反思设计模式
1. 反思设计模式(Reflection Design Pattern)
1.1 2.1 什么是反思模式
反思模式的思路很直接:让 LLM 对自己的输出进行审视和改进。类比人类写作------写完初稿后回头检查,发现模糊、遗漏、错误,然后修改得到更好的版本。
这个过程是硬编码的:工程师预先设计好"生成→反思→改进"的步骤序列,而不是让模型自己决定何时反思。
1.1.1 邮件写作的反思流程
以 Andrew Ng 写给 Tommy 的邮件为例:
初稿(V1)存在三个问题:
- "next month" 不够具体,Tommy 无法确定是哪几天
- "fre" 拼写错误,应为 "free"
- 没有署名
反思改进后(V2): 明确了日期范围(5th-7th),修正拼写,添加署名。
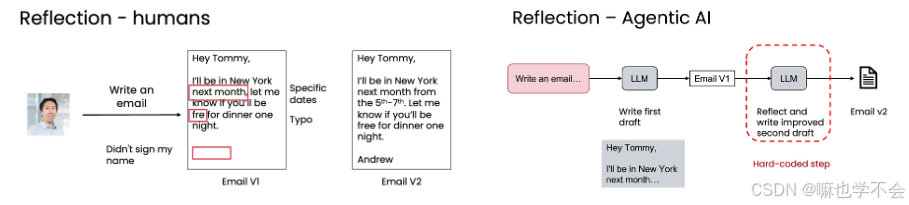
LLM 的反思流程与人类一致:
- 生成初稿:向 LLM 发送初始提示,得到 V1
- 反思改进:将 V1 再次输入 LLM(可以是同一个模型,也可以是另一个擅长推理的模型),提示语变为"请反思这份草稿并写出改进版"
- 得到终稿:LLM 基于对初稿的分析,输出质量更高的 V2
1.1.2 代码编写的三层递进
反思在代码场景中有三种用法,逐层增强:
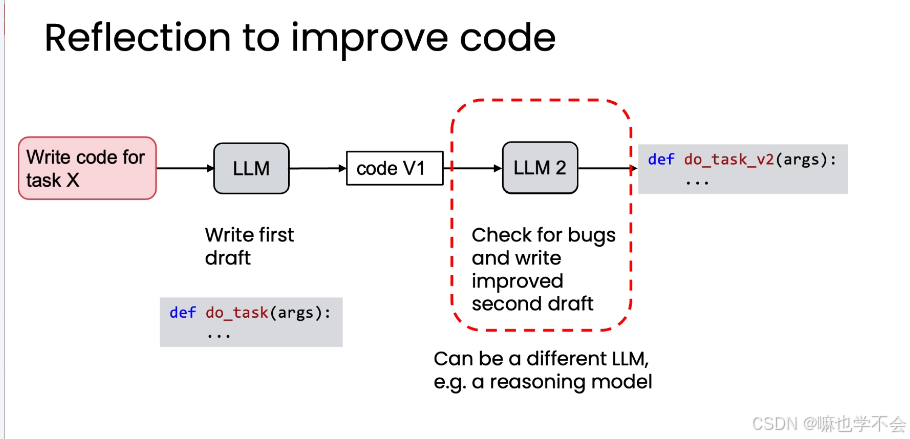
第一层:模型自省
LLM 生成 code V1 → 将 V1 再次输入,提示"检查错误并写出改进版" → 得到修复了潜在 bug 的 V2。
第二层:多模型协作
用一个擅长快速生成的模型写初稿,再用一个擅长逻辑推理的"思考模型"进行反思。不同模型发挥各自优势。
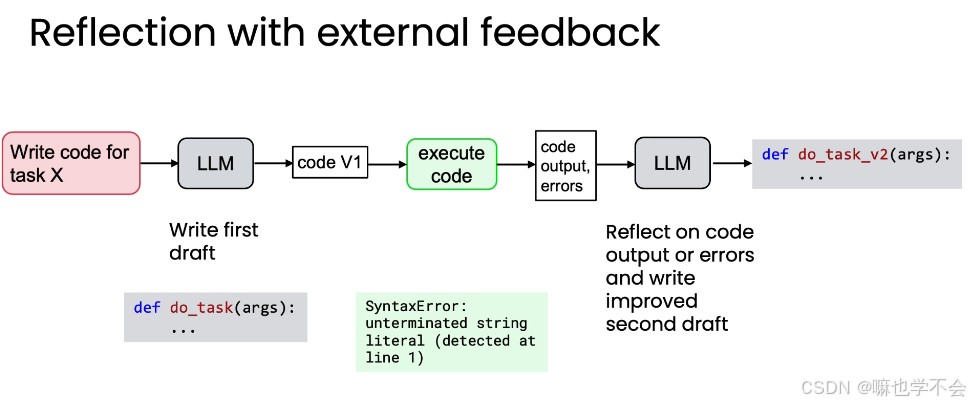
第三层:结合外部反馈(最强形态)
单纯的"内省"有上限。引入外部信息才能带来质的飞跃:
- LLM 生成 code V1
- 在沙盒环境中运行 V1
- 捕获实际输出和错误信息(如
SyntaxError: unterminated string literal) - 将代码 + 输出 + 错误一起交给 LLM 反思
- 基于真实的执行结果修正错误,得到 V2
1.2 2.2 为什么需要反思(而非直接生成)
"直接生成"(Zero-shot)是 LLM 最基础的工作方式:给一个 prompt,一次性完成,中间不修正。看起来简单高效,但反思能在质量上带来"质的飞跃"。
1.2.1 研究证据
论文《Self-refine: Iterative refinement with self-feedback》对比了 7 种任务、4 个模型(GPT-3.5、ChatGPT、GPT-4、Claude)的表现。
结果:在所有任务和所有模型上,加入反思步骤后的性能无一例外地高于直接生成。 即使是最强的 GPT-4,加入反思后也能进一步增强。
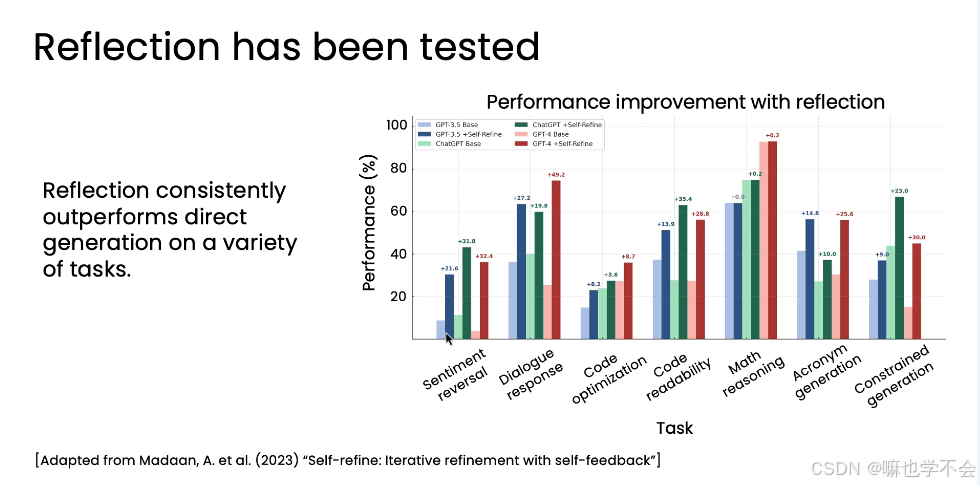
反思不是某个模型的专属能力,而是一个普适的优化策略。
1.2.2 适用场景
反思在以下类型的任务中效果尤其明显:
| 任务类型 | 典型问题 | 反思提示示例 |
|---|---|---|
| 生成 HTML | 格式错误(缺少闭合标签) | "验证 HTML 代码的完整性" |
| 操作流程 | 步骤缺失或顺序错误 | "检查说明的连贯性和完整性" |
| 生成域名 | 有负面含义或难发音 | "域名是否有负面含义?是否易发音?" |
| 代码生成 | 逻辑 bug、边界遗漏 | "检查代码中的错误并写出改进版" |
1.2.3 编写高效反思提示的两条法则
- 明确指示反思动作:不要含糊地说"请改进",而要说"请审查"、"请检查"、"请验证"
- 具体指定检查标准:不要只说"让它更好",而要列出具体的评判维度------"易发音"、"无负面含义"、"语气专业"等

1.3 2.3 实战:图表生成工作流
这个案例展示了反思模式结合多模态 AI 的实际效果:将粗糙的图表初稿迭代优化为专业的可视化作品。
1.3.1 直接生成的问题
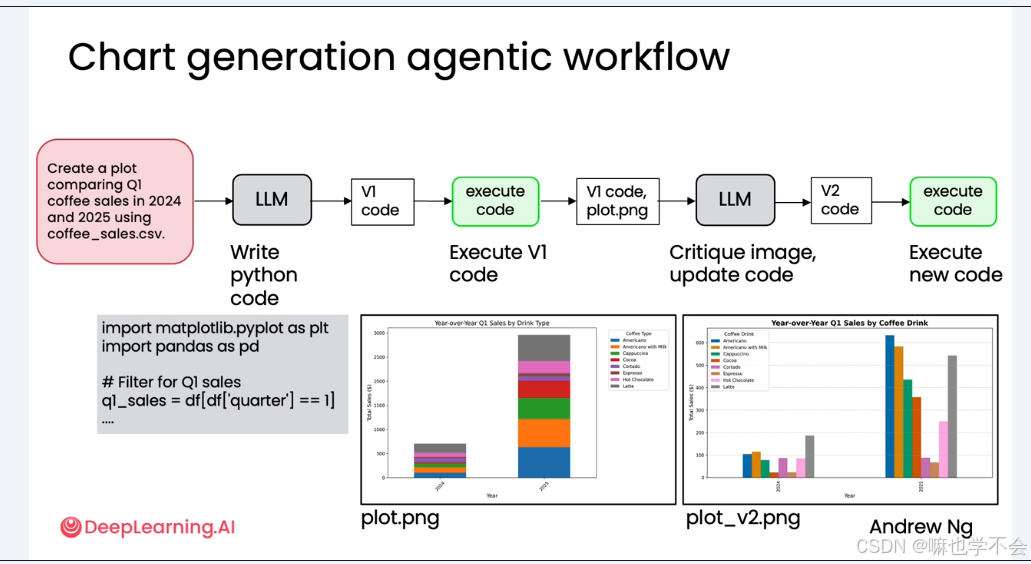
向 LLM 发送提示:"Create a plot comparing Q1 coffee sales in 2024 and 2025 using coffee_sales.csv"
LLM 生成 Python 代码并执行,得到一张堆叠柱状图。问题:
- 堆叠柱状图不适合比较不同年份同一饮品的销量
- 整体观感不专业
1.3.2 引入多模态反思
关键改进:将生成的图片本身作为输入,交给多模态 LLM 进行视觉推理。
流程:
- 将 V1 代码和生成的图表一起打包
- 提示多模态 LLM 扮演"专家数据分析师",评估图表的可读性、清晰度、完整性
- 模型"真正看到"图表后,提出具体改进建议
- 根据建议更新代码,生成 V2
1.3.3 多模型分工
实践中可以用不同模型承担不同角色:
- LLM 1(初始生成) :负责根据用户提示生成第一版代码
- LLM 2(反思阶段) :接收代码 + 图表 + 对话历史,扮演"专家分析师"提供建设性反馈

反思提示语示例:
您是一位专业的数据分析师,能够为可视化提供建设性反馈。
{V1 代码} {plot.png} {对话历史记录}
步骤 1:评估所附图表的可读性、清晰度和完整性。
步骤 2:编写新代码来实现您的改进。
1.4 2.4 评估反思的效果
反思能提升输出质量,但代价是增加计算开销。不能凭感觉决定是否保留反思步骤,必须通过评估来衡量收益。
1.4.1 客观评估(有明确答案的任务)
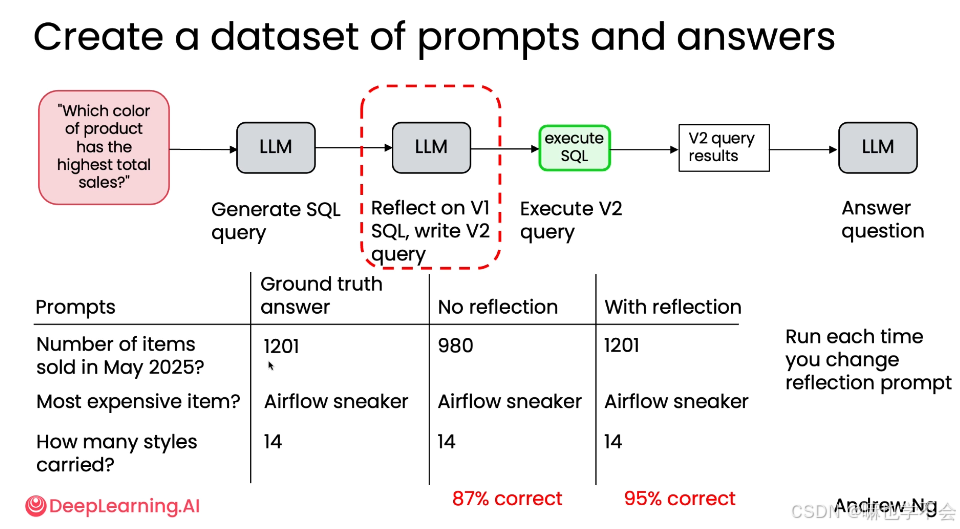
以"SQL 查询生成"为例,构建一个包含"提示词"和"真实答案"的数据集:
| 提示词 | 真实答案 | 无反思 | 有反思 |
|---|---|---|---|
| 2025年5月售出了多少商品? | 1201 | 980 | 1201 |
| 库存中最贵的商品是什么? | Airflow sneaker | Airflow sneaker | Airflow sneaker |
| 我的店铺中有多少款式? | 14 | 14 | 14 |
反思在此任务中带来了 +8% 的正确率提升。对于数据查询这类对准确性要求高的场景,这个提升是有意义的。
建立评估体系后,可以快速迭代:修改反思提示词或初始生成提示词,每次修改后重新运行评估,测量正确率变化,选择最优方案。
1.4.2 主观评估(无明确答案的任务)
图表美观度、清晰度这类标准没有"标准答案"。直接让 LLM 比较两张图并判断"哪个更好"存在已知问题:
- 评判结果不稳定
- 存在位置偏见(倾向选择第一个输入的选项)
更好的方法:使用评分量表(Rubric)
为 LLM 提供结构化的评分标准,让它对每个维度分别打分:
- 是否有清晰的标题?
- 坐标轴是否有标签?
- 图表类型是否合适?
- 坐标轴的数值范围是否恰当?

1.5 2.5 外部反馈:反思的终极形态
1.5.1 提示词工程的收益递减
无论怎么优化提示词,性能增长最终都会进入平台期。反思机制能让性能跃迁到更高的平台,而外部反馈能再次跃升到更高层次。
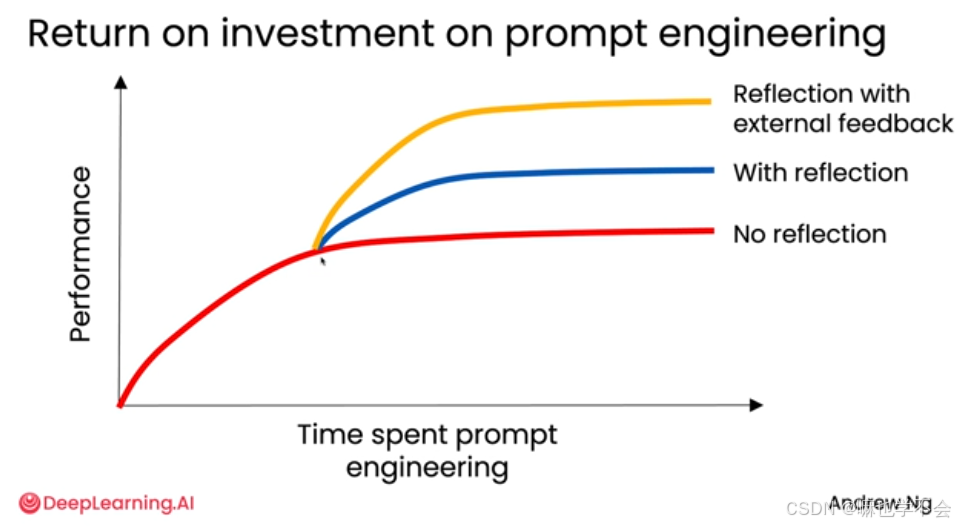
外部反馈的核心价值在于:它为模型注入了训练数据之外的新鲜、实时、客观的信息。
1.5.2 典型外部反馈场景
| 挑战 | 示例 | 反馈来源 | 工作方式 |
|---|---|---|---|
| 提及竞争对手 | "我们的鞋比 RivalCo 好" | 模式匹配(正则表达式) | 扫描输出发现竞争对手名字,要求重写 |
| 事实核查 | "泰姬陵建于1648年" | 网络搜索 | 查询权威资料,将精确信息作为额外输入 |
| 超出字数限制 | 文章超过指定字数 | 字数统计工具 | 统计字数并反馈,要求压缩 |

避免提及竞争对手:用正则表达式扫描输出,若发现竞争对手名字,将其作为批评性输入反馈给模型,要求重写。
事实核查:调用网络搜索 API 核实内容(如泰姬陵实际于1631年下令建造,1648年完工),将精确的时间信息作为额外输入提供给反思模型。
字数控制:编写代码精确统计字数,如果超出限制则将信息反馈给 LLM,要求重新生成符合长度要求的版本。
1.5.3 反思模式的核心要点
- 反思是工程实践,不是魔法------它带来"适度但稳定的性能提升",性价比很高
- 外部反馈是关键------单纯内省有上限,引入外部信息才能突破瓶颈
- 评估是前提------必须通过客观或结构化的主观评估来衡量反思的收益,不能凭感觉