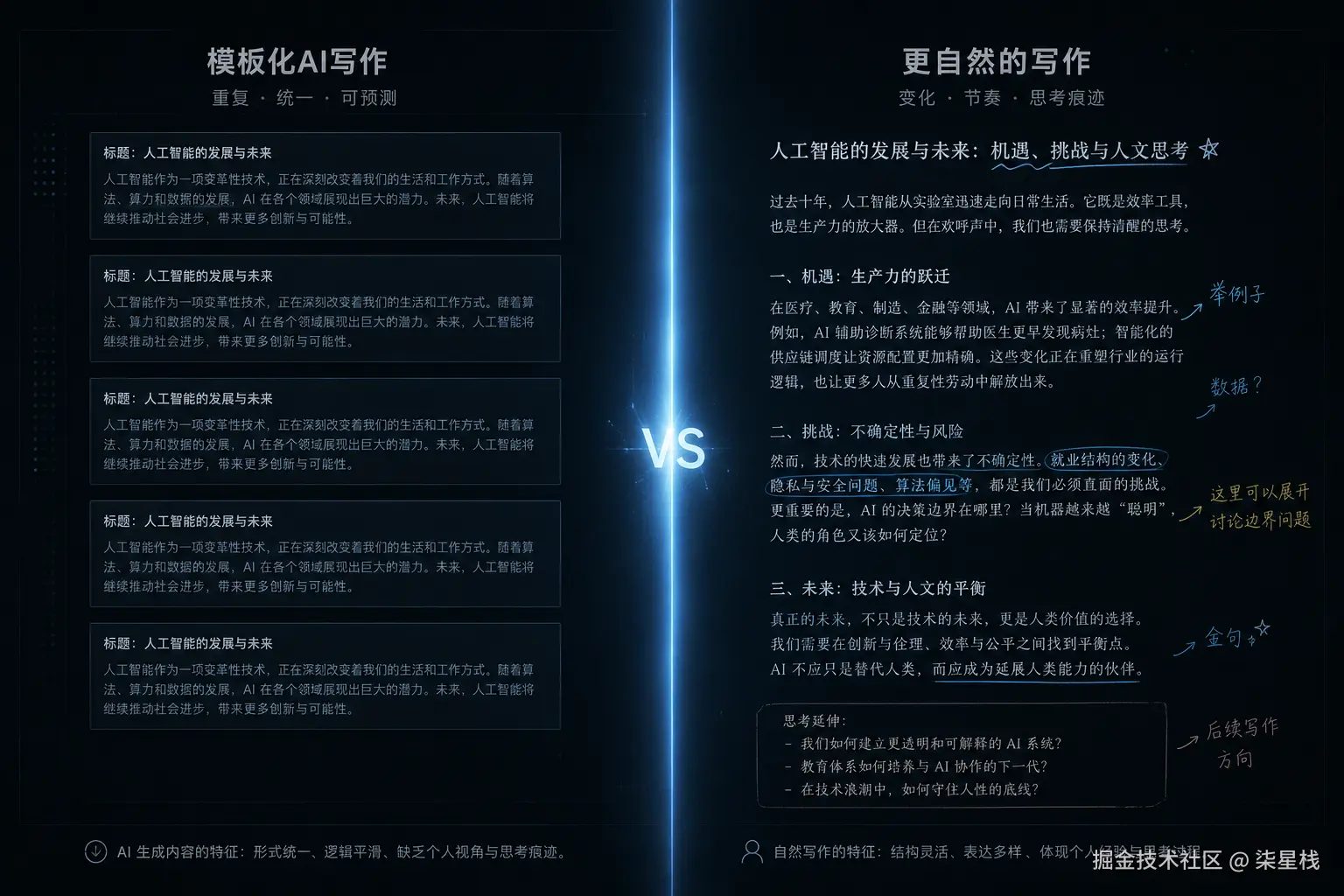
导语
很多人烦的,不是 AI 参与写作。
烦的是另一种情况:文章看着挺完整,语气也稳,像那么回事,可你读着总觉得不对。它不一定有明显错误,但就是轻、空、没抓手,你很难信它。
stop-slop 被盯上,背后说的就是这件事。
这已经不是文风问题了。它碰到的,是信任。
先圈定范围:这篇只聊文字写作。
外部讨论里的 AI slop ,范围更大。The Conversation 的定义是:AI 工具生成的视频、图像、音频、文本,或者混合形式。本文只聚焦一个子集:AI 生成的文字,为什么越来越让人看着发腻。
一、stop-slop 是什么
GitHub 仓库:hardikpandya/stop-slop
项目描述:
"A skill for removing AI tells from prose."
它不是新模型,也不是写作平台。
按 README 和 skill 页面说明,它本质上是一个 skill file。可放入 Claude Code、Claude Projects,或嵌入其他 LLM 的系统提示词。
关键语句:
"This skill teaches Claude (or any LLM) to catch and remove them."
翻译:让模型自己识别、自己擦掉暴露 AI 痕迹的句子习惯。

边界说明
README 也写了别的用法。核心规则可直接拷进 custom instructions。也就是说,它不只有"AI 改 AI"这一条路径------人也可以手动按规则改稿。
结论:它通常是把一套写作约束注入模型,但这套东西也可以被人直接拿来当编辑清单。
作者在公开社交平台提到,项目获得 3200+ GitHub stars 。
(说明:此处为作者公开自述数据,本文未直接核 GitHub 实时星标。)
为什么被关注
原因很直接:
很多人不只想让 AI 帮自己写,他们还不想让别人看出来是 AI 帮的。
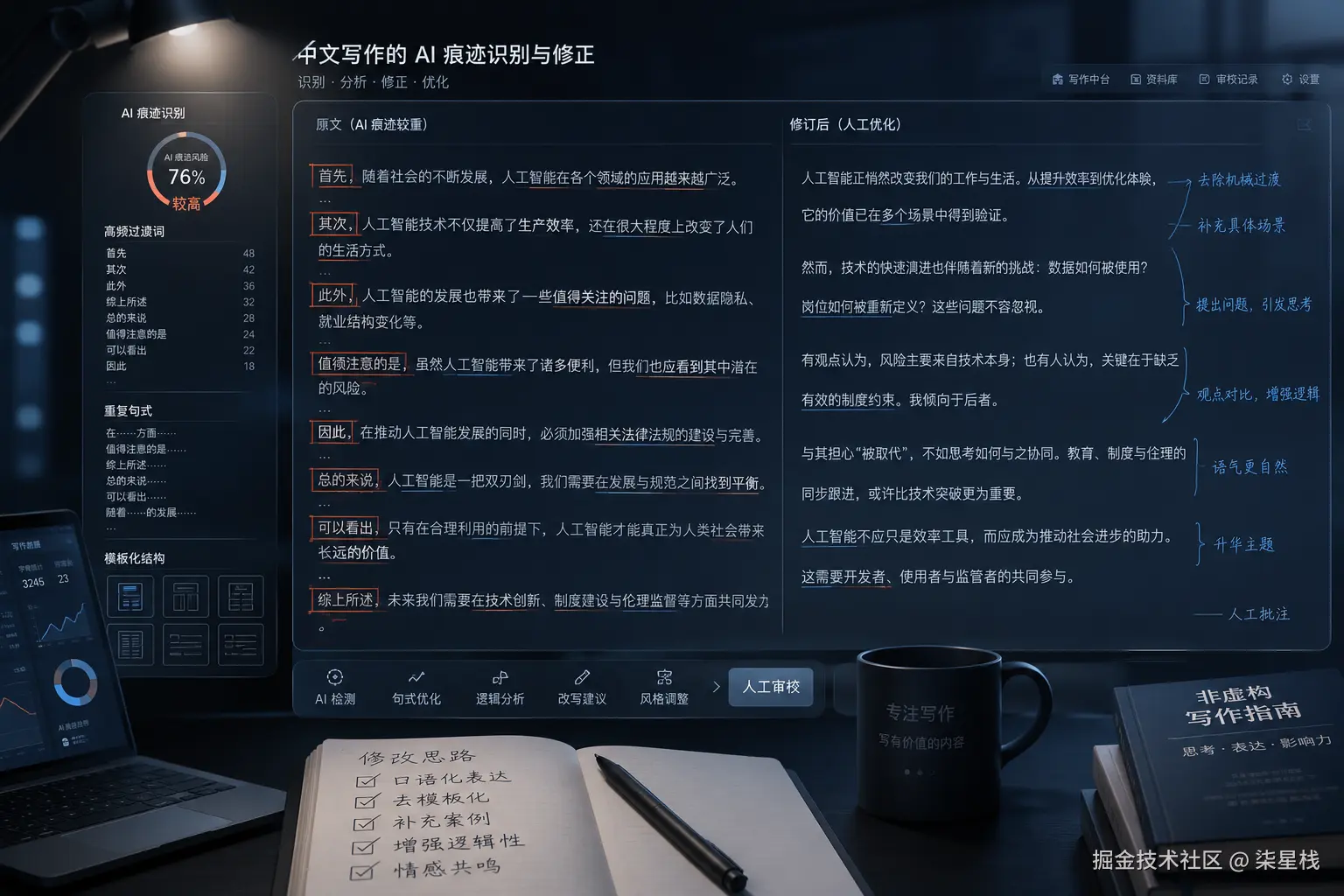
二、它到底在改什么
从公开材料看,stop-slop 有两层结构:
- 核心写作规则
- 五维评分量表
版本差异
一些公开介绍页和早期描述写的是 seven core rules 。
当前 GitHub 主分支 SKILL.md 已编号到 8 条:
- Cut filler phrases
- Break formulaic structures
- Use active voice
- Be specific
- Put the reader in the room
- Vary rhythm
- Trust readers
- Cut quotables
结论:早期"seven core rules"的说法已过时,当前版本以八条为准。
评分量表
作者公开写法中,5 个维度:
- directness
- rhythm
- trust
- authenticity
- density
每项 1--10 分,满分 50。
阈值:低于 35 分,需要修订。
谁执行什么
- 核心规则 → 模型执行,按规则改写
- 评分量表 → 人类执行,判断文本是否达标
关键维度:trust 和 density
- trust:这段话能不能让人信
- density:这段内容到底有没有料
这两个维度说明一件事:stop-slop 不只是让文字"像人",它在设计上承认 AI 文本的问题不止于口气------还在于看起来完整、实际发空。
代表规则
- cut adverbs
- use active voice
- be specific
三条规则都很基础,但打点精准:
- 副词多 → 句子虚
- 被动多 → 动作主体消失
- 不具体 → 滑入"好像什么都说了,其实什么都没钉住"
典型问题短语(可核查)
- "Here's the thing:"
- "Let that sink in."
- "This matters because"
- "Navigate"
- "Unpack"
- "That's the thing."
- "And that's okay."
问题不在于它们一定错。问题在于它们容易变成一种写作姿态:先摆出"我要讲重点了",再慢慢填内容。
典型原文示例(节选)
"Here's the thing: building great products is hard. It turns out that most teams struggle with alignment, communication, and execution. The best teams lean into discomfort and navigate the complex landscape of product development with purpose. The uncomfortable truth is that most product advice is generic. People tell you to 'move fast' and 'talk to users' without unpacking what that actually means. ..."
为什么典型:
- "Here's the thing" → 典型开场姿态
- "navigate""unpack" → 高频问题词
- "The uncomfortable truth is" → 像观点,实际只是抬语气
- 整段像在分析,落地信息不多
项目专门处理的几类问题
- throat-clearing openers:先清嗓子,再说话
- binary contrasts:工整的二元对立,把句子写得像模板
- emphasis crutches:靠语气抬分量,细节没跟上
这三类不是一回事。
stop-slop 比普通"润色提示词"更值得讨论的地方:它不只是删套话,它在处理一种更隐蔽的问题------文本没说出多少新内容,却一直在摆出"我正在说重要话"的姿态。
(本文不逐字复写完整 before/after 对照,只保留可稳定核对的原文段落和修改方向。)

三、它为什么会被注意到
如果只是文风老套,stop-slop 不会被这么多人盯上。
来源: Reuters Institute, 2024-11-26
"AI-generated slop is quietly conquering the internet. Is it a threat to journalism or a problem that will fix itself?"
这篇文章引了 Wachter 和 Mittelstadt 关于 careless speech 的讨论。
careless speech 的定义:一种对真假、精确性和表达责任都不太上心的说话方式。输出可能很顺、很像答案、很有把握,但未必真的在认真对待真实世界。
接上 Harry Frankfurt 的判断:危险的不只是说谎的人,更麻烦的是那种根本不在乎真假的人。
法律维度
Wachter 和 Mittelstadt 讨论的不只是"读者会不会烦",而是:大语言模型是否可能负有说真话的法律义务。
回到 stop-slop
如果一种工具的主要作用是:把 careless speech 的表面痕迹修得更顺、更像人工表达------那它做的就不只是"让文章更好看"。更严一点说,它可能在妨碍人们识别和追责低责任、甚至潜在违法的输出。
结论:这件事不能只当文风问题看。它涉及信任,再往前一步,涉及责任识别。

四、The Conversation 的定义
作者:Adam Nemeroff
关键词:
- little regard for accuracy
- attention economy
翻译:很多 AI slop 不需要做到高质量。它只要够快、够便宜、够像点东西、够抓住几秒注意力,就会不断冒出来。
它不是靠深度赢。
它靠的是 "差不多也能发"。
放到文字写作上,stop-slop 被留意到就不奇怪了。不是大家突然更爱写作了,而是大家已经被一堆"差不多也能发"的东西围住了。
五、修复还是遮掩
更准确的判断:
- 从机制看:stop-slop 更像"遮掩痕迹的工具"
- 从流程看:如果人类作者后续自己补事实、补判断、补责任,它才可能在局部起到修复作用
两层不能混。
- 机制层:压痕迹、修口气、提观感
- 流程层:如果作者没把事实核实、论证深度和表达责任接回来,它只是在帮空心文本变得更难识别
- 只有当作者把后续判断与核查接回来,它才可能从"遮痕迹"转为"修草稿"
结论:stop-slop 不是天然的修复器。它默认更像遮掩痕迹的工具。能不能变成修复器,不取决于它自身,取决于人类作者后续有没有把责任接回来。

六、实际用途
stop-slop 的用处,就这么几项:
- 减痕迹:压掉明显的 AI 套路
- 提可读性:让模板化草稿不那么僵
- 做检查:用五维评分框架审稿
它补不了:
- 事实
- 现场
- 独立判断
- "你到底有没有东西可说"
最稳妥的说法不是"它能让 AI 写得像人"。
而是:它可以让 AI 写出来的内容没那么像 AI。
这个差别不小。
七、"像样的废话"的定义
边界说明:
不是技术文档、学术综述、法律文书,也不是格式规范的新闻稿。这些文本可以没情绪,但不能没责任。
这里说的"像样的废话"是:
形式合格,信息重复,判断空心,对事实和语境的责任投入不足。
它看着像文章。
但它不承担文章该承担的东西。
八、中文语境的相关性
GitHub Issues 中已有人提出:
"Chinese version of stop-slop --- different AI tells for Chinese prose."
说明"去AI味"不是英语写作的小圈子焦虑。已经有人意识到,中文也有自己的 AI 痕迹,且未必和英文一样。
以下为基于中文写作经验的观察(非项目文档定义):
- 结构过分整齐
- 过渡词太熟
- 安全判断太多
- 看起来像在输出,实际上没有具体语境
前提条件
如果"中文版 stop-slop"只是拿来遮掩痕迹,那它和英文版面对的是同一个问题。
它的价值只在一种情况下成立:先帮中文作者看清 AI 文本最容易犯的毛病,后面的核实、删改和判断再由人自己接手。
不然,它只是把遮掩做得更本地化。
九、衍生项目
GitHub 上已出现同方向衍生项目:
stephenturner/skill-deslop(科学写作方向)jalaalrd/anti-ai-slop-writing(多 agent 通用场景)
说明"去 AI 写作痕迹"不是孤立技巧,已有人在复制、迁移、重写这套思路。
当前数据不足以证明已形成"生态",更稳妥的说法:已有同方向衍生项目。
十、总结
stop-slop 值得讨论,不是因为它能把 AI 文本变成人类作品。
它值得讨论,是因为它把一个问题照亮了:
很多人已经不只想让 AI 代写,他们还希望在 AI 代写之后,生成的内容不会被轻易识别出来。
从工具机制看,stop-slop 更像帮模型学习一套贴近人类写作的表面规范。
放进完整写作流程,它能不能产生正面价值,取决于作者有没有把核实、判断和责任接回来。
真正让人不安的,不是 AI 会写。
而是越来越多人开始接受这种写法:
内容可以不真实,判断可以不深入,细节可以不够充分,只要看起来别太像 AI 就行。
stop-slop 没制造这个问题。
但它把这个问题照得更亮了。
参考来源
- Pandya, Hardik. stop-slop . GitHub, github.com/hardikpandy.... Accessed 28 May 2026.
- Pandya, Hardik. "SKILL.md." stop-slop , GitHub, github.com/hardikpandy.... Accessed 28 May 2026.
- Pandya, Hardik. "New Claude Skill: Stop AI Slop in Your Content." Substack , hardik.substack.com/p/new-claud.... Accessed 28 May 2026.
- "Stop Slop." Claude Code Marketplaces , claudemarketplaces.com/skills/hard.... Accessed 28 May 2026.
- "AI-generated slop is quietly conquering the internet. Is it a threat to journalism or a problem that will fix itself?" Reuters Institute for the Study of Journalism , 26 Nov. 2024, reutersinstitute.politics.ox.ac.uk/news/ai-gen.... Accessed 28 May 2026.
- Nemeroff, Adam. "What is AI slop? A technologist explains this new and largely unwelcome form of online content." The Conversation , 2 Sept. 2025, theconversation.com/what-is-ai-.... Accessed 28 May 2026.
- Turner, Stephen. skill-deslop . GitHub, github.com/stephenturn.... Accessed 28 May 2026.
- Jalaalrd. anti-ai-slop-writing . GitHub, github.com/jalaalrd/an.... Accessed 28 May 2026.