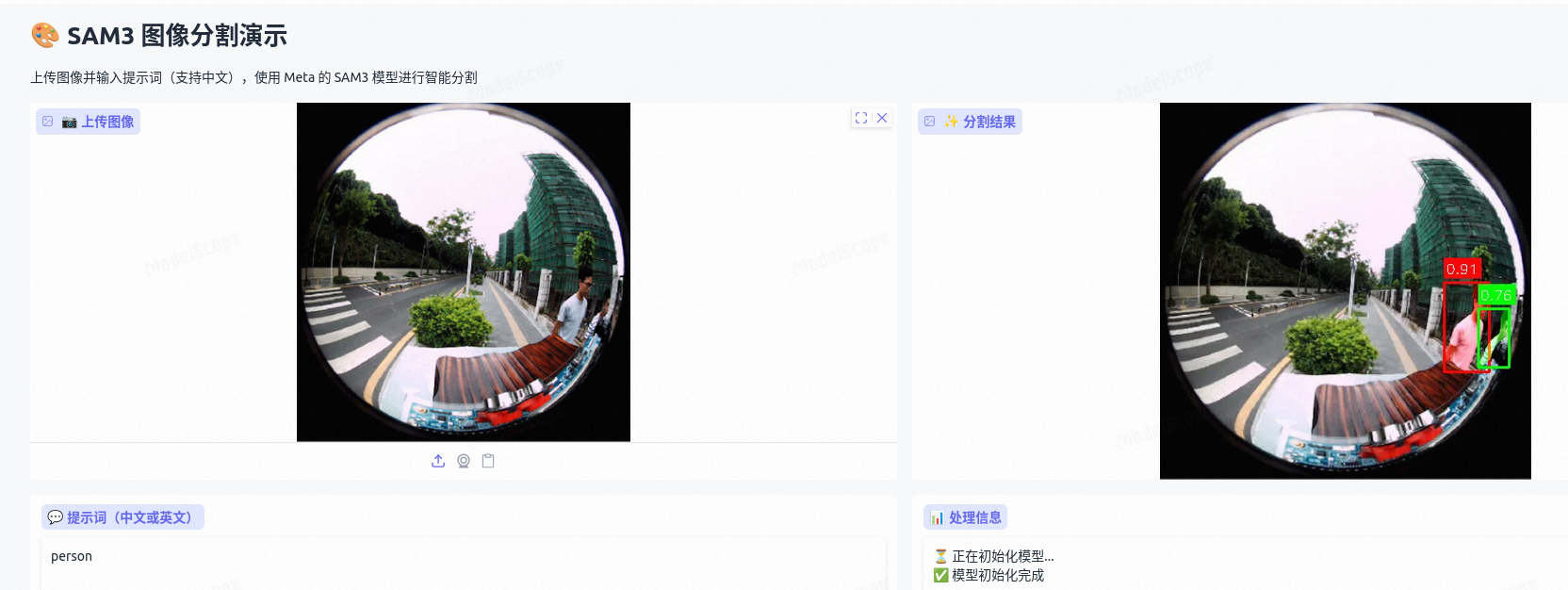
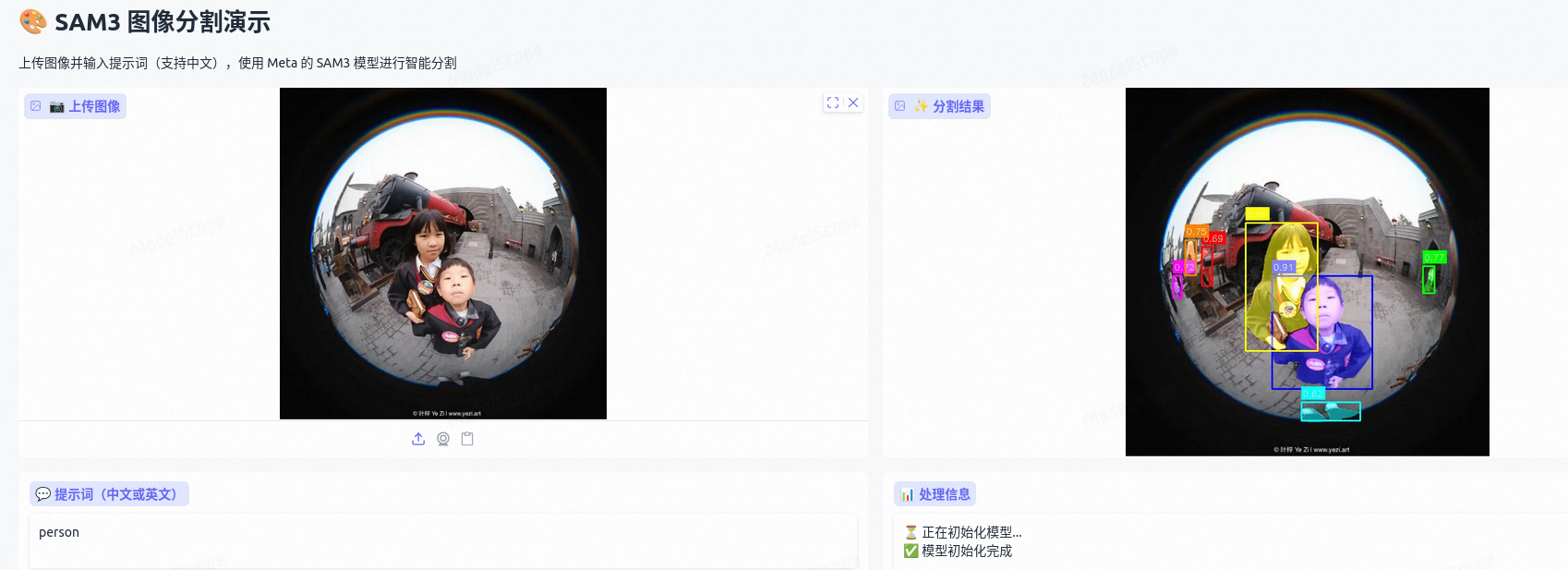
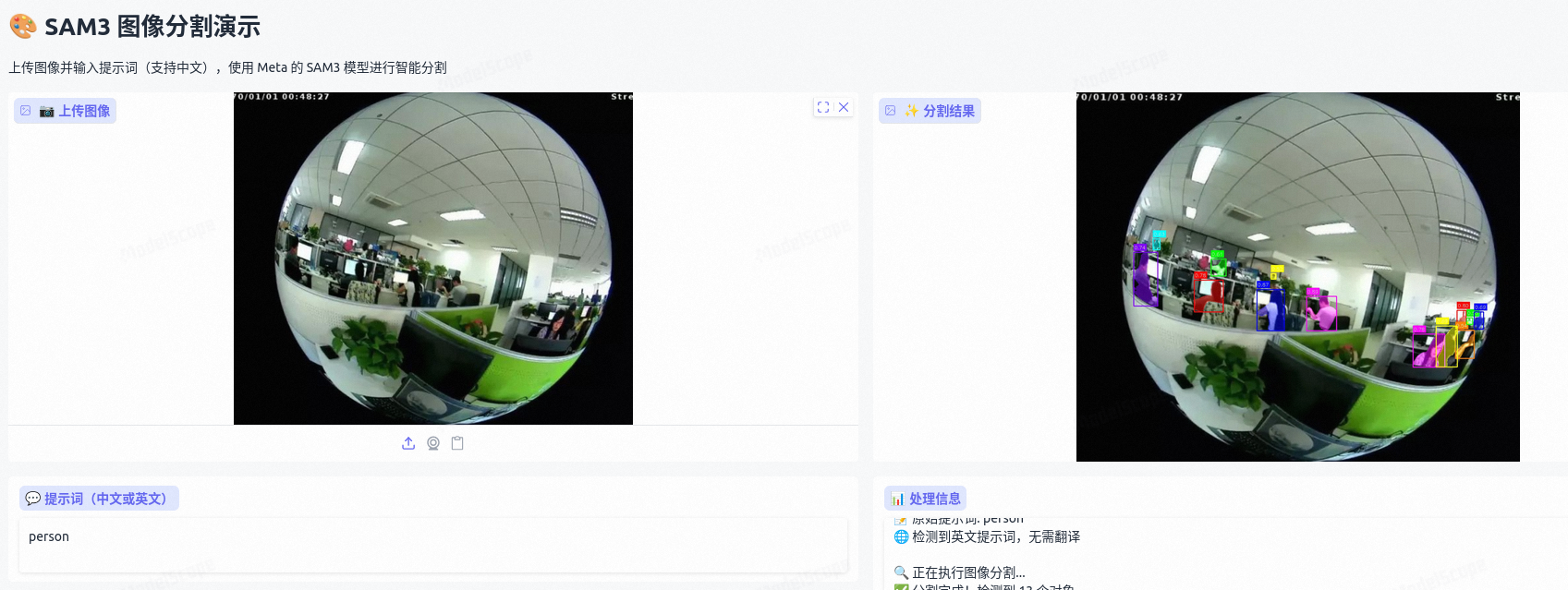
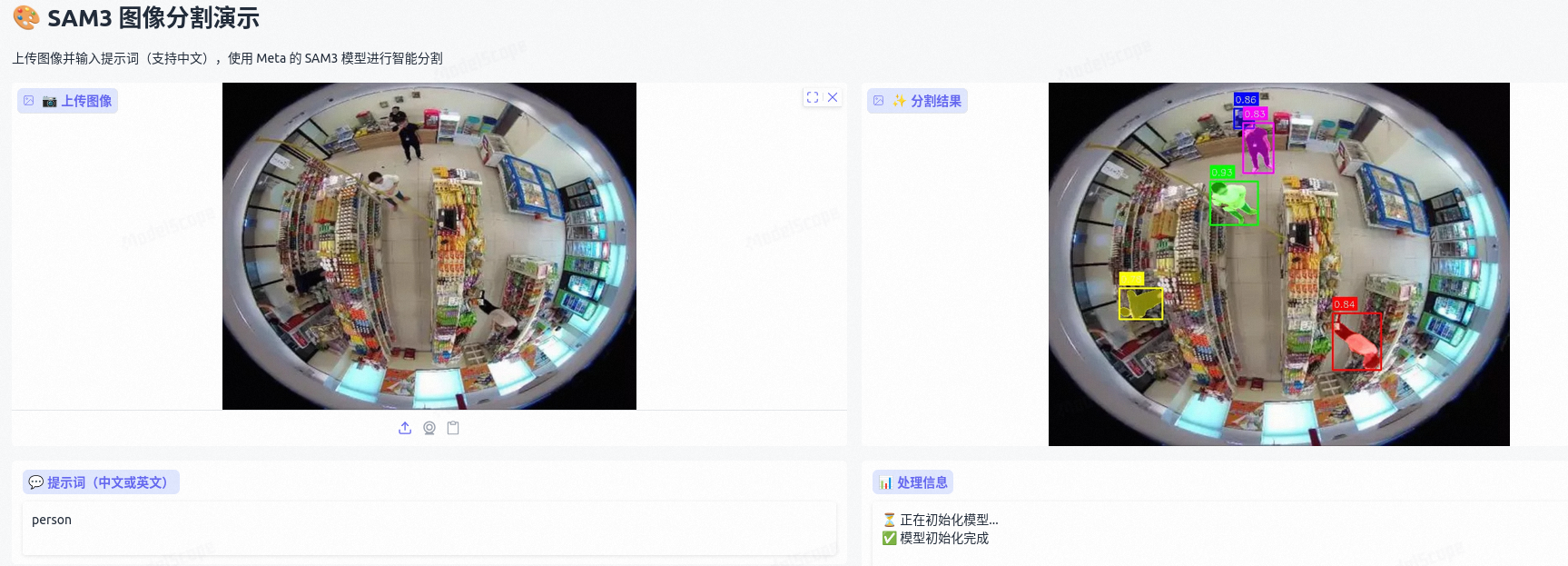
要求在鱼眼相机下检测出图像中的人,不想标注图像,不想微调,就想用点现成的。先找了个专门检测鱼眼相机人体检测的开源项目,然后有尝试了
yolov8-obb,yolov11等,最后尝试了SAM3,还是SAM3效果好。这里RAPiD之前没接触过,着重记录一下,但是这个模型比较老,参考一下思想就行。
引言:鱼眼相机的检测挑战
鱼眼相机(Fisheye Camera)以其超广角视野著称,能够在一个镜头中捕获 180° 甚至更广的场景。这种特性使其在安防监控、智能交通、机器人导航等领域有着广泛应用。然而,鱼眼图像存在一个核心问题:严重的径向畸变。
传统目标检测模型(如标准 YOLO)使用水平边界框(HBB),在鱼眼图像边缘区域面临两大问题:
- 框不精确: 水平矩形框无法紧密包围弯曲变形的人物,导致大量背景被误包含
- 检测漏检: 畸变后的人物特征与训练数据差异大,容易被漏检或误判
这就是 RAPiD 要解决的问题。
RAPiD 是什么
RAPiD (Rotation-Aware People Detection)是一个专门为鱼眼相机人物检测设计的深度学习模型,由 duanzhiihao 开发并开源。
核心特点
| 特性 | 描述 |
|---|---|
| 检测方式 | 旋转边界框(Oriented Bounding Box, OBB) |
| 输出格式 | [x_center, y_center, width, height, angle, confidence] |
| 角度范围 | -180° ~ 180° |
| 骨干网络 | Darknet-53(或 ResNet-34/50/101) |
| 训练数据 | 鱼眼人物数据集(MW, HBCP 等) |
与传统检测的区别
传统 HBB 检测 (YOLO):
输出: [x1, y1, x2, y2, conf, class]
框形状: 矩形,无旋转角度
适用: 正常图像、轻微畸变
RAPiD OBB 检测:
输出: [x, y, w, h, angle, conf]
框形状: 旋转矩形,可任意角度
适用: 鱼眼图像、强畸变场景核心原理:旋转边界框检测
1. OBB 表示方式
RAPiD 使用 5参数表示法:
[x_center, y_center, width, height, angle, confidence]
其中:
- x_center, y_center: 边界框中心坐标
- width, height: 边界框的宽度和高度
- angle: 旋转角度(度数,范围 -180° ~ 180°)
- confidence: 检测置信度2. 角度预测机制
RAPiD 对角度采用 sigmoid 激活 + 线性映射:
python
# 网络输出
angle_raw = sigmoid(raw_angle) # 范围 [0, 1]
# 映射到 [-180°, 180°]
angle_deg = angle_raw * 360 - 180这种设计使得角度预测成为一个回归任务,而不是分类任务,能够预测任意精确的角度值。
3. 旋转 IoU 计算
传统IoU计算适用于水平矩形框,但对于旋转框需要特殊处理:
┌─────────────────────────────────────────┐
│ 旋转框 IoU 计算方法 │
│ │
│ 方法1: mask-based IoU │
│ - 将两个旋转框渲染为二值 mask │
│ - 计算 mask 交集/并集 │
│ - 精度高但计算慢 │
│ │
│ 方法2: RLE-based IoU (RAPiD 使用) │
│ - Run-Length Encoding 表示旋转框 │
│ - 高效计算交集 │
│ - 平衡精度与速度 │
└─────────────────────────────────────────┘RAPiD 提供两种 IoU 计算方式:
iou_mask: 基于mask渲染,精度高iou_rle: 基于RLE编码,速度快
模型架构详解
整体架构
RAPiD 采用 YOLO-style 多尺度检测架构:
┌─────────────────────────────────────────────────────────────┐
│ RAPiD 模型架构 │
│ │
│ 输入图像 (608×608) │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ Backbone │ Darknet-53 / ResNet │
│ │ (特征提取) │ │
│ └─────────────────┘ │
│ │ │
│ ├──────────┬──────────┬────────── │
│ ▼ ▼ ▼ │
│ Small Medium Large │
│ (76×76) (38×38) (19×19) │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │Branch_S │ │Branch_M │ │Branch_L │ YOLO 检测分支 │
│ │(小目标) │ │(中目标) │ │(大目标) │ │
│ └─────────┘ └─────────┘ └─────────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ 输出: 6通道 (x,y,w,h,angle,conf) × 3 anchors │
│ │
└─────────────────────────────────────────────────────────────┘骨干网络选择
| Backbone | 参数量 | 速度 | 精度 | 推荐场景 |
|---|---|---|---|---|
| Darknet-53 | ~41M | 中 | 高 | 通用场景 |
| ResNet-34 | ~21M | 快 | 中 | 实时检测 |
| ResNet-50 | ~25M | 中 | 高 | 高精度需求 |
| ResNet-101 | ~44M | 慢 | 最高 | 离线分析 |
Anchor 设计
RAPiD 使用 9 个预设 Anchors,分为 3 组对应不同尺度:
python
anchors = [
# Small scale (76×76 grid)
[18.78, 33.47], [28.89, 61.75], [48.68, 68.39],
# Medium scale (38×38 grid)
[45.07, 101.47], [63.10, 113.54], [81.39, 134.46],
# Large scale (19×19 grid)
[91.74, 144.99], [137.52, 178.48], [194.44, 250.80]
]这些 Anchor 的尺寸经过聚类分析,专门适配鱼眼图像中人物的典型尺寸分布。
检测分支设计
每个检测分支(YOLOBranch)包含:
python
class YOLOBranch:
# 1. 特征处理(如有上一级特征)
process: ConvBnLeaky(prev_ch)
# 2. 上采样 + 拼接(FPN 思想)
F.interpolate(scale_factor=2)
torch.cat([upsampled, current_feature])
# 3. 多层卷积
cbl_0 → cbl_1 → cbl_2 → cbl_3 → cbl_4 → cbl_5
# 4. 输出层
to_box: Conv2d → 18 channels (3 anchors × 6 params)损失函数
python
# 总损失
Loss = L_xy + 0.5 * L_wh + L_angle + L_obj
其中:
- L_xy: BCE Loss(中心坐标)
- L_wh: MSE Loss(宽高)
- L_angle: Periodic L1/L2 Loss(角度)
- L_obj: BCE Loss(置信度)角度损失的特殊处理:
由于角度是周期性的(180° 和 -180° 实际上相同),RAPiD 使用 周期性损失函数:
python
def period_L1(pred, target):
# pred, target 都是弧度
diff = pred - target
# 周期性约束: 如果差值 > π,则减去 2π
diff = diff - 2π * round(diff / 2π)
return abs(diff).sum()解决的问题
1. 鱼眼畸变下的精确检测
问题: 水平框无法紧密包围畸变人物
解决: 旋转框精确贴合
2. 边缘区域检测率低的问题
传统模型在鱼眼边缘区域的检测率显著下降,因为:
- 人物变形严重,特征与训练数据差异大
- 水平框检测阈值难以适配变形目标
RAPiD 通过:
- 专用鱼眼数据训练: 模型见过各种畸变形态
- 旋转框预测: 无需强行适配水平框
3. 角度信息缺失的问题
传统检测只输出位置和大小,无法获取人物朝向。RAPiD 的角度输出可用于:
- 行为分析: 判断人物行走方向
- 姿态估计: 辅助判断站立/躺卧姿态
- 运动预测: 结合角度预测运动轨迹
适用场景
最佳适用场景
| 场景 | 说明 | 推荐配置 |
|---|---|---|
| 安防监控 | 广角监控摄像头人物检测 | Darknet-53 + GPU |
| 智能交通 | 交叉口行人检测预警 | ResNet-34 + 实时 |
| 机器人导航 | 避障系统人员感知 | ResNet-34 + 嵌入式 |
| VR/AR 应用 | 360° 视场人物定位 | Darknet-53 + 高精度 |
| 无人机监控 | 大范围人员搜救 | ResNet-50 + 平衡 |
不适用场景
| 场景 | 原因 | 替代方案 |
|---|---|---|
| 正常图像检测 | OBB 无优势,速度慢 | YOLO11 标准版 |
| 多类别检测 | RAPiD 只检测人物 | YOLO11 全类别 |
| 极高速度需求 | RAPiD 相对较慢 | YOLO11 + TensorRT |
| 移动端部署 | 模型较大 | YOLO-Nano |
特色与优势
核心特色
1. 专业训练数据
RAPiD 在专门的鱼眼人物数据集上训练:
训练数据集:
- MW (Motion Wrap): 运动场景鱼眼数据
- HBCP (Hirakawa Bay Camera Person): 海滨监控数据
- CEPDOF: CEye Person Detection on Fisheye
特点:
- 涵盖不同畸变程度的人物样本
- 包含不同光照、天气条件
- 覆盖室内/室外多种场景还可以对人体数据集加鱼眼畸变,人工构建畸变矫正图像数据集。
2. 精确的角度预测
RAPiD 能预测人物朝向角度(±180°),这在行为分析中非常有价值:
python
# 角度应用示例
if -45° < angle < 45°:
motion = "朝向摄像头移动"
elif 135° < angle or angle < -135°:
motion = "远离摄像头移动"
elif 45° < angle < 135°:
motion = "横向移动(左侧)"
else:
motion = "横向移动(右侧)"3. 多尺度检测能力
RAPiD 同时检测不同大小的人物:
- Small scale: 远处小人物
- Medium scale: 中等距离人物
- Large scale: 近处大人物
4. 灵活的骨干网络
支持多种骨干网络,可根据需求选择速度-精度平衡点。
与其他 OBB 模型的对比
| 模型 | 训练数据 | person 类别 | 鱼眼适配 | 推荐度 |
|---|---|---|---|---|
| RAPiD | 鱼眼人物数据 | ✓ 专门优化 | ✓✓✓ | ⭐⭐⭐⭐⭐ |
| YOLO8-OBB | DOTA 航空数据 | ✗ 无 | ✗ | ⭐ |
| YOLO11-OBB | DOTA 航空数据 | ✗ 无 | ✗ | ⭐ |
| FCOS-OBB | 多种数据 | 部分 | ✗ | ⭐⭐ |
关键区别 : YOLO-OBB 系列模型训练于DOTA航空图像数据集,检测类别为飞机、船只、车辆等,完全不包含 "person" 类别,不适合人物检测!
实测对比:RAPiD vs YOLO11
测试设置
| 项目 | 配置 |
|---|---|
| 测试图像 | 7 张鱼眼图像 |
| 置信度阈值 | 0.3, 0.5, 0.7, 0.9 |
| RAPiD 配置 | Darknet-53 backbone, 输入尺寸 608 |
| YOLO11 配置 | yolo11n.pt, 输入尺寸 640, 仅检测 person 类别 |
| 运行环境 | CPU 模式(公平对比) |
检测结果总览
| 阈值 | RAPiD 检测数 | YOLO11 检测数 | RAPiD FPS | YOLO11 FPS |
|---|---|---|---|---|
| 0.3 | 16 | 16 | 1.06 | 10.87 |
| 0.5 | 10 | 7 | 0.97 | 15.80 |
| 0.7 | 8 | 3 | 0.97 | 14.09 |
| 0.9 | 6 | 0 | 0.96 | 14.46 |
| 总计 | 40 | 29 | - | - |
| 平均 FPS | 0.99 | 13.80 | - | - |
对比图像展示
以下图像展示了 RAPiD(左侧,红色旋转框)与 YOLO11(右侧,蓝色水平框)的检测结果对比:
阈值 0.3 对比



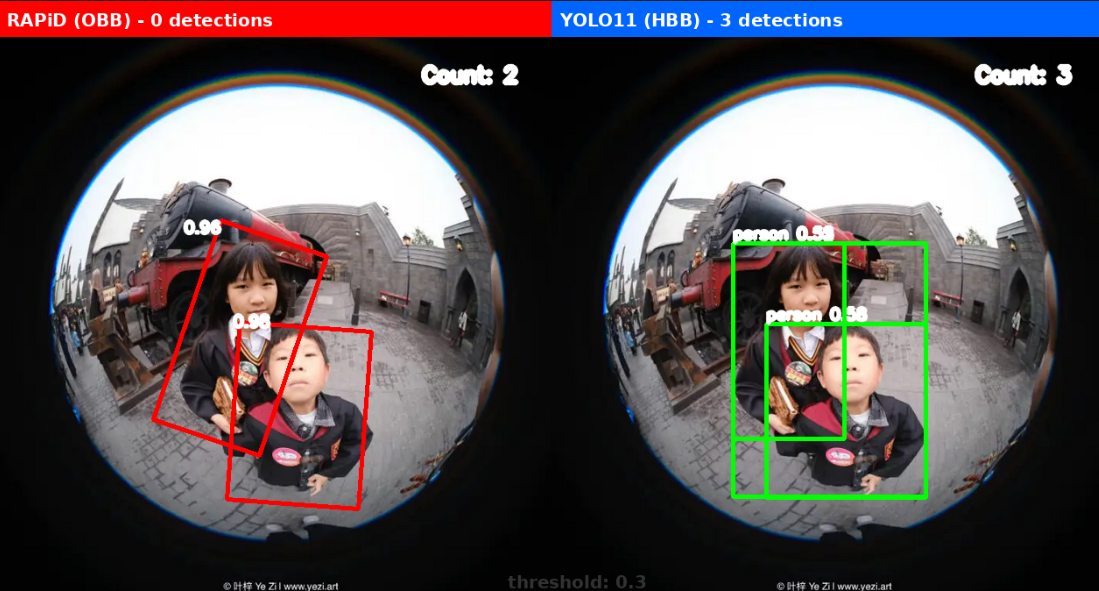
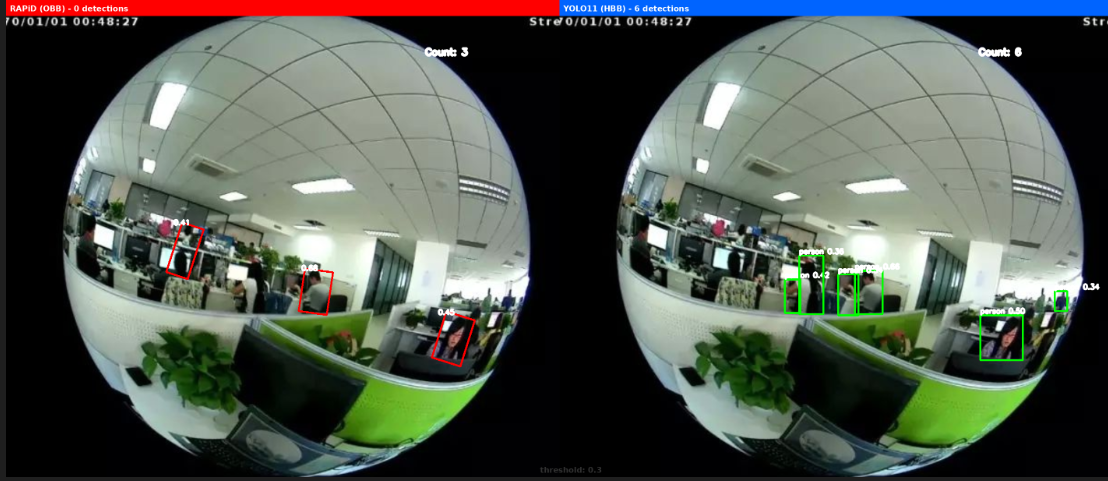

关键发现
1. 速度与精度的权衡
- RAPiD: 适合离线分析、高精度需求场景
- YOLO11: 适合实时监控、速度优先场景
2. 适用场景
- YOLO11 对水平方向效果拍摄图像识别效果更好
- RAPiD 对俯视拍摄效果更好
SAM3 效果展示
以上方法都有漏检,还得看大模型,检测效果非常好: