前言:
大家好,今天这篇文章将从索引本质、数据结构、物理存储、索引分类、创建删除、性能压测、最左前缀、索引优化全覆盖、可直接复制运行,适合学习、笔记、复习、面试使用。在 MySQL 性能优化中,索引是最关键、最有效、最常用的手段。没有索引 = 全表扫描;有了索引 = 快速定位。但索引不是越多越好,理解原理、结构、适用场景,才能写出真正高效的 SQL。声明一下,由于本章概念性的知识比较多,有些地方会直接放上资料的截图大家自行进行查看理解一下。
一. 索引是什么
1.1 初步认识索引
索引是帮助 MySQL高效获取数据的数据结构(B + 树)。可以理解为:书的目录。
优点:
- 大幅提高查询速度
- 降低磁盘 IO 次数
- 优化排序、分组操作
缺点:
- 占用磁盘空间
- 降低增删改效率(需要维护索引树)
- 过多索引会导致优化器选择困难
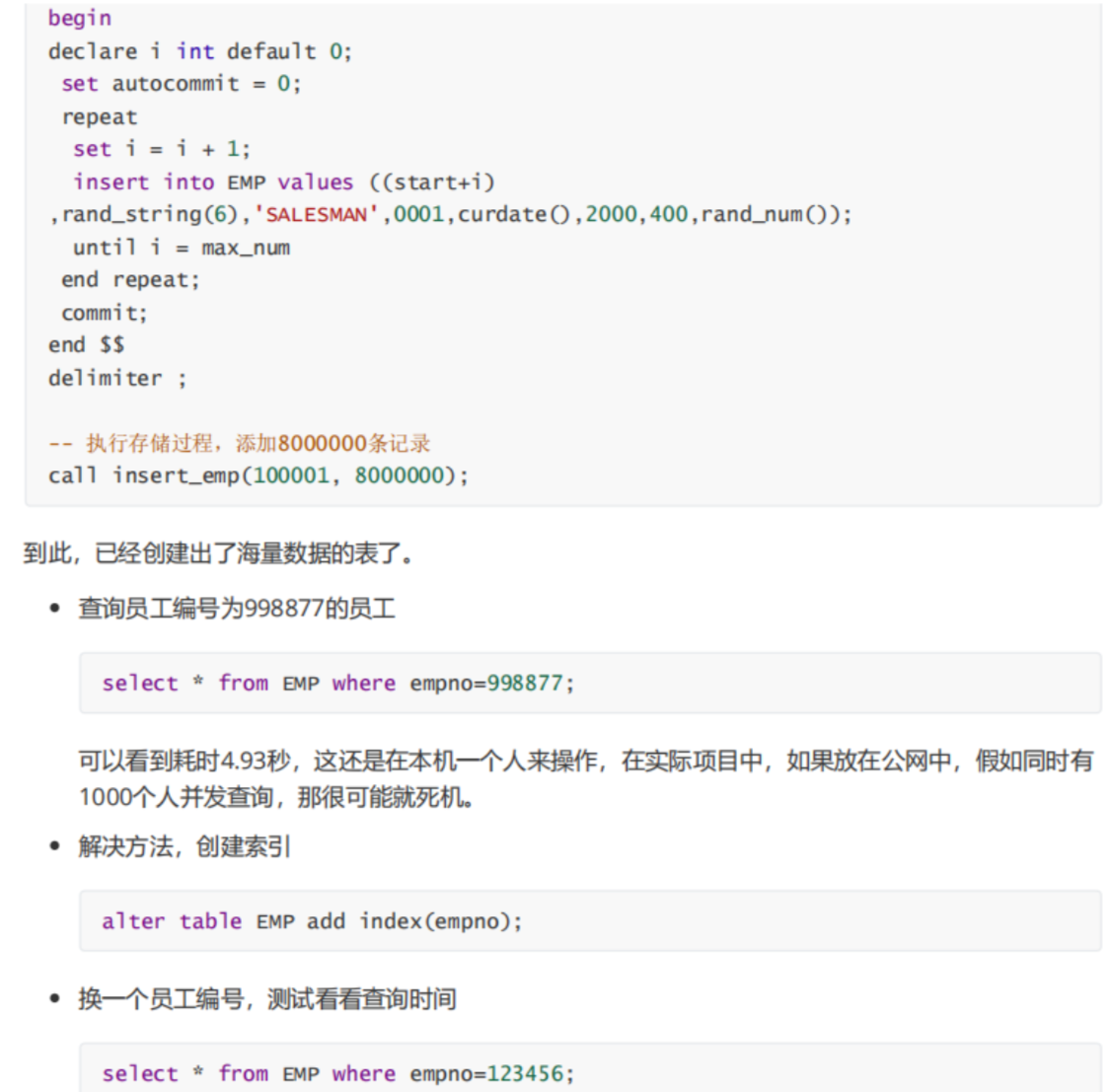
大家感兴趣的话可以做一下下面这个实验

二. 索引底层数据结构:B + 树
2.1 B + 树结构的特点
-
叶子节点保存有数据,非叶子节点(即路上节点)不存储数据,只存储目录项。因为非叶子节点不存数据,所以可以存储更多的目录项,从而管理更多的叶子节点。这样形成的树结构矮胖,查找时经过的节点少,每次读取的 page 更少,可以大大提升搜索效率。在十层左右的树中,整体效率会有显著提高。 -
叶子节点全部用链表级联起来。这是 B+ 树的一个重要特点,主要目的是为了高效地进行范围查找。
为何选择 B+
- 节点不存储 data,这样一个节点就可以存储更多的 key。可以使得树更矮,所以 IO 操作次数更少。
- 叶子节点相连,更便于进行范围查找
2.2 为何选择 B+ 树
重点:为什么不用二叉树、红黑树、B 树?
- 二叉树:数据倾斜时高度极高,IO 多
- 红黑树:层数仍然高
- B 树:叶子节点不连续,范围查询慢
- B + 树:MySQL 最终选择

三. InnoDB 与 MyISAM 索引实现(聚簇索引和非聚簇索引)
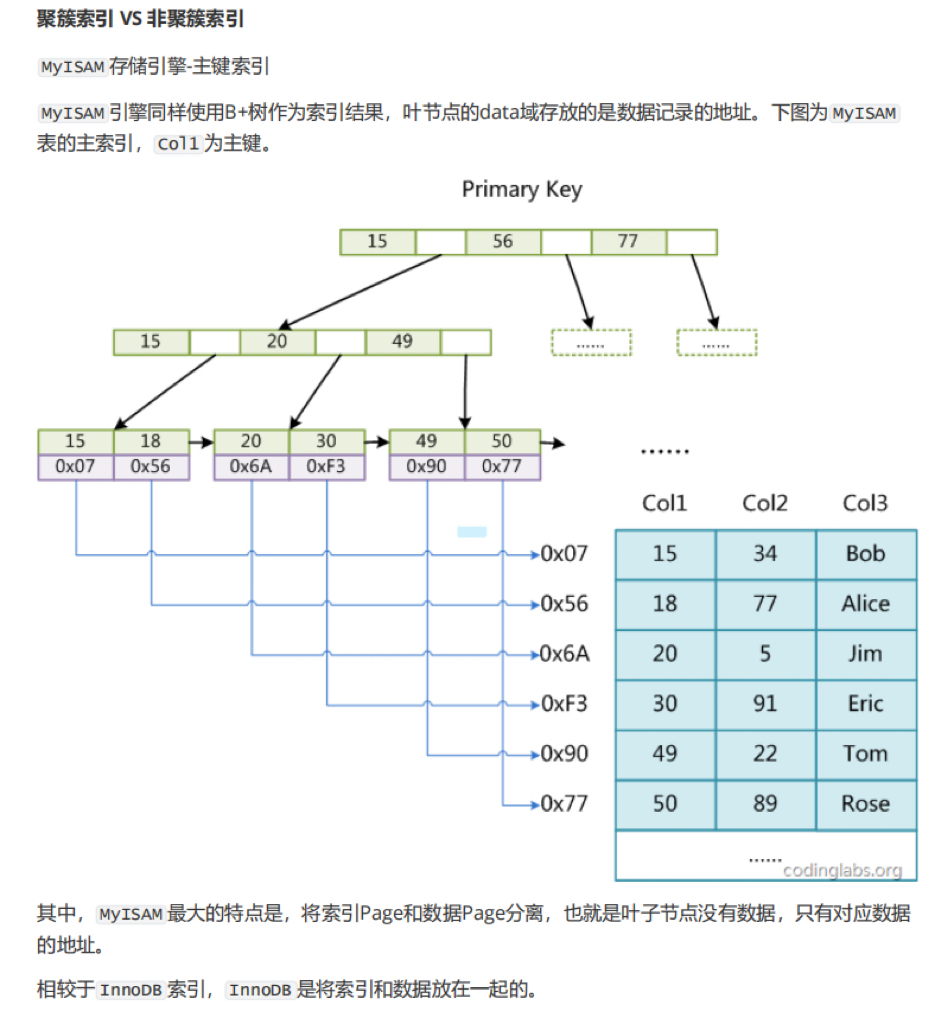
3.1 InnoDB:聚簇索引
- 索引即数据,数据即索引
.ibd文件 = 索引 + 数据- 主键索引叶子节点存储完整记录
- 辅助索引叶子节点存储:主键值

3.2 MyISAM:非聚簇索引
- 索引和数据分开存储
.MYD数据文件.MYI索引文件- 索引叶子节点存储:数据地址指针

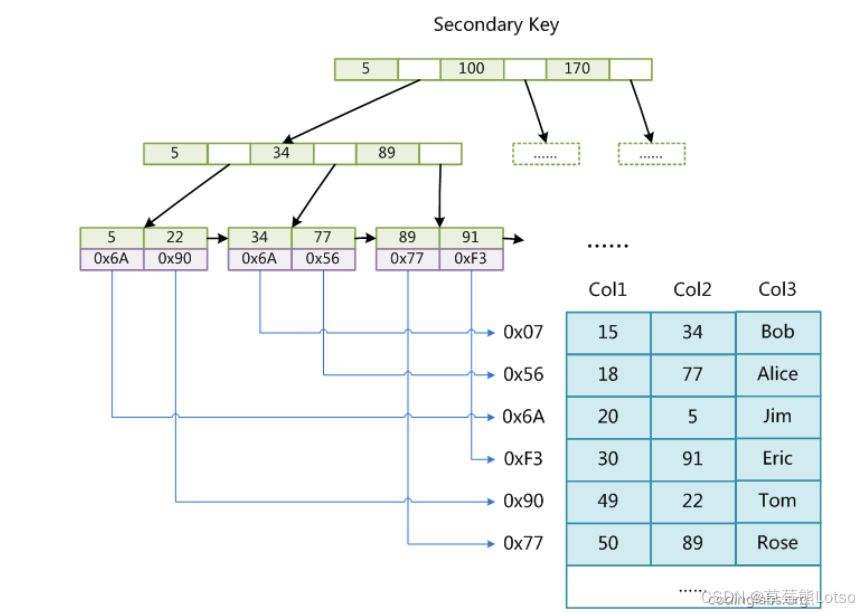
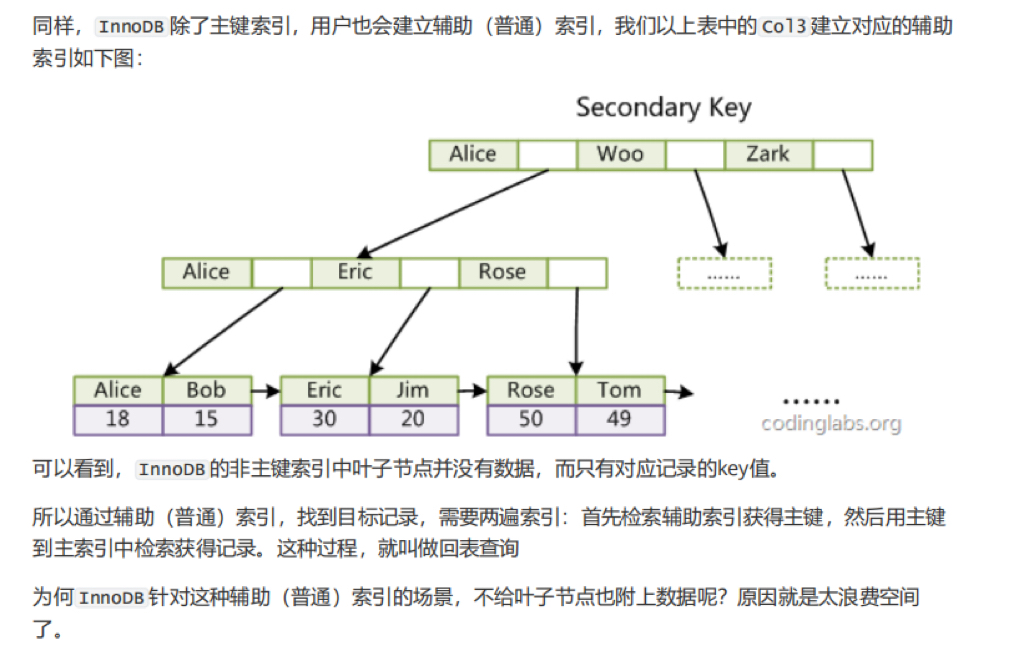
3.3 回表查询(辅助索引补充)
通过辅助索引找到主键 → 再通过主键查数据 → 叫回表 。
避免回表的方法:覆盖索引 (后面会讲到的)。
四. 索引分类与创建
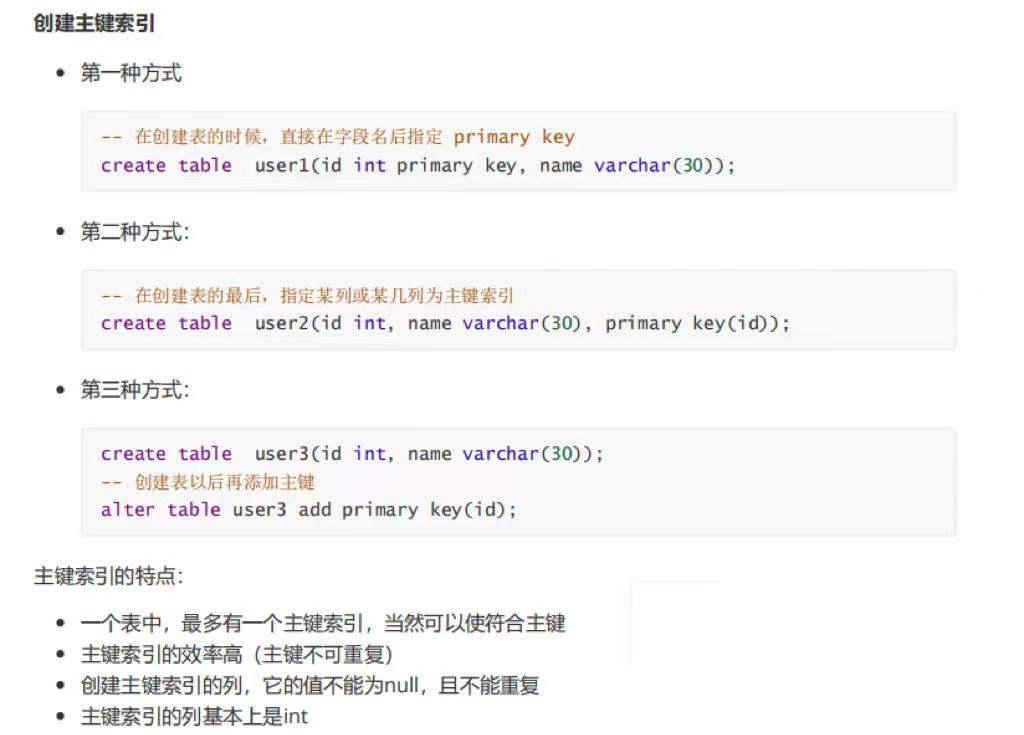
4.1 主键索引(primary key)
- 非空、唯一、一个表只能一个
- 默认为聚簇索引
sql
create table user(
id int primary key auto_increment,
name varchar(20)
);
4.2 唯一索引(unique)
- 列值唯一,允许
null - 适合身份证、手机号、邮箱
sql
create unique index idx_name on user(name);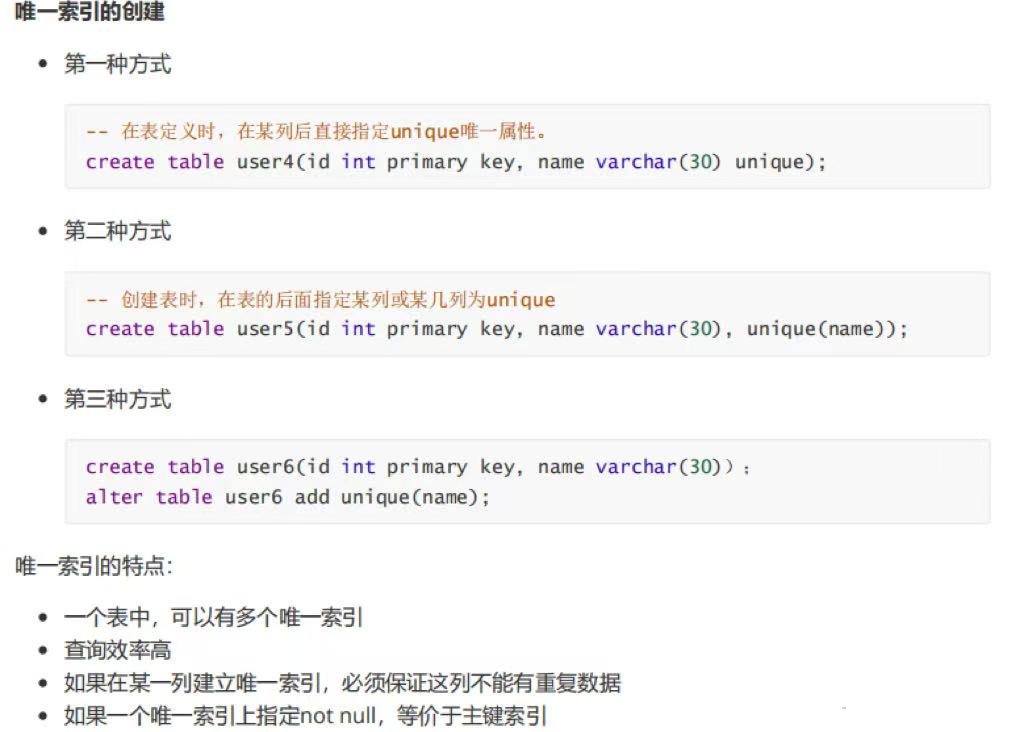
4.3 普通索引(index)
- 仅加速查询
- 无唯一性限制
sql
create index idx_name on user(name);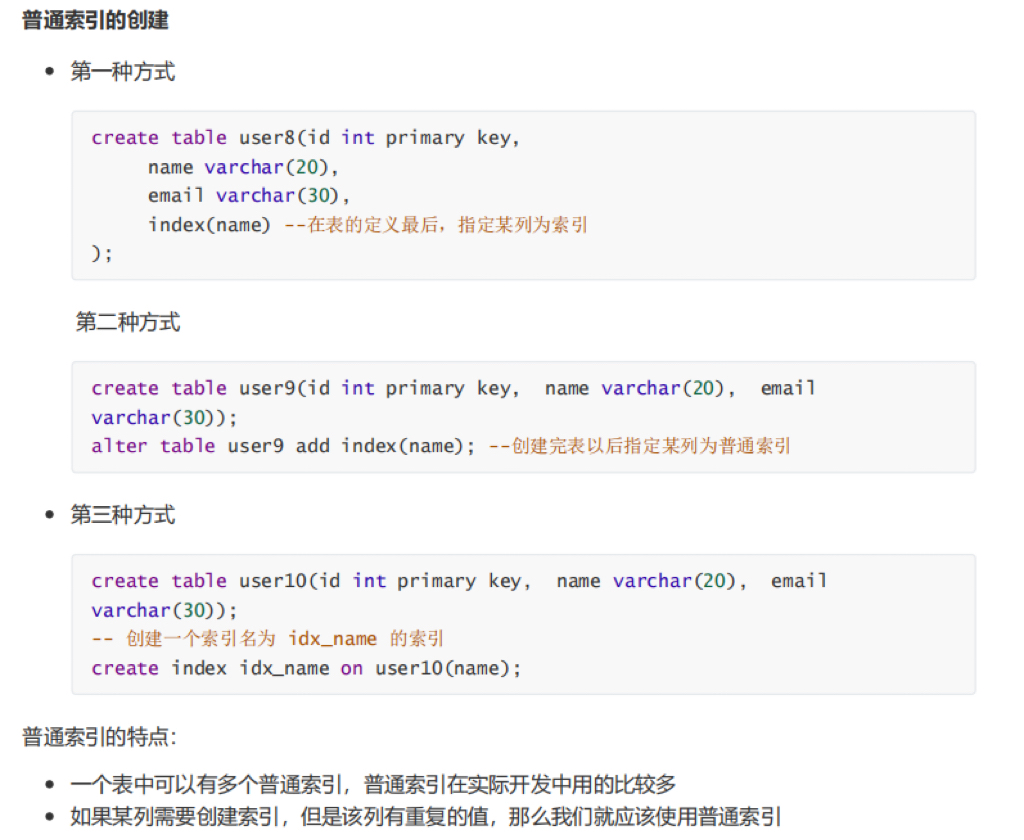
4.4 复合索引(常用)
- 多个字段组合成索引
- 遵循最左前缀原则
最左前缀:必须从左到右依次匹配,不能跳过。
sql
create index idx_name_age on user(name,age);

举个例子
假设有一张用户表:
sql
CREATE TABLE user (
id INT PRIMARY KEY, -- 主键索引
name VARCHAR(20),
age INT,
city VARCHAR(20),
INDEX idx_name_age (name, age) -- 复合索引 (name, age)
);查询1:使用覆盖索引,避免回表
sql
SELECT name, age FROM user WHERE name = '张三';- 条件用了复合索引的最左列
name,满足最左前缀原则。 - 索引
idx_name_age中已经包含了name和age,查询需要的字段都在索引里,直接从索引返回数据,不用回表。
查询2:缺少最左列,索引失效
sql
SELECT name, age FROM user WHERE age = 25;- 条件没有
name,不满足最左前缀原则,idx_name_age无法高效使用。
查询3:索引未覆盖所有字段,仍需回表
sql
SELECT name, age, city FROM user WHERE name = '张三';- 虽然满足最左前缀,但
city不在idx_name_age中,索引只能找到name和age,还得拿着id回主键索引取city。
总结:
复合索引遵循 最左前缀原则 ,只有从第一列开始连续匹配才能被有效利用;如果索引 包含了查询所需的所有列(覆盖索引) ,就能 避免回表,直接返回结果。
4.5 全文索引(fulltext)
- 用于大文本检索
- 不支持 like "% xxx%"
sql
create fulltext index idx_content on article(content);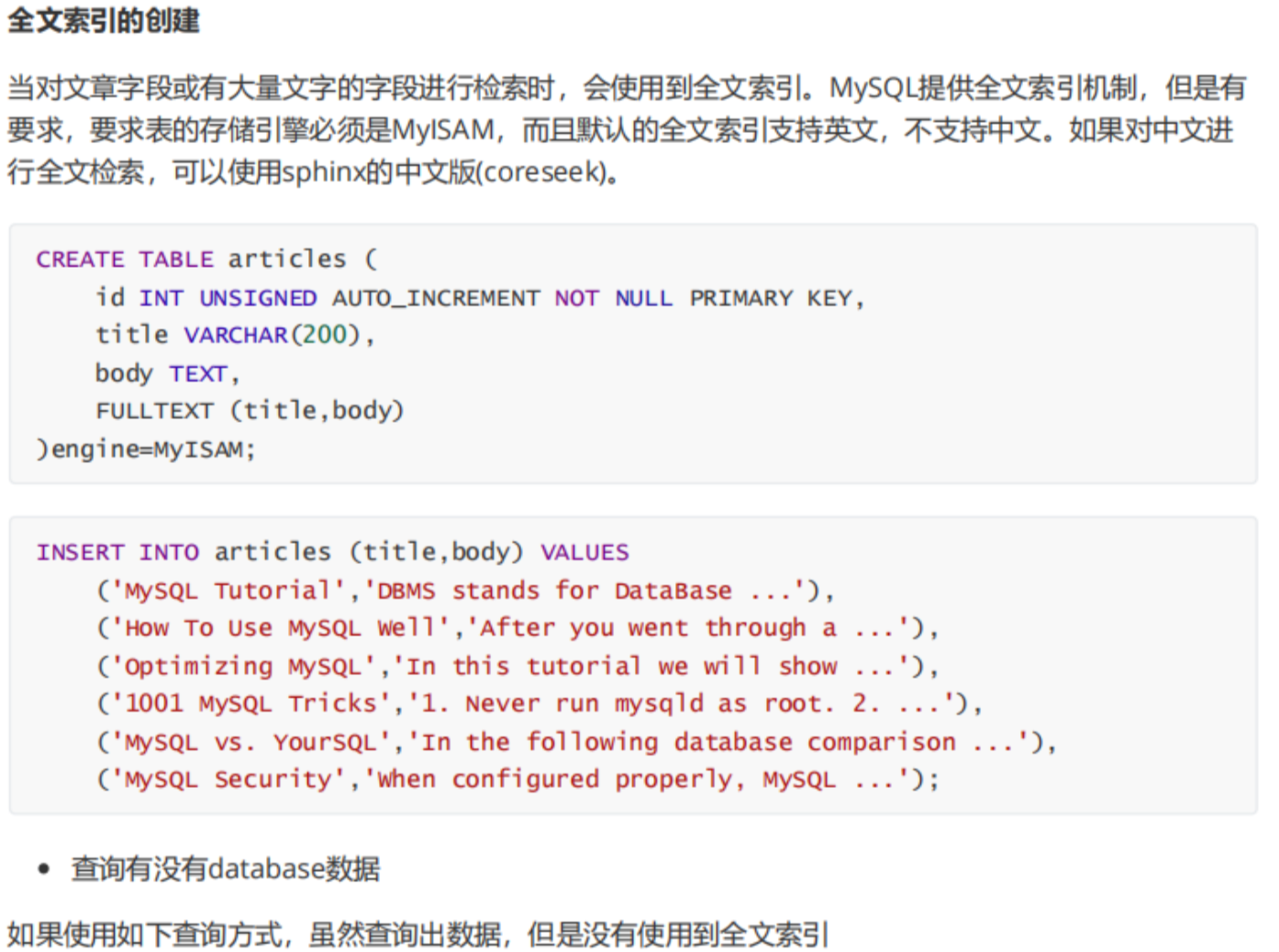

五. 索引的删除与查看操作
5.1 删除索引
sql
drop index idx_name on user;
5.2 查看索引
sql
show index from user;
show index from user\G
六. 索引知识点小结
6.1 索引失效场景
- 违反最左前缀
- 使用函数
where upper(name)='A' - 隐式类型转换
where id='123' - like '% xxx' 以通配符开头
- 使用
or但有字段无索引 - order by 违反最左前缀
- 使用!= 、 not in 、 not exists
- 优化器判断全表扫描更快(数据量少)
6.2 索引设计最佳实践
- 优先创建复合索引,而不是单列索引
- 索引字段要高选择性(如性别不适合)
- 不要索引频繁更新的字段
- 不要索引无用字段
- 单表索引建议不超过 5 个
- 复合索引字段顺序:等值在前,范围在后
- 尽量使用覆盖索引,避免 select *
6.3 总结
- 索引是 B + 树结构,目的是减少 IO、加速查询
- InnoDB 是聚簇索引,MyISAM 是非聚簇索引
- 辅助索引存主键,查询可能回表
- 复合索引必须遵循最左前缀
- 覆盖索引能避免回表,大幅提升速度
- 索引不是越多越好,要按业务设计
- 掌握索引失效场景,SQL 才能真正高效