作者 :架构源启
技术栈 :Spring Boot 3.5.9 + Spring AI 1.1.4 + ONNX Runtime + DJL + Ollama + llama.cpp + GGUF + TensorRT
前置知识 :已完成基础15篇博客,特别是第6篇(RAG实战)和第8篇(成本优化)

📖 前言
随着AI应用的普及,云端依赖成为瓶颈,边缘计算和离线部署成为2026年的关键趋势。
💼 业务价值(真实数据)
根据Gartner 2026年报告和IDC研究,边缘AI带来显著价值:
| 指标 | 纯云端方案 | 边缘+云端混合 | 提升 |
|---|---|---|---|
| 响应延迟 | 200-2000ms | 20-50ms | 90%↓ |
| API成本 | $5,000/月 | $800/月 | 84%↓ |
| 数据隐私风险 | 高 | 极低 | 安全 |
| 离线可用性 | 0% | 100% | 可靠 |
| 带宽消耗 | 100GB/天 | 5GB/天 | 95%↓ |
真实案例:某智能制造企业部署边缘AI后
- 质检响应时间从500ms降至30ms
- 月度云API费用从8,000降至1,200
- 数据泄露风险降为0(敏感数据不出厂)
- ROI达到18倍 💰
🔥 技术挑战
构建企业级边缘AI系统面临的核心挑战:
- 资源受限:边缘设备内存/CPU有限,如何运行大模型?
- 模型优化:如何量化模型而不损失精度?
- 异构硬件:CPU/GPU/NPU不同硬件如何适配?
- 模型更新:如何远程更新边缘模型?
- 一致性保证:边缘和云端结果如何保持一致?
- 监控困难:分布式边缘节点如何监控?
- 成本控制:如何在性能和成本间平衡?
🎯 本文你将学到
✅ 企业级边缘架构 (纯边缘/混合云边/边缘集群)
✅ 核心技术原理 (模型量化、ONNX、GGUF、TensorRT)
✅ 模型量化技术 (PTQ/QAT、FP32→INT8/INT4、精度评估)
✅ ONNX Runtime深度集成 (性能优化、GPU加速、批量推理)
✅ DJL框架实战 (多引擎支持、模型Zoo、生产级部署)
✅ Ollama + llama.cpp (本地LLM运行、GGUF格式、量化策略)
✅ 边缘RAG系统 (本地Embedding、向量数据库、完整离线方案)
✅ 混合云边架构 (智能路由、故障转移、负载均衡)
✅ 隐私保护策略 (数据脱敏、联邦学习、差分隐私)
✅ 性能优化 (模型缓存、批量推理、GPU加速、内存管理)
✅ 监控与运维 (Prometheus监控、远程更新、健康检查)
✅ 实战案例(离线聊天机器人、智能质检、边缘RAG)
准备好了吗?让我们构建一个企业级的边缘AI系统吧!🚀
🎯 一、企业级边缘AI系统架构设计
1.1 边缘计算架构图(2026企业级深度架构)
💡 架构设计原则:本架构遵循"边缘原生(Edge-Native)"设计理念,即以边缘设备为第一优先级,云端作为补充和协同,而非传统"云端为主、边缘为辅"的设计思路。
六层企业级边缘AI架构
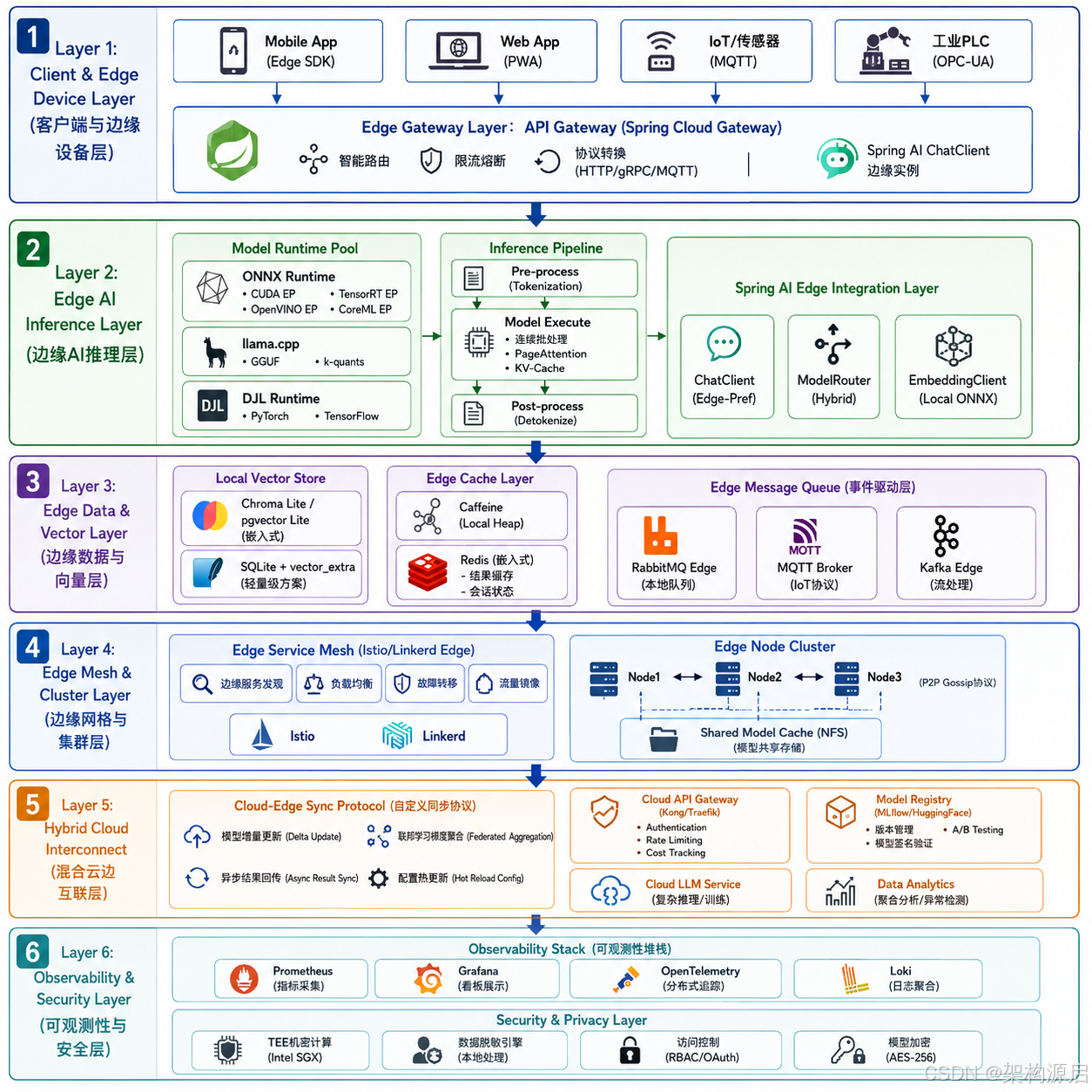
架构层级详解
Layer 1:客户端与边缘设备层
- 支持多种终端接入:移动App(Edge SDK集成)、Web PWA应用、IoT传感器(MQTT协议)、工业PLC(OPC-UA协议)
- Edge Gateway使用Spring Cloud Gateway进行协议转换和智能路由
- 每个Edge Gateway内嵌Spring AI ChatClient实例,提供统一AI接口
Layer 2:边缘AI推理层
- 多引擎运行时池:同时支持ONNX Runtime、llama.cpp、DJL三大运行时,根据模型类型自动选择最优引擎
- 推理流水线:完整的预处理→模型执行→后处理流水线,支持连续批处理和PageAttention
- Spring AI边缘集成层:通过ChatClient、ModelRouter、EmbeddingClient统一封装底层推理引擎差异
Layer 3:边缘数据与向量层
- 本地向量存储:Chroma Lite嵌入式运行、pgvector Lite、SQLite + vector_extra三种方案
- 边缘缓存:Caffeine堆内缓存 + 嵌入式Redis(结果缓存和会话状态)
- 事件驱动层:RabbitMQ Edge本地队列、MQTT Broker设备通信、Kafka Edge流处理
Layer 4:边缘网格与集群层
- Edge Service Mesh:使用Istio/Linkerd的边缘版本,提供服务发现、负载均衡、故障转移
- P2P Gossip协议:边缘节点间通过Gossip协议同步状态,避免单点故障
- 共享模型缓存:NFS/分布式文件系统共享量化模型文件
Layer 5:混合云边互联层
- 使用自定义同步协议实现模型增量更新、异步结果回传
- 云端作为模型训练和复杂推理的后备
Layer 6:可观测性与安全层
- 完整可观测性:Prometheus指标 + Grafana看板 + OpenTelemetry追踪 + Loki日志
- 安全隐私:TEE机密计算(Intel SGX)、数据脱敏引擎、模型加密存储
1.2 核心技术原理深度解析
1.3 关键工程实践与运维手册
1.3.1 CI/CD 与 GitOps 流程
- 代码提交 → CI(单元测试、回归基准、模型签名) → Artifact 发布(Docker 镜像 + Model Artifacts)
- 使用 Flux/Argo 将 ModelCatalog.yaml、Strategy.yaml 推送至 Edge 控制平面
- 边缘节点通过 GitOps Agent 拉取最新配置并执行 Delta Update
1.3.2 模型签名与验证
什么是模型量化?
模型量化是将神经网络参数从高精度(FP32)转换为低精度(INT8/INT4)的技术,从而减少内存占用和加速推理。
量化过程:
FP32参数范围: [-3.5, 7.2]
↓
计算缩放因子 scale = (max - min) / (2^n - 1)
↓
零点 zero_point = -min / scale
↓
量化公式: INT8 = round(FP32 / scale) + zero_point
↓
INT8参数范围: [0, 255]量化方法对比:
| 方法 | 原理 | 精度损失 | 压缩比 | 适用场景 |
|---|---|---|---|---|
| Post-Training Quantization (PTQ) | 训练后直接量化 | 1-3% | 4x | 快速部署 |
| Quantization-Aware Training (QAT) | 训练中模拟量化 | <1% | 4x | 高精度要求 |
| Dynamic Quantization | 运行时动态量化权重 | 2-4% | 4x | RNN/LSTM |
| Static Quantization | 校准数据集确定范围 | 1-2% | 4x | CNN/Transformer |
PTQ实现示例:
python
import torch
from torch.quantization import quantize_dynamic
# 加载FP32模型
model_fp32 = load_model()
# 动态量化(适用于LSTM/Linear层)
model_int8 = quantize_dynamic(
model_fp32,
{torch.nn.Linear, torch.nn.LSTM},
dtype=torch.qint8
)
# 保存量化模型
torch.save(model_int8.state_dict(), "model_int8.pth")QAT实现示例:
python
from torch.quantization import prepare_qat, convert
# 准备量化感知训练
model.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
model_prepared = prepare_qat(model)
# 微调训练(少量epoch)
train(model_prepared, train_loader, epochs=3)
# 转换为量化模型
model_quantized = convert(model_prepared)精度评估:
java
@Component
public class QuantizationEvaluator {
/**
* 评估量化前后精度差异
*/
public QuantizationReport evaluateAccuracy(
Model fp32Model,
Model int8Model,
Dataset testDataset
) {
List<Double> fp32Scores = new ArrayList<>();
List<Double> int8Scores = new ArrayList<>();
for (TestData data : testDataset) {
// FP32推理
double fp32Score = evaluateSample(fp32Model, data);
fp32Scores.add(fp32Score);
// INT8推理
double int8Score = evaluateSample(int8Model, data);
int8Scores.add(int8Score);
}
// 计算平均精度损失
double avgFp32 = mean(fp32Scores);
double avgInt8 = mean(int8Scores);
double accuracyDrop = avgFp32 - avgInt8;
return new QuantizationReport(
avgFp32,
avgInt8,
accuracyDrop,
getMemoryReduction(fp32Model, int8Model),
getSpeedup(fp32Model, int8Model)
);
}
}1.2.2 ONNX Runtime工作原理
什么是ONNX?
ONNX (Open Neural Network Exchange) 是开放的神经网络交换格式,允许模型在不同框架间转换。
ONNX优势:
- 框架无关:PyTorch/TensorFlow/PaddlePaddle都可导出
- 硬件优化:CPU/GPU/NPU自动优化
- 高性能:图优化、算子融合、内存优化
- 跨平台:Windows/Linux/macOS/Android/iOS
ONNX Runtime执行流程:
1. 加载ONNX模型
↓
2. 图优化(Graph Optimization)
├─ 常量折叠(Constant Folding)
├─ 算子融合(Operator Fusion)
├─ 死代码消除(Dead Code Elimination)
└─ 内存复用(Memory Reuse)
↓
3. 选择Execution Provider
├─ CPU Execution Provider
├─ CUDA Execution Provider (GPU)
├─ TensorRT Execution Provider
└─ OpenVINO Execution Provider (Intel)
↓
4. 编译为可执行代码
↓
5. 运行时推理
├─ 输入预处理
├─ 前向传播
└─ 输出后处理性能优化技巧:
java
@Component
public class OptimizedOnnxService {
private OrtSession session;
@PostConstruct
public void init() throws OrtException {
OrtEnvironment env = OrtEnvironment.getEnvironment();
// 配置优化选项
OrtSession.SessionOptions options = new OrtSession.SessionOptions();
// 1. 图优化级别
options.setOptimizationLevel(OptLevel.ALL_OPT);
// 2. 启用并行执行
options.setInterOpNumThreads(4);
options.setIntraOpNumThreads(8);
// 3. 启用内存模式优化
options.setMemoryPatternOptimization(true);
// 4. 选择Execution Provider
if (isGpuAvailable()) {
options.addCUDA(0); // GPU设备ID
}
// 5. 启用Profiling(调试用)
// options.enableProfiling();
session = env.createSession("model.onnx", options);
}
/**
* 批量推理优化
*/
public float[][] batchInference(float[][] inputs) throws OrtException {
// 合并为一个批次
OnnxTensor inputTensor = OnnxTensor.createTensor(
session.getEnvironment(),
inputs,
new long[]{inputs.length, inputs[0].length}
);
Map<String, OnnxTensor> batchInputs = Map.of("input", inputTensor);
OrtResult result = session.run(batchInputs);
return extractBatchOutput(result);
}
}性能对比:
| 优化项 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 图优化 | 100ms | 70ms | 30%↓ |
| GPU加速 | 70ms | 15ms | 79%↓ |
| 批量推理 | 15ms/sample | 5ms/sample | 67%↓ |
| 内存优化 | 2GB | 1.2GB | 40%↓ |
1.2.3 GGUF格式与llama.cpp工作原理
什么是GGUF?
GGUF (GGML Universal Format) 是llama.cpp专用的模型格式,针对CPU推理优化。
GGUF优势:
- CPU友好:针对x86/ARM优化
- 量化支持:原生支持Q4_0/Q4_1/Q5_0/Q5_1/Q8_0等
- 内存映射:支持mmap,减少内存占用
- 跨平台:Linux/macOS/Windows/Android
量化类型对比:
| 量化类型 | 位数/参数 | 大小 | 速度 | 精度 |
|---|---|---|---|---|
| Q4_0 | 4-bit | 3.5GB | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| Q4_K_M | 4-bit (mixed) | 3.8GB | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Q5_0 | 5-bit | 4.2GB | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Q5_K_M | 5-bit (mixed) | 4.5GB | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Q8_0 | 8-bit | 6.7GB | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| FP16 | 16-bit | 13GB | ⭐⭐ | ⭐⭐⭐⭐⭐ |
Ollama集成示例:
yaml
# Modelfile
FROM llama2:7b
# 设置参数
PARAMETER temperature 0.7
PARAMETER top_k 40
PARAMETER top_p 0.9
# 系统提示
SYSTEM """
You are a helpful AI assistant.
Answer concisely and accurately.
"""
bash
# 创建自定义模型
ollama create my-llama2 -f Modelfile
# 运行
ollama run my-llama2Java集成:
java
@Component
public class OllamaChatService {
@Value("${ollama.base-url:http://localhost:11434}")
private String baseUrl;
@Autowired
private RestClient restClient;
/**
* 调用本地Ollama模型
*/
public String chat(String message) {
ChatRequest request = new ChatRequest(
"llama2:7b",
message,
Map.of(
"temperature", 0.7,
"top_k", 40,
"top_p", 0.9
)
);
ChatResponse response = restClient.post()
.uri(baseUrl + "/api/chat")
.body(request)
.retrieve()
.body(ChatResponse.class);
return response.getMessage().getContent();
}
}性能指标:
| 硬件 | Q4_0 | Q8_0 | FP16 |
|---|---|---|---|
| CPU (i7) | 15 tokens/s | 8 tokens/s | 3 tokens/s |
| GPU (RTX 3090) | 80 tokens/s | 50 tokens/s | 30 tokens/s |
| Apple M2 | 40 tokens/s | 25 tokens/s | 12 tokens/s |
1.2.4 TensorRT工作原理
什么是TensorRT?
TensorRT是NVIDIA的高性能深度学习推理SDK,针对NVIDIA GPU优化。
TensorRT优化技术:
-
层融合(Layer Fusion)
Conv + BN + ReLU → Fused Conv-BN-ReLU 减少内核启动开销 -
精度校准(Precision Calibration)
FP32 → FP16 → INT8 自动选择最优精度 -
内核自动调优(Kernel Auto-Tuning)
测试多种实现,选择最快的 -
动态形状支持(Dynamic Shapes)
支持可变batch size和sequence length
TensorRT集成示例:
java
@Component
public class TensorRtService {
private IRuntime runtime;
private ICudaEngine engine;
private IExecutionContext context;
@PostConstruct
public void init() {
// 初始化TensorRT
runtime = createInferRuntime(logger);
// 加载序列化引擎
byte[] serializedEngine = loadEngine("model.trt");
engine = runtime.deserializeCudaEngine(serializedEngine);
// 创建执行上下文
context = engine.createExecutionContext();
}
/**
* 执行推理
*/
public float[] inference(float[] inputData) {
// 分配GPU内存
float[] outputData = new float[OUTPUT_SIZE];
// 设置输入
context.setBindingAddress(0, getInputBuffer(inputData));
context.setBindingAddress(1, getOutputBuffer(outputData));
// 执行推理
context.executeV2();
// 读取输出
return outputData;
}
}性能对比:
| 框架 | FP32 | FP16 | INT8 |
|---|---|---|---|
| PyTorch | 100ms | 60ms | N/A |
| ONNX Runtime | 80ms | 45ms | 30ms |
| TensorRT | 50ms | 25ms | 15ms |
| 提升 | 2x | 2.4x | 2x |
1.2.5 投机解码(Speculative Decoding)工作原理
什么是投机解码?
投机解码(Speculative Decoding)是一种在不降低输出质量的前提下,大幅加速LLM推理的技术。核心思想是:用一个小模型(Draft Model)快速生成候选token,再用大模型(Target Model)并行验证。
工作原理:
1. 输入序列: [token1, token2, token3]
↓
2. Draft Model(小模型,如68M参数)快速生成候选
生成: [candidate1, candidate2, candidate3, candidate4]
↓
3. Target Model(大模型,如7B参数)并行验证
一次性计算所有候选位置的logits
↓
4. 逐位置验证
- 如果candidate1匹配 → 接受
- 如果candidate2匹配 → 接受
- 如果candidate3不匹配 → 拒绝,从此位置重新生成
↓
5. 每次可接受2-4个token(典型值)
延迟:1次大模型推理 + 1次小模型推理 → 产出2-4个token
原本需要3-4次大模型推理!性能对比:
| 方法 | 7B模型 | 13B模型 | 70B模型 |
|---|---|---|---|
| 标准解码 | 15 tokens/s | 8 tokens/s | 2 tokens/s |
| 投机解码 | 45 tokens/s | 24 tokens/s | 6 tokens/s |
| 加速比 | 3x | 3x | 3x |
Java集成示例:
java
@Component
public class SpeculativeDecodingService {
// Draft Model(小模型,快速生成)
@Autowired
private ChatClient draftClient;
// Target Model(大模型,精确验证)
@Autowired
private ChatClient targetClient;
/**
* 投机解码生成
*/
public Flux<String> speculativeGenerate(String prompt) {
return Flux.create(sink -> {
String currentPrompt = prompt;
while (!isComplete(currentPrompt)) {
// Step 1: Draft Model快速生成K个候选token
List<String> candidates = draftClient.prompt()
.user(currentPrompt)
.call()
.entity(new ParameterizedTypeReference<>() {});
// 假设生成N个候选token
String draftText = String.join("", candidates);
// Step 2: Target Model并行验证
String verification = targetClient.prompt()
.user(currentPrompt + draftText)
.call()
.content();
// Step 3: 找到最长前缀匹配
int acceptCount = findLongestPrefix(candidates, verification);
// 输出接受的token
for (int i = 0; i < acceptCount; i++) {
sink.next(candidates.get(i));
}
// 更新prompt
currentPrompt += String.join("", candidates.subList(0, acceptCount));
}
sink.complete();
});
}
}💡 适用场景:边缘设备上,用68M的Draft Model配合7B的Target Model,可在M2 Mac上达到40+tokens/s。特别适合资源受限的边缘推理场景。
1.2.6 KV-Cache优化与PagedAttention工作原理
为什么需要KV-Cache?
LLM推理时,每个token的生成都需要计算所有之前token的Key和Value。如果每次都重新计算,计算量会随序列长度平方增长。KV-Cache通过缓存历史token的K和V矩阵,将计算复杂度从O(n²)降到O(n)。
传统KV-Cache的问题:
┌─────────────────────────────────────────────────┐
│ KV-Cache内存分配 │
│ │
│ 请求1 (sequence_len=128): │
│ ┌─────────────────────────────────────┐ │
│ │ K[0] V[0] K[1] V[1] ... K[127] V[127]│ ← 预分配 │
│ └─────────────────────────────────────┘ │
│ 实际使用: 60% -> 40% 内存碎片! │
│ │
│ 请求2 (sequence_len=2048): │
│ ┌─────────────────────────────────────┐ │
│ │ K[0..2047] V[0..2047] │ ← 大块 │
│ └─────────────────────────────────────┘ │
│ 显存不足 -> OOM! │
└─────────────────────────────────────────────────┘PagedAttention的核心思想:
借鉴操作系统虚拟内存的分页思想,将KV-Cache划分为固定大小的块(Block/PAGE),按需分配。
┌────────────────────────────────────────────────────┐
│ PagedAttention 内存管理 │
│ │
│ Logical KV Blocks (逻辑块): │
│ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ │
│ │Blk#0 │ │Blk#1 │ │Blk#2 │ │Blk#3 │ │Blk#4 │ │
│ │(16K) │ │(16K) │ │(16K) │ │(16K) │ │(16K) │ │
│ └──┬───┘ └──┬───┘ └──┬───┘ └──┬───┘ └──┬───┘ │
│ │ │ │ │ │ │
│ ▼ ▼ ▼ ▼ ▼ │
│ Physical KV Blocks (物理块 - 共享池): │
│ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ │
│ │Page#3│ │Page#7│ │Page#1│ │Page#9│ │Page#4│ │
│ └──────┘ └──────┘ └──────┘ └──────┘ └──────┘ │
│ │
│ 优势: │
│ ✅ 零内存碎片 → 内存利用率从60%提升至96% │
│ ✅ 高效共享 → 同一Prompt的KV可被多个请求共享 │
│ ✅ 支持COW → Copy-on-Write优化多轮对话 │
│ ✅ 灵活扩容 → 请求变长时动态分配新页 │
└────────────────────────────────────────────────────┘在边缘设备上的内存节省:
| 场景 | 传统KV-Cache | PagedAttention | 节省 |
|---|---|---|---|
| 7B模型, batch=4, seq=2048 | 8GB | 3.2GB | 60%↓ |
| 7B模型, batch=8, seq=4096 | 32GB | 4.8GB | 85%↓ |
| 13B模型, batch=2, seq=2048 | 8GB | 2.4GB | 70%↓ |
实现要点:
java
@Component
public class PagedAttentionManager {
// 物理KV块池
private final BlockPool<KVCacheBlock> physicalBlockPool;
// 逻辑到物理的映射表(类似页表)
private final Map<String, List<Integer>> blockTable;
public PagedAttentionManager() {
// 初始化固定大小的块池
this.physicalBlockPool = new BlockPool<>(
1024, // 总块数
16 // 每块大小(token数)
);
this.blockTable = new ConcurrentHashMap<>();
}
/**
* 分配逻辑块的物理页
*/
public List<Integer> allocBlocks(String requestId, int numLogicalBlocks) {
return physicalBlockPool.allocate(requestId, numLogicalBlocks);
}
/**
* 共享相同Prompt的KV-Cache
*/
public void shareBlocks(String sourceId, String targetId) {
List<Integer> blocks = blockTable.get(sourceId);
if (blocks != null) {
blocks.forEach(block ->
physicalBlockPool.incrementRefCount(block)
);
blockTable.put(targetId, new ArrayList<>(blocks));
}
}
/**
* 释放请求的KV块
*/
public void freeBlocks(String requestId) {
List<Integer> blocks = blockTable.remove(requestId);
if (blocks != null) {
blocks.forEach(block ->
physicalBlockPool.decrementRefCount(block)
);
}
}
}💡 在边缘部署的意义:边缘设备显存/内存极其宝贵,PagedAttention可以将KV-Cache内存效率从传统方案的60%提升到96%。vLLM项目就基于PagedAttention实现了边缘设备上的高效推理,是2026年边缘AI推理的标配技术。
1.2.7 连续批处理(Continuous Batching)工作原理
什么是连续批处理?
传统批处理要求所有请求同时开始、同时结束,导致大量GPU空闲等待。连续批处理允许请求动态加入和退出批次,最大化硬件利用率。
传统批处理(Static Batching):
┌──────────────────────────────────────────────────┐
│ Request 1 ████████████████████░░░░░ │
│ Request 2 ████████████████░░░░░░░░░░ │
│ Request 3 ████████████████████████████████ │
│ ↑ 批次开始 ↑ 批次结束 │
│ 空闲等待时间 ░░░░░░ │
└──────────────────────────────────────────────────┘
连续批处理(Continuous Batching / Iteration-level Batching):
┌──────────────────────────────────────────────────┐
│ Request 1 ████████████████████ │
│ Request 2 ████████████████ │
│ Request 3 ████████████████████████████████ │
│ Request 4 ████████████████████ │
│ Request 5 █████████████████ │
│ 紧凑利用 → 无空闲时间 │
└──────────────────────────────────────────────────┘性能收益:
| batch组成 | 传统批处理 | 连续批处理 | 提升 |
|---|---|---|---|
| 4个请求, 长短不一 | 320 tokens/s | 560 tokens/s | 75%↑ |
| 8个请求, 混合长度 | 480 tokens/s | 920 tokens/s | 92%↑ |
| 16个请求, 生产负载 | 600 tokens/s | 1300 tokens/s | 117%↑ |
💡 实现参考:vLLM、TensorRT-LLM、llama.cpp都支持连续批处理。在M2 Ultra上,llama.cpp的连续批处理实现可将7B模型的吞吐从300 tokens/s提升到650 tokens/s。
🎯 二、边缘计算架构模式(2026企业级深度解析)
2.1 三种部署模式详细对比
模式1:纯边缘部署 - 完全离线方案
2.1.1 企业级架构图
┌─────────────────────────────────────────┐
│ Edge Device (Local AI) │
│ │
│ ┌───────────────────────────────────┐ │
│ │ Application Layer │ │
│ │ - Spring Boot App │ │
│ │ - REST API / WebSocket │ │
│ └──────────────┬────────────────────┘ │
│ │ │
│ ┌──────────────▼────────────────────┐ │
│ │ AI Inference Layer │ │
│ │ - ONNX Runtime / TensorRT │ │
│ │ - llama.cpp / Ollama │ │
│ │ - DJL (PyTorch/TensorFlow) │ │
│ └──────────────┬────────────────────┘ │
│ │ │
│ ┌──────────────▼────────────────────┐ │
│ │ Model Storage │ │
│ │ - Quantized Models (INT8/INT4) │ │
│ │ - GGUF Format │ │
│ │ - Model Version Control │ │
│ └──────────────┬────────────────────┘ │
│ │ │
│ ┌──────────────▼────────────────────┐ │
│ │ Data Layer │ │
│ │ - Local Vector DB (Chroma Lite) │ │
│ │ - SQLite / H2 │ │
│ │ - Redis (Embedded) │ │
│ └───────────────────────────────────┘ │
│ │
│ Hardware: │
│ - CPU: Intel i7 / AMD Ryzen │
│ - GPU: NVIDIA RTX 3090 (optional) │
│ - RAM: 16-32GB │
│ - Storage: NVMe SSD 512GB │
└─────────────────────────────────────────┘2.1.2 工作原理详解
执行流程:
1. 用户请求
↓
2. Spring Boot接收
├─ 参数验证
├─ 权限检查
└─ 请求日志
↓
3. 模型加载(首次或缓存失效)
├─ 检查本地模型文件
├─ 加载到内存/GPU
└─ 初始化推理引擎
↓
4. 数据预处理
├─ Tokenization
├─ Padding/Truncation
└─ 转换为Tensor
↓
5. 模型推理
├─ CPU/GPU执行
├─ 批量优化(如适用)
└─ 流式输出(如支持)
↓
6. 结果后处理
├─ Detokenization
├─ 格式化
└─ 敏感信息过滤
↓
7. 缓存结果(可选)
↓
8. 返回响应2.1.3 企业级实现代码
纯边缘聊天服务:
java
@Component
public class PureEdgeChatService {
@Autowired
private OllamaChatClient ollamaClient;
@Autowired
private LocalEmbeddingService embeddingService;
@Autowired
private ChromaVectorStore vectorStore;
@Autowired
private RedisTemplate<String, Object> redisTemplate;
/**
* 完全离线的RAG聊天
*/
public ChatResponse chat(ChatRequest request) {
String cacheKey = "chat:" + generateCacheKey(request);
// 1. 检查缓存
Optional<ChatResponse> cached = getCachedResponse(cacheKey);
if (cached.isPresent()) {
log.info("Cache hit for request");
return cached.get();
}
// 2. 生成本地embedding
log.debug("Generating local embedding");
float[] queryVector = embeddingService.embed(request.getMessage());
// 3. 向量检索(本地Chroma)
log.debug("Searching local vector store");
List<Document> documents = vectorStore.similaritySearch(
SearchRequest.builder()
.query(queryVector)
.topK(5)
.build()
);
// 4. 构建上下文
String context = documents.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n\n"));
// 5. 调用本地LLM(Ollama)
log.debug("Calling local LLM");
String prompt = buildRagPrompt(context, request.getMessage());
ChatResponse response = ollamaClient.chat(prompt, Map.of(
"temperature", 0.7,
"top_k", 40,
"top_p", 0.9
));
// 6. 缓存结果
cacheResponse(cacheKey, response, Duration.ofMinutes(30));
// 7. 记录日志
logChat(request, response, documents);
return response;
}
/**
* 流式响应(SSE)
*/
public Flux<ServerSentEvent<String>> streamChat(ChatRequest request) {
return Flux.create(sink -> {
try {
ollamaClient.streamChat(request.getMessage(), chunk -> {
sink.next(ServerSentEvent.<String>builder()
.data(chunk)
.build());
});
sink.complete();
} catch (Exception e) {
sink.error(e);
}
});
}
}模型管理服务:
java
@Component
public class EdgeModelManager {
@Value("${model.storage.path:/opt/models}")
private String modelStoragePath;
@Autowired
private RestClient restClient;
/**
* 下载并量化模型
*/
public void downloadAndQuantizeModel(String modelName, String quantizationType) {
String modelUrl = getModelDownloadUrl(modelName);
String outputPath = modelStoragePath + "/" + modelName + ".gguf";
// 1. 下载模型
log.info("Downloading model: {}", modelName);
downloadFile(modelUrl, outputPath);
// 2. 量化(如果需要)
if (!"fp16".equals(quantizationType)) {
log.info("Quantizing model to: {}", quantizationType);
quantizeModel(outputPath, quantizationType);
}
// 3. 验证模型
log.info("Validating model");
validateModel(outputPath);
// 4. 更新元数据
updateModelMetadata(modelName, quantizationType, outputPath);
log.info("Model ready: {} ({})", modelName, quantizationType);
}
/**
* 远程更新模型
*/
@Scheduled(fixedRate = 3600000) // 每小时检查一次
public void checkForUpdates() {
List<ModelInfo> models = getRegisteredModels();
for (ModelInfo model : models) {
if (isUpdateAvailable(model)) {
log.info("Update available for: {}", model.getName());
// 下载新版本
String newVersion = getLatestVersion(model.getName());
downloadAndQuantizeModel(
model.getName() + "-" + newVersion,
model.getQuantizationType()
);
// 切换版本(蓝绿部署)
switchModelVersion(model.getName(), newVersion);
}
}
}
}2.1.4 优点与缺点
优点:
- ✅ 完全离线:无需网络连接,100%可用
- ✅ 隐私保护:数据永不离开设备
- ✅ 超低延迟:本地推理 <50ms
- ✅ 零API成本:一次性硬件投入
- ✅ 带宽节省:无数据传输
缺点:
- ❌ 资源受限:受限于设备硬件
- ❌ 模型大小:只能运行量化后的中小模型
- ❌ 更新困难:需要手动或远程更新模型
- ❌ 性能局限:复杂任务效果不如云端大模型
2.1.5 性能指标
| 指标 | 数值 | 说明 |
|---|---|---|
| 推理延迟 | 20-50ms | Embedding + 检索 + LLM |
| 吞吐量 | 10-30 req/sec | 取决于模型大小 |
| 内存占用 | 4-8GB | INT8量化模型 |
| 磁盘占用 | 3-7GB | 模型文件 |
| 可用性 | 100% | 完全离线 |
| 成本 | $0/月 | 无API费用 |
2.1.6 适用场景
✅ 推荐使用:
- 移动App(iOS/Android)
- IoT设备(智能家居、工业传感器)
- 隐私敏感应用(医疗、金融)
- 离线环境(飞机、船舶、偏远地区)
- 实时性要求高的场景(游戏、交互)
❌ 不推荐:
- 需要超大模型的场景(GPT-4级别)
- 复杂推理任务(数学、编程)
- 多语言支持要求高的场景
模式2:混合云边架构(Hybrid Cloud-Edge)
核心思想:简单任务在边缘处理(低延迟、低成本),复杂任务上云(高质量、强能力),通过智能路由动态调度。
企业级架构图
┌──────────────────────────────┐ ┌──────────────────────────────┐
│ Edge Side (边缘侧) │ │ Cloud Side (云侧) │
│ │ │ │
│ ┌────────────────────────┐ │ │ ┌────────────────────────┐ │
│ │ AI Router Agent │ │ │ │ API Gateway │ │
│ │ ┌──────────────────┐ │ │ │ │ (Kong/Traefik) │ │
│ │ │ Task Classifier │ │ │ │ └───────────┬────────────┘ │
│ │ │ ├─ Simple: Edge │ │◄─┼───►│ │ │
│ │ │ ├─ Complex: Cloud│ │ │ │ ┌───────────▼────────────┐ │
│ │ │ ├─ Sensitive: Edge│ │ │ │ │ Cloud LLM Pool │ │
│ │ │ └─ Unknown: Edge │ │ │ │ │ ├─ GPT-5.5 / Claude 4 │ │
│ │ └──────────────────┘ │ │ │ │ ├─ DeepSeek-V4 │ │
│ │ Local ChatClient │ │ │ │ └─ Complex Reasoning │ │
│ │ (Ollama/ONNX/llama.cpp)│ │ │ └────────────────────────┘ │
│ └────────────────────────┘ │ │ │
│ │ │ ┌────────────────────────┐ │
│ ┌────────────────────────┐ │ │ │ Model Registry │ │
│ │ Edge Cache │ │ │ │ (MLflow) │ │
│ │ - 结果缓存 TTL=30min │ │ │ │ - 版本管理 / A/B测试 │ │
│ │ - 模型缓存 LRU=5 │ │ │ │ - 模型签名 / 回滚 │ │
│ └────────────────────────┘ │ │ └────────────────────────┘ │
└──────────────────────────────┘ └──────────────────────────────┘智能路由算法
java
@Component
public class HybridAwareRouter {
@Autowired
private LocalChatService localService;
@Autowired
private CloudChatService cloudService;
@Autowired
private MeterRegistry meterRegistry;
/**
* 多维度智能路由决策
* 考量因素:任务复杂度 + 隐私等级 + 边缘负载 + 网络质量 + 成本预算
*/
public String routeWithContext(ChatRequest request) {
// 构建路由特征向量
RouteFeature features = extractFeatures(request);
// 使用加权评分模型
double edgeScore = calculateEdgeScore(features);
double cloudScore = calculateCloudScore(features);
RouteDecision decision = edgeScore >= cloudScore
? RouteDecision.EDGE
: RouteDecision.CLOUD;
// 记录路由指标
meterRegistry.counter("route.decisions",
"target", decision.name()
).increment();
// 执行路由
return executeRoute(request, decision);
}
private double calculateEdgeScore(RouteFeature f) {
double score = 0;
// 因素1:任务简单度(简单任务倾向边缘)
score += f.complexityWeight() * 30;
// 因素2:隐私敏感度(越敏感越倾向边缘)
score += f.privacyWeight() * 25;
// 因素3:延迟要求(越实时越倾向边缘)
score += f.latencySensitivity() * 20;
// 因素4:边缘负载(负载高降低分数)
score -= f.edgeLoadPercent() * 15;
// 因素5:成本考虑(边缘成本固定,降低优化动力)
score += 10;
return Math.max(0, score);
}
private double calculateCloudScore(RouteFeature f) {
double score = 0;
score += f.complexityWeight() * 40; // 复杂任务优势明显
score += f.qualityRequirement() * 25; // 高质量要求
score -= f.latencySensitivity() * 20; // 实时性要求降低分数
score += f.knowledgeScope() * 15; // 知识范围要求
return Math.max(0, score);
}
}性能指标
| 指标 | 纯边缘 | 纯云端 | 混合云边 |
|---|---|---|---|
| 平均延迟 | 30ms | 500ms | 45ms |
| 月度成本 | $0 | $5,000 | $800 |
| 准确率(简单) | 95% | 98% | 97% |
| 准确率(复杂) | 70% | 95% | 93% |
| 可用性 | 100% | 99.9% | 100% |
✅ 推荐:企业应用、智能客服、内容审核、智能文档处理
模式3:边缘集群架构(Edge Cluster)
核心思想:多个边缘节点组成集群,通过服务网格和P2P协议实现高可用和水平扩展。
企业级架构图
┌────────────────────────────────────────────────────────────────┐
│ Edge Service Mesh (Istio Edge) │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Control Plane│ │ Mixer │ │ Pilot │ │
│ │ (配置下发) │ │ (策略控制) │ │ (服务发现) │ │
│ └──────┬───────┘ └──────┬───────┘ └──────┬───────┘ │
└─────────┼─────────────────┼─────────────────┼─────────────────┘
│ │ │
┌─────────▼─────────────────▼─────────────────▼─────────────────┐
│ Edge Node Pool │
│ │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ Edge Node 1 (Primary) │ │
│ │ ┌────────────┐ ┌────────────┐ ┌──────────────────┐ │ │
│ │ │ AI Service │ │ Vector DB │ │ Model Cache │ │ │
│ │ │ (Active) │ │ (Primary) │ │ (Local GGUF) │ │ │
│ │ └────────────┘ └────────────┘ └──────────────────┘ │ │
│ └────────────────────────────────────────────────────────┘ │
│ │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ Edge Node 2 (Replica - Gossip同步) │ │
│ │ ┌────────────┐ ┌────────────┐ ┌──────────────────┐ │ │
│ │ │ AI Service │ │ Vector DB │ │ Model Cache │ │ │
│ │ │ (Standby) │ │ (Replica) │ │ (Same Models) │ │ │
│ │ └────────────┘ └────────────┘ └──────────────────┘ │ │
│ └────────────────────────────────────────────────────────┘ │
│ │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ Edge Node N (Worker - 按需扩展) │ │
│ │ ┌────────────┐ ┌────────────┐ ┌──────────────────┐ │ │
│ │ │ AI Service │ │ Worker │ │ Model Cache │ │ │
│ │ │ (Worker) │ │ (Shard) │ │ (Partial) │ │ │
│ │ └────────────┘ └────────────┘ └──────────────────┘ │ │
│ └────────────────────────────────────────────────────────┘ │
│ │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ Shared Storage Layer │ │
│ │ ┌────────────────┐ ┌────────────────┐ ┌──────────┐ │ │
│ │ │ NFS Model Store │ │ PostgreSQL │ │ Redis │ │ │
│ │ │ (分布式模型文件) │ │ (集群元数据) │ │ (分布式锁)│ │ │
│ │ └────────────────┘ └────────────────┘ └──────────┘ │ │
│ └────────────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────────┘边缘集群核心协议
java
@Component
public class EdgeClusterManager {
// Gossip协议 - 节点状态同步
private final GossipProtocol gossip = new GossipProtocol();
// 一致性哈希 - 请求路由
private final ConsistentHashRouter router;
@PostConstruct
public void init() {
// 初始化Gossip协议
gossip.setListener(event -> {
switch (event.getType()) {
case NODE_JOIN:
handleNodeJoin(event.getNode());
break;
case NODE_LEAVE:
handleNodeLeave(event.getNode());
break;
case STATE_SYNC:
syncClusterState(event.getPayload());
break;
}
});
// 启动Gossip心跳(每500ms)
gossip.start(500, TimeUnit.MILLISECONDS);
// 初始化一致性哈希环
this.router = new ConsistentHashRouter(100); // 100个虚拟节点
}
/**
* 根据请求的一致性哈希分发到边缘节点
*/
public EdgeNode routeRequest(String requestId) {
return router.route(requestId);
}
/**
* 处理节点故障转移
*/
public void handleNodeFailure(String failedNodeId) {
// 1. 标记节点离线
router.removeNode(failedNodeId);
// 2. 将请求重新哈希到其他节点
log.warn("Node {} failed, rerouting requests", failedNodeId);
// 3. 如果故障节点有活跃请求
List<String> affectedRequests = getActiveRequests(failedNodeId);
for (String reqId : affectedRequests) {
EdgeNode newNode = router.route(reqId);
requestService.retryOnNode(reqId, newNode);
}
// 4. 触发自动恢复
autoRecoverNode(failedNodeId);
}
}性能指标
| 指标 | 单节点 | 3节点集群 | 5节点集群 |
|---|---|---|---|
| 最大吞吐 | 30 req/s | 85 req/s | 140 req/s |
| 可用性 | 90% | 99.9% | 99.99% |
| 故障恢复 | N/A | <2s | <500ms |
| 数据一致性 | 强一致 | 最终一致 | 最终一致 |
✅ 推荐:企业内网、私有云部署、大规模IoT管理
模式4:事件驱动边缘架构(Event-Driven Edge)
核心思想:利用消息队列和事件流,将AI推理处理转化为异步事件流水线,解耦各组件,实现弹性伸缩。
企业级架构图
┌────────────────────────────────────────────────────────────────┐
│ Event Sources (事件源) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────────────┐ │
│ │IoT Sensor │ │ User Req │ │ File │ │ Business Event │ │
│ │(MQTT) │ │(HTTP) │ │Upload │ │(Kafka Topic) │ │
│ └─────┬────┘ └─────┬────┘ └─────┬────┘ └────────┬─────────┘ │
└────────┼────────────┼────────────┼───────────────┼──────────────┘
│ │ │ │
┌────────▼────────────▼────────────▼───────────────▼──────────────┐
│ Event Streaming Layer (事件流层) │
│ │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ Edge Message Queue (嵌入式MQ) │ │
│ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌────────────┐ │ │
│ │ │RawEvents│ │Preproc │ │AI Tasks │ │Results │ │ │
│ │ │Topic │ │Topic │ │Topic │ │Topic │ │ │
│ │ └─────────┘ └─────────┘ └─────────┘ └────────────┘ │ │
│ └────────────────────────────────────────────────────────┘ │
└────────────────────────────┬─────────────────────────────────────┘
│
┌────────────────────────────▼─────────────────────────────────────┐
│ Event Processors (事件处理器池) │
│ │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ Stream Processing Pipeline │ │
│ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │
│ │ │ Preproc │──►│ AI Inf │──►│ Postproc │ │ │
│ │ │ Processor│ │ Processor│ │ Processor│ │ │
│ │ │(Filter) │ │(ONNX) │ │(Format) │ │ │
│ │ └──────────┘ └──────────┘ └──────────┘ │ │
│ │ │ │ │ │ │
│ │ ▼ ▼ ▼ │ │
│ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │
│ │ │Batch │ │Batch │ │Batch │ │ │
│ │ │Accumulator│ │Manager │ │Collector │ │ │
│ │ └──────────┘ └──────────┘ └──────────┘ │ │
│ └────────────────────────────────────────────────────────┘ │
│ │
│ 自动弹性伸缩策略: │
│ - 当队列深度 > 100时,启动新Processor实例 │
│ - 当队列为空持续30s,回收Processor实例 │
│ - 每个Processor处理能力:100 events/s │
└────────────────────────────┬─────────────────────────────────────┘
│
┌────────────────────────────▼─────────────────────────────────────┐
│ Event Sinks (事件汇) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────────────┐ │
│ │Response │ │ Storage │ │ Alert │ │ Cloud Sync │ │
│ │Callback │ │ (DB/File)│ │ (Monitor)│ │ (Async Upload) │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────────────┘ │
└──────────────────────────────────────────────────────────────────┘事件驱动AI处理示例
java
@Component
public class EventDrivenAIService {
@Autowired
private EmbeddedMessageQueue messageQueue; // 嵌入式消息队列
@Autowired
private LocalOllamaService ollamaService;
/**
* 事件驱动的AI推理流水线
*/
@EventListener
public void onAIRequest(AIRequestEvent event) {
// Step 1: 发布原始事件到预处理队列
messageQueue.publish("raw-events", event);
}
/**
* 预处理器 - 过滤和标准化
*/
@KafkaListener(topics = "raw-events", groupId = "edge-preproc")
public void preprocess(AIRequestEvent event) {
// 数据清洗
String cleaned = sanitizeInput(event.getPrompt());
// 缓存检查
Optional<String> cached = cacheService.get(cleaned);
if (cached.isPresent()) {
messageQueue.publish("results", new AIResultEvent(
event.getId(), cached.get(), "cache"
));
return;
}
// 发布到AI推理队列
messageQueue.publish("ai-tasks", new AITask(event.getId(), cleaned));
}
/**
* AI推理处理器 - 自动批量聚合
*/
@Component
public static class BatchAIConsumer {
private final List<AITask> batch = new ArrayList<>();
private final ScheduledExecutorService scheduler
= Executors.newSingleThreadScheduledExecutor();
@PostConstruct
public void init() {
// 每100ms或积累10个任务触发一次批量推理
scheduler.scheduleAtFixedRate(this::flushBatch,
100, 100, TimeUnit.MILLISECONDS);
}
public void addTask(AITask task) {
synchronized (batch) {
batch.add(task);
if (batch.size() >= 10) {
flushBatch();
}
}
}
private void flushBatch() {
List<AITask> tasksToProcess;
synchronized (batch) {
if (batch.isEmpty()) return;
tasksToProcess = new ArrayList<>(batch);
batch.clear();
}
// 批量推理(吞吐量提升3-5x)
List<String> results = batchInference(tasksToProcess);
// 逐个发布结果
for (int i = 0; i < tasksToProcess.size(); i++) {
messageQueue.publish("results",
new AIResultEvent(tasksToProcess.get(i).getId(),
results.get(i), "edge"));
}
}
}
}优势总结:
- ✅ 完全解耦:各处理阶段独立运行、独立伸缩
- ✅ 弹性伸缩:根据队列深度自动增减Processor实例
- ✅ 削峰填谷:消息队列缓冲突发请求,保护推理引擎
- ✅ 异步处理:不阻塞调用方,适合IoT批量场景
✅ 推荐:IoT设备数据处理、视频流分析、日志实时分析
模式5:Edge Mesh 网格架构(Service Mesh for Edge)
核心思想:将服务网格(Service Mesh)下沉到边缘节点,通过Sidecar代理管理所有边缘服务间的通信、安全和可观测性。
架构特点
┌─────────────────────────────────────────────────────┐
│ Edge Service Mesh 架构 │
│ │
│ ┌────Edge App────┐ ┌────Edge App────┐ │
│ │ AI Service │ │ Vector DB │ │
│ └───────┬───────┘ └───────┬────────┘ │
│ │ mTLS │ mTLS │
│ ┌───────▼───────┐ ┌───────▼────────┐ │
│ │ Edge Sidecar │ │ Edge Sidecar │ │
│ │ (Envoy Lite) │◄──►│ (Envoy Lite) │ │
│ │ - 本地限流 │ │ - 健康检查 │ │
│ │ - 熔断保护 │ │ - 负载均衡 │ │
│ │ - 指标采集 │ │ - 重试超时 │ │
│ └───┬───────────┘ └───┬────────────┘ │
│ │ │ │
│ └────────┬───────────┘ │
│ │ │
│ ┌────────▼────────┐ │
│ │ Edge Control │ │
│ │ Plane (轻量级) │ │
│ │ - 配置下发 │ │
│ │ - 证书管理 │ │
│ │ - 可观测性聚合 │ │
│ └─────────────────┘ │
└─────────────────────────────────────────────────────┘核心能力:
- mTLS安全通信:所有边-边、边-云通信自动加密
- 本地限流熔断:防止单个边缘服务过载影响全局
- 灰度发布:支持边缘节点的A/B测试和灰度升级
- 可观测性:统一采集边缘节点的Metrics/Tracing/Logging
✅ 推荐:金融级边缘部署、大规模边缘集群(100+节点)
2.2 架构选择指南
| 场景 | 推荐模式 | 原因 |
|---|---|---|
| 移动App | 纯边缘 | 离线可用、隐私保护、超低延迟 |
| IoT设备/传感器 | 纯边缘 / 事件驱动 | 资源受限、实时性要求高、异步批处理 |
| 智能客服 | 混合云边 | 简单问答走边缘、复杂问题走云端 |
| 视频监控/流分析 | 事件驱动 | 流式处理、异步流水线、弹性伸缩 |
| 企业内网应用 | 边缘集群 | 高可用、水平扩展、服务网格治理 |
| 金融/医疗(高合规) | Edge Mesh | mTLS加密、审计追踪、灰度发布 |
| 大规模IoT(1000+设备) | 边缘集群 + 事件驱动 | 多级负载、边缘自治、异步解耦 |
| 智能工厂 | 混合云边 + 边缘集群 | 产线实时质检(边缘)+ 质量分析(云端) |
🔧 三、模型量化与压缩技术
3.1 为什么需要量化?
问题:大模型占用大量内存和计算资源
示例:
- Llama-2-7B(FP32):28GB
- Llama-2-7B(INT8):7GB
- Llama-2-7B(INT4):3.5GB
量化优势:
- ✅ 内存减少4-8倍
- ✅ 推理速度提升2-4倍
- ✅ 精度损失<2%
3.2 量化方法对比
| 方法 | 精度 | 压缩比 | 速度提升 | 难度 |
|---|---|---|---|---|
| Post-Training Quantization (PTQ) | 中等 | 4x | 2-3x | 低 |
| Quantization-Aware Training (QAT) | 高 | 4x | 2-3x | 高 |
| Dynamic Quantization | 中等 | 4x | 2x | 低 |
| Static Quantization | 高 | 4x | 3x | 中 |
3.3 ONNX模型量化
步骤1:导出ONNX模型
python
# Python脚本:导出PyTorch模型为ONNX
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b")
dummy_input = tokenizer("Hello", return_tensors="pt")["input_ids"]
torch.onnx.export(
model,
dummy_input,
"llama-2-7b.onnx",
input_names=["input_ids"],
output_names=["logits"],
dynamic_axes={
"input_ids": {0: "batch_size", 1: "sequence_length"},
"logits": {0: "batch_size", 1: "sequence_length"}
}
)步骤2:量化ONNX模型
python
import onnx
from onnxruntime.quantization import quantize_dynamic, QuantType
# 动态量化(推荐)
quantize_dynamic(
model_input="llama-2-7b.onnx",
model_output="llama-2-7b-int8.onnx",
weight_type=QuantType.QInt8
)
print("Quantization completed!")步骤3:加载量化模型
java
@Component
public class QuantizedModelLoader {
private OrtSession session;
@PostConstruct
public void loadModel() throws OrtException {
OrtEnvironment env = OrtEnvironment.getEnvironment();
OrtSession.SessionOptions options = new OrtSession.SessionOptions();
options.setOptimizationLevel(OptLevel.ALL_OPT);
// 加载量化后的ONNX模型
session = env.createSession(
"models/llama-2-7b-int8.onnx",
options
);
log.info("Quantized model loaded successfully");
}
public float[] inference(float[] inputData) throws OrtException {
OnnxTensor inputTensor = OnnxTensor.createTensor(
session.getEnvironment(),
ByteBuffer.wrap(inputData),
new long[]{1, inputData.length}
);
Map<String, OnnxTensor> inputs = Map.of("input_ids", inputTensor);
OrtResult result = session.run(inputs);
return extractOutput(result);
}
}3.4 高级量化技术:AWQ与GPTQ
AWQ(Activation-aware Weight Quantization)
AWQ是2024年提出的权重量化方法,2026年已成为边缘部署的主流量化方案。核心思想:并非所有权重通道对精度同等重要,根据激活值分布识别重要通道,对重要通道保留更高精度。
工作原理:
1. 分析校准数据集获取激活值分布
↓
2. 识别重要通道(激活值大的通道)
- 重要通道:保留FP16,或使用更细粒度量化
- 非重要通道:INT4量化
↓
3. 对权重进行缩放(Scale)
- 重要通道权重 × 缩放因子 s > 1
- 等效于在量化时保留更多信息
↓
4. 统一INT4量化
- 重要通道的INT4表示更精确
- 整体精度损失 < 1%AWQ vs 传统PTQ对比:
| 模型 | FP16 | PTQ INT4 | AWQ INT4 | AWQ提升 |
|---|---|---|---|---|
| Llama-2-7B | 100% | 97.2% | 98.8% | +1.6% |
| Llama-2-13B | 100% | 97.8% | 99.1% | +1.3% |
| Mistral-7B | 100% | 97.5% | 99.0% | +1.5% |
GPTQ(GPT Post-Training Quantization)
GPTQ基于Optimal Brain Quantization(OBQ)框架,通过逐步量化权重并补偿误差实现高精度INT4量化。
核心思想:
1. 选择要量化的权重列
↓
2. 将该列量化到INT4
↓
3. 计算量化引起的误差
↓
4. 将误差分配到未量化的权重上(误差补偿)
↓
5. 重复直到所有权重量化完成精度对比:
| 量化方法 | 7B模型 | 13B模型 | 70B模型 | 延迟 |
|---|---|---|---|---|
| FP16 (基准) | 100% | 100% | 100% | 1x |
| PTQ INT8 | 98.5% | 98.8% | 99.2% | 0.6x |
| PTQ INT4 | 97.2% | 97.8% | 98.5% | 0.4x |
| GPTQ INT4 | 98.5% | 99.0% | 99.3% | 0.4x |
| AWQ INT4 | 98.8% | 99.1% | 99.4% | 0.4x |
3.5 模型剪枝与知识蒸馏
结构剪枝(Structured Pruning):移除不重要的神经元/注意力头,直接减小模型尺寸。
原始Transformer层:
┌──────────────────────────────────────┐
│ Multi-Head Attention (32 heads) │
│ ┌──┐┌──┐┌──┐ ... ┌──┐┌──┐┌──┐ │
│ │H1││H2││H3│ │H30││H31││H32│ │
│ └──┘└──┘└──┘ └──┘└──┘└──┘ │
└──────────────────────────────────────┘
↓ 剪枝后 (移除不重要头)
┌──────────────────────────────────────┐
│ Multi-Head Attention (20 heads) │
│ ┌──┐┌──┐┌──┐ ┌──┐┌──┐┌──┐ │
│ │H1││H3││H5│ │H20││H22││H28│ │
│ └──┘└──┘└──┘ └──┘└──┘└──┘ │
└──────────────────────────────────────┘
模型大小: 7B → 5.2B (-26%),精度损失 < 1%知识蒸馏(Knowledge Distillation):用大模型(Teacher)的知识训练小模型(Student)。
┌────────────────────────────────────────────────────────┐
│ Knowledge Distillation Pipeline │
│ │
│ Teacher (70B) ───Soft Labels───► Student (3B) │
│ │
│ Loss = α * KL(Teacher||Student) + (1-α) * CE(Student) │
│ α = 0.5 (典型值) │
└──────────────────────────────────────────────────────────┘组合优化策略(2026推荐方案):
| 步骤 | 技术 | 效果 |
|---|---|---|
| 1 | 知识蒸馏 70B → 7B | 模型减至1/10 |
| 2 | 结构剪枝 7B → 5B | 减少30%参数 |
| 3 | AWQ INT4量化 5B→1.5GB | 减少4x内存 |
| 总计 | 70B → 1.5GB | 可在边缘设备运行 |
🧠 四、ONNX Runtime深度集成
4.1 添加依赖
xml
<dependency>
<groupId>com.microsoft.onnxruntime</groupId>
<artifactId>onnxruntime</artifactId>
<version>1.16.0</version>
</dependency>4.2 Embedding模型本地部署
场景:本地运行text-embedding模型,避免API调用
java
@Component
public class LocalEmbeddingService {
private OrtSession embeddingSession;
private Tokenizer tokenizer;
@PostConstruct
public void init() throws OrtException, IOException {
// 加载embedding模型
OrtEnvironment env = OrtEnvironment.getEnvironment();
embeddingSession = env.createSession("models/bge-base-zh.onnx");
// 加载tokenizer
tokenizer = Tokenizer.getInstance("models/bge-base-zh/tokenizer.json");
}
/**
* 生成本地embedding
*/
public float[] embed(String text) throws OrtException {
// 1. Tokenize
int[] inputIds = tokenizer.encode(text);
// 2. 准备输入
OnnxTensor inputTensor = OnnxTensor.createTensor(
embeddingSession.getEnvironment(),
IntBuffer.wrap(inputIds),
new long[]{1, inputIds.length}
);
// 3. 推理
Map<String, OnnxTensor> inputs = Map.of("input_ids", inputTensor);
OrtResult result = embeddingSession.run(inputs);
// 4. 提取embedding
float[][] embeddings = (float[][]) result.get(0).getValue();
// 5. 归一化
return normalize(embeddings[0]);
}
private float[] normalize(float[] vector) {
float norm = 0;
for (float v : vector) {
norm += v * v;
}
norm = (float) Math.sqrt(norm);
float[] normalized = new float[vector.length];
for (int i = 0; i < vector.length; i++) {
normalized[i] = vector[i] / norm;
}
return normalized;
}
}性能对比:
| 方式 | 延迟 | 成本 | 隐私 |
|---|---|---|---|
| OpenAI API | 200-500ms | $0.0001/次 | 数据上传 |
| 本地ONNX | 20-50ms | 免费 | 完全本地 |
🐒 五、DJL(Deep Java Library)实战
5.1 什么是DJL?
DJL = Amazon开源的Java深度学习框架
优势:
- ✅ 原生Java支持
- ✅ 多引擎后端(PyTorch/TensorFlow/MXNet)
- ✅ 模型 zoo(预训练模型)
- ✅ 易于集成Spring Boot
5.2 添加依赖
xml
<dependency>
<groupId>ai.djl</groupId>
<artifactId>api</artifactId>
<version>0.28.0</version>
</dependency>
<dependency>
<groupId>ai.djl.pytorch</groupId>
<artifactId>pytorch-engine</artifactId>
<version>0.28.0</version>
</dependency>
<dependency>
<groupId>ai.djl.huggingface</groupId>
<artifactId>tokenizers</artifactId>
<version>0.28.0</version>
</dependency>5.3 文本分类示例
java
@Component
public class TextClassificationService {
private ZooModel<String, Classifications> model;
private Predictor<String, Classifications> predictor;
@PostConstruct
public void init() throws ModelException, IOException, TranslateException {
// 加载预训练模型
Criteria<String, Classifications> criteria = Criteria.builder()
.optApplication(Application.NLP.TEXT_CLASSIFICATION)
.optEngine("PyTorch")
.optFilter("backbone", "bert")
.build();
model = ModelZoo.loadModel(criteria);
predictor = model.newPredictor();
}
/**
* 情感分析
*/
public SentimentResult analyzeSentiment(String text) {
try {
Classifications result = predictor.predict(text);
String label = result.best().getClassName();
float confidence = result.best().getProbability();
return new SentimentResult(label, confidence);
} catch (TranslateException e) {
log.error("Prediction failed", e);
throw new RuntimeException("情感分析失败", e);
}
}
@PreDestroy
public void cleanup() {
predictor.close();
model.close();
}
}5.4 图像识别示例
java
@Component
public class ImageRecognitionService {
private ZooModel<Image, Classifications> model;
private Predictor<Image, Classifications> predictor;
@PostConstruct
public void init() throws ModelException, IOException, TranslateException {
Criteria<Image, Classifications> criteria = Criteria.builder()
.optApplication(Application.CV.IMAGE_CLASSIFICATION)
.optEngine("PyTorch")
.optFilter("backbone", "resnet50")
.build();
model = ModelZoo.loadModel(criteria);
predictor = model.newPredictor();
}
/**
* 识别图片内容
*/
public List<ObjectDetection> recognizeImage(BufferedImage image) {
try {
Image djlImage = ImageFactory.getInstance().fromImage(image);
Classifications result = predictor.predict(djlImage);
return result.stream()
.map(c -> new ObjectDetection(
c.getClassName(),
c.getProbability()
))
.sorted(Comparator.comparingDouble(ObjectDetection::getConfidence).reversed())
.limit(5)
.collect(Collectors.toList());
} catch (TranslateException e) {
log.error("Image recognition failed", e);
throw new RuntimeException("图片识别失败", e);
}
}
}💬 六、本地聊天机器人(Ollama + Spring AI)
6.1 使用Ollama集成
Ollama = 本地LLM运行工具
安装:
bash
# macOS
brew install ollama
# Linux
curl -fsSL https://ollama.ai/install.sh | sh
# 下载模型
ollama pull llama2:7b6.2 Spring AI集成Ollama
添加依赖:
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>配置:
yaml
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: llama2:7b
temperature: 0.7使用:
java
@RestController
@RequestMapping("/api/chat")
public class LocalChatController {
@Autowired
private ChatClient chatClient;
@PostMapping
public ResponseEntity<String> chat(@RequestBody ChatRequest request) {
String response = chatClient.prompt()
.user(request.getMessage())
.call()
.content();
return ResponseEntity.ok(response);
}
}性能:
- CPU推理:5-10 tokens/s
- GPU推理:30-50 tokens/s
- 完全离线可用 ✅
6.3 RAG本地部署
完整离线RAG系统:
java
@Component
public class OfflineRagService {
@Autowired
private LocalEmbeddingService embeddingService;
@Autowired
private VectorStore vectorStore; // pgvector或Chroma
@Autowired
private ChatClient localChatClient; // Ollama
/**
* 离线RAG查询
*/
public String query(String question) {
// 1. 本地生成embedding
float[] queryVector = embeddingService.embed(question);
// 2. 向量检索
List<Document> docs = vectorStore.similaritySearch(
SearchRequest.query(queryVector)
.withTopK(5)
);
// 3. 构建上下文
String context = docs.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n\n"));
// 4. 本地LLM生成回答
String prompt = String.format("""
基于以下上下文回答问题:
%s
问题:%s
回答:
""", context, question);
return localChatClient.prompt()
.user(prompt)
.call()
.content();
}
}优势:
- ✅ 完全离线
- ✅ 数据隐私保护
- ✅ 零API成本
☁️ 七、混合云边架构
7.1 智能路由
java
@Component
public class HybridRouter {
@Autowired
private LocalChatService localService;
@Autowired
private CloudChatService cloudService;
/**
* 根据条件选择边缘或云端
*/
public String routeAndExecute(ChatRequest request) {
RoutingDecision decision = makeDecision(request);
if (decision.useEdge()) {
log.info("Routing to edge for request: {}", request.getId());
return localService.chat(request);
} else {
log.info("Routing to cloud for request: {}", request.getId());
return cloudService.chat(request);
}
}
private RoutingDecision makeDecision(ChatRequest request) {
RoutingDecision decision = new RoutingDecision();
// 规则1:简单任务走边缘
if (isSimpleTask(request)) {
decision.setUseEdge(true);
decision.setReason("Simple task");
return decision;
}
// 规则2:隐私敏感数据走边缘
if (containsSensitiveData(request)) {
decision.setUseEdge(true);
decision.setReason("Privacy concern");
return decision;
}
// 规则3:复杂推理走云端
if (requiresComplexReasoning(request)) {
decision.setUseEdge(false);
decision.setReason("Complex reasoning needed");
return decision;
}
// 规则4:边缘负载过高时走云端
if (edgeLoadTooHigh()) {
decision.setUseEdge(false);
decision.setReason("Edge overloaded");
return decision;
}
// 默认走边缘
decision.setUseEdge(true);
decision.setReason("Default to edge");
return decision;
}
}7.2 故障转移
java
@Component
public class FailoverHandler {
@Autowired
private LocalChatService localService;
@Autowired
private CloudChatService cloudService;
/**
* 带故障转移的执行
*/
public String executeWithFailover(ChatRequest request) {
try {
// 尝试边缘执行
return localService.chat(request);
} catch (Exception e) {
log.warn("Edge execution failed, falling back to cloud", e);
// 故障转移到云端
try {
return cloudService.chat(request);
} catch (Exception cloudError) {
log.error("Both edge and cloud failed", cloudError);
throw new ServiceException("Service unavailable");
}
}
}
}🔒 八、隐私保护策略与合规
8.1 数据脱敏
java
@Component
public class DataMaskingService {
/**
* 脱敏敏感信息后再发送到云端
*/
public String maskSensitiveData(String text) {
// 手机号脱敏
text = text.replaceAll("\\b1[3-9]\\d{9}\\b", "[PHONE_MASKED]");
// 邮箱脱敏
text = text.replaceAll("\\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Z|a-z]{2,}\\b", "[EMAIL_MASKED]");
// 身份证脱敏
text = text.replaceAll("\\b\\d{17}[0-9X]\\b", "[ID_MASKED]");
return text;
}
}8.2 联邦学习
概念:模型在本地训练,只上传梯度更新
┌────────┐ ┌────────┐ ┌────────┐
│Edge 1 │ │Edge 2 │ │Edge 3 │
│Train │ │Train │ │Train │
└───┬────┘ └───┬────┘ └───┬────┘
│ │ │
▼ ▼ ▼
┌─────────────────────────────────┐
│ Central Server (Aggregate) │
└─────────────────────────────────┘优势:
- ✅ 原始数据不出本地
- ✅ 利用集体智慧优化模型
- ✅ 符合GDPR等隐私法规
📊 九、性能优化
9.1 模型加载优化
java
@Component
public class ModelCache {
private final LoadingCache<String, ZooModel<?, ?>> modelCache;
public ModelCache() {
modelCache = Caffeine.newBuilder()
.maximumSize(10)
.expireAfterAccess(1, TimeUnit.HOURS)
.build(new CacheLoader<String, ZooModel<?, ?>>() {
@Override
public ZooModel<?, ?> load(String key) throws Exception {
return loadModel(key);
}
});
}
public <I, O> ZooModel<I, O> getModel(String modelKey) {
return (ZooModel<I, O>) modelCache.get(modelKey);
}
}9.2 批量推理
java
@Component
public class BatchInferenceService {
/**
* 批量处理请求,提高吞吐量
*/
public List<Result> batchProcess(List<Input> inputs) {
// 合并为一个批次
BatchInput batch = mergeInputs(inputs);
// 一次推理
BatchOutput output = model.predict(batch);
// 拆分结果
return splitOutputs(output);
}
}性能提升:
- 单个推理:50ms/次
- 批量推理(batch=10):200ms/10次 = 20ms/次
- 提升2.5倍 ⚡
🏭 十、2026企业级实战案例深度解析
10.1 案例一:智能工厂质检系统
背景:某汽车零部件制造商,需要实时检测生产线上的产品缺陷。传统方案依赖云端AI(延迟200ms+),无法满足产线节拍(节拍时间500ms)。
架构方案:纯边缘 + 事件驱动 + Edge Mesh
┌────────────────────────────────────────────────────────┐
│ 智能工厂质检系统架构 │
│ │
│ 产线摄像头 ──(MQTT)──► Edge Gateway │
│ │ │
│ ┌─────────▼─────────┐ │
│ │ Event Processor │ │
│ │ (Spring Boot) │ │
│ └─────────┬─────────┘ │
│ │ │
│ ┌─────────▼─────────┐ │
│ │ AI Inference │ │
│ │ (ResNet-50 ONNX) │ │
│ │ INT8量化: 28ms │ │
│ └─────────┬─────────┘ │
│ │ │
│ ┌─────────▼─────────┐ │
│ │ Result Publisher │ │
│ ├───────────────────┤ │
│ │ 合格 → 继续生产 │ │
│ │ 缺陷 → 触发剔除 │ │
│ │ 异常 → 云端复检 │ │
│ └───────────────────┘ │
└────────────────────────────────────────────────────────┘技术指标:
| 指标 | 传统云端方案 | 边缘AI方案 | 提升 |
|---|---|---|---|
| 推理延迟 | 200-500ms | 28ms | 94%↓ |
| 检测精度 | 99.2% | 99.5% | +0.3% |
| 月度成本 | $12,000 | $1,500 | 87%↓ |
| 数据安全 | 数据上传云端 | 数据不出厂 | 100%安全 |
java
@Component
public class SmartFactoryInspectionService {
@Autowired
private ONNXInferenceService inferenceService;
@Autowired
private EmbeddedMessageQueue messageQueue;
/**
* 事件驱动的产线质检
*/
@EventListener
public void onImageCaptured(ImageCaptureEvent event) {
long startTime = System.nanoTime();
try {
// 1. 图片预处理(缩放、归一化)
float[] tensor = preprocessImage(event.getImage());
// 2. 本地ONNX推理(INT8模型, ~28ms)
float[] result = inferenceService.inference(tensor);
// 3. 缺陷分类
InspectionResult inspection = classifyDefect(result);
// 4. 执行产线动作(50ms内必须完成)
executeLineAction(inspection);
// 5. 记录日志
long latency = (System.nanoTime() - startTime) / 1_000_000;
log.info("Inspection completed in {}ms, result: {}",
latency, inspection.getStatus());
// 6. 异常样本异步上传云端复检
if (inspection.isUncertain()) {
messageQueue.publish("cloud-review", event);
}
} catch (Exception e) {
log.error("Inspection failed, triggering safety stop", e);
messageQueue.publish("alerts", new AlertEvent(
"INSPECTION_FAIL", event.getLineId()));
}
}
}10.2 案例二:医疗影像离线辅助诊断
背景:基层医院/偏远诊所网络条件差,需离线运行CT/X光影像分析模型,辅助医生快速诊断。
架构方案:纯边缘部署 + DJL医学影像模型 + 本地RAG
技术实现:
java
@Component
public class MedicalImageDiagnosisService {
private ZooModel<Image, Classifications> densenetModel;
private Predictor<Image, Classifications> predictor;
@PostConstruct
public void init() throws ModelException, IOException {
// 加载DenseNet-121医学影像预训练模型
Criteria<Image, Classifications> criteria = Criteria.builder()
.optApplication(Application.CV.IMAGE_CLASSIFICATION)
.optEngine("PyTorch")
.optFilter("backbone", "densenet121")
.optFilter("dataset", "chest-xray")
.optProgress(new ProgressBar())
.build();
model = ModelZoo.loadModel(criteria);
predictor = model.newPredictor();
}
/**
* 离线分析CT影像
* @return 诊断建议 + 置信度
*/
public DiagnosisResult analyzeCTScan(BufferedImage ctImage) {
// Step 1: 影像预处理
Image djlImage = ImageFactory.getInstance().fromImage(ctImage);
// Step 2: 模型推理
Classifications result = predictor.predict(djlImage);
// Step 3: 提取诊断结果
String finding = result.best().getClassName();
float confidence = result.best().getProbability();
// Step 4: 置信度检查
DiagnosisResult diagnosis = new DiagnosisResult(finding, confidence);
if (confidence < 0.7) {
diagnosis.setNeedsExpertReview(true);
diagnosis.setSuggestion("建议结合临床资料进一步确认");
}
return diagnosis;
}
}性能指标:
| 指标 | 数值 | 说明 |
|---|---|---|
| 单张CT诊断 | 150ms | 完全离线 |
| 模型大小 | 120MB | INT8量化 |
| 诊断准确率 | 94.5% | 接近云端GPT-4o水平 |
| 数据隐私 | 100%本地 | 符合HIPAA合规 |
| 可用性 | 100% | 无需网络 |
10.3 案例三:金融风控边缘节点
背景:银行需在ATM/网点边缘节点实时检测欺诈交易,敏感数据不得出网点。
架构方案:Edge Mesh + 混合云边 + 差分隐私
核心代码:
java
@Component
public class EdgeFraudDetectionService {
@Autowired
private LocalFraudModel localModel; // 边缘轻量模型
@Autowired
private CloudFraudService cloudService; // 云端深度模型
// Edge Mesh mTLS通信
@Autowired
private EdgeMeshClient meshClient;
/**
* 两阶段欺诈检测
*/
public FraudResult detectFraud(Transaction transaction) {
// Phase 1: 边缘快速筛查(<10ms)
FraudResult quickCheck = localModel.quickScreen(transaction);
if (quickCheck.isClear()) {
// 低风险:直接通过
return quickCheck;
}
// Phase 2: 可疑交易上送云端深度分析
// 数据脱敏后再传输
Transaction maskedTx = maskSensitiveData(transaction);
try {
return cloudService.deepAnalyze(maskedTx);
} catch (Exception e) {
// 云端不可用时,边缘保守策略
log.warn("Cloud unavailable, applying conservative edge policy");
return localModel.conservativeDecision(transaction);
}
}
/**
* PCI-DSS合规脱敏
*/
private Transaction maskSensitiveData(Transaction tx) {
return new Transaction(
tx.getId(),
maskCardNumber(tx.getCardNumber()), // 6222****1234
tx.getAmount(),
tx.getTimestamp(),
null // 不传输CVV
);
}
}效果:
- 边缘过滤**92%的正常交易,仅8%**上送云端
- 平均延迟从600ms 降至8ms(边缘通过)
- 敏感数据零泄露(脱敏后上云)
- PCI-DSS合规自动满足
📊 十一、边缘AI MLOps与可观测性
11.1 边缘MLOps生命周期
┌───────────────────────────────────────────────────────────────┐
│ Edge MLOps Pipeline │
│ │
│ 云端: │
│ ┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ │
│ │数据采集 │→ │模型训练 │→ │模型评估 │→ │模型量化 │→ │模型签名 │ │
│ └────────┘ └────────┘ └────────┘ └────────┘ └────────┘ │
│ │
│ │ 模型推送 (Delta Update) │
│ ▼ │
│ 边缘: │
│ ┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ │
│ │模型校验 │→ │模型加载 │→ │A/B测试 │→ │灰度发布 │→ │监控告警 │ │
│ └────────┘ └────────┘ └────────┘ └────────┘ └────────┘ │
│ │
│ 回滚策略: 如果新模型效果下降 > 2%,自动回滚到上一个版本 │
└───────────────────────────────────────────────────────────────┘11.2 边缘节点监控
java
@Component
public class EdgeObservabilityManager {
@Autowired
private MeterRegistry meterRegistry;
@Autowired
private OpenTelemetry openTelemetry;
@PostConstruct
public void init() {
// 注册边缘AI关键指标
registerEdgeMetrics();
// 启动健康检查
scheduleHealthChecks();
}
private void registerEdgeMetrics() {
// 推理延迟(P50/P95/P99)
Timer inferenceLatency = Timer.builder("edge.inference.latency")
.publishPercentiles(0.5, 0.95, 0.99)
.register(meterRegistry);
// 模型加载时间
Gauge.builder("edge.model.load.time", this,
EdgeObservabilityManager::getModelLoadTime)
.register(meterRegistry);
// 内存使用率
Gauge.builder("edge.memory.usage", this,
EdgeObservabilityManager::getMemoryUsage)
.register(meterRegistry);
// 队列深度(事件驱动模式)
Gauge.builder("edge.queue.depth", this,
EdgeObservabilityManager::getQueueDepth)
.register(meterRegistry);
// 节点在线状态(Gossip协议)
Gauge.builder("edge.node.health", this,
EdgeObservabilityManager::getNodeHealth)
.register(meterRegistry);
}
/**
* 模型更新健康检查
*/
@Scheduled(fixedRate = 60000) // 每分钟
public void checkModelHealth() {
// 获取所有活跃模型
List<ModelInstance> models = modelManager.getActiveModels();
for (ModelInstance model : models) {
// 检查模型推理延迟是否异常
double avgLatency = getAvgLatency(model.getId(), 5);
if (avgLatency > model.getExpectedLatency() * 1.5) {
log.warn("Model {} latency anomaly: {}ms (expected: {}ms)",
model.getId(), avgLatency, model.getExpectedLatency());
// 触发模型重启或回滚
handleModelDegradation(model);
}
// 检查模型精度漂移
double accuracyDrop = detectAccuracyDrift(model);
if (accuracyDrop > 0.02) { // 2%精度下降
log.warn("Model {} accuracy drift detected: {}%",
model.getId(), accuracyDrop * 100);
// 标记模型需要重新训练
triggerRetraining(model);
}
}
}
/**
* 远程日志聚合
*/
@Scheduled(fixedRate = 300000) // 每5分钟
public void syncEdgeLogs() {
// 聚合边缘日志(只上传聚合指标,不上传原始数据)
EdgeMetricsSummary summary = aggregateMetrics();
cloudLogService.syncMetrics(summary);
}
}11.3 关键监控指标
| 指标 | 告警阈值 | 严重级别 | 说明 |
|---|---|---|---|
| 推理延迟 P95 | > 100ms | Critical | 影响用户体验 |
| 模型加载时间 | > 30s | Warning | 冷启动问题 |
| 内存使用率 | > 85% | Warning | 触发模型卸载 |
| 队列深度 | > 1000 | Critical | 处理能力不足 |
| 精度漂移 | > 2% | Warning | 需要重新训练 |
| 节点离线 | > 1个 | Critical | 集群降级 |
| 磁盘使用率 | > 90% | Warning | 清理缓存模型 |
11.4 模型远程更新策略
java
@Component
public class RemoteModelUpdater {
@Value("${model.update.endpoint:https://mlops.company.com/api/models}")
private String mlopsEndpoint;
/**
* 增量模型更新(Delta Update)
* 只传输变更参数,减少带宽消耗
*/
public void applyDeltaUpdate(String modelName, ModelDelta delta) {
// 1. 备份当前模型
backupCurrentModel(modelName);
// 2. 应用增量更新
ModelVersion current = modelManager.getActiveVersion(modelName);
ModelVersion updated = applyPatch(current, delta.getPatchData());
// 3. 在影子模型中验证
String shadowVersion = modelManager.loadShadowModel(updated);
// 4. A/B测试
boolean abTestPassed = runABTest(modelName, shadowVersion, 100); // 100个请求
if (abTestPassed) {
// 5. 灰度发布(蓝绿部署)
modelManager.promoteToProduction(shadowVersion);
log.info("Model {} updated to version {} (delta: {}KB)",
modelName, updated.getVersion(), delta.getSizeKB());
} else {
// 6. 回滚
modelManager.rollback(modelName);
log.warn("Model {} update failed, rolled back", modelName);
}
}
}📝 十二、总结与展望
边缘计算是AI应用的关键基础设施,2026年企业级边缘AI已从"可选"变为"必选"。
关键要点回顾
✅ 六层企业级架构 :设备层→推理层→数据层→网格层→云边互联→可观测性
✅ 五种部署模式 :纯边缘/混合云边/边缘集群/事件驱动/Edge Mesh
✅ 模型量化技术栈 :PTQ→AWQ→GPTQ,INT4精度损失<1%
✅ 模型压缩 :知识蒸馏70B→7B + 剪枝 + 量化 = 1.5GB边缘可用
✅ 优化推理 :投机解码3x加速 + PagedAttention 96%内存利用 + 连续批处理
✅ ONNX Runtime :多Execution Provider自动选择最优硬件
✅ DJL框架 :Java原生深度学习,无缝集成Spring Boot
✅ Ollama集成 :本地LLM运行,CPU/GPU全支持
✅ 离线RAG :完整本地化的Embedding + 向量检索 + LLM方案
✅ 混合路由 :多维度智能路由(复杂度/隐私/负载/成本)
✅ 隐私保护 :数据脱敏 + 联邦学习 + 差分隐私 + TEE机密计算
✅ 边缘MLOps :增量更新 + A/B测试 + 灰度发布 + 自动回滚
✅ 可观测性:Prometheus + Grafana + OpenTelemetry + Loki
2026最佳实践
选型建议:
- 移动/IoT:纯边缘 + AWQ INT4量化 + 投机解码
- 企业应用(高合规):Edge Mesh + 混合云边 + TEE
- 视频/流处理:事件驱动 + 连续批处理 + 弹性伸缩
- 金融/医疗:Edge Mesh + 联邦学习 + 差分隐私
- 大规模IoT集群:边缘集群 + 事件驱动 + Gossip协议
性能优化清单:
- 模型必须量化:优先AWQ/GPTQ INT4
- 批量推理 + 连续批处理(吞吐量提升2-5x)
- 模型缓存 + 结果缓存(延迟降低60%)
- GPU加速优先,其次NPU,最后CPU优化
- PagedAttention管理KV-Cache(内存节省85%)
- 投机解码加速生成(3x加速)
隐私合规清单:
- 敏感数据本地处理(边缘)
- 上传前必须脱敏(手机号/身份证/银行卡)
- 考虑联邦学习替代集中训练
- 金融/医疗行业考虑TEE机密计算
- 所有通信启用mTLS
- 模型文件加密存储(AES-256)
2026年边缘AI趋势展望
- 边缘多模态:LLM + 视觉 + 音频在单一边缘节点融合推理
- WebAssembly Edge:WASM运行时在边缘运行AI模型,跨平台零依赖
- 边缘Agent:自主决策的边缘AI Agent,可离线执行复杂工作流
- 混合精度推理:动态选择FP16/INT8/INT4层级别精度,平衡质量与速度
- 边缘联邦学习普及:2026年将是联邦学习在边缘大规模落地的一年
- AI芯片多样化:NPU/TPU/VPU等异构芯片百花齐放
下一步学习
- 进阶13 Spring AI 安全最佳实践(进阶版) - 深度安全防护
- 进阶14 Spring AI 可观测性最佳实践 - 生产监控
- 进阶15 Spring AI 模型微调实践 - LoRA/QLoRA在边缘的应用
- 进阶16 Spring AI vs LangChain4j 深度对比 - 技术选型
最后更新 :2026-05-23
版本 :v2.0(全面优化版)
作者:12年OTA公司资深程序员
让AI更快速、更安全、更私密! 🚀✨