Apple Silicon 经过多年的架构演进,在本地运行大语言模型的体验已经达到生产环境的标准。随着 2026 年 Ollama 0.19 版本的发布以及底层推理引擎全面切换至 MLX,Mac 设备的生成速度和资源利用率那就不一样了,堪称熹妃回宫。
对于开发者与技术团队来说,仅仅依赖单一云端API,长期调用接口是一笔不小的数字,而本地化部署就能削减这个成本,更能大幅提升数据安全性与应用的离线可用性。接下来就在 Mac 平台上部署 AI 模型的硬件选型、环境搭建步骤以及架构设计方案。

Mac 跑本地 AI 需要多大内存
决定 Mac 本地推理能力的直接指标是统一内存的大小。苹果芯片将显存与系统内存合二为一,大模型加载时会直接占用这部分物理空间。业界通常存在过度预估硬件需求的误区,当前的量化技术已经能让参数量庞大的模型在有限内存中流畅运行。
8GB 至 16GB 内存配置适合运行 3B 级别的小型基础模型。系统自带的 Apple Foundation Models 经过专门优化,能够在此类设备上无缝处理文本分类、提取和基础对话。若需运行 7B 到 8B 级别的模型,采用 4-bit 量化(约占用 5GB 常驻内存)也能勉强加载,但容易占用较多系统资源并导致其他应用响应变慢。
16GB 至 32GB 内存是目前本地跑图与中型语言模型的门槛。在此容量下,设备能够轻松运行 Q4 量化版本的 Qwen 3 8B 模型,并为操作系统预留充足的活动空间。
32GB 以上直至 128GB 的大内存机型完全解锁了运行 30B 甚至 70B 级别大语言模型的能力。深度量化的 DeepSeek V3-Distill-32B 或 Qwen3.5-35B-A3B 能够在该内存区间内实现全载入,生成质量可直接对标主流的云端大模型。
2026 适合 AI 开发的 Mac 推荐
针对不同开发阶段的实际需求,2026 年的 Mac 产品线提供了明确的性能分级。
M1 与 M2 系列(包含 Pro 版本)适合轻量级任务。由于设备已经支持 macOS 26 的原生 Foundation Models 框架,开发者可以直接调用内置的 3B 参数模型处理结构化输出任务,同时搭配 Whisper-base 模型完成基础的语音转写工作。
M3 Pro 与 M3 Max 是目前单兵开发者的极佳选择。该配置能够同时保持多个模型在后台常驻。开发者可以一边运行 Qwen 3 8B 处理常规的文本生成,一边在需要复杂逻辑推演时调用 Phi-4 14B 模型,多任务切换十分流畅。
M4 与 M5 系列(特别是 Max 版本)专门针对重度推理进行了底层重构。M5 芯片搭载的 GPU 神经加速器针对 LLM 推理进行了深度定向优化。在 Ollama 0.19 配合 MLX 引擎的测试中,M5 Max 运行 Qwen3.5-35B-A3B 的解码速度达到了 112 tokens/s。对于需要极高吞吐量及代码分析能力的开发团队,配备大内存的 M5 Max 能够直接替代部分专用的 GPU 工作站。
Ollama MLX Mac 安装教程
Ollama 换用 MLX 引擎后补齐了过去依赖 llama.cpp 时在苹果芯片上的性能短板。由于完全支持 REST API,任何兼容 OpenAI 接口规范的应用都能将其作为底层的推理服务。
过去开发者通常习惯使用命令行包管理器进行环境配置,现在通过 ServBay 平台可以极大简化这一部署流程。ServBay 能够一键安装Ollama ,同时能顺便配置好 Python、Node.js、PHP 等各种主流开发语言的运行环境,省去了繁琐的环境变量设置与排错环节。
在 Mac 上下载并运行 ServBay 后,只需在其服务管理面板中勾选启用 Ollama,系统即会自动完成依赖配置并启动后台服务。
接着在 ServBay 里下载和安装本地 AI 大模型。
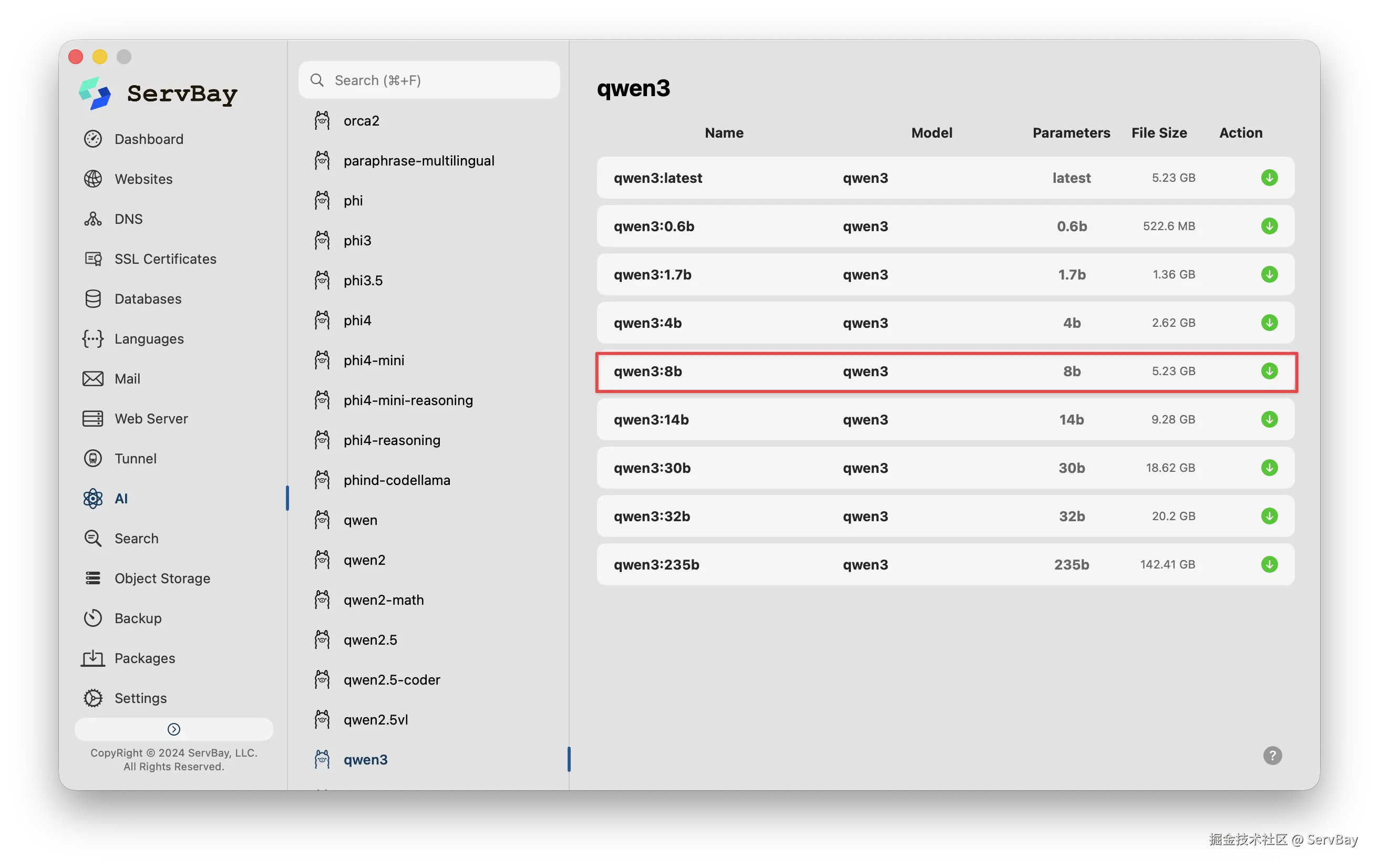
或者可以打开系统终端,执行下方指令拉取对应的模型文件即可开始使用。
bash
# 下载并运行 8B 版本的 Qwen 3 模型
ollama pull qwen3:8b启动完成后系统会在本地 11434 端口开启一个兼容 OpenAI 格式的 HTTP 服务。下述 Python 脚本展示了如何利用官方 SDK 接入本地环境进行测试。
python
from openai
import OpenAI
# 初始化客户端并指向本地 ServBay 托管的 Ollama 接口
local_client = OpenAI(
api_key="sk-servbay-local-test",
base_url="http://127.0.0.1:11434/v1"
)
# 构建对话请求
response = local_client.chat.completions.create(
model="qwen3:8b",
messages=[
{"role": "developer", "content": "只输出代码,无须解释"},
{"role": "user", "content": "请用 Swift 实现一个简单的单例模式"}
],
temperature=0.1
)
print(response.choices[0].message.content)通过修改应用框架的基础 API 地址,现有的 AI 编程助手(如 Cursor、Aider 等)能够顺畅对接到本地的 MLX 推理端,实现离线编码辅助。
架构设计方案 探讨本地与云端混合
纯依赖本地或者全盘上云都不是最高效的工程实践。2026 年主流的商业级 AI 应用普遍采用三层混合调度架构,根据任务复杂度进行算力分发。
第一层为极低延迟的常驻原生层。利用苹果系统内置的 Foundation Models 处理所有的基础请求。由于该 3B 模型深度融合在系统中,开发者可以借助 Swift 中的 @Generable 宏直接获取类型安全的结构化数据。这一层完全免费且不消耗额外的安装空间,非常适合处理频繁的路由分发、状态判断和短文摘要。
第二层为按需拉起的本地重负载层。当应用遇到多步推理、长文本创作或复杂逻辑分析时,系统会唤醒驻留在内存中的 Qwen 3 8B 级别的开源模型。这一部分承担了绝大多数核心业务逻辑的运算,且不依赖任何外部网络。
第三层为云端大模型回退机制。仅当遇到本地硬件无法攻克的超高难度任务时,应用会在获取用户明确授权后,向 Claude Opus 4.7 或 GPT-5.5 发起 API 请求。这种本地与云端混合的设计确保了日常使用的零成本运转,同时将昂贵的云端资源用在收益最高的场景。
在语音处理方面,基于神经引擎运行的 WhisperKit 以及 NVIDIA 开源的 FluidAudio 已经全面取代传统的 Python 脚本转录方式。FluidAudio 处理大量英文音频的单次推理时间缩短至 0.19 秒,能够在本地实现极高并发的批量文字转换。
保护隐私的本地 AI 部署
各行各业对数据出境及云端存储的合规要求正变得空前严格。医疗机构、律所及金融科技公司在处理用户敏感数据时,几乎排除了将原始信息发送至第三方大模型提供商的可能。
推进保护隐私的本地 AI 部署有效解决了业务开展中的合规阻碍。上文提到的三层混合架构默认将绝大部分数据流拦截在用户的物理设备内。即便在没有 Wi-Fi 或处于极端网络环境的场景下,应用的核心逻辑依然能够运转。硬件设备一次性投入后,单次调用的边际成本降至零,为软件产品带来了高度可控的财务预期与极强的抗风险能力。由于不涉及网络往返等待,本地服务的首字响应时间通常优于大部分商业云端节点。
本地 AI 软件生态历经几年的技术迭代,框架集成度与模型质量均已达标。摸清目标受众的硬件基线,摒弃过度量化与对云端模型的盲目追求,选择合适的运行环境,是当前打造原生 AI 产品的合理路径。