agent + subagent 比"agent + 多 skill"更好,但不是最优。最优是"router agent + 按需 subagent + skill 内置在 subagent 里"。
几种方案对比
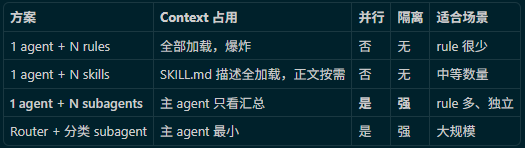
为什么 subagent 更好
Context 隔离 :每个 subagent 独立上下文,主 agent 只收到最终报告,不被 rule 细节污染。
并行执行 :N 个 rule 可以同时跑(你工作区里 runSubagent 就支持),墙钟时间 ≈ 单条 rule。
失败隔离 :一个 rule 跑飞不影响其他。
token 成本可控:主 agent 不需要把所有 SKILL.md 描述都塞进 system prompt。
但 subagent 也有坑
启动开销 :每个 subagent 是一次独立 LLM 调用,rule 很多时总 token 反而更高。
结果聚合难 :每个 subagent 只返回一条 message,跨 rule 的关联问题(例如 rule A 的修复触发 rule B)需要主 agent 二次推理。
无法共享中间产物:subagent A 已经读过的文件,subagent B 还要再读一遍。
推荐的架构:Router + 分层 subagent + 精简 skill
┌─ Main Agent (router, 极简 prompt)
│ 职责:看 diff → 判断涉及哪些 rule 类别 → 分派
│
├─ 并行 dispatch
│ ├─ Subagent: 安全类 rule (内嵌 OWASP/注入/越权 skill)
│ ├─ Subagent: C++23 现代化 (复用已有 cpp23-upgrade skill)
│ ├─ Subagent: libs 复用检查 (复用 libs-reuse-checker)
│ ├─ Subagent: dead code (复用 cplane-dead-code-checker)
│ └─ Subagent: 命名/格式/forbidden words
│
└─ Aggregator(可选,第二轮主 agent)
去重 + 按文件聚合 + 排优先级输出
分类 vs 分层
分类(横向):把 rule 按主题分组
undefined-behavior 类
├─ 越界访问 skill
├─ 生命周期/悬垂指针 skill
├─ 未初始化读 skill
└─ 有符号溢出 skill
分层(纵向):不同抽象层次的 agent 串联
Layer 1: Router → 看 diff,决定跑哪些类
Layer 2: 类 subagent → 例如 UB-check subagent
Layer 3: skill → subagent 内部按需 read_file 加载具体 skill
推荐的落地形态
Main Agent (Router)
│ 只看 diff + 文件路径,输出:"需要跑 UB / 并发 / 复用 / 命名"
│
├─► Subagent: UB-checker
│ prompt 里写:根据改动特征,按需 read_file 这些 skill:
│ - skills/ub/out-of-bounds.md
│ - skills/ub/lifetime.md
│ - skills/ub/uninitialized.md
│ - skills/ub/signed-overflow.md
│ → 只加载相关的,不是全加载
│
├─► Subagent: Concurrency-checker
│ - skills/concurrency/data-race.md
│ - skills/concurrency/deadlock.md
│ - skills/concurrency/rt-safety.md
│
├─► Subagent: Reuse-checker
│ - skills/libs-reuse-checker
│ - skills/cpp23-upgrade
│
└─► Subagent: Style/Naming
-
skills/forbidden-words.md
-
skills/naming.md
关键设计点 :
类 subagent 的 prompt 要小,只写"你负责 UB 类问题,根据下面的特征判断该读哪个 skill"。不要把 skill 正文塞进 prompt。
Skill 文件保持独立、单一职责:一个 skill 只讲一种 UB(例如 lifetime),方便复用和增量维护。和你现在 cpp23-upgrade/references/features/NN-*.md 的模式一致------每个特征一个文件。
subagent 内部用 SKILL.md 描述做二次筛选:类 subagent 拿到代码后,先扫一眼所有 skill 的 description(很短),再决定读哪几个正文。这就是 VS Code skills 机制本身的玩法,套到 subagent 里就行。
跨类问题怎么办:例如"用 std::span 同时能修 UB 又是 C++23 现代化"。让主 agent 在聚合阶段去重,或者让 subagent 之间不通信、各报各的,最后由人/aggregator 合并。不要让 subagent 互相调用,那样复杂度爆炸。
关键点:
- 按"类别"而不是"每条 rule"建 subagent。10 条命名规范放一个 subagent 里跑,比 10 个 subagent 高效。
- Skill 作为 subagent 的"私有知识",而不是主 agent 的。subagent prompt 里直接 read_file 加载 SKILL.md,主 agent 完全看不到。
- Router 用 diff/文件路径预筛,例如 component_cprt 下的改动才跑实时性 rule,itf 改动才跑接口兼容 rule。这能砍掉 50%+ 无关 subagent。
- 共享 cache:让 router 先读一次改动文件清单 + diff,作为 context 传给所有 subagent,避免重复 IO。
更激进的优化(如果 rule 真的很多)
- 两阶段 review:第一阶段 cheap subagent(小模型)做粗筛,标记"可能违反 X 类规则";第二阶段 expensive subagent(大模型)只针对被标记的部分深查。
- 静态工具前置:能用 clang-tidy / grep / AST 工具确定性判断的 rule,根本不要进 LLM。LLM 只处理需要语义理解的 rule(例如"是否在重复造轮子")。你们 repo 里已经有 clang-tidy.cmake、forbidden_words_config.yaml,应该尽量榨干。
- rule 优先级 + 早停:P0 rule 违反就直接 block,不跑后续。
结论
- 从"全 skill 加载"切到 agent + subagent 是正确方向。
- 但不要 1 rule = 1 subagent,按类别聚合。
- 配合 router 预筛 + 静态工具前置 + skill 私有化到 subagent,才能真正解决 context 膨胀。