背景
目录
想要入门深度学习算法,首先可以从代码阅读开始。那么多文件,不知道从何看起,因此写下这个教程提供给后面的人学习,也给自己一个静下心来复习的机会。什么叫学习,学习知识相当于学武功,学武功除了要学基本功再就是学招式,什么是深度学习的基本功呢,那肯定是代码的阅读能力,能够看懂代码,能够写出代码。有了基本功之后,剩下的就是招式。把招式连上上百遍,练成肌肉记忆,就像你走路的时候不用想先迈出哪一只脚一样简单。李小龙在 1971 年接受皮埃尔·伯顿(Pierre Berton)专访时曾对此做出过完整的阐述:"The ideal is unnatural naturalness, or natural unnaturalness."(理想的状态是不自然的自然,或是自然的不自然)。他进一步解释道,这是"自然本能"与"后天控制"的成功结合。任何一方走向极端都不行:纯粹凭本能会显得原始,而完全靠控制则会变成机械人。只有将两者和谐地融为一体,才是真实的、流动的"人"。学习也是这样,学而习之,学了之后不断地练习,不断地练习,就像与生俱来的一样。这样才能真正的掌握住要学习的东西。以此套方法去实践,只要是人类创造的东西,基本上都能学会。自闭症能够弹钢琴,失去手臂的人能够吃饭和写字以及用手机,甚至游泳。这些都是通过大量的练习,使得练习的动作成为很自然的事情。所以我们学习任何一门知识和技能,很多时候都不是看一下就会,瞅一眼就懂,这是很正常的,不断地练习,让大脑有一个熟悉的过程,建立长久记忆,成为自己身体的一部分。这样我们就达成了学习最终的目的,也成为了更好一点的自己。
项目预览
我现在拿到的是MapDiffuion这个项目,https://github.com/tmonnin/mapdiffusion
可以看到顶层内容,包括:
bash
plugin/
tools/
resources/
mmdetection3d/
README.md
requirements.txt大纲总览
建议从"训练入口 → 配置文件 → 数据集 → 模型 → loss/评估"这条线开始。这个项目是基于 MMDetection3D 风格组织的,最适合按一次训练流程去读。
建议顺序是:
1. 先看 README.md
了解项目目标、数据集、训练命令、配置文件入口。
这一步不用抠细节,只要知道它大概在做什么:MapDiffusion / StreamMapNet / HD map vector prediction。
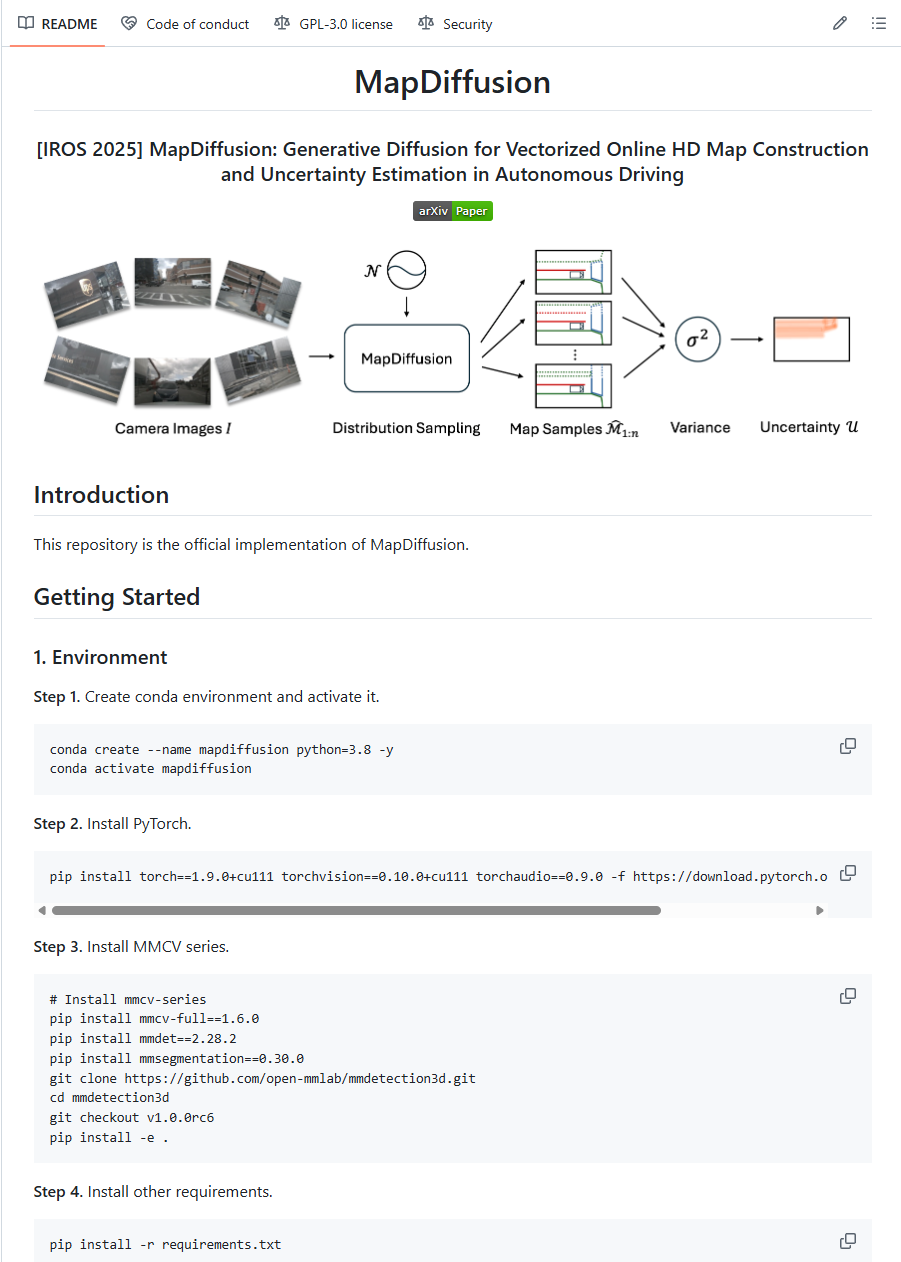
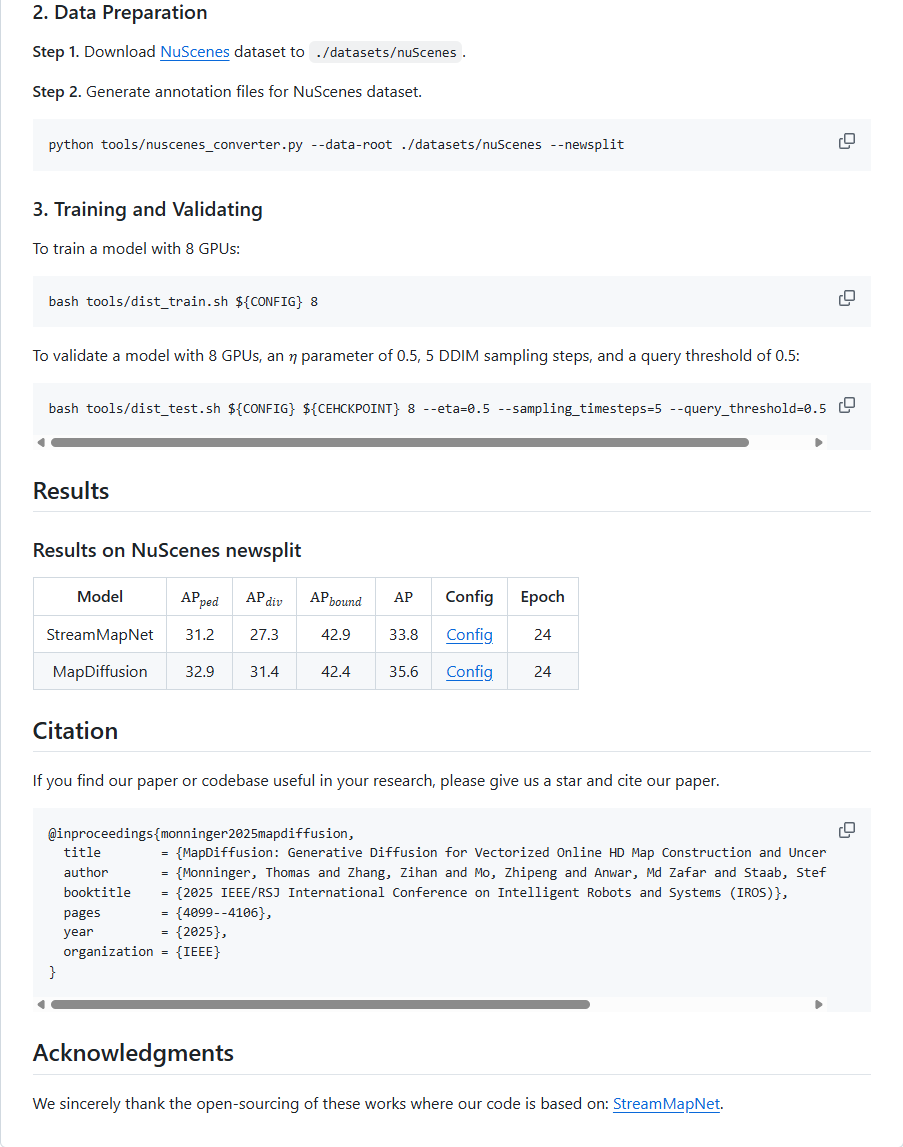
通过readme可以看到核心主要是安装方法,测试和训练命令以及最后的结果。通过安装我们知道是基于mmdetection3d和mmcv库的。
2. 看配置文件
重点从:
bash
plugin/configs/mapdiffusion.py开始。配置文件通常是整个项目的"总开关",里面会告诉你:
bash
用哪个模型
用哪个 dataset
train/test pipeline
optimizer
loss 配置
输入图像尺寸
map 类别
BEV 范围
batch size / epoch 等如果你想理解项目,配置文件比直接读模型源码更适合当入口。
3. 看训练入口
然后看:
bash
tools/train.py
plugin/core/apis/train.py这部分回答:"配置文件是怎么被加载,并真正开始训练的?"
你不需要一开始完全读懂 MMDetection3D 的所有封装,先抓住主线:
配置文件 → build dataset → build model → train loop。
4. 看数据集代码
你现在打开的这个文件就很关键:
bash
plugin/datasets/argo_dataset.py同时建议一起看:
bash
plugin/datasets/base_dataset.py
plugin/datasets/nusc_dataset.py
plugin/datasets/pipelines/
plugin/datasets/map_utils/av2map_extractor.py这里主要回答:
bash
Argoverse 数据怎么读进来
annotation 是什么格式
vector map 是怎么生成的
每个 sample 返回哪些字段
图像、位姿、地图向量是怎么组织的
如果你做数据相关修改,应该优先从这里开始。5. 看模型主体
重点文件:
bash
plugin/models/mapers/MapDiffusion.py
plugin/models/mapers/StreamMapNet.py
plugin/models/mapers/base_mapper.py这里是模型主干逻辑。你可以重点追踪:
forward_train
forward_test
image features 怎么提取
BEV 特征怎么生成
diffusion 部分在哪里发生
head 如何输出 map vectors
6. 看 head 和 loss
重点:
bash
plugin/models/heads/MapDetectorHeadDiffuse.py
plugin/models/heads/MapDetectorHead.py
plugin/models/losses/detr_loss.py
plugin/models/assigner/assigner.py这里回答:
模型最终预测什么
prediction 和 ground truth 怎么匹配
loss 怎么算
diffusion 训练目标是什么
7. 最后看 evaluation
重点:
bash
plugin/datasets/evaluation/vector_eval.py
plugin/datasets/evaluation/AP.py
plugin/core/evaluation/eval_hooks.py这里回答测试指标是怎么来的,比如 vectorized map 的 AP / Chamfer distance 等。
我建议你第一轮不要从底层工具函数开始读,而是按这条主线:
bash
plugin/configs/mapdiffusion.py
→ tools/train.py
→ plugin/datasets/argo_dataset.py
→ plugin/models/mapers/MapDiffusion.py
→ plugin/models/heads/MapDetectorHeadDiffuse.py模块细究
配置文件
我们先把 plugin/configs/mapdiffusion.py 当入口读。它不是普通参数文件,而是整个训练实验的总装配图。
第一层:它在做什么
这个配置当前跑的是 MapDiffusion,数据集是 NuscDataset,也就是 nuScenes 路线,不是 Argoverse。主流程可以概括成:
bash
nuScenes 样本
→ train_pipeline 读取图像和矢量地图
→ BEVFormerBackbone 提取 BEV 特征
→ MapDetectorHeadDiffuse 做扩散式 vector map 预测
→ HungarianLinesAssigner 匹配预测线和 GT 线
→ FocalLoss + LinesL1Loss 训练
python
...
img_h = 480
img_w = 800
img_size = (img_h, img_w)
num_gpus = 8
batch_size = 1
...
num_queries = 100
# diffusion
scheduler = 'cosine'
total_steps = 1000
# category configs
cat2id = {
'ped_crossing': 0,
'divider': 1,
'boundary': 2,
}
...
# bev configs
roi_size = (60, 30) # bev range, 60m in x-axis, 30m in y-axis
bev_h = 50
bev_w = 100
pc_range = [-roi_size[0]/2, -roi_size[1]/2, -3, roi_size[0]/2, roi_size[1]/2, 5]
...
model = dict(
type='MapDiffusion',
...
backbone_cfg=dict(
...
head_cfg=dict(
...
streaming_cfg=dict(
...
model_name='SingleStage'
..
)
# data processing pipelines
train_pipeline = [
dict(
type='VectorizeMap',
...
),
dict(type='LoadMultiViewImagesFromFiles', to_float32=True),
dict(type='PhotoMetricDistortionMultiViewImage'),
dict(type='ResizeMultiViewImages',
size=img_size, # H, W
change_intrinsics=True,
),
dict(type='Normalize3D', **img_norm_cfg),
dict(type='PadMultiViewImages', size_divisor=32),
dict(type='FormatBundleMap'),
# gts are added to train diffusion model
dict(type='Collect3D', keys=['img', 'vectors', 'gts'], meta_keys=(
'token', 'ego2img', 'sample_idx', 'ego2global_translation',
'ego2global_rotation', 'img_shape', 'scene_name'))
]
# data processing pipelines
test_pipeline = [
dict(type='LoadMultiViewImagesFromFiles', to_float32=True),
dict(type='ResizeMultiViewImages',
size=img_size, # H, W
change_intrinsics=True,
),
dict(type='Normalize3D', **img_norm_cfg),
dict(type='PadMultiViewImages', size_divisor=32),
dict(type='FormatBundleMap'),
dict(type='Collect3D', keys=['img'], meta_keys=(
'token', 'ego2img', 'sample_idx', 'ego2global_translation',
'ego2global_rotation', 'img_shape', 'scene_name'))
]最先看这几块
1. 基础实验参数
在 mapdiffusion.py 前半部分:
bash
img_h = 480
img_w = 800
num_gpus = 8
batch_size = 1
num_epochs = 24
num_queries = 100
total_steps = 1000这里定义输入图像大小、训练轮数、query 数量、diffusion 总步数。
num_queries = 100 很关键,
意思是模型每帧最多用 100 个 query 去预测地图 polyline。
2. 地图类别
bash
cat2id = {
'ped_crossing': 0,
'divider': 1,
'boundary': 2,
}模型只预测三类 HD map 元素:
bash
人行横道
车道分隔线
边界线所以后面所有 num_classes=3、分类 loss、评估,都围绕这三个类别。
3. BEV 范围
bash
roi_size = (60, 30)
bev_h = 50
bev_w = 100
pc_range = [-30, -15, -3, 30, 15, 5]这表示模型关注自车周围前后 60m、左右 30m 的区域。
BEV feature map 分辨率是 50 x 100。
这里你可以建立一个直觉:
真实世界局部地图区域: 60m x 30m
bash
被编码成 BEV 网格: 100 x 50
每条地图线: 20 个点
每个点: x, y 两个坐标4. 模型主体
核心配置从这里开始:
bash
model = dict(
type='MapDiffusion',
...
)它对应代码:
plugin/models/mapers/MapDiffusion.py
python
@MAPPERS.register_module()
class MapDiffusion(BaseMapperDiffuse):
def forward_train(self, coef, total_steps, img, vectors, gts, img_metas=None, points=None, **kwargs):
'''
Args:
img: torch.Tensor of shape [B, N, 3, H, W]
N: number of cams
vectors: list[list[Tuple(lines, length, label)]]
- lines: np.array of shape [num_points, 2].
- length: int
- label: int
len(vectors) = batch_size
len(vectors[_b]) = num of lines in sample _b
img_metas:
img_metas['lidar2img']: [B, N, 4, 4]
Out:
loss, log_vars, num_sample
'''
device = img.device
inputs = self.rerange_gts(gts) # from [bs, keys 0/1/2] to [lines/labels, bs, k, num_points, num_coords]
# prepare labels and images
gts, img, img_metas, valid_idx, points = self.batch_data(
vectors, img, img_metas, img.device, points)
bs = img.shape[0]
# Backbone
_bev_feats = self.backbone(img, img_metas=img_metas, points=points)
if self.streaming_bev:
self.bev_memory.train()
_bev_feats = self.update_bev_feature(_bev_feats, img_metas)
# Neck
bev_feats = self.neck(_bev_feats)
preds_list, loss_dict, det_match_idxs, det_match_gt_idxs = self.head(
coef, total_steps, inputs,
bev_features=bev_feats,
img_metas=img_metas,
gts=gts,
return_loss=True)
# format loss
loss = 0.0
for name, var in loss_dict.items():
loss = loss + var
# update the log
log_vars = {k: v.item() for k, v in loss_dict.items()}
log_vars.update({'total': loss.item()})
num_sample = img.size(0)
return loss, log_vars, num_sample里面最关键的是 forward_train():
bash
img + vectors + gts
→ batch_data 整理 GT
→ backbone(img) 得到 BEV feature
→ streaming BEV 融合历史帧
→ head(...) 做 diffusion 预测和 loss也就是说,MapDiffusion.py 是训练时真正把数据、backbone、head 串起来的地方。
5. Backbone
配置里这块:
bash
backbone_cfg=dict(
type='BEVFormerBackbone',
img_backbone=dict(type='ResNet', depth=50),
img_neck=dict(type='FPN'),
transformer=dict(type='PerceptionTransformer')
)大意是:
bash
多相机图像
→ ResNet50 提图像特征
→ FPN 多尺度融合
→ BEVFormer Transformer 投影到 BEV 空间对应文件主要在:
plugin/models/backbones/bevformer_backbone.py
这一块可以第二轮再细读,因为它偏底层。
6. Diffusion Head
最核心的是:
bash
head_cfg=dict(
type='MapDetectorHeadDiffuse',
num_queries=100,
embed_dims=512,
num_points=20,
transformer=dict(type='MapTransformer', ...)
)对应代码:
plugin/models/heads/MapDetectorHeadDiffuse.py
这里做的事情是:
bash
GT polyline
→ padding 到 100 条
→ 加 diffusion noise
→ 用 noisy polyline 作为 query
→ transformer decoder 结合 BEV feature
→ 预测去噪后的 line + class score
→ 算 loss训练时关键位置是forward_train(),我刚才看到了这段逻辑:它会随机采样一个timestep t ,对 GT polyline 加噪,然后让模型学习恢复。
7. 数据 pipeline
训练 pipeline:
python
train_pipeline = [
VectorizeMap,
LoadMultiViewImagesFromFiles,
PhotoMetricDistortionMultiViewImage,
ResizeMultiViewImages,
Normalize3D,
PadMultiViewImages,
FormatBundleMap,
Collect3D
]这条链路回答:"一个 raw sample 怎么变成模型输入?"
最重要的是 VectorizeMap,它把地图几何转成固定点数的 polyline。对应:
plugin/datasets/pipelines/vectorize.py
而 NuscDataset 负责从 annotation 里拿样本、图像路径、相机参数、ego pose、地图几何:
plugin/datasets/nusc_dataset.py
你下一步最适合这样读
我建议你按这个顺序继续:
plugin/configs/mapdiffusion.py
先完全理解每个配置块。
plugin/datasets/nusc_dataset.py
看一个样本里到底有哪些字段。
plugin/datasets/pipelines/vectorize.py
看地图线怎么变成 vectors 和 gts。
plugin/models/mapers/MapDiffusion.py
看训练 forward 的主干。
plugin/models/heads/MapDetectorHeadDiffuse.py
看 diffusion 训练细节。
有一个小提醒:你现在开的 plugin/datasets/argo_dataset.py 是 Argoverse2 数据集适配,但当前 mapdiffusion.py 配的是 NuscDataset。所以我们先读 nuScenes 主线会更顺,之后再对照 Argoverse 看怎么换数据集。