时参数判断是否生效、拼接对应SQL片段,最终所有节点拼接为完整可执行SQL。
(3)核心参数DynamicContext:动态SQL上下文容器,存储SQL拼接结果、参数映射、OGNL表达式运行环境,全程累积拼接SQL文本,自动处理空格、冗余关键字。
4.2 全部SQL节点分类(全覆盖·对应标签+作用)
MyBatis将XML中所有SQL内容精准拆解为7类核心SqlNode,分为静态节点 和动态节点,覆盖所有原生SQL语法,各司其职完成解析:
4.2.1 静态SQL节点(StaticTextSqlNode)
-
对应场景:XML中固定不变的SQL文本(无任何动态标签、无OGNL表达式)
-
核心特性:项目启动时直接加载固定SQL文本,运行时无需判断、直接拼接,性能极高
-
示例 :
SELECT id,user_name FROM user固定查询语句 -
解析规则:启动阶段一次性解析缓存,运行时直接复用,无计算开销
4.2.2 混合节点(MixedSqlNode)
-
对应场景:一条SQL中同时包含静态文本+多个动态标签的混合结构
-
核心特性 :容器型节点,不负责具体解析,仅用于有序收纳多个子SqlNode(静态节点、各类动态节点)
-
执行逻辑:遍历所有子节点,按顺序执行apply方法,逐层拼接SQL片段
-
地位:绝大多数复杂动态SQL的顶层节点,是SQL树形结构的核心载体
4.2.3 条件判断节点(IfSqlNode)
-
对应标签:<if test="">
-
核心作用:基于OGNL表达式判断条件是否成立,成立则拼接内部SQL片段,不成立则跳过
-
解析规则:运行时读取入参,解析test属性的OGNL表达式,动态判断节点是否生效
-
示例:根据用户传入参数是否非空,动态拼接查询条件
4.2.4 多分支选择节点(ChooseSqlNode、WhenSqlNode、OtherwiseSqlNode)
-
对应标签:<choose>、<when>、<otherwise>
-
核心作用:实现多分支互斥判断,等价于Java的switch-case逻辑
-
执行规则:自上而下匹配when条件,命中第一个成立条件即终止匹配;所有条件不成立则执行otherwise节点
4.2.5 循环遍历节点(ForEachSqlNode)
-
对应标签:<foreach>
-
核心作用:遍历集合、数组参数,动态拼接批量查询、批量插入SQL片段
-
核心属性解析:collection(遍历集合)、item(单元素)、separator(分隔符)、open/close(首尾包裹字符)
-
底层逻辑:运行时动态遍历参数集合,循环生成SQL片段,自动拼接分隔符,规避手动拼接的语法错误
4.2.6 关键字修剪节点(TrimSqlNode、WhereSqlNode、SetSqlNode)
-
对应标签:<trim>、<where>、<set>
-
核心作用:自动修剪SQL冗余关键字,解决动态条件拼接的语法报错问题
-
细分特性: WhereSqlNode:自动去除首个前置多余的AND/OR,无条件时不拼接WHERE关键字
-
SetSqlNode:自动去除末尾多余的逗号,适配动态字段更新
-
TrimSqlNode:通用修剪节点,可自定义前后缀去除字符,适配所有特殊场景
4.2.7 文本替换节点(TextSqlNode)
-
对应场景 :包含 ${} 字符串直接替换的SQL片段
-
核心特性:运行时直接替换参数文本,无预编译,存在SQL注入风险
-
区别:区别于静态节点,属于动态替换节点,参数可变;区别于#{}预编译,直接字符串拼接
4.3 SqlSource 核心分类(静态VS动态SQL本质区别)
MyBatis解析完所有SqlNode节点后,会统一封装为SqlSource对象,分为两类,是区分静态、动态SQL的核心标识,直接决定SQL的编译时机:
4.3.1 StaticSqlSource(静态SQL源)
-
适用场景:无任何动态标签、无${}占位符的纯固定SQL
-
编译时机 :项目启动时一次性预编译,运行时直接执行,无需二次解析
-
性能优势:无运行时解析开销,执行效率最高
-
示例:固定单条件查询、无参数固定SQL
4.3.2 DynamicSqlSource(动态SQL源)
-
适用场景:包含if/where/foreach等动态标签、${}占位符的SQL
-
编译时机 :每次请求运行时动态解析,根据入参实时拼接、生成最终SQL
-
核心依赖:依托各类SqlNode节点的树形解析能力,结合OGNL表达式动态渲染
-
特点:灵活适配多条件动态查询,存在微量运行时解析开销
4.3.3 混合补充:RawSqlSource
- 适配注解式固定SQL,无动态逻辑,启动预编译,性能同StaticSqlSource
4.4 完整SQL节点解析执行流程(启动+运行双阶段)
阶段一:项目启动初始化(静态解析)
-
MyBatis加载Mapper XML文件,通过XMLMapperBuilder逐行解析SQL标签;
-
根据标签类型、文本内容,自动匹配创建对应SqlNode节点,组装为MixedSqlNode树形结构;
-
判断是否包含动态节点,封装为DynamicSqlSource或StaticSqlSource;
-
将SqlSource注册到MappedStatement,全局缓存备用。
阶段二:业务请求运行(动态渲染)
-
接收业务入参,创建DynamicContext动态上下文容器;
-
从MappedStatement获取SqlSource,遍历顶层MixedSqlNode的所有子节点;
-
依次执行每个SqlNode的apply()方法:动态节点解析OGNL表达式判断生效、静态节点直接拼接文本;
-
通过Trim/Where/Set节点自动修剪冗余关键字,修正SQL语法;
-
上下文累积生成完整可执行SQL,完成预编译与参数绑定;
-
最终交由StatementHandler执行SQL。
4.5 OGNL表达式核心作用
动态SqlNode(If/When)的条件判断完全依托**OGNL(对象图导航语言)**实现,是动态SQL条件生效的核心支撑:
-
支持参数非空判断、属性取值、逻辑运算、比较运算;
-
支持嵌套对象、集合参数取值,适配复杂参数场景;
-
运行时解析test表达式,动态判定节点是否拼接;
-
OGNL表达式仅用于条件判断,不参与SQL参数赋值,参数赋值统一使用#{}预编译。
4.6 生产高频坑点与解决方案
- 坑点1:动态拼接多余AND/OR导致SQL语法报错
问题:多个if标签嵌套,首个条件不生效,残留前置AND/OR关键字。
解决方案:必须使用<where>标签包裹动态if节点,自动修剪冗余关键字。
- 坑点2:foreach批量拼接逗号冗余
问题:手动拼接集合参数,首尾出现多余逗号。
解决方案:使用foreach自带separator分隔符,框架自动处理拼接规则,无冗余字符。
- 坑点3:OGNL表达式语法错误导致动态节点失效
问题:test表达式大小写错误、空格缺失、属性名写错,条件永久不生效。
解决方案:严格遵循OGNL语法,参数属性与实体一致,禁止手写语法错误。
- 坑点4:混淆#{}与${}导致注入风险
问题:动态节点中滥用${}字符串替换,引发SQL注入。
解决方案:动态条件参数统一使用#{}预编译,仅排序、表名动态场景少量使用${}。
4.7 面试满分核心考点
- 问:MyBatis动态SQL的底层原理是什么?
答:MyBatis通过SqlNode树形节点机制实现动态SQL,将SQL拆分为静态文本、if、foreach、where等独立节点;启动时组装节点树,运行时通过DynamicContext上下文,结合OGNL表达式动态判断节点是否生效,逐层拼接、修剪SQL,最终生成完整可执行语句。
- 问:StaticSqlSource和DynamicSqlSource的区别?
答:1. 静态SQL无动态标签,启动预编译,运行直接执行,性能更高;
-
动态SQL包含动态节点,运行时实时解析渲染,灵活性强;
-
静态SQL不走动态节点判断逻辑,动态SQL依赖SqlNode+OGNL动态解析。
- 问:WhereSqlNode的核心作用是什么?如何解决动态条件语法问题?
答:自动识别动态条件,无查询条件时不生成WHERE关键字,有条件时自动去除首个多余的AND/OR,彻底规避动态拼接导致的SQL语法错误。
核心总结
-
动态SQL核心根基:SqlNode树形节点 + OGNL表达式动态判断;
-
所有动态标签均对应专属SqlNode,各司其职、分层解析;
-
静态SQL启动预编译,动态SQL运行实时渲染;
-
修剪类节点自动修正SQL语法,是动态SQL无报错的关键。
总结:
SqlSource 区分静态 / 动态 SQL;IfSqlNode、MixedSqlNode 节点树解析
5. 扩展工厂(ObjectFactory 完整版·原理+自定义实战+配置+坑点面试)
ObjectFactory(对象工厂)是MyBatis核心扩展组件,负责所有Java实体对象、集合对象的实例化创建,是MyBatis结果集映射、参数封装的底层对象创建入口。默认提供通用对象创建能力,支持开发者自定义扩展,实现对象初始化拦截、属性默认赋值、统一初始化逻辑,是MyBatis无侵入拓展实体能力的核心,属于进阶源码与生产定制化高频考点。
5.1 核心基础认知
-
核心作用:统一创建MyBatis操作过程中所有需要实例化的对象,包含自定义POJO实体、List/Map/Set等集合对象、自定义返回对象。
-
默认实现:DefaultObjectFactory,MyBatis内置默认工厂,通过反射调用类无参构造方法实例化对象,满足绝大多数常规开发场景。
-
执行时机:SQL执行完毕、结果集映射封装阶段,框架需要实例化实体对象时触发;参数绑定需要创建集合/实体对象时也会触发。
-
扩展价值:无需修改业务代码、无需改动SQL,全局拦截所有实体创建过程,实现统一初始化逻辑,解耦通用实体初始化代码。
5.2 核心底层原理
MyBatis所有对象创建均通过ObjectFactory统一调度,核心执行链路:
结果集映射阶段 → 判定目标对象类型 → 调用ObjectFactory.createObject() → 反射实例化对象 → 完成属性赋值 → 返回封装实体
默认工厂核心规则:
-
优先调用无参构造方法实例化实体,因此MyBatis实体类必须保留无参构造,否则实例化报错;
-
自动适配常用集合类型:List、ArrayList、Map、HashMap、Set、HashSet等;
-
仅负责对象创建,不参与属性赋值、映射逻辑,职责单一纯粹。
5.3 自定义ObjectFactory实战开发(企业标准实现)
自定义对象工厂可实现实体默认值初始化、创建日志记录、统一字段赋值、对象全局拦截等通用能力,以下是可直接落地的完整实现。
步骤1:自定义工厂类,继承DefaultObjectFactory
java
import org.apache.ibatis.reflection.factory.DefaultObjectFactory;
import java.util.Date;
/**
* 自定义MyBatis对象工厂
* 全局拦截所有实体对象创建,完成统一初始化
*/
public class CustomObjectFactory extends DefaultObjectFactory {
/**
* 重写对象创建方法
* @param type 目标对象类型
* @return 实例化后的对象
* @param <T> 泛型
*/
@Override
public <T> T create(Class<T> type) {
// 调用父类方法,通过反射创建原生对象
T obj = super.create(type);
// 自定义全局初始化逻辑:统一填充创建时间、默认状态等通用字段
if (obj instanceof BaseEntity) {
BaseEntity baseEntity = (BaseEntity) obj;
// 新建实体默认填充创建时间
baseEntity.setCreateTime(new Date());
// 默认状态为正常
baseEntity.setStatus(1);
}
return obj;
}
}步骤2:全局配置注入自定义工厂(mybatis-config.xml)
XML
<configuration>
<!-- 注册自定义对象工厂 -->
<objectFactory type="com.example.config.CustomObjectFactory">
<!-- 可配置自定义参数,工厂内可读取 -->
<property name="enableInit" value="true"/>
</objectFactory>
</configuration>步骤3:SpringBoot yml配置方式(主流)
XML
mybatis:
configuration:
# 配置自定义对象工厂全类名
object-factory: com.example.config.CustomObjectFactory5.4 企业核心实战场景
-
实体通用字段统一初始化:所有实体自动填充创建时间、更新时间、默认状态、删除标记,无需业务手动set,减少重复代码;
-
对象创建日志监控:拦截所有实体创建行为,记录对象类型、创建时机,用于数据溯源、异常排查;
-
默认值统一管控:枚举默认值、数值默认零值、字符串默认空值,规避空指针异常;
-
自定义对象适配:对特殊业务实体做差异化初始化,统一业务规范。
5.5 生产高频坑点与解决方案
-
坑点1:实体无无参构造,对象创建失败 问题:自定义实体仅定义有参构造,无默认无参构造,默认工厂反射实例化报错 解决方案:所有MyBatis实体必须保留无参构造(显式/隐式),是对象创建的基础前提
-
坑点2:自定义工厂覆盖原生逻辑导致异常 问题:重写create方法未调用父类方法,导致对象无法正常实例化 解决方案:自定义逻辑基于父类创建的对象拓展,禁止完全重写覆盖原生创建逻辑
-
坑点3:初始化逻辑过重影响性能 问题:工厂内添加大量耗时逻辑、IO操作,频繁创建对象导致接口卡顿 解决方案:工厂仅做轻量初始化赋值,禁止复杂业务、耗时操作
-
坑点4:Spring环境配置不生效 问题:同时配置yml工厂与xml工厂,出现配置覆盖 解决方案:统一使用yml配置,遵循MyBatis配置优先级规则
5.6 面试高频考点(满分答案)
问:ObjectFactory的作用是什么?如何自定义扩展?应用场景有哪些?
答: 1. ObjectFactory是MyBatis的对象工厂,核心负责所有实体、集合对象的反射实例化创建,默认由DefaultObjectFactory实现,依托无参构造创建对象;
-
自定义扩展方式:继承DefaultObjectFactory重写create方法,自定义对象初始化逻辑,通过全局配置注册自定义工厂,全局生效;
-
核心应用场景:统一实体通用字段初始化、默认值填充、对象创建监控,实现业务代码解耦,简化重复初始化逻辑;
-
核心注意点:实体必须保留无参构造,工厂仅做轻量拓展,禁止复杂耗时逻辑。
5.7 核心总结
-
ObjectFactory 是MyBatis对象实例化的唯一入口,掌控所有实体创建逻辑;
-
默认通过无参构造反射创建对象,实体无参构造是必备条件;
-
自定义工厂可实现全局实体初始化,是轻量化无侵入拓展的最佳方案;
-
生产多用于通用字段自动赋值,大幅简化业务代码。
6. 命名空间绑定(完整版·绑定规则+原理+规范+报错坑点+面试)
命名空间(namespace)是 MyBatis 绑定 Mapper 接口与 XML 映射文件的唯一核心标识,是实现接口方法与 SQL 语句精准匹配、动态代理正常执行的基础,所有 Mapper 绑定报错、方法找不到、SQL 不生效问题,90% 源于命名空间绑定不规范,属于开发必备、面试高频核心知识点。
6.1 核心绑定原理
MyBatis 依托 namespace 全限定类名精准绑定机制 实现接口与 XML 双向绑定:项目启动时,框架解析所有 Mapper XML 文件,读取根标签 mapper 的 namespace 属性,将该属性值与项目中扫描到的 Mapper 接口全类名(包名+类名)做精准匹配,匹配成功则完成绑定,建立「Mapper接口方法 <=> XML SQL节点」的唯一映射关系。
核心绑定逻辑:XML namespace = Mapper接口全限定类名,绑定成功后,接口中每一个方法名,精准对应 XML 中相同 id 的 SQL 标签(select/insert/update/delete)。
6.2 标准绑定规范(企业强制标准)
6.2.1 XML文件命名空间规范
Mapper.xml 根节点 mapper 必须配置 namespace 属性,值为对应 Mapper 接口的完整全类名,大小写、包路径必须完全一致,不可简写、错写、漏写。
正确示例:
XML
<!-- 对应接口:com.example.mapper.UserMapper -->
<mapper namespace="com.example.mapper.UserMapper">
<!-- 方法名与标签id完全一致 -->
<select id="selectUserById" resultType="User">
SELECT id,user_name,age FROM user WHERE id = #{id}
</select>
</mapper>6.2.2 方法绑定规范
-
XML 中 SQL 标签的 id 属性 必须与 Mapper 接口中的抽象方法名完全一致(大小写敏感);
-
接口方法重载场景下,需结合参数类型区分,保证「namespace+方法名+参数」唯一匹配 SQL 节点;
-
resultType/resultMap、参数类型必须与接口方法返回值、入参类型匹配。
6.2.3 文件路径匹配规范(SpringBoot主流)
-
规范1:Mapper 接口与 Mapper XML 文件同包同名(推荐),接口在 com.example.mapper,XML 同步放在 resources/com/example/mapper 路径下;
-
规范2:通过 mybatis.mapper-locations 配置统一扫描 XML 路径,无需严格同包,但 namespace 必须精准匹配接口全类名;
-
禁止不同接口的 XML 文件混用同一个命名空间,会导致方法覆盖、SQL 错乱。
6.3 命名空间核心作用
-
唯一隔离作用:不同 Mapper 接口的 SQL 节点通过 namespace 隔离,避免全局 id 重复冲突,支持多模块同名方法、同名 SQL 标签;
-
绑定桥梁作用:是动态代理匹配 SQL 的唯一依据,无合法 namespace 则接口无法绑定 XML SQL,代理调用直接报错;
-
缓存隔离作用:MyBatis 二级缓存、命名空间级缓存以 namespace 为单位隔离,不同命名空间缓存相互独立,互不干扰;
-
复用引用作用:可通过 namespace.标签id 的方式,跨文件引用其他 Mapper 的 sql 片段、resultMap,实现资源复用。
6.4 生产高频报错坑点与解决方案
坑点1:namespace包名/类名书写错误
问题现象 :启动无报错,调用接口报BindingException: Invalid bound statement,提示找不到绑定的 SQL 方法。
成因:XML namespace 与接口全类名不匹配,框架无法完成接口与 SQL 的绑定。
解决方案:核对接口全类名,保证 namespace 大小写、包路径、类名完全一致。
坑点2:XML标签id与接口方法名不一致
问题现象:命名空间匹配成功,但调用具体方法报无对应 statement 异常。
成因:namespace 正确,但 SQL 标签 id 与接口方法名拼写、大小写不一致。
解决方案:统一方法名与标签id,严格一一对应。
坑点3:多个XML共用同一个namespace
问题现象:部分SQL方法莫名失效、执行结果错乱、旧代码逻辑覆盖。
成因:不同Mapper的XML文件配置相同namespace,后加载的SQL节点覆盖先加载的节点。
解决方案:一个 Mapper 接口唯一对应一个 namespace,专属 XML 文件独立配置。
坑点4:SpringBoot扫描路径不匹配导致绑定失效
问题现象:namespace书写正确,但项目无法加载对应XML映射文件。
成因:mapper-locations 配置路径错误,无法扫描到XML文件,绑定无法生效。
解决方案:正确配置yml扫描路径:
XML
mybatis:
mapper-locations: classpath:mapper/*.xml,classpath:**/mapper/*.xml6.5 命名空间高级用法(跨文件复用)
通过 namespace+id 全路径引用,可跨 Mapper 文件复用 ResultMap、SQL 片段,减少重复代码:
XML
<!-- 复用其他Mapper的通用结果集映射 -->
<select id="getUserInfo" resultMap="com.example.mapper.UserMapper.UserResultMap">
SELECT * FROM user
</select>6.6 面试满分核心考点
问:MyBatis命名空间namespace的作用是什么?绑定规则?绑定失败会出现什么问题?
答: 1. 核心作用:作为 Mapper 接口与 XML 映射文件的唯一绑定标识,隔离不同Mapper的SQL节点、缓存资源,支持跨文件资源复用,是动态代理匹配SQL的核心依据;
-
绑定规则 :XML的namespace必须与对应Mapper接口的全限定类名完全一致,SQL标签id必须与接口方法名一一对应;
-
失败后果:接口与SQL无法绑定,调用数据库方法会抛出 BindingException 绑定异常,方法执行失败。
6.7 核心总结
-
命名空间是 接口与XML绑定的唯一凭证,精准匹配是核心;
-
一接口一命名空间,严格隔离,杜绝混用覆盖;
-
绑定异常是生产最常见MyBatis报错,核心排查点为 namespace 和 标签id 匹配性;
-
命名空间同时管控SQL隔离、缓存隔离、资源复用三大核心能力。
十、生态框架整合
1. MyBatis-Spring 整合(完整版·原理+配置+流程+坑点+面试)
MyBatis-Spring 是 Spring 官方适配 MyBatis 的核心整合中间件,彻底解决原生 MyBatis 需手动创建 SqlSessionFactory、SqlSession、手动管控事务与资源的冗余问题,实现全组件自动托管、事务无缝整合、Mapper自动注入、生命周期自动管控,是 SpringBoot 项目使用 MyBatis 的唯一标准方案,所有企业级项目均基于该整合方案开发。
1.1 整合核心价值(解决原生痛点)
-
消除手动硬编码:无需手动加载配置、创建 SqlSessionFactory 和 SqlSession,全程 Spring 自动初始化
-
事务无缝融合:完美适配 Spring 声明式事务,统一事务管理,放弃原生手动事务提交/回滚
-
线程安全增强:解决原生 SqlSession 非线程安全问题,实现会话线程隔离、自动复用与释放
-
容器统一托管:SqlSessionFactory、Mapper 代理对象、数据源等核心对象全部纳入 Spring 容器,统一生命周期管理
-
简化开发流程:仅需简单配置,即可直接 @Autowired 注入 Mapper 调用数据库操作,极致简化业务代码
1.2 核心整合组件(四大核心类·源码必知)
MyBatis-Spring 整合体系依托四大核心类实现所有自动适配能力,是整合原理、面试核心考点:
- SqlSessionFactoryBean
核心作用:Spring 托管的 SqlSessionFactory 工厂构建类,替代原生 SqlSessionFactoryBuilder。
核心能力 :自动读取 Spring 配置(yml/properties)、整合数据源、加载 MyBatis 全局配置与 Mapper 文件,项目启动一次性创建全局单例 SqlSessionFactory。
特性:交由 Spring 容器管理,无需手动 new,全局唯一,线程安全。
- SqlSessionTemplate
核心作用 :Spring 封装的线程安全 SqlSession 模板,替代原生非线程安全的 DefaultSqlSession 核心能力 :实现线程隔离,自动绑定当前线程事务、自动创建/关闭会话、自动释放数据库连接
核心优势:多线程并发安全,同一事务内复用同一个 SqlSession,事务结束自动销毁,彻底杜绝连接泄露
- MapperScannerConfigurer
核心作用:Mapper 接口扫描注册器,实现包扫描自动注册 Mapper
核心能力 :扫描指定包下所有 Mapper 接口,通过 JDK 动态代理生成代理对象,注入 Spring 容器 对应注解:SpringBoot 中 @MapperScan 注解底层就是该类的简化封装
- TransactionSynchronization
核心作用:事务同步器,实现 MyBatis 与 Spring 事务绑定
核心能力:监听 Spring 事务状态,事务开启时绑定 SqlSession,事务提交/回滚后自动关闭会话、清空缓存,保证事务一致性
1.3 完整整合依赖(版本适配规范)
SpringBoot 项目无需单独引入 mybatis-spring 原生包,官方 starter 已内置整合依赖,严格遵循版本适配规则,避免启动报错:
-
SpringBoot 2.x 适配:mybatis-spring-boot-starter 2.x 版本(兼容 Spring5)
-
SpringBoot 3.x 适配:mybatis-spring-boot-starter 3.x 版本(兼容 Spring6、JDK17+)
-
禁止手动引入 mybatis 原生包 + mybatis-spring 整合包,会引发类冲突、容器初始化失败
1.4 企业标准完整配置(零冗余)
1.4.1 核心yml配置(SpringBoot标配)
XML
# 数据源配置(Spring事务、连接池依赖该配置)
spring:
datasource:
url: jdbc:mysql://localhost:3306/test?useSSL=false&serverTimezone=Asia/Shanghai&allowMultiQueries=true
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
# Hikari连接池优化配置
hikari:
maximum-pool-size: 10
minimum-idle: 5
idle-timeout: 300000
connection-timeout: 20000
# MyBatis-Spring整合核心配置
mybatis:
# 扫描Mapper XML文件路径
mapper-locations: classpath:mapper/*.xml
# 实体类别名包,无需写全类名
type-aliases-package: com.example.entity
configuration:
map-underscore-to-camel-case: true # 驼峰自动映射
cache-enabled: true # 开启二级缓存
default-statement-timeout: 5 # SQL超时时间,防慢查询雪崩1.4.2 启动类扫描配置(必配)
java
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
// 扫描Mapper接口所在包,自动生成代理对象注入容器
@MapperScan("com.example.mapper")
public class MybatisApplication {
public static void main(String[] args) {
SpringApplication.run(MybatisApplication.class, args);
}
}1.5 Spring+MyBatis 完整执行流程(整合后核心链路)
1.项目启动初始化阶段:
SpringBoot 自动加载 yml 配置,初始化数据源、连接池;
SqlSessionFactoryBean 解析所有 MyBatis 配置与 Mapper XML,创建全局单例 SqlSessionFactory;
MapperScannerConfigurer 扫描所有 Mapper 接口,生成动态代理对象注入 Spring 容器。
2.业务调用运行阶段:
业务层 @Autowired 注入 Mapper 代理对象,调用数据库方法;
Spring 通过事务同步器检测当前事务环境,从线程池获取/绑定线程级 SqlSession(SqlSessionTemplate);
执行动态 SQL 解析、参数绑定、预编译、数据库操作;
Spring 自动管控事务:无异常自动提交、有异常自动回滚;方法执行完毕,自动关闭 SqlSession、释放数据库连接、清空一级缓存。
1.6 整合后事务核心机制(企业核心)
-
事务统一托管:完全废弃 MyBatis 原生手动 commit/rollback,所有事务由 Spring AOP 动态管控
-
声明式事务使用 :通过
@Transactional注解快速开启事务,支持事务传播、隔离级别、超时时间配置 -
事务绑定规则:同一线程、同一事务内,始终复用同一个 SqlSession,保证事务原子性;事务结束立即销毁会话,避免线程复用导致的事务错乱
-
默认事务规则:单条增删改语句自动提交事务;多条联动 SQL 必须手动添加 @Transactional 注解保证原子性
java
import org.springframework.transaction.annotation.Transactional;
import org.springframework.stereotype.Service;
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
// 声明式事务:多条操作原子执行,异常自动回滚
@Transactional(rollbackFor = Exception.class)
public void batchAdd() {
userMapper.insertUser(new User());
userMapper.insertUser(new User());
}
}1.7 整合核心优势对比(原生 VS Spring整合)
| 对比维度 | 原生 MyBatis | Spring 整合 MyBatis |
|---|---|---|
| SqlSession 管理 | 手动创建、手动关闭、易泄露 | Spring 自动托管、线程隔离、自动释放 |
| 事务控制 | 手动 commit/rollback,代码冗余 | 注解式事务,自动提交回滚 |
| 线程安全 | SqlSession 非线程安全,需严格管控 | SqlSessionTemplate 线程安全,支持并发 |
| Mapper 获取 | 手动从会话获取,无法注入 | 容器自动注入,随用随取 |
| 配置方式 | 仅原生 XML 配置 | yml 简化配置,优先级更高 |
总结:
SqlSessionFactoryBean、MapperScannerConfigurer 核心配置 Spring 事务注解 @Transactional 管理数据库事务
2. MyBatis-Plus 增强框架(完整版·核心特性+实战配置+原理+坑点+面试)
MyBatis-Plus(简称 MP)是一款基于原生MyBatis无侵入增强的开源框架 ,只增强、不改动原生MyBatis任何底层逻辑,完美兼容所有MyBatis原生语法、配置、插件,彻底补齐原生MyBatis基础CRUD繁琐、缺少工程化特性的短板,是目前Java企业级项目持久层开发的标配框架,大幅简化重复代码、提升开发效率,同时适配生产级规范与性能要求。
2.1 核心定位与核心优势
核心宗旨:只做增强不做改变,简化CRUD、强化工程化、适配生产场景
-
无侵入性:完全基于MyBatis原生开发,无需改动原有MyBatis代码、XML文件、配置,项目无缝接入,兼容所有原生特性,零迁移成本
-
极简CRUD:内置通用Mapper、通用Service,封装全套单表CRUD,无需手写任何SQL,告别重复模板代码
-
工程化能力齐全:原生缺失的逻辑删除、乐观锁、自动填充、分页、主键策略等企业刚需特性一站式集成
-
灵活度极高:单表操作用MP简化开发,复杂联表、动态SQL、特殊业务仍可使用原生MyBatis XML,兼顾效率与灵活性
-
性能无损:底层依旧依托MyBatis原生执行流程,无额外性能损耗,适配高并发生产环境
2.2 版本适配规范(生产避坑核心)
MP版本与SpringBoot、JDK、MyBatis版本强绑定,版本不匹配直接启动报错,企业标准适配规则:
-
MyBatis-Plus 3.4.x/3.5.x:适配 SpringBoot 2.x、JDK8+、MyBatis 3.5.x,主流稳定版本,绝大多数企业项目首选
-
MyBatis-Plus 4.x:适配 SpringBoot 3.x、JDK17+、MyBatis 3.5.13+,适配新版Spring生态
-
禁止混用版本:项目中不可同时引入原生mybatis starter与MP starter,会引发类加载冲突、初始化异常
2.3 企业标准Maven依赖
SpringBoot2.x 通用稳定依赖,无需额外引入原生MyBatis启动器
XML
<!-- MyBatis-Plus 核心启动器 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<!-- 数据库驱动、lombok、spring-jdbc 依赖同原生MyBatis配置 -->2.4 核心工程化配置(yml完整版)
整合原生MyBatis配置+MP专属增强配置,生产项目通用标配
XML
spring:
datasource:
url: jdbc:mysql://localhost:3306/test?useSSL=false&serverTimezone=Asia/Shanghai&allowMultiQueries=true
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
# MyBatis-Plus 全局配置
mybatis-plus:
# 映射文件扫描路径
mapper-locations: classpath:mapper/*.xml
# 实体类别名包
type-aliases-package: com.example.entity
configuration:
# 驼峰自动映射
map-underscore-to-camel-case: true
# 开启二级缓存
cache-enabled: true
# SQL执行超时时间
default-statement-timeout: 5
# MP全局增强配置
global-config:
# 数据库全局配置
db-config:
# 主键自增策略
id-type: auto
# 逻辑删除字段(默认0未删除、1已删除)
logic-delete-field: deleted
logic-delete-value: 1
logic-not-delete-value: 0
# 表名前缀(统一规范)
table-prefix: t_
# 关闭MP启动banner
banner: false2.5 六大核心增强特性(企业高频使用)
2.5.1 通用CRUD封装(BaseMapper+IService)
MP核心基础能力,彻底告别单表SQL手写,全覆盖新增、修改、删除、查询、批量操作
-
BaseMapper(Dao层):所有Mapper接口继承该接口,内置selectById、insert、update、delete、batch批量操作、条件查询等数十种通用方法,无需实现直接调用
-
IService+ServiceImpl(Service层):封装业务层通用逻辑,提供批量保存、分页查询、链式查询、数据校验等增强方法,分层规范统一
基础代码示例:
java
// Mapper接口直接继承BaseMapper
public interface UserMapper extends BaseMapper<User> {}
// Service层标准实现
public interface UserService extends IService<User> {}
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {}
// 业务调用(无SQL实现CRUD)
userService.getById(1); // 根据ID查询
userService.save(user); // 新增数据
userService.updateById(user); // 根据ID修改
userService.removeById(1); // 物理删除
userService.list(); // 查询全部2.5.2 条件构造器(QueryWrapper/UpdateWrapper)
MP核心亮点,无需手写XML/注解SQL,通过Java代码链式拼接动态条件,完美适配多条件动态查询,彻底解决原生动态SQL代码冗余问题
-
QueryWrapper :用于查询、删除条件构造,支持等值、模糊、区间、排序、分组、空值判断
-
UpdateWrapper :用于动态修改,可按需更新指定字段,避免全字段覆盖更新
-
LambdaQueryWrapper:Lambda表达式构造,杜绝硬编码字段名,避免拼写错误,更优雅安全
实战示例:动态条件分页查询
java
// Lambda条件构造器,无硬编码字段
LambdaQueryWrapper<User> wrapper = Wrappers.lambdaQuery();
// 动态拼接条件:用户名模糊查询 + 年龄区间 + 未删除
wrapper.like(StringUtils.isNotBlank(userName), User::getUserName, userName)
.ge(age != null, User::getAge, 18)
.lt(age != null, User::getAge, 30)
.eq(User::getDeleted, 0)
.orderByDesc(User::getCreateTime);
// 分页查询
Page<User> page = userService.page(new Page<>(1, 10), wrapper);2.5.3 自动填充功能
全局自动填充通用字段,无需业务手动set赋值,适配所有实体的创建时间、更新时间、创建人、更新人等通用字段
-
核心场景:新增自动填充创建时间、创建人;修改自动填充更新时间、更新人
-
实现方式:自定义MetaObjectHandler配置类,全局拦截所有新增/修改操作,自动赋值
实战配置:
java
@Component
public class MyMetaHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
// 新增自动填充
this.strictInsertFill(metaObject, "createTime", Date::new, Date.class);
this.strictInsertFill(metaObject, "createUser", () -> getCurrentUserId(), Long.class);
}
@Override
public void updateFill(MetaObject metaObject) {
// 修改自动填充
this.strictUpdateFill(metaObject, "updateTime", Date::new, Date.class);
this.strictUpdateFill(metaObject, "updateUser", () -> getCurrentUserId(), Long.class);
}
}2.5.4 逻辑删除
生产必备特性,替代物理删除,实现数据软删除,保留数据溯源、恢复能力,一键全局配置
-
原理:新增deleted字段,删除操作自动修改字段状态,查询自动过滤已删除数据,底层SQL自动拼接条件
-
优势:无需手动拼接删除条件,全局统一规范,避免误删数据无法恢复
-
特殊场景:清理冗余数据可手动执行物理删除
2.5.5 乐观锁插件
解决并发更新数据覆盖问题,适配库存、订单、积分等并发修改场景,无锁实现并发安全
-
实现原理:新增version版本字段,更新时校验版本号,版本一致则更新+版本自增,版本不一致则更新失败,规避并发覆盖
-
使用方式:开启插件+实体字段添加@Version注解,框架自动完成版本校验与自增
2.5.6 分页插件
替代第三方PageHelper,官方原生分页能力,支持物理分页、分页参数自动解析、总条数自动统计,无第三方依赖冲突
java
@Configuration
public class MybatisPlusConfig {
// 开启分页插件
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}2.6 代码生成器(核心提效工具)
MP内置代码生成器,一键自动生成实体类、Mapper接口、Mapper XML、Service、Controller全套代码,适配前后端分离项目,彻底解放重复编码,企业开发标配
-
支持自定义代码模板、包路径、注释、Lombok注解、主键策略
-
支持多表批量生成,适配快速搭建项目基础架构
-
可自定义过滤字段、生成逻辑,适配项目个性化规范
2.7 底层核心原理
-
无侵入增强原理:基于MyBatis插件拦截机制、SQL动态拼接能力拓展,未修改MyBatis核心源码,所有原生执行流程、配置完全保留
-
通用CRUD原理:启动时根据实体类泛型、数据库表结构,动态生成通用CRUD SQL,封装为内置方法,运行时直接执行
-
条件构造器原理:通过链式调用拼接SQL片段,最终组装为完整可执行SQL,交由MyBatis原生执行器执行
-
自动填充/逻辑删除原理:基于MyBatis拦截器,在SQL执行前动态修改参数、拼接条件,实现全局增强
2.8 生产高频坑点与解决方案
- 坑点1:MP与原生MyBatis混用冲突
问题:同时引入原生mybatis-starter与mp-starter,导致容器初始化失败
解决方案:统一使用mybatis-plus-boot-starter,废弃原生启动器
- 坑点2:Lambda构造器字段硬编码失效
问题:手写字段名导致字段拼写错误、维护困难
解决方案:统一使用LambdaQueryWrapper,通过实体方法引用传参
- 坑点3:自动填充不生效
问题:填充类未注入Spring容器、字段名不匹配、新增/修改场景判断错误
解决方案:添加@Component注解,严格匹配实体字段名,区分新增/修改填充逻辑
- 坑点4:逻辑删除查询不过滤数据
问题:全局配置未生效、自定义SQL未适配逻辑删除
解决方案:全局统一配置逻辑删除规则,自定义XML SQL手动拼接删除条件
- 坑点5:乐观锁失效
问题:未开启插件、实体未添加@Version、version字段默认值为空
解决方案:配置乐观锁插件,实体版本字段默认初始值为1
2.9 面试高频满分考点
- 问:MyBatis-Plus和原生MyBatis的区别?为什么企业都用MP?
答:1. MP基于MyBatis无侵入增强,完全兼容原生所有特性,无学习成本;
-
原生缺少工程化特性,CRUD代码冗余,MP封装通用CRUD、分页、逻辑删除、自动填充等刚需能力;
-
MP条件构造器简化动态SQL开发,大幅提升开发效率,兼顾灵活性与规范性,适配企业生产场景。
- 问:MyBatis-Plus的无侵入原理是什么?
答:MP并未修改MyBatis核心源码,依托MyBatis内置的插件拦截机制、动态SQL组装能力实现功能增强,原生执行流程、配置、SQL语法完全保留,因此可以无缝兼容原生MyBatis项目。
- 问:MP乐观锁的实现原理与适用场景?
答:通过版本号机制实现无锁并发控制,更新时校验version版本,一致则更新并自增版本,不一致则更新失败;
适用于库存扣减、订单修改、积分变动等并发更新场景,解决数据覆盖问题。
2.10 核心总结
-
MP 只增强不修改原生MyBatis,兼容性拉满,零接入成本;
-
核心解决原生CRUD繁琐、工程化能力缺失的痛点,适配企业开发规范;
-
条件构造器、自动填充、逻辑删除、乐观锁、分页是生产高频核心能力;
-
单表用MP简化开发,复杂多表、特殊SQL沿用原生MyBatis XML,兼顾高效与灵活。
总结:
CRUD 封装、条件构造器、代码生成、乐观锁、逻辑删除、分页增强 只增强不改动原生 MyBatis,大幅提升开发效率
3. 多数据库兼容
一套项目适配 MySQL、Oracle 等多种数据库语法
十一、逆向工程开发工具
MyBatis逆向工程是企业开发标配工具,核心作用是根据数据库表结构,自动反向生成Java实体类、Mapper接口、Mapper XML映射文件、甚至Service/Controller层代码 ,彻底摒弃手动搭建基础代码的重复工作,保证代码与数据库表结构精准同步,统一项目编码规范,大幅提升项目初始化、迭代开发效率。目前主流逆向工程方案分为两种:传统MBG(MyBatis Generator) 原生逆向工具、MyBatis-Plus代码生成器(现代企业主流),下面两套方案均提供完整可落地配置、实战步骤、适配规则与避坑要点。
1. 主流逆向工具对比(选型依据)
两种工具适配不同项目场景,可根据项目技术栈灵活选择:
-
MyBatis Generator(MBG):MyBatis官方原生逆向工具,专属原生MyBatis项目,轻量化、无多余依赖,精准生成原生CRUD代码,适配纯MyBatis架构项目,稳定性极强。
-
MyBatis-Plus代码生成器:适配MP增强项目,功能更全面,可一键生成全套分层代码(Entity/Mapper/Service/Controller),支持Lombok、自动填充、逻辑删除、乐观锁等MP专属特性,是目前SpringBoot+MP项目首选方案。
2. 原生MBG逆向工程(适配纯MyBatis项目)
2.1 核心依赖(Maven)
仅需引入插件依赖,无需项目主依赖,不影响项目运行环境
XML
<!-- MyBatis逆向工程插件 -->
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.4.2</version>
<configuration>
<!-- 配置文件路径 -->
<configurationFile>src/main/resources/generator/generatorConfig.xml</configurationFile>
<!-- 覆盖已生成文件 -->
<overwrite>true</overwrite>
<!-- 允许移动生成的文件 -->
<verbose>true</verbose>
</configuration>
<dependencies>
<!-- 数据库驱动,与项目数据库版本匹配 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.30</version>
</dependency>
</dependencies>
</plugin>2.2 完整核心配置文件(generatorConfig.xml)
放置在 resources/generator/ 目录下,可直接复用,支持自定义包路径、表过滤、代码规则
XML
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<!-- 数据库驱动路径,本地可省略,插件已引入驱动 -->
<!-- 环境配置:适配MyBatis3核心版本 -->
<context id="MysqlContext" targetRuntime="MyBatis3" defaultModelType="flat">
<!-- 统一编码 -->
<property name="javaFileEncoding" value="UTF-8"/>
<!-- 格式化代码 -->
<property name="enableSubPackages" value="true"/>
<property name="trimStrings" value="true"/>
<!-- 数据库连接配置 -->
<jdbcConnection driverClass="com.mysql.cj.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/test?serverTimezone=Asia/Shanghai&useSSL=false"
userId="root"
password="123456">
<property name="nullCatalogMeansCurrent" value="true"/>
</jdbcConnection>
<!-- 数值类型精度处理 -->
<javaTypeResolver>
<property name="forceBigDecimals" value="false"/>
</javaTypeResolver>
<!-- 1. 实体类生成配置 -->
<javaModelGenerator targetPackage="com.example.entity" targetProject="src/main/java">
<property name="enableSubPackages" value="true"/>
<property name="trimStrings" value="true"/>
</javaModelGenerator>
<!-- 2. Mapper XML文件生成配置 -->
<sqlMapGenerator targetPackage="mapper" targetProject="src/main/resources">
<property name="enableSubPackages" value="true"/>
</sqlMapGenerator>
<!-- 3. Mapper接口生成配置 -->
<javaClientGenerator type="XMLMAPPER" targetPackage="com.example.mapper" targetProject="src/main/java">
<property name="enableSubPackages" value="true"/>
</javaClientGenerator>
<!-- 逆向生成指定数据表,%代表生成所有表 -->
<table tableName="user" domainObjectName="User" enableCountByExample="false"
enableUpdateByExample="false" enableDeleteByExample="false" enableSelectByExample="false"
selectByExampleQueryId="false"/>
</context>
</generatorConfiguration>2.3 执行生成步骤
-
配置数据库连接信息、包路径、需要逆向的数据表;
-
IDE中找到Maven插件:mybatis-generator:generate;
-
双击执行,自动生成实体类、Mapper接口、XML映射文件;
-
生成后可按需删除Example冗余代码(配置中已默认关闭)。
2.4 MBG核心优缺点
-
优点:官方原生、零适配问题、生成代码纯净、无冗余逻辑、完全贴合原生MyBatis语法;
-
缺点:仅生成持久层代码、无Service/Controller层、不支持Lombok、无工程化增强特性。
3. MyBatis-Plus代码生成器(企业主流)
适配SpringBoot+MP项目,是目前互联网企业标配逆向方案,一键生成全套分层代码,支持自定义模板、工程化特性,完美适配MP所有增强功能。
3.1 核心依赖
需单独引入生成器依赖及模板依赖(SpringBoot项目)
XML
<!-- MyBatis-Plus代码生成器 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.3.1</version>
</dependency>
<!-- 模板引擎(默认Velocity) -->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.3</version>
</dependency>3.2 完整可运行生成工具类
直接新建测试类,运行main方法即可生成全套代码,可自定义所有规则
java
import com.baomidou.mybatisplus.generator.FastAutoGenerator;
import com.baomidou.mybatisplus.generator.config.OutputFile;
import com.baomidou.mybatisplus.generator.engine.VelocityTemplateEngine;
import java.util.Collections;
/**
* MyBatis-Plus代码生成器(企业标准版)
* 一键生成:Entity、Mapper、MapperXML、Service、ServiceImpl、Controller
*/
public class MpCodeGenerator {
public static void main(String[] args) {
// 1. 数据库连接地址
String url = "jdbc:mysql://localhost:3306/test?serverTimezone=Asia/Shanghai&useSSL=false";
String username = "root";
String password = "123456";
// 2. 全局初始化配置
FastAutoGenerator.create(url, username, password)
// 全局配置
.globalConfig(builder -> {
builder.author("开发人员") // 作者名称
.outputDir("D:/code") // 代码输出路径
.dateType("TIME_PACK") // 时间类型策略
.disableOpenDir() // 关闭生成后自动打开文件夹
.commentDate("yyyy-MM-dd"); // 注释日期格式
})
// 包路径配置
.packageConfig(builder -> {
builder.parent("com.example") // 父包名
.moduleName("system") // 模块名
.entity("entity")
.mapper("mapper")
.service("service")
.serviceImpl("service.impl")
.controller("controller")
.pathInfo(Collections.singletonMap(OutputFile.xml, "D:/code/mapper"));
})
// 策略配置(核心规范)
.strategyConfig(builder -> {
// 需生成的表名,多个用逗号分隔
builder.addInclude("user")
.addTablePrefix("t_") // 过滤表前缀
// 实体类配置
.entityBuilder()
.enableLombok() // 开启Lombok注解
.enableTableFieldAnnotation() // 开启字段注解
.logicDeleteFieldName("deleted") // 逻辑删除字段
.versionFieldName("version") // 乐观锁字段
.enableInsertFileComment(true)
// Mapper配置
.mapperBuilder()
.enableMapperAnnotation()
.enableBaseResultMap()
// Service配置
.serviceBuilder()
.formatServiceFileName("%sService")
.formatServiceImplFileName("%sServiceImpl")
// Controller配置
.controllerBuilder()
.enableRestStyle() // 开启REST风格接口
.formatFileName("%sController");
})
// 模板引擎配置
.templateEngine(new VelocityTemplateEngine())
// 执行生成
.execute();
}
}3.3 核心生成能力
-
全分层生成:一次性生成 Controller、Service、ServiceImpl、Mapper、Entity、XML 全套代码;
-
工程化适配:自动适配Lombok、逻辑删除、乐观锁、自动填充、RESTful接口风格;
-
规范化处理:自动去除表前缀、字段驼峰转换、生成标准注释、统一代码格式;
-
灵活可控:支持单表/多表批量生成、自定义输出路径、自定义代码模板。
4. 逆向工程通用规范(企业强制)
-
命名规范:数据库下划线字段自动映射Java驼峰属性,表名对应实体类大驼峰命名;
-
注释规范:自动读取数据库表、字段注释,生成Java代码注释,保证代码可读性;
-
覆盖规范:首次生成可全覆盖,迭代生成前建议备份自定义代码,避免业务逻辑被覆盖;
-
精简规范:关闭无用的Example条件代码,减少冗余,贴合业务开发需求。
5. 生产高频坑点与解决方案
- 坑点1:逆向生成字段缺失/字段不匹配
成因:数据库字段注释不规范、字段为空、驱动版本不匹配
解决方案:统一数据库字段规范,保证驱动与数据库版本一致,重新逆向生成
- 坑点2:重复生成覆盖自定义代码
成因:开启自动覆盖,手动修改的XML/Java代码被重置
解决方案:迭代开发禁止频繁逆向,仅初始化使用,自定义代码单独维护
- 坑点3:Lombok注解不生效
成因:生成器未开启Lombok配置、项目未引入Lombok依赖
解决方案:代码生成器手动开启enableLombok,项目引入Lombok依赖并开启注解生效
- 坑点4:时间类型映射异常
成因:数据库datetime类型映射为LocalDateTime/Date不统一
解决方案:统一生成器时间类型策略,全局规范时间字段映射规则
6. 面试核心考点
- 问:MyBatis逆向工程的作用是什么?常用工具区别?
答:逆向工程可根据数据库表自动生成持久层基础代码,减少重复编码、统一代码规范。MBG是官方原生工具,仅生成基础持久层代码,适配原生MyBatis;MP代码生成器功能更全面,可生成全套分层代码,支持工程化特性,适配现代SpringBoot企业项目。
- 问:逆向工程开发有哪些注意事项?
答:1. 严格匹配数据库驱动版本,避免类型映射异常;
-
禁止迭代开发中频繁覆盖生成,防止自定义逻辑丢失;
-
统一开启Lombok、驼峰映射、注释生成,保证代码规范;
-
关闭冗余Example代码,精简项目结构。
7. 核心总结
-
原生MyBatis项目优先使用MBG官方逆向工具,纯净无冗余;
-
SpringBoot+MP项目首选MP代码生成器,一键生成全套业务代码,提效最大化;
-
逆向工程仅用于项目初始化搭建,迭代开发以手动优化、自定义SQL为主;
-
核心价值:统一编码规范、消除重复劳动、保证代码与表结构精准同步。
十二、生产调优与实战坑点
1. SQL 生产规范与性能调优(核心必守)
MyBatis 项目80%的线上性能问题均源于SQL不规范、执行低效、未做优化,本小节统一梳理企业级SQL书写规范、慢查询优化方案、动态SQL避坑要点,适配高并发、大数据量生产场景。
1.1 强制SQL书写规范(生产红线)
-
严禁使用 select *:必须按需指定查询字段,减少数据库IO、网络传输、实体映射开销,避免查询冗余字段引发的性能损耗,同时防止表结构新增字段后,旧代码出现未知字段映射异常。
-
禁止无限制全表查询:所有列表查询必须加分页、条件过滤、时间范围限制,杜绝不带where条件的全表扫描,防止大数据量查询拖垮数据库。
-
统一SQL大小写规范:关键字大写(SELECT、FROM、WHERE、AND、ORDER BY),表名字段名小写,代码可读性统一,避免解析异常。
-
复杂SQL拆分、简单SQL复用:多表超级复杂联表、子查询嵌套过深的SQL,拆分为多次简单查询+业务层组装数据;简单CRUD、高频查询SQL统一封装复用,减少重复编码。
-
杜绝隐式类型转换:字符串字段必须传字符串参数、数字字段传数字参数,避免数据库自动隐式转换导致索引失效、全表扫描。
-
慎用 distinct、order by、group by:高频查询场景尽量避免去重、排序、分组操作,如需使用必须保证对应字段建立索引,防止内存排序、临时表生成。
1.2 动态SQL生产避坑与优化
-
where标签自动去多余and/or:禁止手动拼接前缀and,避免条件为空时出现SQL语法报错,所有多条件动态查询统一使用<where>标签包裹。
-
foreach批量操作优化:批量插入、更新、删除时,控制单次遍历数据量,单次批量操作不超过1000条,避免SQL语句过长超出数据库限制、引发连接超时。
-
if判空精准匹配 :字符串必须同时判断
null != 字段 and 字段 != '',数值类型只判断非空,杜绝空字符串、空参数拼接无效条件。 -
禁止动态SQL过度嵌套:多层if、choose、when嵌套会导致SQL解析耗时增加、可读性极差,复杂条件拆分到多条SQL或业务层处理。
1.3 慢查询专项调优方案
-
开启慢查询日志监控:数据库开启慢日志阈值(默认2秒),MyBatis配置SQL执行超时时间,超时自动拦截告警,快速定位低效SQL。
-
索引适配优化:查询条件、排序、分组字段必须建立索引,遵循最左匹配原则;避免索引失效场景(like %前缀模糊查询、or拆分索引、隐式类型转换)。
-
大表查询优化 :百万级以上大表,禁止limit超大分页(如limit 100000,10),采用主键分页(where id > 上一页最后id limit 10),避免全表扫描排序。
-
避免N+1查询问题:关联查询优先使用联表查询,禁止循环单表查询;如需关联懒加载,严格控制加载时机,杜绝批量数据循环查询数据库。
2. 数据库连接池生产调优(防雪崩核心)
SpringBoot默认HikariCP连接池是MyBatis项目性能兜底,连接池参数不合理会导致连接耗尽、请求阻塞、超时报错、并发雪崩,以下为线上通用最优配置,适配绝大多数企业项目。
2.1 HikariCP核心最优参数配置
XML
spring:
datasource:
hikari:
# 最大连接数:根据数据库连接上限配置,普通业务10-20,高并发20-30
maximum-pool-size: 15
# 最小空闲连接:保证常驻连接,避免频繁创建销毁
minimum-idle: 5
# 连接超时时间:单次获取连接最大等待时长,防止请求阻塞
connection-timeout: 20000
# 空闲连接超时:闲置连接自动释放,节省数据库资源
idle-timeout: 300000
# 连接最大生命周期:避免长时间连接失效
max-lifetime: 1200000
# 测试连接可用性,防止死连接
connection-test-query: SELECT 12.2 核心参数调优原理与避坑
-
maximum-pool-size 最大连接数:并非越大越好,数据库单节点默认连接数上限100,单服务配置10-20即可;过大导致数据库连接争抢、锁等待超时,过小导致并发请求排队阻塞。
-
idle-timeout 空闲超时:生产必须配置,避免大量空闲连接常驻占用数据库资源,低峰期自动释放多余连接,高峰期保留常驻连接快速响应。
-
connection-timeout 连接超时:设置20秒超时,防止线程无限等待连接,快速失败兜底,避免服务线程池耗尽引发雪崩。
2.3 连接池高频线上问题解决方案
- 问题1:连接池耗尽、Too many connections:
成因:SqlSession未关闭、事务未释放、长事务阻塞连接;
解决方案:Spring托管会话、杜绝手动持有连接、拆分长事务、优化慢查询。
- 问题2:连接超时、读写超时:
成因:SQL执行过慢、连接闲置失效、网络波动;
解决方案:优化慢SQL、配置连接心跳检测、调整超时参数。
- 问题3:并发卡顿、响应缓慢:
成因:最大连接数过小,并发请求排队;
解决方案:根据压测数据微调连接数,不盲目加大配置。
3. 缓存机制生产调优与避坑(高频踩坑)
MyBatis一、二级缓存使用不当会导致数据脏读、缓存失效、数据不一致,是生产环境最易忽略的隐形坑点,以下为精准调优与避坑方案。
3.1 一级缓存生产规范与坑点
-
核心特性:默认开启、会话级缓存,同一SqlSession内重复查询复用缓存,事务提交/会话关闭后清空。
-
生产坑点1:
事务内脏读:同一事务内,先查询后修改,未提交事务时再次查询,会读取旧缓存数据,无法感知最新修改。
解决方案:实时一致性业务,查询前手动清空缓存或设置一级缓存为语句级。
- 生产坑点2:
长事务缓存堆积:长事务内大量查询会堆积一级缓存数据,占用内存。
解决方案:拆分长事务,避免单次事务执行过多查询操作。
- 高并发实时业务调优 :实时库存、订单、支付业务,配置
localCacheScope: STATEMENT,关闭会话级缓存,每次查询直接走数据库,保证数据绝对实时。
3.2 二级缓存生产开关与避坑
-
适用场景:静态数据、配置数据、低频修改、高频查询的业务(字典、分类、系统配置),大幅提升查询性能。
-
禁用场景:实时交易、库存、订单、资金等高一致性业务,坚决关闭二级缓存,避免脏读。
-
核心坑点:
跨Mapper数据不同步:同一张表在多个Mapper中操作,一个Mapper修改数据清空自身缓存,其他Mapper缓存依旧保留,导致脏数据。
解决方案:单表统一对应一个Mapper,或自定义全局缓存刷新机制。
- 序列化坑点:开启二级缓存后,实体类必须实现Serializable序列化接口,否则启动/运行报错。
4. 事务生产坑点与调优(数据一致性核心)
事务问题是生产数据错乱、数据丢失、事务回滚失效的核心原因,梳理企业高频事务坑点与优化方案。
4.1 高频事务坑点
- 坑点1:
@Transactional 回滚失效:默认仅捕获RuntimeException回滚,受检异常、自定义异常不回滚。
解决方案 :统一配置 rollbackFor = Exception.class,所有异常强制回滚。
- 坑点2:
事务内部try-catch失效 :方法内手动捕获异常,未抛出,Spring无法感知异常,不会自动回滚。 解决方案:catch异常后手动抛出,或手动事务回滚。
- 坑点3:
事务传播机制误用:嵌套事务、异步事务导致事务独立、回滚错乱。
解决方案:核心业务统一使用REQUIRED传播机制,杜绝随意修改传播属性。
- 坑点4:
长事务导致锁超时:事务内嵌套大量业务逻辑、网络请求、循环逻辑,占用数据库行锁,导致其他请求锁等待超时。
解决方案:事务内只保留数据库操作,剥离非DB逻辑,精简事务执行时长。
4.2 事务生产调优规范
-
事务注解仅加在Service业务层方法,禁止加在Controller、Mapper层。
-
查询方法禁止开启事务,减少事务开销,提升接口响应速度。
-
批量操作优先使用Batch批量事务,减少数据库IO交互,提升批量处理性能。
-
设置全局事务超时时间(默认30秒),避免事务永久阻塞。
5. 并发与批量操作生产优化
5.1 批量操作核心优化
-
禁止循环单条CRUD:for循环中单次insert/update,频繁交互数据库,性能极差;统一使用MyBatis Batch批量事务或MP批量方法。
-
大数据量拆分批次:上万条数据批量操作,拆分批次(每批500-1000条),避免SQL超长、事务超时、数据库压力过大。
-
批量操作关闭自动主键回填:Batch模式下主键回填失效,批量新增后统一查询主键,避免性能损耗。
5.2 并发更新避坑
- 并发数据覆盖问题:多线程同时更新同一条数据,后提交数据覆盖前提交数据。
解决方案:引入MP乐观锁、数据库版本号机制,或分布式锁控制并发。
- 超卖、库存错乱问题:库存更新使用数据库原子SQL(update set stock = stock - 1),禁止业务层计算后更新,杜绝并发偏差。
6. 日志与脱敏生产规范
6.1 日志分级管控(生产必调)
-
开发环境:开启完整SQL日志、参数日志、结果日志,方便调试排错。
-
生产环境:关闭详细SQL打印,仅保留错误日志、慢查询日志,减少日志IO开销,避免泄露敏感数据。
-
慢日志监控:对接日志监控系统,超时SQL自动告警,及时优化低效语句。
6.2 敏感数据脱敏
-
手机号、身份证、银行卡、密码、用户隐私信息,禁止明文打印日志、明文返回前端。
-
通过MyBatis类型处理器、全局拦截器实现数据库查询数据自动脱敏,统一生产数据安全规范。
7. 生产高频异常与快速排查方案
7.1 绑定异常(BindingException)
-
成因:namespace与接口全类名不匹配、SQL标签id与方法名不一致、Mapper扫描路径错误。
-
排查方案:优先核对namespace、方法名、XML扫描路径,三步快速定位问题。
7.2 字段映射异常
-
成因:数据库字段与实体属性不匹配、驼峰映射未开启、resultMap配置错误、字段类型不兼容。
-
排查方案:开启驼峰自动映射、核对字段名与类型、校验resultMap映射规则。
7.3 SQL语法异常
-
成因:动态SQL拼接多余and/or、foreach标签参数为空、SQL关键字冲突。
-
排查方案:打印最终执行SQL,定位拼接错误位置,优化动态SQL逻辑。
7.4 连接泄露异常
-
成因:手动创建SqlSession未关闭、长事务阻塞、异常未释放连接。
-
排查方案:统一交由Spring托管会话、规范事务使用、监控连接池使用情况。
8. 生产终极调优总结(落地清单)
-
SQL层面:禁select *、必加索引、分页限流、优化动态SQL、杜绝全表扫描
-
连接池层面:适配最优Hikari参数、防连接耗尽、防超时阻塞
-
缓存层面:实时业务关二级缓存、静态业务开缓存、规避缓存脏读
-
事务层面:精简事务时长、统一异常回滚、杜绝嵌套事务混乱
-
并发层面:批量拆分执行、并发更新用原子SQL+乐观锁
-
运维层面:分级日志、数据脱敏、慢日志监控、异常快速排查
禁止 select *,按需查询字段;复杂 SQL 写 XML,简单 SQL 用注解
十三、高频面试核心考点
-
#{} 与 ${} 区别、SQL 注入原理与防范
-
一级缓存、二级缓存区别、生效范围、失效场景
-
MyBatis 完整执行流程、核心组件作用
-
动态 SQL 实现原理、OGNL 作用
-
四种执行器差异、线程安全问题
-
延迟加载、关联查询使用场景
-
插件拦截器实现原理与应用场景
-
Mapper 动态代理底层实现
-
N+1 查询问题成因与解决方案
-
MyBatis 与 MyBatis-Plus 优缺点对比
-
多数据源、读写分离实现思路
学习周期规划
1 周:基础环境 + CRUD + 基础配置
2 周:参数映射 + 动态 SQL 语法精通
3 周:缓存 + 分页 + 类型处理器高级用法
4 周:插件开发 + 源码流程理解
5 周:Spring 整合 + MyBatis-Plus 实战
6 周:生产调优 + 坑点复盘 + 面试刷题