缓存不仅是单独的组件,还是计算机系统长期对抗速度差的产物。
一、引言:速度差和缓存的基本逻辑
计算机系统中一直都存在部件速度不匹配的问题。
CPU比内存快几个数量级,内存比磁盘快几个数量级。
网络络延迟的范围很大:数据中心内部访问可能只需要几微秒,而跨地域访问往往达到数十到数百毫秒,甚至超过本地磁盘访问延迟。
而从部件的设计目标和底层物理原理来看,这种速度差几乎是天然存在的:
CPU是为了计算而生的,其上集成大量晶体管,通过逻辑门实现与非、或非、加法器等基本计算单元,晶体管开关和门级延迟是几皮秒、几十皮秒量级。
磁盘是为了低成本、大容量的持久性存储而生的。
早期机械硬盘需要磁头在旋转盘片上读写磁畴,磁头需要进行寻道和旋转等待,因此访问延迟通常在毫秒级。
现在流行的SSD虽然使用电子存储,延时较机械硬盘有量级的提升,但因为它的NAND的擦写、电荷泵、页块管理以及FTL映射等机制,所以它的访问延迟通常在几十到上百微秒量级。
从存储层次的角度看,内存可以看作是磁盘数据的缓存角色。
它让数据离CPU更近、被访问得更快。内存通过电容充放电临时保存数据,能够在成本、容量和速度之间取得折中,提供GB级容量和纳秒级访问延迟。
这些部件的技术基因决定了它们的速度天然不在一个量级上。如果完全依赖慢速部件自身变快,系统性能就会长期受制于最慢的部件。
不过,工程师们发现了一个重要规律:程序执行时的数据访问不是随机的,而是具有局部性的特征。
- 时间局部性:刚用过的数据,后面很可能再被用到。
- 空间局部性:刚用过的数据旁边的数据,也可能被用到。
所以工程师们不再追求让所有数据都同样快,而是让经常用的数据先快起来。
这就是缓存的核心思想:缓存不是简单的"拿空间换时间" , 而是 利用局部性原理,用一小块快速介质存放热点数据,让大多数访问绕过慢速部件。
如果数据的访问完全随机,那么缓存没有任何意义。正因为访问行为存在可利用的统计规律,缓存才真正有效。
从CPU到数据库,从CDN到大模型,缓存技术的历史,就是不断发现新的局部性、构造新的缓存层,并承受新的系统代价的过程。
缓存的本质,并不是存的更快,而是尽量少搬数据。
二、硬件缓存时代:在 CPU和内存之间加一层
1965年,剑桥大学的计算机科学家Maurice Wilkes在论文《Slave Memories and Dynamic Storage Allocation》中,首次提出了现代CPU Cache的雏形概念。
当时的主存是磁芯存储器(磁芯),速度慢但便宜,Wilkes的方案是用少量高速磁芯或晶体管存储器做从属,Wilkes给它取了个名字,叫Slave Memory(从属存储器):
从属存储器会自动缓存从低速主存读取的数据,并在局部性有效期间尽可能保留,后续再次访问时无需重复访问慢速主存。
由于从属存储器容量远小于主存,无法永久保存所有数据,必须在硬件中内置替换覆写算法,通过替换策略动态淘汰低热点数据。
在访问局部性良好的场景下,大部分被访问过的数据能长期留在高速从属存储器中,显著提升系统整体运行速度。实际提速幅度取决于程序的内存访问统计特征。
在文章中,描述Slave Memory的缓存方案用到的"标记位 Tag、缓存命中 / 缺失、写回策略、程序局部性、动态替换",全部沿用至今,是Cache技术的理论源头。
那么现代计算机的Cache方案是怎么样的呢?
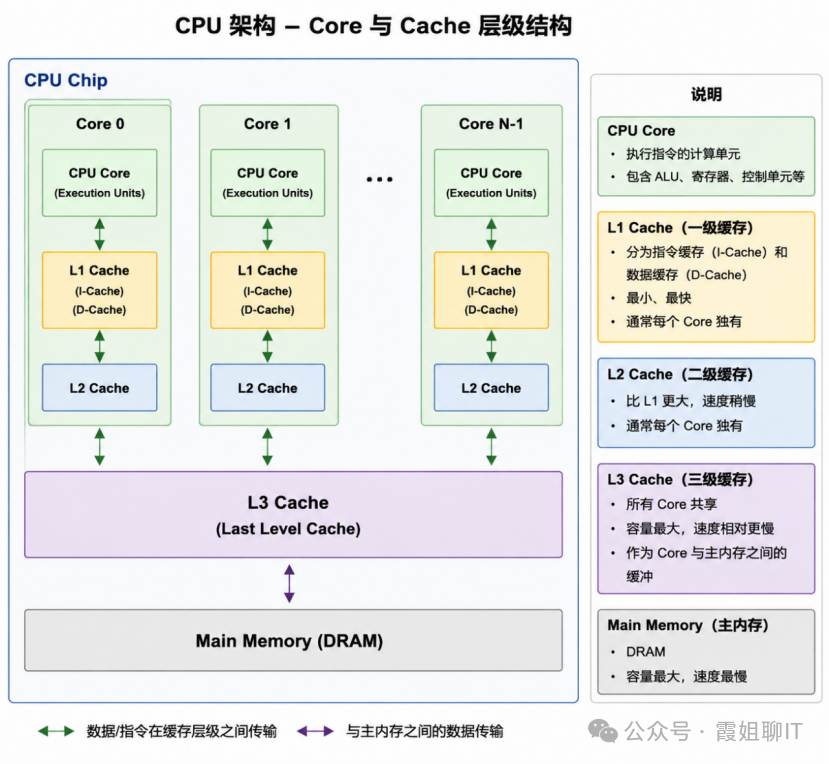
现代计算机一般都是多核CPU,在 CPU 内部,每个 Core(核心)都包含独立的执行单元,用于完成指令计算、逻辑运算与数据处理。CPU引入多级缓存机制来减少访存时延。
****- L1 Cache(一级缓存)****位于距离Core 最近的位置,每个Core独享。通常分为指令缓存和数据缓存。速度最快、容量最小。
****- L2 Cache(二级缓存)****通常也由单个Core 独享,容量比L1更大,但访问速度略慢。可用于缓存更多热点数据。
****-L3 Cache(三级缓存)****是Last Level Cache(LLC),通常由所有 Core 共享。容量最大,用于减少多个Core访存时的带宽压力,提高多核协同效率。
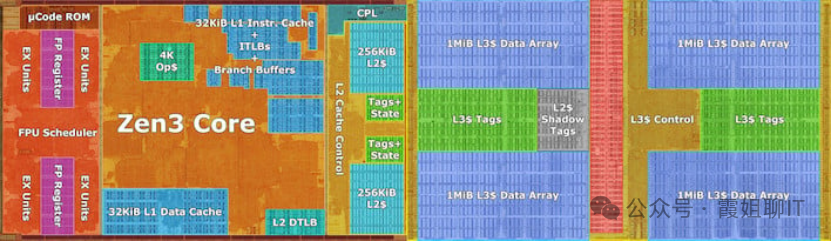
我们来直观看下CPU上的缓存的物理形态吧!
下图是AMD Zen3 CPU Core 的 Die Shot芯片裸片显微图。
左边橙色部分是CPU Core的计算单元。
离计算单元最近的是各32KB的L1 数据缓存和L1 指令缓存。
中间有一片区域是512KB的L2 缓存,右边有非常大一片区域用于4MB的L3缓存。
可以看到CPU芯片面积的一大半都被用于缓存了,这就是CPU为了速度愿意付出的面积代价。
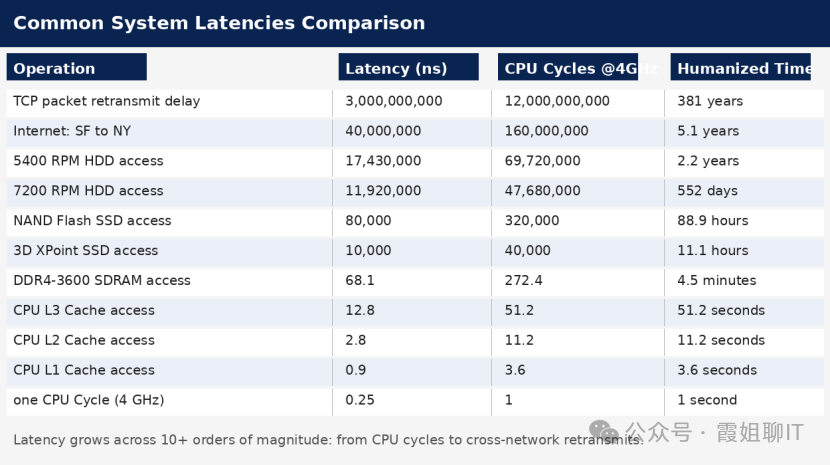
读者们可以通过下表感受一下计算机内部的访存时延量级。
不过,缓存虽好,也带来了两个经典问题:
1. 缓存一致性问题 ( Cache Coherence )
在多核 CPU 中,当多个Core同时缓存同一份数据时,就可能出现:
一个Core修改了数据,而另一个Core仍然在使用旧缓存数据。
这就会导致:数据不一致、并发行为不可预测等麻烦。
例如:
Core0:
x = 1
Core1:
while(x == 0)
如果 Core1 的缓存里一直是旧值 0,程序可能永远循环。
因此现代 CPU 必须实现MESI、MOESI、MESIF等Cache Coherence Protocol(一致性协议)。这些协议能保证多个Core看到的数据一致。
MESI协议通过缓存行状态(Modified/Exclusive/Shared/Invalid)和监听机制,让每个Core在修改数据前,先通知其他Core失效其副本。
这也是为什么多线程同步(锁、原子操作、memory barrier)本质上很多时候是在和 Cache coherence 系统协同工作的原因。
如果没有缓存一致性协议,程序员将被迫对所有共享变量使用'禁用缓存'的访问方式,性能将退化到原始内存访问级别。
2. 如何写 缓存友好程序 (Cache Friendly Programming)
程序员在编程时,需要考虑到局部性、以及缓存的特征:
CPU并不是按变量缓存数据,而是按 Cache Line(通常64B)为单位进行缓存和传输,
才能开发出性能好的软件。
缓存优化能力是写出高性能代码的核心能力。
(1)空间局部性
连续访问的数据更容易被缓存。
比如对数组的访问最好采用顺序访问的形式。
因为数组是连续存储的,而CPU通常会按整个Cache Line进行预取和缓存,所以后续元素已经在缓存里了,所以对它的访问会更快。
而随机访问会导致Cache Miss增加,所以CPU会不断等待从DRAM获取数据进缓存,因此CPU会频繁停顿等待内存数据返回。
(2)时间局部性
刚访问过的数据,很可能马上再次访问。
例如:
sum += x;
sum += x;
sum += x;
变量 x 会一直留在 Cache 中。
因此:重复使用热点数据、减少大范围扫描都会提升性能。
(3)Cache Line 与伪共享
多个线程即使修改不同变量,只要这些变量落在同一个 Cache Line 中,CPU 仍然会不断同步缓存。这叫:False Sharing(伪共享)。
伪共享会严重降低并发性能。
这种情况可采用padding(缓存行填充)对齐数据结构,避免线程共享邻近变量的方法来处理。
再说的具体一点:
比如两个线程分别频繁修改x和y,而x和y在同一个64字节的Cache Line里。每次修改x,另一Core的缓存行就失效,导致性能下降几倍到几十倍。
Padding让它们分开到不同Cache Line,问题消失。
所以,现代高性能编程已经不只是看算法复杂度,而更需要同时考虑内存访问模式和Cache 行为这些实际工程特点。