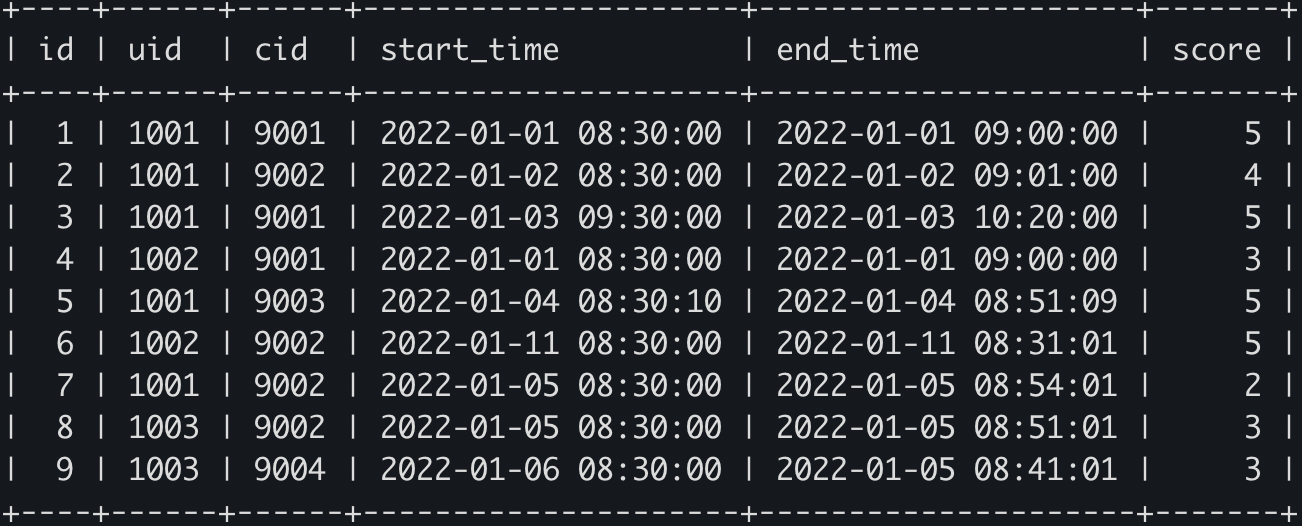
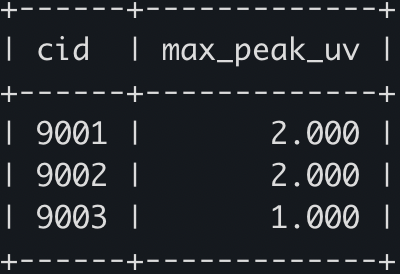
WITH time_points AS (
-- 将每个观看记录拆分成开始(+1)和结束(-1)两个事件
SELECT
cid,
start_time AS event_time,
1 AS delta
FROM play_record_tb
UNION ALL
SELECT
cid,
end_time AS event_time,
-1 AS delta
FROM play_record_tb
),
concurrent_count AS (
-- 按时间排序,计算累计并发数
SELECT
cid,
event_time,
SUM(delta) OVER (PARTITION BY cid ORDER BY event_time) AS concurrent_num
FROM time_points
),
max_concurrent AS (
-- 对每个视频取最大并发数
SELECT
cid,
MAX(concurrent_num) AS max_concurrent
FROM concurrent_count
GROUP BY cid
)
-- 取TOP3
SELECT
cid,
ROUND(CAST(max_concurrent AS DECIMAL(10,3)), 3) AS max_concurrent
FROM max_concurrent
ORDER BY max_concurrent DESC, cid
LIMIT 3;
另一种更简洁的实现方式(使用LATERAL或自关联)
sql复制代码
WITH RECURSIVE time_points AS (
-- 收集所有可能的时间点(开始和结束时间)
SELECT cid, start_time AS time_pt FROM play_record_tb
UNION
SELECT cid, end_time FROM play_record_tb
),
concurrent_at_time AS (
-- 每个时间点的并发数
SELECT
tp.cid,
tp.time_pt,
COUNT(*) AS concurrent_num
FROM time_points tp
JOIN play_record_tb pr
ON pr.cid = tp.cid
AND pr.start_time <= tp.time_pt
AND pr.end_time > tp.time_pt
GROUP BY tp.cid, tp.time_pt
),
max_concurrent AS (
SELECT
cid,
MAX(concurrent_num) AS max_concurrent
FROM concurrent_at_time
GROUP BY cid
)
SELECT
cid,
ROUND(CAST(max_concurrent AS DECIMAL(10,3)), 3) AS max_concurrent
FROM max_concurrent
ORDER BY max_concurrent DESC, cid
LIMIT 3;
-- 第1步:把每一条观看记录拆成两个事件(开始+1,结束-1)
WITH time_points AS (
SELECT cid, start_time, 1 AS delta FROM play_record_tb -- 开始事件:+1
UNION ALL
SELECT cid, end_time, -1 AS delta FROM play_record_tb -- 结束事件:-1
),
-- 第2步:按时间排序,把delta累加起来
concurrent_count AS (
SELECT
cid,
event_time,
SUM(delta) OVER (PARTITION BY cid ORDER BY event_time) AS concurrent_num
FROM time_points
)
-- 第3步:找出每个视频的最大值
SELECT cid, MAX(concurrent_num) FROM concurrent_count GROUP BY cid
WITH time_points AS (
-- 开始事件:+1
SELECT
cid,
start_time AS event_time,
1 AS delta,
1 AS event_order -- 开始事件优先级高(先加)
FROM play_record_tb
UNION ALL
-- 结束事件:-1
SELECT
cid,
end_time AS event_time,
-1 AS delta,
0 AS event_order -- 结束事件优先级低(后减)
FROM play_record_tb
),
concurrent_count AS (
SELECT
cid,
event_time,
-- 按时间排序,时间相同时按event_order排序(先加后减)
SUM(delta) OVER (
PARTITION BY cid
ORDER BY event_time, event_order DESC -- DESC确保+1先于-1
) AS concurrent_num
FROM time_points
),
max_concurrent AS (
SELECT
cid,
MAX(concurrent_num) AS max_concurrent
FROM concurrent_count
GROUP BY cid
)
SELECT
cid,
ROUND(CAST(max_concurrent AS DECIMAL(10,3)), 3) AS max_concurrent
FROM max_concurrent
ORDER BY max_concurrent DESC, cid
LIMIT 3;
WHERE start_time IS NOT NULL AND end_time IS NOT NULL
更简洁的替代方案(使用UNION ALL + ROW_NUMBER)
sql复制代码
WITH all_events AS (
SELECT
cid,
start_time AS event_time,
1 AS delta
FROM play_record_tb
WHERE start_time IS NOT NULL
UNION ALL
SELECT
cid,
end_time AS event_time,
-1 AS delta
FROM play_record_tb
WHERE end_time IS NOT NULL
),
concurrent_count AS (
SELECT
cid,
event_time,
SUM(delta) OVER (
PARTITION BY cid
ORDER BY event_time, delta DESC -- delta DESC: +1(1) 排在 -1(-1) 前面
) AS concurrent_num
FROM all_events
)
SELECT
cid,
ROUND(MAX(concurrent_num), 3) AS max_concurrent
FROM concurrent_count
GROUP BY cid
ORDER BY max_concurrent DESC, cid
LIMIT 3;