目录
[第一章:RAG 技术概述](#第一章:RAG 技术概述)
[1.1 什么是 RAG](#1.1 什么是 RAG)
[1.2 RAG 的核心目标](#1.2 RAG 的核心目标)
[1.3 RAG 的整体流程](#1.3 RAG 的整体流程)
[1.4 RAG 与传统微调区别](#1.4 RAG 与传统微调区别)
[第二章:RAG 系统架构](#第二章:RAG 系统架构)
[2.1 RAG 架构组成](#2.1 RAG 架构组成)
[2.2 在线推理流程](#2.2 在线推理流程)
[2.3 离线知识入库流程](#2.3 离线知识入库流程)
[3.1 为什么需要文档切分](#3.1 为什么需要文档切分)
[3.2 常见切分策略](#3.2 常见切分策略)
[3.3 Chunk Size 与 Overlap](#3.3 Chunk Size 与 Overlap)
[3.4 切分实践建议](#3.4 切分实践建议)
[第四章:Embedding 嵌入模型](#第四章:Embedding 嵌入模型)
[4.1 什么是 Embedding](#4.1 什么是 Embedding)
[4.2 向量相似度计算](#4.2 向量相似度计算)
[4.3 主流 Embedding 模型](#4.3 主流 Embedding 模型)
[4.4 中文 Embedding 选型](#4.4 中文 Embedding 选型)
[4.5 Embedding 模型评估指标](#4.5 Embedding 模型评估指标)
[5.1 什么是向量数据库](#5.1 什么是向量数据库)
[5.2 主流向量数据库](#5.2 主流向量数据库)
[5.3 向量检索原理](#5.3 向量检索原理)
[5.7 常见索引结构](#5.7 常见索引结构)
[5.8 FAISS 实战特点](#5.8 FAISS 实战特点)
[5.9 Milvus 企业级方案](#5.9 Milvus 企业级方案)
[第六章:检索增强生成(Retrieval + Generation)](#第六章:检索增强生成(Retrieval + Generation))
[6.1 Retriever 检索器](#6.1 Retriever 检索器)
[6.2 Top-K 检索](#6.2 Top-K 检索)
[6.3 Rerank 重排序](#6.3 Rerank 重排序)
[6.4 Prompt Engineering](#6.4 Prompt Engineering)
[6.5 生成阶段](#6.5 生成阶段)
[7.1 项目目标](#7.1 项目目标)
[7.2 技术栈](#7.2 技术栈)
[7.3 系统架构](#7.3 系统架构)
[7.4 环境安装](#7.4 环境安装)
[7.5 文档加载代码示例](#7.5 文档加载代码示例)
[第八章:RAG 高级优化](#第八章:RAG 高级优化)
[8.1 Hybrid Search 混合检索](#8.1 Hybrid Search 混合检索)
[8.2 多路召回](#8.2 多路召回)
[8.3 Query Rewrite](#8.3 Query Rewrite)
[8.4 Parent-Child Chunk](#8.4 Parent-Child Chunk)
[8.5 Agentic RAG](#8.5 Agentic RAG)
[8.6 Graph RAG](#8.6 Graph RAG)
[8.7 其他RAG](#8.7 其他RAG)
[第九章:RAG 项目落地最佳实践](#第九章:RAG 项目落地最佳实践)
[9.1 知识库建设原则](#9.1 知识库建设原则)
[9.2 Chunk 优化](#9.2 Chunk 优化)
[9.3 Prompt 优化](#9.3 Prompt 优化)
[9.4 幻觉控制](#9.4 幻觉控制)
[9.5 性能优化](#9.5 性能优化)
[第十章:RAG 应用场景](#第十章:RAG 应用场景)
[10.1 企业知识助手](#10.1 企业知识助手)
[10.2 智能客服](#10.2 智能客服)
[10.3 法律与医疗](#10.3 法律与医疗)
[10.4 教育培训](#10.4 教育培训)
[10.5 代码知识库](#10.5 代码知识库)
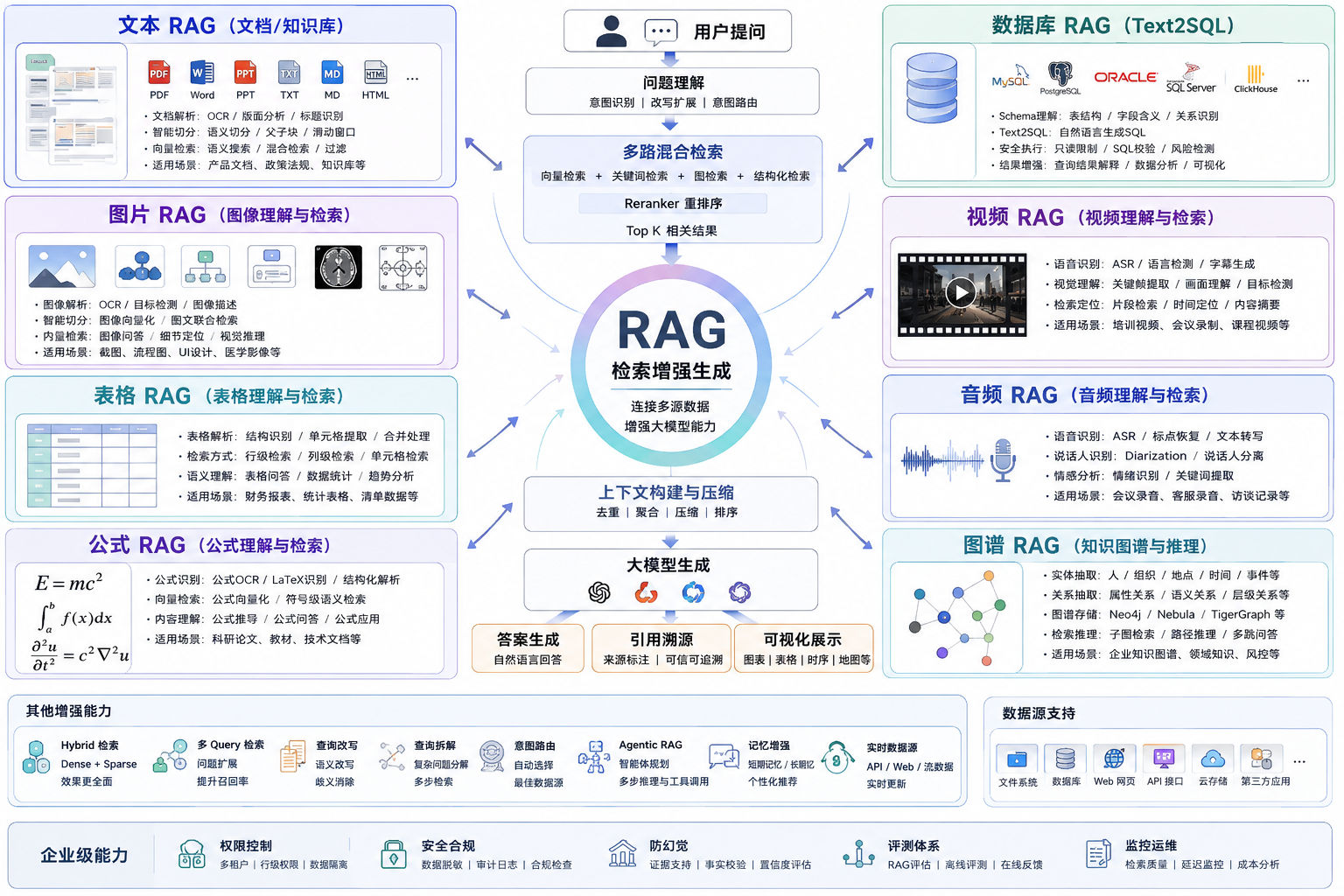
本培训文档系统讲解 RAG(Retrieval-Augmented Generation,检索增强生成)技术的原理、架构、核心组件与工程实践,重点覆盖向量数据库、文档切分、Embedding 嵌入模型、检索增强生成流程以及本地知识库问答系统的构建。
第一章:RAG 技术概述
1.1 什么是 RAG
RAG(Retrieval-Augmented Generation)是一种结合"信息检索"和"大语言模型生成"的技术架构。它通过从外部知识库中检索相关内容,再将结果作为上下文输入大模型,从而解决模型知识过期、幻觉、私有知识缺失等问题。
1.2 RAG 的核心目标
• 解决大模型知识时效性问题
• 支持企业私有知识问答
• 降低模型幻觉
• 提升回答准确率
• 构建企业 AI 助手
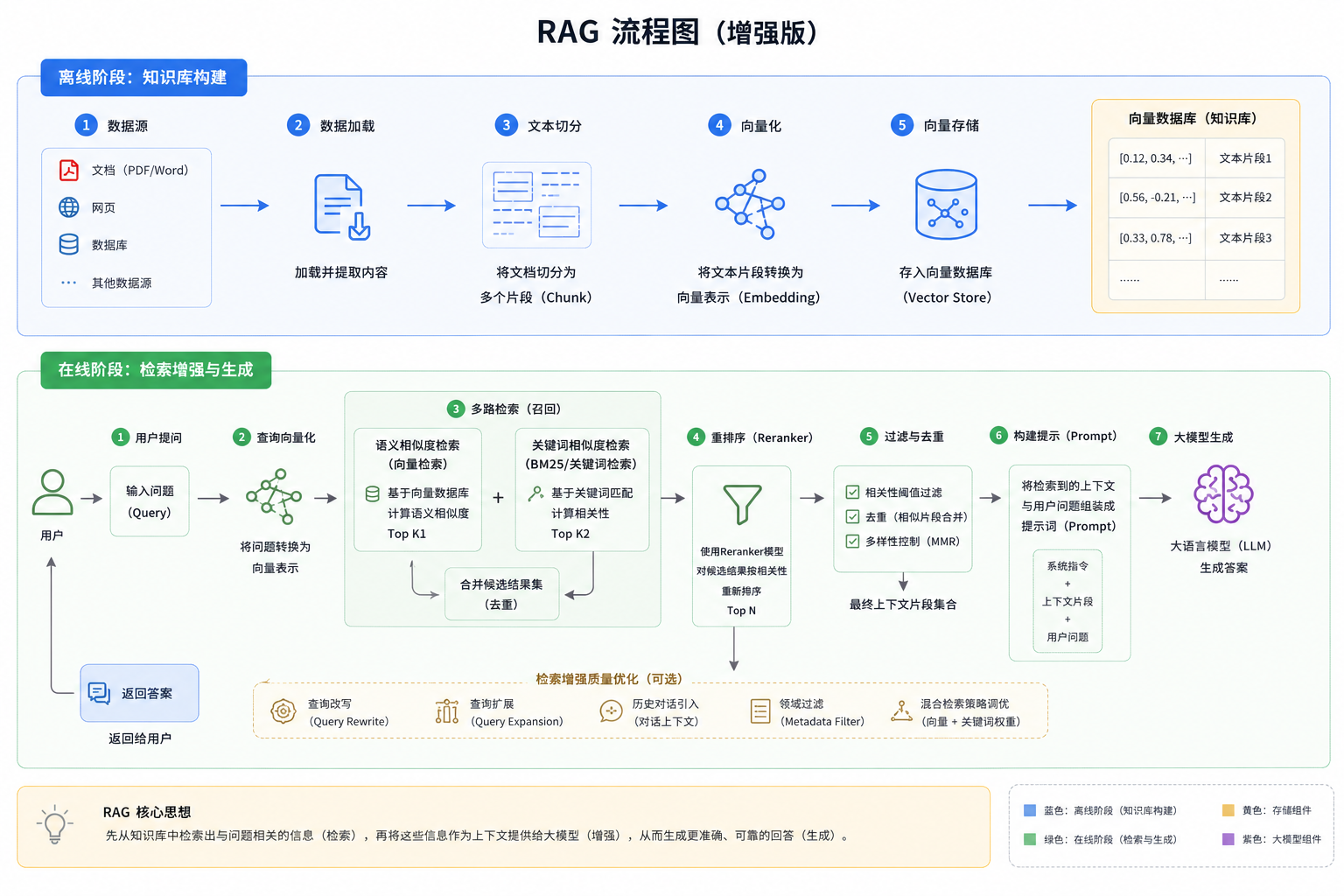
1.3 RAG 的整体流程
用户问题 → 问题向量化 → 向量检索 → 返回相关文档 → 拼接 Prompt → 大模型生成答案
1.4 RAG 与传统微调区别
RAG 不需要重新训练模型,而是通过动态检索知识库增强回答;微调则需要重新训练模型参数。RAG 更适合知识频繁变化的场景。
第二章:RAG 系统架构
2.1 RAG 架构组成
RAG 系统一般包含:
• 文档加载器(Document Loader)
• 文档切分器(Text Splitter)
• Embedding 嵌入模型
• 向量数据库
• Retriever 检索器
• Prompt 模板
• LLM 大语言模型
2.2 在线推理流程
步骤如下:
① 用户输入问题
② 问题进行向量化
③ 向量数据库相似度检索
④ 返回 Top-K 相关片段
⑤ 拼接 Prompt
⑥ LLM 基于上下文生成答案
2.3 离线知识入库流程
原始文档 → 清洗 → 切分 Chunk → Embedding → 写入向量数据库
第三章:文档切分(Chunking)
3.1 为什么需要文档切分
大模型上下文窗口有限,Embedding 模型也存在最大 Token 限制,因此必须对长文档进行切分。
3.2 常见切分策略
• 固定长度切分
• 递归切分
• 按段落切分
• 按语义切分
• Markdown 标题切分
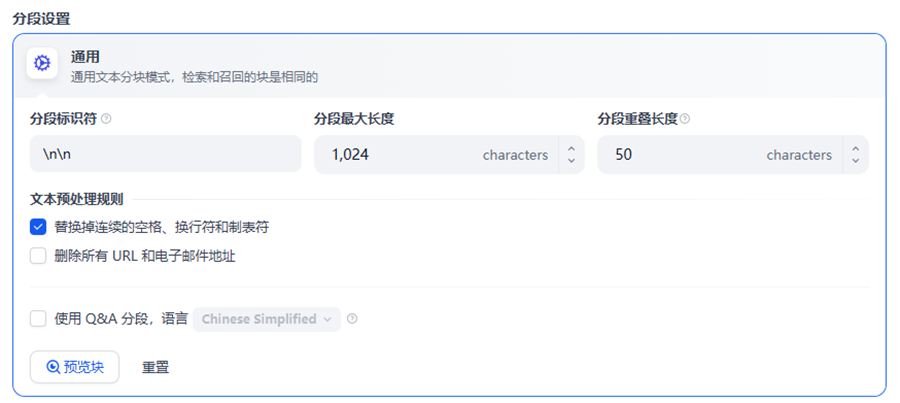
3.3 Chunk Size 与 Overlap
Chunk Size 表示每个文本块大小;Overlap 表示块之间重叠区域。合理的 overlap 可以减少上下文断裂问题。
3.4 切分实践建议
推荐:
• 技术文档:500~1000 tokens
• FAQ:200~500 tokens
• 使用 10%~20% overlap
第四章:Embedding 嵌入模型
4.1 什么是 Embedding
Embedding 是将文本映射为高维向量的过程,使语义相近的文本在向量空间距离更近。
4.2 向量相似度计算
常见算法:
• Cosine Similarity(余弦相似度)
• 欧氏距离
• 点积
4.3 主流 Embedding 模型
• BGE 系列
• Qwen系列
• text-embedding-3-large
• m3e
• E5
• Instructor
4.4 中文 Embedding 选型
中文场景推荐:BGE-large-zh、m3e-large、bce-embedding-base_v1。
4.5 Embedding 模型评估指标
• Recall@K
• MRR
• nDCG
第五章:向量数据库
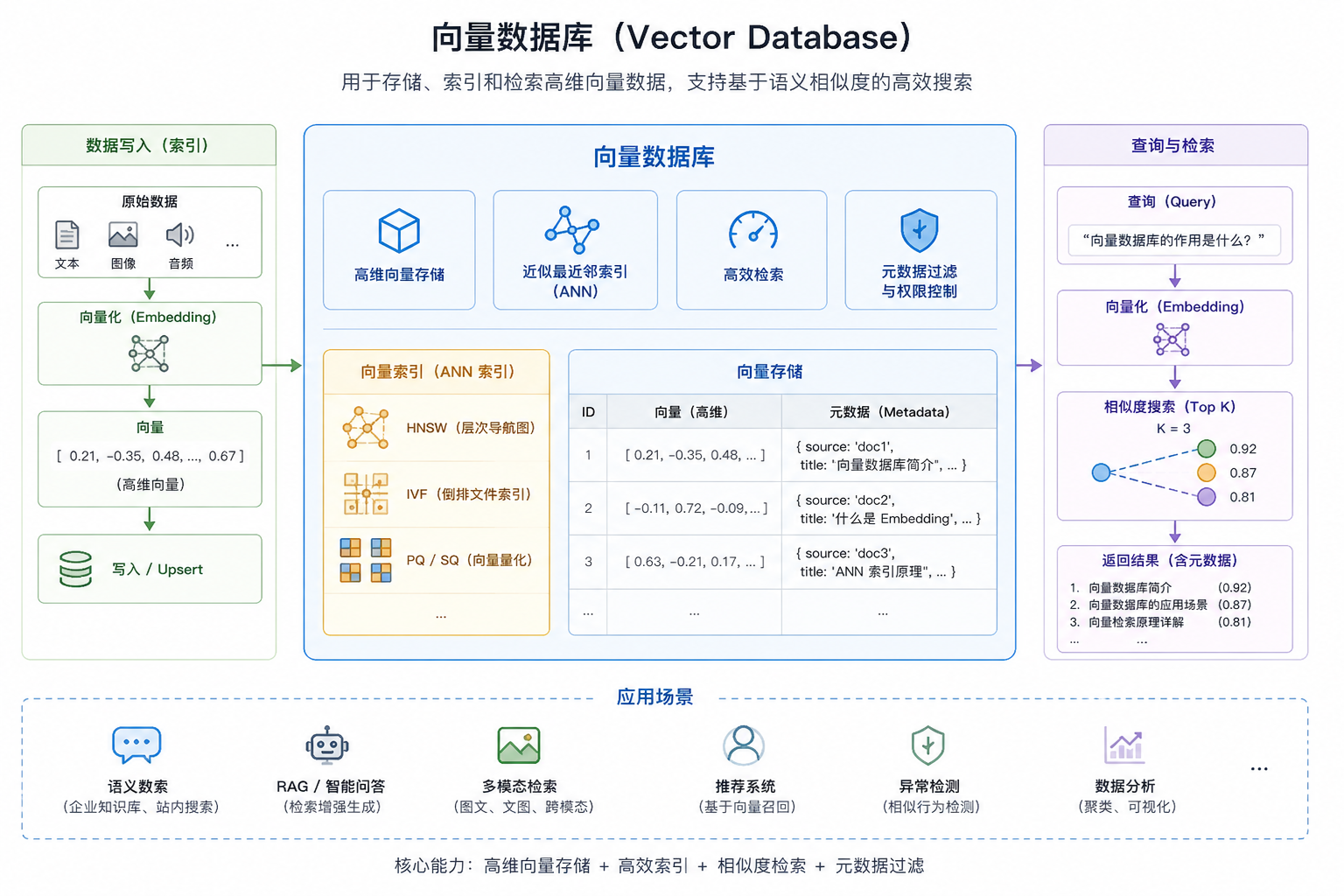
5.1 什么是向量数据库
向量数据库 是专门用于存储、管理、检索高维向量 的专用数据库,主打相似性检索,是 AI、多模态检索、RAG 场景的核心组件。
5.2 主流向量数据库
• FAISS
• Milvus
• Chroma
• Weaviate
• Pinecone
5.3 向量检索原理
核心思想:通过 高效近似最近邻检索(ANN) 算法快速找到与查询向量最相似的 Top-K 向量。
1.向量化:用 Embedding 模型把非结构化数据转为固定维度的稠密向量,语义相近的数据向量距离更近。
2.建索引:对向量构建 ANN 索引,避免全量暴力计算距离,解决 "维度灾难"。
3.相似度计算 :用余弦相似度 / 欧氏距离 / 点积衡量向量距离,返回最相似结果。
4.查询流程:输入→向量化→查索引→算相似度→返回 Top-N。
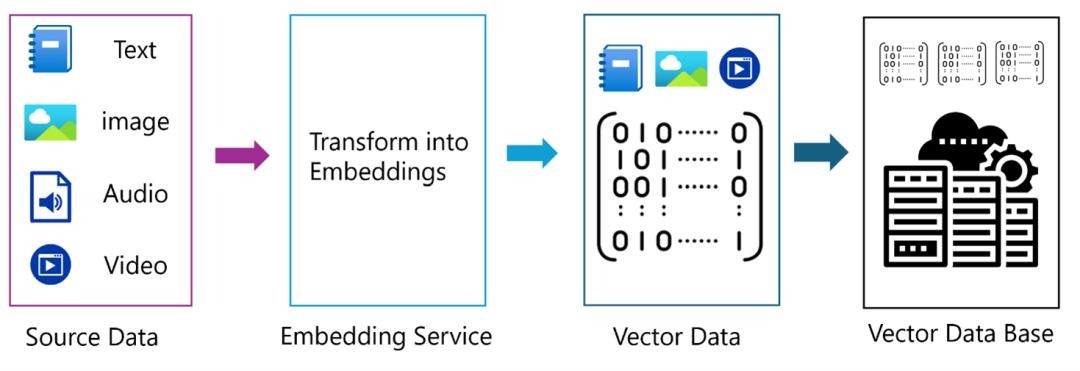
5.4、特点
- 专门存储和检索高维向量(文本 / 图像 / 音频经 Embedding 模型转换的 "数字指纹")。
- 核心能力是相似性搜索(按向量距离找最相似结果),而非传统数据库的精确匹配。
- 采用ANN 近似最近邻索引(如 HNSW、IVF),毫秒级返回海量数据中 Top-K 相似项。
- 天然适配RAG、大模型记忆、多模态检索、智能推荐等 AI 场景。
5.5、优点
- ✅ 语义检索强:理解含义,支持跨模态相似匹配,远超关键词检索。
- ✅ 检索极快:亿级数据毫秒级响应,支撑高并发 AI 应用。
- ✅ 大模型刚需 :提供外部知识库,减少幻觉、实时更新知识。
- ✅ 水平扩展好:分布式架构,易扩容处理海量向量。
5.6、缺点
- ❌ 精度与速度权衡:ANN 牺牲少量召回率换速度;100% 精确则慢。
- ❌ 成本高:高维向量存储 / 计算对硬件要求高,运维复杂。
- ❌ 事务与复杂查询弱:不支持强 ACID、JOIN 与复杂聚合,不适合核心业务库。
- ❌ 生态与标准化不足:产品兼容差,工具链薄弱,向量化可能损失信息。
5.7 常见索引结构
• IVF(倒排文件,分桶)
• HNSW(层次化导航小世界图)
• PQ(乘积量化)
• Flat(精确索引,暴力检索)
5.8 FAISS 实战特点
FAISS 适合本地部署与小规模知识库,部署简单、速度快。
持久化 = 手动 save/load,无事务、无版本、无原生分布式。
5.9 Milvus 企业级方案
Milvus 支持分布式部署、海量向量检索和 GPU 加速。
在 FAISS 之上封装了持久化、元数据、分布式、高可用
第六章:检索增强生成(Retrieval + Generation)
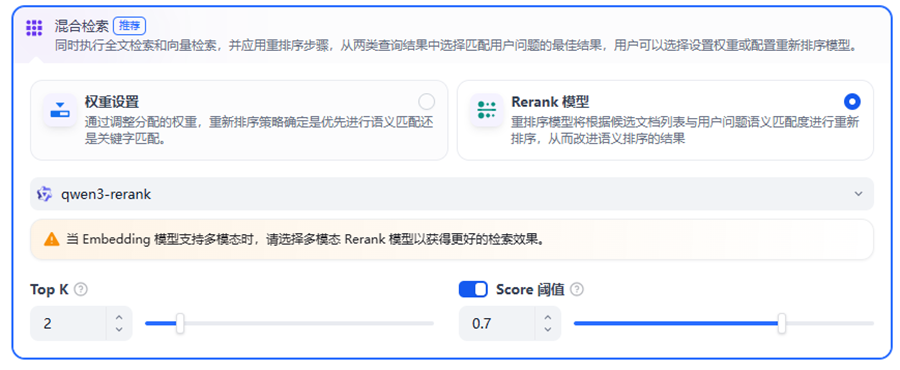
6.1 Retriever 检索器
Retriever 负责从向量数据库中召回相关文档。
6.2 Top-K 检索
一般会返回最相关的 K 个 Chunk。K 值过小可能丢失信息,过大会引入噪声。
6.3 Rerank 重排序
Rerank 模型用于对召回结果再次排序,提高最终相关性。
6.4 Prompt Engineering
Prompt 通常包含:
• 系统角色
• 检索内容
• 用户问题
• 输出要求
6.5 生成阶段
LLM 根据检索结果生成最终回答,实现"带知识依据"的回答。
第七章:本地知识库问答系统实战
7.1 项目目标
构建一个支持 PDF / Word / Markdown 文档问答的本地 RAG 系统。
7.2 技术栈
• Python
• LangChain、LangGraph
• FAISS
• HuggingFace Embedding
• Ollama / OpenAI API
• Streamlit
7.3 系统架构
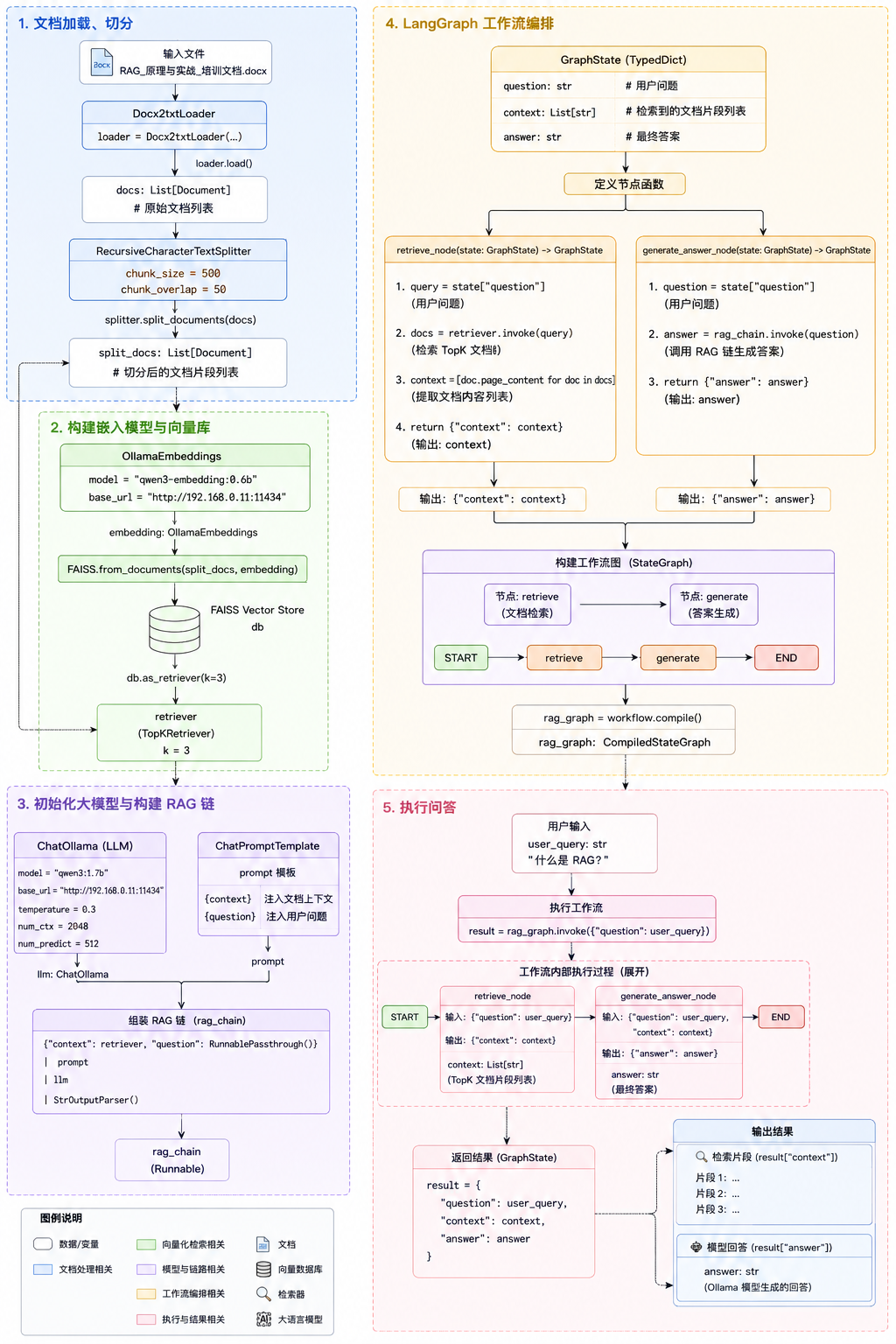
7.4 环境安装
pip install pypdf
pip install docx2txt
pip install langchain
pip install langchain-huggingface
pip install faiss-cpu
pip install sentence-transformers
pip install streamlit7.5 文档加载代码示例
#rag.py
# ===================== 1. 文档加载、切分 =====================
from langchain_community.document_loaders import Docx2txtLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 加载 Word 文档
loader = Docx2txtLoader('RAG_原理与实战_培训文档.docx')
docs = loader.load()
# 文本切分
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
split_docs = splitter.split_documents(docs)
# ===================== 2. 构建 向量检索 + BM25 检索(混合检索核心) =====================
from langchain_ollama import OllamaEmbeddings
from langchain_community.vectorstores import FAISS
# 新增:BM25 稀疏检索 & 混合检索器
from langchain_community.retrievers import BM25Retriever
from langchain_classic.retrievers import EnsembleRetriever
# 2.1 初始化 Ollama Embedding 模型
embedding = OllamaEmbeddings(
model="qwen3-embedding:0.6b",
base_url="http://192.168.0.11:11434"
)
# 2.2 构建 FAISS 向量库 & 向量检索器
db = FAISS.from_documents(split_docs, embedding)
vector_retriever = db.as_retriever(k=3)
# 2.3 构建 BM25 关键词检索器
bm25_retriever = BM25Retriever.from_documents(split_docs)
bm25_retriever.k = 3
# 2.4 混合检索器(EnsembleRetriever 默认使用 RRF 融合)
# weights: [BM25权重, 向量检索权重],可根据业务调整 0~1
hybrid_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.4, 0.6]
)
# ===================== 3. 初始化 Ollama 对话大模型 + 构建 RAG 链 =====================
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_ollama import ChatOllama
# 对话 LLM
llm = ChatOllama(
model="qwen3:1.7b",
base_url="http://192.168.0.11:11434",
temperature=0.3,
num_ctx=2048,
num_predict=512
)
# RAG 提示词
prompt = ChatPromptTemplate.from_template("""
你是专业的知识库问答助手,请严格根据下方参考文档内容回答用户问题。
如果文档中没有相关信息,请直接回答:「知识库中未查询到相关内容」,不要编造答案。
### 参考文档:
{context}
### 用户问题:
{question}
请给出简洁、准确的回答:
""")
# 组装 RAG 链路:替换为 混合检索器
rag_chain = (
{"context": hybrid_retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# ===================== 4. LangGraph 工作流编排 =====================
from langgraph.graph import StateGraph, START, END
from typing import TypedDict, List
# 定义流转状态
class GraphState(TypedDict):
question: str
context: List[str]
answer: str
# 检索节点:使用混合检索
def retrieve_node(state: GraphState) -> GraphState:
print("【执行节点:混合检索(BM25 + 向量)】")
query = state["question"]
docs = hybrid_retriever.invoke(query)
context = [doc.page_content for doc in docs]
return {"context": context}
# 答案生成节点
def generate_answer_node(state: GraphState) -> GraphState:
print("【执行节点:答案生成】")
question = state["question"]
answer = rag_chain.invoke(question)
return {"answer": answer}
# 构建图
workflow = StateGraph(GraphState)
workflow.add_node("retrieve", retrieve_node)
workflow.add_node("generate", generate_answer_node)
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "generate")
workflow.add_edge("generate", END)
rag_graph = workflow.compile()
# ===================== 5. 执行问答 =====================
if __name__ == "__main__":
user_query = "什么是 RAG?"
print(f"用户提问:{user_query}\n" + "="*60 + "\n")
result = rag_graph.invoke({"question": user_query})
# 输出结果
print("="*60)
print("🔍 混合检索召回片段:")
for idx, text in enumerate(result["context"], 1):
print(f"\n片段{idx}:\n{text}")
print("\n" + "="*60)
print("🤖 Ollama 模型回答:")
print(result["answer"])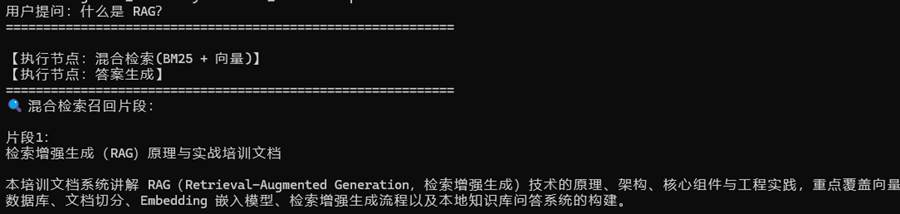

第八章:RAG 高级优化
8.1 Hybrid Search 混合检索
8.1.1定义
融合BM25 关键词检索 与向量语义检索两种方式联合检索,综合两者优势提升召回效果。
两类检索特点
- BM25:基于字词匹配,精准匹配关键词、专有名词,擅长字面命中
- 向量检索:依托语义相似度匹配,理解同义、转述语句,擅长语义匹配
其中,
TF-IDF :TF-IDF = 词频 (TF) + 逆文档频率 (IDF),是文本检索、关键词权重 经典算法,常和倒排索引搭配使用。结合词在单篇文档的出现频次、在全部文档的稀有度计算权重,用来评判词语重要性、给检索结果排序;缺点是词频会无限累加,长文档容易占优。
BM25:TF-IDF 的优化版本,限制词频过度增长,还加入文档长度做归一化,排序效果更合理,是现在检索系统主流算法。工业界(Elasticsearch)现在默认用 BM25。
8.1.2工作流程
- 分别用 BM25、向量检索独立召回候选文本
- 对两份结果加权打分、融合排序
- 去重筛选,输出最终有效检索片段
8.1.3核心优势
- 兼顾字面精准度与语义理解能力
- 有效提升召回覆盖率,减少信息遗漏
- 适配口语、专业术语、同义改写各类提问
8.1.4应用定位
RAG 基础主流检索方案,常作为多路召回的基础检索单元。
8.2 多路召回
8.2.1定义
多路召回:使用 ** 多种不同检索器(Retriever)** 并行检索文档,汇总多来源结果,扩大信息覆盖范围。
8.2.2核心作用
规避单一检索器局限,减少信息漏召,提升检索素材完整度。
8.2.3常见检索器类型
- 稠密向量检索:语义相似度匹配
- 稀疏关键词检索:字词精准匹配
- 图谱检索:实体关系关联召回
- 层级索引检索:按目录、章节召回
8.2.4工作流程
- 拆分查询语句
- 多个检索器同时独立召回候选文本
- 合并、去重、筛选多路结果
- 送入后续排序、推理、生成环节
8.2.5优势
- 兼顾字面关键词与深层语义
- 覆盖不同结构文档,召回更全面
- 降低单一检索算法缺陷带来的遗漏
8.2.6适用场景
复杂问答、长文档检索、混合格式知识库 RAG 系统
8.3 Query Rewrite
8.3.1定义
Query Rewrite :对用户原始提问做优化改写、扩写、拆分、补全、纠错,提升检索召回精度与覆盖度,让检索更容易匹配到有效文档。
8.3.2核心目的
- 修正口语化、歧义、残缺、错别字问题
- 补充隐含语义、关键词、限定条件
- 拆分复杂长问句,适配检索模型
- 统一表述措辞,贴合知识库文本用语
- 减少无效检索,拉高答案准确率
8.3.3常见改写方式
- 口语转书面
口语:帮我查下夏天去哪玩
改写:夏季适合出游的目的地推荐
- 补全缺失信息
原问:这款手机续航咋样
改写:该型号手机电池续航能力与使用时长
- 歧义消歧义
原问:苹果价格
改写:新鲜苹果市场售价 / 苹果手机售价
- 关键词扩充同义词
原问:如何减肥
改写:科学瘦身方法、减脂饮食运动技巧
- 复杂问句拆分
原问:公司营收和利润同比变化及原因
拆为:公司年度营收同比变化、利润变动成因
- 纠错修正
原问:人工智能发张趋势
改写:人工智能行业发展趋势
- 泛化 / 细化调整
太宽泛:历史名人故事 → 细化:唐代著名诗人生平故事
太细碎:今早 8 点地铁 3 号线客流 → 泛化:工作日早高峰地铁客流量
8.3.4在 RAG 中的作用
- 原始问句模糊简短,检索极易漏资料
- 重写后关键词更匹配索引库,召回相关上下文
- 搭配 Graph RAG 时,重写实体、关系表述,方便图谱检索推理
8.3.5简单流程
用户原始提问 → 语义理解 → 纠错 / 补词 / 扩义 / 拆分 → 生成多条优化查询 → 批量检索 → 汇总结果生成回答
8.3.6典型应用场景
智能问答、文档检索、搜索引擎、知识库查询、电商商品搜索
8.4 Parent-Child Chunk
通过父子块机制兼顾检索精度与上下文完整性。
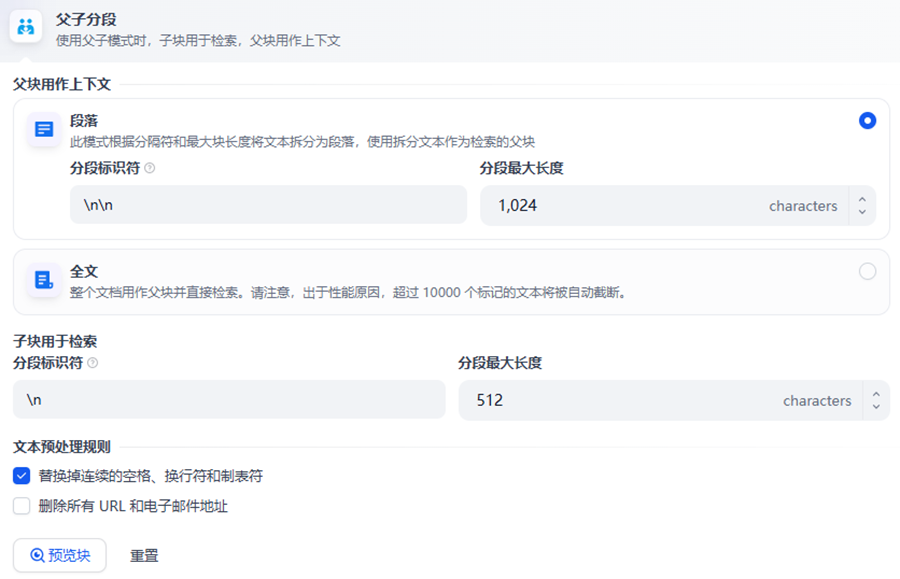
8.4.1核心定义
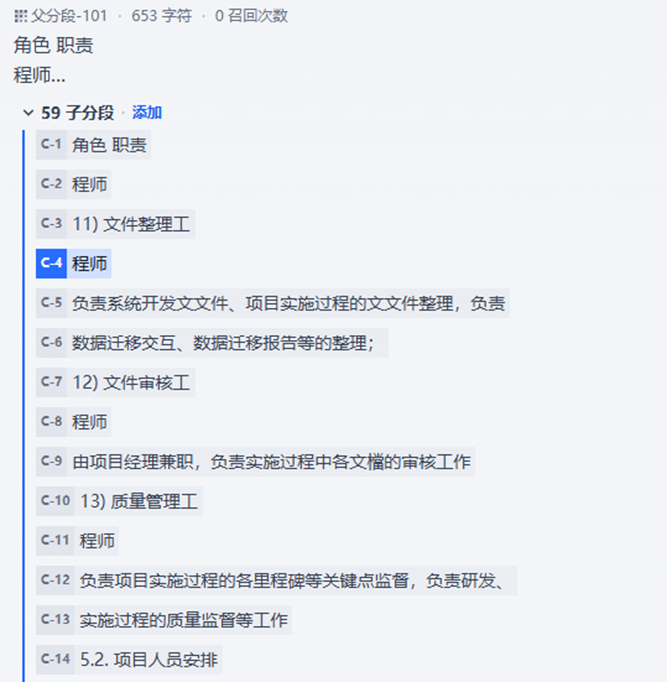
父子块是双层文档切片策略 ,把文档切分为父块(大块)和子块(小块),兼顾检索精准度与上下文完整性,解决普通固定切块的短板。
8.4.2切块规则
父块 Parent:分片尺寸大,保留完整语义、整段上下文,用于最终答案拼接、保证内容连贯。
子块 Child :分片尺寸小,粒度精细,用于向量检索匹配,提升召回准确率。
8.4.3工作流程
- 文档先切分成大尺寸父块
- 每个父块再二次细分成多个小尺寸子块
- 仅把子块向量化存入向量库,检索时用子块精准匹配相关片段
- 命中子块后,反向溯源归属的原始父块
- 用完整父块上下文给到大模型,生成通顺完整回答
8.4.4解决的痛点
- 小块检索:精准但上下文残缺,回答断章取义
- 大块检索:语义完整但匹配粗糙,容易召回无关内容
- 父子块:子块搜得准,父块看得全,两全兼顾
8.4.5优缺点
优点
- 检索召回精度更高
- 回答上下文完整,逻辑连贯
- 减少语义割裂、信息丢失
- 适配长文档、专业文档 RAG 场景
缺点
切片、存储、检索溯源开销略高于普通切块
8.4.6和普通单一切块对比
- 普通切块:固定大小一层切片,精度和完整性只能二选一
- 父子切块:双层联动,精准检索 + 完整上下文同时满足
8.4.7适用场景
企业知识库、技术文档、合同论文、长培训文档等对回答完整性、准确性要求高的 RAG 问答。
8.5 Agentic RAG
结合 Agent 能力,实现复杂任务推理。
8.5.1核心定义
Agentic RAG = 智能代理 + 检索增强生成
在传统 RAG 只做查资料、答问题基础上,加入 Agent 自主决策、规划、工具调用、多步推理能力,处理复杂多轮任务。
ReAct = Reason + Act (推理 + 行动)
是 Agent 最经典的决策运行模式。
核心原理
- Reason 推理:思考当前问题、判断缺什么信息、该做什么动作
- Act 行动:调用工具、检索、查询、执行操作
- 循环往复:推理→行动→观察结果→再推理,直到解决问题
8.5.2传统 RAG 局限
只能单次检索、单次问答,没法拆解复杂问题,不会主动思考步骤。
8.5.3Agentic RAG 核心能力
- 问题拆解:把复杂大题拆成多个小子问题
- 自主规划:判断需要查哪些文档、调用什么工具
- 多轮检索:一次查不到就多次补充检索资料
- 逻辑推理:整合多份信息推导结论
- 自我校验:判断答案是否够用,不足继续补查
8.5.4运行流程
- 接收复杂提问
- Agent 分析问题,拆分执行步骤
- 按需调用 RAG 检索知识库资料
- 多轮搜集、汇总信息
- 逻辑推理整合答案
- 输出完整可靠回复
8.5.5适用场景
多条件查询、资料对比、流程推理、复杂业务答疑、连环问题解答。
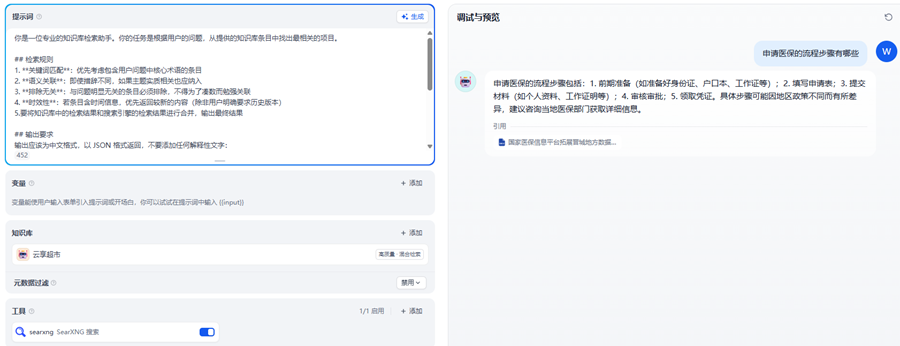
8.5.6部署searxng搜索引擎:
docker compose up -d
#docker-compose.yml
version: "3.8"
services:
searxng:
image: searxng/searxng:latest
container_name: searxng
restart: always
ports:
- "8080:8080"
volumes:
- ./config:/etc/searxng
- ./cache:/var/cache/searxng
dns:
- 223.5.5.5
- 114.114.114.114
environment:
- SEARXNG_BASE_URL=http://0.0.0.0:8080/
- SEARXNG_UWSGI_WORKERS=4
redis:
image: redis:alpine
container_name: searxng-redis
restart: always
volumes:
- ./redis-data:/data
#settings.yml
general:
debug: false
instance_name: "SearXNG"
privacypolicy_url: false
donation_url: false
contact_url: false
enable_metrics: true
open_metrics: ''
brand:
docs_url: https://docs.searxng.org/
public_instances: https://searx.space
wiki_url: https://github.com/searxng/searxng/wiki
issue_url: https://github.com/searxng/searxng/issues
search:
safe_search: 0
autocomplete: ""
autocomplete_min: 4
favicon_resolver: ""
default_lang: "auto"
ban_time_on_fail: 5
max_ban_time_on_fail: 120
suspended_times:
SearxEngineAccessDenied: 180
SearxEngineCaptcha: 3600
SearxEngineTooManyRequests: 180
cf_SearxEngineCaptcha: 1296000
cf_SearxEngineAccessDenied: 86400
recaptcha_SearxEngineCaptcha: 604800
formats:
- html
- json
server:
port: 8080
bind_address: "0.0.0.0"
base_url: false
limiter: false
public_instance: false
secret_key: "GTH6DXtR0sj1LiAD9yxyz39YWnFvw"
image_proxy: false
http_protocol_version: "1.0"
method: "GET"
default_http_headers:
X-Content-Type-Options: nosniff
X-Download-Options: noopen
X-Robots-Tag: noindex, nofollow
Referrer-Policy: no-referrer
valkey:
url: redis://redis:6379/0
ui:
static_path: ""
templates_path: ""
query_in_title: false
default_theme: simple
center_alignment: false
default_locale: ""
theme_args:
simple_style: auto
search_on_category_select: true
hotkeys: default
url_formatting: pretty
outgoing:
request_timeout: 3.0
pool_connections: 100
pool_maxsize: 20
enable_http2: true
plugins:
searx.plugins.calculator.SXNGPlugin:
active: true
searx.plugins.hash_plugin.SXNGPlugin:
active: true
searx.plugins.self_info.SXNGPlugin:
active: true
searx.plugins.unit_converter.SXNGPlugin:
active: true
searx.plugins.ahmia_filter.SXNGPlugin:
active: true
searx.plugins.hostnames.SXNGPlugin:
active: true
searx.plugins.time_zone.SXNGPlugin:
active: true
searx.plugins.tracker_url_remover.SXNGPlugin:
active: true
categories_as_tabs:
general:
images:
news:
it:
engines:
- name: baidu
baidu_category: general
categories: [general]
engine: baidu
shortcut: bd
disabled: false
- name: baidu images
baidu_category: images
categories: [images]
engine: baidu
shortcut: bdi
disabled: false
- name: baidu kaifa
baidu_category: it
categories: [it]
engine: baidu
shortcut: bdk
disabled: false
doi_resolvers:
oadoi.org: 'https://oadoi.org/'
doi.org: 'https://doi.org/'
sci-hub.se: 'https://sci-hub.se/'
sci-hub.st: 'https://sci-hub.st/'
sci-hub.ru: 'https://sci-hub.ru/'
default_doi_resolver: 'oadoi.org'8.6 Graph RAG
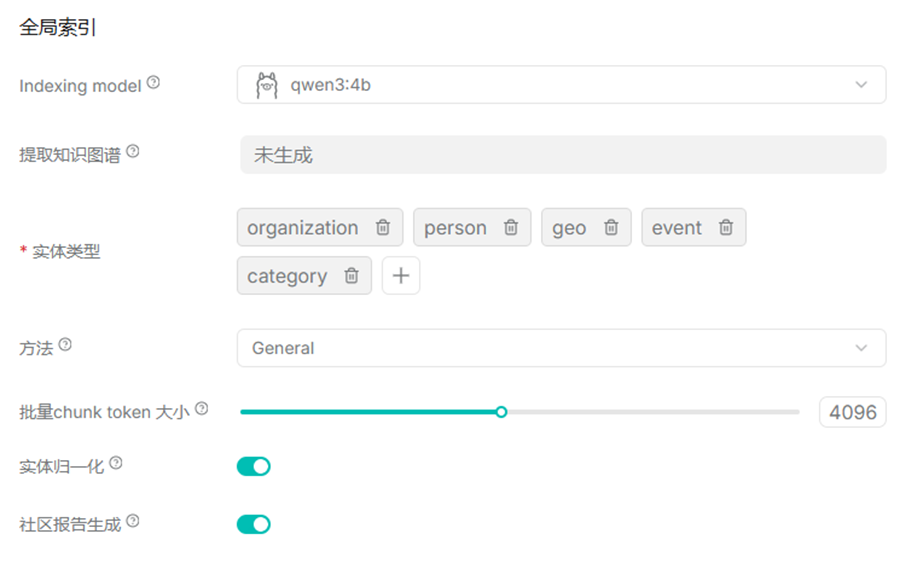
8.6.1基础定义
Graph RAG = 图检索增强生成,是RAG 检索增强生成 结合知识图谱 的进阶架构,核心用图谱的实体、关系、层级结构,替代传统纯文本检索,实现语义 + 关系双重推理。
核心组成:知识图谱
8.6.2知识图谱是结构化网状数据,基础三元组格式:
( 头实体,关系,尾实体)
例:(李白,朝代,唐朝)
图谱存储实体、属性、关联链路,天然自带逻辑关联。
结合知识图谱做关系推理的核心原理
- 传统 RAG 短板
只检索零散文本片段,无法识别实体关联、因果、从属、上下级关系,容易逻辑断裂、事实错乱。
- Graph RAG 改进逻辑
把文本信息结构化存入知识图谱,检索不再找段落,而是遍历图谱节点与关系链路,顺着实体关联推导隐藏信息。
- 关系推理三类常见形式
- 直接推理:匹配三元组,直接调取已知关系
- 链路推理:多跳关系推导,A→B→C,推出 A 与 C 隐含关系
- 属性推理:依托实体属性、分类层级做逻辑判断
8.6.3Graph RAG 完整工作流程
- 文档图谱化
非结构化文本抽取实体、关系、属性,构建知识图谱。
- 查询实体解析
用户提问拆解出核心实体、意图关系。
- 图谱检索 + 关系遍历
在图谱中匹配实体,沿着关联关系做多跳游走检索。
- 逻辑关系推理
根据链路推导隐藏事实、因果、从属、对比关系。
- 图谱信息拼接
把推理出的结构化关系转为自然语言上下文。
- 大模型生成回答
依托带逻辑关系的图谱信息输出精准答案。
8.6.4核心优势
- 具备逻辑推理能力,不再局限表面文本理解
- 解决实体关联、溯源、因果类复杂问题
- 大幅减少事实幻觉,关系链路可溯源校验
- 支持多轮、多跳深度问答
8.6.5简单实例
提问:李白和杜甫是什么关系?
- 抽取实体:李白、杜甫
- 图谱匹配关系:(李白,好友,杜甫)、(二人,朝代,唐朝)
- 关系推理:推导二人同为唐代诗人、诗坛挚友
- 模型输出带逻辑关系的回答
8.6.6应用场景
智能问答、医疗诊断推理、金融风控关联分析、人物 / 事件溯源、法律条文关系检索、企业股权关系查询。
8.7 其他RAG
RAG-Anything (多模态RAG, 文本、图片、表格、公式):https://github.com/HKUDS/RAG-Anything
MinerU (面向大模型、检索增强生成、智能体业务流的高精度文档解析引擎,支持将 PDF、Word、PPT、Excel、图片、网页解析为结构化 Markdown / JSON 格式):
https://github.com/opendatalab/MinerU

OpenDataLoader PDF(一个开源的 PDF 解析工具,能从任意 PDF 中提取 Markdown、JSON 和 HTML 格式数据,在基准测试中排名第一(准确率 0.907),支持本地确定性解析和 AI 混合模式处理复杂页面、扫描件 OCR、表格公式等,适合 RAG 场景。)
https://github.com/opendataloader-project/opendataloader-pdf
8.8未来趋势
第九章:RAG 项目落地最佳实践
9.1 知识库建设原则
• 数据结构化
• 去重清洗
• 定期更新
9.2 Chunk 优化
Chunk 不宜过大,否则检索噪声增加。
9.3 Prompt 优化
明确要求"仅基于提供资料回答"。
9.4 幻觉控制
增加引用来源与可信度约束。
9.5 性能优化
• 批量向量化
• GPU 加速
• 缓存检索结果
第十章:RAG 应用场景
10.1 企业知识助手
企业制度、产品文档、研发知识问答。
10.2 智能客服
FAQ 自动问答与工单辅助。
10.3 法律与医疗
专业领域知识检索与辅助生成。
10.4 教育培训
教学资料智能问答。
10.5 代码知识库
代码仓库问答与 API 检索。
总结
RAG 已成为企业级大模型应用的重要架构。通过"检索 + 增强 + 生成"模式,可以有效解决大模型知识时效性与幻觉问题。随着 Hybrid Search、Graph RAG、Agentic RAG 等技术发展,RAG 将在企业 AI 场景中发挥越来越重要的作用。